Complementando IRIS con MLflow para un pipeline de entrenamiento continuo (CT)
Una canalización (pipeline) de entrenamiento continuo (CT) formaliza un modelo de aprendizaje automático (ML) desarrollado mediante la experimentación en ciencia de datos, utilizando los datos disponibles en un momento dado. Prepara el modelo para su despliegue, al tiempo que permite actualizaciones autónomas a medida que se dispone de nuevos datos, junto con capacidades sólidas de monitorización del rendimiento, registro (logging) y registro de modelos para fines de auditoría.
InterSystems IRIS ya proporciona casi todos los componentes necesarios para soportar un pipeline de este tipo. Sin embargo, falta un elemento clave: una herramienta estandarizada para el registro de modelos. En este artículo, presento este enfoque, que combina las fortalezas de IRIS con la plataforma de ingeniería de IA de código abierto MLflow. Juntos, actúan como herramientas complementarias para construir un pipeline eficaz de entrenamiento continuo (CT).
La implementación en este repositorio aprovecha la configuración integrada de MLflow para almacenar explicadores de SHAP, con el fin de proporcionar explicaciones sobre las predicciones realizadas por el modelo correspondiente en ese momento, incluidos modelos complejos de tipo “caja negra” como Random Forest, XGBoost, redes neuronales, etc.
Demo: https://youtu.be/qLdc4jhn83c
Componentes del pipeline CT
La teoría detrás de los módulos de este pipeline CT se basa en el estándar de la industria para el nivel 1 de MLOps definido por Google en este artículo, y la implementación de cada uno de sus componentes aprovecha las mejores funcionalidades tanto de IRIS como de MLflow, destacadas en rojo, como se muestra en la imagen a continuación:
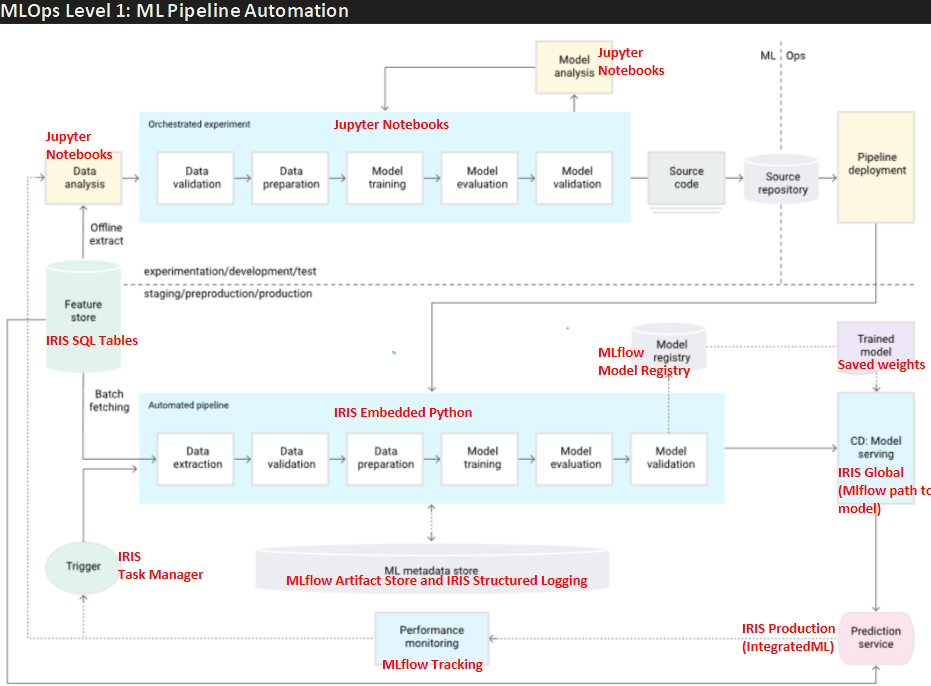
Para quienes no estén familiarizados con los pipelines CT, la imagen anterior describe cómo la fase tradicional de experimentación de un proyecto de ciencia de datos (sección superior “experimentación/desarrollo/pruebas”), normalmente realizada en notebooks de Jupyter, se transforma en un despliegue de nivel productivo del modelo desarrollado que permite una monitorización continua del rendimiento a lo largo del tiempo, y un reentrenamiento automático siempre que el rendimiento del modelo se degrade. Todo ello con un adecuado versionado del modelo y registro (logging) con fines de auditoría.
Entramos en detalle en el README del repositorio, pero para una comprensión inicial de cada componente, definimos a continuación de forma breve qué hace cada uno y cómo se relaciona con la herramienta IRIS/MLflow elegida para ese propósito.
- Feature Store: Es la única fuente de verdad para la obtención de los datos, y donde se definen todos los parámetros constantes o definiciones relacionadas con los propios datos, que pueden variar entre clientes y casos de uso (por ejemplo, cada cliente puede definir la reingestión hospitalaria como 15, 30 o cualquier otro número de días. La llegada tardía a una cita puede considerarse a partir de 5, 10 o cualquier otro número de minutos). Las tablas SQL de IRIS, basadas en globals multidimensionales, permiten un almacenamiento de alta velocidad, y las propiedades computadas almacenadas facilitan la definición de propiedades personalizadas junto con los datos en bruto.
- Automated Pipeline: Es la versión formalizada y claramente modularizada del “experimento orquestado” que normalmente se realiza en un notebook de Jupyter, preparada para ejecutarse cada vez que sea necesario reentrenar el modelo. Incluye todos los procesos de datos y de entrenamiento necesarios para obtener el modelo con mejor rendimiento global. En esta sección se definen todas las constantes relacionadas con el propio modelo que se eligieron durante la fase de experimentación (previamente realizada por los data scientists en notebooks de Jupyter), por ejemplo: seed, tamaño de test, K-folds para validación, etc. En nuestra implementación, utilizamos Python embebido para acceder fácilmente a clases de IRIS, junto con todas las librerías estándar de Machine Learning en Python (Pandas, scikit-learn, MLflow, etc).
- Model Registry: Durante el entrenamiento, cada modelo entrenado se registra en el backend registry de MLflow, configurado automáticamente al construir el proyecto. En cualquier momento podemos volver a descargar modelos desde allí y consultar el rendimiento de modelos anteriores.
- Trained Model: Aunque el backend de MLflow dispone de un Artifact Store donde se guardan los pesos de todos los modelos entrenados, este proyecto además guarda los artefactos directamente en una ubicación persistente (volumen de Docker) para una carga rápida cuando sea necesario. En caso de que se eliminen, se vuelven a descargar y a guardar en la misma ubicación desde el Artifact Store de MLflow.
- Model Serving: Este bloque se encarga de gestionar el modelo que se sirve en producción. El path a los artefactos del modelo en producción se almacena en un global de IRIS, que es lo que se actualiza cuando es necesario. En este repositorio se promueve directamente el nuevo modelo si tiene mejor rendimiento que el anterior, pero en un escenario real esto podría requerir aprobación humana. Se decidió almacenar el path del modelo en un global y no el propio modelo porque hacerlo implicaría tiempo adicional de serialización y deserialización del objeto Python, mientras que el texto es más rápido y directo de leer desde un global, independientemente de las clases del repositorio, lo que lo hace fácil y eficiente de consultar desde cualquier parte.
- Prediction Service: Es el servicio real que un cliente utilizaría para solicitar inferencias del modelo actualmente en producción. En este momento, el repositorio utiliza un método en Python embebido para ello, pero este bloque puede mejorarse transformando el modelo a formato PMML para que el servicio de producción pueda ejecutarse con Integrated ML para modelos sklearn, o cualquier modelo Python como LightGBM usando los próximos modelos personalizados de IntegratedML en IRIS 2026.1.
- Performance Monitoring: Es cualquier tipo de monitorización implementada para hacer seguimiento del rendimiento del modelo en producción, junto con modelos anteriores si es necesario. Para ello utilizamos la interfaz de MLflow, donde podemos crear gráficos personalizados con cualquier variable registrada, fecha, métricas de rendimiento, tanto para cada modelo como para todos los modelos entrenados históricamente.
- Trigger: Es cualquier mecanismo que activa la ejecución del Automated Pipeline. Puede ser deriva de datos, degradación del modelo por debajo de un umbral, disponibilidad de una cierta cantidad de nuevos datos con suficiente ground truth, o una simple programación periódica. En este proyecto se compara directamente contra un umbral definido de la métrica R², de modo que cada vez que el rendimiento cae por debajo del valor definido en
MLpipeline.PerformanceMonitoring.R2THRESHOLD, se ejecuta el pipeline automática. Para esta tarea, otra alternativa válida sería utilizar el gestor de tareas para programar un método que revise el rendimiento registrado en el tracking de MLflow y decida si se debe reentrenar un nuevo modelo.
La incorporación de MLflow permite una monitorización histórica sencilla del rendimiento de los modelos a lo largo del tiempo mediante una única interfaz de usuario alojada localmente en un contenedor Docker. Permite almacenar y acceder a los artefactos de todos los modelos entrenados previamente, incluidos los que han sido desplegados en producción. Estos artefactos pueden descargarse cuando sea necesario, junto con métricas de rendimiento estándar y personalizadas, así como visualizaciones personalizadas.
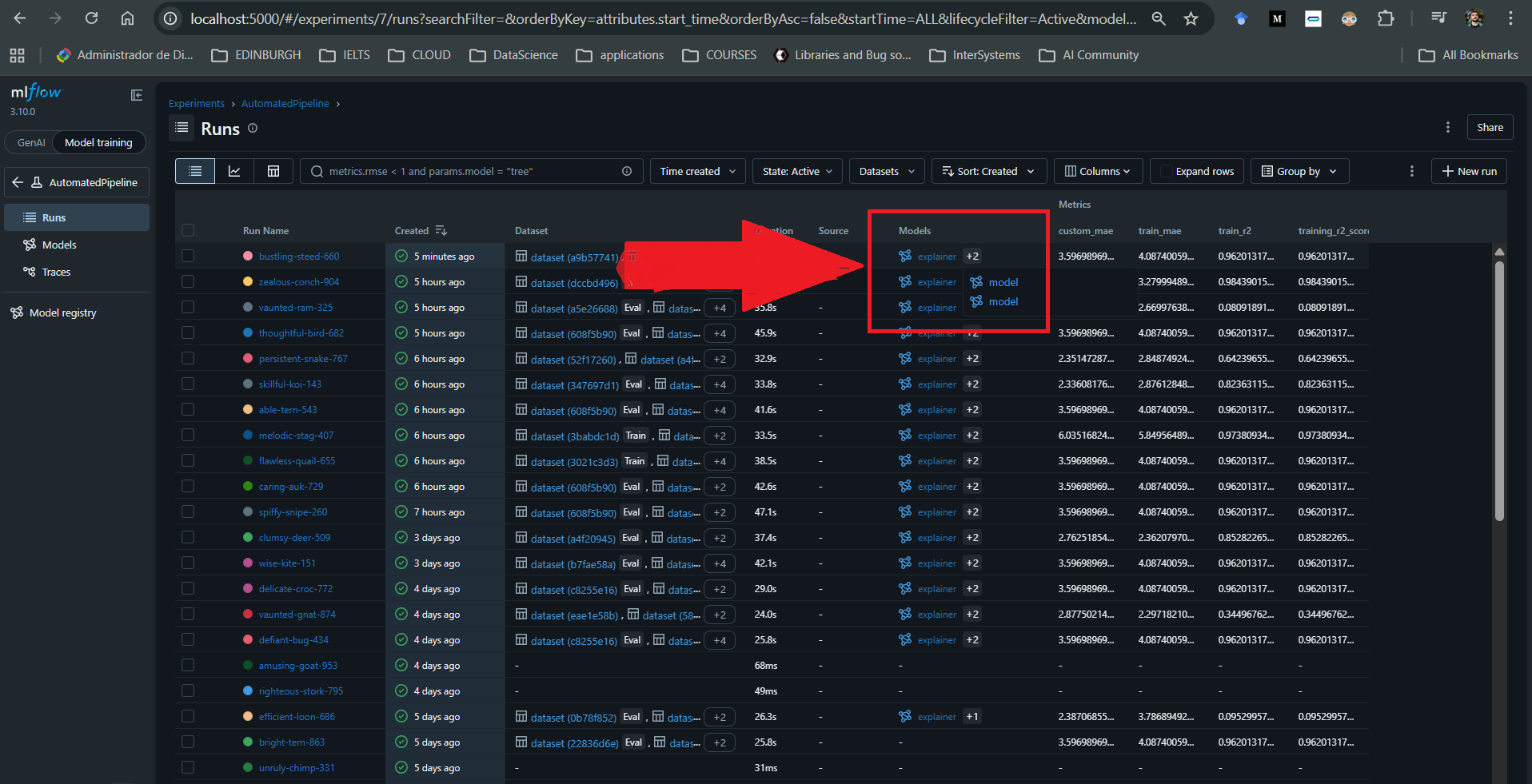
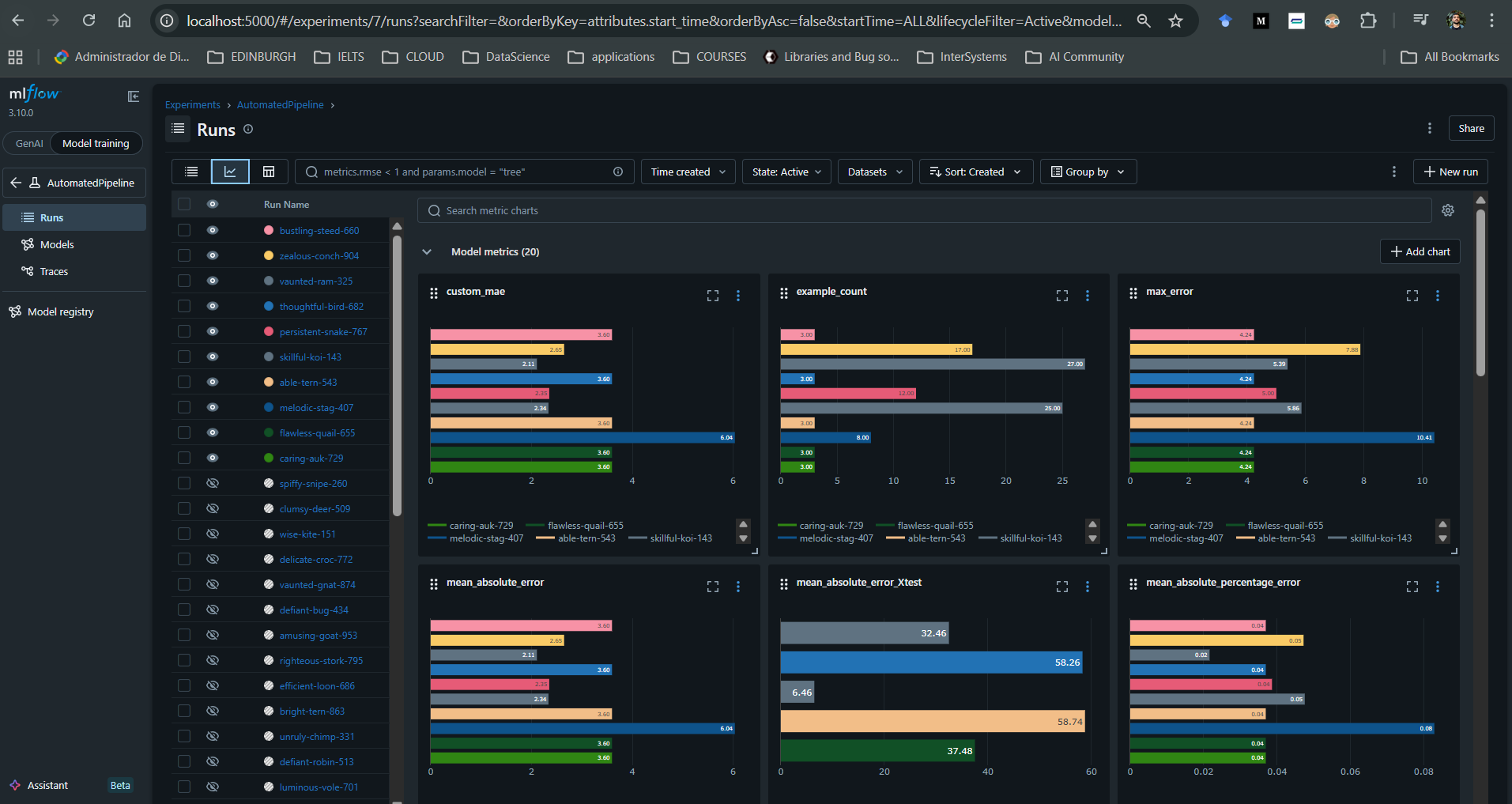
Para cada ejecución asociada a un modelo, también es posible registrar artefactos adicionales como explicadores SHAP, gráficos personalizados y métricas definidas por el usuario.
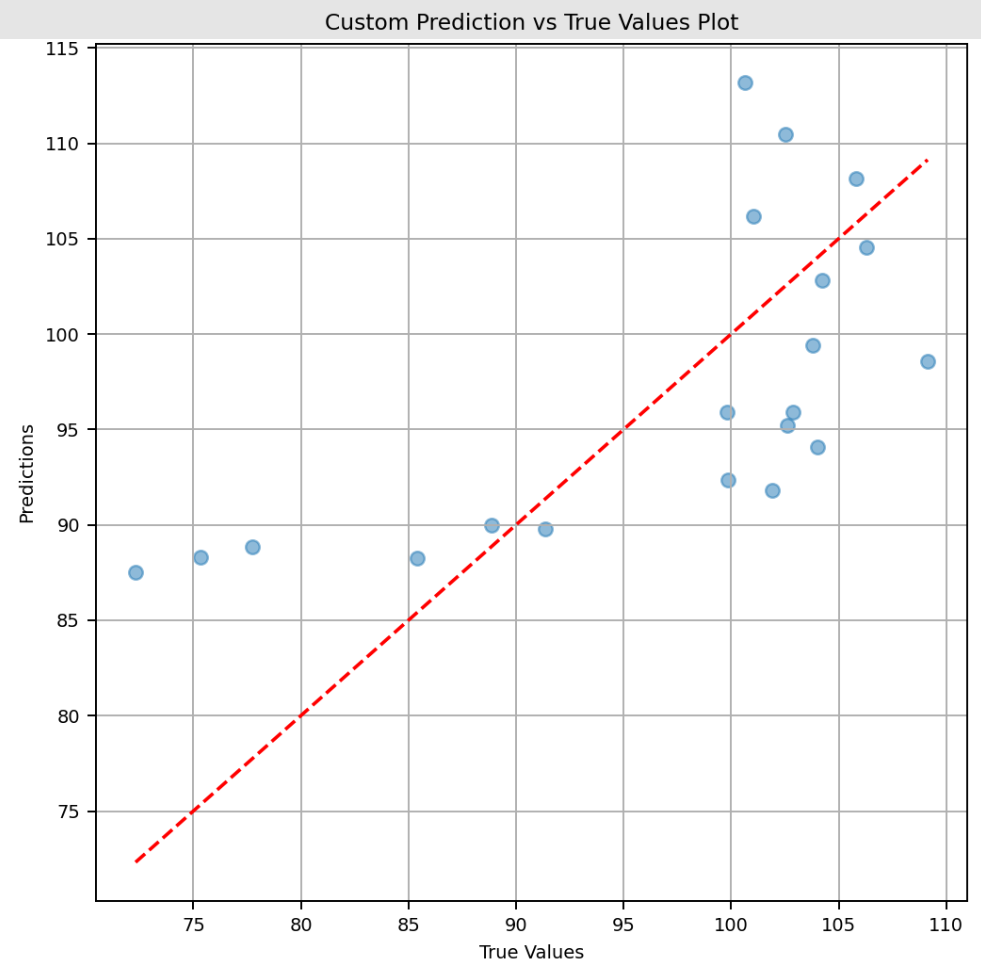
La implementación de este pipeline CT utiliza registro estructurado para separar los registros de este pipeline del resto del sistema, almacenándolos en una ruta persistente dentro del volumen del contenedor que aloja IRIS.
Trabajo futuro
- En el futuro, este pipeline puede aprovechar la nueva funcionalidad de IRIS 2026.1: modelos personalizados de IntegratedML, para simplificar el servicio de predicción mediante comandos SQL, independientemente del modelo (con soporte añadido para LightGBM, redes neuronales, XGBoost, etc.).
- Actualmente, el modelo solo se actualiza automáticamente mediante reentrenamiento con nuevos datos, pero los hiperparámetros permanecen estáticos. Siguiendo las instrucciones de esta guía, este pipeline podría mejorarse introduciendo flexibilidad en los hiperparámetros y permitiendo reoptimizar el modelo mediante el framework de optimización de hiperparámetros de código abierto Optuna.
- En este proyecto, cuando el rendimiento de las predicciones cae por debajo de un umbral predefinido, el modelo se reentrena y se actualiza automáticamente. Sin embargo, en algunos casos debería requerirse aprobación humana antes de realizar cambios en producción, algo que debe considerarse en un escenario real.