 Por visualizaciones
Por visualizacionesInterSystems IRIS es una gran plataforma de datos y posee las funcionalidades que demanda el mercado. En este artículo, recojo las 10 mejores:

InterSystems IRIS es una Plataforma completa de datos.
InterSystems IRIS le proporciona todo lo que necesita para capturar, compartir, comprender y actuar sobre el activo más valioso de su organización, sus datos.
Dado que es una plataforma completa, InterSystems IRIS elimina la necesidad de integrar varias tecnologías de desarrollo. Las aplicaciones necesitan una menor cantidad de código, menos recursos del sistema y poco mantenimiento.
 Open Exchange app
Open Exchange app
 ) .
) ..gif)
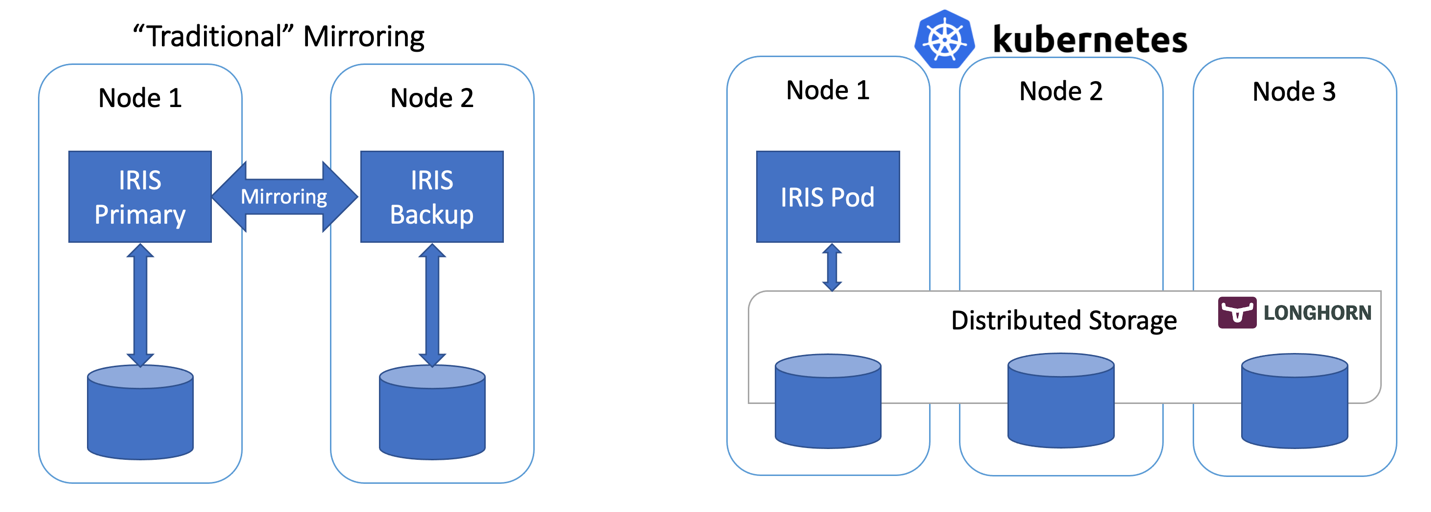
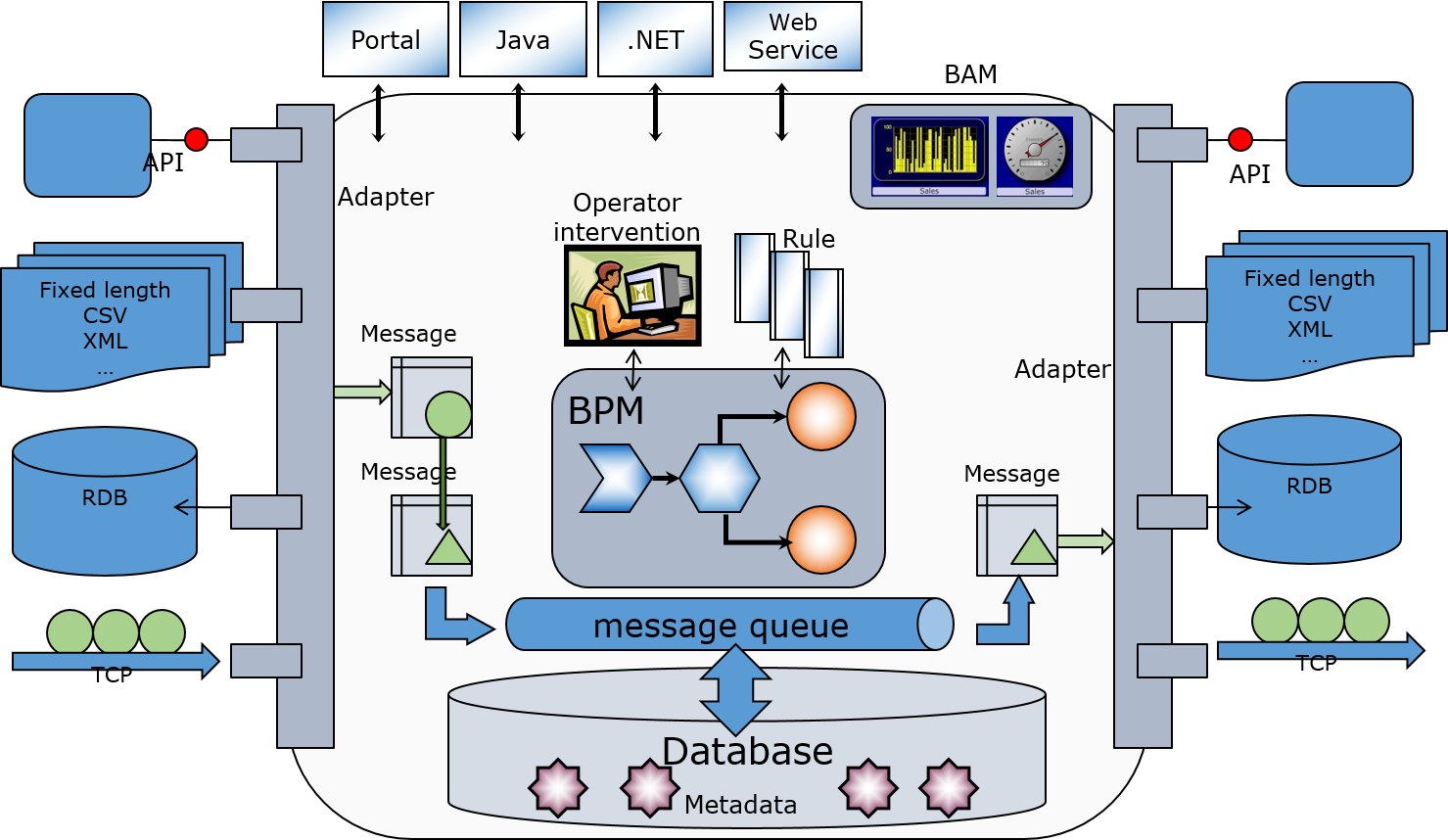

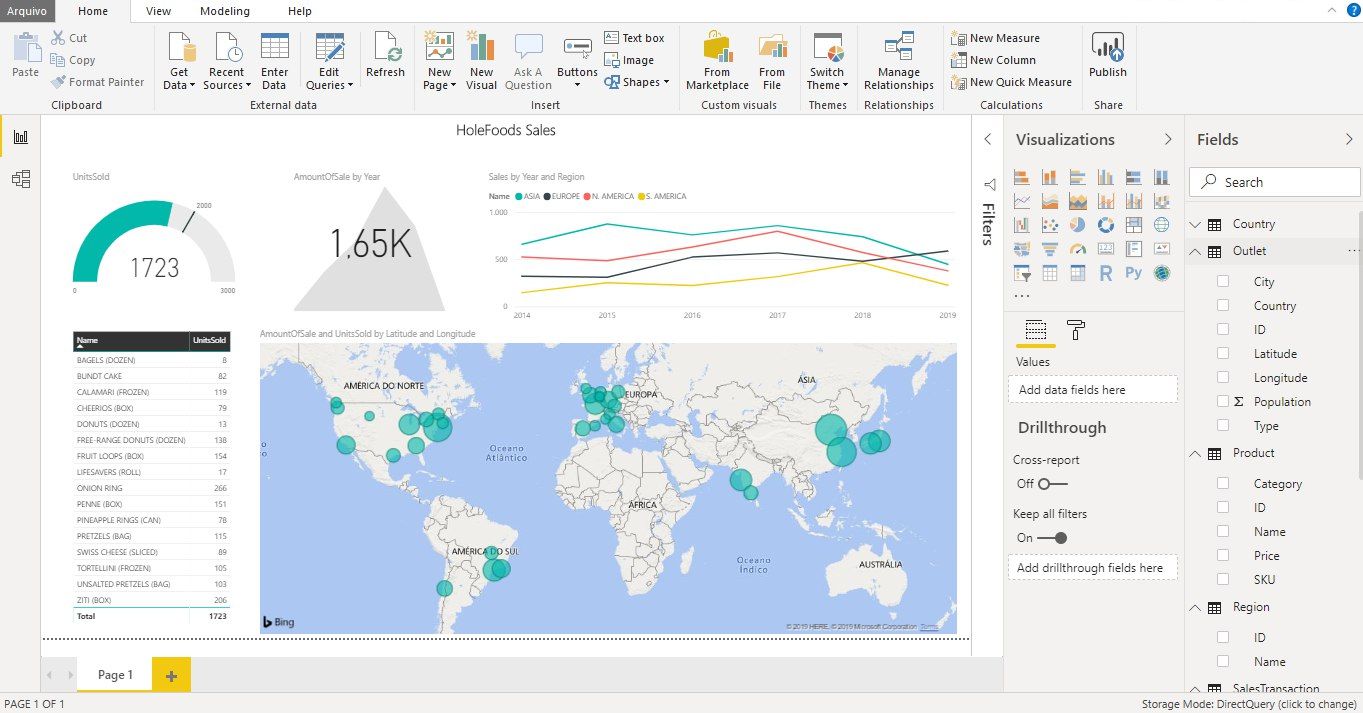
.png)
- primero
- ‹ anterior
- 1
- 2
- 3
- 4
- 5
- …
- siguiente ›
- último