Modelos de datos en InterSystems IRIS
Antes de empezar a hablar de bases de datos y de los distintos modelos de datos que existen, primero explicaré qué es una base de datos y cómo se utiliza.
Una base de datos es una colección organizada de datos, almacenados y accesibles de forma electrónica. Se utiliza para almacenar y recuperar datos estructurados, semiestructurados o sin procesar, que normalmente están relacionados con un tema o una actividad.
En el corazón de toda base de datos hay al menos un modelo utilizado para describir sus datos. Y según el modelo que utilice, una base de datos puede tener características ligeramente diferentes y almacenar distintos tipos de datos.
Para escribir, recuperar, modificar, ordenar, transformar o imprimir la información de la base de datos, se utiliza un software llamado Sistema de Gestión de Bases de Datos (DBMS, por sus siglas en inglés).
El tamaño, la capacidad y el rendimiento de las bases de datos y sus respectivos DBMS ha aumentado de forma significativa. Esto ha sido posible gracias a los avances tecnológicos en varios ámbitos, como los procesadores, la memoria y almacenamiento de los ordenadores y las redes informáticas. En general, el desarrollo de la tecnología de bases de datos puede dividirse en cuatro generaciones basadas en los modelos o la estructura de los datos: navegacional, relacional, de objetos y post-relacionales.
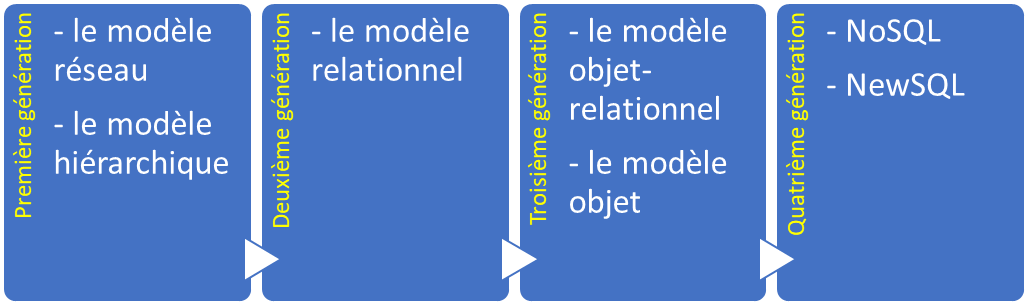

A diferencia de las tres primeras generaciones, que se caracterizan por un modelo de datos específico, la cuarta generación incluye muchas bases de datos diferentes basadas en distintos modelos, como columnas, gráficos, documentos, componentes, multidimensiones, clave-valor, almacenamiento en memoria, etc. Todas estas bases de datos están unidas por un único nombre NoSQL (NoSQL o ahora es más preciso decir No sólo SQL).
Además, ahora aparece una nueva clase, que se llama NewSQL. Se trata de bases de datos relacionales modernas que tienen como objetivo ofrecer el mismo rendimiento escalable que los sistemas NoSQL para cargas de trabajo de procesamiento de transacciones en línea (lectura-escritura), a la vez que utilizan SQL y mantienen ACID.
Por casualidad, entre estas bases de datos de cuarta generación se encuentran las que admiten los modelos de datos múltiples mencionados anteriormente. Se llaman bases de datos multimodelo. Un buen ejemplo de este tipo de base de datos es InterSystems IRIS. Por ello, la utilizaré para dar ejemplos de distintos tipos de modelos, según vayan presentándose.
La primera generación de bases de datos utilizaba modelos jerárquicos o modelos en red. El núcleo de los primeros es una estructura en forma de árbol en la que cada registro tiene un solo propietario. Podéis ver cómo funciona utilizando el ejemplo de InterSystems IRIS, porque su modelo principal es jerárquico y todos los datos se almacenan en globals (que son árboles B). Podéis leer más sobre los globals aquí.

Podemos crear este árbol en IRIS:
Set ^a("+7926X", "city") = "Moscow"
Set ^a("+7926X", "city", "street") = "Req Square"
Set ^a("+7926X", "age") = 25
Set ^a("+7916Y", "city") = "London"
Set ^a("+7916Y", "city", "street") = "Baker Street"
Set ^a("+7916Y", "age") = 36Y verlo en la base de datos:

Después, Edgar F. Codd propuso su álgebra relacional y su teoría del almacenamiento de datos, basada en principios relacionales, en 1969. Y tras ello se crearon las bases de datos relacionales. El uso de relaciones (tablas), atributos (columnas), tuplas (filas) y, lo que es más importante, transacciones y requisitos ACID, hizo que estas bases de datos fueran muy populares y lo siguen siendo ahora.
Por ejemplo, tenemos el siguiente esquema:
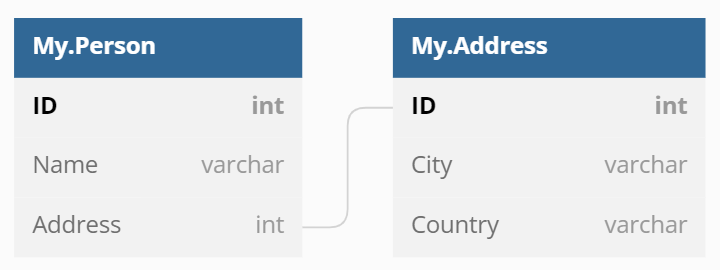
Podemos crear y completar tablas:
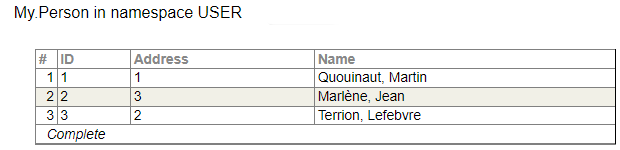
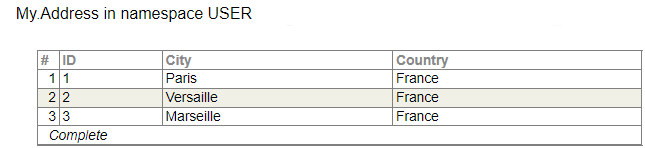
Y si escribimos la consulta:
select p.ID, p.Name, a.Country, A.City
from My.Person p left join My.Address a
on p.Address = a.IDrecibiremos la respuesta:
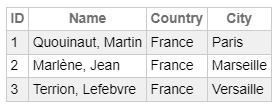
A pesar de las significativas ventajas de las bases de datos relacionales, con la difusión de los lenguajes de objetos se hizo necesario almacenar datos orientados a objetos en bases de datos. Por eso, en los años 90 aparecieron las primeras bases de datos orientadas a objetos y objeto-relacionales. Estas últimas se crearon a partir de bases de datos relacionales y añadiéndole complementos para simular el trabajo con objetos. Las primeras se desarrollaron desde cero a partir de las recomendaciones del consorcio OMG (Object Management Group) y después del ODMG (Object Data Management Group).
Las ideas clave de estas bases de datos orientadas a objetos son las siguientes.
El almacén de datos único es accesible usando:
- object definition language - schema definition, permite definir clases, sus atributos, relaciones y métodos
- object-query language - declarative, es un lenguaje similar a SQL, que permite obtener objetos de la base de datos
- object manipulation language - permite modificar y guardar datos en la base de datos, admite transacciones y la invocación de métodos.
Este modelo permite obtener datos de bases de datos mediante lenguajes orientados a objetos.
Si tomamos la misma estructura que en el ejemplo anterior, pero en la forma orientada a objetos, tendremos las siguientes clases:
Class My.Person Extends %Persistent
{
Property Name As %Name;
Property Address As My.Address;
}Class My.Address Extends %Persistent
{
Property Country;
Property City;
}Y podemos crear los objetos utilizando el lenguaje orientado a objetos:
set address = ##class(My.Address).%New()
set address.Country = "France"
set address.City = "Marseille"
do address.%Save()
set person = ##class(My.Person).%New()
set person.Address = address
set person.Name = "Quouinaut, Martin"
do person.%Save()Desafortunadamente, las bases de datos de objetos no lograron competir con las bases de datos relacionales a pesar de su posición dominante, y como resultado, surgieron muchos ORM.
En cualquier caso, con la expansión de Internet en la década de los 2000 y la aparición de nuevos requisitos para el almacenamiento de datos, empezaron a surgir otros modelos de datos y DBMS. Dos de estos modelos que se utilizan en IRIS son los de documentos y columnas.
Las bases de datos orientadas a documentos se utilizan para gestionar datos semiestructurados. Se trata de datos que no siguen una estructura fija y llevan la estructura dentro. Cada unidad de información en una base de datos de este tipo es un par simple: una clave y un documento específico. Este documento normalmente tiene un formato JSON y contiene la información. Como la base de datos no requiere un esquema particular, también es posible integrar distintos tipos de documentos en el mismo almacén.
Si tomamos el ejemplo anterior, podemos tener documentos como estos:
{
"Name":"Quouinaut, Martin",
"Address":{
"Country":"France",
"City":"Paris"
}
}
{
"Name":"Merlingue, Luke",
"Address":{
"Country":"France",
"City":"Nancy"
},
"Age":26
}Estos dos documentos con un distinto número de campos se almacenan en la base de datos de IRIS sin ningún problema.
Y el último ejemplo de un modelo que estará disponible en la versión 2022.2 es el modelo de columnas. En este caso, el DBMS almacena las tablas de datos por columnas y no por filas.
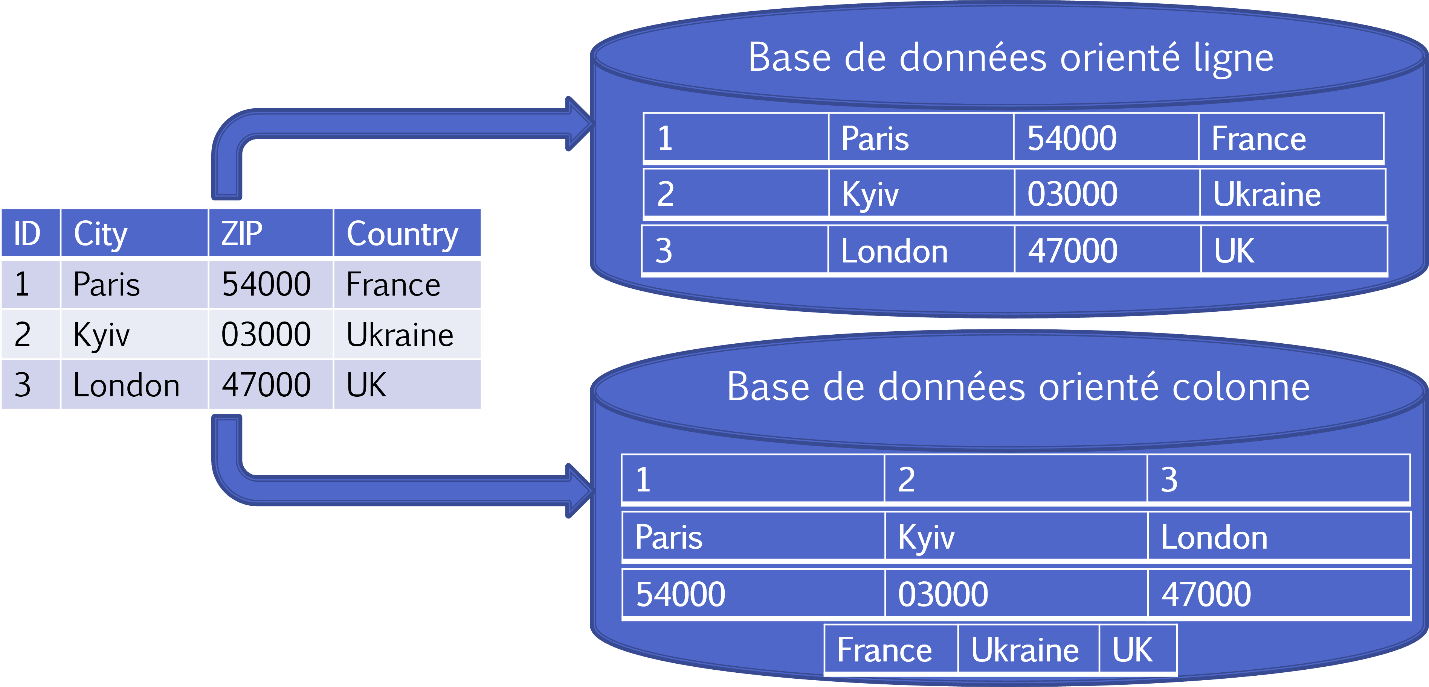
La orientación por columnas permite un acceso más eficiente a los datos para consultar un subconjunto de columnas (eliminando la necesidad de leer columnas que no son relevantes), y más opciones para comprimir datos. Asimismo, comprimir por columnas es más eficaz cuando los datos de la columna son similares. No obstante, generalmente son menos eficaces para insertar nuevos datos.
Podéis crear esta tabla:
Create Table My.Address (
city varchar(50),
zip varchar(5),
country varchar(15)
) WITH STORAGETYPE = COLUMNAREn este caso, la clase es la siguiente:
Class My.Address Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {UnknownUser}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = Address ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50) [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 5) [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15) [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
Storage Default
{
<Data name="_CDM_city">
<Attribute>city</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V1</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_country">
<Attribute>country</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V2</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_zip">
<Attribute>zip</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V3</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<DataLocation>^q3AW.DZLd.1</DataLocation>
<ExtentLocation>^q3AW.DZLd</ExtentLocation>
<ExtentSize>3</ExtentSize>
<IdFunction>sequence</IdFunction>
<IdLocation>^q3AW.DZLd.1</IdLocation>
<Index name="DDLBEIndex">
<Location>^q3AW.DZLd.2</Location>
</Index>
<Index name="IDKEY">
<Location>^q3AW.DZLd.1</Location>
</Index>
<IndexLocation>^q3AW.DZLd.I</IndexLocation>
<Property name="%%ID">
<AverageFieldSize>3</AverageFieldSize>
<Selectivity>1</Selectivity>
</Property>
<Property name="city">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<Property name="country">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<Property name="zip">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<SQLMap name="%%DDLBEIndex">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="IDKEY">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_city">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_country">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_zip">
<BlockCount>-4</BlockCount>
</SQLMap>
<StreamLocation>^q3AW.DZLd.S</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}Después insertamos los datos:
insert into My.Address values ('London', '47000', 'UK')
insert into My.Address values ('Paris', '54000', 'France')
insert into My.Address values ('Kyiv', '03000', 'Ukraine')En los globals podemos ver:

Si abrimos el global con los nombres de las ciudades, podremos ver:

Y si escribimos una consulta:
select City
from My.Addressrecibimos los datos:

En este caso, el DBMS se limita únicamente a leer un global para obtener el resultado completo. Además, ahorra tiempo y recursos en la lectura.
Así pues, hemos hablado de 5 modelos de datos diferentes compatibles con la base de datos InterSystems IRIS: los modelos jerárquicos, relacionales, de objetos, de documentos y de columnas.
Espero que este artículo os resulte útil para saber qué modelos están disponibles. Si tenéis alguna pregunta, podéis escribirla en los comentarios.
Comments
El código se rompió.png)
Thanks Iryna.