Usando IRIS y Presto para consultas SQL de alto rendimiento y escalabilidad
El auge de los proyectos de Big Data, las analíticas en tiempo real con herramientas self-service, los servicios de consultas en línea y las redes sociales, entre otros, han habilitado escenarios para consultas masivas y de alto rendimiento. En respuesta a este desafío, se creó la tecnología MPP (procesamiento masivamente paralelo) y rápidamente se consolidó. Entre las opciones de MPP de código abierto, Presto (https://prestodb.io/) es la más conocida. Surgió en Facebook y se utilizó para análisis de datos, pero luego se convirtió en código abierto. Sin embargo, desde que Teradata se unió a la comunidad de Presto, ahora ofrece soporte.
Presto se conecta a fuentes de datos transaccionales (Oracle, DB2, MySQL, PostgreSQL, MongoDB y otras bases de datos SQL y NoSQL) y proporciona procesamiento SQL distribuido y en memoria, combinado con optimizaciones automáticas de los planes de ejecución. Su objetivo, sobre todo, es ejecutar consultas rápidas sin importar si gestionáis gigabytes o terabytes de datos, escalando y paralelizando las cargas de trabajo.
Presto no tenía originalmente un conector nativo para la base de datos IRIS, pero afortunadamente, este problema se resolvió con un proyecto comunitario de InterSystems llamado presto-iris (https://openexchange.intersystems.com/package/presto-iris). Por ello, ahora podéis exponer una capa MPP frente a los repositorios de InterSystems IRIS para habilitar consultas, informes y paneles de alto rendimiento a partir de datos transaccionales en IRIS.
En este artículo, seguiremos una guía paso a paso para configurar Presto, conectarlo con IRIS y establecer una capa MPP que vuestros clientes puedan utilizar. También os mostraremos las principales características de Presto, sus comandos y herramientas principales, siempre utilizando IRIS como base de datos fuente.
Características de Presto
Presto contiene las siguientes características:
- Arquitectura sencilla pero extensible.
- Conectores enchufables (Presto admite conectores enchufables para proporcionar metadatos y datos para las consultas).
- Ejecuciones en cadena (evita la sobrecarga innecesaria de latencia de E/S).
- Funciones definidas por el usuario (los analistas pueden crear funciones personalizadas definidas por el usuario para migrar fácilmente).
- Procesamiento vectorizado en columnas.
Beneficios de Presto
A continuación, podéis ver una lista de beneficios que ofrece Apache Presto:
Operaciones SQL especializadas.
Instalación y depuración sencillas.
Abstracción de almacenamiento simple.
Escalabilidad rápida para petabytes de datos con baja latencia.
Arquitectura de Presto
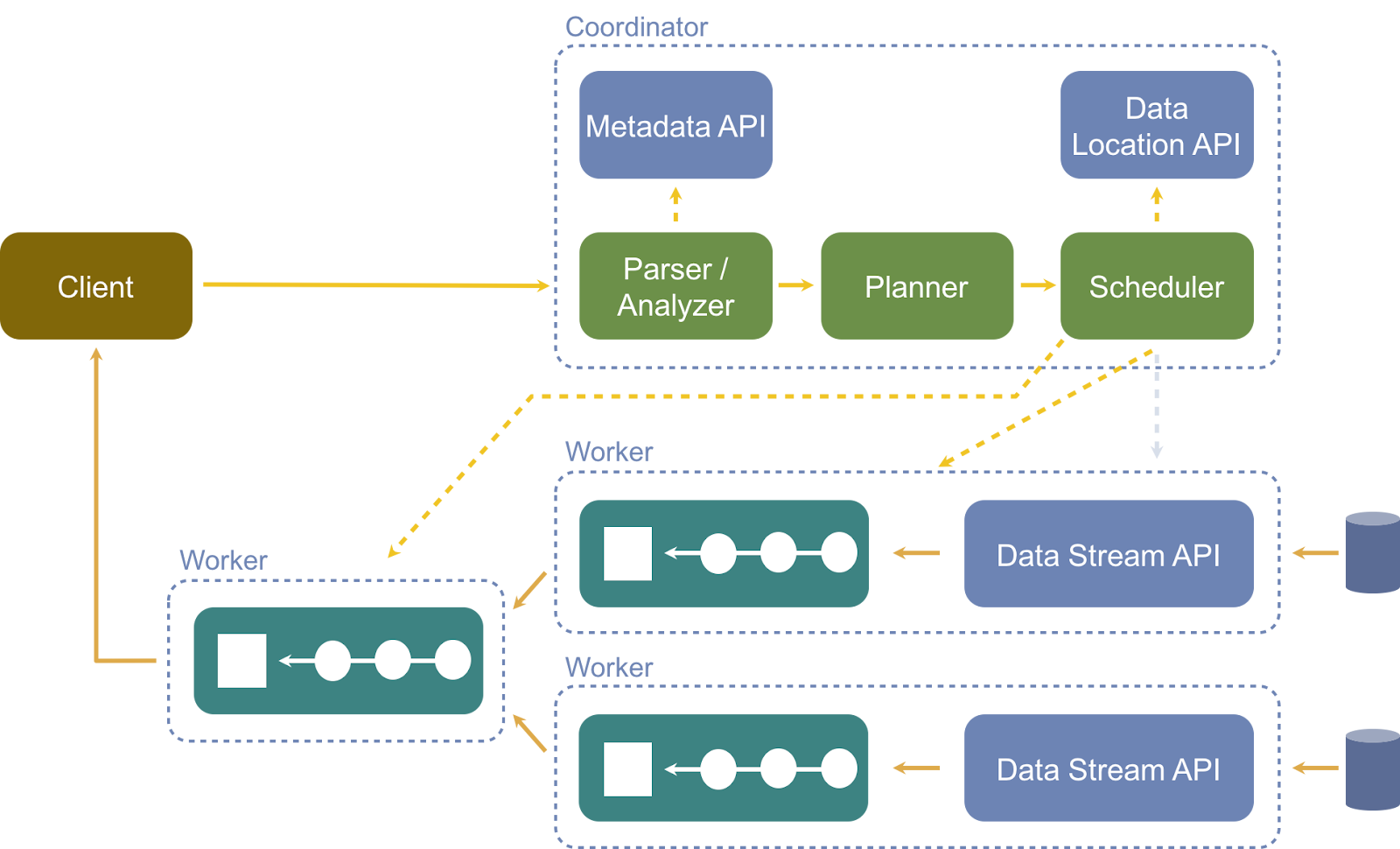
- Clientes: Son los consumidores de PrestoDB. Los clientes utilizan el protocolo JDBC/ODBC/REST para comunicarse con los coordinadores.
- Coordinadores: Son responsables de gestionar los nodos de trabajo asociados, analizar y manejar las consultas, y generar planes de ejecución. También se encargan de la entrega de datos para el procesamiento entre los trabajadores, creando planes lógicos compuestos por etapas, donde cada etapa se ejecuta de manera distribuida utilizando tareas asignadas a los trabajadores.
- Trabajadores: Son nodos de cálculo responsables de ejecutar tareas y procesar datos, lo que permite escalar el procesamiento y consumo de datos.
- Comunicación: Cada trabajador de Presto se anuncia al coordinador utilizando un servidor de descubrimiento para prepararse para trabajar.
- Conectores: Cada tipo posible de fuente de datos tiene un conector empleado por Presto para consumir datos. El proyecto https://openexchange.intersystems.com/package/presto-iris permite que Presto utilice InterSystems IRIS.
- Catálogo: Contiene información sobre la ubicación de los datos, incluidos esquemas y la fuente de datos. Cuando los usuarios ejecutan una instrucción SQL en Presto, la ejecutan contra uno o más catálogos.
Casos de uso de Presto
InterSystems IRIS y Presto juntos os permiten los siguientes casos de uso:
- Consultas ad-hoc: Podéis ejecutar consultas ad-hoc con alto rendimiento sobre terabytes de datos.
- Informes y paneles: Hay un motor para ofrecer consultas de datos de alto rendimiento para informes, herramientas de BI de autoservicio y análisis, como Apache Superset (consultad el ejemplo en este artículo).
- Lakehouse abierto: Presto tiene los conectores y catálogos necesarios para unificar las fuentes de datos requeridas y ofrecer consultas escalables y datos utilizando SQL entre trabajadores.
InterSystems IRIS es un socio perfecto para Presto. Al ser un repositorio de datos de alto rendimiento que admite procesamiento distribuido con la ayuda de fragmentos (shards) y asociado con los trabajadores de Presto, cualquier volumen de datos puede ser consultado en solo unos pocos milisegundos.
Instalación y puesta en marcha de PrestoDB
Hay varias opciones (Docker y Java JAR) para instalar Presto. Podéis encontrar más detalles al respecto en https://prestodb.io/docs/current/installation/deployment.html. En este artículo, utilizaremos Docker. Para facilitar la comprensión y permitir un inicio rápido, hemos puesto a vuestra disposición una aplicación de ejemplo en Open Exchange (derivada de otro paquete https://openexchange.intersystems.com/package/presto-iris). Seguid estos pasos para probarlo vosotros mismos:
- Id a https://openexchange.intersystems.com/package/iris-presto-sample y descargad el ejemplo utilizado en este tutorial.
- Iniciad el entorno de demostración con
docker-compose.
docker-compose up -d --buildNota: Para fines de demostración, el entorno opera Apache Superset con superset-iris y los ejemplos que vienen incluidos. Por esa razón, tarda un tiempo en cargar.
- La interfaz de usuario de Presto estará disponible en este enlace: http://localhost:8080/ui/#.
- Esperad entre 15 y 20 minutos (hay una gran cantidad de datos de ejemplo para cargar). Cuando Superset termine de cargar los ejemplos después de 10-15 minutos, debería estar disponible en el enlace http://localhost:8088/databaseview/list. Introducid admin/admin como usuario y contraseña en la página de inicio de sesión.
- Ahora id a los paneles
- Si visitáis http://localhost:8080/ui, podréis notar que Presto ha ejecutado consultas y está mostrando algunas estadísticas:
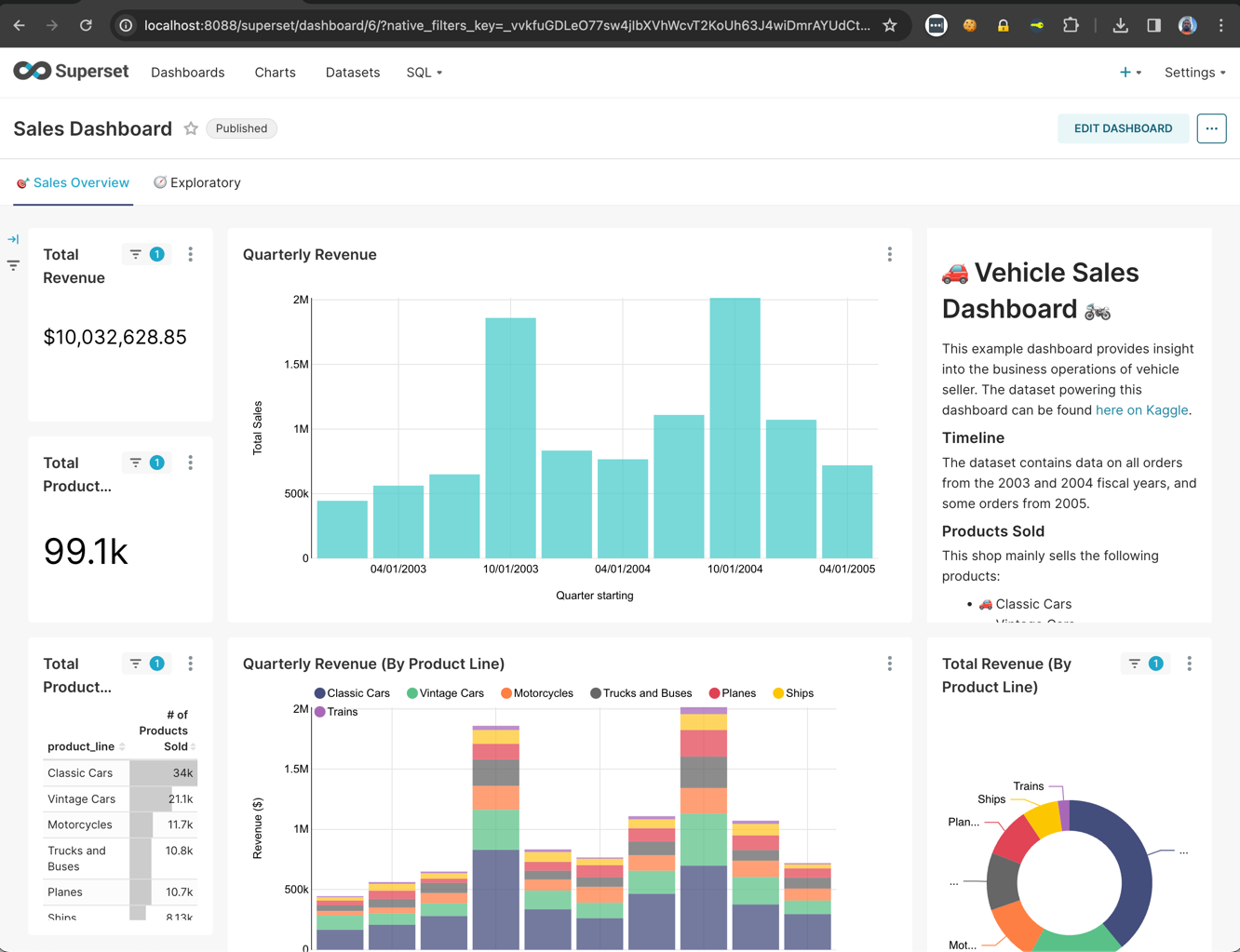
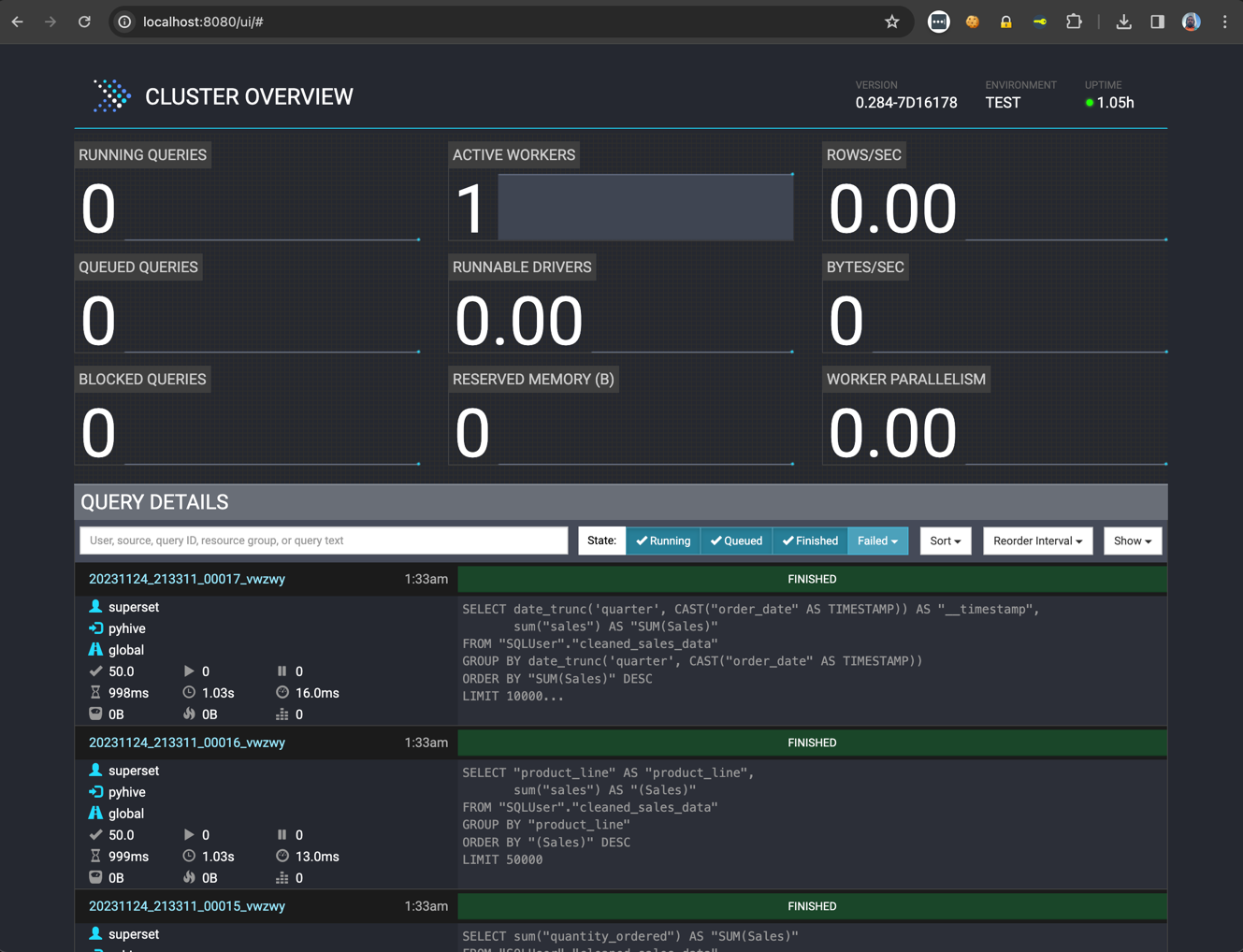
Arriba podéis ver la interfaz web de Presto para supervisar y gestionar consultas. Se puede acceder a través del número de puerto especificado en las Propiedades de Configuración del Coordinador (en este artículo, es el 8080).
Detalles sobre el código de ejemplo
Dockerfile
El Dockerfile se emplea para crear una imagen Docker de PrestoDB con el plugin presto-iris y el archivo JDBC de InterSystems IRIS incluidos:
# Official PrestoDB image on Docker Hub
FROM prestodb/presto
# From https://github.com/caretdev/presto-iris/releases
# Adding presto-iris plugin into the Docker image
ADD https://github.com/caretdev/presto-iris/releases/download/0.1/presto-iris-0.1-plugin.tar.gz /tmp/presto-iris/presto-iris-0.1-plugin.tar.gz
# From https://github.com/intersystems-community/iris-driver-distribution
# Adding IRIS JDBC driver into the Docker image
ADD https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/refs/heads/main/JDBC/JDK18/com/intersystems/intersystems-jdbc/3.8.4/intersystems-jdbc-3.8.4.jar /opt/presto-server/plugin/iris/intersystems-jdbc-3.8.4.jar
RUN --mount=type=bind,src=.,dst=/tmp/presto-iris \
tar -zxvf /tmp/presto-iris/presto-iris-0.1-plugin.tar.gz -C /opt/presto-server/plugin/iris/ --strip-components=1
Archivo Docker-compose.yml
Este archivo crea 3 instancias de contenedor: una para InterSystems IRIS (servicio IRIS), una para PrestoDB (servicio Presto) y una para Superset (servicio Superset). El Superset es una herramienta de visualización de Analytics que se utiliza para ver los datos en cuadros de mando.
# from the project https://github.com/caretdev/presto-iris
services:
# create an InterSystems IRIS container instance
iris:
image: intersystemsdc/iris-community
ports:
- 1972
- 52773
environment:
IRIS_USERNAME: _SYSTEM
IRIS_PASSWORD: SYS
# create a PrestoDB container instance consuming the IRIS database
presto:
build: .
volumes:
# PrestoDB will use iris.properties to get connection information
- ./iris.properties:/opt/presto-server/etc/catalog/iris.properties
ports:
- 8080:8080
# create a Superset (Dashboard analytics tool) container instance
superset:
image: apache/superset:3.0.2
platform: linux/amd64
environment:
SUPERSET_SECRET_KEY: supersecret
# create an InterSystems IRIS connection to load sample data
SUPERSET_SQLALCHEMY_EXAMPLES_URI: iris://_SYSTEM:SYS@iris:1972/USER
volumes:
- ./superset_entrypoint.sh:/superset_entrypoint.sh
- ./superset_config.py:/app/pythonpath/superset_config.py
ports:
- 8088:8088
entrypoint: /superset_entrypoint.shEl archivo iris.properties
Este archivo contiene la información necesaria para conectar PrestoDB a InterSystems IRIS DB y crear una capa MPP para consultas de alto rendimiento y escalables desde cuadros de mando Superset.
# from the project https://github.com/caretdev/presto-iris
connector.name=iris
connection-url=jdbc:IRIS://iris:1972/USER
connection-user=_SYSTEM
connection-password=SYSEl archivo superset_entrypoint.sh
Este script instala la librería superset-iris (para soporte Superset de IRIS), inits la instancia Superset, y carga datos de ejemplo en InterSystems IRIS DB. En tiempo de ejecución los datos consumidos por Superset vendrán de PrestoDB, que será una capa MPP para IRIS DB.
#!/bin/bash
# Install the InterSystems IRIS Superset extension
pip install superset-iris
superset db upgrade
superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password ${ADMIN_PASSWORD:-admin}
superset init
# Load examples to IRIS
superset load-examples
# Change examples database URI to Presto
superset set-database-uri -d examples -u presto://presto:8080/iris
/usr/bin/run-server.shSobre Superset
En este artículo se ha utilizado Superset para los cuadros de mando. Se trata de una moderna plataforma de exploración y visualización de datos que puede sustituir o aumentar las herramientas de inteligencia empresarial propias de muchos equipos. Superset se integra bien con una gran variedad de fuentes de datos.
Superset proporciona lo siguiente:
- Una interfaz sin código para crear gráficos rápidamente
- Un potente editor SQL basado en la web para consultas avanzadas
- Una capa semántica ligera para definir dimensiones y métricas personalizadas de manera rápida
- Soporte listo para usar para casi cualquier base de datos SQL o motor de datos
- Una amplia gama de visualizaciones hermosas para mostrar vuestros datos, desde gráficos de barras simples hasta visualizaciones geoespaciales
- Capa de almacenamiento en caché configurable y ligera para ayudar a reducir la carga en la base de datos
- Roles de seguridad altamente extensibles y opciones de autenticación
- Una API para personalización programática
- Una arquitectura nativa en la nube diseñada desde cero para escalar
Fuentes y materiales adicionales para el aprendizaje:
- Tutorial extenso sobre PrestoDB: https://www.tutorialspoint.com/apache_presto/apache_presto_quick_guide.htm
- Documentación de PrestoDB: https://prestodb.io/docs/current/overview.html
- Plugin Presto-iris: https://openexchange.intersystems.com/package/presto-iris
- Ejemplo Iris-presto: https://openexchange.intersystems.com/package/iris-presto-sample
- Información sobre Superset: https://github.com/apache/superset
- Superset con InterSystems IRIS: https://openexchange.intersystems.com/package/superset-iris