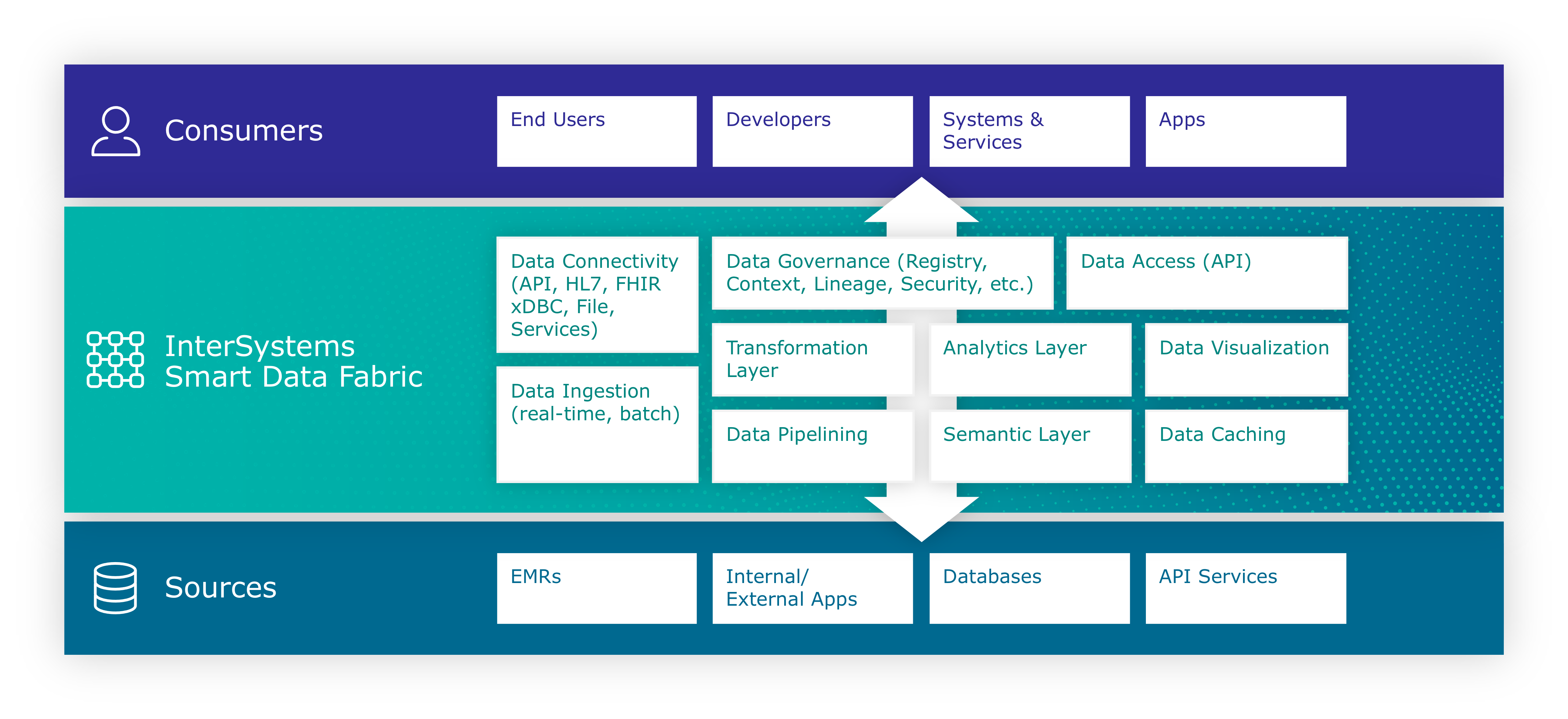
Por visualizaciones
Por visualizaciones
¡Hola a tod@s!
K-Medias es uno de los algoritmos de aprendizaje no supervisado más simples para resolver el problema de agrupamiento. Este problema consiste en formar grupos de objetos con características similares. Por ejemplo, si tenemos una imagen de una pelota roja sobre césped verde, K-Medias separará los pixels de la imagen en dos grupos (clusters): un grupo con los pixels que forman la pelota, y otro grupo con los pixels del césped.
Repasaremos un artículo publicado por Niyaz Khafizov en el que implementaremos un ejemplo donde cargaremos un conjunto de datos en IRIS y ejecutaremos el algoritmo K-Medias utilizando Apache Zeppelin con el conector Spark. Utilizaremos InterSystems IRIS, Apache Zeppelin 0.8.0 y python.
.png)
 Open Exchange app
Open Exchange app






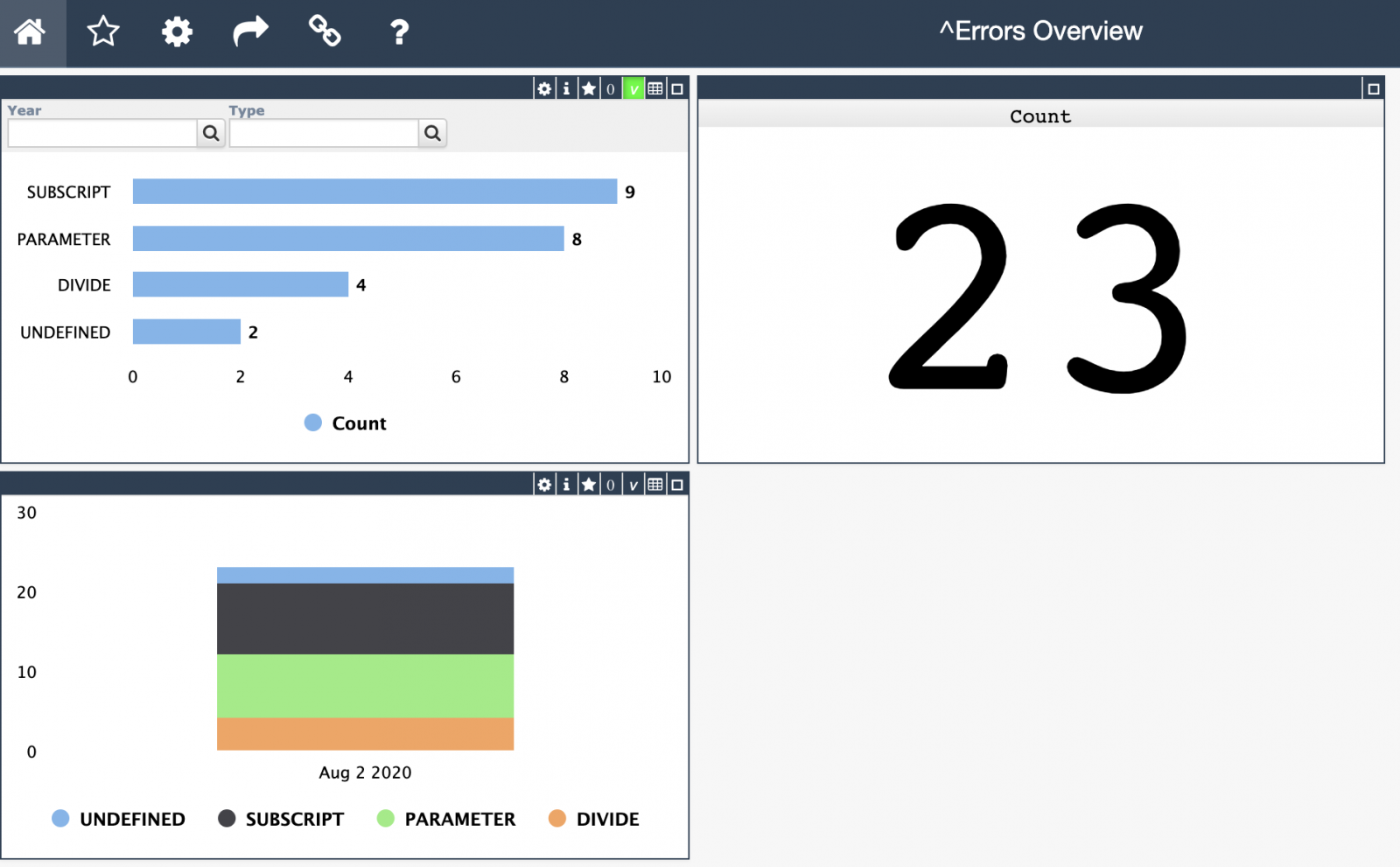
.png)