Escalabilidad horizontal con InterSystems IRIS
Nuestra plataforma de datos InterSystems IRIS es una plataforma perfecta para todo lo que necesite realizar con sus datos, ya sean transacciones, análisis o ambos. Incluye muchas de las funciones de Caché y Ensemble que nuestros clientes ya conocen, y en este artículo descubriremos un poco más acerca de una de sus nuevas funcionalidades: SQL Sharding.
Si solo dispone de 5 minutos, puede echar un vistazo a este sencillo vídeo para aprender más sobre la escalabilidad. O puede seguir leyendo...
Escalabilidad vertical y horizontal
Ya sea porque gestionan millones de ventas o porque tratan a decenas de miles de pacientes al día, una plataforma de datos que ofrezca soporte a esas empresas debería ser capaz de enfrentarse eficientemente con la gestión de datos a gran escala. Eficientemente significa que los desarrolladores y los usuarios no tengan que preocuparse por esos números y puedan concentrarse en su negocio, mientras que la plataforma se encarga de la escalabilidad.
Durante muchos años, Caché fue compatible con la escalabilidad vertical, donde los avances en el hardware son beneficiosos para el software, al aprovechar de manera eficiente un gran número de núcleos y enormes cantidades de RAM. En este tipo de escalabilidad, un buen esfuerzo inicial por establecer las dimensiones puede proporcionarle un sistema perfectamente equilibrado, pero existe un límite inherente a lo que se puede lograr con un solo sistema para que este sea rentable.
Entonces surge la escalabilidad horizontal, donde la carga de trabajo se distribuye entre varios servidores separados que trabajan en conjunto, en vez de utilizar uno solo. Caché fue compatible con los servidores para aplicaciones ECP como una manera de escalar horizontalmente, pero InterSystems IRIS ahora también añade SQL sharding.
¿Cuál es la novedad?
Entonces, ¿cuál es la diferencia entre los servidores para aplicaciones ECP y la nueva funcionalidad de sharding? Para entender en qué son diferentes, vamos a examinar más de cerca las cargas de trabajo. Una carga de trabajo puede consistir en decenas de miles de pequeños dispositivos que escriben continuamente pequeñas cantidades de datos en la base de datos, o un grupo de analistas que realizan consultas analíticas, que ocupan los GB disponibles para datos, al mismo tiempo. ¿Cuál de ellos tiene la escala más grande? Es difícil saberlo. Las cargas de trabajo tienen más de una dimensión y, por lo tanto, la escalabilidad que necesitan también debe ser un poco más especializada.
Para explicarlo de manera general, vamos a considerar los siguientes componentes en la carga de trabajo de una aplicación: N representa la carga de trabajo del usuario y Q el tamaño de la consulta. En los ejemplos que vimos anteriormente, la primera carga de trabajo tiene una N grande pero una Q pequeña y la siguiente carga de trabajo tiene una N pequeña y una Q grande. Los servidores para las aplicaciones ECP son excelentes para soportar N grandes, ya que permiten particionar la aplicación del usuario entre diferentes servidores. Sin embargo, esto no necesariamente es útil si el conjunto de datos es muy grande y el conjunto de trabajo no cabe en la memoria de un solo equipo. Sharding se encarga de las Q grandes, lo que le permitirá particionar el conjunto de datos entre varios servidores, al mismo tiempo que se reduce al máximo el trabajo que realizan los servidores de shard.
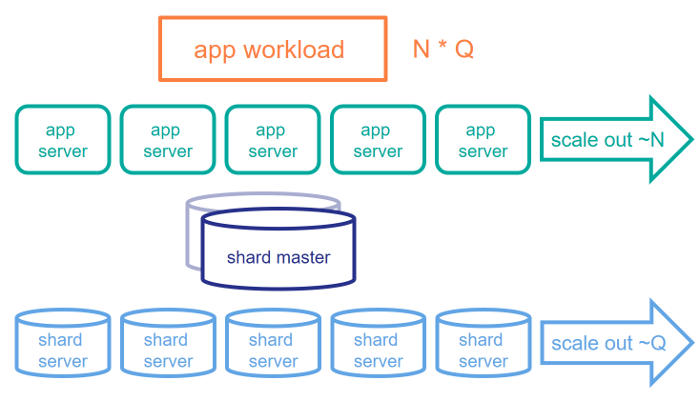
SQL Sharding
Entonces, ¿qué hace realmente el sharding? Es una funcionalidad de SQL que permite la división de los datos en conjuntos desarticulados de filas dentro de una tabla "sharded", que se almacenan en los servidores "shard". Cuando se conecte al "shard" maestro, seguirá viendo esta tabla como si fuera una tabla única con todos los datos dentro de ella, pero las consultas que se realicen allí se dividirán en consultas "shard" locales y se enviarán a todos los servidores "shard". Una vez allí, los servidores "shard" calcularán los resultados basándose en los datos que almacenaron de forma local y enviarán sus resultados al "shard" maestro. Éste junta los resultados, realiza la combinación lógica que sea relevante y devuelve los resultados a la aplicación.
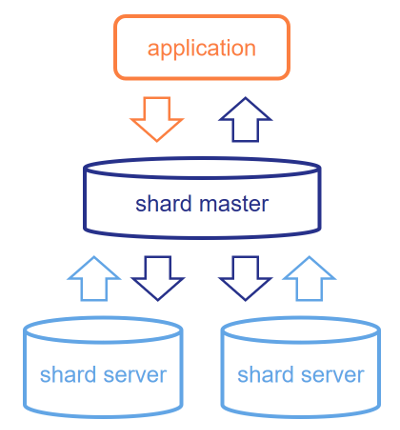
Aunque este sistema es trivial para utilizarlo con una simple tabla SELECT * FROM, en el fondo, existen una gran cantidad de razonamientos lógicos que garantizan que se pueda usar en (casi) cualquier consulta SQL y que la mayor cantidad de trabajo se envíe hacia los fragmentos para aprovechar al máximo el paralelismo. El "shard" principal, que define qué filas y dónde van, es el que le permite anticipar los patrones de consulta más frecuentes. Y aún más importante, si puede garantizar que las tablas que usualmente se unen (JOIN) entre sí se fragmentan a lo largo de los mismos "shard" principales, las uniones (JOINS) pueden resolverse por completo al nivel "shard", lo que le proporcionará el elevado rendimiento que busca.
Por supuesto, esto es solo un avance y aún faltan muchas cosas por descubrir, pero lo más importante es lo que representa la imagen anterior: SQL sharding es como una nueva receta en el libro de los platos altamente escalables que usted puede cocinar con InterSystems IRIS. Es un complemento a los servidores para aplicaciones ECP y se centra en el tamaño de los conjuntos de datos complejos, lo que le convierte en una buena opción para la mayoría de los casos en los que se realicen análisis. Al igual que los servidores para aplicaciones ECP, es totalmente transparente durante su uso y cuenta con algunas variaciones de arquitectura para escenarios muy específicos.
Para saber más...
Puede ver un par de ponencias sobre el tema, realizadas en el Global Summit 2017. Los vídeos están disponibles en estos enlaces:
- What's Lurking in Your Data Lake, un resumen técnico sobre la escabilidad y el sharding en particular
- We Want More! Solving Scalability, un resumen sobre las aplicaciones principales que requieren de una plataforma altamente escalable
y en learning.intersystems.com
También puede consultar este curso online sobre InterSystems IRIS y descubrir otras funcionalidades de la nueva plataforma. Si quiere probar el sharding en algún caso particular, entre en http://www.intersystems.com/iris.