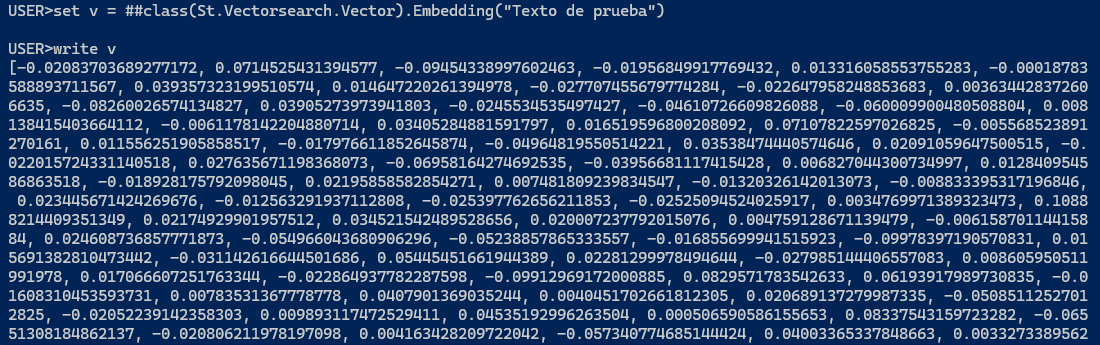
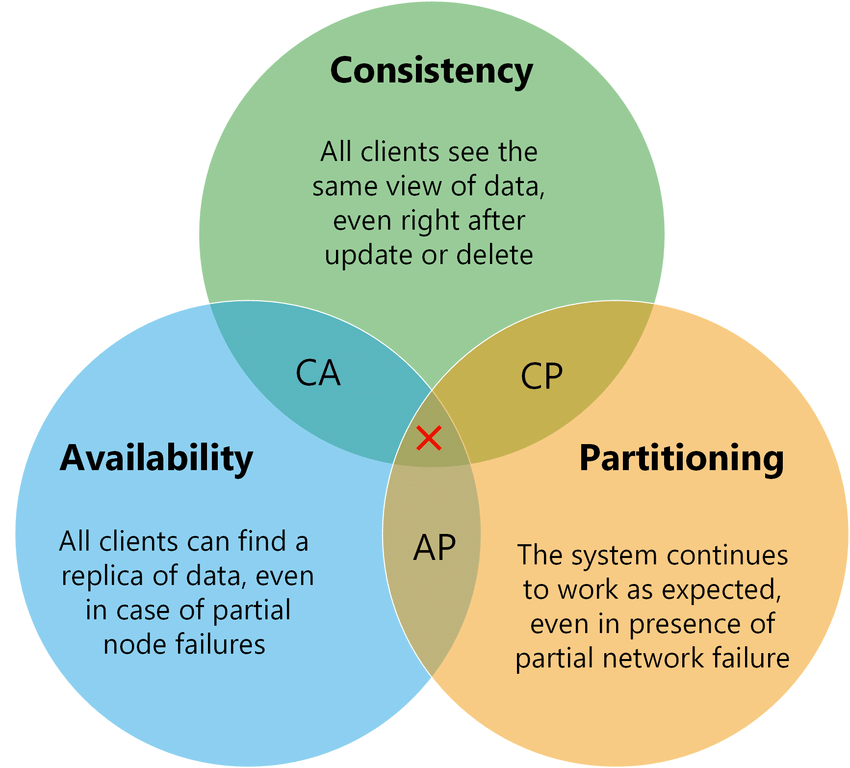
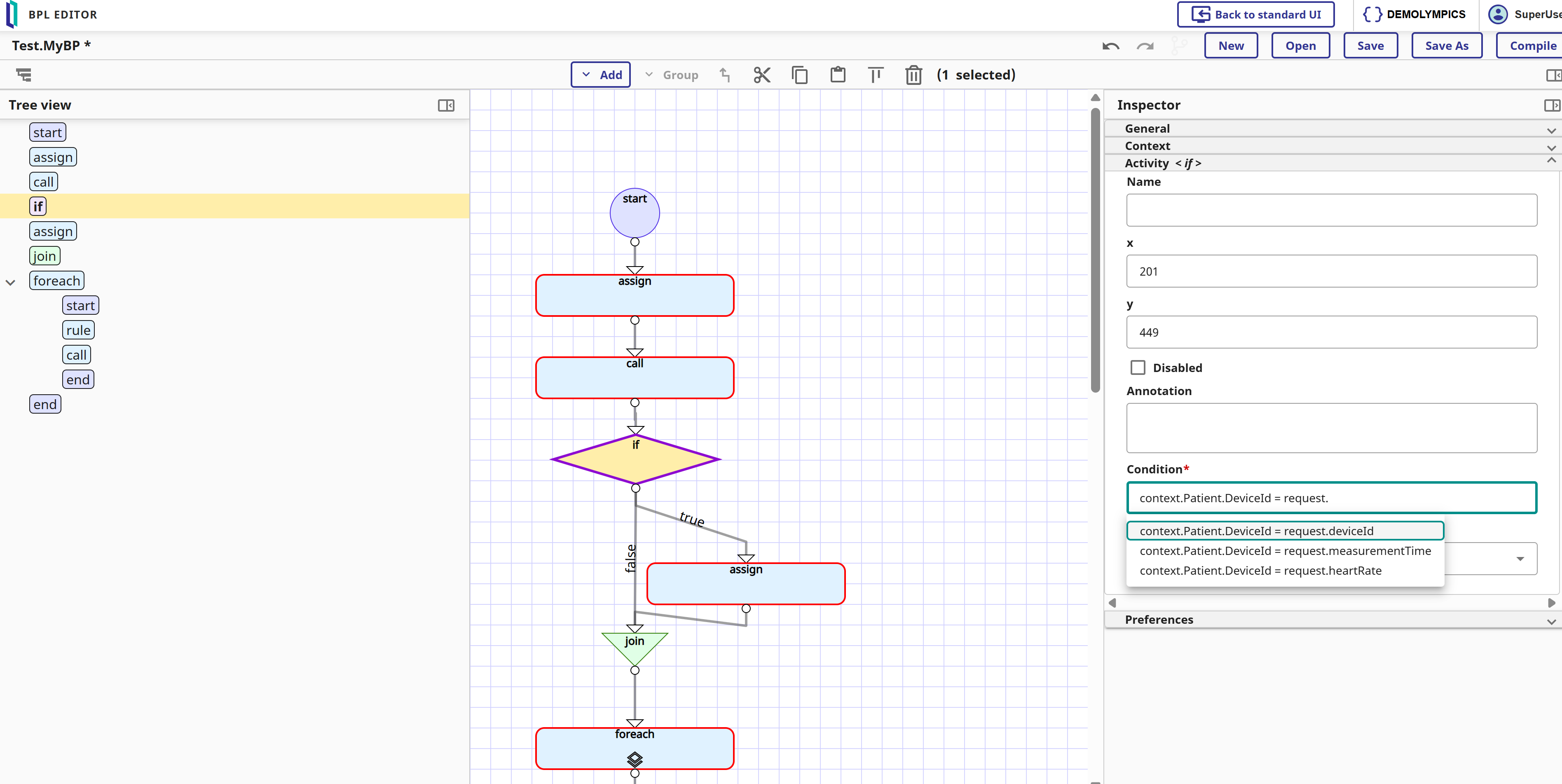
Nueva
A continuación tenéis una actualización del calendario de lanzamientos de IRIS para 2026 y un primer avance de los cambios previstos para 2027. La idea clave para 2026 es que la numeración de las versiones de mantenimiento diferirá ligeramente de la de años anteriores.
2026: numeración de las versiones de mantenimiento de IRIS 2026.1

- Julio de 2026: primera versión de mantenimiento de IRIS 2026.1 (versión prevista: 2026.1.4)
- Octubre de 2026: siguiente versión de mantenimiento (versión prevista: 2026.1.5)
- Febrero de 2027: siguiente versión de mantenimiento (versión prevista: 2026.1.