 Por comentarios
Por comentarios
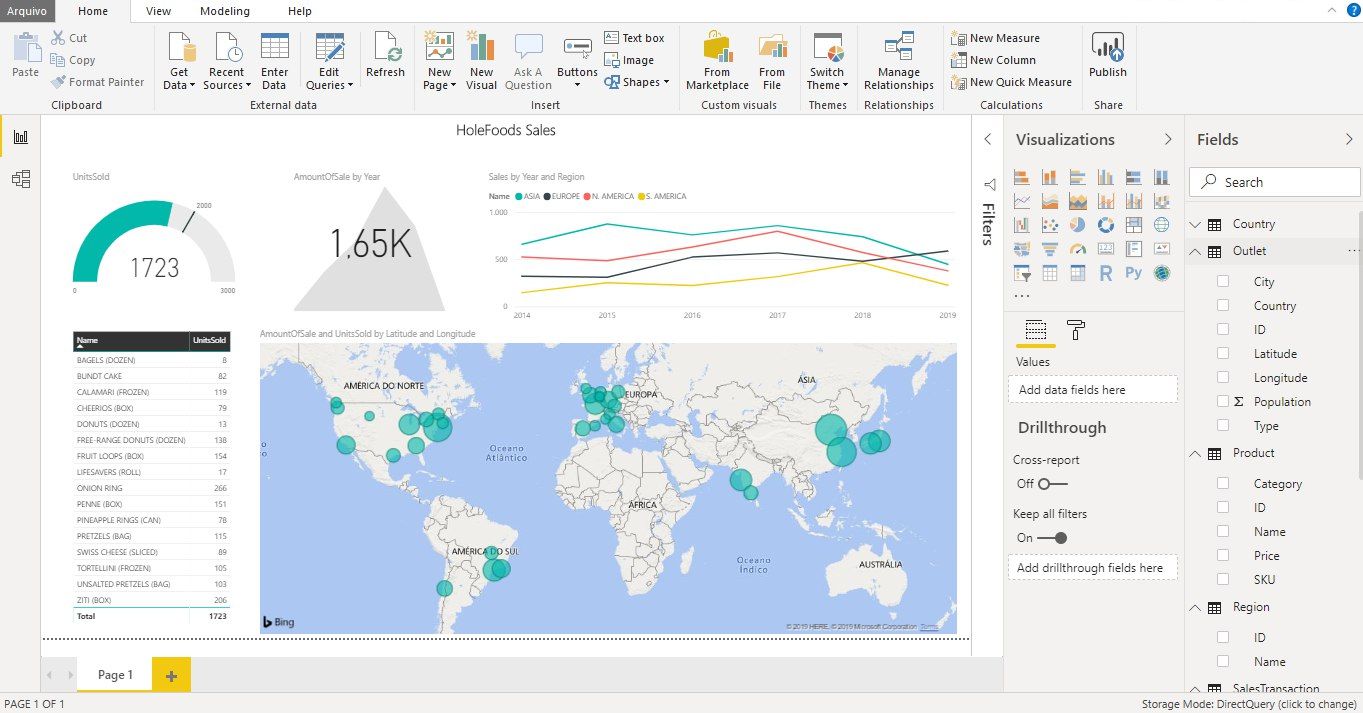
La pandemia que afectó al mundo en 2020 hizo a todo el mundo seguir las noticias y los datos relacionados con la COVID-19. ¿Por qué no aprovechar la oportunidad para crear algo sencillo y fácil de usar, para seguir el número de vacunaciones a nivel mundial?
 Open Exchange app
Open Exchange app





.png)


- 1
- 2
- 3
- siguiente ›
- último