El teorema PACELC y InterSystems IRIS
El teorema PACELC fue creado por Daniel Abadi (Universidad de Maryland, College Park) en 2010 como una extensión del teorema CAP (creado por Eric Brewer: consistencia, disponibilidad y tolerancia a particiones). Ambos ayudan a diseñar cómo arquitecturar el funcionamiento más adecuado de las plataformas de datos en entornos distribuidos bajo los aspectos de consistencia frente a disponibilidad. La diferencia es que PACELC también permite analizar la mejor opción para entornos no distribuidos, convirtiéndose en el estándar de referencia para considerar todos los escenarios posibles al definir vuestra topología de despliegue y arquitectura.
El teorema CAP establece que en sistemas distribuidos no es posible tener simultáneamente consistencia, disponibilidad y tolerancia a particiones, por lo que requiere elegir dos de las tres, según el siguiente diagrama.
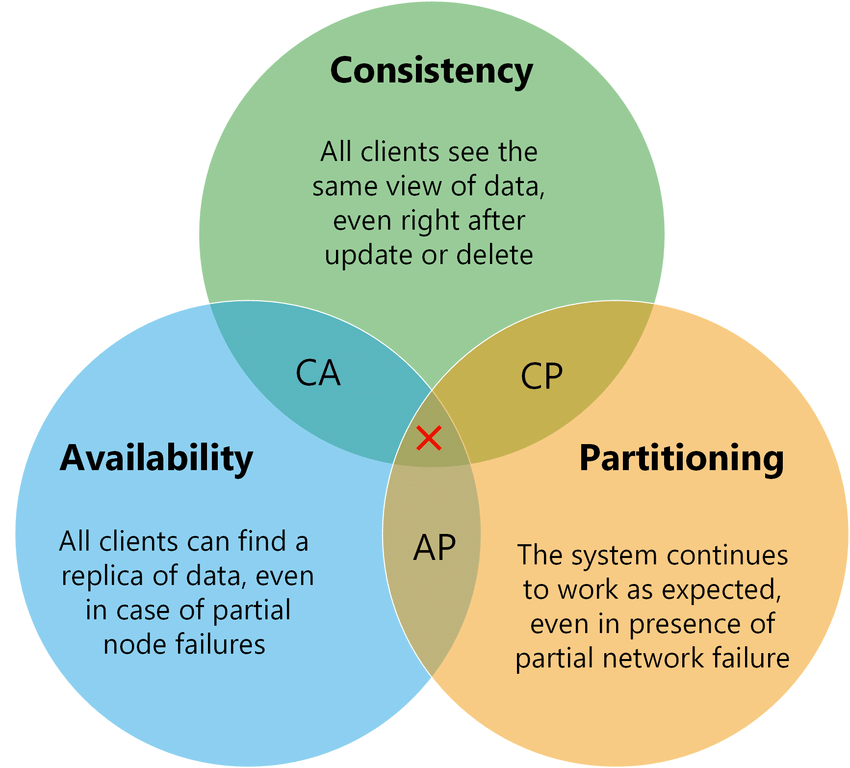
Fuente: https://medium.com/nerd-for-tech/understand-cap-theorem-751f0672890e
El PACELC, al ser una extensión, confirma el CAP, pero añade el escenario sin particiones (E - En caso contrario):
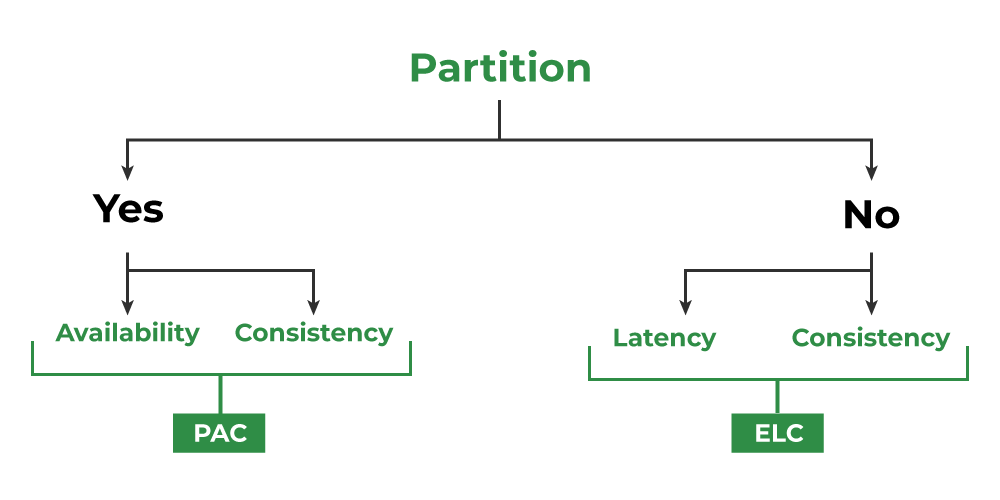
Fuente: https://www.geeksforgeeks.org/operating-systems/pacelc-theorem/
Componentes de InterSystems IRIS para cumplir con PACELC
El siguiente diagrama ilustra cómo los componentes de la arquitectura de InterSystems IRIS pueden satisfacer plenamente cualquiera de las características de PACELC:
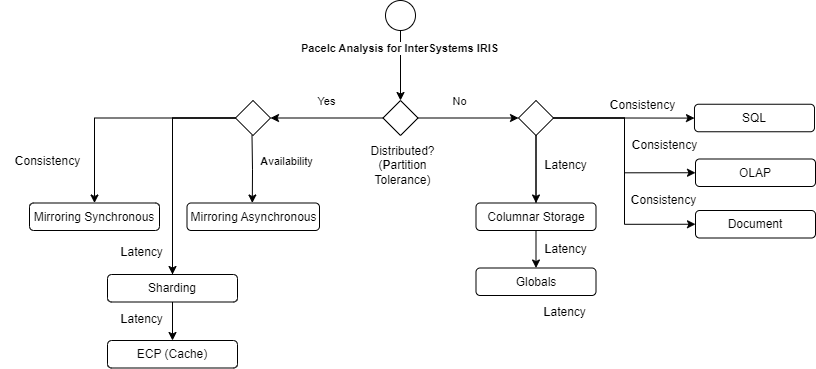
|
Clasificación PACELC |
Arquitectura de IRIS |
Análisis |
|
PC / EC |
Mirror síncrono con SQL o Document para transaccional y OLAP para analítica | Alta consistencia y latencia uniforme |
|
PC / EL |
Mirror asíncrono con Globals para transaccional y almacenamiento columnar para latencia | Consistencia regular y alta latencia |
|
PL / EL |
Mirror con ECP Fragmentación (sharding) para grandes volúmenes de datos |
Buena consistencia y buena latencia (estrategia híbrida) |
Cuándo usar los recursos de IRIS para mejorar la latencia y la disponibilidad
Algunos recursos de IRIS se utilizan para fines conocidos:
- Mirroring síncrono:
- Alta disponibilidad con consistencia.
- Procesamiento distribuido con latencia regular.
- Mirroring asíncrono:
- Recuperación ante desastres.
- Instancia aislada para informes o analítica.
- Procesamiento distribuido con muy buena latencia.
- ECP - Procesamiento de caché empresarial:
- Procesamiento distribuido con buena latencia.
- Alta disponibilidad con buena latencia.
- Sharding:
- Procesamiento de datos distribuido para grandes volúmenes con buena latencia.
- Buena latencia para grandes volúmenes de datos.
- Almacenamiento Columnar:
- Buena latencia para datos desnormalizados.
- Buena latencia para analítica, data lake y escenarios de reporting.
Estrategias de ajuste para mejorar la latencia
Además de los componentes arquitectónicos que mejoran significativamente la latencia, incluso en escenarios de procesamiento distribuido, es posible aplicar varias configuraciones de ajuste:
- Optimización de memoria (memoria compartida y buffers)
- Buffers de base de datos (Global Buffers): debes asignar suficiente memoria para mantener los datos “calientes” (globals de acceso frecuente) en RAM. En sistemas de 64 bits, este valor debe ser lo más alto posible para evitar accesos a disco.
- Buffers de rutinas: si tu aplicación ejecuta rutinas intensivas en ObjectScript o rutinas legacy, aumenta la caché de rutinas para evitar la sobrecarga de cargar y compilar código en tiempo de ejecución.
- Páginas enormes (Huge Pages) (Linux): configura siempre Huge Pages a nivel del sistema operativo. Esto reduce la sobrecarga del kernel al gestionar las tablas de páginas para grandes asignaciones de memoria.
- Ajuste de E/S de disco:
- Separación de discos: para mejores resultados, utiliza discos físicos separados (o LUNs) para:
-
WIJ (Write Image Journal): requiere alto rendimiento en ráfagas.
-
Journals: requieren escrituras secuenciales de baja latencia.
-
Bases de datos: donde residen los archivos .dat.
-
-
Arquitectura de globals: IRIS almacena los datos en estructuras B-Tree. Los globals grandes y crecidos de forma desordenada pueden fragmentarse. Utiliza la utilidad ^GBLOCKCOPY para compactar globals y mejorar la localidad de los datos.
-
Asegura el uso de discos SSD o NVMe de alta velocidad.
-
Optimiza la asignación de bloques y el striping en los volúmenes de base de datos.
-
Monitoriza y ajusta los parámetros de asignación de caché de disco.
- Separación de discos: para mejores resultados, utiliza discos físicos separados (o LUNs) para:
- Configuración de la caché de base de datos:
- Aumenta el tamaño de la caché principal (Main Cache) para mantener más datos e índices en memoria, reduciendo la necesidad de E/S de disco.
- Supervisa las tasas de aciertos de la caché (cache hit rates) y ajusta el tamaño de forma dinámica si es necesario.
- Optimización de consultas:
-
Ajuste de tablas: ejecuta regularmente el comando GATHER_TABLE_STATS (a través del Portal de Administración o SQL). El optimizador de consultas de IRIS depende de estas estadísticas para elegir entre un escaneo completo de tabla o un índice.
-
Revisa y reescribe las consultas SQL lentas, asegurándote de que utilicen los índices de forma eficiente.
-
Utiliza el visor de planes de ejecución de consultas de IRIS para identificar cuellos de botella y forzar planes de ejecución óptimos.
-
- Uso eficiente de índices:
- Crea índices compuestos que correspondan a las cláusulas WHERE y ORDER BY.
- Evita el uso excesivo de índices, ya que puede degradar el rendimiento de escritura (insert/update).
- Ajuste de red:
- Asegura una red de baja latencia y alto ancho de banda, especialmente para conexiones ECP y de sharding.
- Optimiza los parámetros TCP/IP del sistema operativo para el tráfico de IRIS.
- Optimización de transacciones:
- Mantén las transacciones cortas para liberar los bloqueos más rápidamente y aumentar la concurrencia.
- Ajusta la frecuencia de los checkpoints de la base de datos para equilibrar la consistencia y el rendimiento de E/S.
- Sincronización de hilos y procesos:
- Ajusta los parámetros de jobs y hilos de IRIS para optimizar el paralelismo según el hardware del servidor.
- Ajuste de interoperabilidad (productions):
- Para sistemas que actúan como ESB (Enterprise Service Bus):
- Niveles de registro de eventos: en un entorno de producción, evita el registro en modo “Debug”. Un registro excesivo en las bases de datos de gestión (IRISSYS o ENSLIB) puede degradar significativamente el rendimiento del flujo principal de mensajes.
- Tamaño del pool: ajusta el tamaño del pool de los adaptadores. Si el pool es demasiado pequeño, los mensajes se encolan; si es demasiado grande, puedes provocar contención de recursos o sobrecargar el sistema externo.
- Procesamiento asíncrono: utiliza llamadas asíncronas en los Business Processes siempre que sea posible para evitar bloquear la ejecución mientras se espera a sistemas externos lentos.
- Resumen de los parámetros de iris.cpf utilizados para mejorar el rendimiento:
|
Sección CPF |
Parámetro |
Valor sugerido (ejemplo 32 GB RAM) |
Objetivo |
|
[config] |
globals |
16384 (16 GB en buffers de 8K) |
Reducir E/S de lectura |
|
[config] |
routines |
1024 (1GB) |
Acelerar la ejecución del código |
|
[config] |
gmheap |
524288 (512MB) |
Estabilidad en entornos de producción |
|
[config] |
locksiz |
67108864 (64MB) |
Soportar alta concurrencia |
|
[config] |
wijsize |
1024 (1GB) |
Mejorar el rendimiento de escritura |
Artículos y referencias de documentación
- Guía de alta disponibilidad: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA
- Guía de escalabilidad: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSCALE
- Guía de integridad de datos: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI
- Arquitecturas de referencia de InterSystems IRIS para Amazon Web Services (AWS): https://community.intersystems.com/post/intersystems-iris-example-reference-architectures-amazon-web-services-aws#:~:text=Large%20Production%20Configuration,massive%20horizontal%20scaling%20of%20users
- Índice de la serie de planificación de capacidad y rendimiento de plataformas de datos de InterSystems: https://community.intersystems.com/post/intersystems-data-platforms-capacity-planning-and-performance-series-index
- Artículos de Robert Cemper: https://community.intersystems.com/user/69016/posts?filter=articles