DeepSee: Bases de datos, Namespaces y Mapeos (Parte 1 de 5)
Estoy pensando en implementar Business Intelligence basada en los datos existentes en mis instancias. ¿Cuál es la mejor manera de configurar mis bases de datos y mi entorno para utilizar DeepSee?

En este tutorial se responde esta pregunta mostrando tres ejemplos de la arquitectura que se utiliza en DeepSee. Comenzaremos con un modelo de arquitectura básico y resaltaremos sus limitaciones. El siguiente modelo se recomienda para las aplicaciones de Business Intelligence con una complejidad intermedia, y debería ser suficiente para la mayoría de los casos de uso. Terminaremos el tutorial describiendo cómo mejorar la flexibilidad de la arquitectura para administrar implementaciones avanzadas.
Cada ejemplo del tutorial presenta una nueva base de datos y sus correspondientes mapeos globales (global mappings), junto con una discusión sobre por qué y cuándo deben establecerse. Conforme se construye la arquitectura, también se señalarán los beneficios que proporciona mediante diversos ejemplos flexibles.
Antes de empezar
Servidores principales y analíticos
Para hacer que los datos tengan una alta disponibilidad, por lo general, InterSystems recomienda usar "mirrroring" o "shadowing", y basar la implementación de DeepSee en el servidor de mirror/shadow. La máquina que aloja la copia original de los datos se llama "Servidor principal" ("Primary server"), mientras que las máquinas que alojan las copias de los datos y las aplicaciones de Business lntelligence suelen llamarse "Servidores analíticos" ("Analytics servers") o, a veces, "Servidores de informes" ("Reporting servers").
Es muy importante tener Servidores principales y de análisis, ya que esto permitirá evitar problemas de rendimiento en cualquiera de los dos servidores. Puedes consultar la documentación sobre Arquitectura recomendada.
Los datos y el código de la aplicación
Almacenar los datos y el código fuente en la misma base de datos normalmente funciona bien, pero solo para aplicaciones a pequeña escala. Para aplicaciones más grandes, es recomendable almacenar los datos y el código fuente en dos bases de datos dedicadas, lo que te permitirá compartir el código con todos los namespaces en los que se ejecute DeepSee, mientras se conservan los datos por separado. La base de datos para los datos de origen debe replicarse desde el servidor en producción. Esta base de datos puede ser solamente de lectura, o de lectura y escritura. También es recomendable mantener el "journaling" activado para esta base de datos.
Las clases de origen y las aplicaciones personalizadas deben almacenarse en una base de datos dedicada tanto en el servidor de producción como en el de análisis. Ten en cuenta que estas dos bases de datos para el código fuente no necesitan estar sincronizadas o incluso ejecutar la misma versión de Caché. Por lo general, no es necesario tener activado "journaling", siempre y cuando se realicen con frecuencia copias de seguridad del código en otro sitio.
En este tutorial tendremos la siguiente configuración. El namespace APP en el servidor de análisis tiene el APP-DATA y el APP-CODE como las bases de datos predeterminadas. La base de datos APP-DATA tiene acceso a los datos que se encuentran en la base de datos de origen (la tabla de la clase de origen y sus datos) del servidor primario. La base de datos APP-CODE almacena el código de Caché (archivos de tipo .cls y .INT) y otros tipos de código personalizado. Esta separación de los datos y el código es una arquitectura típica y permite que el usuario, por ejemplo, implemente de manera eficiente el código de DeepSee y la aplicación personalizada.
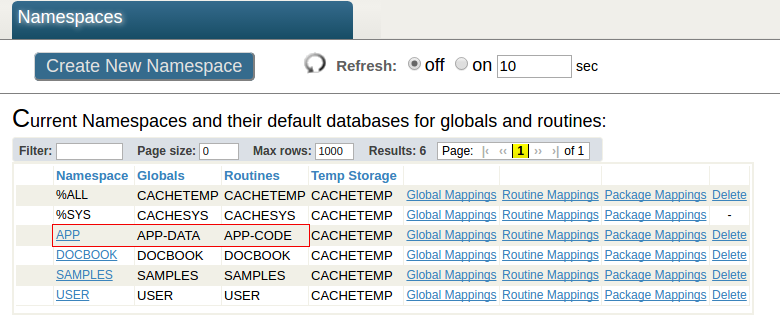
Cómo ejecutar DeepSee en diferentes namespaces
Las implementaciones de la Business Intelligence usando DeepSee con frecuencia se ejecutan desde diferentes namespaces. En esta publicación mostraremos cómo configurar un namespace APP único, pero este mismo procedimiento es válido para todos los namespaces donde se ejecute la aplicación de Business Intelligence.
Documentación
Es recomendable estar familiarizado con esta página: Cómo establecer la configuración inicial. En esta página se incluye la configuración de las aplicaciones web, cómo colocar los globales de DeepSee en bases de datos separadas y una lista de mapeos alternativos para los globales de DeepSee.
* * * En la segunda parte de esta serie de artículos mostraremos cuál es la implementación de un modelo con una arquitectura básica.