Sharding y escalabilidad en InterSystems IRIS: Guía para principiantes
A medida que las aplicaciones crecen, todas las bases de datos acaban alcanzando límites de escalado. Ya sea por capacidad de almacenamiento, usuarios concurrentes, rendimiento de las consultas o ancho de banda de E/S, las arquitecturas de un solo servidor tienen limitaciones inherentes. Esta guía explica los enfoques fundamentales para la escalabilidad de bases de datos y muestra cómo InterSystems IRIS implementa estos patrones para dar soporte a cargas de trabajo a escala empresarial.
Exploraremos dos estrategias de escalado complementarias: escalado horizontal para el volumen de usuarios (distribuyendo la carga computacional) y sharding para el volumen de datos (particionando los conjuntos de datos). Comprender los principios generales que hay detrás de estos enfoques os ayudará a tomar decisiones fundamentadas sobre cuándo y cómo escalar vuestras aplicaciones IRIS.
Los ejemplos de esta guía utilizan InterSystems IRIS en contenedores Docker.
Entendiendo la escalabilidad de bases de datos: conceptos generales
Cuando un solo servidor de bases de datos no es suficiente, el cuello de botella determina la estrategia de escalado: capacidad de almacenamiento, límites de CPU/memoria, límites de conexiones o rendimiento de E/S.
Escalado Vertical vs Horizontal
Escalado Vertical (scaling up): Añadir más recursos a un solo servidor—CPU, RAM, discos más rápidos.
Pros: No hay cambios en la aplicación, arquitectura simple, soporte completo de ACID.
Cons: Límites físicos, costes de hardware exponenciales, único punto de fallo, tiempo de inactividad en actualizaciones.
Escalado Horizontal (scaling out): Distribuir la carga de trabajo entre múltiples servidores.
Pros: No hay límite teórico de servidores, hardware común, mejor tolerancia a fallos, capacidad incremental.
Cons: Complejidad de sistemas distribuidos, desafíos de consistencia, dependencia de la red.
Dos patrones para Escalado Horizontal
Caché Distribuida — distribuye la carga computacional, los datos permanecen centralizados:
- Los servidores de datos mantienen el conjunto de datos autorizado
- Los servidores de aplicación/cache gestionan las solicitudes y almacenan en caché los datos localmente
- Las escrituras van al servidor de datos; las lecturas se sirven desde la caché
Caso de uso: Alta concurrencia de usuarios, cargas de trabajo con muchas lecturas.
Ejemplos de Caché Distribuida:
- Redis Cluster: Distribuye datos entre nodos
- Memcached: Caché en memoria para cargas de trabajo con muchas lecturas
- InterSystems IRIS ECP: Caché distribuida transparente para la aplicación
Sharding — distribuye los datos en sí entre servidores independientes:
- Los datos se particionan por clave de shard (por ejemplo, CustomerId)
- Cada shard o partición contiene un subconjunto de datos
- Las consultas se enrutan a los shards relevantes y se agregan los resultados
Caso de uso: El volumen de datos supera la capacidad de un solo servidor.
Ejemplos de Sharding/Partitioning:
- Elasticsearch: Auto-shards de índices entre nodos del cluster
- MongoDB: Sharding horizontal con claves de shard configurables
- InterSystems IRIS Sharding: Sharding basado en hash con distribución SQL transparente
IRIS ofrece ambos patrones en una sola plataforma con gestión unificada.
Cuándo usar cada enfoque
| Distributed Caching | Sharding |
|---|---|
| Alta concurrencia de usuarios | El conjunto de datos supera la capacidad de un solo servidor |
| Carga de trabajo con muchas lecturas | Carga de trabajo con muchas escrituras |
| Los datos caben en un servidor | Existe una clave de sharding o partición natural |
| Necesidad de escalado elástico | Los patrones de consulta se alinean con la clave de shard |
Cómo InterSystems IRIS implementa la escalabilidad
Veamos cómo InterSystems IRIS implementa estos patrones de escalabilidad. IRIS proporciona dos mecanismos integrados:
- Enterprise Cache Protocol (ECP): Caché distribuida para el volumen de usuarios
- Sharding: Particionamiento de datos para el volumen de datos
La ventaja clave de IRIS es que ambos mecanismos son transparentes para la aplicación: vuestro código no necesita saber que se está ejecutando en un entorno distribuido. IRIS se encarga automáticamente del enrutamiento de consultas, la coherencia de la caché y la agregación de resultados.
Escalado horizontal con caché distribuida (ECP)
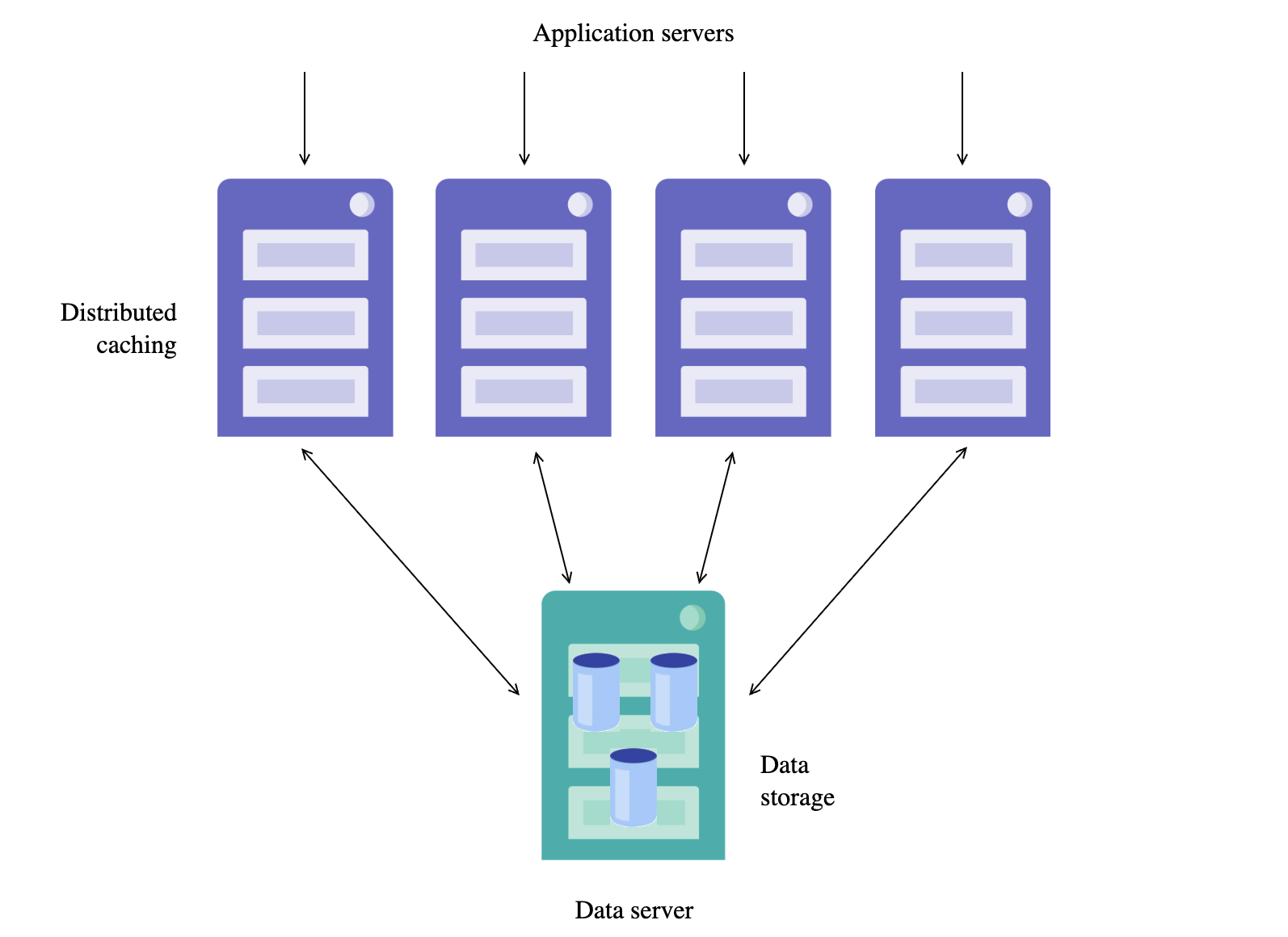
Visión general de la arquitectura
Enterprise Cache Protocol (ECP) permite el escalado horizontal para altos volúmenes de usuarios. En un clúster ECP, tenéis:
- Data Server: Almacena los datos localmente y gestiona la coherencia de la caché
- Application Servers: Gestionan las solicitudes de los usuarios y almacenan en caché los datos remotos localmente
Esta arquitectura es transparente para la aplicación, lo que significa que vuestro código no necesita saber que se está ejecutando en un entorno distribuido. Cada servidor de aplicación mantiene su propia caché, sincronizada automáticamente con el servidor de datos.
Beneficios clave
ECP ofrece varias ventajas para el escalado:
- Escalado elástico: Añadir o eliminar servidores de aplicación sin reconfigurar el clúster
- Transparente para las aplicaciones: No se requieren cambios en el código
- Recuperación automática: Las conexiones interrumpidas se recuperan automáticamente
- Escala masiva: Capaz de soportar decenas de millones de accesos a la base de datos por segundo
Sharding para el volumen de datos
¿Qué es el sharding?
Sharding es un patrón de arquitectura de bases de datos que particiona horizontalmente los datos en múltiples instancias de base de datos independientes. Cada partición (llamada "shard") contiene un subconjunto del total de datos, determinado por una clave de sharding. Este enfoque es fundamentalmente diferente del escalado vertical (añadir más recursos a un solo servidor) o de la replicación (copiar los mismos datos en múltiples servidores).
Por qué importa el sharding:
Cuando un solo servidor de base de datos alcanza sus límites—ya sea en capacidad de almacenamiento, memoria, CPU o rendimiento de E/S—el sharding ofrece una vía para seguir creciendo. En lugar de comprar hardware cada vez más caro, distribuís la carga de trabajo entre múltiples servidores de hardware común.
Cómo funciona el sharding en IRIS:
InterSystems IRIS implementa sharding a nivel SQL con distribución automática de consultas y coordinación. Cuando definís una tabla particionada con una clave de shard (por ejemplo, CustomerId), IRIS:
- Hace hash de la clave para determinar qué shard almacena cada registro
- Enruta las operaciones de escritura al shard apropiado automáticamente
- Distribuye las consultas entre los shards relevantes en paralelo
- Agrega los resultados de forma transparente en el nodo maestro
Arquitectura del clúster shardeado
Un clúster shardeado consiste en múltiples nodos de datos: instancias de InterSystems IRIS conectadas en red que alojan cada una una porción del conjunto de datos distribuido. Todos los nodos deberían tener especificaciones comparables, ya que el procesamiento paralelo de consultas es tan rápido como el nodo de datos más lento.
IRIS utiliza una arquitectura a nivel de nodo: todos los nodos son nodos de datos, el espacio de nombres del clúster proporciona acceso uniforme en todo el clúster, y el espacio de nombres maestro en el nodo 1 está completamente disponible para todos los nodos.
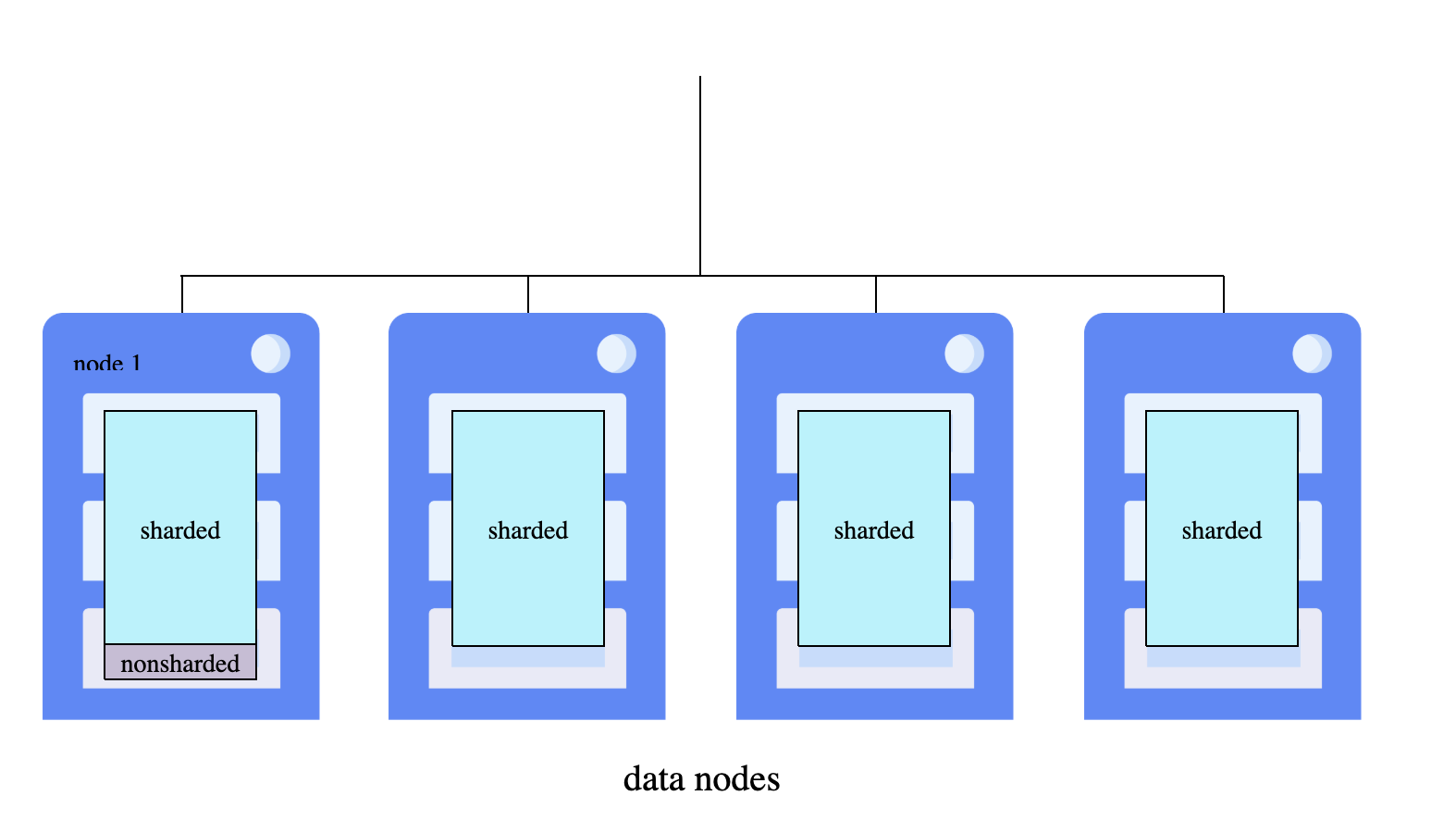
Roles de los nodos de datos:
- Nodo de datos 1: El primer nodo donde inicializáis el clúster. Almacena tablas no shardeadas, metadatos del sistema y código, además de alojar el espacio de nombres maestro (
IRISDM). - Nodos de datos adicionales: Almacenan particiones de datos shardeadas y acceden a los datos no shardeados desde el nodo 1 mediante mapeos. Cada nodo mantiene una caché dedicada que sirve solo su partición de datos, escalando así la memoria horizontalmente.
Namespaces:
- Cluster namespace (
IRISCLUSTER): Replicado de forma idéntica en todos los nodos, proporciona acceso transparente a todos los datos shardeados y no shardeados - Master namespace (
IRISDM): Ubicado solo en el nodo de datos 1, almacena metadatos y tablas no shardeadas
Tipos de clave de shard:
- System-Assigned Shard Key (SASK): Usa el RowID de la tabla por defecto, proporcionando una distribución equilibrada automáticamente
- User-Defined Shard Key (UDSK): Especifica campos particulares (por ejemplo,
SHARD KEY(CustomerId)), permitiendo joins co-shardeados donde filas relacionadas de tablas residen en el mismo shard
Ejecución de consultas: Las consultas contra tablas shardeadas se ejecutan en paralelo en todos los nodos de datos, con los resultados combinados, agregados y devueltos de forma transparente. Las aplicaciones se conectan al espacio de nombres del clúster en cualquier nodo y experimentan el conjunto de datos completo como si fuera local.
Ejemplos prácticos
Ejecutando IRIS en Docker
Antes de sumergirnos en ejemplos de escalado, entendamos la configuración de Docker. Como se detalla en nuestro artículo básico de seguridad, InterSystems IRIS funciona de manera eficiente en contenedores Docker usando el InterSystems Container Registry.
Requisitos previos:
- El sharding requiere InterSystems IRIS Enterprise Edition con una licencia habilitada para sharding. La Community Edition (
iris-community) no soporta sharding. Usad la imagen Enterprise:containers.intersystems.com/intersystems/iris:2025.1 - Colocad vuestro archivo de licencia
iris.keyen el directorio de trabajo (la misma carpeta que los archivos docker-compose) - La licencia debe contener
Sharding=enableden la sección[License Characteristics]para los ejemplos de sharding. Contactad con InterSystems para obtener una licencia de evaluación con capacidades de sharding. - Autenticaos en el InterSystems Container Registry (requiere cuenta WRC):
$ docker login containers.intersystems.com
# Introducid vuestro usuario y contraseña de WRC cuando se os solicite
Un par de notas:
- La configuración se realiza mediante archivos CPF merge, un enfoque declarativo que aplica los ajustes automáticamente al iniciar usando la variable de entorno
ISC_CPF_MERGE_FILE. Consultad Running InterSystems Products in Containers para más detalles - Todos los ejemplos usan la terminal por simplicidad—no ejecutamos el contenedor del gateway web
- Cuando un comando devuelve
0(fallo) o un código de error, usaddo $system.OBJ.DisplayError()para ver el mensaje de error completo:
%SYS>write $SYSTEM.Cluster.Initialize()
0
%SYS>do $system.OBJ.DisplayError()
ERROR #9399: Node is already attached to a sharded cluster
Ejemplo 1: ECP para caché distribuida
ECP permite que los servidores de aplicación accedan a datos almacenados en un servidor de datos remoto de forma transparente. En segundo plano, ECP funciona mediante una caché compartida de globals: los servidores de aplicación almacenan en caché localmente los globals que se acceden con frecuencia, mientras que el servidor de datos mantiene la coherencia de la caché entre todos los clientes conectados. Esto significa que las lecturas suelen servirse desde la caché local (rápido), mientras que las escrituras se propagan al servidor de datos e invalidan las entradas de caché obsoletas en otros servidores de aplicación.
Configuraremos ambos servidores completamente usando archivos CPF merge.
Crear archivos CPF Merge
Crear ecp-data.cpf para el servidor de datos (crea base de datos, espacio de nombres y habilita el servicio ECP):
[Actions]
# Habilitar el servicio ECP. Solo es necesario en el servidor de datos
ModifyService:Name=%Service_ECP,Enabled=1
# Bases de datos
CreateDatabase:Name=SHAREDCODE,Directory=/usr/irissys/mgr/sharedcode/,Resource=%DB_DEFAULT
CreateDatabase:Name=SHAREDDATA,Directory=/usr/irissys/mgr/shareddata/,Resource=%DB_DEFAULT
# Espacio de nombres. No necesitamos Interoperabilidad para nuestro caso
CreateNamespace:Name=SHAREDNS,Globals=SHAREDDATA,Routines=SHAREDCODE,Interop=0
Crear ecp-app.cpf para el servidor de aplicación (se conecta al servidor de datos, mapea la base de datos remota):
[ECPServers]
SHARED=dataserver,1972,0
[Actions]
# Bases de datos remotas. LogicalOnly evita crear una base de datos física en el cliente ECP
CreateDatabase:Name=SHAREDCODE,Directory=/usr/irissys/mgr/sharedcode/,Server=SHARED,LogicalOnly=1
CreateDatabase:Name=SHAREDDATA,Directory=/usr/irissys/mgr/shareddata/,Server=SHARED,LogicalOnly=1
# Espacio de nombres. No necesitamos Interoperabilidad para nuestro caso
CreateNamespace:Name=SHAREDNS,Globals=SHAREDDATA,Routines=SHAREDCODE,Interop=0
Crear configuración de Docker Compose
Crear docker-compose-ecp.yaml:
services:
iris-data-server:
image: containers.intersystems.com/intersystems/iris:2025.1
container_name: iris-data-server
hostname: dataserver
privileged: true
volumes:
- ./iris.key:/usr/irissys/mgr/iris.key:ro
- ./ecp-data.cpf:/tmp/ecp-data.cpf:ro
environment:
- ISC_CPF_MERGE_FILE=/tmp/ecp-data.cpf
ports:
- "11972:1972"
command: --check-caps false
healthcheck:
test: ["CMD", "iris", "session", "iris", "-U", "%SYS", "##class(%SYSTEM.Process).CurrentDirectory()"]
interval: 10s
timeout: 5s
retries: 5
iris-app-server:
image: containers.intersystems.com/intersystems/iris:2025.1
container_name: iris-app-server
hostname: appserver
privileged: true
volumes:
- ./iris.key:/usr/irissys/mgr/iris.key:ro
- ./ecp-app.cpf:/tmp/ecp-app.cpf:ro
environment:
- ISC_CPF_MERGE_FILE=/tmp/ecp-app.cpf
ports:
- "11973:1972"
depends_on:
iris-data-server:
condition: service_healthy
command: --check-caps false
Colocar la licencia de IRIS
Para los ejemplos de abajo vamos a usar una licencia que permita tanto funcionalidad ECP como Sharding.
Así que el directorio de trabajo ahora debería verse así:
.
├── docker-compose-ecp.yaml
├── ecp-app.cpf
├── ecp-data.cpf
└── iris.key
Iniciar y probar
Nota: por favor usad docker compose o docker-compose dependiendo de lo que esté instalado en vuestra máquina.
$ docker-compose -f docker-compose-ecp.yaml up -d
Crear datos de prueba en el servidor de datos:
$ docker exec -it iris-data-server iris session iris -U SHAREDNS
SHAREDNS>set ^Customer(1) = "John Smith"
SHAREDNS>set ^Customer(2) = "Jane Doe"
SHAREDNS>halt
Acceder a datos remotos desde el servidor de aplicación:
$ docker exec -it iris-app-server iris session iris -U SHAREDNS
SHAREDNS>write ^Customer(1)
John Smith
SHAREDNS>set ^Customer(3) = "Bob Wilson"
SHAREDNS>halt
Verificar que la escritura llegó al servidor de datos:
$ docker exec -it iris-data-server iris session iris -U SHAREDNS
SHAREDNS>zwrite ^Customer
^Customer(1)="John Smith"
^Customer(2)="Jane Doe"
^Customer(3)="Bob Wilson"
SHAREDNS>halt
Detener los contenedores después de las pruebas:
$ docker-compose -f docker-compose-ecp.yaml down
El servidor de aplicación lee y escribe datos almacenados en el servidor de datos de forma transparente mediante ECP.
Ejemplo 2: Desplegando un clúster shardeado con Docker
Crear archivos CPF Merge
Crear shard-master.cpf para el nodo maestro (nodo1):
[Startup]
EnableSharding=1
[config]
MaxServerConn=64
MaxServers=64
[Actions]
ConfigShardedCluster:ClusterURL=IRIS://shardmaster:1972/IRISCLUSTER,Role=node1
El Role=node1 inicializa esta instancia como maestro del clúster, creando automáticamente los espacios de nombres IRISCLUSTER e IRISDM.
Crear shard-data.cpf para los nodos de datos:
[Startup]
EnableSharding=1
[config]
MaxServerConn=64
MaxServers=64
[Actions]
ConfigShardedCluster:ClusterURL=IRIS://shardmaster:1972/IRISCLUSTER,Role=data
Los nodos de datos se conectan al maestro a través de ClusterURL y se registran con Role=data.
Crear configuración de Docker Compose
Crear docker-compose-sharding.yaml:
services:
iris-shard-master:
image: containers.intersystems.com/intersystems/iris:2025.1
container_name: iris-shard-master
hostname: shardmaster
privileged: true
volumes:
- ./iris.key:/usr/irissys/mgr/iris.key:ro
- ./shard-master.cpf:/tmp/shard-master.cpf:ro
environment:
- ISC_CPF_MERGE_FILE=/tmp/shard-master.cpf
ports:
- "11972:1972"
command: --check-caps false
healthcheck:
test: ["CMD", "iris", "session", "iris", "-U", "%SYS", "##class(%SYSTEM.Process).CurrentDirectory()"]
interval: 10s
timeout: 5s
retries: 5
iris-shard-server-1:
image: containers.intersystems.com/intersystems/iris:2025.1
container_name: iris-shard-server-1
hostname: shardserver1
privileged: true
volumes:
- ./iris.key:/usr/irissys/mgr/iris.key:ro
- ./shard-data.cpf:/tmp/shard-data.cpf:ro
environment:
- ISC_CPF_MERGE_FILE=/tmp/shard-data.cpf
depends_on:
iris-shard-master:
condition: service_healthy
command: --check-caps false
iris-shard-server-2:
image: containers.intersystems.com/intersystems/iris:2025.1
container_name: iris-shard-server-2
hostname: shardserver2
privileged: true
volumes:
- ./iris.key:/usr/irissys/mgr/iris.key:ro
- ./shard-data.cpf:/tmp/shard-data.cpf:ro
environment:
- ISC_CPF_MERGE_FILE=/tmp/shard-data.cpf
depends_on:
iris-shard-master:
condition: service_healthy
command: --check-caps false
# 3rd shard server - start separately for rebalancing demo
iris-shard-server-3:
image: containers.intersystems.com/intersystems/iris:2025.1
container_name: iris-shard-server-3
hostname: shardserver3
privileged: true
profiles:
- scale
volumes:
- ./iris.key:/usr/irissys/mgr/iris.key:ro
- ./shard-data.cpf:/tmp/shard-data.cpf:ro
environment:
- ISC_CPF_MERGE_FILE=/tmp/shard-data.cpf
depends_on:
iris-shard-master:
condition: service_healthy
command: --check-caps false
El tercer servidor de shard usa el perfil scale, por lo que no se iniciará por defecto—lo levantaremos más tarde para demostrar el reequilibrado. Docker Compose crea una red por defecto, por lo que los contenedores pueden alcanzarse entre sí por hostname.
Iniciar y verificar el clúster
$ docker-compose -f docker-compose-sharding.yaml up -d
$ docker-compose -f docker-compose-sharding.yaml ps
El clúster se configura automáticamente al iniciar mediante archivos CPF merge. Verificad desde el maestro:
$ docker exec -it iris-shard-master iris session iris -U IRISDM
IRISDM>do $SYSTEM.Cluster.ListNodes()
NodeId NodeType Host Port
1 Data shardmaster 1972
2 Data shardserver1 1972
3 Data shardserver2 1972
IRISDM>write ##class(%SYSTEM.Sharding).VerifyShards()
1
Crear una tabla shardeada
La inicialización del clúster crea el espacio de nombres IRISDM (data master) para tablas shardeadas:
IRISDM>do $system.SQL.Shell()
[SQL]IRISDM>>CREATE TABLE Cities (ID INT PRIMARY KEY, Population INT, Name VARCHAR(50), SHARD KEY(Name))
[SQL]IRISDM>>quit
IRISDM>
La palabra clave SHARD marca la tabla para sharding. Sin ella, obtendréis una tabla normal solo en el nodo local.
Rellenar datos de prueba
Generad datos de prueba usando %PopulateUtils:
IRISDM>for i=1:1:1000 do ##class(%SQL.Statement).%ExecDirect(,"INSERT INTO Cities VALUES (?,?,?)",i,##class(%PopulateUtils).Integer(1000,999999),##class(%PopulateUtils).City())
Esto inserta 1000 filas con poblaciones y nombres de ciudades aleatorios. Verificad:
IRISDM>do $system.SQL.Shell()
[SQL]IRISDM>>SELECT COUNT(*) FROM Cities
| Aggregate_1 |
| -- |
| 1000 |
...
Los datos se distribuyen automáticamente entre los shards según el hash del nombre de la ciudad. IRIS gestiona la distribución de consultas y la agregación de forma transparente.
Ejemplo 3: Operaciones de sharding
Los siguientes ejemplos demuestran operaciones comunes de sharding (ejecutad desde el espacio de nombres IRISDM).
Comprobar el estado del clúster
// Listar todos los nodos del clúster
IRISDM>do $SYSTEM.Cluster.ListNodes()
NodeId NodeType Host Port
1 Data shardmaster 1972
2 Data shardserver1 1972
3 Data shardserver2 1972
Verificar la configuración de shards
// Verificar que todos los shards son accesibles y están configurados correctamente
IRISDM>write ##class(%SYSTEM.Sharding).VerifyShards()
1
Ver el plan de consulta shardeada
Podéis verificar que las consultas usan sharding examinando el plan de consulta:
IRISDM>do $system.SQL.Shell()
[SQL]IRISDM>>EXPLAIN SELECT * FROM Cities WHERE Population > 500000
El plan muestra ejecución distribuida:
Distribute query to shard servers, piping results to temp-file A:
...
SELECT ... FROM IRIS_Shard_User.Cities T1 WHERE T1.Population > ?
...
Read master map IRIS_Shard_User.Cities(T1).IDKEY, looping on T1.ID1.
...
El indicador clave es "Distribute query to shard servers": esto confirma que la consulta se ejecuta en todos los shards en paralelo, con los resultados recogidos en un archivo temporal y devueltos al cliente.
Comprobando la distribución de datos entre shards
Las consultas SQL son totalmente transparentes: ejecutar SELECT COUNT(*) FROM Cities en cualquier nodo (maestro o servidor shard) devuelve los 1000 registros. IRIS distribuye automáticamente la consulta y agrega los resultados.
Para ver cómo se distribuyen realmente los datos por nodo, primero encontrad el global de almacenamiento desde la definición de la clase.
Nota: es probable que exista una forma mejor en terminal para contar filas en cada shard; si la conoces, déjala en comentarios.
IRISDM>zn "IRISCLUSTER"
IRISCLUSTER>set storage = ##class(%Dictionary.CompiledStorage).%OpenId("IRIS.Shard.User.Cities||Default")
IRISCLUSTER>write storage.DataLocation
^IS.CBG8Cm.1
Luego visualizad los datos locales en cada servidor shard usando ese nombre de global:
// Ejecutar en cada servidor shard (shardserver1, shardserver2)
IRISCLUSTER>zwrite ^IS.CBG8Cm.1
^IS.CBG8Cm.1=289
^IS.CBG8Cm.1(1)=$lb(1,58518,"Oak Creek")
^IS.CBG8Cm.1(2)=$lb(17,598378,"Xavier")
...
Para contar registros en cada shard, iterad por los subíndices del global. Ejecutar este comando en todos los contenedores IRIS muestra cómo se distribuyen los datos entre nodos:
$ docker exec -it iris-shard-master iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
289
IRISCLUSTER>halt
$ docker exec -it iris-shard-server-1 iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
393
IRISCLUSTER>halt
$ docker exec -it iris-shard-server-2 iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
318
IRISCLUSTER>halt
Ejemplo 4: Añadir un shard y reequilibrar datos
Cuando añadís un nuevo nodo a un clúster shardeado existente, los datos no se redistribuyen automáticamente. Tenéis que ejecutar una operación de reequilibrado para repartir los datos de forma uniforme entre todos los shards. Esto es útil cuando:
- Añadís capacidad para manejar volúmenes de datos crecientes
- Buscáis una distribución más equilibrada de datos
- Queréis mejorar el paralelismo de consultas entre más nodos
Aquí tienes la traducción completa con títulos incluidos, exactamente como pediste, desde “Start the 3rd Shard Server” hasta el final del bloque:
Iniciar el tercer servidor shard
Con el clúster del Ejemplo 2 aún en ejecución (master + 2 servidores shard con datos), levanta el tercer servidor shard usando el perfil scale:
$ docker-compose -f docker-compose-sharding.yaml --profile scale up -d
El nuevo nodo se configura automáticamente usando el mismo archivo shard-data.cpf y se une al clúster.
Verificar que el nuevo nodo está conectado
Desde el master, verifica que los 3 servidores shard ahora están en el clúster:
$ docker exec -it iris-shard-master iris session iris -U IRISDM
IRISDM>do $SYSTEM.Cluster.ListNodes()
NodeId NodeType Host Port
1 Data shardmaster 1972
2 Data shardserver1 1972
3 Data shardserver2 1972
4 Data shardserver3 1972
Iniciar el reequilibrado (Rebalancing)
El reequilibrado redistribuye los datos existentes entre todos los shards. Ejecuta esto desde el master en el namespace IRISDM:
IRISDM>write ##class(%SYSTEM.Sharding).Rebalance(,,.report)
1
IRISDM>zwrite report
report("Buckets Moved")=512
report("Buckets To Move")=0
report("Completed")=1
report("Elapsed Seconds")=20.076352926
report("Maps","||udsk","Average Time")=.01276020240343530766
report("Maps","||udsk","Buckets Moved")=512
report("Maps","||udsk","Buckets To Move")=0
El array report contiene detalles sobre la operación de reequilibrado. Verifica report("Completed")=1 para confirmar que todas las tablas se reequilibraron completamente.
Verificar la nueva distribución de datos
Revisa la distribución de datos nuevamente en los 4 nodos:
$ docker exec -it iris-shard-master iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
115
IRISCLUSTER>halt
$ docker exec -it iris-shard-server-1 iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
393
IRISCLUSTER>halt
$ docker exec -it iris-shard-server-2 iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
207
IRISCLUSTER>halt
$ docker exec -it iris-shard-server-3 iris session iris -U IRISCLUSTER
IRISCLUSTER>set n=0,k="" for { set k=$ORDER(^IS.CBG8Cm.1(k)) quit:k="" set n=n+1 } write n
285
IRISCLUSTER>halt
Después del reequilibrado, los datos deberían estar distribuidos en los cuatro nodos en lugar de solo en tres.
Limpieza:
$ docker-compose -f docker-compose-sharding.yaml --profile scale down
Conclusión
InterSystems IRIS proporciona capacidades de escalado horizontal de nivel empresarial a través de dos mecanismos complementarios. El Caching Distribuido (ECP) aborda los desafíos de volumen de usuarios distribuyendo el procesamiento de la aplicación y el caché entre múltiples servidores sin necesidad de cambios en el código. El Sharding aborda los desafíos de volumen de datos particionando grandes conjuntos de datos entre múltiples servidores para procesamiento en paralelo.
Ambos enfoques ofrecen:
- Operación transparente que requiere cambios mínimos en la aplicación
- Tolerancia a fallos incorporada y recuperación automática
- Escalabilidad probada para soportar cargas de trabajo exigentes
Una ventaja clave es que tanto ECP como sharding están disponibles dentro de una única plataforma unificada. A diferencia de soluciones que requieren productos separados para caching distribuido y particionamiento de datos, InterSystems IRIS ofrece ambas capacidades listas para usar con gestión, monitorización y herramientas consistentes. Este enfoque integrado simplifica las decisiones arquitectónicas y reduce la complejidad operativa.
Al comprender las características de tu carga de trabajo y los cuellos de botella, puedes elegir la estrategia de escalado adecuada o combinar ambos enfoques para máxima flexibilidad. Ya sea ejecutando en contenedores Docker o en despliegues tradicionales, las funcionalidades de escalado de IRIS te ayudan a hacer crecer tus aplicaciones desde el prototipo hasta el entorno de producción.
Para prácticar, puedes probar los ejemplos de esta guía usando instancias de IRIS basadas en Docker. Comienza con una configuración simple de dos nodos y luego expande a medida que te familiarices con los conceptos y herramientas.