Por comentarios
Por comentarios¡Hola Comunidad!
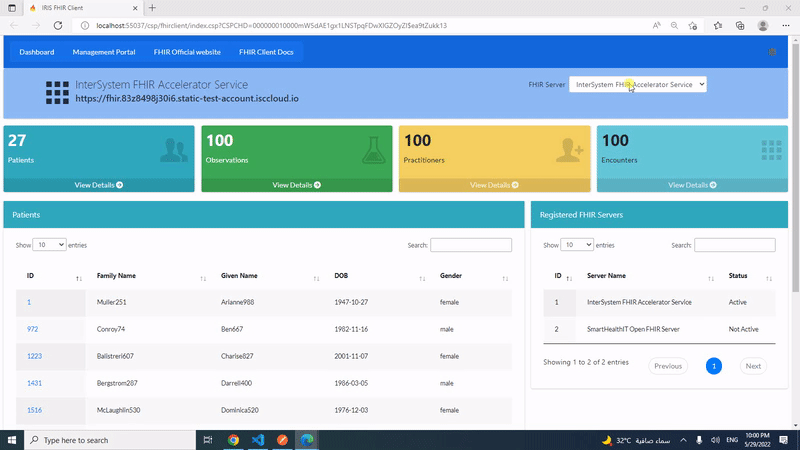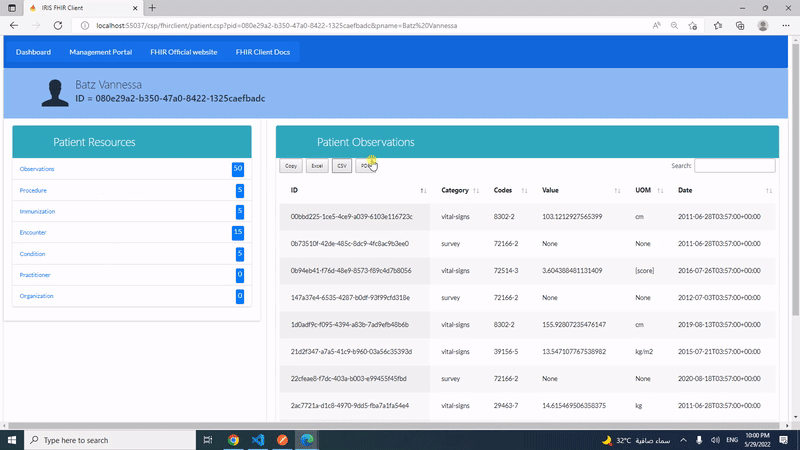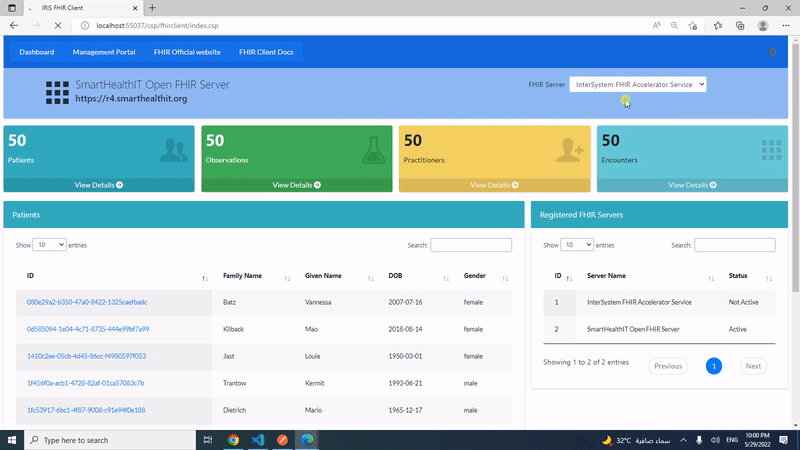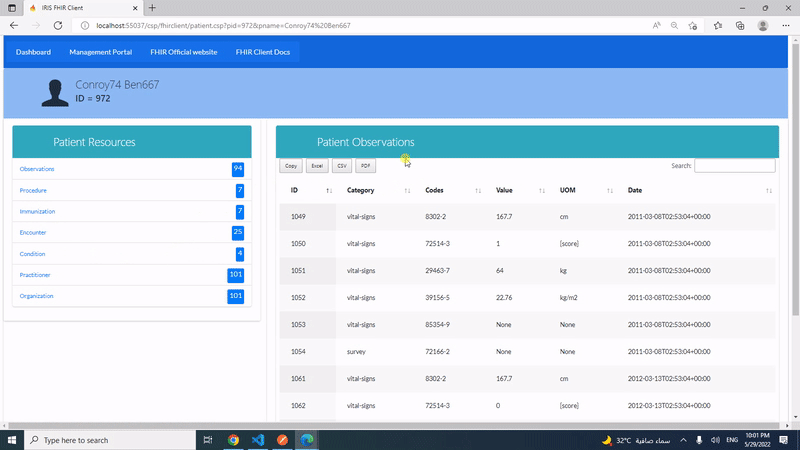
Con IRIS nos llegó una INTERESANTÍSIMA funcionalidad - ¡SHARDING! Sin duda una gran característica.
Pero, ¿cómo puedo descubrir si encaja con mis aplicaciones actuales? ¿Hay alguna funcionalidad práctica para apostar por ello en mi perfecta aplicación transaccional? ¿O es sólo algo para las nuevas aplicaciones que vaya a diseñar?




 Open Exchange app
Open Exchange app