La etiqueta del concurso une las publicaciones relacionadas con cualquier competencia de codificación que tenga lugar en la Comunidad de desarrolladores de InterSystems.
Llevaba un tiempo queriendo dedicarle un rato para implementar alguna DLL o algo que pudiese usar desde Caché y al final he sacado un huequillo, si te interesa poder producir mensajes que se envíen a Kafka de una manera rápida estás en el lugar adecuado ;-)
Antes de daros la chapa con lo que vamos a ver os hago un resumen para que decidáis si os puede interesar leer el artículo.
En este artículo nos vamos a centrar "solo" en la parte de producir mensajes y enviarlos a Kafka:
He desarrollado una aplicación para importar de forma dinámica 12 conjuntos de datos junto con 43 tablas usando el comando LOAD DATA, que carga los datos de una fuente a una tabla SQL de IRIS.
No es una tarea facil dominar fechas y horas, siempre es un problema y a veces confuso en cualquier lenguaje de programación, vamos a aclarar y a poner unos cuantos tips para que esta tarea sea lo mas sencilla posible.
Súbete a la TARDIS que te voy a convertir en un Señor del tiempo
La pandemia que afectó al mundo en 2020 hizo a todo el mundo seguir las noticias y los datos relacionados con la COVID-19. ¿Por qué no aprovechar la oportunidad para crear algo sencillo y fácil de usar, para seguir el número de vacunaciones a nivel mundial?
En este artículo, os demostraré los siguientes pasos para crear vuestro propio chatbot utilizando spaCy (spaCy es una biblioteca de software de código abierto para el procesamiento avanzado del lenguaje natural, escrita en los lenguajes de programación Python y Cython):
Paso 1: Instalar las librerías necesarias
Paso2: Crear el archivo de patrones y respuestas
Paso 3: Entrenar el modelo
Paso 4: Crear una aplicación ChatBot basada en el modelo entrenado
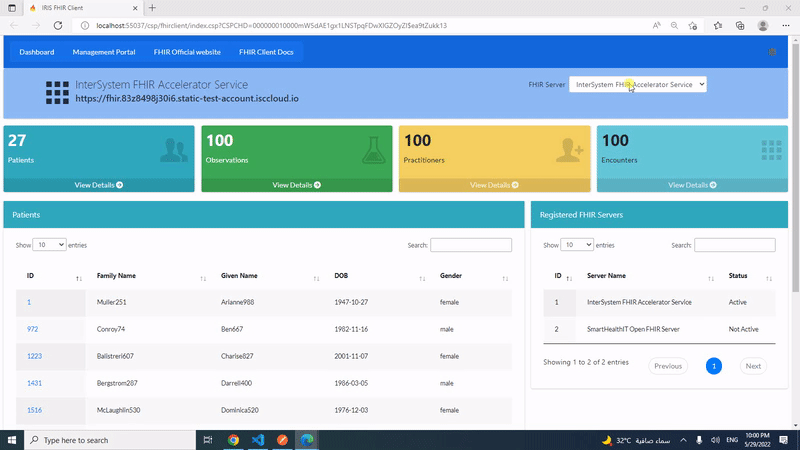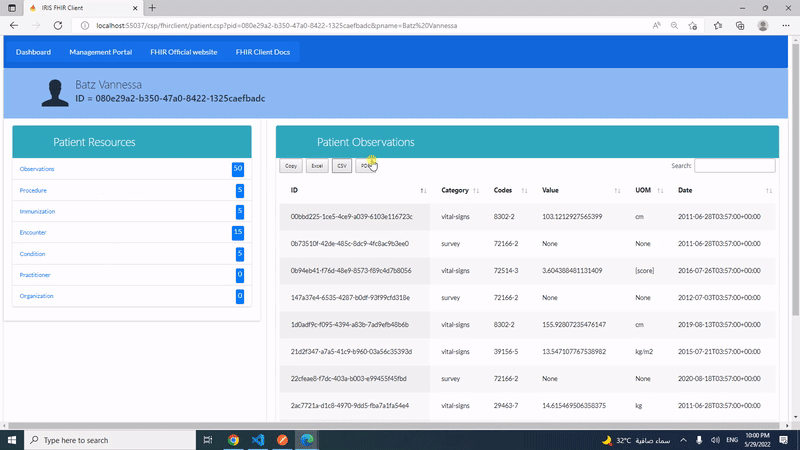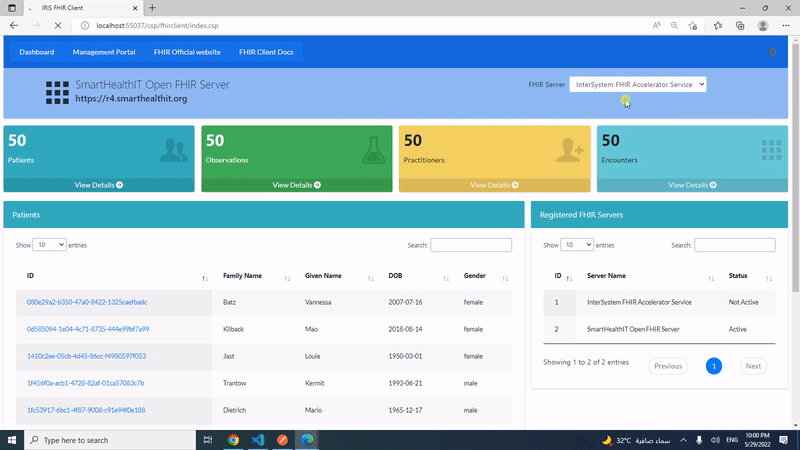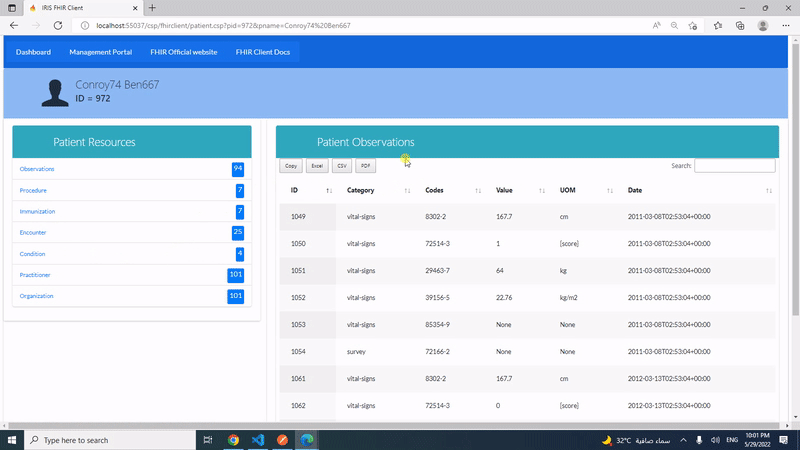
Esta publicación es una introducción a mi aplicación iris-fhir-client en Open Exchange.
Usando Python embebido y con la ayuda de la librería fhirpy, iris-fhir-client puede conectarse a cualquier servidor FHIR abierto. Obten información de recursos por terminal y mediante el uso de la aplicación web CSP.
Con frecuencia, cuando colaboramos con el repositorio de alguien en GitHub, seguimos el siguiente ciclo:
1. Fork: crear nuestra bifurcación del repositorio
2. Clone: clonar una copia local de nuestro repositorio bifurcado
3. Realizar nuestros cambios y guardarlos con un Commit en nuestra copia local
4. Push: publicar nuestros cambios al repositorio clonado de GitHub
5. Hacer Pull-Request para solicitar incorporar nuestros cambios desde nuestro fork — bifurcación — al repositorio original
6. Y si todo va bien se hará un Merge — fusión o incorporación — con nuestros cambios en el repositorio original
¡Todo esto es genial y funciona bien!
Y si queremos realizar una segunda colaboración justo después de llevar a cabo un Merge , es necesario que primero realicemos un Fetch upstream en nuestro repositorio clonado para que tengamos disponibles los cambios actualizados que incorporamos al repositorio original a través del Pull Request.
Los más frikies de git lo hacen muy fácilmente, pero muchos terminamos simplemente por eliminar nuestro primer fork y crear otro nuevo.
Viajar en el tiempo es como visitar París. No puedes simplemente leer la guía, tienes que arrojarte. Come la comida, usa los verbos equivocados, recibe el doble de cargos y terminas besando a completos desconocidos.
El Doctor
Vamos ahora a viajar por el tiempo, osea, vamos a ver fechas futuras y pasadas y como calcularlas en diferentes formatos. La TARDIS no espera, ponte a los mandos y sujétate fuerte.
Estos días he estado trabajando con la excelente y nueva funcionalidad: LOAD DATA. Con este artículo me gustaría compartir mis primeras experiencias con todos. Los siguientes puntos no contienen ningún orden ni ningún otro análsis. Son solo cosas que observé al utilizar el comando LOAD DATA. Y se debe tener en cuenta que estos puntos se basan en la versión 2021.2.0.617 de IRIS, que es una versión de prueba.
¿Sabéis cómo crear una solución de analítica de datos con InterSystems IRIS?
Para empezar, pongámonos de acuerdo sobre lo que es una solución de analítica de datos - este podría ser un tema muy amplio -. Por ello, acotaremos el conjunto de soluciones que se podían presentar al Concurso de Analítica de Datos.
Y a continuación examinaremos tres tipos de soluciones para analítica de datos: de monitorización, de análisis interactivo y de elaboración de informes (reporting).
Hoy quiero hablar sobre nuestro proyecto y utilizar el tema del conjunto de datos para el concurso.
Nuestra intención nunca fue ser unos gestores de datos, sobre todo porque a veces nuestros preciosos datos significan mucho para nosotros, pero no para el resto del mundo.
Queremos ir un paso más allá y permitir que los usuarios encuentren el conjunto de datos perfecto para satisfacer sus necesidades.
Nuestro proyecto es un puente entre la comunidad de la Ciencia de Datos y la Comunidad de Desarrolladores, utilizando InterSystems IRIS para lograr esta misión.
Quiero compartir con vosotros mi primera aplicación del Open Exchange.
Es una herramienta para hacernos los desarrollos mas fáciles. Es un microservicio con IRIS en un docker que nos ayuda en los desarrollos de campañas de SMS, Mail y en los links para las tiendas de nuestras apps brindándonos un acortador de Url's.
La Inteligencia Artificial (IA) está recibiendo mucha atención últimamente porque puede cambiar muchos aspectos de nuestras vidas. Una mayor potencia informática y más datos han ayudado a la IA a hacer cosas asombrosas, como mejorar las pruebas médicas y fabricar coches que se conducen solos. La IA también puede ayudar a las empresas a tomar mejores decisiones y a trabajar de forma más eficiente, por lo que cada vez es más popular y se utiliza más. ¿Cómo se pueden integrar las llamadas a la API OpenAI en una aplicación de interoperabilidad IRIS existente?
En este artículo te voy a contar mi experiencia y conocimientos en el poco tiempo que llevo utilizando los distintos productos de InterSystems.
A parte de contar mis vivencias también veremos como hacer una pequeña API Rest con la que poder hacer un CRUD con la base de datos SQL de InterSystems.
¡Hola a todos los estimados miembros de la comunidad de desarrolladores de InterSystems en español!
Aunque suelo consultar la comunidad de desarrolladores y alguna vez he dejado alguna pregunta por aquí, este será mi primer artículo y qué mejor ocasión para hacerlo que participando en el 3er concurso de artículos técnicos.
Encontrar errores en tu código o examinar un comportamiento inesperado es el principal objetivo de la depuración.
Trataré de actualizar las herramientas tradicionales aparte de las ayudas que tienen Studio, VScode, Serenji... Las herramientas básicas que han estado ahí antes de que tu EDI preferido lo utilizara en segundo plano.
OData (Open Data Protocol) es un estándar OASIS, con certificación ISO/IEC, que define un conjunto de prácticas recomendadas para construir y consumir APIs RESTful. OData te ayuda a enfocarte en tu lógica de negocio mientras construyes APIs RESTful, sin tener que preocuparte por los diversos enfoques para definir cabeceras de solicitud y respuesta, códigos de estado, métodos HTTP, convenciones URL, tipos de medios audiovisuales, formatos de carga, opciones de consulta, etc. OData también proporciona orientación para registrar cambios, definir funciones/acciones para llevar a cabo procedimientos reutilizables y enviar solicitudes asíncronas/por lotes (Fuente: OData.org).
FHIR ha revolucionado la industria de la atención médica al proporcionar un modelo de datos estandarizado para crear aplicaciones y promocionar el intercambio de datos entre diferentes sistemas. El estándar FHIR se basa en enfoques modernos impulsados por APIs, lo que lo hace más accesible para los desarrolladores web y móviles. Sin embargo, interactuar con las API de FHIR aún puede ser un desafío, especialmente cuando se trata de consultar datos usando lenguaje natural.
El desarrollo frontend puede ser una tarea desalentadora, incluso una pesadilla, para los desarrolladores centrados en el backend. Al principio de mi carrera, la línea entre frontend y backend era difusa, y se esperaba que todos manejaran ambos. El CSS, en particular, siempre fue una lucha constante; sentía que era una misión imposible.
@José Pereiray yo hemos creado un proyecto del que queremos hablar en este artículo.
¿Qué es IRIS RAD Studio?
IRIS RAD Studio es nuestra idea de una solución low-code para hacer más fácil la vida del desarrollador.
¿Por qué?
¿Y por qué no? Las aplicaciones low-code se han hecho muy populares últimamente. La imagen de abajo muestra el "Cuadrante mágico" ofrecido por la consultora Gartner para plataformas de aplicaciones low-code empresariales, y que muestra lo interesante que es este mercado.
IRIS Interoperability, antes conocida como Ensemble, viene con muchos adaptadores integrados. No tiene un servicio o un adaptador para recibir correo. He escrito un servicio de correo electrónico para recibir mensajes de correo a través de SMTP que se pueden pasar a la operación de correo electrónico.
 Siempre
Siempre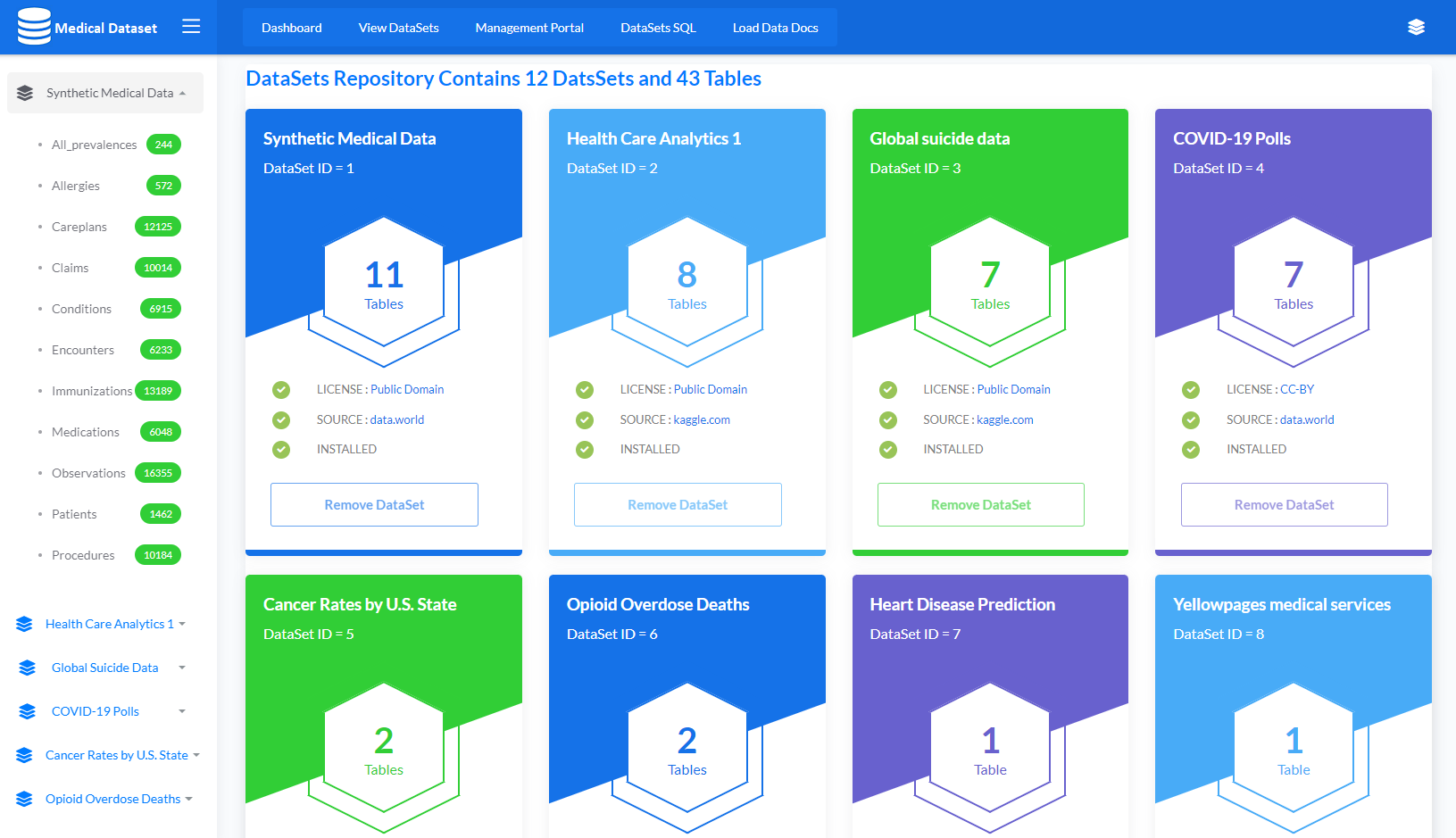
 Open Exchange app
Open Exchange app





.png)
.png)

.png)