Nueva
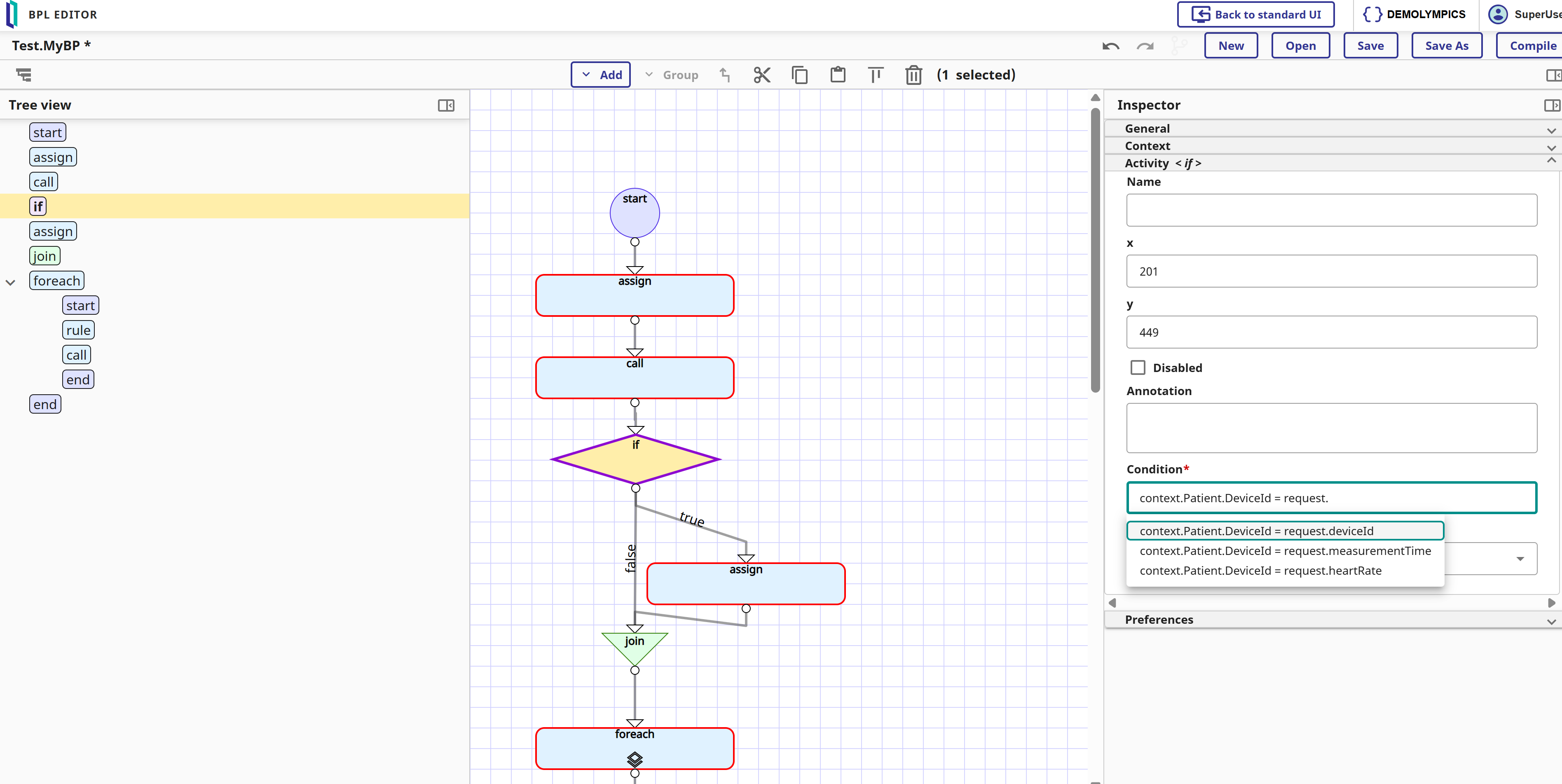
Para quienes no estuvieron en READY la semana pasada, puede que os hayáis perdido el emocionante anuncio de que el Programa de Acceso Anticipado (EAP de Early Access Program en inglés) de AI Hub ya está oficialmente abierto. Se anunció durante una increíble demostración de @Benjamin De Boe y @Jeff Fried, os recomiendo ver esta demo cuando se publique la grabación.
He tenido la oportunidad de probar AI Hub con antelación y he pensado que podría compartir una introducción con la comunidad.