Antes de empezar a hablar de bases de datos y de los distintos modelos de datos que existen, primero explicaré qué es una base de datos y cómo se utiliza.
Una base de datos es una colección organizada de datos, almacenados y accesibles de forma electrónica. Se utiliza para almacenar y recuperar datos estructurados, semiestructurados o sin procesar, que normalmente están relacionados con un tema o una actividad.
En el corazón de toda base de datos hay al menos un modelo utilizado para describir sus datos. Y según el modelo que utilice, una base de datos puede tener características ligeramente diferentes y almacenar distintos tipos de datos.
Para escribir, recuperar, modificar, ordenar, transformar o imprimir la información de la base de datos, se utiliza un software llamado Sistema de Gestión de Bases de Datos (DBMS, por sus siglas en inglés).
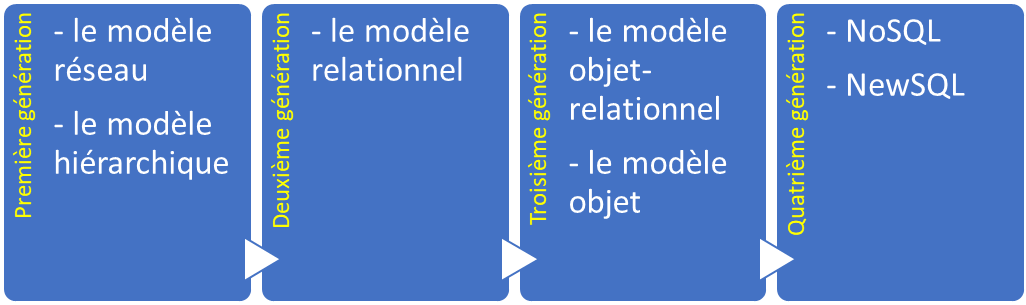
El tamaño, la capacidad y el rendimiento de las bases de datos y sus respectivos DBMS ha aumentado de forma significativa. Esto ha sido posible gracias a los avances tecnológicos en varios ámbitos, como los procesadores, la memoria y almacenamiento de los ordenadores y las redes informáticas. En general, el desarrollo de la tecnología de bases de datos puede dividirse en cuatro generaciones basadas en los modelos o la estructura de los datos: navegacional, relacional, de objetos y post-relacionales.
 Por comentarios
Por comentarios
 Open Exchange app
Open Exchange app



.png)
