Método de Python no funciona en Business Process
Hola a todos.
Tengo un problema bastante extraño.
He creado un método en Python para crear un vector para una búsqueda vectorial. Hasta aquí todo correcto.
Si invoco a este método desde el termina, funciona correctamente:
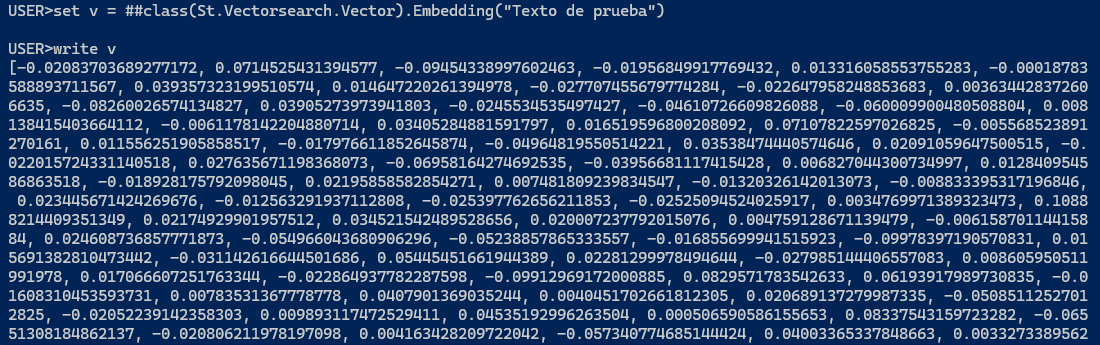
Pero si hago esta misma llamada desde un bloque de código en una Business Process, se queda bloqueado, no responde y lanza el siguiente error:
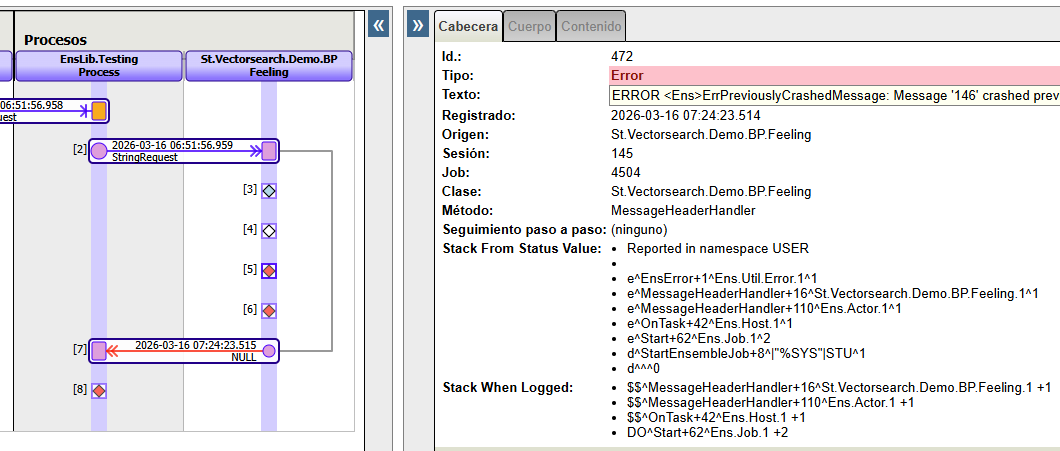
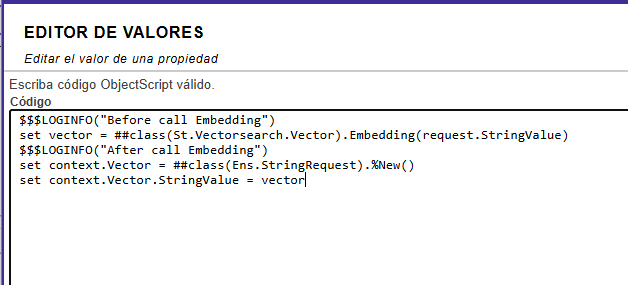
¿Alguien sabe que está ocurriendo y como solucionarlo?
Muchas gracias por adelantado
Comments
Buenas @Kurro Lopez ¿Qué tipo de datos retorna tu método Embedding?
Este es mi código
ClassMethod Embedding(Text) [ Language = python ]
{
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
# sentences = ['This is an example sentence', 'Each sentence is converted']
sentences = [Text]
# Load model from HuggingFace Hub
#; tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
#; model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Load model from multilingual model
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
#print(sentence_embeddings)
return str(sentence_embeddings[0].tolist())
}
Te sugeriría que añadas a tu código un try/catch y unas cuantas trazas para identificar el punto exacto que te genera el problema. Hace no mucho me pasó algo parecido, aunque en mi caso el problema era un fallo con la última versión de sentence-transformers.
Si puedes, añade a la declaración del método el tipo de datos de salida.
Voy a probar.
Es curioso porque si lo ejecuto desde el termina, tarda un poco pero responde. En cambio si es invocado desde un BP, se queda pillado y da un error en el BP.
El código de invocación es el que he puesto en el mensaje.
¿Se llega a escribir en el log el "After call embedding"?
No, en ningún momento. Simplemente se queda esperando una respuesta del método Embedding y ahí se queda
Modifica la versión de sentence-transformers como te indico justo debajo.
Modifica la versión de sentence-transformers que estás usando por la siguiente:
He reiniciado mi docker para que vuelva a compilar todo desde cero para ver si así volvía a la vida, pero ahora me aparece el siguiente error cuando compila la clase St.Vectorsearch.Vector
USER>do $system.OBJ.Compile("St.Vectorsearch.Vector","ck")
Compilation started on 04/16/2026 06:05:04 with qualifiers 'ck'
Compiling class St.Vectorsearch.Vector
ERROR #7802: Worker job/s '878:23' unexpectedly shut down in group '#Default:(4743230725894):0'.
ERROR #7812: Work queue unexpectedly removed, shutting down.
ERROR #5002: ObjectScript error: <THROW>WaitForComplete+215^%SYS.WorkQueueMgr *%Exception.StatusException ERROR #7802: Worker job/s '878:23' unexpectedly shut down in group '#Default:(4743230725894):0'.
ERROR #7812: Work queue unexpectedly removed, shutting down.
Detected 3 errors during compilation in 1.003s.He probado a usar tanto la versión de sentence-transforme que me habías pasado como usando la última versión, y da el mismo error al compilarlo.
¿Alguna idea?
Esta es mi clase St.Vectorsearch.Vector
Class St.Vectorsearch.Vector Extends %RegisteredObject
{
ClassMethod Embedding(Test) [ Language = python ]
{
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
# sentences = ['This is an example sentence', 'Each sentence is converted']
sentences = [Test]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
#print(sentence_embeddings)
return str(sentence_embeddings[0].tolist())
}
}Estoy usando la imagen de docker de community
Nota: También he probado creando una clase con un código de python simple y da el mismo error. ¿Puede ser que esta imagen de docker tenga problemas con Python?
Class St.Vectorsearch.Vector Extends %RegisteredObject
{
ClassMethod Embedding(Test) [ Language = python ]
{
return (Test)
}
}Compilation started on 04/16/2026 06:12:25 with qualifiers 'cuk'
Compiling class St.Vectorsearch.Vector
ERROR #7802: Worker job/s '1199:40' unexpectedly shut down in group '#Default:(2988722416963):0'.
ERROR #7812: Work queue unexpectedly removed, shutting down.
ERROR #5002: ObjectScript error: <THROW>WaitForComplete+215^%SYS.WorkQueueMgr *%Exception.StatusException ERROR #7802: Worker job/s '1199:40' unexpectedly shut down in group '#Default:(2988722416963):0'.
ERROR #7812: Work queue unexpectedly removed, shutting down.
Detected 3 errors during compilation in 1.014s.
En la imagen de la traza, pone que falla en la línea 16 del método: "Stack When Logged: $$^MessageHeaderHandler+16^St.Vectorsearch.Demo.BP.Feeling.1 +1".
Prueba a abrir la clase: "St.Vectorsearch.Demo.BP.Feeling.1" y buscar esa línea.
No sé si te serviría. Quizás te de una pista. Imagino que apuntará a una clase interna, como por ejemplo (si busco en un BP cualquiera "MessageHeaderHandler+16", sale lo siguiente):
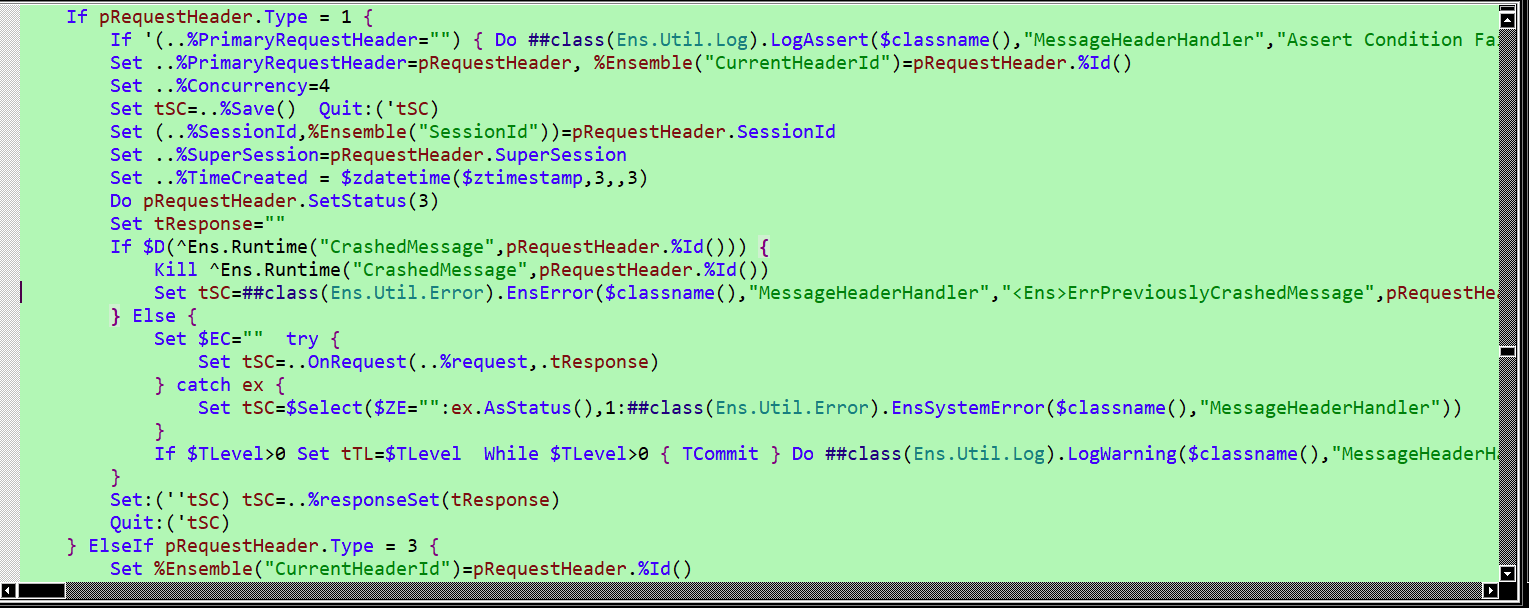
Este mensaje de error me lo dá cuando reinicio el componente, porque se queda totalmente bloqueado. Esa linea es la que apunta a la llamada al método
set vector = ##class(St.Vectorsearch.Vector).Embedding(request.StringValue)
@Kurro Lopez quizás podrías probar a separar las líneas del "Editor de Valores" del BP, del margen izquierdo; es decir, poner un tabulador entre las 5 líneas del ObjectScript escrito en el BP, porque, en mi caso, he visto, que si el código lo escribo pegado al margen izquierdo, al compilar el Proceso, el BP, podría dar errores. Ahora bien, no sé si tiene relación con lo que nos has escrito en el hilo. En mi caso, he trabajado con IRIS 2020 e IRIS 2023 (y versiones anteriores), no sé si en la 2025, esto ya está solucionado.
Lo digo, porque por Terminal si te funciona, y llamando al Proceso no.