Es posible que, al actualizar IRIS for Health de la versión 2024.1 a 2024.2+ (2025.1, 2026.1, etc.), observéis que el portal FHIR al que accedíais anteriormente ahora muestra el mensaje “No encontrado”.

Es posible que, al actualizar IRIS for Health de la versión 2024.1 a 2024.2+ (2025.1, 2026.1, etc.), observéis que el portal FHIR al que accedíais anteriormente ahora muestra el mensaje “No encontrado”.
Los globals de InterSystems IRIS son uno de los puntos fuertes principales de la plataforma: almacenan datos jerárquicos en una estructura directa, ordenada y eficiente. Pero cuando trabajáis desde Python, manipular globals a veces puede parecer más una API de bajo nivel que algo alineado con las formas naturales de trabajar del lenguaje.
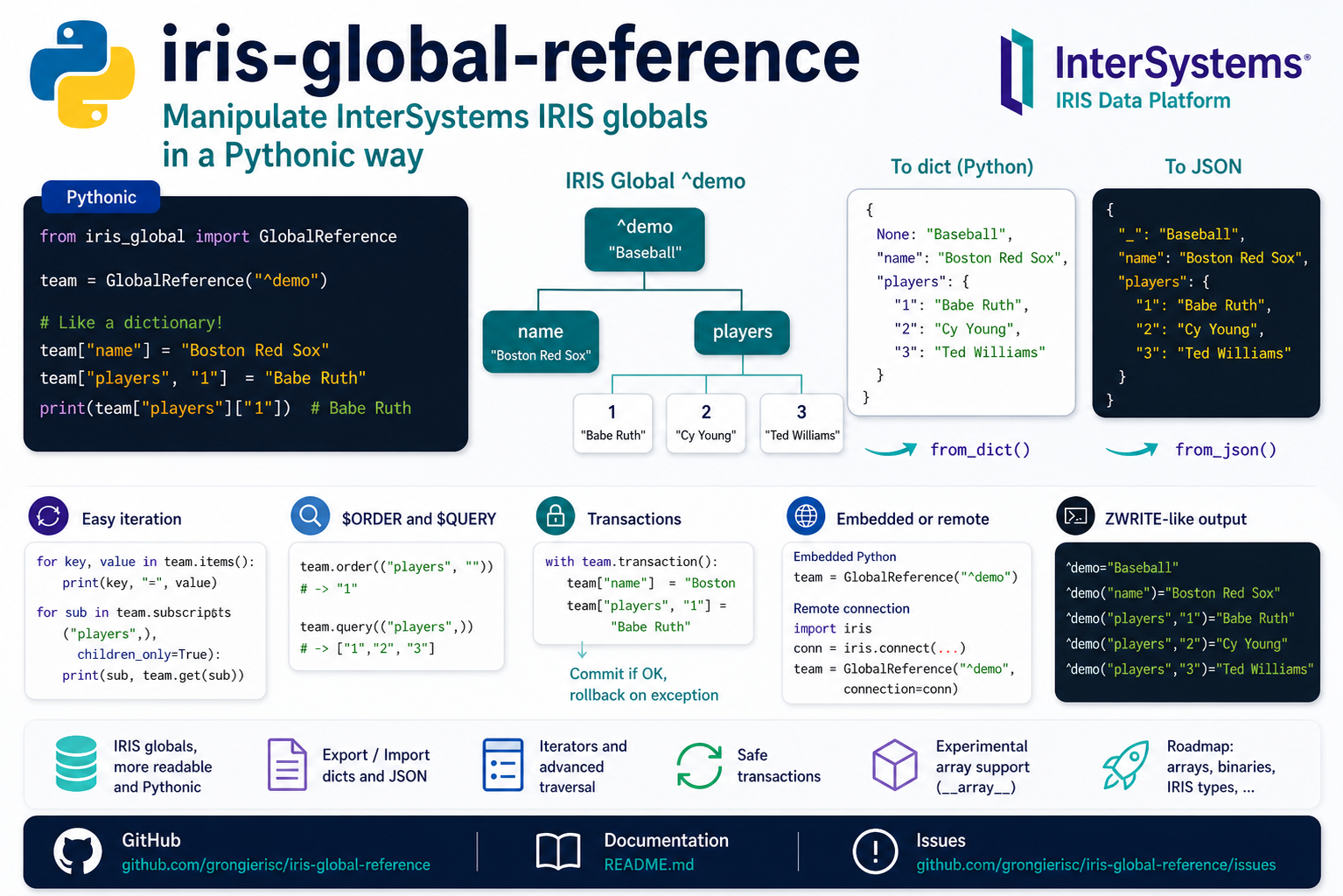
El proyecto iris-global-reference proporciona una capa de Python sobre los globals de InterSystems IRIS.
Bienvenidos al siguiente capítulo de mi serie sobre CI/CD, donde analizamos posibles enfoques para el desarrollo de software con tecnologías de InterSystems y GitLab.
Hoy quiero compartiros algunos enfoques que reducirán vuestros tiempos de compilación (especialmente si estáis haciendo compilaciones incrementales o por diferencias en lugar de una compilación completa).
La carga de código y la compilación se ven afectadas por una variedad de indicadores y calificadores.
En este ejemplo he buscado el punto intermedio entre una demo muy simple y una arquitectura muy complicada: una integración pequeña, clara y útil para entender cómo conectar InterSystems IRIS con Azure Service Bus usando una producción de interoperabilidad de IRIS que aprovecha Embedded Python para utilizar la librería oficial de Azure.
La idea es sencilla:
Business Operation.Inbound Adapter y un Business Service.azure-servicebus sin salir del entorno de IRIS.Dicho de otra forma: una solución en IRIS que usa Embedded Python donde corresponda para integrarse con Azure.
Introducción
InterSystems IRIS Adaptive Analytics es una extensión opcional que proporciona una capa de modelo de datos virtual entre InterSystems IRIS y herramientas populares de Business Intelligence (BI) e Inteligencia Artificial (IA). Adaptive Analytics está impulsado por AtScale, y la documentación de AtScale puede consultarse en este enlace: https://documentation.intersystems.atscale.com
Este artículo mostrará algunas funcionalidades de AtScale que pueden facilitar el análisis de datos:
Agregaciones
Se ha introducido una característica muy importante para HL7 FHIR con la versión v2026.1: el soporte para los ámbitos (scopes) granulares de SMART on FHIR v2.
Esto os permite ser mucho más estrictos y precisos en el acceso que otorgáis a los datos en vuestro repositorio FHIR.
Parte de este nuevo soporte consiste en rechazar solicitudes que no coincidan con los scopes, pero una capacidad aún más interesante es filtrar los resultados de acuerdo con los scopes proporcionados.
Esta demostración te guía a través de la nueva funcionalidad de particionamiento de tablas en IRIS SQL, explicando qué hace y cómo funciona. Usaremos solo unas pocas decenas de filas para mostrar el concepto, aunque la funcionalidad está pensada para conjuntos de datos mucho más grandes.
Si queréis una introducción más breve y a alto nivel sobre Table Partitioning, podéis consultar el módulo de formación online Managing Tables with Partitioning in InterSystems IRIS
ℹ️ Table Partitioning está incluido en IRIS 2026.1 como una funcionalidad experimental.
Las extensiones oficiales de InterSystems para VS Code están repletas de funcionalidades que facilitan el desarrollo con los productos de InterSystems. Hoy me gustaría destacar algunas funciones pequeñas pero útiles que quizá hayáis pasado por alto.
Podéis ver todos los miembros de la clase actual, incluidos los miembros heredados, con solo hacer clic en un botón. Simplemente haced clic en el icono de la clase en la esquina superior derecha de la ventana del editor y aparecerá una lista filtrable de todos los miembros.
Como parte de la nueva ola de la interfaz de Interoperabilidad (consultad las novedades de 2025.1 y 2025.3 por @Aya Heshmat), la versión v2026.1, ya disponible como Developer Preview —y que podría ser una razón para probarla— incluirá la nueva interfaz para el editor BPL (y otras mejoras de UI).
Aquí tenéis un pequeño adelanto:
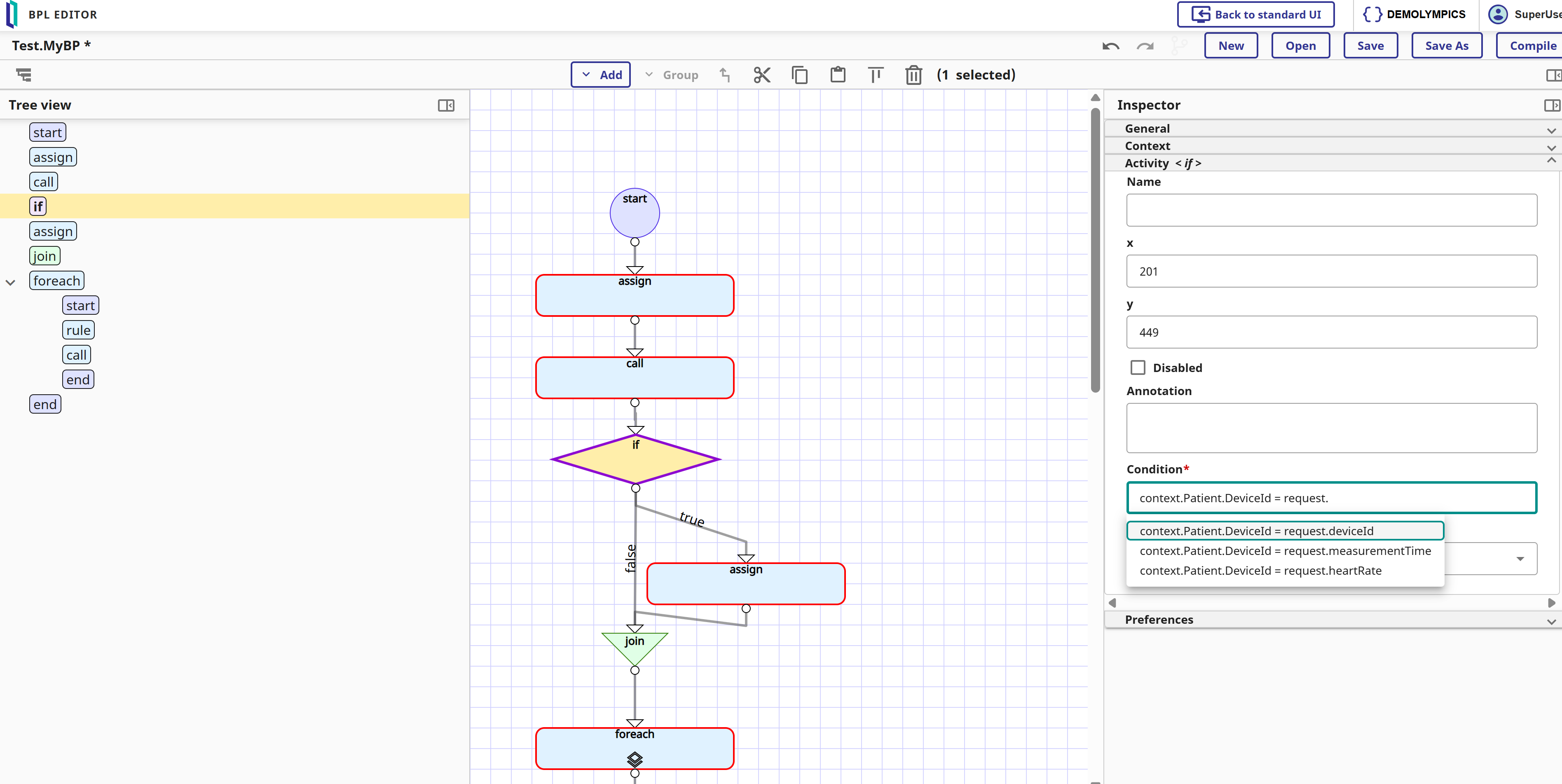
Parte de lo que me gusta especialmente:
10:47 AM — Los resultados de creatinina de José García llegan al servidor FHIR del hospital. 2.1 mg/dL — un aumento del 35% frente al mes pasado.
¿Qué pasa después?
Sin chatbot. Sin prompts manuales. Sin razonamiento de caja negra.
Esto es soporte a la decisión clínica impulsado por eventos con trazabilidad completa:
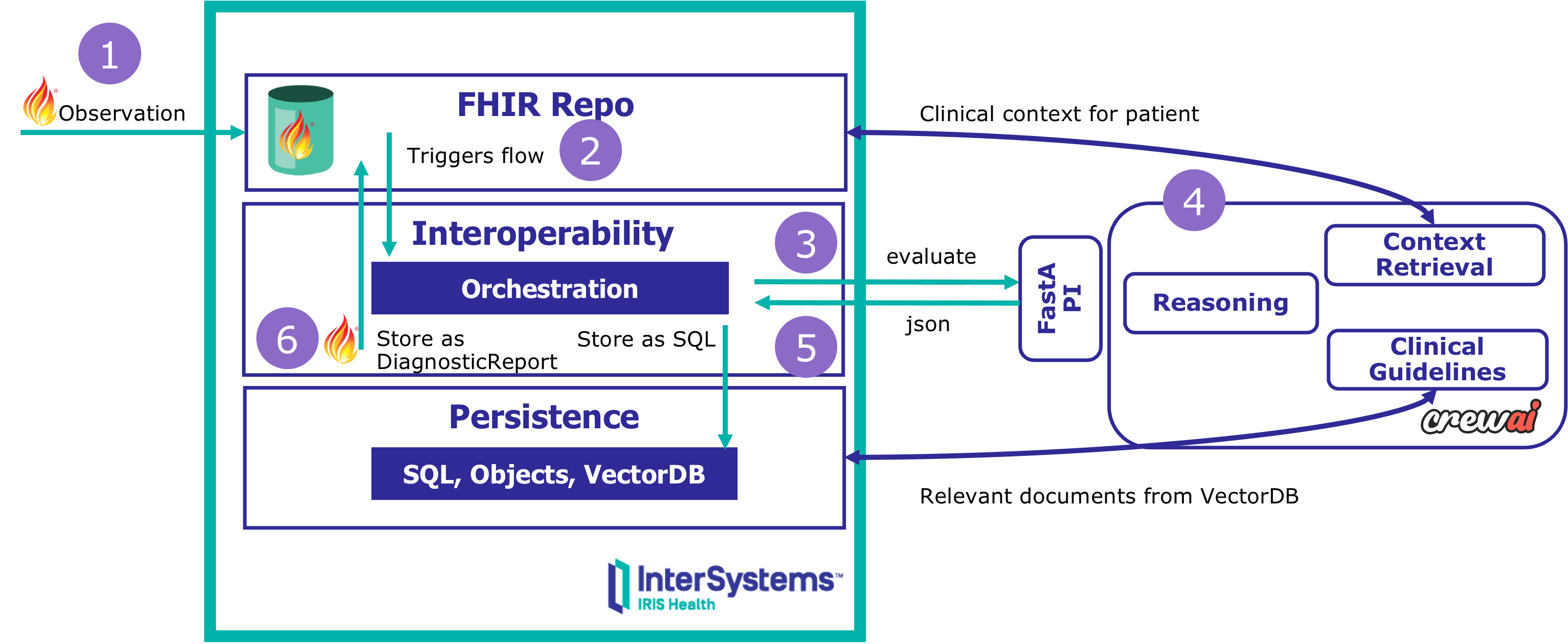
✅ Activado automáticamente por eventos FHIR ✅ Razonamiento multiagente (contexto, guías, recomendaciones) ✅ Trazabilidad completa en SQL (cada decisión, cada fuente de evidencia) ✅ Salidas nativas FHIR (DiagnosticReport publicado en el servidor)
Construido con:
Aprenderás: 🖋️ Cómo orquestar flujos de IA agéntica dentro de sistemas de interoperabilidad listos para producción, y por qué la explicabilidad importa más que la precisión por sí sola.
PEP 578 añadió hooks de auditoría de Python. Una gran variedad de eventos (carga de módulos, interacciones con el sistema operativo, etc.) generan eventos de auditoría a los que podéis suscribiros.
Así es como se hace. Primero, cread un hook de Python embebido:
Class/// do ##class(User.Python).Audit()ClassMethodEn este ejemplo:
Todo esto se escribirá en el STDOUT por defecto.
A medida que las aplicaciones crecen, todas las bases de datos acaban alcanzando límites de escalado. Ya sea por capacidad de almacenamiento, usuarios concurrentes, rendimiento de las consultas o ancho de banda de E/S, las arquitecturas de un solo servidor tienen limitaciones inherentes. Esta guía explica los enfoques fundamentales para la escalabilidad de bases de datos y muestra cómo InterSystems IRIS implementa estos patrones para dar soporte a cargas de trabajo a escala empresarial.
Exploraremos dos estrategias de escalado complementarias: escalado horizontal para el volumen de usuarios (distribuyendo la carga computacional) y sharding para el volumen de datos (particionando los conjuntos de datos). Comprender los principios generales que hay detrás de estos enfoques os ayudará a tomar decisiones fundamentadas sobre cuándo y cómo escalar vuestras aplicaciones IRIS.
Los ejemplos de esta guía utilizan InterSystems IRIS en contenedores Docker.
Si queréis generar JWT a partir de un certificado/clave x509, cualquier operación (incluida la lectura) sobre %SYS.X509Credentials requiere el permiso U en el recurso %Admin_Secure. Esto se debe a que %SYS.X509Credentials es persistente y está implementado así para evitar que todos los usuarios tengan acceso a las claves privadas.
Si el recurso %Admin_Secure no está disponible en tiempo de ejecución, podéis usar la siguiente solución alternativa.
Revisándo el código de generación de JWT, descubrí que sólo utiliza %SYS.X509Credentials
Existen numerosas herramientas excelentes para probar vuestras APIs REST, especialmente cuando están en funcionamiento. Postman, distintas extensiones de navegador e incluso código personalizado en ObjectScript usando objetos %Net.HttpRequest pueden hacer el trabajo. Sin embargo, a menudo resulta complicado probar únicamente la API REST sin involucrar, sin querer, el esquema de autenticación, la configuración de la aplicación web o incluso la conectividad de red. Son muchos obstáculos solo para probar el código dentro de vuestra clase dispatch.
La buena noticia es que, si nos tomamos el tiempo para comprender cómo funciona internamente la clase %CSP.REST, encontraremos una alternativa que permite probar únicamente el contenido de la clase dispatch. Podemos configurar los objetos de request y response para invocar los métodos directamente.
En el día a día de cualquier organización, la información fluye entre aplicaciones, servicios y sistemas muy distintos entre sí. Integrarlos de forma eficiente puede ser un reto... a menos que uses InterSystems IRIS.
En este nuevo vídeo te muestro cómo construir un flujo completo de integración combinando múltiples tecnologías —APIs REST, ficheros CSV, bases de datos y servicios SOAP— todo dentro del entorno visual que ofrece el motor de interoperabilidad de IRIS.
👉 Puedes ver el vídeo aquí:
Hola,
He pensado en compartir con vosotros un hook bastante útil que me ha ayudado cuando desarrollo en Health Connect Cloud con VS Code y GitBash. Al desarrollar en Health Connect Cloud, si hacéis cambios directamente en el servidor, como reglas de enrutamiento o despliegue de componentes, estos no se incluyen automáticamente en el control de versiones; por lo tanto, debéis exportarlos desde el servidor a vuestros archivos locales y hacer push a vuestro repositorio remoto. Estoy seguro de que hay métodos más sencillos para gestionar esto, que estoy en proceso de probar, pero como solución rápida pensé que sería útil tener un hook de pre-commit que active un recordatorio en GitBash. Mirad el ejemplo a continuación.
.png)
¿Te gustaría integrar capacidades de machine learning directamente en tu plataforma IRIS desde tus datos SQL?
Este vídeo te muestra exactamente cómo hacerlo utilizando InterSystems IRIS e IntegratedML.
En el artículo anterior vimos cómo construir un agente de IA de atención al cliente con smolagents e InterSystems IRIS, combinando SQL, RAG con búsquedas vectoriales e interoperabilidad.
En ese caso, utilizamos modelos en la nube (OpenAI) para el LLM y los embeddings.
En esta ocasión daremos un paso más: ejecutar el mismo agente, pero con modelos locales gracias a Ollama.
Las preguntas de atención al cliente pueden abarcar datos estructurados (pedidos, productos 🗃️), conocimiento no estructurado (docs/FAQs 📚) y otros sistemas integrados (actualizaciones de envío 🚚). En este post vamos a construir un agente de IA compacto que cubre los tres—usando:

Si alguna vez habéis observado a un verdadero artesano—ya sea un alfarero que convierte barro en una obra maestra o un luthier que transforma madera en una guitarra maravillosa—sabéis que la magia no está en los materiales, sino en el cuidado, el oficio y el proceso. Lo sé por experiencia propia: mi guitarra eléctrica hecha a mano es una fuente diaria de inspiración, pero lo admito—crear algo así es un talento que no poseo.
Sin embargo, en el mundo digital, veo a menudo gente que espera “magia” de la IA generativa escribiendo prompts vagos y sin contexto como “crea una app”.
En el artículo anterior, os hablamos sobre Python y los cuadros de mando, y en este artículo los compararé entre sí. Si estáis a punto de comenzar con la visualización en Python, la cantidad de librerías y soluciones definitivamente os sorprenderá.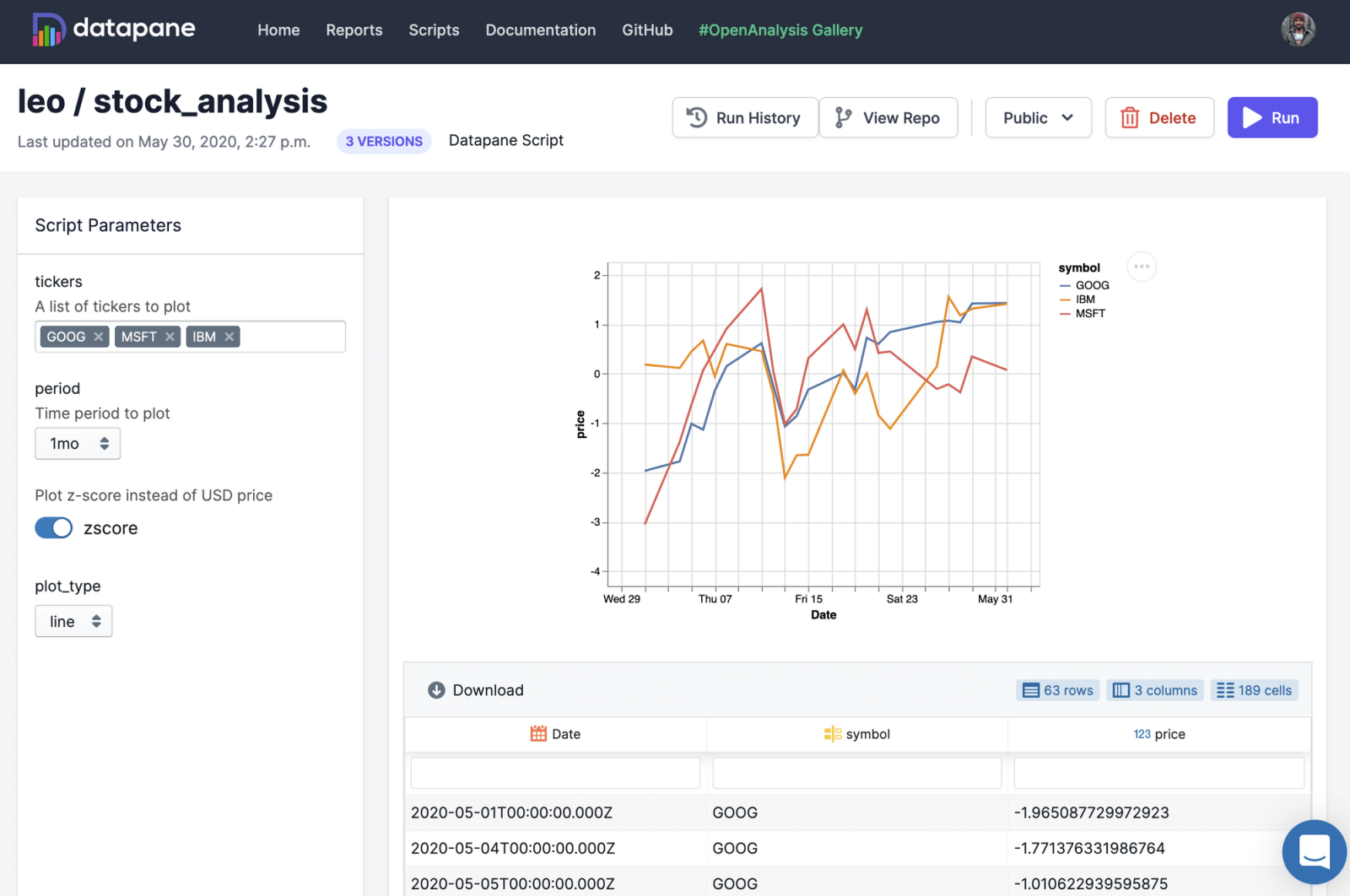
Una visualización en algunas librerías, como Matplotlib, es una imagen estática simple, lo cual es útil para explicar conceptos (en un documento, en diapositivas o en una presentación).
Estoy escribiendo esta publicación principalmente para recopilar un consenso informal sobre cómo los desarrolladores están utilizando Python junto con IRIS, ¡así que por favor responded a la encuesta al final del artículo! En el cuerpo del artículo, daré un poco de contexto sobre cada una de las opciones proporcionadas, así como sus ventajas, pero si lo preferís, podéis hacer una lectura rápida y simplemente responder la encuesta.
Aquellos interesados en explorar nuevos casos de uso de GenerativeAI.
Comparte ideas y razones al entrenar inteligencia artificial generativa para el reconocimiento de patrones.
Un desarrollador aspira a concebir una solución elegante para ciertos requerimientos.
Los patrones de coincidencia (como las expresiones regulares) pueden resolverse de muchas maneras. ¿Cuál es la mejor solución en código?
¿Puede una IA postular una solución elegante de coincidencia de patrones para un rango de ejemplos que van de simples a complejos?
Si estáis migrando de Oracle a InterSystems IRIS, como muchos de mis clientes, podríais encontraros con patrones SQL específicos de Oracle que necesitan ser traducidos.
Tomad este ejemplo:
SELECT (TO_DATE('2023-05-12','YYYY-MM-DD') - LEVEL + 1) AS gap_date
FROM dual
CONNECT BY LEVEL <= (TO_DATE('2023-05-12','YYYY-MM-DD') - TO_DATE('2023-05-02','YYYY-MM-DD') + 1);
En Oracle:
LEVEL es una pseudocolumna usada en consultas jerárquicas (CONNECT BY). Comienza en 1 y se incrementa de 1 en 1.CONNECT BY LEVEL <= (...)Kong ofrece una herramienta de gestión de configuración de código abierto (escrita en Go), llamada decK, que significa declarative Kong en inglés.
deck gateway ping
deck gateway dump -o kong.yaml
Con el lanzamiento de InterSystems IRIS Cloud SQL, recibimos cada vez más preguntas sobre cómo establecer conexiones seguras mediante JDBC y otras tecnologías de drivers. Aunque contamos con una documentación resumida y detallada sobre las tecnologías de los drivers, nuestra documentación no describe herramientas cliente individuales, como nuestra favorita personal, DBeaver. En este artículo, describiremos los pasos para crear una conexión segura desde DBeaver a vuestra implementación de Cloud SQL.
Hola desarrolladores:
Al observar la avalancha de herramientas de desarrollo impulsadas por IA y al estilo vibe coding que han estado apareciendo últimamente casi cada mes, con funciones cada vez más emocionantes, me preguntaba si sería posible aprovecharlas con InterSystems IRIS. Al menos para construir un frontend. Y la respuesta es: ¡sí! Al menos con el enfoque que seguí en este ejemplo.
Aquí tenéis mi receta para crear la interfaz de usuario mediante prompts frente al backend de InterSystems IRIS:
Aquí tenéis el resultado de mi propio experimento: una interfaz 100 % generada por prompts frente a la API REST de IRIS, que permite listar, crear, actualizar y eliminar entradas de una clase persistente (Open Exchange, código del frontend, vídeo).
¿Cómo es la receta en detalle?
A veces, los clientes necesitan una instancia pequeña de IRIS para hacer algo en la nube y luego apagarla, o necesitan cientos de contenedores (es decir, uno por usuario final o uno por interfaz) con cargas de trabajo pequeñas. Este ejercicio surgió para ver cuán pequeña podría ser una instancia de IRIS. Para este ejercicio, nos centramos en cuál es la menor cantidad de memoria que podemos configurar para una instancia de IRIS. ¿Conocéis todos los parámetros que afectan la memoria asignada por IRIS?
Recientemente ayudé a investigar un problema en una instalación que surgió después de que actualizaran su instancia de Caché en Windows de la versión 2015.1 a la 2017.1. Una sesión de terminal iniciada desde el icono del cubo del escritorio del servidor no podía ejecutar comandos a nivel del sistema operativo utilizando la función $ZF(-1). Por ejemplo, al tratar de lanzar el comando "REM" (que no tiene ningún efecto) de la siguiente manera
write $zf(-1,"rem")
devolvía -1, lo que indicaba que el comando de Windows no se podía ejecutar.
Resultó que el servicio original de Caché 2015.
Debido a que la interpretación de SCHEMA por parte de MySQL difiere de la comprensión interpretación común en SQL (como se ve en IRIS, SQL Server u Oracle), nuestro asistente automático de tablas vinculadas puede encontrar errores al intentar recuperar la información de metadatos para construir la tabla vinculada.
(Esto también se aplica a procedimientos y vistas vinculadas)
Al intentar crear una tabla vinculada mediante el asistente, os encontraréis con un error que se parece a esto:
ERROR #5535: SQL Gateway catalog table error in 'SQLPrimaryKeys'.