Estructura interna de los bloques de bases de datos en Caché (Parte 3)
¡Hola a tod@s de nuevo!
En este tercer artículo (consulte la Parte 1 y la Parte 2) continúo con la presentación de la estructura interna de las bases de datos en Caché. Esta vez, les contaré algunas cosas interesantes y les explicaré cómo mi proyecto sobre el Explorador de bloques en Caché puede ayudarles a hacer que su trabajo sea más productivo.
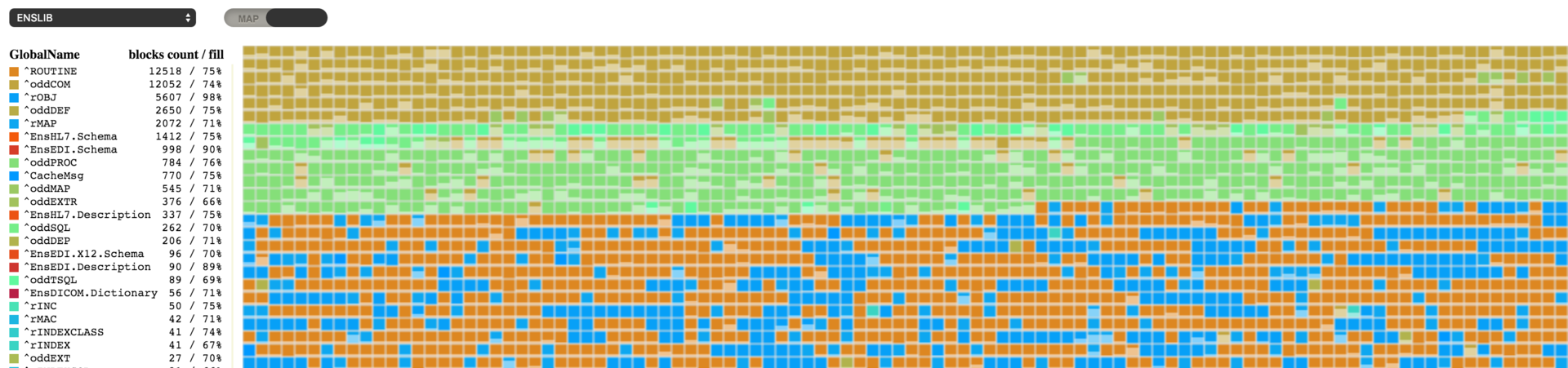
Creo que muchos de ustedes reconocerán lo que se muestra en la imagen (sobre la que se puede hacer clic). Cuando necesité visualizar la fragmentación de los globales, lo primero que pasó por mi mente fueron varias herramientas para desfragmentar el disco. Y, tengo la esperanza, de que conseguí elaborar un producto que es tan útil como dichas herramientas para hacerlo.
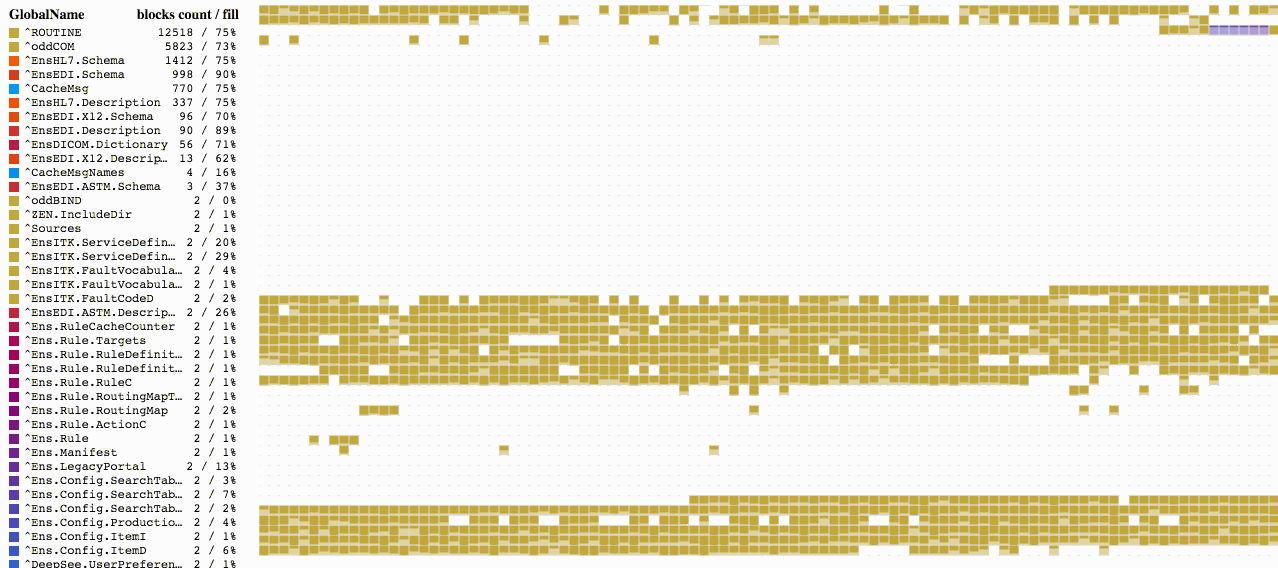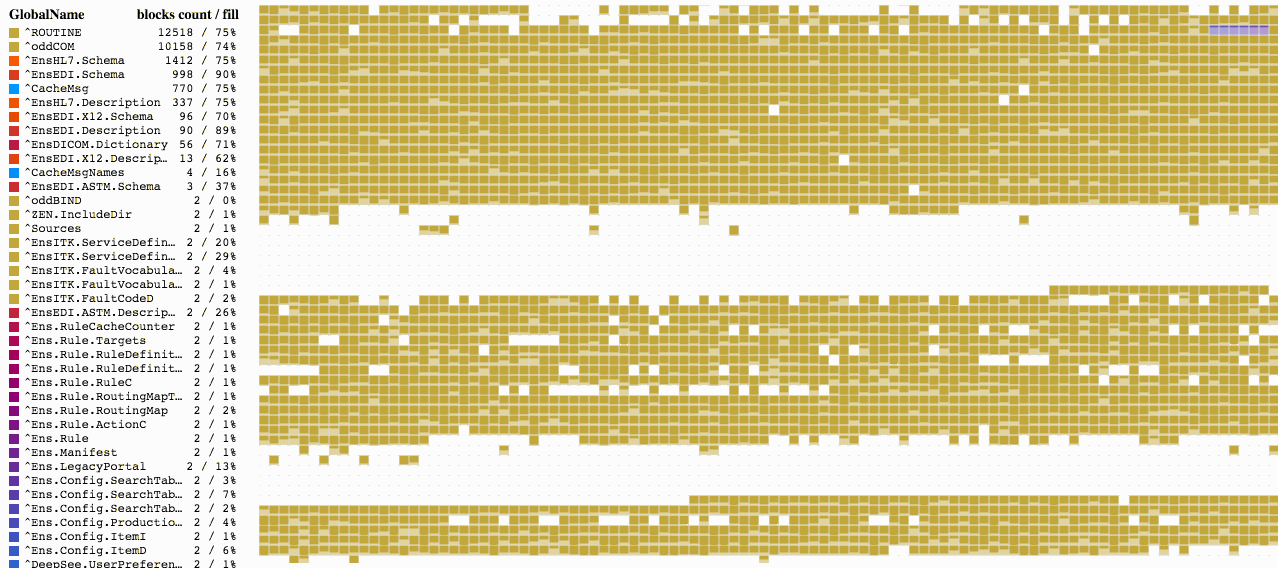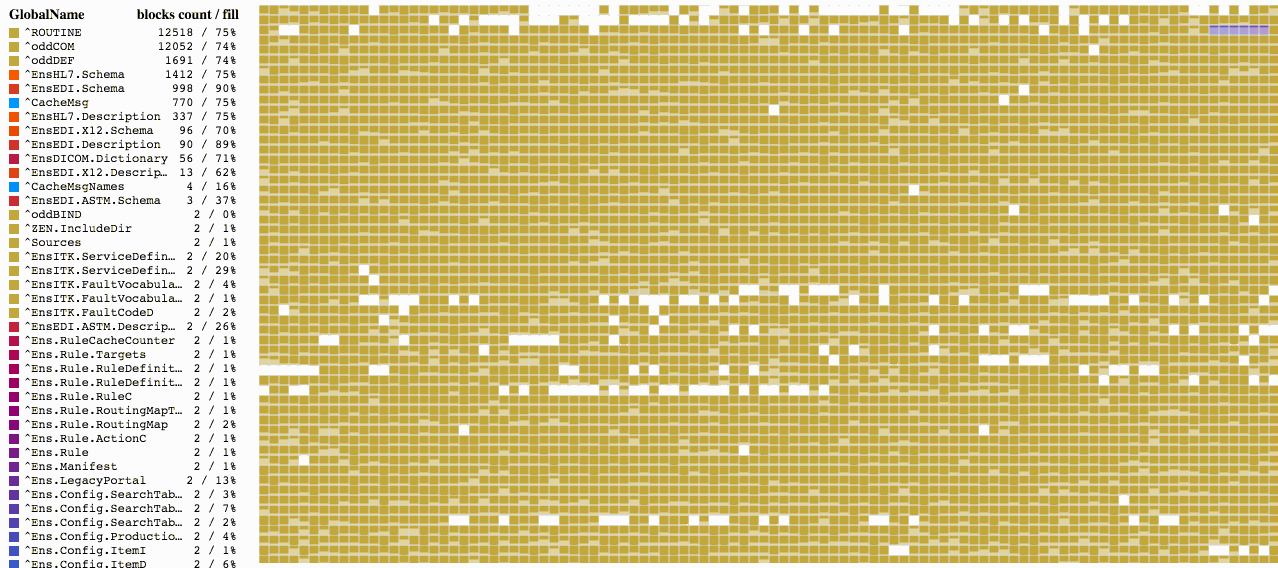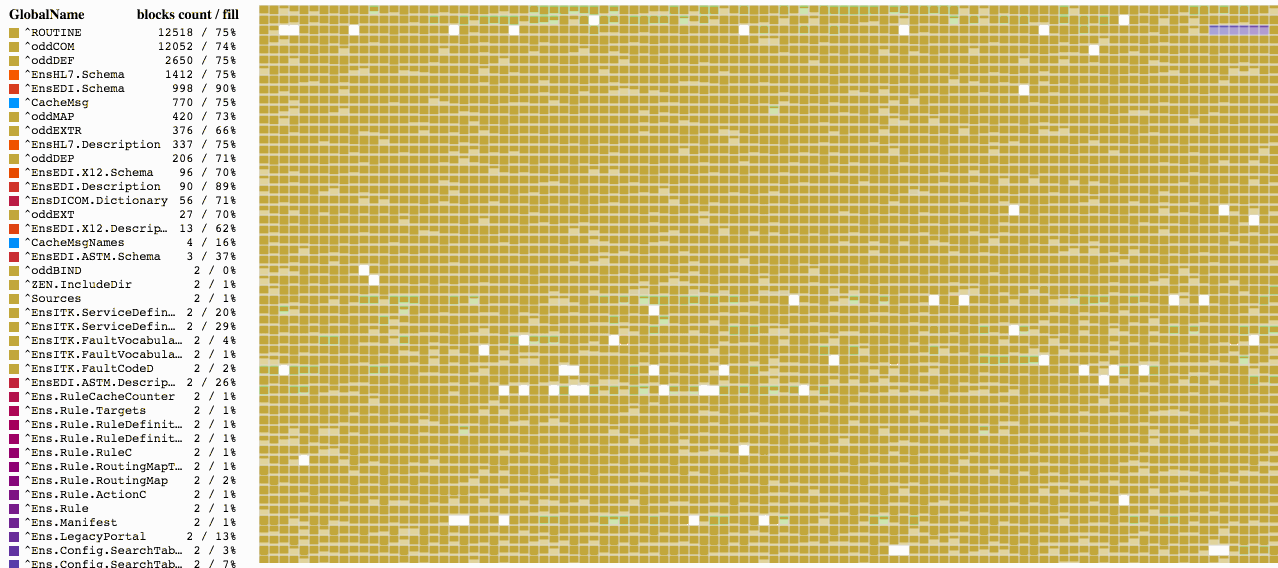
En esta herramienta se muestra un diagrama de bloques. Donde cada cuadro representa un bloque, y su color corresponde a un global determinado, el cual se muestra mediante una lista en la sección de leyendas. Cada uno de los bloques, por sí mismo, también muestra que tan saturado de datos está. Esto les ayudaría a calcular rápidamente la capacidad de toda la base de datos con tan solo echar un vistazo en el diagrama. La visualización del global y niveles del diagrama de bloques aún no se han implementado, al igual que todos los bloques vacíos, por lo que estos se mostrarán en color blanco.
Puede seleccionar una base de datos y el diagrama de bloques comenzará a cargarlos inmediatamente. La información no se carga de manera consecutiva, sino que lo hace de acuerdo al orden que tengan los bloques en el árbol de bloques, de modo que el proceso puede verse muy similar al que se muestra en la siguiente imagen.
Continuaremos trabajando con la base de datos que utilizamos en el artículo anterior. Eliminé todos los globales, ya que no los necesitaremos. También generé nuevos datos mediante el paquete de la clase Sample, la cual se encuentra en la base de datos SAMPLES. Para hacerlo, configuré el mapeo de paquetes con mi namespace llamado HAB.

Después, ejecuté un comando para generar datos.
do ##class(Sample.Utils).Generate(20000)En nuestro mapa, obtuve el siguiente resultado:

Observe que los bloques no comienzan a llenarse desde el inicio del archivo. Comienzan a llenarse a partir del bloque 16 y vemos los bloques puntero en el nivel superior desde el bloque 50, en los bloques de datos. Tanto el 16 como el 50 son valores predeterminados pero, si es necesario, pueden modificarse. El inicio del bloque puntero se define en la propiedad NewGlobalPointerBlock de la clase SYS.Database, en esta se establece el valor predeterminado para los nuevos globales. Para los globales que ya existen, esto se puede modificar desde la clase %Library.GlobalEdit mediante la propiedad PointerBlock. El bloque que iniciará la secuencia de bloques de datos se especifica en la propiedad NewGlobalGrowthBlock de la clase SYS.Database. La propiedad GrowthBlock de la clase %Library.GlobalEdit hace lo mismo para los globales individuales. La modificación de estas propiedades únicamente tiene sentido para aquellos globales que todavía no contienen datos, ya que estos cambios no tienen efecto sobre la posición actual del bloque puntero que se encuentra en el nivel superior o de los bloques de datos.
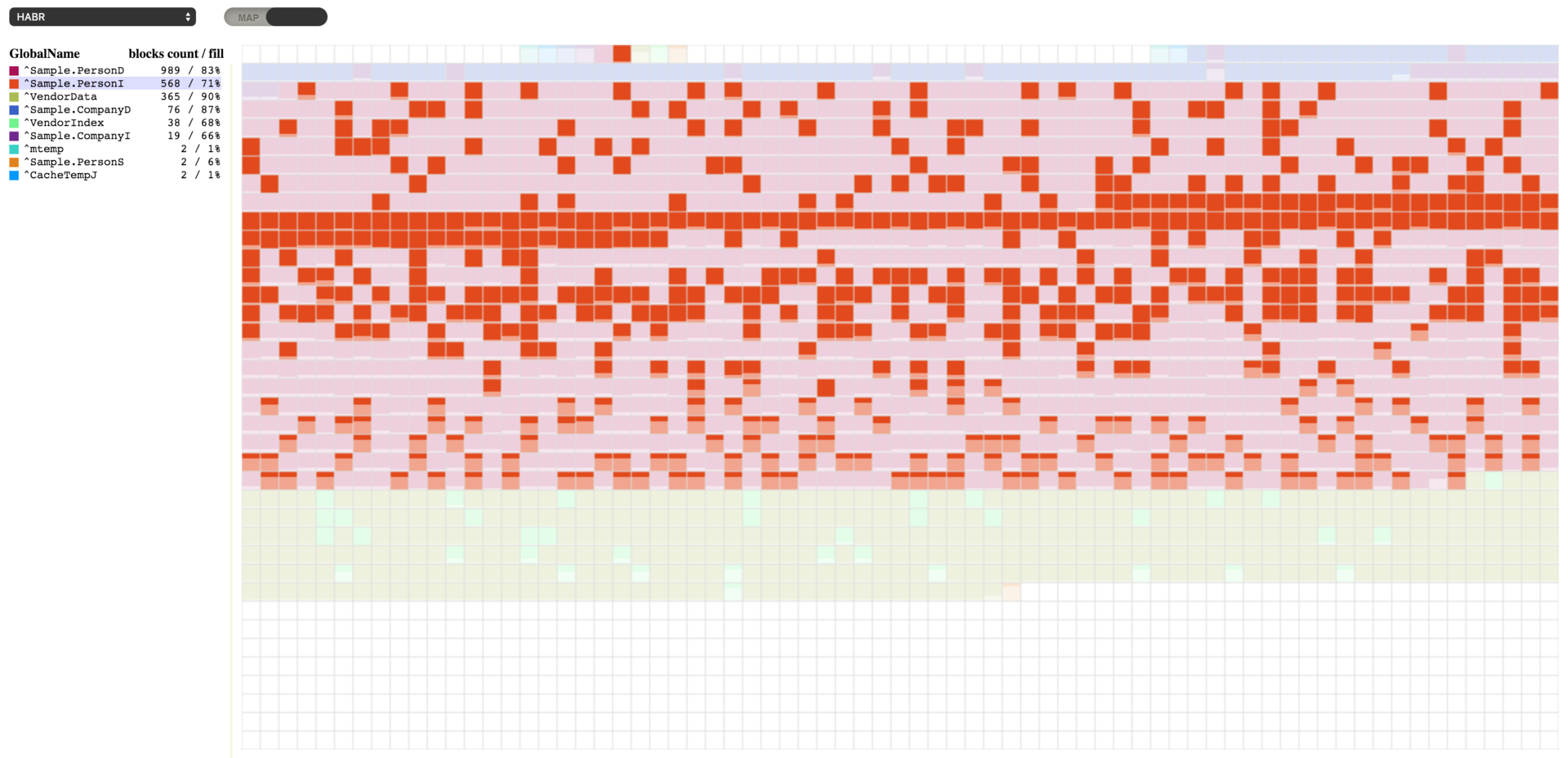
Aquí podemos ver que el global ^Sample.PersonD cuenta con 989 bloques y está lleno en un 83%, seguido por el global ^Sample.PersonI que tiene 573 bloques (y está lleno en un 70% de su capacidad). Podemos escoger cualquiera de los globales para ver los bloques que están asignados para él. Y si seleccionamos el global ^Sample.PersonI, veremos que algunos de sus bloques están casi vacíos. También podemos ver que los bloques que pertenecen a estos dos globales están mezclados. Pero existe una razón para esto. Cuando se crean nuevos objetos, ambos globales se llenan: uno con los datos y el otro con los índices para la tabla Sample.Person.
Ahora que tenemos algunos datos para hacer una prueba, podemos aprovechar las funciones de administración de la base de datos que ofrece Caché y ver el resultado. Para comenzar, ajustemos un poco nuestros datos para crear una ilusión de actividad, en la que se puedan añadir y eliminar datos. Ejecutaremos un código que eliminará algunos datos de manera aleatoria.
set id=""
set first=$order(^Sample.PersonD(""),1)
set last=$order(^Sample.PersonD(""),-1)
for id=first:$random(5)+1:last {
do ##class(Sample.Person).%DeleteId(id)
}
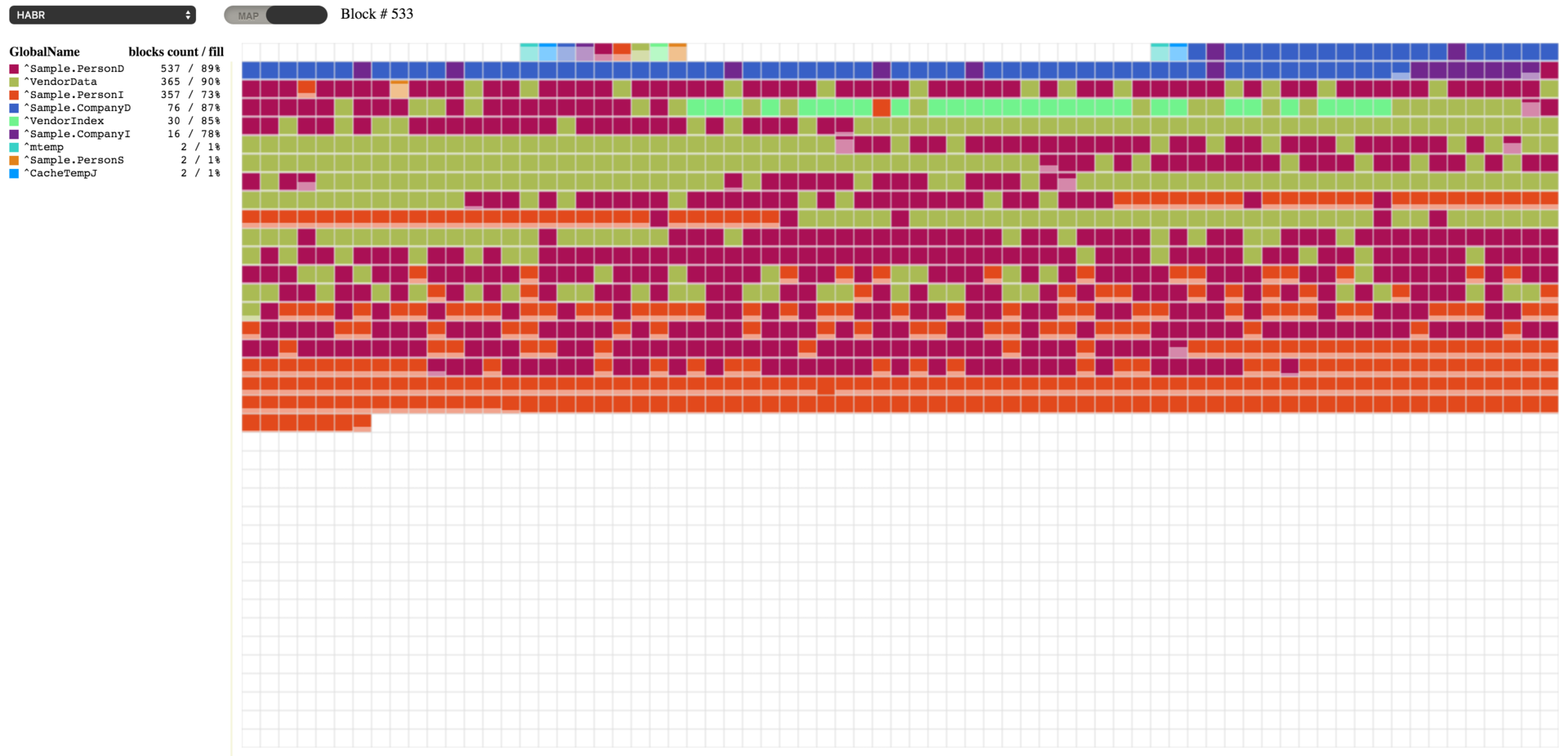
Cuando ejecute este código, verá el resultado que se muestra a continuación. Tenemos algunos bloques vacíos, mientras que otros están llenos entre un 64% y un 67% de su capacidad.
Podemos utilizar la herramienta ^DATABASE desde el namespace %SYS para trabajar con nuestra base de datos. Utilizaremos algunas de sus funciones.
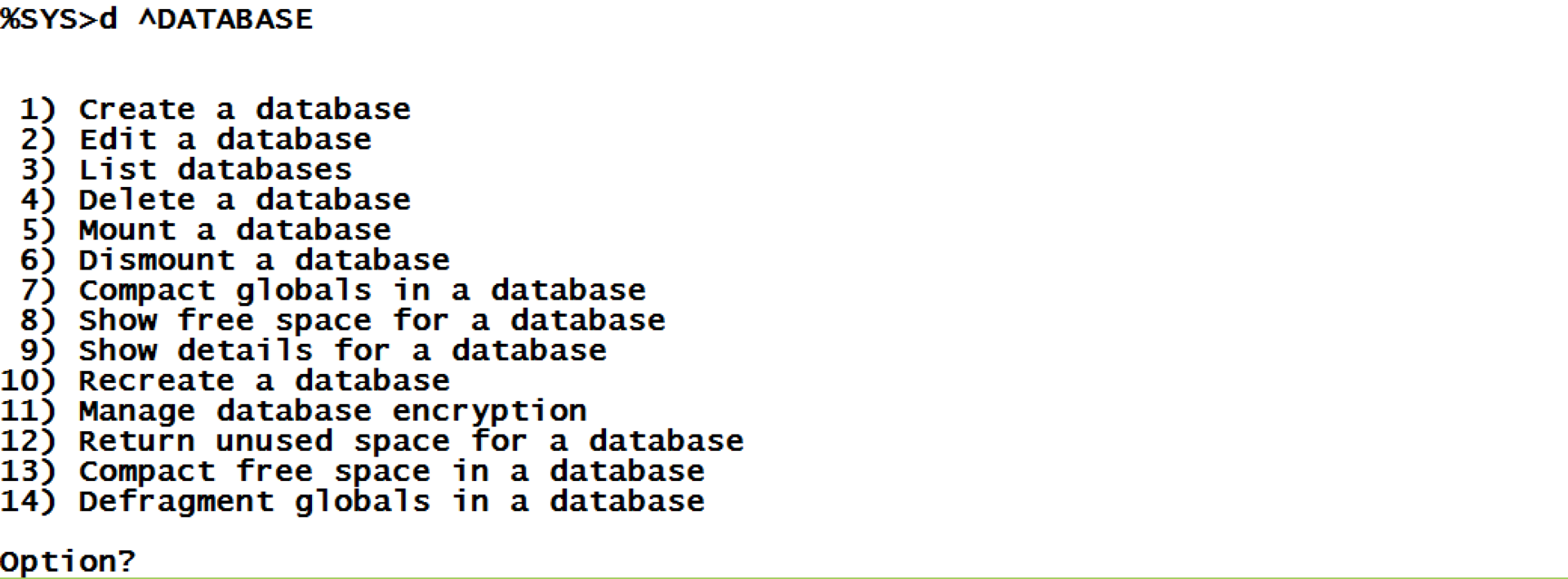
En primer lugar, ya que apenas llenamos los bloques, vamos a comprimir todos los globales de la base de datos y veamos lo que ocurre.
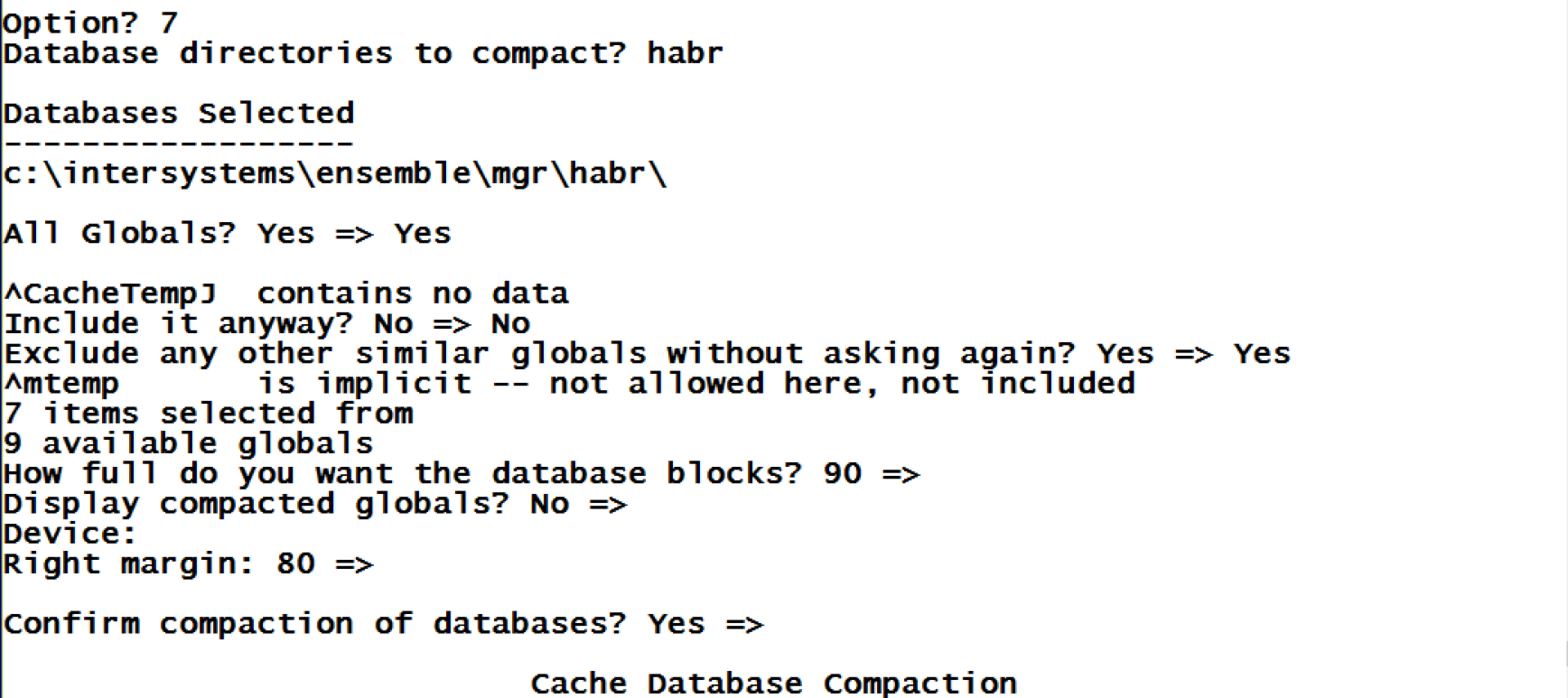

Como puede ver, la compresión nos permitió acercarnos, tanto como fue posible, al valor que necesitábamos del 90% de la capacidad. Y como resultado, los bloques que antes estuvieron vacíos ahora están llenos de los datos que se reubicaron desde los otros bloques. Los globales de la base de datos pueden comprimirse utilizando la herramienta ^DATABASE (función 7) o mediante el siguiente comando con la ruta hacia la base de datos que se aprobó como el primer parámetro:
do ##class(SYS.Database).CompactDatabase("c:\intersystems\ensemble\mgr\habr\")También podemos mover todos los bloques vacíos hacia el final de la base de datos. Esto puede ser necesario, por ejemplo, cuando elimine una gran cantidad de datos y posteriormente desee compactar la base de datos. Para demostrar esto, repetiremos la eliminación datos desde la base de datos con la que hicimos nuestra prueba.
set gn=$name(^Sample.PersonD)
set first=$order(@gn@(""),1)
set last=$order(@gn@(""),-1)
for i=1:1:10 {
set id=$random(last)+first
write !,id
set count=0
for {
set id=$order(@gn@(id))
quit:id=""
do ##class(Sample.Person).%DeleteId(id)
quit:$increment(count)>1000
}
}Esto es lo que obtuve después de la eliminación de datos.

Aún podemos ver algunos bloques vacíos aquí. Caché le permite mover estos bloques vacíos al final del archivo de la base de datos y después compactarlos. Para mover los bloques vacíos, utilizaremos el método FileCompact desde la clase SYS.Database, que se encuentra en el namespace del sistema o podemos recurrir a la herramienta ^DATABASE (función 13). En este método se aceptan tres parámetros: la ruta hacia la base de datos, la cantidad de espacio libre que deseamos obtener al final del archivo (0 como valor predeterminado), y el parámetro de retorno (la cantidad de espacio libre resultante).
do ##class(SYS.Database).FileCompact("c:\intersystems\ensemble\mgr\habr\",999)Y esto es lo que obtenemos: no hay ningún bloque vacío. Los únicos bloques vacíos que aparecen al principio no cuentan, ya que se encuentran allí debido a la configuración (el lugar donde comienza el puntero del nivel superior más alto y los bloques de datos).
Desfragmentación
Ahora podemos realizar la desfragmentación de nuestros globales. En este proceso se reordenarán los bloques de cada global con una distribución diferente. Para la desfragmentación puede requerirse que haya algo de espacio libre al final del archivo de la base de datos, de modo que este espacio puede añadirse si la situación así lo requiere. El proceso puede iniciarse mediante la función 14 de la herramienta ^DATABASE o utilizando el siguiente comando:
d ##class(SYS.Database).Defragment("c:\intersystems\ensemble\mgr\habr\")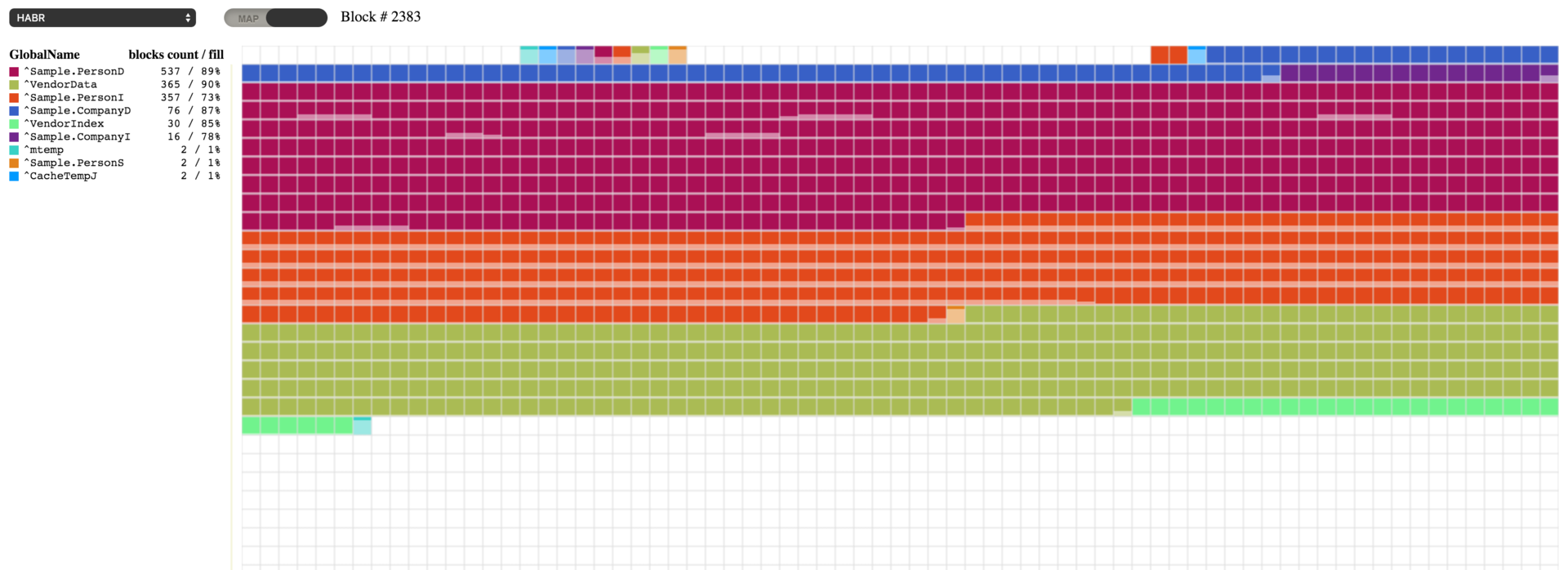
Liberación de espacio en disco
Ahora podemos ver nuestros globales alineados. Sin embargo, parece que la desfragmentación utilizó un poco más de espacio adicional en el archivo de la base de datos. Podemos liberar este espacio utilizando la función 12 de la herramienta ^DATABASE o mediante el siguiente comando:
d ##class(SYS.Database).ReturnUnusedSpace("c:\intersystems\ensemble\mgr\habr\")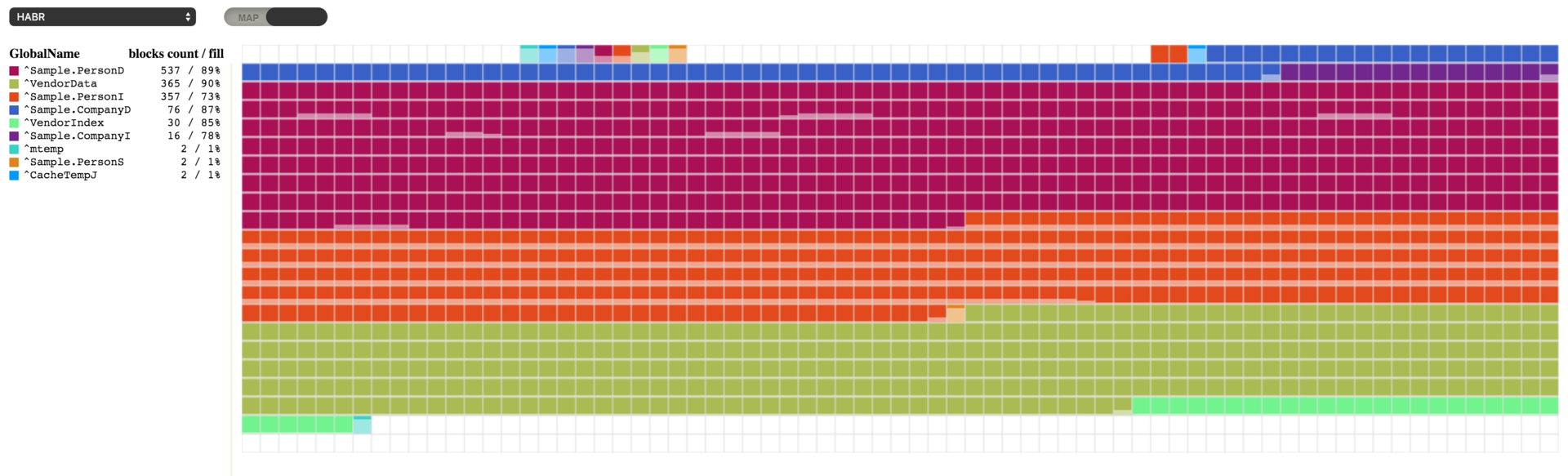
Ahora, nuestra base de datos ocupa mucho menos espacio y solo queda 1 Mb de espacio libre en el archivo de la base de datos. La posibilidad de desfragmentar a los globales en una base de datos y administrar el espacio libre que tienen disponible al mover los bloques y crear espacio para liberar otros se introdujo recientemente. Antes de eso, cada vez que era necesario desfragmentar la base de datos y reducir el tamaño del archivo de la base de datos se tenía que utilizar la herramienta ^GBLOCKCOPY . Esta realizaba una copia "bloque por bloque" desde la base de datos de origen hacia otra que se hubiera creado recientemente, y permitía que el usuario seleccionara los globales específicos que se iban a transferir. La herramienta todavía está disponible.