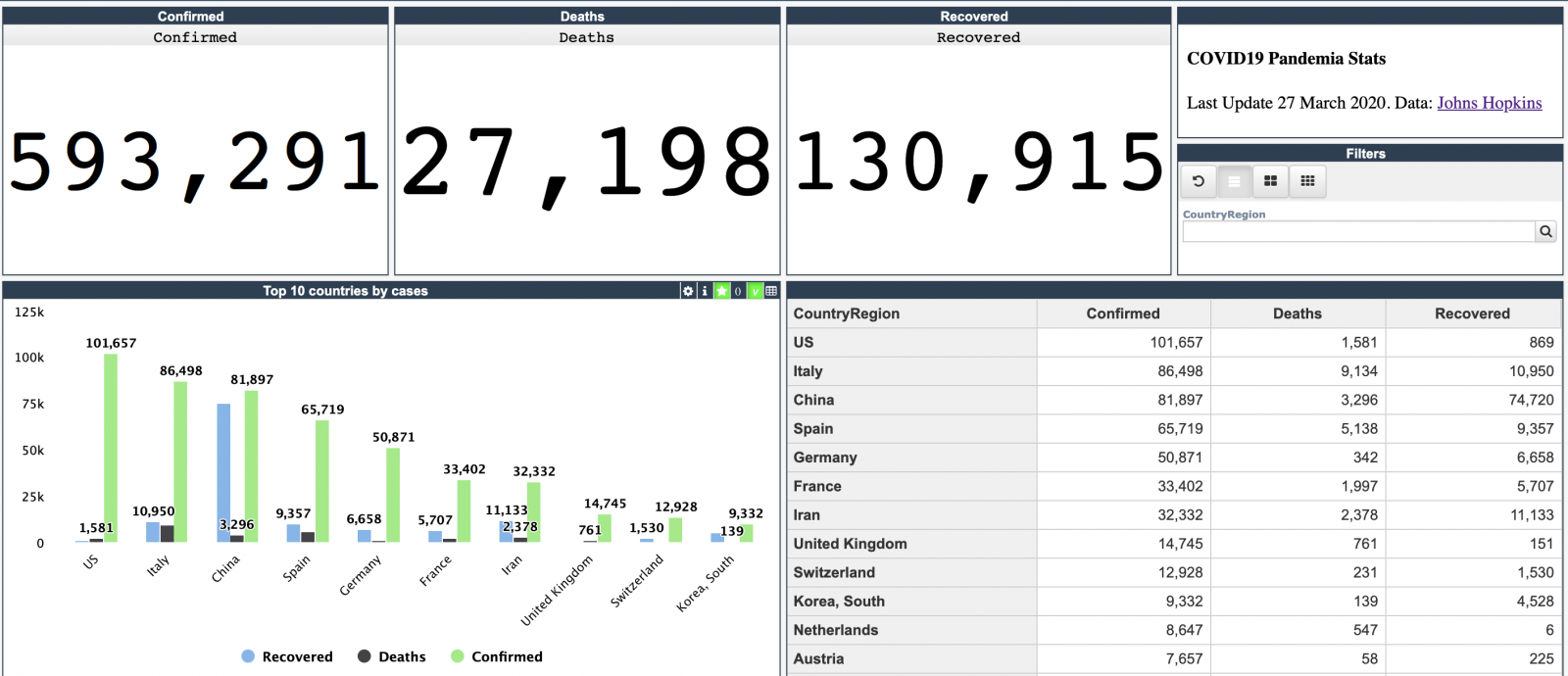
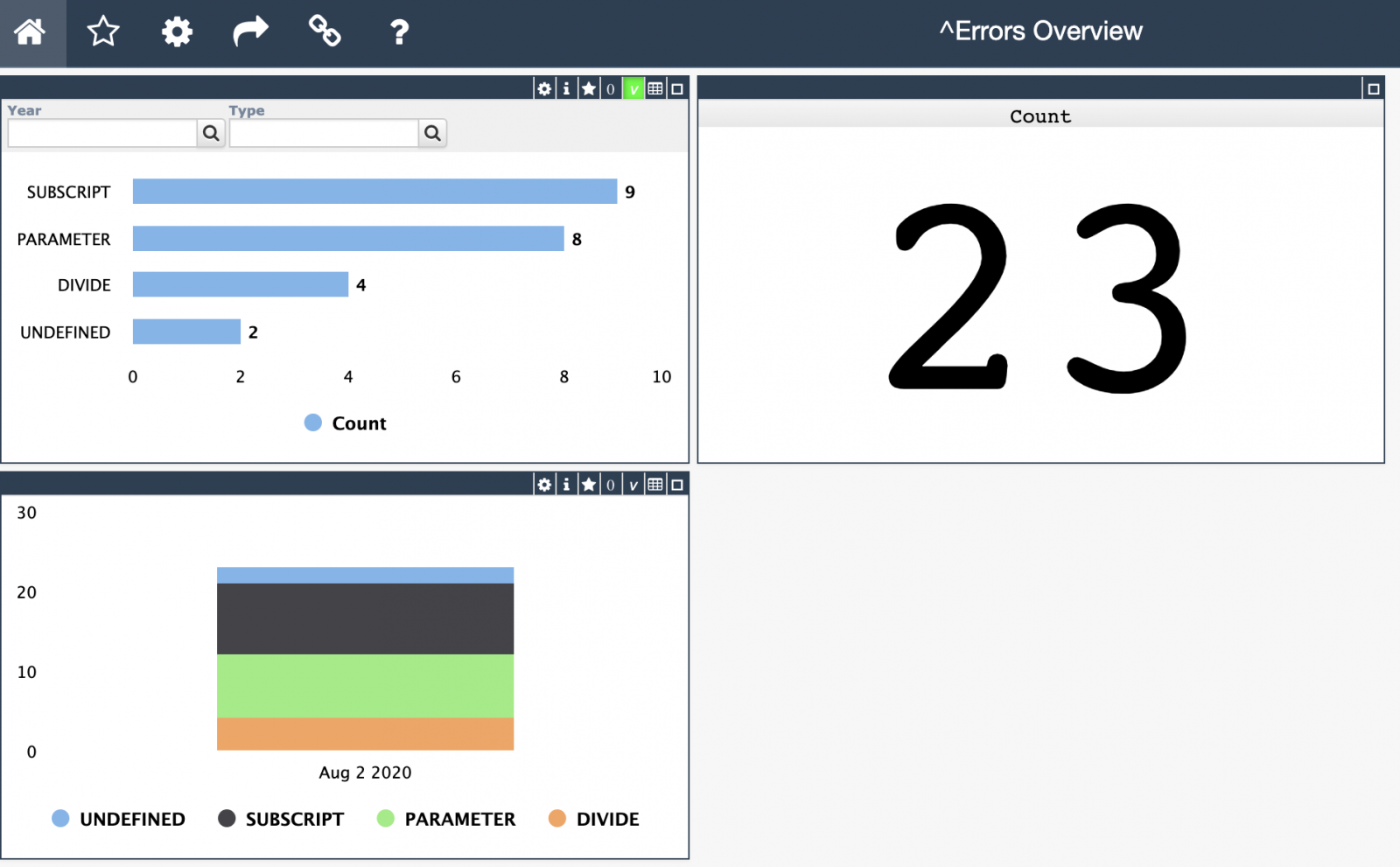
¡Hola desarrolladores!
¿Sabéis cómo crear una solución de analítica de datos con InterSystems IRIS?

Para empezar, pongámonos de acuerdo sobre lo que es una solución de analítica de datos - este podría ser un tema muy amplio -. Por ello, acotaremos el conjunto de soluciones que se podían presentar al Concurso de Analítica de Datos.
Y a continuación examinaremos tres tipos de soluciones para analítica de datos: de monitorización, de análisis interactivo y de elaboración de informes (reporting).