¡Hola a todos!
¿Os pensabais perder el último webinar del año? ¡Claro que no! Siguen subiendo los registros, y no es para menos... 
Esta etiqueta se relaciona con las discusiones sobre el desarrollo de soluciones analíticas y de inteligencia empresarial, visualización, Indicadores clave del rendimiento (KPI) y otros tipos de administradores sobre los indicadores empresariales.
¡Hola a todos!
¿Os pensabais perder el último webinar del año? ¡Claro que no! Siguen subiendo los registros, y no es para menos...
¡Buenas a todos!
Vamos a cerrar el año por todo lo alto. Os invitamos a este webinar en español con @Pierre-Yves Duquesnoy "Smart Supply Chain 360: Ver, Decidir, Actuar" el jueves 27 de noviembre, a las 4:00 PM (CET).

Quizá esto sea bien conocido, pero quería ayudar a compartirlo.
Considerad que tenéis las siguientes definiciones de clases persistentes:
Una clase Factura con una propiedad que referencia a Proveedor.
Class Sample.Invoice Extends (%Persistent, %Populate)
{
Parameter DSTIME = "AUTO";Property InvoiceNumber As%Integer(MINVAL = 100000) [ Required ];Property ServiceDate As%Date(MINVAL = "+$h-730") [ Required ];
Index InvoiceNumber On InvoiceNumber;Property Provider As Sample.Provider [ Required ];
Index Provider On Provider [ Type = bitmap ];/// Build some invoices, this will firstlyInterSystems ha estado a la vanguardia de la tecnología de bases de datos desde su creación, siendo pionera en innovaciones que superan constantemente a competidores como Oracle, IBM y Microsoft. Al centrarse en un diseño eficiente del núcleo y adoptar un enfoque sin concesiones en el rendimiento de los datos, InterSystems se ha hecho un hueco en las aplicaciones de misión crítica, garantizando fiabilidad, velocidad y escalabilidad.
Una historia de excelencia técnica
Durante sus primeros años, InterSystems se distinguió por su innovadora arquitectura de bases de datos, que abordaba las
Nos han desbordado las previsiones. Así que, ante el éxito de asistencia y todos los comentarios recibidos, os anuncio una nueva convocatoria extraordinaria del curso: Desarrollo de asistentes virtuales con RAG. ¡Mantenemos el precio promocional reducido! (plazas limitadas).
Para quien se hubiera perdido el anuncio de la primera convocatoria, repito lo que os comentaba. Se trata de un curso abierto a todo el que quiera iniciarse en el desarrollo de asistentes virtuales utilizando IA generativa y el patrón común RAG (Retrieval Augmented Generation). Utilizaréis Python, Jupyter Notebooks y
¿Preferís no leer? Echad un vistazo al vídeo demo:
El auge de los proyectos de Big Data, las analíticas en tiempo real con herramientas self-service, los servicios de consultas en línea y las redes sociales, entre otros, han habilitado escenarios para consultas masivas y de alto rendimiento. En respuesta a este desafío, se creó la tecnología MPP (procesamiento masivamente paralelo) y rápidamente se consolidó. Entre las opciones de MPP de código abierto, Presto (https://prestodb.io/) es la más conocida.Surgió en Facebook y se utilizó para análisis de datos, pero luego se convirtió en código abierto.
Hola Comunidad,
En este artículo, os presentaré mi aplicación iris-DataViz.
iris-DataViz es una aplicación de análisis y visualización de datos exploratorios basada en Streamlit que aprovecha la funcionalidad de IRIS embebido en Python y SQLAlchemy para interactuar con IRIS, así como la biblioteca de Python PyGWalker para el análisis de datos y la visualización de datos. PyGWalker (Python Graphic Walker) es una biblioteca de visualización de datos interactiva creada para Python, que tiene como objetivo llevar la facilidad y funcionalidad de la visualización al estilo de Tableau con arrastrar y
Nos alegra compartir que el equipo de Servicios de Aprendizaje ha añadido recientemente nuevos contenidos a nuestra Ruta de Aprendizaje de InterSystems Reports. Estos últimos vídeos, creados por nuestro socio, insightsoftware, proporcionan instrucciones para desarrollar informes con InterSystems Report Designer.
En estos tres breves vídeos, aprenderéis a:
La invención y popularización de LLMs (Large Language Models) como GPT-4 de OpenAI ha desencadenado una ola de soluciones innovadoras que permiten aprovechar grandes volúmenes de datos no estructurados, que eran prácticamente imposibles de procesar manualmente hasta hace poco. Estas aplicaciones pueden incluir la recuperación de datos (echad un vistazo al curso sobre ML301 de Don Woodlock, con una excelente introducción a la Generación Aumentada de Recuperación), el análisis de sentimientos, e incluso agentes de IA totalmente autónomos, por nombrar sólo algunos ejemplos!
En este artículo, quiero demostrar cómo la funcionalidad de Python Embebido de IRIS puede ser utilizada para interactuar directamente con la librería Python de OpenAI, a través de la creación de una sencilla aplicación de etiquetado de datos que asignará automáticamente palabras clave a los registros que metamos en una tabla de IRIS. Estas palabras clave pueden después ser usadas para buscar y categorizar los datos, así como para analítica de datos. Utilizaré reseñas de productos realizadas por clientes como ejemplo de caso de uso.
 | Cómo incluir IRIS Data en vuestro almacén de datos de Google Big Query y en vuestras exploraciones de datos de Data Studio. En este artículo utilizaremos Google Cloud Dataflow para conectarnos a nuestro Servicio de InterSystems Cloud SQL y crear un trabajo para persistir los resultados de una consulta de IRIS en Big Query en un intervalo. Si tuvisteis la suerte de obtener acceso a Cloud SQL en el Global Summit 2022, como se menciona en "InterSystems IRIS: What's New, What's Next" (InterSystems IRIS: Lo nuevo, lo siguiente), el ejemplo será pan comido, pero se puede realizar con cualquier punto de acceso público o vpc que hayáis provisionado. |
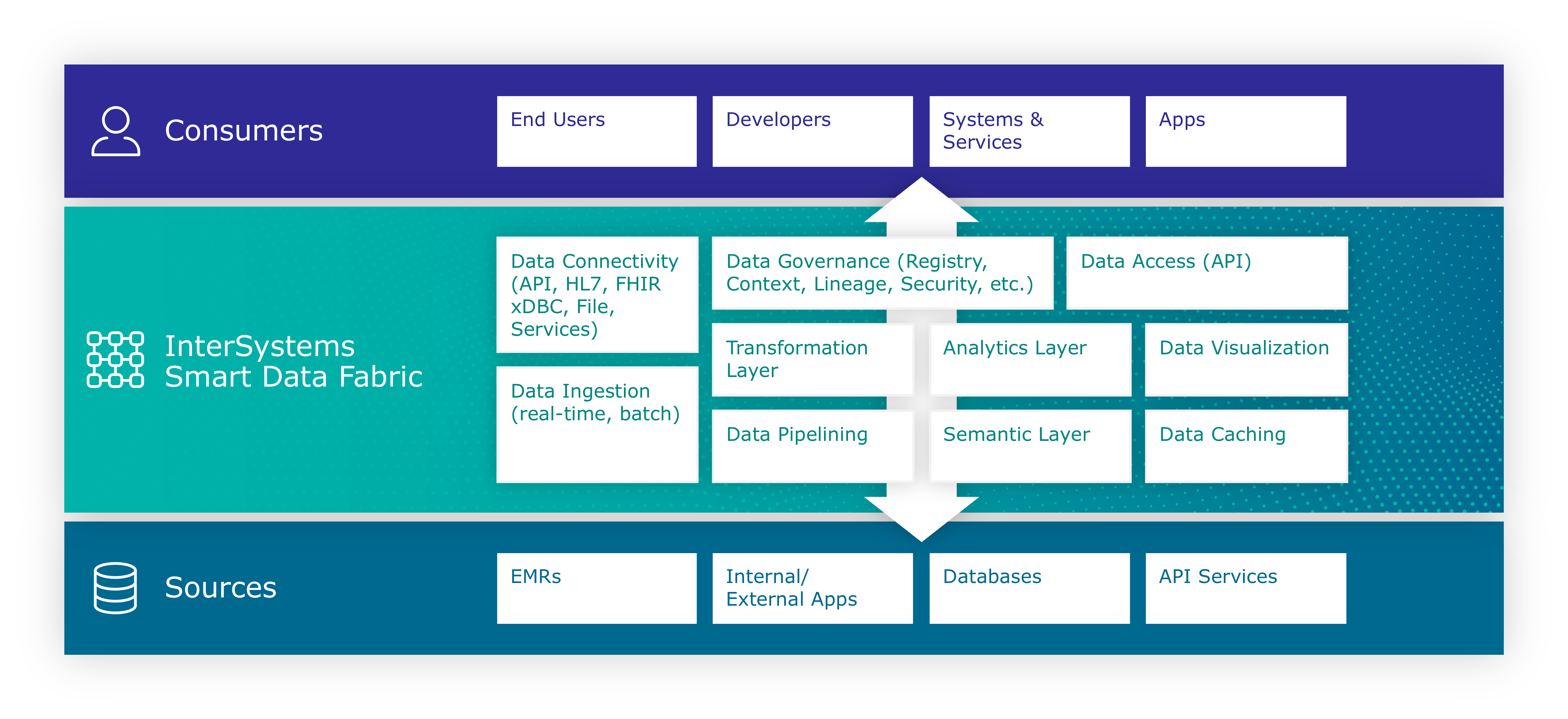
Hoy en día es muy común que los datos que necesitas vengan de diferentes fuentes (e.g. aplicaciones externas e internas, distintas bases de datos y servicios, APIs, etc.). Además, seguro que tienes múltiples tipos de consumidores diferentes (e.g. usuarios finales, otras aplicaciones, servicios que publicas a terceros, etc.) y cada uno necesitará acceder a la información de forma diferente y para distintos objetivos. ¿Cómo construir una capa que de forma sencilla te permita gestionar estas necesidades? Hoy hablamos de Data Fabric 👈.
Apache Superset es una moderna plataforma para la visualización y exploración de datos. Superset puede reemplazar o aumentar las herramientas patentadas de business intelligence para muchos equipos. Y se puede integrar con una gran variedad de fuentes de datos.
¡Y ahora es posible utilizarla con InterSystems IRIS!
Hay disponible una demo online que usa IRIS Cloud SQL como fuente de datos.
.png)
Llamamos Procesamiento Híbrido Transaccional y Analítico (HTAP por sus siglas en inglés) a la capacidad de recuperar numerosos registros por segundo, mientras que a la vez se permiten consultas simultáneas en tiempo real. También se llama Analítica Transaccional ó Transanalítica y es un elemento muy útil en escenarios en los que disponemos de un flujo constante de datos en tiempo real, como podría ser el caso de datos provenientes de sensores IIOT o información de las fluctuaciones en el mercado bursátil y nos permite satisfacer la necesidad de consultar estos conjuntos de datos en tiempo real o casi en tiempo real.
Os comparto un ejemplo que podréis ejecutar en el que se recibe un conjunto de datos en streaming, con entradas de datos constantes y consultas continuas a la vez. El ejemplo está desarrollado en varias plataformas y podréis comparar cómo reaccionó cada una de ellas, con la velocidad de entrada y salida de datos en cada plataforma y su rendimiento. Las plataformas con las que he probado en esta demo son: InterSystems IRIS, MariaDB y MySQL.
Me gustaría compartir con la comunidad un log de datos de un servidor webde un cliente nuestro desde hace muchos años, una compañia operadora.
Su servidor web funciona sobre Apache y contiene datos útiles para analizar la carga y la actividad de los motores de búsqueda.
Tras instalar el proyecto, podrás ver los datos generados durante unos cuantos meses y que muestran la carga y la actividad típica de clientes, bots... también podrás ver cómo dicha carga depende del día de la semana, si son vacaciones o no, así como del momento del día.
El diseño del cubo se encuentra incluido en el paquete.
Podé
@José.Pereiray yo hemos creado un proyecto del que queremos hablar en este artículo.
IRIS RAD Studio es nuestra idea de una solución low-code para hacer más fácil la vida del desarrollador.
¿Y por qué no? Las aplicaciones low-code se han hecho muy populares últimamente. La imagen de abajo muestra el "Cuadrante mágico" ofrecido por la consultora Gartner para plataformas de aplicaciones low-code empresariales, y que muestra lo interesante que es este mercado.
Este artículo describe un diseño arquitectónico más flexible para DeepSee. Al igual que en el ejemplo anterior, esta implementación incluye bases de datos separadas para almacenar la memoria caché, la implementación y la configuración de DeepSee y la sincronización de los globals. Este ejemplo introduce una nueva base de datos para almacenar los índices de DeepSee. Redefiniremos los mapeos globales para que los índices de DeepSee no se mapeeen junto con las tablas de hechos y dimensiones.

Caso de Uso: tenemos acceso a datos remotos; vía JDBC o vía ODBC desde IRIS, y queremos presentar la información en un Dashboard, pero no deseamos o no podemos migrar dicha información a IRIS.
Alternativa: Tomamos ventaja de la conexión al origen de Datos, usamos "Linked Tables" de IRIS, luego podemos realizar el análisis a estos datos y presentarlos finalmente en un Dashboard.
Para este ejemplo vamos a realizarlo en este escenario:
Tenemos una instancia de IRIS for Health, y tenemos acceso a una Base de Datos de empleados (un archivo de MS access).
¡Hola desarrolladores!
Os invitamos a un nuevo webinar en español: "Analítica de datos en FHIR. Del paciente a la población", el jueves 17 de noviembre, a las 3:00 PM (CET).
El webinar se retransmitirá en directo desde el Congreso "Iberia Summit" que InterSystems celebrará en Valencia la semana que viene.

Según la consultora IDC, el 80% de todos los datos producidos son NoSQL. Mira:
.png)
Hay documentos digitales y escaneados, textos online y offline, contenido BLOB (objeto binario grande) en SQL, imágenes, vídeos y audio. ¿Te imaginas una iniciativa de Analítica Corporativa sin todos estos datos para analizar y apoyar las decisiones?
En todo el mundo, muchos proyectos están utilizando tecnologías para transformar estos datos NoSQL en contenido de texto, para poder analizarlo. Fíjate:
Durante las últimas semanas, el equipo de Solution Architecture (Soluciones de Arquitectura) ha estado trabajando para terminar la carga de trabajo de 2019: esto incluyó la creación del código abierto de la Demostración de Readmisiones que llevó a cabo HIMSS el año pasado, para poder ponerla a disposición de cualquiera que busque una forma interactiva de explorar las herramientas proporcionadas por IRIS.
Durante el proceso de creación del código abierto de la demostración, nos encontramos de inmediato con un error crítico.
¡Hola Desarroladores!
IRIS External Table es un proyecto de código abierto de la comunidad de InterSystems, que permite utilizar archivos almacenados en el sistema de archivos local y almacenar objetos en la nube como AWS S3 y tablas SQL. 
Se puede encontrar en GitHub https://github.com/intersystems-community/IRIS-ExternalTable Open Exchange https://openexchange.intersystems.com/package/IRIS-External-Table y está incluido en el administrador de paquetes InterSystems Package Manager (ZPM).
Para instalar External Table desde GitHub, utilice:
git cloneAcabo de redactar un ejemplo rápido para ayudar a un colega a cargar datos en IRIS desde R usando RJDBC y pensé que sería útil compartirlo aquí para futuras consultas.
Fue bastante sencillo, aparte de que a IRIS no le gusta el uso de puntos "." en los nombres de las columnas; la solución alternativa es simplemente renombrar las columnas. Alguien con más conocimientos que yo en R seguramente pueda ofrecer un enfoque más amplio ![]()
# Es necesario un valor válido para el JAVA_HOME antes de cargar la librería (RJDBC) Sys.setenv(JAVA_HOME="C:\\Java\\jdk-8.0.322.6-hotspot\\jre") library(RJDBC) library(dplyr) # Conexión a IRIS – se requiere la ruta a la librería JAR de InterSystems JDBC JAR de tu instalación drv <- JDBC("com.intersystems.jdbc.IRISDriver", "C:\\InterSystems\\IRIS\\dev\\java\\lib\\1.8\\intersystems-jdbc-3.3.0.jar","\"") conn <- dbConnect(drv, "jdbc:IRIS://localhost:1972/USER", "IRIS Username", "IRIS Password") dbListTables(conn) # Para mayor confusión, cargar el dataset de IRIS:) data(iris) # A IRIS no le gustan los puntos "." en el nombre de las columnas, así que los renombramos. (Probablemente se pueda codificar de una forma más genérica, pero no soy muy bueno con R.) iris <- iris %>% rename(sepal_length = Sepal.Length, sepal_width = Sepal.Width, petal_length = Petal.Length, petal_width = Petal.Width) # dbWriteTable/dbGetQuery/dbReadTable funcionan dbWriteTable(conn, "iris", iris, overwrite = TRUE) dbGetQuery(conn, "select count(*) from iris") d <- dbReadTable(conn, "iris")
Este artículo describe un diseño arquitectónico de complejidad intermedia para DeepSee. Al igual que en el ejemplo anterior, esta implementación incluye bases de datos separadas para almacenar la información, la implementación y la configuración de DeepSee. También presenta dos nuevas bases de datos: la primera para almacenar los globals necesarios para la sincronización, la segunda para almacenar tablas de hechos e índices.

En un mundo en constante cambio, las empresas deben innovar para ser competitivas. Esto asegura que tomarán decisiones con agilidad y seguridad, aspirando a obtener buenos resultados con mayor exactitud.
Las herramientas de Business Intelligence (BI) ayudan a las compañías a tomar decisiones inteligentes en vez de confiar en la "prueba y error". Estas decisiones inteligentes pueden ser la diferencia entre el éxito y el fracaso en el mercado.
Microsoft Power BI es una de las herramientas de Business Intelligence líderes. Con unos pocos clics, Power BI permite a los gerentes y analistas explorar los datos de la compañía. Esto es importante porque cuando es fácil accceder y visualizar los datos, es más probable que se usen para tomar decisiones.

InterSystems IRIS Business Intelligence te permite mantener actualizados tus modelos analíticos o cubos de varias formas. Este artículo tratará sobre Construir/Generar vs Sincronizar. Hay maneras de actualizar manualmente los cubos, pero son casos muy especiales y casi siempre los cubos se mantienen actualizados por medio de la (Re)construcción o la sincronización.
La interoperabilidad es uno de los temas más discutidos en los últimos años. Notamos cada vez más que nuestros datos de salud se comparten entre múltiples sistemas con el fin de acercar el concepto de salud del paciente.
A través de la interoperabilidad, utilizamos diferentes estándares de comunicación (independientemente del lenguaje/tecnología en el que esté integrado un sistema dado) para mover información entre diferentes sistemas. Cada día se hace más explícita la necesidad no solo del intercambio de información entre sistemas (interoperabilidad funcional/técnica) sino también del uso de

Con InterSystems IRIS Adaptive Analytics puedes visualizar datos en tiempo real y representar analíticas, para poder tomar decisiones más inteligentes. Puedes conocer la herramienta en este vídeo general (3m) y realizar este curso online (2h).
¡Hola desarrolladores!
¿Sabéis cómo crear una solución de analítica de datos con InterSystems IRIS?

Para empezar, pongámonos de acuerdo sobre lo que es una solución de analítica de datos - este podría ser un tema muy amplio -. Por ello, acotaremos el conjunto de soluciones que se podían presentar al Concurso de Analítica de Datos.
Y a continuación examinaremos tres tipos de soluciones para analítica de datos: de monitorización, de análisis interactivo y de elaboración de informes (reporting).
¡Hola Comunidad!
Hemos grabado el webinar que hicimos ayer y lo hemos subido al canal de YouTube de la Comunidad de Desarrolladores en español. Si os perdisteis el webinar o lo queréis volver a ver con más detalle, ya está disponible la grabación!
Alberto Fuentes es uno de los cracks de InterSystems. Así que... si queréis saber todo sobre la Analítica de datos y el Reporting, ¡no os perdáis el vídeo!