Limpiar filtro
Artículo
Carlos Castro · 28 feb, 2023
Buenas a todos,
una de las herramientas potentes que tiene Intersystems es la posibilidad de implementar en el propio sistema la autenticación OAuth2. Esta herramienta nos da la posibilidad de poder controlar quien accede a nuestros recursos y como accede.
A continuación planteo una solución ante el problema de querer controlar quien accede a mis recursos y la posibilidad de monitorizarlo. Para ello deberemos seguir los siguientes pasos:1.- Definir un Servidor de Autenticacion
1.1.- Crear Servidor
1.2.- Crear Cliente del Servidor
1.3.- Crear Servidor de Recursos
1.4.- Crear cliente de Servidor de Recursos
2.- Definir un servicio SOPA/REST para acceder a los recursos.
2.1.- Crear Servicio
2.2.- Validar Acceso desde el servicio
** Os intentaré ir dejando capturas del portal de gestión para situaros mejor en el proceso. Si lo seguís secuencialmente no deberíais tener problema para completar el proceso.
Teniendo claros los pasos a seguir, ¡COMENCEMOS!
Presentación del Problema:
Supongamos que tenemos un Servicio que accede a unos recursos determinados. La publicación de este servicio es accesible por todo aquel cliente que ataque el servicio, y deseamos controlar quien accede a estos recursos, pues no queremos que todo el mundo acceda a los recursos, ademas que tampoco queremos que los clientes autorizados para acceder a los mismos puedan acceder a los recursos de otros que también tengan permisos, por lo que vamos a ponerle un "portero" al servicio para que nos asegure que este cliente tiene autorizado acceder a nuestros recursos.
Para solucionar este problema de forma ágil, haremos uso del servidor de autenticación OAuth2 que podemos utilizar en IRIS siguiendo los siguientes pasos:
1.1.- Crear Servidor
En la Producción Web seleccionamos Administración>seguridad>oauth2.0>servidor y deberíamos observar:
A continuación, necesitamos escribir en el formulario:
URL: DNS o IP del Servidor donde se va a alojar el Servidor de Autorización
Puerto: Puerto interno del Servidor Web [p.e: 57773]
El puerto del Apache interno es el que se debe utilizar, seguramente sea necesario habilitar el acceso a estos puertos con edición del fichero httpd.conf
Prefijo: Indicar la aplicación donde se va a alojar el Servidor de Autorización. De forma automática se crea la aplicación al guardar el servidor. [p.e: oauth2]
Tipos de concesiones: deja solo credenciales de cliente
Configuración SSL/TLS: Certificado SSL que tengamos
En la segunda pestaña, nombrada como “Ámbitos” define my/scope así:
Ámbito | my/scope | Introducir ámbito compatible: my/scopeDescripción | First Scope | Introducir descripción del ámbito: First Scope
Además, en la 5ª pestaña, “Personalización”; hay que configurar el cuarto valor:
Generar clase de token: %OAuth2.Server.JWT
Guardar y ya deberíamos ver que se ha creado.
En este punto, tenemos el servidor creado.
1.2.- Crear Cliente del Servidor
Estando en la pantalla de: Administración>seguridad>oauth2.0>servidor; pulsar en el botón “Descripciones de cliente”.
Esto nos permitirá indicar qué clientes pudieran autorizarse en nuestro servidor. En concreto nos creamos uno de ejemplo:
Nombre
cliente desde postman
Identificador del Cliente a nivel local.
ID del cliente
HbOAGs6byL-gTlabW8gCDguQnYyHCWT82EToGTjP5fQ
Valor del ID del Cliente.
Tipo de cliente
confidential
URL de redireccionamiento
https://DNS/IP:57773
DNS y Puerto del Servidor de Autorización configurados en el apartado 2.1
Descripción
cliente servidor de autenticación
Descripción del Cliente.
Al guardarlo deberíamos observar:
Llegados aquí, ya disponemos de un servidor de autenticación con un cliente. El proceso ahora consiste en obtener el token de acceso del servidor en base a las credenciales de acceso que acabamos de crear. Una vez obtenemos este token, deberemos validarlo al intentar acceder a los recursos.
Procedimiento para obtener el token:A) Atacar por REST a: https://DNS/IP:57773/oauth2/token?grant_type=client_credentials&scope=my/scope
con datos:
Authorizacion= Basic OAuth
Username= clientID (obtenido de la definición del cliente creada en el paso 1.2)
Password=SecretID (obtenido de la definición del cliente creada en el paso 1.2)
Esta petición nos devolverá un TOKEN de acceso que tendremos que validar a continuación.
1.3.- Crear Servidor de Recursos
En Sistema > Gestión de seguridad > Cliente de OAuth 2.0 > Descripción del servidor - (Configuración de seguridad)
1.4.- Crear cliente de Servidor de Recursos
Con el objetivo de definir a qué información se accede una vez el Sistema Externo se ha validado, se construye el “Servidor de Recursos”.
Para generar el Servidor de Recursos, debemos estar en: Sistema > Gestión de seguridad > Configuración del servidor de autorización OAuth 2.0 > Servidor de OAuth 2.0 y pulsar en el botón “Crear la descripción de cliente” tal y como se muestra en la siguiente captura:
NOMBRE: resserver
Descripción: [Texto descriptivo]
Tipo de cliente: Servidor de recursos
Tipo de concesiones: Código de autorización
Tipo de concesiones compatibles: código
Tipo de autenticación: básico
Llegados a este punto, Ya hemos definido un servidor de autenticación y un servidor de recursos, ¡Vamos a unirlo todo!
A continuación debemos incluir en nuestro servicio SOAP o REST el control para validar el token generado por el servidor de autenticación, para ello incluiremos en nuestro servicio lo siguiente:
Parameter OAUTH2APPNAME = "resserver";
Parameter OAUTH2SCOPES = "openid profile email my/scope";
Dentro del método del servicio al principio:
set authorization = $tr(pInput.GetAttribute("authorization"),"")set tokenSinBearer = $PIECE(authorization,"Bearer ",2)
set tSC= ..ResServer(tokenSinBearer)
Método:
ClassMethod ResServer(accessToken As %String(MAXLEN="")) As %Status{ // validate token set isJWTValid = ##class(%SYS.OAuth2.Validation).ValidateJWT("resserver",accessToken,"","",.jwtPayload ,.securityParameters,.sc) if (('isJWTValid) || ($$$ISERR(sc))) { quit '$$$OK } // introspection set sc = ##class(%SYS.OAuth2.AccessToken).GetIntrospection("resserver", accessToken, .jsonObject) if $$$ISERR(sc) { quit '$$$OK } quit $$$OK}
Con este método lo que vamos a realizar es la validación del token recibido en el servicio contra el servidor de autenticación. La respuesta tSC es la que deberemos validar para dar acceso o no al resto de recursos a los que accede el servicio, de una forma esquematizada sería: Method misRecursos(pInput As %Stream.Object, Output pOutput As %Stream.Object) As %Status
{
set authorization = $tr(pInput.GetAttribute("authorization"),"")set tokenSinBearer = $PIECE(authorization,"Bearer ",2)
set tSC= ..ResServer(tokenSinBearer)
if (tSC= 1){
ACCESO A LOS RECURSOS
quit pOutput
}else{
quit '$$$OK
}
}
En resumidas cuentas, el servidor de autenticación OAUTH2 nos sirve para generar un token en base al clientID y secretID que hemos generado al crear el cliente para el mismo Servidor OUATH2. Este Token seguidamente lo enviaremos al servidor de recursos que previo al acceso de los mismos, validara este token contra el servidor de autenticación, y si es correcto, nos dará acceso a los mismos.
El proceso completo os lo dejo aquí indicado:
Finalmente si quisiéramos aplicar algún control extra, lo podemos realizar dentro del Business Process incluyéndole en el control la información de clientID que queramos monitorizar y/o validar.
Pregunta
Yone Moreno · 17 abr, 2023
Buenas tardes,
Antes que nada, muchísimas gracias por leer esta duda, y sobre todo por dedicar tiempo en entenderla y en responderla. Gracias.
Por favor, necesitaríamos su ayuda. Actualmente estamos desarrollando una Integración REST, y se nos da un caso que nos gustaría comentar con ustedes, a fin de hallar pistas, documentación, ejemplos, o mecanismos para gestionarlo y depurarlo.
En la Operación REST recibimos:
[{"codigo":"5128","descripcion":"LAS ENFERMERAS FRENTE A LOS PROBLEMAS DE SALUD MENTAL","programa":"Probabilidad de contagio ante un accidente hemático.","admitido":1,"desdefecha":"26/10/2022","hastafecha":"26/10/2029","cursohorario":[{"aula":"AULA 1","desdefecha":"2022/12/26","hastafecha":"2022/12/26","desdehora":"16:00:00","hastahora":"20:30:00"},{"aula":"AULA 2","desdefecha":"27/10/2022","hastafecha":"27/12/2022","desdehora":"10:00:00","hastahora":"12:45:00"}],"error":null},{"codigo":"5129","descripcion":"HISTORIA DE SALUD ELECTRONICA DRAGO-AP","programa":"XXXX","admitido":0,"desdefecha":"15/01/2022","hastafecha":"15/01/2029","cursohorario":[{"aula":"AULA MAGNA","desdefecha":"15/01/2022","hastafecha":"15/01/2022","desdehora":"16:00:00","hastahora":"20:30:00"}],"error":null}]
E ingenuamente transformamos el String a objeto Mensaje Response mediante:
// se transforma el objeto JSON a un objeto local
set claseAux = ##class(%ZEN.Auxiliary.jsonProvider).%New()
set tSC= claseAux.%ConvertJSONToObject(.linea,"Mensajes.Response.miFormacion.GetCursosAdmitidosResponse",.pResponse,1)
Lo cual implica Excepción:
Id.:
273670753
Tipo:
Error
Texto:
ERROR #5002: Error de cache: <LIST>%GetSerial+1^%Library.ListOfObjects.1
Registrado:
2023-04-17 14:04:55.913
Origen:
Operaciones.REST.miFormacionv01r00
Sesión:
19206868
Job:
423529
Clase:
Ens.MessageHeader
Método:
NewResponseMessage
Seguimiento paso a paso:
(ninguno)
Pila:
$$^%GetSerial+1^%Library.ListOfObjects.1 +4
$$^%SerializeObject+2^%Library.ListOfObjects.1 +1
$$^%GetSwizzleObject+13^%Library.ListOfObjects.1 +9
$$^zNewResponseMessage+5^Ens.MessageHeader.1 +1
$$^zMessageHeaderHandler+208^Operaciones.REST.miFormacionv01r00.1 +1
$$^zOnTask+42^Ens.Host.1 +1
DO^zStart+62^Ens.Job.1 +2
Para recapitular, el Sistema Destino nos responde con esta String; la cual sí es un JSON válido tal y como se puede comrpobar en https://jsonlint.com/
[
{
"codigo": "5128",
"descripcion": "LAS ENFERMERAS FRENTE A LOS PROBLEMAS DE SALUD MENTAL",
"programa": "Probabilidad de contagio ante un accidente hemático.",
"admitido": 1,
"desdefecha": "26/10/2022",
"hastafecha": "26/10/2029",
"cursohorario": [
{
"aula": "AULA 1",
"desdefecha": "2022/12/26",
"hastafecha": "2022/12/26",
"desdehora": "16:00:00",
"hastahora": "20:30:00"
},
{
"aula": "AULA 2",
"desdefecha": "27/10/2022",
"hastafecha": "27/12/2022",
"desdehora": "10:00:00",
"hastahora": "12:45:00"
}
],
"error": null
},
{
"codigo": "5129",
"descripcion": "HISTORIA DE SALUD ELECTRONICA DRAGO-AP",
"programa": "XXXX",
"admitido": 0,
"desdefecha": "15/01/2022",
"hastafecha": "15/01/2029",
"cursohorario": [
{
"aula": "AULA MAGNA",
"desdefecha": "15/01/2022",
"hastafecha": "15/01/2022",
"desdehora": "16:00:00",
"hastahora": "20:30:00"
}
],
"error": null
}
]
Siendo nuestros Mensaje Response:
Class Mensajes.Response.miFormacion.GetCursosAdmitidosResponse Extends Ens.Response
{
Property cursos As list Of EsquemasDatos.miFormacion.CursoAdmitido;
Y el EsquemasDatos interno:
Class EsquemasDatos.miFormacion.CursoAdmitido Extends Ens.Response
{
Property codigo As %String(MAXLEN = "");
Property descripcion As %String(MAXLEN = "");
Property programa As %String(MAXLEN = "");
Property admitido As %Boolean;
Property desdefecha As %String(MAXLEN = "");
Property hastafecha As %String(MAXLEN = "");
Property cursohorario As list Of EsquemasDatos.miFormacion.CursoHorario;
Property error As EsquemasDatos.Seguridad.Error;
¿De qué manera nos aconsejan depurar, documentarnos, buscar la causa de la Excepción?
Para tratar de resolverlo por nosotros mismos hemos considerado utilizar alguna herramienta para convertir el objeto JSON en un objeto que podamos manipular en nuestro código. Por ejemplo, en lugar de utilizar la clase %ZEN.Auxiliary.jsonProvider, podríamos utilizar la clase %Object, que es una clase básica de InterSystems IRIS que permite trabajar con objetos de forma dinámica. El código es:
Set pResponse = {} // Creamos un objeto vacío
Set tSC = pResponse.%FromJSON(linea) // Convertimos la respuesta JSON en un objeto
If $$$ISERR(tSC) {
Write "Error al convertir respuesta JSON: ", tSC.GetErrorText(), !
Quit
}
$$$LOGINFO("pResponse: "_pResponse)
Sin embargo de esta forma, sí es verdad que el LOGINFO pinta que disponemos de:
Info
2023-04-17 15:10:46.749
pResponse: 8@%Library.DynamicObject
Ahora bien, en el visor de mensaje se nos ve en azul:
¿De qué manera nos aconsejan depurar, documentarnos, buscar la causa de la Excepción?
¿Pudiera ser que la respuesta JSON de Sistema Destino, no coincida con la definición interna hecha a mano del Mensaje Response y el EsquemasDatos?
Lo pregunto porque: la excepción que se muestra parece indicar que hay un problema al serializar la lista de objetos en Cache ObjectScript. Para depurar este problema, es posible que necesite verificar si la definición de clase de "Mensajes.Response.miFormacion.GetCursosAdmitidosResponse" coincide con el formato del objeto JSON devuelto por el servicio REST. Lo cual en teoría puede hacerse comparando la definición de clase con el objeto JSON.
➕🔎🔍Además hemos indagado:
https://community.intersystems.com/post/convert-string-json
https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GJSON_INTRO
https://community.intersystems.com/post/how-convert-xml-string-json-object-script
¿De qué manera nos aconsejan depurar, documentarnos, buscar la causa de la Excepción?
Muchísimas gracias por su ayuda. Y muchas gracias por respondernos con pasos a seguir, documentación y/o ejemplos. Gracias porque es un alivio contar con el apoyo de ustedes que tienen gran cantidad de práctica, experiencia y conocimientos valiosísimos y muy únicos.
Un saludo. Buenas Yone. Sospecho que quizás el problema pueda estar en la definición del objeto GetCursosAdmitidosResponse, según su definición tiene una propiedad cursos:
Property cursos As list Of EsquemasDatos.miFormacion.CursoAdmitido;
Pero lo que enviais para hacer el mapeo de json al objeto comienza así:
[
{
"codigo": "5128",
"descripcion": "LAS ENFERMERAS FRENTE A LOS PROBLEMAS DE SALUD MENTAL",
"programa": "Probabilidad de contagio ante un accidente hemático.",
"admitido": 1,
"desdefecha": "26/10/2022",
"hastafecha": "26/10/2029",
"cursohorario": [
{
"aula": "AULA 1",
Cuando debiera ser:
"cursos": [
{
"codigo": "5128",
"descripcion": "LAS ENFERMERAS FRENTE A LOS PROBLEMAS DE SALUD MENTAL",
"programa": "Probabilidad de contagio ante un accidente hemático.",
"admitido": 1,
"desdefecha": "26/10/2022",
"hastafecha": "26/10/2029",
"cursohorario": [
{
"aula": "AULA 1",
Yo probaría modificando el JSON que estáis enviado para ver si es ese el problema. ¡Hola Yone! ¿Funcionó la solución propuesta?
Artículo
Alberto Fuentes · 24 mayo, 2019
Al igual que con Pattern Matching, se pueden utilizar Expresiones Regulares para identificar patrones en textos en ObjectScript, sólo que con una potencia mucho mayor.
En este artículo se proporciona una breve introducción sobre las Expresiones Regulares y lo que puede hacerse con ellas en ObjectScript. La información que se proporciona aquí se basa en varias fuentes, entre las que destaca el libro “Mastering Regular Expressions” (Dominando las expresiones regulares) escrito por Jeffrey Friedl y, por supuesto, la documentación online de la plataforma. El procesamiento de textos utiliza patrones que algunas veces pueden ser complejos. Cuando utilizamos expresiones regulares, normalmente tenemos varias estructuras: el texto en el que buscamos los patrones, el patrón en sí mismo (la expresión regular) y las coincidencias (las partes del texto que coinciden con el patrón). Para que sea más sencillo distinguir entre estas estructuras, se utilizan las siguientes convenciones a lo largo de este documento:
Los ejemplos en el texto se muestran en monospace y sin comillas adicionales:
Esta es una "cadena de texto" en la cual deseamos encontrar "algo".
A menos que sean evidentes, las expresiones regulares que estén dentro del texto principal se visualizan en un fondo gris, como en el siguiente ejemplo: \".*?\".
Cuando sea necesario, las coincidencias se resaltarán mediante colores diferentes:
Esta es una "cadena de texto" en la cual deseamos encontrar "algo".
Los ejemplos de códigos que sean más grandes se mostrarán en cuadros:
set t="Esta es una ""cadena de texto"" en la cual queremos encontrar ""algo""."set r="\"".*?\"""w $locate(t,r,,,tMatch)
1. Un poco de historia (y algunas curiosidades)
A principios de los años 40, los neurofisiólogos desarrollaron modelos para representar el sistema nervioso de los humanos. Unos años después, un matemático describió estos modelos mediante expresiones algebraicas que a las que llamó “conjuntos regulares”. La notación que se utilizó en estas expresiones algebraicas se denominó “expresiones regulares”.
En 1965, las expresiones regulares se mencionaron por primera vez en el contexto de la informática. Con qed, un editor que formó parte del sistema operativo UNIX, el uso de las expresiones regulares se extendió. Las siguientes versiones de ese editor proporcionan secuencias de comandos g/expresiones regulares/p (global, expresión regular, imprimir), las cuales realizan búsquedas de coincidencias de las expresiones regulares en todas las líneas del texto y muestran los resultados. Estas secuencias de comandos se convirtieron finalmente en la utilidad grep.
Hoy en día, existen varias implementaciones de expresiones regulares (RegEx) para muchos lenguajes de programación.
2. Regex 101
En esta sección se describen los componentes de las expresiones regulares, su evaluación y algunos de los motores disponibles. Los detalles de cómo utilizarlos se describen en la sección 4.
2.1. Componentes de las expresiones regulares
2.1.1. Metacaracteres
Los siguientes caracteres tienen un significado especial en las expresiones regulares.
. * + ? ( ) [ ] \ ^ $ |
Para utilizarlos como valores literales, deben utilizarse utilizando la contrabarra \. También pueden definirse explícitamente secuencias de valores literales utilizando \Q <literal sequence> \E.
2.1.2. Valores literales
El texto normal y caracteres de escape se tratan como valores literales, por ejemplo:
abc
abc
\f
salto de página
\n
salto de línea
\r
retorno de carro
\r
tabulación
\0+tres dígitos (por ejemplo,\0101)
Número octal.El motor de RegEx que utiliza Caché / IRIS (ICU), es compatible con los números octales hasta el \0377 (255 en el sistema decimal). Al migrar expresiones regulares desde otro motor hay que considerar cómo procesa los octales dicho motor.
\x+dos dígitos (por ejemplo, \x41)
Número hexadecimal.La biblioteca ICU cuenta con varias opciones para procesar los números hexadecimales, consulte los documentos de apoyo sobre ICU (los enlaces están disponibles en la sección 5.8)
2.1.3. Anclas
Las anclas (anchors) permiten encontrar ciertos puntos en un texto/cadena, por ejemplo:
\A Inicio de la cadena
\Z Final de la cadena
^ Inicio del texto o línea
$ Final de un texto o línea
\b Límite de palabras
\B No en un límite de palabras
\< Inicio de una palabra
\> Final de una palabra
Algunos motores de regex se comportan de forma diferente, por ejemplo, al definir lo que constituye exactamente una palabra y cuáles caracteres se consideran delimitadores de palabras.
2.1.4. Cuantificadores
Con los cuantificadores, puede definir qué tan frecuentemente el elemento anterior puede crear una coincidencia:
{x} exactamente x número de veces
{x,y} mínimo x, máximo y número de veces
* 0 ó más, es equivalente a {0,}
+ 1 ó más, es equivalente a {1,}
? 0 ó 1
Codicia
Se dice que los cuantificadores son “codiciosos” (greedy), ya que toman tantos caracteres como sea posible. Supongamos que tenemos la siguiente cadena de texto y queremos encontrar el texto que está entre las comillas:
Este es "un texto" con "cuatro comillas".
Debido a la naturaleza codiciosa de los selectores, la expresión regular \".*\" encontrará demasiado texto:
Este es "un texto" con "cuatro comillas".
En este ejemplo, la expresión regular .* pretende incluir tantos caracteres que se encuentren entre comillas como sea posible. Sin embargo, debido a la presencia del selector punto ( . ) también buscará las comillas, de modo que no obtendremos el resultado que deseamos.
Con algunos motores de regex (incluyendo el que utiliza Caché / IRIS) se puede controlar la codicia de los cuantificadores, al incluir un signo de interrogación en ellos. Entonces, la expresión regular \".*?\" ahora hace que coincidan las dos partes del texto que se encuentran entre las comillas, es decir, exactamente lo que buscábamos:
Este es "un texto" con "cuatro comillas".
2.1.5. Clases de caracteres (rangos)
Los corchetes se utilizan para definir los rangos o conjuntos de caracteres, por ejemplo, [a-zA-Z0-9] o [abcd] . En el lenguaje de las expresiones regulares esta notación se refiere a una clase de caracteres. Un rango coincide con los caracteres individuales, de modo que el orden de los caracteres dentro de la definición del rango no es importante: [dbac] devuelve tantas coincidencias como [abcd].
Para excluir un rango de caracteres, simplemente se coloca el símbolo ^ frente a la definición del rango (¡dentro de los corchetes!): [^abc] buscará todas las coincidencias excepto con a, b o c.
Algunos motores de regex proporcionan clases de caracteres previamente definidas (POSIX), por ejemplo:
[:alnum:] [a-zA-z0-9]
[:alpha:] [a-zA-Z]
[:blank:] [ \t]
…
2.1.6. Grupos
Los componentes de una expresión regular pueden agruparse utilizando un par de paréntesis. Esto resulta útil para aplicar cuantificadores a un grupo de selectores, así como para referirse a los grupos tanto desde las expresiones regulares como desde ObjectScript. Los grupos también pueden anidarse.
Las siguientes coincidencias en las cadenas regex consisten en un número de tres dígitos, seguidos por un guion, a continuación, tres pares de letras mayúsculas y un dígito, seguidas por un guion, y para finalizar el mismo número de tres dígitos como en la primera parte:
([0-9]{3})-([A-Z][[0-9]){3}-\1
El siguiente ejemplo muestra cómo utilizar las referencias previas para que coincidan no solamente la estructura, sino también el contenido: el punto de referencia (en morado) le indica al motor que busque el mismo número de tres dígitos al principio y al final de la cadena (en amarillo). El ejemplo también muestra cómo aplicar un cuantificador a las estructuras más complejas (en verde).
La expresión regular de arriba coincidiría con la siguiente cadena:
123-D1E2F3-123
Pero no coincidiría con las siguientes cadenas:
123-D1E2F3-456 (los últimos tres dígitos son diferentes de los primeros tres)
123-1DE2F3-123 (la parte central no consiste en tres letras/pares de dígitos)
123-D1E2-123 (la parte central incluye únicamente dos letras/pares de dígitos)
Los grupos también puede accederse utilizando los búferes de captura desde ObjectScript ( sección 4.5.1). Esta es una característica muy útil que permite buscar y extraer información al mismo tiempo.
2.1.7. Alternancia
Con el carácter de barra vertical se especifica alternancia entre opciones, por ejemplo, skyfall|done. Esto permite comparar expresiones más complejas, como las clases de caracteres que se describieron en la sección 3.1.5.
2.1.8. Referencias
Los referencias permiten consultar grupos previamente definidos (selectores dentro de los paréntesis). En el siguiente ejemplo se muestra una expresión regular que coincide con tres caracteres consecutivos, los cuales deben ser iguales:
([a-zA-Z])\1\1
Los puntos de referencia se especifican con \x, donde x representa la expresión x-ésima entre paréntesis.
2.1.9. Reglas de precedencia
[] antes de ()
, + y ? antes de una secuencia: ab es equivalente a a(b*), y no a (ab)*
Secuencia antes de una alternancia: ab|c es equivalente a (ab)|c, y no a a(b|c)
2.2. Un poco de teoría
La evaluación de las expresiones regulares, por lo general, se realiza mediante la implementación de alguno de los dos siguientes métodos (las descripciones se han simplificado, en las referencias que se mencionan en el capítulo 5 se pueden encontrar más detalles):
Orientado por el texto (DFA – Autómata finito determinista) El motor de búsqueda avanza a través del texto de entrada, carácter por carácter, e intenta encontrar coincidencias en el texto recorrido hasta el momento. Cuando llega al final del texto que de entrada, declara que el proceso se realizó con éxito.
Orientado por las expresiones regulares (NFA – Autómata finito no determinista) El motor de búsqueda avanza a través de la expresión regular, token por token, e intenta aplicarla al texto. Cuando llega al último token (y encuentra todas las coincidencias), declara que el proceso se realizó con éxito.
El método 1 es determinista, su tiempo de ejecución depende únicamente de la longitud del texto introducido. El orden de los selectores en las expresiones regulares no influye en el tiempo de ejecución.
El método 2 no es determinista, el motor reproduce todas las combinaciones posibles de los selectores en la expresión regular, hasta que encuentre una coincidencia o se produzca algún error. Por ende, este método es particularmente lento cuando no encuentra una coincidencia (debido a que tiene que reproducir todas la combinaciones posibles). El orden de los selectores influye en el tiempo de ejecución. Sin embargo, este método le permite retroceder y capturar los búferes.
2.3. Motores de búsqueda
Existen muchos motores de regex disponibles, algunos ya están incorporados en los lenguajes de programación o en los sistemas operativos, otros son librerías que pueden utilizarse en casi cualquier parte. Aquí se muestran algunos motores de regex, los cuales se agruparon por el tipo de método de evaluación:
DFA: grep, awk, lex
NFA: Perl, Tcl, Python, Emacs, sed, vi, ICU
En la siguiente tabla se realiza una comparación de las características que están disponibles en regex, entre varias bibliotecas y en lenguajes de programación:
Puede encontrar más información aquí: https://en.wikipedia.org/wiki/Comparison_of_regular_expression_engines
3. RegEx y Caché
InterSystems Caché/IRIS utiliza la biblioteca ICU para buscar expresiones regulares, en los documentación online se describen muchas de estas características. El objetivo de las siguientes secciones es hacer una introducción rápida sobre cómo utilizarlas.
3.4. $match() y $locate()
En ObjectScript (COS), las funciones $match() y $locate() brindan acceso directo a la mayoría de las características de regex a las que se tiene acceso desde la biblioteca de ICU. $match(String, Regex) busca en la cadena de entrada un patrón de regex. Cuando la función encuentra una coincidencia devuelve 1, en caso contrario devuelve 0.
Ejemplos:
w $match("baaacd",".*(a)\1\1.*") devuelve 1
w $match("bbaacd",".*(a)\1\1.*") devuelve 0
$locate(String,Regex,Start,End,Value) busca en la cadena de entrada un patrón de regex, del mismo modo que lo hace $match(). Sin embargo, $locate() proporciona mayor control del proceso y también devuelve más información. En Start, se puede indicar a $locate en qué punto de la cadena de entrada debe comenzar la búsqueda. Cuando $locate() encuentra una coincidencia, regresa al punto donde se encuentra el primer carácter de la coincidencia y establece End para la siguiente posición del carácter después de la coincidencia. El contenido de la coincidencia es devuelto en Value.
Si $locate() no encuentra alguna coincidencia devuelve 0 y no tocará los contenidos de End y Value (si se especificaron). End y Value se pasan por referencia, por lo que hay que ser cuidadoso si utilizan continuamente (por ejemplo en bucles).
Ejemplo:
w $locate("abcdexyz",".d.",1,e,x) devuelve 3, e se establece en 6, x se establece en "cde"
$locate() realiza la búsqueda de coincidencias en los patrones y puede devolver el contenido de la primera coincidencia, al mismo tiempo. Si necesita extraer el contenido de todas las coincidencias, puede llamar a $locate() continuamente mediante un bucle o puede utilizar los métodos que se proporcionan en %Regex.Matcher (siguiente sección).
3.5.% Regex.Matcher
%Regex.Matcher proporciona acceso a funciones de regex de la librería ICU del mismo modo que lo hacen las funciones $match() y $locate() pero además cuenta con características avanzadas. En las siguientes secciones se retomará el concepto de los búferes de captura, se analizará la posibilidad de sustituir cadenas con expresiones regulares y las formas para controlar el comportamiento del tiempo de ejecución.
3.5.1. Búferes de captura
Como ya hemos visto con los grupos, las referencias y $locate(), las expresiones regulares le permiten buscar simultáneamente los patrones en el texto y devolver el contenido con las coincidencias. Esto funciona al colocar las partes del patrón que desea extraer entre un par de paréntesis (agrupación). Si la búsqueda de coincidencias es exitosa, los búferes de captura tendrán el contenido de todos los grupos en los que se hayan encontrado coincidencias. Hay que tener en cuenta que este procedimiento es un poco diferente de lo que $locate() proporciona con sus parámetros de valores: $locate() devuelve el contenido de todas la coincidencias en sí, mientras que los búferes de captura le dan acceso a algunas partes de las coincidencias (los grupos).
Para utilizarlo, hay crear un objeto a partir de la clase %Regex.Matcher y pasar la expresión regular y la cadena de entrada. Después, puede llamar a uno de los métodos proporcionados por %Regex.Matcher para que realice el trabajo.
Ejemplo 1 (grupos simples):
set m=##class(%Regex.Matcher).%New("(a|b).*(de)", "abcdeabcde")
w m.Locate() returns 1
w m.Group(1) returns a
w m.Group(2) returns de
Ejemplo 2 (grupos anidados y referencias):
set m=##class(%Regex.Matcher).%New("((a|b).*?(de))(\1)", "abcdeabcde")
w m.Match() returns 1
w m.GroupCount returns 4
w m.Group(1) returns abcde
w m.Group(2) returns a
w m.Group(3) returns de
w m.Group(4) returns abcde
(hay que tener en cuenta el orden de los grupos anidados, porque el paréntesis de apertura marca el inicio de un grupo, los grupos internos tienen un índice numérico mayor que los externos)
Como se mencionó anteriormente, los búferes de captura son una característica muy poderosa, ya que permiten buscar coincidencias en los patrones y extraer el contenido de las coincidencias al mismo tiempo. Sin las expresiones regulares, tendría que buscar las coincidencias como se indica en el paso uno (por ejemplo, utilizando el operador para coincidencias de patrones) y extraer el contenido de las coincidencias (o partes de las mismas) basándose en algunos de los criterios que se indican en el paso dos.
Si necesita agrupar alguna parte de su patrón (por ejemplo, para aplicarle un cuantificador a esa parte), pero no desea rellenar un búfer de captura con el contenido de la parte coincidente, puede definir el grupo como "sin captura" o "pasivo" al colocarle un signo de interrogación seguido de dos puntos adelante del grupo, como en el ejemplo 3, el cual se muestra a continuación.
Ejemplo 3 (grupo pasivo):
set m=##class(%Regex.Matcher).%New("((a|b).*?(?:de))(\1)","abcdeabcde")
w m.Match() returns 1
w m.Group(1) returns abcde
w m.Group(2) returns a
w m.Group(3) returns abcde
w m.Group(4) returns <REGULAR EXPRESSION>zGroupGet+3^%Regex.Matcher.1
3.5.2. Reemplazar
%Regex.Matcher también proporciona métodos para reemplazar rápidamente el contenido de las coincidencias: ReplaceAll() y ReplaceFirst():
set m=##class(%Regex.Matcher).%New(".c.","abcdeabcde")
w m.ReplaceAll("xxxx") returns axxxxeaxxxxe
w m.ReplaceFirst("xxxx") returns axxxxeabcde
También puede referirse a los grupos en sus cadenas de reemplazo. Si añadimos un grupo al patrón del ejemplo anterior, podemos referirnos a su contenido al incluir $1 en la cadena de reemplazo:
set m=##class(%Regex.Matcher).%New(".(c).","abcdeabcde")
w m.ReplaceFirst("xx$1xx") returns axxcxxeabcde
Se puede utilizar $0 para incluir todo el contenido de la coincidencia en la cadena de reemplazo:
w m.ReplaceFirst("xx$0xx") returns axxbcdxxeabcde
3.5.3. La propiedad OperationLimit
En la sección 3.2 hablamos sobre los dos métodos para evaluar una expresión regular (DFA y NFA). El motor regex que se utiliza en Caché es un Autómata finito no determinista (NFA, por sus siglas en inglés). Por lo tanto, el tiempo requerido para evaluar varias expresiones regulares en una determinada cadena de entrada puede variar. [1]
Se puede utilizar la propiedad OperationLimit de un objeto %Regex.Matcher para limitar el número de unidades de ejecución (llamados clusters). El tiempo exacto para la ejecución de un cluster depende del entorno. Por lo general, el tiempo requerido para la ejecución de un cluster es de unos cuantos milisegundos. La propiedad OperationLimit se establece de manera predeterminada en 0 (sin límites).
3.6. Un ejemplo de la vida real: la migración de Perl hacia Caché
Esta sección describe la parte relacionada con regex en un caso de migración de Perl a Caché. En este caso, el script en Perl consiste en docenas de expresiones regulares con mayor o menor complejidad, las cuales se utilizaban tanto para buscar coincidencias como para extraer contenido.
Si no existieran funciones de regex disponibles en Caché, el proyecto de migración implicaría un enorme esfuerzo. Sin embargo, las funciones de regex están disponibles en ObjectScript, y las expresiones regulares de los scripts en Perl pueden utilizarse casi sin realizar modificaciones.
Aquí se muestra una parte del script en Perl:
El único cambio necesario en las expresiones regulares para la migración de Perl hacia Caché fue en el modificador /i- (este provoca que regex no distinga entre las mayúsculas y minúsculas), el cual tuvo que moverse desde el final hacia el principio en las expresiones regulares.
En Perl, el contenido de los búferes de captura se copia en variables especiales ($1 y $2 en el código de Perl que vimos anteriormente). Casi todas las expresiones regulares en el proyecto Perl utilizaban este mecanismo. Para emularlo, se escribió un simple método de encapsulamiento en ObjectScript. Este método utiliza a %Regex.Matcher para evaluar una expresión regular contra una cadena de texto y devuelve el contenido del buffer de captura en forma de una lista ($lb()).
El código correspondiente en ObjectScript es:
if ..RegexMatch(
tVCSFullName,
"(?i)[\\\/]([^\\^\/]+)[\\\/]ProjectDB[\\\/](.+)[\\\/]archives[\\\/]",
.tCaptureBufferList)
{
set tDomainPrefix=$zcvt($lg(tCaptureBufferList,1), "U")
set tDomain=$zcvt($lg(tCaptureBufferList,2), "U")
}
…
Classmethod RegexMatch(pString as %String, pRegex as %String, Output pCaptureBuffer="") {
#Dim tRetVal as %Boolean=0
set m=##class(%Regex.Matcher).%New(pRegex,pString)
while m.Locate() {
set tRetVal=1
fori=1:1:m.GroupCount {
set pCaptureBuffer=pCaptureBuffer_$lb(m.Group(i))
}
}
quit tRetVal
}
4. Información de referencia
4.7. Información general
Información general y tutoriales:
http://www.regular-expressions.info/engine.html
Tutoriales y ejemplos:
http://www.sitepoint.com/demystifying-regex-with-practical-examples/
Comparaciones entre varios motores regex:
https://en.wikipedia.org/wiki/Comparison_of_regular_expression_engines
Hoja de referencia:
https://www.cheatography.com/davechild/cheat-sheets/regular-expressions/pdf/
Libros:
Jeffrey E. F. Friedl: “Mastering Regular Expressions (Dominando las expresiones regulares)” (consulte http://regex.info/book.html)
4.8. Documentación online
Resumen sobre "El uso de las expresiones regulares en Caché": http://docs.intersystems.com/latest/csp/docbook/ DocBook.UI.Page.cls?KEY=GCOS_regexp
Documentación sobre $match(): http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fmatch
Documentación sobre $locate(): http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_flocate
Documentación de la clase %Regex.Matcher: http://docs.intersystems.com/latest/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25Regex.Matcher
4.9. ICU
Como se mencionó anteriormente, InterSystems Caché/IRIS utiliza los motores de ICU. La información completa está disponible en línea:
http://userguide.icu-project.org/strings/regexp
http://userguide.icu-project.org/strings/regexp#TOC-Regular-Expression-Metacharacters
http://userguide.icu-project.org/strings/regexp#TOC-Regular-Expression-Operators
http://userguide.icu-project.org/strings/regexp#TOC-Replacement-Text
http://userguide.icu-project.org/strings/regexp#TOC-Flag-Options
This is excellent as far as my poor Spanish (inherited from Italian) allows.It would be great to see it also in the English version. It's already available in English! https://community.intersystems.com/post/using-regular-expressions-cach%C3%A9This here is our Spanish version of the great article by Michael Brosdorf
Este artículo está etiquetado como "Mejores prácticas" ("Best practices")
(Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).
Artículo
Javier Lorenzo Mesa · 11 mar, 2020
¡Hola a tod@s!
El desarrollo completo en JavaScript (Full-Stack) permite crear aplicaciones de última generación con Caché. En cualquiera de las aplicaciones (web) que se desarrollan hoy en día, hay que tomar muchas decisiones estructurales y debemos saber cuales son las decisiones correctas. Con el conector Node.js disponible para Caché, se puede crear un potente servidor de aplicaciones, que permitirá utilizar la última tecnología de JavaScript y marcos de aplicaciones (frameworks) tanto del lado del cliente como del servidor.
Con todas estas nuevas tecnologías, lo más importante es integrarlas de la manera más eficiente posible y que permitan generar una experiencia de desarrollo muy productiva. Este artículo pretende introducirte paso a paso en la tecnología Node.js.
Antes de empezar a desarrollar aplicaciones con Node.js para Caché, lo primero que hay que hacer es configurar un entorno.
Para utilizar Node.js con Caché, se necesita un módulo (conector) Node.js para Caché.
En cada kit de distribución de Caché, encontrarás diferentes versiones de este módulo en el directorio bin de Caché, los cuales se llaman, por ejemplo: cache0100.node, cache0120.node... Como las versiones de Node.js se actualizan con frecuencia, recomiendo que primero solicites al Centro de Soporte Internacional (WRC) que te envíen la última versión.
Una vez que recibas del WRC el paquete zip con la última versión, verás que hay diferentes números de versión dentro del directorio bin. No es difícil elegir la versión correcta, pero es muy importante saber que estos módulos son nativos y que la plataforma de Caché, el procesador (x86 o x64) y la versión del módulo Node.js deben coincidir con tu sistema. Este es un paso muy importante a tener en cuenta, pues de lo contrario el conector de Node.js no funcionará en tu sistema.
Las versiones de Node.js están disponibles en dos opciones: las "LTS" y las "actuales". Para nuestras aplicaciones, siempre recomiendo utilizar las LTS, ya que son las más adecuadas para usarse con Caché (proporcionan soporte a largo plazo y estabilidad).
* Si deseas conocer todos los detalles sobre las versiones, puedes encontrar un resumen de todas las versiones en la página web de Node.js. Verás que es una lista larga, pero solo necesitas la última versión de LTS (incluso con los principales números de la versión, que actualmente son v6.x.x y v4.x.x). No utilices las versiones principales que tengan números impares, son versiones que no están diseñadas para usarse en programación y se utilizan para introducir y probar las funciones más recientes de JavaScript la versión 8.
Dos ejemplos:
si utilizas Caché 2016.2 ejecutándose en un sistema Windows x64 y quieres utilizar Node.js v6.9.4, necesitarás que el archivo cache610.node esté en el directorio bin\winx64.
si utilizas Caché 2008.2 ejecutándose en un sistema Windows x86 y quieres utilizar Node.js v4.8.2, necesitarás que el archivo cache421.node esté dentro del directorio bin\winx86.
Ahora describiré paso a paso cómo descargar e instalar Node.js en un sistema Windows x64 y conectarlo con Caché.
Primero, se comienza con la descarga del último Node.js LTS release:
La versión actual es la v6.10.2, solo hay que hacer clic en el botón verde para descargarla. Instala esta versión en tu sistema con la configuración predeterminada, asegurándote de que la opción "add to PATH" esté instalada/verificada:
Ahora que has instalado el entorno de ejecución (runtime) en Node.js, se puede verificar si se instaló correctamente al abrir una línea de comandos y verificar la versión del nodo:
Como se puede ver, actualmente tengo instalada la versión Node.js v6.9.1 en mi sistema.
Por cierto, Node.js ahora está instalado dentro de tu sistema de Windows (en la carpeta "Archivos de programa").
En el portal de gestión de Caché, también deben asegurarse de que el %Service_CallIn se encuentra entre tus servicios de seguridad.
Cuando se inicia una nueva aplicación con Node.js, es una práctica habitual crear primero un nuevo directorio para la aplicación. Lo primero que necesitamos crear es una pequeña aplicación/script en Node.js para probar la conexión entre Node.js y Caché. Este es el paso más importante para comprobar, en primer lugar, si nuestra configuración de Node.js funciona bien antes de comenzar con el desarrollo de otros módulos en Node.js.
Crea un directorio vacío para la prueba, por ejemplo C:\Temp\nodetest
Crea un subdirectorio node_modules (C:\Temp\nodetest\node_modules)
Inserta el cache610.node correcto (que se encuentra dentro del directorio bin\winx64 en el archivo del conector Node.js para Caché) dentro del directorio node_modules y cambia su nombre a cache.node. En todas sus aplicaciones Node.js del lado del servidor, siempre es necesario que el conector para Caché cambie de nombre a cache.node, independientemente de la versión de Node.js, el procesador y sistema operativo en el que se esté ejecutando. ¡Esto hará que tus aplicaciones multiplataforma sean independientes de la versión y sistema operativos instalados!
* Cada vez que desarrolles una nueva aplicación del lado del servidor en Node.js, tendrás que añadir este módulo cache.node al directorio node_modules. Simplemente copia la instancia desde tu aplicación de prueba al directorio node_modules, que se encuentra en la nueva aplicación en sus sistemas. Recuerda que si instalas/implementas tus aplicaciones del lado del servidor en/hacia otro sistema, necesitará revisar cuál de las versiones debes instalar en dicho sistema, ya que la versión de Node.js, el procesador del sistema y el sistema operativo pueden ser diferentes!
Ahora, solo tenemos que crear nuestro script de prueba nodeTest.js dentro de C:\Temp\nodetest mediante este código:
// first, load the Cache connector module inside node_modules
let cacheModule = require('cache');
// instantiate a Cache connector object in JavaScript
let db = new cacheModule.Cache();
console.log('Caché database object instance: ', db);
// Open the connection to the Caché database (adjust parameters for your Cache system):
let ok = db.open({
path: 'C:\\InterSystems\\Cache\\Mgr',
username: '_SYSTEM',
password: 'SYS',
namespace: 'USER'
});
console.log('Open result: ', ok);
console.log('Version: ', db.version());
let d = new Date();
// construct a JavaScript global node object to set a test global in the USER namespace
let node = {
global: 'nodeTest',
subscripts: [1],
data: 'At ' + d.toUTCString() + ': global set from Node.js'
};
// set the global in the database
db.set(node);
// retrieve the global contents back from Cache
let result = db.get(node);
// show it on the console
console.log('Set global ^nodeTest(1) result: ', result);
// close the database connection
db.close();
Si guardas este script e instalas todo correctamente, este código debería funcionar inmediatamente cuando lo llames dentro de una línea de comandos:
¡Enhorabuena! Ya has probado tu servidor para aplicaciones Node.js y lo has conectado con éxito a tu base de datos en Caché.
Con el script de prueba te darás cuenta de que el módulo cache.node contiene toda la funcionalidad que necesitas para acceder a tus datos en Caché (¡no solo los globales, también las funciones, las clases y el SQL!). Encontrarás toda la documentación sobre el módulo Node.js para Caché en los documentos disponibles online en Using Node.js with Caché. Dentro del archivo zip que te proporcione el WRC, también encontrarás un archivo PDF en el directorio de los documentos con todos los detalles sobre las funciones.
También te darás cuenta de que cuando comiences a programar con el módulo Node.js para Caché , este te proporcionará funciones de nivel inferior para acceder a Caché.
En el siguiente artículo, mostraré cómo se pueden utilizar algunos módulos de Node.js para escribir el código fuente de JavaScript, para acceder a sus globales en Caché, las funciones, las clases y las preguntas sobre SQL que utilizan una abstracción funcional de alto nivel.
Artículo
Ricardo Paiva · 14 ene, 2022
Hola desarrolladores,
Escribir un *script* para el despliegue de una aplicación puede ser muy interesante para garantizar un despliegue rápido sin olvidarse de nada.
config-api es una biblioteca para ayudar a los desarrolladores a escribir *scripts* de configuración basados en un documento JSON.
Características implementadas:
* Establecer la configuración del sistema
* Establecer la configuración de seguridad
* Habilitar servicios
* Configurar *namespaces*, bases de datos y mapeos
* Exportar configuración existente
* Todas las funciones están expuestas con una API RESTful
Esta biblioteca se centra en la configuración de IRIS para ayudar a la implementación de aplicaciones. Por lo tanto, config-api no importa/compila la función de código, considerando queesa debería ser la función del módulo de instalación de tu aplicación o el registro del cliente. config-api podría usarse con el cliente ZPM para configurar los ajustes de IRIS en la implementación del módulo; aprenderemos cómo combinar esta biblioteca con ZPM en otro artículo.
## Instalación
```
zpm “install config-api”
```
Si no eres usuario de ZPM, descarga la última versión en formato XML con dependencias [página de publicación](https://github.com/lscalese/iris-config-api/releases/) importación y compilación.
## Primer paso
Vamos a escribir un documento JSON de configuración simple, para establecer algunas configuraciones del sistema.
En este primer documento:
* Habilitamos *journal freeze* en caso de error.
* Establecemos el tamaño límite de *journal* en 256 MB.
* Establecemos SystemMode para desarrollo.
* Aumentamos el `locksiz`.
* Aumentamos el `LockThreshold`.
```
Set config = {
"Journal": { /* Service class Api.Config.Journal */
"FreezeOnError":1,
"FileSizeLimit":256
},
"SQL": { /* Service class Api.Config.SQL */
"LockThreshold" : 2500
},
"config": { /* Service class Api.Config.config */
"locksiz" : 33554432
},
"Startup":{ /* Service class Api.Config.Startup */
"SystemMode" : "DEVELOPMENT"
}
}
Set sc = ##class(Api.Config.Services.Loader).Load(config)
```
### Estructura del documento JSON de configuración
Las claves de primer nivel (`Journal`,`SQL`,`config`,`Startup`) están relacionadas con las clases en el *namespace* %SYS (usando una clase intermedia en el paquete Api.Config.Services). Significa que `Journal` admite todas las propiedades disponibles en [Config.Journal](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&CLASSNAME=Config.Journal), ` SQL`todas las propiedades en [Config.SQL](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&CLASSNAME=Config.SQL), etc...
Salida:
```
2021-03-31 18:31:54 Start load configuration
2021-03-31 18:31:54 {
"Journal":{
"FreezeOnError":1,
"FileSizeLimit":256
},
"SQL":{
"LockThreshold":2500
},
"config":{
"locksiz":33554432
},
"Startup":{
"SystemMode":"DEVELOPMENT"
}
}
2021-03-31 18:31:54 * Journal
2021-03-31 18:31:54 + Update Journal ... OK
2021-03-31 18:31:54 * SQL
2021-03-31 18:31:54 + Update SQL ... OK
2021-03-31 18:31:54 * config
2021-03-31 18:31:54 + Update config ... OK
2021-03-31 18:31:54 * Startup
2021-03-31 18:31:54 + Update Startup ... OK
```
**Truco**: el método `Load` es compatible con un argumento de cadena, en este caso, la cadena debe ser un nombre de archivo para un documento de configuración JSON (también se permite objetos *stream*).
## Crear un entorno de aplicación
En esta sección, escribimos un documento de configuración para crear:
* Un *namespace* "MYAPP"
* 4 bases de datos (MYAPPDATA, MYAPPCODE, MYAPPARCHIVE,MYAPPLOG)
* 1 aplicación web CSP (/csp/zwebapp)
* 1 aplicación web REST (/csp/zrestapp)
* Configuración de mapeo de *globals*
```
Set config = {
"Defaults":{
"DBDIR" : "${MGRDIR}",
"WEBAPPDIR" : "${CSPDIR}",
"DBDATA" : "${DBDIR}myappdata/",
"DBARCHIVE" : "${DBDIR}myapparchive/",
"DBCODE" : "${DBDIR}myappcode/",
"DBLOG" : "${DBDIR}myapplog/"
},
"SYS.Databases":{
"${DBDATA}" : {"ExpansionSize":128},
"${DBARCHIVE}" : {},
"${DBCODE}" : {},
"${DBLOG}" : {}
},
"Databases":{
"MYAPPDATA" : {
"Directory" : "${DBDATA}"
},
"MYAPPCODE" : {
"Directory" : "${DBCODE}"
},
"MYAPPARCHIVE" : {
"Directory" : "${DBARCHIVE}"
},
"MYAPPLOG" : {
"Directory" : "${DBLOG}"
}
},
"Namespaces":{
"MYAPP": {
"Globals":"MYAPPDATA",
"Routines":"MYAPPCODE"
}
},
"Security.Applications": {
"/csp/zrestapp": {
"DispatchClas" : "my.dispatch.class",
"Namespace" : "MYAPP",
"Enabled" : "1",
"AuthEnabled": "64",
"CookiePath" : "/csp/zrestapp/"
},
"/csp/zwebapp": {
"Path": "${WEBAPPDIR}zwebapp/",
"Namespace" : "MYAPP",
"Enabled" : "1",
"AuthEnabled": "64",
"CookiePath" : "/csp/zwebapp/"
}
},
"MapGlobals":{
"MYAPP": [{
"Name" : "Archive.Data",
"Database" : "MYAPPARCHIVE"
},{
"Name" : "App.Log",
"Database" : "MYAPPLOG"
}]
}
}
Set sc = ##class(Api.Config.Services.Loader).Load(config)
```
Salida:
```
2021-03-31 20:20:07 Start load configuration
2021-03-31 20:20:07 {
"SYS.Databases":{
"/usr/irissys/mgr/myappdata/":{
"ExpansionSize":128
},
"/usr/irissys/mgr/myapparchive/":{
},
"/usr/irissys/mgr/myappcode/":{
},
"/usr/irissys/mgr/myapplog/":{
}
},
"Databases":{
"MYAPPDATA":{
"Directory":"/usr/irissys/mgr/myappdata/"
},
"MYAPPCODE":{
"Directory":"/usr/irissys/mgr/myappcode/"
},
"MYAPPARCHIVE":{
"Directory":"/usr/irissys/mgr/myapparchive/"
},
"MYAPPLOG":{
"Directory":"/usr/irissys/mgr/myapplog/"
}
},
"Namespaces":{
"MYAPP":{
"Globals":"MYAPPDATA",
"Routines":"MYAPPCODE"
}
},
"Security.Applications":{
"/csp/zrestapp":{
"DispatchClas":"my.dispatch.class",
"Namespace":"MYAPP",
"Enabled":"1",
"AuthEnabled":"64",
"CookiePath":"/csp/zrestapp/"
},
"/csp/zwebapp":{
"Path":"/usr/irissys/csp/zwebapp/",
"Namespace":"MYAPP",
"Enabled":"1",
"AuthEnabled":"64",
"CookiePath":"/csp/zwebapp/"
}
},
"MapGlobals":{
"MYAPP":[
{
"Name":"Archive.Data",
"Database":"MYAPPARCHIVE"
},
{
"Name":"App.Log",
"Database":"MYAPPLOG"
}
]
}
}
2021-03-31 20:20:07 * SYS.Databases
2021-03-31 20:20:07 + Create /usr/irissys/mgr/myappdata/ ... OK
2021-03-31 20:20:07 + Create /usr/irissys/mgr/myapparchive/ ... OK
2021-03-31 20:20:07 + Create /usr/irissys/mgr/myappcode/ ... OK
2021-03-31 20:20:07 + Create /usr/irissys/mgr/myapplog/ ... OK
2021-03-31 20:20:07 * Databases
2021-03-31 20:20:07 + Create MYAPPDATA ... OK
2021-03-31 20:20:07 + Create MYAPPCODE ... OK
2021-03-31 20:20:07 + Create MYAPPARCHIVE ... OK
2021-03-31 20:20:07 + Create MYAPPLOG ... OK
2021-03-31 20:20:07 * Namespaces
2021-03-31 20:20:07 + Create MYAPP ... OK
2021-03-31 20:20:07 * Security.Applications
2021-03-31 20:20:07 + Create /csp/zrestapp ... OK
2021-03-31 20:20:07 + Create /csp/zwebapp ... OK
2021-03-31 20:20:07 * MapGlobals
2021-03-31 20:20:07 + Create MYAPP Archive.Data ... OK
2021-03-31 20:20:07 + Create MYAPP App.Log ... OK
```
¡Funciona! La configuración se cargó con éxito.
En el próximo artículo, aprenderemos a usar config-api con ZPM para implementar tu aplicación.
Este artículo está etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Estevan Martinez · 23 jul, 2019
Los globales de InterSystems Caché proporcionan un conjunto de funciones muy útiles para los desarrolladores. Pero, ¿por qué los globales son tan rápidos y eficientes?TeoríaBásicamente, la base de datos de Caché es un catálogo con el mismo nombre que la base de datos y contiene el archivo CACHE.DAT. En los sistemas Unix, la base de datos también puede ser una partición normal del disco.Todos los datos en Caché se almacenan en bloques que, a su vez, se organizan como un árbol-B* balanceado. Si tenemos en cuenta que todos los globales básicamente se almacenan en un árbol, los subíndices de los globales se representarán como ramas, mientras que los valores de los subíndices globales se almacenarán como hojas. La diferencia entre un árbol-B* balanceado y un árbol-B ordinario es que sus ramas también tienen los enlaces apropiados para realizar iteraciones a través de los subíndices (por ejemplo, en nuestro caso los globales) usando rápidamente las funciones $Order y $Query sin necesidad de regresar al tronco del árbol. De manera predeterminada, cada bloque en el archivo de la base de datos tiene un tamaño fijo de 8,192 bytes. Por lo tanto, no podrá modificar el tamaño de los bloques en una base de datos que ya exista. Mientras crea una nueva base de datos puede elegir entre bloques de 16 KB, 32 KB o incluso bloques de 64 KB, dependiendo del tipo de datos que almacenará. Sin embargo, siempre tenga en cuenta que todos los datos se leen bloque por bloque, en otras palabras, incluso si solicita un solo valor de 1 byte de tamaño el sistema leerá muchos bloques, entre los cuales, el bloque de datos que solicitó será el último. También debe recordar que Caché utiliza búferes globales para almacenar los bloques de las bases de datos en la memoria para utilizarlos después, y que los búferes de bloques tienen el mismo tamaño. No podrá utilizar una base de datos existente o crear una nueva cuando el búfer global, con el tamaño de bloques correspondiente, falte en el sistema. Además, deberá definir la cantidad de memoria que desea asignar para el tamaño específico de los bloques. Es posible utilizar búferes con bloques más grandes que los bloques en las bases de datos, pero en este caso, cada bloque en el búfer solamente almacenará un bloque en dicha base, que será incluso más pequeño.En esta imagen, se asignó memoria para un búfer global con un tamaño de 8 KB, con la finalidad de utilizarla en bases de datos conformadas por bloques de 8 KB. En esta base de datos, los bloques que no están vacíos se definieron en los mapas, de tal modo que alguno de los mapas contenga 62,464 bloques (para bloques con capacidad de 8KB).Tipos de BloquesEl sistema es compatible con varios tipos de bloques. En cada nivel, los enlaces correctos de un bloque deben señalar un bloque del mismo tipo o un bloque nulo que defina el final de los datos.Tipo 9: Bloques de un catálogo de globales. En estos bloques generalmente se describen todos los globales existentes junto con sus parámetros, incluida la compilación de los subíndices globales, el cual es uno de los parámetros más importantes y no puede modificarse una vez que el global se creóTipo 66: Bloques punteros de alto nivel. Solo un bloque de un catálogo de globales puede estar en la parte superior de estos bloques.Tipo 6: Bloques punteros de nivel inferior. Únicamente los bloques punteros de alto nivel pueden estar en la parte superior de estos bloques y solamente los bloques de datos pueden colocarse en niveles inferiores.Tipo 70: Bloques punteros tanto de alto nivel como de nivel inferior. Estos bloques se utilizan cuando el global correspondiente almacena una pequeña cantidad de valores y, por lo tanto, no es necesario tener varios niveles de bloques. Estos bloques generalmente señalan hacia los bloques de datos, al igual que los bloques de un catálogo de globales.Tipo 2: Bloques punteros para almacenar una cantidad relativamente grande de globales. Para asignar valores de manera equitativa entre los bloques de datos, es posible que desee crear niveles adicionales de bloques punteros. Estos bloques generalmente se colocan entre los bloques punteros.Tipo 8: Bloques de datos. En estos bloques generalmente se almacenan varios nodos globales en lugar de un solo nodo.Tipo 24: Bloques para cadenas largas. Cuando el valor de un solo global es mayor que un bloque, dicho valor se registrará en un bloque especial para cadenas largas, mientras que el nodo del bloque de datos almacenará enlaces en la lista de bloques para cadenas largas junto con la longitud total de este valor.Tipo 16: Diagrama de bloques. Estos bloques están diseñados para almacenar información sobre bloques que no han sido asignados.Por lo tanto, el primer bloque en una base de datos típica de Caché contiene la información de servicio acerca del mismo archivo en la base de datos, mientras que los segundos bloques constituyen un diagrama de bloques. El primer bloque del catálogo va en el tercer lugar (bloque #3), y una sola base de datos puede tener varios bloques en el catálogo. Los siguientes son bloques punteros (ramas), bloques de datos (hojas) y bloques de cadenas largas. Como ya mencioné anteriormente, los bloques en los catálogos globales almacenan información sobre todos los globales que existen en la base de datos o en la configuración global (si no hay datos disponibles en este tipo de globales). En este caso, un nodo que describa a dicho global tendrá un puntero nulo de nivel inferior. Puede consultar la lista de los globales que están disponibles en el catálogo de globales que se encuentra en el portal de administración. En este portal también se le permitirá guardar un global en el catálogo después de haberlo eliminado (por ejemplo, guardar su secuencia de compilación) así como crear un nuevo global con un tipo de compilación ya sea predeterminada o personalizada.En general, el árbol de bloques puede representarse como la imagen que se muestra a continuación. Tenga en cuenta que los enlaces a estos bloques se muestran en color rojo.Integridad de la Base de DatosEn la versión actual de Caché, resolvimos los temas y los problemas más importantes con las bases de datos, entonces el riesgo de degradación en las bases de datos es extremadamente bajo. Sin embargo, le recomendamos que realice comprobaciones de la integridad automáticas en las bases de datos de manera regular utilizando nuestra herramienta ^Integrity, la cual puede ejecutarse en el terminal desde el namespace %SYS, mediante nuestro portal de administración, en la página de la Base de datos o desde el administrador de tareas. Por defecto, la comprobación de la integridad automática ya está configurada y predefinida, por lo tanto lo único que debe hacer es activarla: La opción "integrity check" incluye la verificación de los enlaces en los niveles inferiores, la validación de los tipos de bloques, el análisis de los enlaces correctos y la correspondencia de los nodos globales con la secuencia para la aplicación de la compilación. Si el programa encuentra algún error durante la comprobación de la integridad, puede ejecutar nuestra herramienta ^REPAIR desde el namespace %SYS. Al utilizar esta herramienta, podrá visualizar cualquier bloque y modificarlo según sea necesario, por ejemplo, para reparar su base de datos. PrácticaEsto fue solo la teoría. Todavía es difícil comprender qué hace un global y cómo se ven en realidad sus bloques. Actualmente, la única manera en que podemos visualizar los bloques es utilizando nuestra herramienta ^REPAIR, que mencionamos anteriormente. A continuación, se muestra la forma característica en que se visualizan los resultados de este programa: Hace tres años, Dmitry comenzó un nuevo proyecto para desarrollar una herramienta que nos permitiera iterar a través de un árbol de bloques sin ningún riesgo de que la base de datos se dañara, visualizar estos bloques en una IU web y proporcionara opciones para guardar dichas visualizaciones en formatos SVG o PNG. El proyecto se llama CacheBlocksExplorer, y su código fuente está disponible para que lo descargue en GitHub.A partir del momento de la redacción del artículo original en 2016.Las características que se implementaron incluyen:Visualizar cualquier base de datos que se haya configurado o simplemente instalado en el sistema;Visualizar la información por bloque, los tipos de bloques, el puntero correcto o una lista de nodos con sus enlaces;Visualizar a detalle la información sobre cualquier nodo que señale hacia un bloque de nivel inferior;Ocultar bloques al eliminar los enlaces hacia ellos (sin dañar los datos almacenados en estos bloques).Lista de cosas pendientes:Mostrar los enlaces correctos: en la versión actual los enlaces correctos se muestran en la información sobre los bloques, pero lo mejor sería que pudiéramos visualizarlos como flechas,Mostrar los bloques de las cadenas largas: en la versión actual simplemente no se muestran,Mostrar todos los bloques que se encuentran en el catálogo de globales en lugar de que solamente se visualice el terceroAsimismo, me gustaría mostrar el árbol completo, pero todavía no encuentro ninguna biblioteca capaz de renderizar rápidamente los cientos de miles de bloques junto con sus enlaces. Con la biblioteca actual es posible renderizarlos en los navegadores web, pero mucho más lentamente que el tiempo que le toma a Caché leer toda la estructura.En el próximo artículo, intentaré describir con más detalle cómo funciona, proporcionar algunos ejemplos sobre su uso y mostrar cómo se recuperan muchos datos que pueden procesarse sobre los globales y los bloques mediante mi Cache Block Explorer.
Artículo
Nancy Martínez · 13 mar, 2020
Introducción
Un requisito frecuente en muchas aplicaciones es registrar en una base de datos los cambios que se realizan en los datos- qué datos se modificaron, quién los modificó y cuándo (control de cambios). Hay muchos artículos relacionados con el tema y existen diferentes métodos sobre cómo hacer esto en Caché.
Por ello, comparto un procedimiento que puede ayudar con la implementación de una estructura para seguir y registrar los cambios en los datos. Este procedimiento crea un trigger mediante un método "objectgenarator" cuando su clase persistente la hereda de "Audit Abstract Class" (Sample.AuditBase). Debido a que su clase persistente hereda Sample.AuditBase, cuando sea compilada, el activador generará automáticamente el control de las modificaciones.
Audit Class
Esta es la clase en la que se registrarán las modificaciones.
Class Sample.Audit Extends %Persistent{ Property Date As %Date; Property UserName As %String(MAXLEN = ""); Property ClassName As %String(MAXLEN = ""); Property Id As %Integer; Property Field As %String(MAXLEN = ""); Property OldValue As %String(MAXLEN = ""); Property NewValue As %String(MAXLEN = "");}
Audit Abstract Class
Esta es la clase abstracta de la que heredará su clase persistente. Esta clase contiene el método trigger (objectgenerator), que sabe cómo identificar cuáles fueron los campos que se modificaron, quién los modificó, cuáles son los antiguos y los nuevos valores, etc.; además escribirá las modificaciones en la tabla de auditoría (Sample.Audit).
Class Sample.AuditBase [ Abstract ]{Trigger SaveAuditAfter [ CodeMode = objectgenerator, Event = INSERT/UPDATE, Foreach = row/object, Order = 99999, Time = AFTER ]{ #dim %compiledclass As %Dictionary.CompiledClass #dim tProperty As %Dictionary.CompiledProperty #dim tAudit As Sample.Audit Do %code.WriteLine($Char(9)_"; get username and ip adress") Do %code.WriteLine($Char(9)_"Set tSC = $$$OK") Do %code.WriteLine($Char(9)_"Set tUsername = $USERNAME") Set tKey = "" Set tProperty = %compiledclass.Properties.GetNext(.tKey) Set tClassName = %compiledclass.Name Do %code.WriteLine($Char(9)_"Try {") Do %code.WriteLine($Char(9,9)_"; Check if the operation is an update - %oper = UPDATE") Do %code.WriteLine($Char(9,9)_"if %oper = ""UPDATE"" { ") While tKey '= "" { set tColumnNbr = $Get($$$EXTPROPsqlcolumnnumber($$$pEXT,%classname,tProperty.Name)) Set tColumnName = $Get($$$EXTPROPsqlcolumnname($$$pEXT,%classname,tProperty.Name)) If tColumnNbr '= "" { Do %code.WriteLine($Char(9,9,9)_";") Do %code.WriteLine($Char(9,9,9)_";") Do %code.WriteLine($Char(9,9,9)_"; Audit Field: "_tProperty.SqlFieldName) Do %code.WriteLine($Char(9,9,9)_"if {" _ tProperty.SqlFieldName _ "*C} {") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit = ##class(Sample.Audit).%New()") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.ClassName = """_tClassName_"""") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.Id = {id}") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.UserName = tUsername") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.Field = """_tColumnName_"""") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.Date = +$Horolog") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.OldValue = {"_tProperty.SqlFieldName_"*O}") Do %code.WriteLine($Char(9,9,9,9)_"Set tAudit.NewValue = {"_tProperty.SqlFieldName_"*N}") Do %code.WriteLine($Char(9,9,9,9)_"Set tSC = tAudit.%Save()") do %code.WriteLine($Char(9,9,9,9)_"If $$$ISERR(tSC) $$$ThrowStatus(tSC)") Do %code.WriteLine($Char(9,9,9)_"}") } Set tProperty = %compiledclass.Properties.GetNext(.tKey) } Do %code.WriteLine($Char(9,9)_"}") Do %code.WriteLine($Char(9)_"} Catch (tException) {") Do %code.WriteLine($Char(9,9)_"Set %msg = tException.AsStatus()") Do %code.WriteLine($Char(9,9)_"Set %ok = 0") Do %code.WriteLine($Char(9)_"}") Set %ok = 1}}
Data Class (Persistent Class)
Esta es la clase de datos del usuario, en la que el usuario (la aplicación) realiza modificaciones, genera y elimina historiales, o hace cualquier cosa que se le permita hacer :)
En resumen, esta generalmente es su clase %Persistent.
Para iniciar el seguimiento y registro de los cambios, necesitará que la clase persistente se herede de la clase abstracta (Sample.AuditBase).
Class Sample.Person Extends (%Persistent, %Populate, Sample.AuditBase){ Property Name As %String [ Required ]; Property Age As %String [ Required ]; Index NameIDX On Name [ Data = Name ];}
Prueba
Como se ha heredado la clase de datos (Sample.Person) de la clase de Audit Abstract Class (Sample.AuditBase) se podrá insertar datos, realizar modificaciones y analizar los cambios que se registraron en Audit Class (Sample. Audit).
Para comprobar esto, es necesario crear un método Test() para la clase, en la clase Sample.Person o en cualquier otra clase se elija.
ClassMethod Test(pKillExtent = 0){ If pKillExtent '= 0 { Do ##class(Sample.Person).%KillExtent() Do ##class(Sample.Audit).%KillExtent() } &SQL(INSERT INTO Sample.Person (Name, Age) VALUES ('TESTE', '01')) Write "INSERT INTO Sample.Person (Name, Age) VALUES ('TESTE', '01')",! Write "SQLCODE: ",SQLCODE,!!! Set tRS = $SYSTEM.SQL.Execute("SELECT * FROM Sample.Person") Do tRS.%Display() &SQL(UPDATE Sample.Person SET Name = 'TESTE 2' WHERE Name = 'TESTE') Write !!! Write "UPDATE Sample.Person SET Name = 'TESTE 2' WHERE Name = 'TESTE'",! Write "SQLCODE:",SQLCODE,!!! Set tRS = $SYSTEM.SQL.Execute("SELECT * FROM Sample.Person") Do tRS.%Display() Quit}
Ejecutar el método Test():
d ##class(Sample.Person).Test(1)
Parameter 1 will kill extent from Sample.Person and Sample.Audit classes.
El método Test para clase realiza lo siguiente:
Introduce una nueva persona con el nombre "TEST";
Muestra el resultado de la introducción;
Actualiza la persona "TEST" a "TEST ABC";
Muestra el resultado de la actualización;
Ahora se podrá verificar la tabla de control de cambios. Para ello, entra en el Portal de Administración del Sistema -> Explorador del Sistema -> SQL. (No olvides cambiarse a su namespace)
Ejecuta el siguiente comando en SQL y verifica los resultados:
SELECT * FROM Sample.Audit
Debes Tener en cuenta que la variable OldValue es "TEST" y la NewValue es "TEST ABC". A partir de ahora podrás realizar tus propias pruebas al cambiar el nombre "TEST ABC" por "Su propio nombre" y/o cambiar, por ejemplo, los valores de Age. Consulte:
UPDATE Sample.Person SET Name = 'Fabio Goncalves' WHERE Name = 'TEST ABC'
Generación del Código
Teniendo en cuenta que hemos implementado el procedimiento de control de cambios que se muestra a continuación, inicia Studio (o Atelier) en tu equipo, abre la clase persistente (Sample.Person) y analiza el código intermedio que se generó después de compilar la clase Sample.Person. Para hacerlo, presiona Ctrl + Shift + V (Consultar otro código fuente), y analiza .INT. Desplázate hacia abajo hasta la etiqueta zSaveAuditAfterExecute y échele un vistazo al código que se generó:
Ventajas
Es muy sencillo implementar el control de cambios basado en el despliegue de datos antiguos. No es necesario tablas adicionales. El mantenimiento también es sencillo. Si decides eliminar datos antiguos, entonces debes utilizar un SQL.
Si se necesita implementar el control de cambios en más tablas, solo es necesario heredarlo desde la clase abstracta (Sample.AuditBase)
Realiza los cambios conforme a tus necesidades, por ejemplo, registra los cambios en Streams.
Registra solamente los campos que se han modificado. No guarda todo el historial de cambios.
Desventajas
Un problema puede ser que cuando se modifican los datos, también se copia todo el historial, es decir, también se copian los datos que no se modificaron.
Si la tabla persona tiene una columna "foto" con los datos binarios (stream) que contiene la fotografía, entonces cada vez que el usuario cambie la imagen también se registrará la función stream (la cual consume espacio en el disco).
Otra desventaja es que también aumenta la complejidad con cada tabla complementaria que añade en el control de cambios. Deberas tener en cuenta, todo el tiempo, que no es tan sencillo recuperar los historiales. Siempre debes utilizar la cláusula SELECT con el condicional: "...WHERE Status = active" o considere algún "DATE INTERVAL"
Todas las modificaciones que se realicen a los datos se registran en una tabla común.
Piensa en las translocaciones y los rollbacks.
El control de cambios es un requisito importante para que algunas aplicaciones sean eficientes. Por lo general, para determinar si hubo alguna modificación en los datos, los desarrolladores deben implementar un método de seguimiento personalizado en sus aplicaciones, mediante una combinación de triggers, columnas para registrar la hora y tablas adicionales. Crear estos procedimientos normalmente requiere mucho trabajo para su implementación, conduce a actualizaciones de esquemas y con frecuencia, implica una disminución en el rendimiento. Este es un ejemplo sencillo que te podría ayudar a establecer tu propia estructura.
Este artículo ha sido etiquetado como "Best practices"
(Los artículos con la etiqueta "Best practices" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).
Artículo
Ricardo Paiva · 26 mar, 2020
Este es el primero de dos artículos sobre los índices SQL.
Parte 1 - Conoce tus índices
¿Qué es un índice?
Recuerda la última vez que fuiste a una biblioteca. Normalmente, los libros están ordenados por temática (y luego autor y título) y cada repisa tiene un cartel en el extremo con un código que describe la temática de los libros. Si necesitaras libros de un cierto tema, en lugar de caminar por cada pasillo y leer la descripción en la parte interior de cada libro, podrías dirigirte directamente al estante cuyo cartel describa la temática que buscas y elegir tus libros de allí. Sin esos carteles, el proceso de encontrar los libros que quieres, habría sido muy lento.
Un índice SQL tiene la misma función general: mejorar el rendimiento, al ofrecer una referencia rápida del valor de los campos para cada fila de una tabla.
Configurar índices es uno de los pasos más importantes a la hora de preparar tus clases para un rendimiento óptimo de SQL.
En este artículo veremos:
¿Qué es un índice y por qué/cuando se deben usar?
¿Qué tipo de índices existen y en qué situaciones son perfectos?
¿A qué se parece un índice?
¿Cómo se puede crear uno?
Y cuando tengo índices, ¿qué hago con ellos?
Me referiré a las clases de nuestro esquema Sample, que se incluye en el namespace Samples en instalaciones de Caché y Ensemble. Puedes descargar estas clases de nuestro repositorio en Github:
https://github.com/intersystems/Samples-Data
Lo fundamental
Puedes indexar cualquier propiedad persistente y cualquier propiedad que puede ser calculada de forma fiable a partir de datos persistentes.
Supongamos que queremos indexar la propiedad TaxID (identificador impositivo) en Sample.Company. En Studio o Atelier, añadiríamos lo siguiente a la definición de la clase:
Index TaxIDIdx On TaxID [ Type = index, Unique ];
La sentencia DDL SQL equivalente se vería como algo así:
CREATE UNIQUE INDEX TaxIDIdx ON Sample.Company (TaxID);
La estructura del índice global predeterminado es la siguiente:
^Sample.CompanyI("TaxIDIdx ",<TaxIDValueAtRowID>,<RowID>) = ""
Ten en cuenta que hay menos subíndices para leer que campos en un global de datos típicos.
Mira la consulta “SELECT Name,TaxID FROM Sample.Company WHERE TaxID = 'J7349'”. Es lógica y simple, y el plan de consulta para ejecutar esta consulta lo refleja:
Este plan dice, básicamente, que buscamos columnas con el valor dado de TaxID en el global del índice, y luego volvemos a buscar en el global de datos ("master map") para recuperar la fila coincidente.
Ahora mira la misma consulta sin un índice en TaxIDX. El plan de consulta resultante es, como se esperaría, menos eficiente:
Sin índices, la ejecución de consultas subyacente de Caché se basa en leer en la memoria y aplicar la condición de la cláusula WHERE a cada fila de la tabla. Y como TaxID es único, ¡estamos haciendo todo este trabajo tan solo para una fila!
Por supuesto, tener índices significa tener datos de índices y filas en disco. Dependiendo de en qué tengamos una condición y cuántos datos contenga nuestra tabla, esto puede generar sus propios desafíos al crear y poblar un índice.
Entonces, ¿cuándo agregamos un índice a una propiedad?
El caso general es cuando condicionamos con frecuencia en base a una propiedad. Algunos ejemplos son identificar información como el número de seguridad social (SSN) de una persona o su número de cuenta bancaria. También puede pensar en fechas de nacimiento o en los fondos de una cuenta. Volviendo a Sample.Company, quizás la clase se vería beneficiada de indexar la propiedad Revenue (ingresos) si quisiéramos recopilar datos sobre organizaciones con altos ingresos. Por otra parte, las propiedades que es poco probable que condicionemos son menos adecuadas para indexar, como por ejemplo el eslogan o descripción de una empresa.
Simple, ¡excepto que también debemos considerar qué tipo de índice es el mejor!
Tipos de índices
Hay seis tipos principales de índices que describiré aquí: estándar, bitmap, compuesto, recopilación, bitslice y datos. También describiré brevemente los índices iFind, que se basan en flujos. Aquí hay posibles solapamientos, y ya hemos visto los índices estándar con el ejemplo anterior.
Compartiré ejemplos de cómo crear índices en tu definición de clase, pero añadir nuevos índices a una clase es más complejo que tan solo añadir una línea a tu definición de clase. En la próxima parte analizaremos todas las consideraciones adicionales.
Usemos Sample.Person como ejemplo. Ten en cuenta que Person tiene la subclase Employee (empleado), que será relevante para entender algunos ejemplos. Employee comparte su almacenamiento de global de datos con Person, y todos los índices de Person son heredados por Employee. Esto significa que Employee usa el global de índices de Person para estos índices heredados.
Si no estás familiarizado con ellas, esta es una descripción general de las clases: Person tiene propiedades SSN (número de seguridad social), DOB (fecha de nacimiento), Name (nombre), Home (un objeto embebido de dirección tipo Address que contiene State (estado) y City (ciudad)), Office (oficina, también de tipo Address) y la colección de listas FavoriteColors (colores favoritos). Employee tiene la propiedad adicional Salary (salario, que definí yo misma).
Estándar
Index DateIDX On DOB;
Aquí uso "estándar" de forma de forma poco precisa, para referirme a índices que almacenan el valor sencillo de una propiedad (a diferencia de una representación binaria). Si el valor es una cadena, se almacenará bajo alguna compilación (collation) – SQLUPPER por defecto.
En comparación con índices bitmap o bitslice, los índices estándar son mucho más fáciles de leer por una persona y su mantenimiento es bastante sencillo. Tenemos un nodo global para cada fila de la tabla.
A continuación se muestra cómo se almacena DateIDX a nivel global.
^Sample.PersonI("DateIDX",51274,100115)="~Sample.Employee~" ; Date is 05/20/81
Ten en cuenta que el primer subscript después del nombre del índice es el valor de la fecha, el último subscript es el ID de Person con esa DOB (fecha de nacimiento) y el valor almacenado en este nodo global indica que esta persona también es miembro de la subclase Sample.Employee. Si esa persona no fuera miembro de ninguna subclase, el valor en el nodo sería una cadena vacía.
Esta estructura base será consistente con la mayoría de los índices que no sean bits, en los cuales los índices en más de una propiedad crean más subscripts en el global y tener más de un valor almacenado en el nodo genera un objeto $listbuild, por ejemplo:
^Package.ClassI(IndexName,IndexValue1,IndexValue2,IndexValue3,RowID) = $lb(SubClass,DataValue1,DataValue2)
Bitmap – Una representación bit a bit (bitwise) del conjunto de IDs que corresponden al valor de una propiedad.
Index HomeStateIDX On Home.State [ Type = bitmap];
Los índices de bitmap se guardan por valor único, a diferencia de los índices estándar, que se almacenan por fila.
Continuando con el ejemplo anterior, digamos que la persona con el ID 1 vive en Massachusetts, el ID 2 en Nueva York, ID 3 en Massachusetts e ID 4 en Rhode Island. HomeStateIDX básicamente se almacena así:
ID
1
2
3
4
(…)
(…)
0
0
0
0
-
MA
1
0
1
0
-
NY
0
1
0
0
-
RI
0
0
0
1
-
(…)
0
0
0
0
-
Si quisiéramos que una consulta devuelva datos de las personas que viven en New England, el sistema realizaría un OR bit a bit (bitwise) sobre las filas relevantes del índice bitmap. Se puede ver rápidamente que debemos cargar en memoria los objetos Person con ID 1, 3 y 4 como mínimo.
Los bitmaps pueden ser eficientes para operadores AND, RANGE y OR en tus claúsulas WHERE.
Si bien no hay un límite oficial sobre la cantidad de valores únicos que puede tener para una propiedad antes de que un índice tipo bitmap sea menos eficiente que un índice estándar, la regla general es de hasta unos 10.000 valores distintos. Entonces, mientras un índice tipo bitmap podría ser efectivo en un estado de los EE. UU., un índice bitmap para una ciudad o condado no sería tan útil.
Otro concepto a tener en cuenta es la eficiencia de almacenamiento. Si piensas añadir o eliminar filas de tu tabla con frecuencia, el almacenamiento de tu índice tipo bitmap podría volverse menos eficiente. Veamos el ejemplo anterior: si elimináramos muchas filas por algún motivo y ya no tenemos a nadie en nuestra tabla que viva en estados menos poblados como Wyoming o Dakota del Norte, el bitmap entonces tendría varias filas solo con ceros. Por otra parte, crear nuevas filas en tablas grandes al final puede volverse más lento, ya que el almacenamiento de bitmaps grandes debe alojar más valores únicos.
En estos ejemplos tengo unas 150.000 filas en Sample.Person. Cada nodo global almacena hasta 64.000 ID's, por lo que el global del índice bitmap en el valor MA está dividido en tres partes:
^Sample.PersonI("HomeStateIDX"," MA",1)=$zwc(135,7992)_$c(0,(...))
^Sample.PersonI("HomeStateIDX"," MA",2)=$zwc(404,7990,(…))
^Sample.PersonI("HomeStateIDX"," MA",3)=$zwc(132,2744)_$c(0,(…))
Caso especial: Extent Bitmap
Un bitmap extent, a menudo llamado $<ClassName>, es un índice tipo bitmap sobre los ID de una clase. Esto brinda a Caché una forma rápida de saber si una fila existe y puede ser útil para consultas COUNT o consultas sobre subclases. Estos índices se generan cuando un índice tipo bitmap se añade a la clase. También puedes crear manualmente un índice extent bitmap en una definición de clase de la siguiente forma:
Index Company [ Extent, SqlName = "$Company", Type = bitmap ];
O mediante la DDL keyword BITMAPEXTENT:
CREATE BITMAPEXTENT INDEX "$Company" ON TABLE Sample.Company
Compuesto – Índices basados en dos o más propiedades
Index OfficeAddrIDX On (Office.City, Office.State);
El caso de uso general de los índices compuestos es tener consultas frecuentes con condiciones sobre dos o más propiedades.
El orden de las propiedades en un índice compuesto importa, debido a la forma en que se almacena el índice en un nivel global. Tener primero la propiedad más selectiva es más eficiente para el rendimiento, ya que ahorrará lecturas de disco iniciales del global de índices. En este ejemplo. Office.City está primero debido a que hay más ciudades únicas que estados en los EE. UU.
Tener primero una propiedad menos selectiva es más eficiente para el espacio. En términos de estructura global, el árbol de índices estaría mejor equilibrado si el estado (State) estuviera primero. Piénsalo: cada estado contiene varias ciudades, pero algunos nombres de ciudades pertenecen a un único estado.
También puedes considerar si esperas ejecutar consultas frecuentes que condicionan solo una de las propiedades. Esto puede ahorrarte definir otro índice más.
Este es un ejemplo de la estructura global del índice compuesto:
^Sample.PersonI("OfficeAddrIDX"," BOSTON"," MA",100115)="~Sample.Employee~"
¿Índice compuesto o índices de bitmap?
Para consultas con condiciones sobre múltiples propiedades, puede que también quieras evaluar si índices tipo bitmap separados serían más efectivos que un único índice compuesto.
Las operaciones bit a bit en dos índices distintos podrían ser más eficientes, considerando que los índices bitmap se adecuan bien a cada propiedad.
También puedes tener índices tipo bitmap compuestos: son índices tipo bitmap en los que el valor único es la intersección de las múltiples propiedades sobre las que estás indexando. Por ejemplo, la tabla de la sección anterior, pero si en lugar de estados tenemos cada par posible de estado y ciudad (p. ej. Boston, MA, Cambridge, MA, incluso Los Angeles, MA, etc.) y las celdas reciben valores 1 por las filas que cumplen ambos valores.
Recopilación – Índices basados en propiedades de recopilación
Aquí tenemos la propiedad FavoriteColors definida de la siguiente forma:
Property FavoriteColors As list Of %String(JAVATYPE = "java.util.List", POPSPEC = "ValueList("",Red,Orange,Yellow,Green,Blue,Purple,Black,White""):2");
Con cada uno de los siguientes índices definidos con fines de demostración:
Index fcIDX1 On FavoriteColors(ELEMENTS);Index fcIDX2 On FavoriteColors(KEYS);
Aquí uso "recopilación" para referirme de forma más amplia a propiedades de una celda que contienen más de un valor. Las propiedades List Of y Array Of son relevantes aquí e incluso las cadenas delimitadas.
Las propiedades de recopilación se analizan automáticamente para construir sus índices. Para propiedades delimitadas, como un número telefónico, deberá definir este método, <PropertyName>BuildValueArray(value, .valueArray), de forma explícita.
Dado el ejemplo anterior para FavoriteColors, fcIDX1 se vería como algo así para una persona cuyos colores favoritos fueran azul y blanco:
^Sample.PersonI("fcIDX1"," BLUE",100115)="~Sample.Employee~"
(…)
^Sample.PersonI("fcIDX1"," WHITE",100115)="~Sample.Employee~"
fcIDX2 se vería así:
^Sample.PersonI("fcIDX2",1,100115)="~Sample.Employee~"
^Sample.PersonI("fcIDX2",2,100115)="~Sample.Employee~"
En este caso, como FavoriteColors es una colección de List, un índice basado en sus claves es menos útil que un índice basado en sus elementos.
Consulta nuestra documentación para cuestiones más específicas sobre crear y gestionar índices basados en propiedades de recopilación:
https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQLOPT_indices#GSQLOPT_indices_collections
Bitslice – Representación bitmap de la representación de la cadena de bits de datos numéricos
Index SalaryIDX On Salary [ Type = bitslice ]; //In Sample.Employee
A diferencia de los índices bitmap, que contienen marcas (flags) que representan qué filas contienen un valor específico, los índices bitslice primero convierten valores numéricos de decimal a binario y luego crean un bitmap en cada dígito del valor binario.
Tomemos el ejemplo anterior y, para ser realistas, simplifiquemos Salary (salario) como unidades de $1000. Así, si el salario de un empleado se guarda como 65, se entiende que representa $65.000.
Digamos por ejemplo que tenemos Employee con ID 1 y salario 15, ID2 con salario 40, ID 3 con salario 64 e ID 4 con salario 130. Los valores de bits correspondientes son:
15
0
0
0
0
1
1
1
1
40
0
0
1
0
1
0
0
0
64
0
1
0
0
0
0
0
0
130
1
0
0
0
0
0
1
0
Nuestra cadena de bits abarca 8 dígitos. La representación bitmap correspondiente (los valores de índices bitslice) se almacena básicamente así:
^Sample.PersonI("SalaryIDX",1,1) = "1000" ; Row 1 has value in 1’s place
^Sample.PersonI("SalaryIDX",2,1) = "1001" ; Rows 1 and 4 have values in 2’s place
^Sample.PersonI("SalaryIDX",3,1) = "1000" ; Row 1 has value in 4’s place
^Sample.PersonI("SalaryIDX",4,1) = "1100" ; Rows 1 and 2 have values in 8’s place
^Sample.PersonI("SalaryIDX",5,1) = "0000" ; etc…
^Sample.PersonI("SalaryIDX",6,1) = "0100"
^Sample.PersonI("SalaryIDX",7,1) = "0010"
^Sample.PersonI("SalaryIDX",8,1) = "0001"
Ten en cuenta que las operaciones que modifican Sample.Employee o los salarios de sus filas (es decir, INSERT, UPDATES y DELETE) ahora requieren actualizar cada uno de estos nodos globales, o bitslices. Añadir un índice bitslice a múltiples propiedades de una tabla o una propiedad que se modifica con frecuencia puede conllevar riesgos de rendimiento. En general, mantener un índice bitslice es más costoso que mantener índices de tipo estándar o bitmap.
Los índices bitslice son altamente especializados y por eso tienen casos de uso específicos: consultas que deben realizar cálculos agregados (p.ej. SUM, COUNT o AVG).
Además, solo pueden usarse de forma efectiva sobre valores numéricos (las cadenas de caracteres se convierten a un 0 binario).
Si es necesario leer la tabla de datos, en lugar de los índices, para verificar la condición de una consulta, los índices bitslice no se elegirán para ejecutar la consulta. Digamos que Sample.Person no tiene un índice en Name. Si quisiéramos calcular el salario medio de los empleados cuyo apellido es Smith (“SELECT AVG(Salary) FROM Sample.Employee WHERE Name %STARTSWITH 'Smith,' “) necesitaríamos leer filas de datos para aplicar la condición WHERE, por lo que en la práctica no se usaría el índice bitslice.
Hay varios problemas de almacenamiento similares para índices bitslice y bitmap en tablas en las que se crean o eliminan filas frecuentemente.
Datos - Índices con datos almacenados en sus nodos globales.
Index QuickSearchIDX On Name [ Data = (SSN, DOB, Name) ];
En varios de los ejemplos anteriores, puedes haber observado la cadena “~Sample.Employee~” almacenada como el valor del propio nodo. Recuerda que Sample.Employee hereda índices de Sample.Person. Cuando hacemos una consulta sobre los empleados (Employees) en particular, leemos el valor en los nodos de índices que coinciden con la condición de nuestra propiedad para verificar que dicha persona (Person) también sea un empleado.
También podemos definir explícitamente qué valores almacenar. Definir los datos en tus nodos globales de índices puede ahorrarte lecturas de todos los datos globales. Esto puede ser útil para consultas ordenadas o selectivas frecuentes.
Tomamos como ejemplo el índice anterior. Si quisiéramos extraer información identificatoria sobre una persona dado su nombre completo o parcial (p. ej. para buscar información del cliente en una aplicación de atención al público), podríamos tener una consulta como “SELECT SSN, Name, DOB FROM Sample.Person WHERE Name %STARTSWITH 'Smith,J' ORDER BY Name”. Como las condiciones de nuestra consulta sobre Name y los valores que estamos recuperando se encuentran todos dentro de los nodos globales QuickSearchIDX, solo necesitamos leer nuestro global I para ejecutar esta consulta.
Ten en cuenta que los valores de datos no pueden almacenarse con índices bitmap o bitslice.
^Sample.PersonI("QuickSearchIDX"," LARSON,KIRSTEN A.",100115)=$lb("~Sample.Employee~","555-55-5555",51274,"Larson,Kirsten A.")
Índices iFind
¿Alguna vez ha oído hablar de ellos? Yo tampoco. Los índices iFind se usan en propiedades de flujo, pero para usarlos se deben especificar sus nombres con palabras clave en la consulta.
Podría explicarlo más en detalle, pero Kyle Baxter tiene un artículo muy útil sobre esto:
https://community.intersystems.com/post/free-text-search-way-search-your-text-fields-sql-developers-are-hiding-you
Continúa leyendo la Parte 2, sobre la gestión de índices definidos.
Este artículo ha sido etiquetado como "Best practices"
(Los artículos con la etiqueta "Best practices" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).
Artículo
Rizmaan Marikar · 21 abr, 2022
Hay varias maneras de generar ficheros Excel usando tecnología InterSystems: por ejemplo utilizando informes generados con InterSystems Reports, o los antiguos informes ZEN, o incluso haciendo uso de librerías Java de terceros. Las posibilidades son casi infinitas.
Pero, ¿qué pasa si quieres crear una sencilla hoja de cálculo sólo con ObjectScript? (sin aplicaciones de terceros)
En mi caso, necesito generar informes que contengan muchos datos sin procesar (a los financieros les encantan), pero mi antiguo informe ZEN fallaba y me da lo que me gusta llamar un "archivo con cero bytes". Básicamente, Java se queda sin memoria y provoca una sobrecarga en el servidor de informes.
Esto se puede hacer usando Office Open XML (OOXML). El formato Office Open XML está compuesto por un número de archivos XML dentro de un paquete ZIP. Así que, básicamente, necesitamos generar estos archivos XML y comprimirlos renombrandolos a .xslx. Así de fácil.
Los archivos siguen un sencillo conjunto de convenciones llamadas Open Packaging Conventions (OPC). Hay que declar los tipos de contenido de las partes, así como indicar a la aplicación que lo consumirá donde debería empezar.
Parar crear una sencilla hoja de cálculo, necesitamos un mínimo de 5 ficheros:
workbook.xml
worksheet.xml
[Content_Types].xml
styles.xml
_rels
.rels
workbook.xml.rels
workbook.xmlEl workbook es el contenedor de diferentes worksheets. El workbook es donde puedes referenciar estilos, tablas de cadenas de texto compartidas, y otras piezas de información cuyo ámbito es la totalidad de la hoja de cálculo.
ClassMethod GenerateWorkbookXML(){
set status =$$$OK
set xmlfile = tempDirectoryPath_"workbook.xml"
try{
set stream = ##class(%Stream.FileCharacter).%New()
set sc=stream.LinkToFile(xmlfile)
do stream.WriteLine("<?xml version='1.0' encoding='UTF-8' standalone='yes'?>")
do stream.WriteLine("<workbook xmlns='http://schemas.openxmlformats.org/spreadsheetml/2006/main' xmlns:r='http://schemas.openxmlformats.org/officeDocument/2006/relationships'>")
do stream.WriteLine("<sheets> <sheet name='"_workSheetName_"' sheetId='1' r:id='rId1'/>")
do stream.WriteLine("</sheets> </workbook>")
do stream.%Save()
}catch{
set status=$$$NO
}
kill stream
return status
}
_rels/workbook.xml.relsSólo necesitamos crear una relación que tenga un id de rId1 de manera que coincida con la referencia desde la parte de workbook.xml
ClassMethod CreateRelsXML(){
set status =$$$OK
set isunix=$zcvt($p($zv," ",3,$l($p($zv," (")," ")),"U")["UNIX"
if isunix {
set ext="/"
}else{
set ext="\"
}
set xmlfile = fileDirectory_"_rels"_ext_"workbook.xml.rels"
set stream = ##class(%Stream.FileCharacter).%New()
set sc=stream.LinkToFile(xmlfile)
do stream.WriteLine("<?xml version='1.0' encoding='UTF-8' standalone='yes'?>")
do stream.WriteLine("<Relationships xmlns='http://schemas.openxmlformats.org/package/2006/relationships'>")
do stream.WriteLine("<Relationship Id='rId1' Type='http://schemas.openxmlformats.org/officeDocument/2006/relationships/worksheet' Target='worksheet.xml'/>")
do stream.WriteLine("<Relationship Id='rId2' Type='http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles' Target='styles.xml' />")
do stream.WriteLine("</Relationships>")
try{
do stream.%Save()
}catch{
set status=$$$NO
}
kill stream
set xmlfile = fileDirectory_"_rels"_ext_".rels"
set stream = ##class(%Stream.FileCharacter).%New()
set sc=stream.LinkToFile(xmlfile)
do stream.WriteLine("<?xml version='1.0' encoding='UTF-8' standalone='yes'?>")
do stream.WriteLine("<Relationships xmlns='http://schemas.openxmlformats.org/package/2006/relationships'>")
do stream.WriteLine("<Relationship Id='rId1' Type='http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument' Target='workbook.xml'/>")
do stream.WriteLine("</Relationships>")
try{
do stream.%Save()
}catch{
set status=$$$NO
}
kill stream
return status
}
[Content_Types].xmlArchivo estático (por el momento, aunque debería ser un archivo dinámico dependiendo del número de worksheets) que vincula workbook, worksheet y estilos. Cada archivo Office Open XML debe declarar los tipos de contenido usados en el paquete ZIP. Eso se hace con el archivo [Content_Types].xml.
ClassMethod GenerateConntentTypesXML(){
set status =$$$OK
set xmlfile = tempDirectoryPath_"[Content_Types].xml"
set stream = ##class(%Stream.FileCharacter).%New()
set sc=stream.LinkToFile(xmlfile)
try{
do stream.WriteLine("<?xml version='1.0' encoding='UTF-8' standalone='yes'?>")
do stream.WriteLine("<Types xmlns='http://schemas.openxmlformats.org/package/2006/content-types'>")
do stream.WriteLine("<Default Extension='rels' ContentType='application/vnd.openxmlformats-package.relationships+xml'/>")
do stream.WriteLine("<Override PartName='/workbook.xml' ContentType='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet.main+xml'/>")
do stream.WriteLine("<Override PartName='/worksheet.xml' ContentType='application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml'/>")
do stream.WriteLine("<Override PartName='/styles.xml' ContentType='application/vnd.openxmlformats-officedocument.spreadsheetml.styles+xml' />")
do stream.WriteLine("</Types>")
do stream.%Save()
}catch{
set status=$$$NO
}
kill stream
return status
}
styles.xmlTodo lo necesario para el formateo se coloca aquí. Por el momento hay varios estilos estáticos (aunque debería ser dinámico dependiendo del workbook)
Excel Styles
ID
Style
Excel Format
1
default
Text
2
#;[Red]-#
Number
3
#.##;[Red]-#.##
Number
4
yyyy/mm/dd
Date
5
hh:mm
Date
6
Header and Center Aligned
Text
7
Header 2 Left Aligned
Text
8
Good(Green Highlight)
General
9
Bad(Red Highlight)
General
10
Neutral(Orange Highlight)
General
11
yyyy/mm/dd hh:mm
Date
ClassMethod CreateStylesXML(){
set status =$$$OK
set xmlfile = tempDirectoryPath_"styles.xml"
try{
set stream = ##class(%Stream.FileCharacter).%New()
set sc=stream.LinkToFile(xmlfile)
do stream.WriteLine("<?xml version=""1.0"" encoding=""UTF-8"" standalone=""yes""?>")
do stream.WriteLine("<styleSheet xmlns=""http://schemas.openxmlformats.org/spreadsheetml/2006/main"" xmlns:mc=""http://schemas.openxmlformats.org/markup-compatibility/2006"" mc:Ignorable=""x14ac x16r2 xr"" xmlns:x14ac=""http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac"" xmlns:x16r2=""http://schemas.microsoft.com/office/spreadsheetml/2015/02/main"" xmlns:xr=""http://schemas.microsoft.com/office/spreadsheetml/2014/revision"">")
do stream.WriteLine("<numFmts count=""4"">")
do stream.WriteLine("<numFmt numFmtId=""166"" formatCode=""#,##0;[Red]\-#,##0""/>")
do stream.WriteLine("<numFmt numFmtId=""168"" formatCode=""#,##0.00;[Red]\-#,##0.00""/>")
do stream.WriteLine("<numFmt numFmtId=""169"" formatCode=""dd\/mm\/yyyy;@""/>")
do stream.WriteLine("<numFmt numFmtId=""170"" formatCode=""dd/mm/yyyy\ hh:mm""/></numFmts>")
do stream.WriteLine("<fonts count=""5"" x14ac:knownFonts=""1"">")
do stream.WriteLine("<font><sz val=""10""/><color theme=""1""/><name val=""Calibri""/><family val=""2""/><scheme val=""minor""/></font>")
do stream.WriteLine("<font><sz val=""10""/><color rgb=""FF006100""/><name val=""Calibri""/><family val=""2""/><scheme val=""minor""/></font>")
do stream.WriteLine("<font><sz val=""10""/><color rgb=""FF9C0006""/><name val=""Calibri""/><family val=""2""/><scheme val=""minor""/></font>")
do stream.WriteLine("<font><sz val=""10""/><color rgb=""FF9C5700""/><name val=""Calibri""/><family val=""2""/><scheme val=""minor""/></font>")
do stream.WriteLine("<font><b/><sz val=""10""/><color theme=""1""/><name val=""Calibri""/><family val=""2""/><scheme val=""minor""/></font></fonts>")
do stream.WriteLine("<fills count=""5"">")
do stream.WriteLine("<fill><patternFill patternType=""none""/></fill>")
do stream.WriteLine("<fill><patternFill patternType=""gray125""/></fill>")
do stream.WriteLine("<fill><patternFill patternType=""solid""><fgColor rgb=""FFC6EFCE""/></patternFill></fill>")
do stream.WriteLine("<fill><patternFill patternType=""solid""><fgColor rgb=""FFFFC7CE""/></patternFill></fill>")
do stream.WriteLine("<fill><patternFill patternType=""solid""><fgColor rgb=""FFFFEB9C""/></patternFill></fill></fills>")
do stream.WriteLine("<borders count=""1""><border><left/><right/><top/><bottom/><diagonal/></border></borders>")
do stream.WriteLine("<cellStyleXfs count=""4"">")
do stream.WriteLine("<xf numFmtId=""0"" fontId=""0"" fillId=""0"" borderId=""0""/>")
do stream.WriteLine("<xf numFmtId=""0"" fontId=""1"" fillId=""2"" borderId=""0"" applyNumberFormat=""0"" applyBorder=""0"" applyAlignment=""0"" applyProtection=""0""/>")
do stream.WriteLine("<xf numFmtId=""0"" fontId=""2"" fillId=""3"" borderId=""0"" applyNumberFormat=""0"" applyBorder=""0"" applyAlignment=""0"" applyProtection=""0""/>")
do stream.WriteLine("<xf numFmtId=""0"" fontId=""3"" fillId=""4"" borderId=""0"" applyNumberFormat=""0"" applyBorder=""0"" applyAlignment=""0"" applyProtection=""0""/></cellStyleXfs>")
do stream.WriteLine("<cellXfs count=""12""><xf numFmtId=""0"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0""/>")
do stream.WriteLine("<xf numFmtId=""49"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0"" quotePrefix=""1"" applyNumberFormat=""1""/>")
do stream.WriteLine("<xf numFmtId=""166"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1""/>")
do stream.WriteLine("<xf numFmtId=""168"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1""/>")
do stream.WriteLine("<xf numFmtId=""169"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1""/>")
do stream.WriteLine("<xf numFmtId=""20"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1""/>")
do stream.WriteLine("<xf numFmtId=""49"" fontId=""4"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1"" applyFont=""1""/>")
do stream.WriteLine("<xf numFmtId=""49"" fontId=""4"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1"" applyFont=""1"" applyAlignment=""1""><alignment horizontal=""center""/>")
do stream.WriteLine("</xf>")
do stream.WriteLine("<xf numFmtId=""49"" fontId=""1"" fillId=""2"" borderId=""0"" xfId=""1"" applyNumberFormat=""1""/>")
do stream.WriteLine("<xf numFmtId=""0"" fontId=""2"" fillId=""3"" borderId=""0"" xfId=""2""/>")
do stream.WriteLine("<xf numFmtId=""0"" fontId=""3"" fillId=""4"" borderId=""0"" xfId=""3""/>")
do stream.WriteLine("<xf numFmtId=""170"" fontId=""0"" fillId=""0"" borderId=""0"" xfId=""0"" applyNumberFormat=""1""/></cellXfs>")
do stream.WriteLine("<cellStyles count=""4""><cellStyle name=""Bad"" xfId=""2"" builtinId=""27""/>")
do stream.WriteLine("<cellStyle name=""Good"" xfId=""1"" builtinId=""26""/><cellStyle name=""Neutral"" xfId=""3"" builtinId=""28""/>")
do stream.WriteLine("<cellStyle name=""Normal"" xfId=""0"" builtinId=""0""/></cellStyles><dxfs count=""0""/>")
do stream.WriteLine("<tableStyles count=""0"" defaultTableStyle=""TableStyleMedium2"" defaultPivotStyle=""PivotStyleLight16""/> ")
do stream.WriteLine("<extLst><ext uri=""{EB79DEF2-80B8-43e5-95BD-54CBDDF9020C}"" xmlns:x14=""http://schemas.microsoft.com/office/spreadsheetml/2009/9/main"">")
do stream.WriteLine("<x14:slicerStyles defaultSlicerStyle=""SlicerStyleLight1""/></ext><ext uri=""{9260A510-F301-46a8-8635-F512D64BE5F5}"" xmlns:x15=""http://schemas.microsoft.com/office/spreadsheetml/2010/11/main"">")
do stream.WriteLine("<x15:timelineStyles defaultTimelineStyle=""TimeSlicerStyleLight1""/></ext></extLst>")
do stream.WriteLine("</styleSheet>")
do stream.%Save()
}catch{
set status=$$$NO
}
kill stream
return status
}
worksheet.xmlAquí es donde se colocan nuestros datos. La primera fila tendrá los títulos de las columnas. Las siguientes filas sólo tendrán datos.Aquí definiremos los anchos de columna para cada columna; si no, las columnas por defecto se configurarán con ajuste automático.
Worksheet de muestra en xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet xmlns="https://schemas.openxmlformats.org/spreadsheetml/2006/main" xmlns:r="https://schemas.openxmlformats.org/officeDocument/2006/relationships">
<sheetData>
<row>
<c t="inlineStr">
<is>
<t>Name</t>
</is>
</c>
<c t="inlineStr">
<is>
<t>Amount</t>
</is>
</c>
</row>
<row>
<c t="inlineStr">
<is>
<t>Jhon Smith</t>
</is>
</c>
<c>
<v>1000.74</v>
</c>
</row>
<row>
<c t="inlineStr">
<is>
<t>Tracy A</t>
</is>
</c>
<c>
<v>6001.74</v>
</c>
</row>
</sheetData>
</worksheet>
Excel de muestra
Las fórmulas dentro de la worksheet las podemos incluir utilizando una etiqueta <f>
<c >
<f>B2*0.08</f >
</c >
<c >
<f>B2+C2</f >
</c>
y finalmente lo empaquetamos y renombramos a .xlsx (usando unix zip)
set cmd ="cd "_fileDirectory_" && find . -type f | xargs zip .."_ext_xlsxFile
Cómo generar un documento Excel
Este código de muestra genera un documento Excel.
set file = "/temp/test.xlsx"
set excelObj = ##class(XLSX.writer).%New(file)
do excelObj.SetWorksheetName("test1")
set status = excelObj.BeginWorksheet()
set row = 0
set row = row+1
;----------- excelObj.Cells(rowNumber,columnNumber,style,content)
set status = excelObj.Cells(row,1,1,"Header1")
set row = row+1
set status = excelObj.Cells(row,1,2,"Content 1")
set status = excelObj.EndWorksheet()
W !,excelObj.fileName
Podéis encontrar el código en :
https://github.com/RizmaanMarikar/ObjectScriptExcelGenerator
Artículo
Estevan Martinez · 11 feb, 2020
Esta publicación es el resultado directo de trabajar con un cliente de InterSystems que acudió a mí con el siguiente problema:
SELECT COUNT(*) FROM MyCustomTable
Esto tarda 0.005 segundos, con 2300 filas en total. Sin embargo:
SELECT * FROM MyCustomTable
Tardó algunos minutos. La razón de que esto sucediera es lo suficientemente sutil e interesante para mí como para escribir una publicación sobre ello. Esta publicación es extensa, pero si va hasta el final verá que escribí un resumen rápido. Por ello, si llegó hasta aquí y cree que ya leyó demasiado, desplácese hasta el final para leer únicamente las ideas principales. Busque la frase que se encuentra en negrita.
Cuando esté creando sus clases, hay un aspecto a tener cuenta relacionada con el almacenamiento. Como muchos ya saben, todos los datos en Caché se almacenan en globals.
<Paréntesis>
Si no sabe esto, creo que esta publicación va a ser un poco extensa. Recomiendo echar un vistazo a este excelente tutorial que se encuentra en nuestra documentación:
ObjectScript Tutorial
Si nunca ha utilizado Caché/Ensemble/HealthShare, el tutorial anterior es muy útil. E incluso si ya los ha utilizado, ¡vale la pena revisarlo!
</Paréntesis>
Ahora, debido a que todos los datos se almacenan en globals, es importante que comprenda cómo las definiciones de su clase se mapean con los globals. ¡Creemos una aplicación juntos! Repasaremos algunos de los errores más comunes y discutiremos cómo el desarrollo de su clase afecta a sus estrategias de almacenamiento, con atención especial al rendimiento de SQL.
Imaginemos que somos la Oficina del Censo de Estados Unidos y necesitamos una base de datos para almacenar la información de todas las personas que viven en el país. Entonces construiremos una clase como esta:
Class USA.Person extends %Persistent
{
Property Name as %String;
Property SSN as %String;
Property Address as %String;
Property DateOfBirth as %Date;
}
SSN significa "Social Security Number (Número de Seguridad Social)" que, aunque originariamente no estaba destinado a funcionar como un número para identificar a las personas, en la práctica es su número de identificación. Sin embargo, somos tradicionalistas, así que no lo utilizaremos para el ID. Dicho esto, a la vez queremos que se indexe, ya que es una excelente manera de buscar a alguien. Sabemos que algunas veces tendremos que buscar a las personas por su nombre, así que también queremos un índice de nombres. Y como a nuestro jefe le encantan los informes basados en grupos de edad, creemos que también sería bueno incluir un índice para la fecha de nacimiento (DOB). Así que vamos a añadir todo esto a nuestra clase
Class USA.Person extends %Persistent
{
Property Name as %String;
Property SSN as %String;
Property Address as %String;
Property DateOfBirth as %Date;
Index NameIDX On Name;
Index SSNIDX On SSN [Unique];
Index DOBIDX on DateOfBirth;
}
Muy bien. Agreguemos una fila y veamos cómo son nuestros globals. Nuestra sentencia INSERT se ve de la siguiente manera:
INSERT INTO USA.Person (Name,SSN,Address,DateOfBirth) VALUES
('Baxter, Kyle','111-11-1111','1 Memorial Drive, Cambridge, MA 02142','1985-07-20')
Y el global:
USER>zw ^USA.PersonD
^USA.PersonD=1
^USA.PersonD(1)=$lb("","Baxter, Kyle","111-11-1111","1 Memorial Drive, Cambridge, MA 02142",52796)
El almacenamiento predeterminado para una clase almacena sus datos en ^Package.ClassD. Si el nombre de la clase es demasiado extenso, puede descomponerse en otros más pequeños, y puede encontrarlo en la Definición de Almacenamiento que se encuentra en la parte inferior de su definición de clase. ¿Cómo se ven los índices?
USER>zw ^USA.PersonI
^USA.PersonI("DOBIDX",52796,1)=""
^USA.PersonI("NameIDX"," BAXTER, KYLE",1)=""
^USA.PersonI("SSNIDX"," 111-11-1111",1)=""
¡Genial! Nuestro almacenamiento se ve bastante bien hasta ahora. De modo que añadimos nuestros 320 millones de personas y podemos conseguir más personas muy rápidamente. Pero ahora tenemos un problema, porque queremos tratar al presidente y a todos los ex presidentes con algunas consideraciones especiales. Entonces, agregaremos una clase especial para el presidente:
Class USA.President extends USA.Person
{
Property PresNumber as %Integer;
Index PresNumberIDX on PresNumber;
}
Bien. Debido a la herencia, obtuvimos todas las propiedades de USA.Person, y agregamos una que nos permitiera saber qué número de presidente era. Ya que quiero ser lo menos político posible, colocaré INSERT para añadir a nuestro SIGUIENTE presidente. Esta es la sentencia:
INSERT INTO USA.President (Name,SSN,DateOfBirth,Address,PresNumber) VALUES ('McDonald,Ronald','221-18-7518','01-01-1963','1600 Pennsylvania Ave NW, Washington, DC 20006',45)
Nota: Su SSN significa 'burger'. Lo siento mucho si es su SSN.
¡Genial! Veamos el global de su presidente:
USER>zw ^USA.PresidentD
¡No hay datos! Y aquí es donde llegamos al motivo de esta publicación. Debido a que PRIMERO decidimos heredarlo desde USA.Person, no solo heredamos sus propiedades e índices, ¡también obtuvimos su almacenamiento! Entonces, para localizar al presidente McDonald tenemos que buscarlo en ^USA.PersonD. Podemos ver lo siguiente:
^USA.PersonD(2)=$lb("~USA.President~","McDonald,Ronald","221-18-7518","1600 Pennsylvania Ave NW, Washington, DC 20006",44560)
^USA.PersonD(2,"President")=$lb(45)
Aquí destacamos dos cosas importantes. La primera es que podemos ver que el nodo (2) tiene toda la información que ya se almacenó en USA.Person. Mientras que el nodo (2, "President") solamente tiene la información específica para la clase USA.President.
¿Qué significa esto en la práctica? Bueno, si queremos realizar: SELECT * FROM USA.President entonces NECESITAREMOS revisar toda la tabla de personas. Si esperamos que la tabla de personas tenga 320,000,000 filas, y la tabla de presidentes 45, ¡entonces debemos hacer más de 320,000,045 referencias globales para extraer 45 filas! De hecho, si miramos el plan de la consulta:
Read master map USA.President.IDKEY, looping on ID.
For each row:
Output the row.
Vemos exactamente lo que esperábamos. Sin embargo, ya vimos que esto significa realizar búsquedas en todo el global ^USA.PersonD. Por tanto, esta será una referencia global de más de 320,000,000 ya que necesitamos probar CADA ^USA.PersonD para comprobar si existen datos en ^USA.PersonD(i, "Presidente"), pues no sabemos cuáles de entre todas las personas serán los presidentes. Esto no está muy bien. ¡No es lo que queríamos hacer! ¡¿Qué podemos hacer ahora?! Bueno, tenemos 2 opciones:
Opción 1
Agregar un índice de extensión. Si lo hacemos, obtendremos una lista de los ID, de modo que sabremos qué personas son presidentes y podemos utilizar esa información para leer nodos específicos del global ^USA.Person. Debido a que tengo un almacenamiento predeterminado, puedo utilizar un índice para mapas de bits, el cual hará que este proceso se realice aún más rápidamente. Agregamos el índice de esta manera:
Index Extent [Type=Bitmap, Extent];
Y cuando buscamos SELECT * FROM USA.President en nuestro plan de consulta, podemos observar:
Read extent bitmap USA.President.Extent, looping on ID.
For each row:
Read master map USA.President.IDKEY, using the given idkey value.
Output the row.
Muy bien, ahora esto va a ser rápido. Una referencia global para revisar la extensión, y después 45 más para los presidentes. Eso es bastante eficiente.
¿Cuáles son los inconvenientes? Bueno, unir esta tabla lo vuelve un poco más problemático y puede involucrar más tablas temporales de las que le gustaría tener.
Opción 2
Cambiar la definición de clase por:
Class USA.President extends (%Persistent, USA.Person)
Hacer que %Persistent sea la primera clase extendida significaría que USA.President obtendrá su propia definición de almacenamiento. Entonces, los presidentes se almacenarán de la siguiente manera:
USER>zw ^USA.PresidentD
^USA.PresidentD=1
^USA.PresidentD(1)=$lb("","McDonald,Ronald","221-18-7518","1600 Pennsylvania Ave NW, Washington, DC 20006",44560,45)
Esto está bien, porque seleccionarlo desde USA.President. significa que podrá leer los 45 miembros de este global. Es agradable, fácil y tiene un diseño limpio.
¿Cuáles son los inconvenientes? Bueno, ahora los Presidentes NO están en la tabla de personas (Person). De modo que si quiere la información acerca de los presidentes y las personas que no son presidentes, es necesario que haga lo siguiente SELECT ... FROM USA.Person UNION ALL SELECT ... FROM USA.President
Si dejó de leer al principio, siga leyendo aquí:
Cuando creamos herencias, tenemos dos opciones
Opción 1: Heredar desde la primera superclase. Esto almacena los datos en el mismo global que la superclase. Hacer esto es útil si quiere tener toda la información junta, y puede mitigar los problemas de rendimiento en la subclase mediante un índice de extensión.
Opción 2: Heredar primero desde %Persistent. Esto almacena los datos en un nuevo global. Hacer esto es útil si va a consultar mucho la subclase. Sin embargo, si quiere ver los datos tanto de la superclase como de la subclase, necesita utilizar una consulta de tipo UNION.
¿Cuál de estas opciones es mejor? Bueno, eso depende de cómo va a utilizar su aplicación. Si va a querer hacer muchas consultas sobre todos los datos juntos, entonces probablemente prefiera el primer método. Sin embargo, si cree que nunca tendrá que consultar todos los datos juntos, entonces probablemente prefiera utilizar el segundo método. Ambos son bastante buenos, siempre y cuando recuerde el índice de extensión en la Opción 1.
¿Preguntas? ¿Comentarios? ¿Se siente confundido? Puede escribir en la parte de abajo.
¡Muchas gracias!
Artículo
Javier Lorenzo Mesa · 25 jun, 2020
¡Hola desarrolladores!
El desarrollo de una aplicación web Full-Stack en JavaScript con Caché requiere que juntes los bloques correctos para construirla. En la primera parte de este artículo, creamos una aplicación básica para desarrollar el frontal de usuario (front-end) en React. En esta segunda parte, mostraré cómo elegir la tecnología más adecuada para desarrollar la parte servidora (back-end) de tu aplicación. Verás que Caché te permite utilizar diferentes enfoques para vincular tu front-end con tu servidor de Caché, dependiendo de las necesidades de tu aplicación. También configuraremos un back-end mediante Node.js/QEWD y CSP/REST. En la siguiente parte, vamos a mejorar nuestra aplicación básica web y la conectaremos a Caché usando estas tecnologías.
Caché es una base de datos multi-modelo muy potente y flexible, además de un servidor para aplicaciones que cuenta con un enfoque único. Permite conectar el front-end de tu aplicación utilizando muchas tecnologías diferentes. Esta es una gran ventaja, pero también puede hacer que sea más difícil decidir cuál de estas tecnologías se debe utilizar para desarrollar el back-end.
Como desarrollador, quieres elegir una tecnología que permanezca a lo largo del tiempo, te haga ser productivo durante el desarrollo, mantenga estable la base de tu código y permita que tu aplicación se ejecute en tantos dispositivos y plataformas como sea posible utilizando el mismo código fuente.
Estos requisitos te conducen hoy en día, inevitablemente, a escribir las aplicaciones con JavaScript porque es el lenguaje que se utiliza en los navegadores (lo que hace que esté disponible en todo tipo de plataformas y sea tan popular). La aparición de Node.js hizo que también fuera posible utilizar JavaScript del lado del servidor, lo que permite a los desarrolladores usar el mismo lenguaje tanto en el front-end como en el back-end.
Básicamente, puedes escribir un sitio web o una aplicación web de dos maneras diferentes: usando la tecnología del lado del servidor o del lado del cliente (rendering). El renderizado del lado del servidor es una excelente opción para los sitios web habituales, mientras que el renderizado del lado del cliente es la mejor elección cuando se escribe una aplicación web (dado que también necesita funcionar sin conexión). Las páginas CSP de Caché son un buen ejemplo de la tecnología del lado del servidor, mientras que React es una tecnología del lado del cliente (aunque actualmente también puede utilizarse para el renderizado del lado del servidor). Esta es una decisión que deberás tomar y depende totalmente de tu aplicación.
Por ahora, nos centraremos en la escritura de las aplicaciones web, no hablaré de las páginas CSP aquí.
En el back-end, también deberás elegir qué tecnologías utilizarás para tu aplicación web: ¿usarás únicamente el servidor para aplicaciones de Caché y las llamadas CSP/REST o usarás Node.js como tu servidor para aplicaciones de modo que funcione con Caché? Al utilizar Node.js como tu servidor para la aplicación tendrás lo mejor de ambos mundos: te permite escribir el código de tu back-end en JavaScript con Caché, como una base de datos y un servidor para aplicaciones detrás de él.
¿Qué hace que esta combinación sea tan potente?
Utiliza el mismo lenguaje (JavaScript) tanto para el front-end como para el back-end
Utiliza todos los módulos estándares disponibles de Node.js en tus aplicaciones (esto aumenta la funcionalidad de tu aplicación hacia todos los tipos de dispositivos y servicios externos que puedas imaginar)
Te permite reutilizar tu código COS existente mediante envoltorios de función muy pequeños
Integra tu aplicación con otros servicios y protocolos estándar
...
Escribir tus aplicaciones con estas tecnologías no te limita a una única tecnología: de hecho, ¡puedes combinarlas todas en la misma aplicación!
La siguiente pregunta es cómo puedes vincular tu front-end con tu back-end. Actualmente, existen diversas opciones, cada una con sus (des)ventajas:
WebSockets: crea un canal bidireccional (con estados) para el back-end y tu servidor puede "impulsar" (push) un mensaje hacia el front-end, no es necesario que tu aplicación inicie primero una solicitud. Esta es una excelente opción para las aplicaciones internas que cuentan con una conexión estable a la red. La biblioteca socket.io de Node.js también proporciona una "degradación elegante", ya que cuenta con una función de retroceso para las llamadas de Ajax
REST: tu front-end está ligeramente acoplado a su back-end (sin estados), no es posible la comunicación bidireccional y la aplicación tiene que iniciar cada solicitud. Esta es una buena opción para las aplicaciones que no requieren de sesiones, redes inestables,...
Ajax: aún se sigue utilizando ampliamente, y también sirve como una función de retroceso para las conexiones de WebSockets
Como primer ejemplo, presentaré las características de un back-end en Node.js usando el módulo QEWD:
crea un canal de comunicación seguro entre tu aplicación web y el back-end a través de WebSockets, de manera predeterminada, mediante la biblioteca que está incorporada en socket.io, y te permite cambiar al modo Ajax de forma transparente (¡sin que sea necesario modificar el código de tu aplicación!)
conecta el código de tu aplicación desde el back-end hacia tu base de datos en Caché
contiene un potente servidor Express REST estándar, que proporciona los servicios REST en el mismo servidor de back-end, y también te permite crear llamadas federadas hacia los servidores remotos subyacentes y combinarlo todo en una sola respuesta (¡incluso te permite interceptar y modificar la respuesta según tus propias necesidades!)
es completamente modular y se integra con los módulos de Node.js que ya existen; también le permite utilizar todos los demás módulos de Node.js en tus aplicaciones. Incluso te permite reemplazar el servidor Express por algún otro, como Ember.js
simplifica enormemente el desarrollo de código en el back-end, ya que resuelve el problema de la falta de sincronización durante la codificación en JavaScript: esto te permite escribir tu código de una manera completamente sincronizada
crea un procesamiento múltiple del back-end para ti, con tantos procesos de Node.js como sean necesarios - la funcionalidad de Node.js en sí no lo proporciona de manera predeterminada
te permite utilizar cualquier tipo de estructura del lado del cliente (front-end), como React, Angular, ExtJS, Vue.js,...
Antes de que empecemos, hay que tener en cuenta una consideración importante: en la parte 1 construimos una pequeña demo de una aplicación en React mediante el módulo create-react-app. Notarías que este módulo contiene un servidor de programación en Node.js que se ejecuta en el localhost:3000. Es importante tener en cuenta que este servidor únicamente sirve para el front-end - el servidor back-end QEWD que configuraremos aquí es un servidor back-end (para aplicaciones) completamente distinto y que se ejecuta por separado en un puerto diferente (normalmente en el localhost:8080 para el desarrollo). Durante el desarrollo, tanto el servidor de programación React en el puerto 3000 como el servidor para aplicaciones QEWD en el puerto 8080 se ejecutarán en la misma máquina, ¡no te confundas con los dos servidores! En producción, la situación será diferente: tu aplicación React se ejecutará desde el navegador del cliente y tu servidor QEWD recibirá en el servidor de Caché las conexiones que provengan del cliente.
A continuación, mostraré todos los pasos necesarios para comenzar nuestro ejemplo de una aplicación en React.
Primero, abre una línea de comandos en Windows para instalar QEWD en tu sistema:
Cuando se termine la instalación, verás un par de advertencias que puedes ignorar. Observa cómo el módulo QEWD utiliza los módulos Node.js que ya existen como bloques de construcción (echa un vistazo dentro de la carpeta C:\qewd\node_modules). El módulo qewd-monitor se utilizará más adelante para monitorizar tu servidor QEWD y el módulo cors será necesario para las solicitudes REST.
El QEWD necesita conectarse con Caché, por lo que debemos copiar el conector cache.node que usamos durante el primer script de prueba entre Node.js y Caché en C:\qewd\node_modules. Esto permitirá que QEWD inicie nuestros nuevos procesos o "procesos hijos" en Node.js, que se conectarán con Caché.
Solo necesitamos crear un pequeño script de inicio en JavaScript, que nos permita iniciar el servidor para aplicaciones QEWD. Primero, añade la carpeta del proyecto C:\qewd en tu editor Atom. Después, dentro de la carpeta C:\qewd, crea un nuevo archivo qewd-start.js y ábrelo para editarlo.
Copia/pega el siguiente código en este archivo y guárdalo:
// define the QEWD configuration (adjust directories if needed)
let config = {
managementPassword: 'keepThisSecret!',
serverName: 'My first QEWD Server',
port: 8080,
poolSize: 1,
database: {
type: 'cache',
params: {
path:"C:\\InterSystems\\Cache\\Mgr",
username: "_SYSTEM",
password: "SYS",
namespace: "USER"
}
}
};
// include the cors module to automatically add CORS headers to REST responses
let cors = require('cors');
// define the QEWD Node.js master process variable
let qewd = require('qewd').master;
// define the internal QEWD Express module instance
let xp = qewd.intercept();
// define a basic test path to test if our QEWD server is up- and running
xp.app.get('/testme', function(req, res) {
console.log('*** /testme query: ', req.query);
res.send({
hello: 'world',
query: req.query
});
});
// start the QEWD server now ...
qewd.start(config);
* Para tener una introducción completa al servidor para aplicaciones QEWD para Node.js/Caché, recomiendo consultar la documentación, disponible en el apartado "Training" en el menú superior.
Ahora podemos iniciar nuestro servidor para aplicaciones QEWD en la línea de comandos:
Si recibes alguna advertencia del firewall de Windows, concede permiso a los procesos de Node.js para que tengan acceso a la red.
Ahora abre Chrome, e instala la extensión (app) Advanced REST client (ARC) para depurar las solicitudes REST que enviaremos hacia nuestro servidor para aplicaciones.
Abre una nueva pestaña en la página y haz clic sobre la opción "Apps" en la barra de herramientas. Verás que la nueva extensión está disponible allí. Haz clic en el icono para iniciar la aplicación ARC.
Ahora escribe la url http://localhost:8080/testme?nodejs=hot&cache=cool en la solicitud de línea de texto que se encuentra en la parte superior y observa la respuesta del módulo QEWD/Express:
¡Enhorabuena! Si ves esta respuesta, tu servidor QEWD se inició satisfactoriamente ¡y el módulo Express en su interior también está funcionando!
Hasta ahora, aún no nos hemos conectado a Caché: solo probamos el proceso maestro QEWD, en el que se recibirán todas las solicitudes. Este proceso está recibiendo las conexiones de WebSockets y el módulo Express está listo para atender las solicitudes REST.
La primera opción que implementaremos ahora para acceder a nuestro back-end será mediante el servidor QEWD REST (consulta la documentación): crear un archivo para el módulo testrest.js dentro de C:\qewd\node_modules
module.exports = {
restModule: true,
handlers: {
isctest: function(messageObj, finished) {
// this isctest handler retrieves text from the ^nodeTest global and returns it
let incomingText = messageObj.query.text;
let nodeTest = new this.documentStore.DocumentNode('nodeTest');
let d = new Date();
let ts = d.getTime();
nodeTest.$(ts).value = incomingText;
finished({text: 'You sent: ' + incomingText + ' at ' + d.toUTCString()});
}
}
};
Guarda este archivo y edita el archivo qewd-start.js en C:\qewd. Aquí necesitamos añadir un endpoint para nuestro módulo REST:
// define the QEWD configuration (adjust directories if needed)
let config = {
managementPassword: 'keepThisSecret!',
serverName: 'My first QEWD Server',
port: 8080,
poolSize: 1,
database: {
type: 'cache',
params: {
path:"C:\\InterSystems\\Cache\\Mgr",
username: "_SYSTEM",
password: "SYS",
namespace: "USER"
}
}
};
// include the cors module to automatically add CORS headers to REST responses
let cors = require('cors');
// define the QEWD Node.js master process variable
let qewd = require('qewd').master;
// define the internal QEWD Express module instance
let xp = qewd.intercept();
// define a basic test path to test if our QEWD server is up- and running
xp.app.get('/testme', function(req, res) {
console.log('*** /testme query: ', req.query);
res.send({
hello: 'world',
query: req.query
});
});
// define REST endpoint for /testrest requests
xp.app.use('/testrest', cors(), xp.qx.router());
// start the QEWD server now ...
qewd.start(config);
La línea que añadimos enrutará todas las solicitudes que empiecen con la ruta /testrest hacia nuestro módulo testrest.js. Para activar la nueva ruta, es necesario que reiniciemos el servidor QEWD presionando Ctrl-C en la ventana de la línea de comandos y reiniciarlo:
* Ten en cuenta que incluso puedes reiniciar un servidor QEWD, cuando los clientes estén conectados, en caso de que lo necesites (no se recomienda hacer este procedimiento en un sistema ocupado): todas las conexiones de los clientes se reiniciarán/reconectarán automáticamente. Por cierto, también existe una manera más sencilla para añadir/(re)definir dinámicamente las rutas en un servidor QEWD que esté en ejecución, aunque esto requiere de un pequeño módulo de enrutamiento, que le proporcionará más flexibilidad sin la necesidad de detener el servidor QEWD.
Ahora, vuelve al ARC REST client y envía una nueva solicitud para http://localhost:8080/testrest/isctest?text=REST+call+to+cache
En la línea de comandos donde se está ejecutando el servidor QEWD, verás que aparecen mensajes de la llamada entrante:
Ahora puedes ver que QEWD comenzó un proceso de trabajo para esta solicitud. ¿Por qué? El proceso maestro (el servidor Express) recibe tu solicitud y se la entrega al middleware QEWD Express cors(), en primer lugar, para añadir los encabezados CORS y después para agregar la función de enrutamiento QEWD/REST xp.qx.router() en este momento, que añade la solicitud a la lista de solicitudes en espera e inicia un "proceso hijo" (el worker). Estos workers se encargan de gestionar tus solicitudes y procesan el código de tu aplicación (en testrest.js). Esto permite el procesamiento múltiple de las solicitudes, ya que QEWD puede iniciar tantos workers como sea necesario.
Probablemente te diste cuenta de que, en la salida del espacio de trabajo, el proceso maestro recibió la solicitud REST y entregó dicha solicitud al worker. Entonces, el worker carga el módulo de tu aplicación, llama al controlador de las solicitudes correcto y envia la respuesta.
Ahora que ya definimos un endpoint para QEWD REST, añadiremos una segunda opción para llamar a nuestro back-end utilizando WebSockets: crear un archivo para el módulo test.js en C:\qewd\node_modules, para procesar las solicitudes (mensajes) que entran mediante las conexiones de WebSockets:
module.exports = {
handlers: {
isctest: function(messageObj, session, send, finished) {
// get the text coming in from the message request
var incomingText = messageObj.params.text;
// instantiate the global node ^nodeTest as documentStore abstraction
let nodeTest = new this.documentStore.DocumentNode('nodeTest');
// get the current date & time
let d = new Date();
let ts = d.getTime();
// save the text from the request in the ^nodeTest global (subscripted by the current timestamp)
nodeTest.$(ts).value = incomingText;
// return the response to the client using WebSockets (or Ajax mode)
finished({text: 'You sent: ' + incomingText + ' at ' + d.toUTCString()});
}
}
};
Este controlador de solicitudes es casi igual al controlador de solicitudes REST, sin embargo, notarás que hay algunas diferencias sutiles: en los parámetros que definen las funciones del controlador, ahora están disponibles un objeto de sesión y un método send(). El método send() permite que el back-end envíe mensajes "push" hacia el front-end, y también tenemos un objeto de sesión ahora, porque las conexiones de WebSockets tienen estados.
No es posible probar este controlador de solicitudes de WebSockets mediante la herramienta ARC, porque necesitamos configurar una conexión de WebSockets para probarlo. En la siguiente parte, donde mejoraremos el front-end de nuestra aplicación en React, verás cómo funciona el controlador para iniciar una conexión de WebSockets con nuestro back-end QEWD.
Para tener información más detallada y formación sobre el funcionamiento del servidor QEWD/Express, te recomiendo que consultes la cdocumentación, disponible en el apartado "Training" en el menú superior.
La tercera opción para establecer una conexión con nuestro back-end es utilizar las llamadas CSP/REST: ve al portal del Sistema y en la sección Administración del sistema, ve a las Seguridad - Aplicaciones - Aplicaciones web y define una nueva aplicación web (consulta también la documentación sobre CSP/REST):
Abre Caché Studio, crea una clase App.TestRestHandler en el namespace USER y añade este código:
Class App.TestRestHandler Extends %CSP.REST
{
Parameter HandleCorsRequest = 1;
XData UrlMap
{
<Routes>
<Route Url="/isctest/:text" Method="GET" Call="GetIscTest"/>
</Routes>
}
ClassMethod GetIscTest(text As %String = "") As %Status
{
#Dim e as %Exception.AbstractException
#Dim status as %Status
Try {
Set d = $now()
Set ts = $zdt(d,-2)
Set ^nodeTest(ts) = text
If $Data(%response) Set %response.ContentType="application/json"
Write "{"
Write " ""text"" : ""You sent: ",text," at ",$zdt(d,5,1),""""
Write "}"
} Catch (e) {
Set status=e.AsStatus()
Do ..ErrorHandler(status)
}
Quit $$$OK
}
ClassMethod ErrorHandler(status)
{
#Dim errorcode, errormessage as %String;
set errorcode=$piece(##class(%SYSTEM.Status).GetErrorCodes(status),",")
set errormessage=##class(%SYSTEM.Status).GetOneStatusText(status)
Quit ..ErrorHandlerCode(errorcode,errormessage)
}
ClassMethod ErrorHandlerCode(errorcode, errormessage) As %Status
{
Write "{"
Write " ""ErrorNum"" : """,errorcode,""","
Write " ""ErrorMessage"" : """,errormessage,""""
write "}"
If $Data(%response) {
Set %response.ContentType="application/json"
}
quit $$$OK
}
}
* Gracias a Danny Wijnschenk por este ejemplo sobre CSP/REST
Vamos a probar este back-end REST también, usando ARC:
¡Enhorabuena! Hemos creado tres posibles maneras para establecer una conexión entre nuestro back-end y Caché:
utilizando el servidor para aplicaciones Node.js/QEWD/Express mediante llamadas REST
utilizando el servidor para aplicaciones Node.js/QEWD/Express mediante WebSockets (con funciones de retroceso opcionales para las llamadas de Ajax)
utilizando el puerto de enlace CSP/REST con Caché como el servidor para aplicaciones, mediante clases para el controlador CSP/REST
Como puedes ver, con Caché hay muchas maneras de lograr nuestro objetivo. Puedes decidir cuál de las opciones es la más apropiada para ti.
Si tú (o la mayoría de tu equipo de desarrollo) estás familiarizado con JavaScript y quieres desarrollar tu aplicación utilizando el mismo lenguaje, pero con los potentes frameworks de JavaScript para el front-end, y/o tu aplicación necesita las funciones o servicios externos que ya estén disponibles en los módulos de Node.js, entonces un servidor para aplicaciones Node.js que funcione con Caché es tu mejor opción, porque tendrás lo mejor de ambos mundos y podrás conservar y reutilizar tu código, las clases y el SQL en Caché. El servidor para aplicaciones QEWD se diseñó específicamente para escribir aplicaciones empresariales con Caché y es tu mejor opción para integrar el front-end y el back-end.
Si tu front-end está escrito en HTML simple, no estás utilizando los potentes frameworks de JavaScript y tu aplicación únicamente necesita llamadas REST hacia Caché, puedes conectarte directamente a Caché usando CSP/REST. Solamente recuerda que en este caso no podrás usar todos los módulos fácilmente disponibles de Node.js.
Ahora, ya estamos listos para la parte 3: ¡conectaremos el front-end de nuestra aplicación en React con los tres posibles back-ends!
Artículo
Kurro Lopez · 5 dic, 2019
¡Hola a tod@s!
En las partes anteriores (1, 2) de este artículo, hablamos de Globals como árboles. En esta tercera parte, los veremos como matrices dispersas.
Una matriz dispersa es un tipo de matriz donde la mayoría de los valores asumen un valor idéntico.
En la práctica, a menudo veréis matrices dispersas tan grandes que no tiene sentido ocupar memoria con elementos idénticos. Por lo tanto, tiene sentido organizar matrices dispersas de tal manera que no se desperdicie memoria al almacenar valores duplicados.
En algunos lenguajes de programación, las matrices dispersas son parte del lenguaje (por ejemplo, en J, MATLAB). En otros lenguajes, hay bibliotecas especiales que permiten usarlas. Para C ++, esos serían Eigen y similares.
Los Globals son buenos candidatos para implementar matrices dispersas por las siguientes razones:
Solo almacenan valores de nodos particulares y no almacenan valores indefinidos;
La interfaz de acceso para un valor de nodo es extremadamente similar a la que ofrecen muchos lenguajes de programación para acceder a un elemento de una matriz multidimensional.
Set ^a(1, 2, 3)=5
Write ^a(1, 2, 3)
Un Global es una estructura de nivel bastante bajo para almacenar datos, razón por la cual los Globals poseen características de rendimiento sobresalientes (cientos de miles a docenas de millones de transacciones por segundo dependiendo del hardware, ver 1)
Dado que una estructura Global es persistente, solo tiene sentido crear matrices dispersas sobre la base de situaciones en las que sabe de antemano que tendrá suficiente memoria para ellas.
Uno de los matices de la implementación de matrices dispersas es el retorno de un cierto valor por defecto si se dirige a un elemento indefinido.
Esto se puede implementar usando la función $GET en COS. Echemos un vistazo a una matriz tridimensional en este ejemplo.
SET a = $GET(^a(x,y,z), defValue)
Entonces, ¿qué tipo de tareas requieren matrices dispersas y cómo pueden ayudarlo los Globals?
Matriz de adyacencia
Tales matrices se utilizan para la representación gráfica:
Es obvio que cuanto más grande es un gráfico, más ceros habrá en la matriz. Si miramos un gráfico de una red social, por ejemplo, y lo representamos como una matriz o este tipo, consistirá principalmente en ceros, es decir, será una matriz dispersa.
Set ^m(id1, id2) = 1
Set ^m(id1, id3) = 1
Set ^m(id1, id4) = 1
Set ^m(id1) = 3
Set ^m(id2, id4) = 1
Set ^m(id2, id5) = 1
Set ^m(id2) = 2
....
En este ejemplo, guardaremos la matriz de adyacencia en el global ^m, así como el número de bordes de cada nodo (quién es amigo de quién y el número de amigos).
Si el número de elementos en el gráfico no supera los 29 millones (este número se calcula como 8 * longitud máxima del string), Incluso hay un método más económico para almacenar tales matrices: cadenas de bits, ya que optimizan los espacios grandes de una manera especial.
Las manipulaciones con cadenas de bits se llevan a cabo con la ayuda de la función $BIT .
; setting a bit
SET $BIT(rowID, positionID) = 1
; getting a bit
Write $BIT(rowID, positionID)
Tabla de conmutadores FSM
Dado que el gráfico de conmutadores FSM es un gráfico regular, la tabla de conmutadores FSM es esencialmente la misma matriz de adyacencia de la que hablamos anteriormente.
Autómata celular
El autómata celular más famoso es "El juego de la vida", donde las reglas (cuando una celda tiene muchos vecinos, muere) esencialmente la convierten en una matriz dispersa.
Stephen Wolfram cree que los autómatas celulares son un nuevo campo de la ciencia. En 2002, publicó un libro de 1280 páginas llamado "Un nuevo tipo de ciencia", donde afirma que los logros en el área de autómatas celulares no están aislados, pero son bastante estables y son importantes para todos los campos de la ciencia.
Se ha demostrado que cualquier algoritmo que pueda ser procesado por una computadora también puede implementarse con la ayuda de un autómata celular. Los autómatas celulares se utilizan para simular entornos y sistemas dinámicos, para resolver problemas algorítmicos y para otros fines.
Si tenemos un campo enorme y necesitamos registrar todos los estados intermedios de un autómata celular, tiene sentido usar Globals.
Cartografía
Lo primero que me viene a la mente cuando se trata de usar matrices dispersas es la cartografía.
Como regla general, los mapas tienen mucho espacio vacío. Si imaginamos que el mapa mundial se compone de píxeles grandes, veremos que el 71% de todos los píxeles de la Tierra estarán ocupados por una matriz dispersa del océano. Y si solo agregamos estructuras artificiales al mapa, habrá más del 95% del espacio vacío.
Por supuesto, nadie almacena mapas como matrices de mapas de bits, todos usan la representación vectorial en su lugar.¿Pero qué son los mapas vectoriales? Es una especie de marco junto con polilíneas y polígonos. En esencia, es una base de datos de puntos y relaciones entre ellos.
Una de las tareas más desafiantes en cartografía es la creación de un mapa de nuestra galaxia realizado por el telescopio Gaia. Hablando en sentido figurado, nuestra galaxia es un mamut de matriz dispersa : enormes espacios vacíos con puntos brillantes ocasionales: estrellas. Es 99,999999 .......% de espacio absolutamente vacío. Cache, una base de datos basada en Globals, fue seleccionada para almacenar el mapa de nuestra galaxia.
No sé la estructura exacta de Globals en este proyecto, pero puedo suponer que es algo así:
Set ^galaxy(b, l, d) = 1; star catalog number, if exists
Set ^galaxy(b, l, d, "name") = "Sun"
Set ^galaxy(b, l, d, "type") = "normal" ; Otras opciones pueden incluir un agujero negro, cuásar, enana roja y similar.
Set ^galaxy(b, l, d, "weight") = 14E50
Set ^galaxy(b, l, d, "planetes") = 7
Set ^galaxy(b, l, d, "planetes", 1) = "Mercury"
Set ^galaxy(b, l, d, "planetes", 1, weight) = 1E20
...
Donde b, l, d son coordenadas galácticas: latitud, longitud y distancia desde el sol.
La estructura flexible de Globals le permite almacenar cualquier característica de estrella y planeta, ya que las bases de datos globales no tienen esquemas.
Se seleccionó Caché para almacenar el mapa de nuestro universo no solo por su flexibilidad, sino también por su capacidad de guardar rápidamente un hilo de datos mientras se crean simultáneamente Globales de índice para una búsqueda rápida.
Si volvemos a la Tierra, se usaron Globals en proyectos centrados en mapas OpenStreetMap XAPI y FOSM, una bifurcación de OpenStreetMap.
Recientemente, en un hackathon de Caché, un grupo de desarrolladores implementó Geospatial indexes usando esta tecnología. Verr el artículo para mas detalles.
Implementación de índices geoespaciales usando Globals en OpenStreetMap XAPI
Se tomaron ilustraciones de esta presentación.
Todo el globo se divide en cuadrados, luego en subcuadros, luego en más subcuadros, y así sucesivamente. Al final, obtenemos una estructura jerárquica para la que se crearon Globals.
En cualquier momento, podemos solicitar instantáneamente cualquier cuadrado o vaciarlo, y todos los subcuadrados serán devueltos o vaciados también.
Un esquema detallado basado en Globals puede implementarse de varias maneras.
Variante 1:
Set ^m(a, b, a, c, d, a, b,c, d, a, b, a, c, d, a, b,c, d, a, 1) = idPointOne
Set ^m(a, b, a, c, d, a, b,c, d, a, b, a, c, d, a, b,c, d, a, 2) = idPointTwo
...
Variante 2:
Set ^m('abacdabcdabacdabcda', 1) = idPointOne
Set ^m('abacdabcdabacdabcda', 2) = idPointTwo
...
En ambos casos, no será un gran problema en COS/M solicitar puntos ubicados en un cuadrado de cualquier nivel. Será un poco más fácil limpiar segmentos cuadrados de espacio en cualquier nivel en la primera variante, pero esto rara vez se requiere.
Un ejemplo de un cuadrado de bajo nivel.:
Y aquí hay algunos Globals del proyecto XAPI: representación de un índice basado en Globals:
El Global ^way es utilizado para almacenar los vértices de polilíneas (caminos, ríos pequeños, etc.) y polígonos (áreas cerradas: edificios, bosques, etc.).
Una clasificación aproximada del uso de matrices dispersas en Globals.
Almacenamos las coordenadas de algunos objetos y su estado (cartografía, autómatas celulares).
Almacenamos matrices dispersas.
En la variante 2) cuando se solicita una determinada coordenada y no hay un valor asignado a un elemento, necesitamos obtener el valor predeterminado del elemento de la matriz dispersada.
Beneficios que obtenemos al almacenar matrices multidimensionales en Globals
Eliminación rápida y/o selección de segmentos de espacio que son múltiples de cadenas, superficies, cubos, etc.Para casos con índices enteros, puede ser conveniente poder eliminar rápidamente y/o seleccione segmentos de espacio que sean múltiples de cadenas, superficies, cubos y demás.
El comando Kill puede eliminar un elemento independiente, una cadena e incluso una superficie completa. Gracias a las propiedades de lo global, ocurre muy rápidamente, mil veces más rápido que la eliminación de elemento por elemento.
La ilustración muestra una matriz tridimensional en Global ^a y diferentes tipos de eliminaciones.
Para seleccionar segmentos de espacio por índices conocidos, puedes usar el comando Merge .
Selección de una columna de matriz en la variable Column:
; Let's define a three-dimensional 3x3x3 sparse array
Set ^a(0,0,0)=1,^a(2,2,0)=1,^a(2,0,1)=1,^a(0,2,1)=1,^a(2,2,2)=1,^a(2,1,2)=1
Merge Column = ^a(2,2)
; Let's output the Column variable
Zwrite Column
Output:
Column(0)=1
Column(2)=1
Lo interesante es que tenemos una matriz dispersa en la variable Column que puede abordar a través de $GET ya que los valores predeterminados no se almacenan allí.
La selección de segmentos de espacio también se puede hacer con la ayuda de un pequeño programa que utiliza la función $Order . Esto resulta especialmente útil en espacios con índices no cuantificados (cartografía).
Conclusión
Las realidades de hoy plantean nuevos desafíos. Los gráficos pueden consistir en miles de millones de vértices, los mapas pueden tener miles de millones de puntos, algunos incluso pueden querer lanzar su propio universo basado en autómatas celulares (1, 2).
Cuando el volumen de datos en matrices dispersas no puede exprimirse en la RAM, pero aún necesita trabajar con ellos, debe considerar implementar tales proyectos utilizando Globals y COS.
¡Gracias por su atención! Esperamos ver sus preguntas y solicitudes en la sección de comentarios.
Descargo de responsabilidad: Este artículo y mis comentarios reflejan solo mi opinión y no tienen nada que ver con la posición oficial de InterSystems Corporation.
Artículo
Alberto Fuentes · 7 abr, 2021
Hola a todos! Os traigo hoy un ejemplo de código que compartía [Robert Cemper](https://community.intersystems.com/user/robert-cemper-0) para mostrar por SQL los registros de error almacenados en `^ERRORS`.
Este es un ejemplo de código que funciona en Caché 2018.1.3 e IRIS 2020.2
No se mantendrá sincronizado con las nuevas versiones.
Es un ejemplo de código y como tal no está soportado por el Soporte de InterSystems
Los errores en IRIS/Caché/Ensemble se registran entre otros en la global `^ERRORS`. Como este mecanismo se remonta a muchas versiones atrás (décadas del milenio anterior!) su estructura está lejos de las estructuras de almacenamiento de SQL típicas.
El global se escribe mediante la rutina `^%ETN.int` y el contenido se hace visible desde la línea de comandos del terminal mediante la rutina `^%ERN` o en el Portal de Administración como *Log de Errores de la Aplicación*.
Por defecto no está disponible a través de SQL ya que no hay ninguna clase que lo presente como tabla. Por varias razones:
* Cuando se diseñó, era una buena práctica tener estructuras similares a índices en los mismos globals que los datos. Si digo "similares", significa que no sirve para SQL.
* El contenido de los objetos va a niveles más profundos que el resto. En consecuencia, la profundidad de los subíndices (normalmente IdKey) varía de 3 a 11.
`^ERRORS` es independiente en cada namespace.
Está estructurado por Day, SequenceByDay, Type, ItemName (Variable, OREF),Value.
**zrcc.ERRORStack** muestra esta información como tabla SQL.
El contenido más profundo de los objetos se hace visible por la consulta personalizada incluida.
El procedimiento SQL **zrcc.ERRORStack_Dump(Day,Sequence)** devuelve todo el contenido disponible y presenta subíndices y valores como se ve en la lista de globals.
A continuación veremos cómo sacar partido de estas utilidades:
Primero: localiza el día que te interese y el número de secuencia con la ayuda de SQL
Por ejemplo: `SELECT * FROM zrcc.ERRORStack where item='$ZE'`
```
Day Seq Stk Type Item Value
2020-07-02 1 0 V $ZE <WRITE>zSend+204^%Net.HttpRequest.1
2020-07-07 1 0 V $ZE <WRITE>zSend+204^%Net.HttpRequest.1
2020-07-15 1 0 V $ZE <WRITE>zSend+204^%Net.HttpRequest.1
2020-07-20 1 0 V $ZE <LOG ENTRY>
2020-07-26 1 0 V $ZE <WRITE>zSend+204^%Net.HttpRequest.1
```
A continuación, llama al procedimiento en SQL: `CALL zrcc.ERRORStack_Dump('2020-07-26',1)`
Row count: 541 Performance: 0.026 seconds 6557 global references
Ref Value
2020-07-26,1,"*STACK",0,"V","Routine") zSend+204^%Net.HttpRequest.1
2020-07-26,1,"*STACK",1,"I") 1^S^^^0^
2020-07-26,1,"*STACK",1,"L") 1 SIGN ON
2020-07-26,1,"*STACK",1,"S")
2020-07-26,1,"*STACK",1,"T") SIGN ON
2020-07-26,1,"*STACK",1,"V","%dsTrackingKeys","N","""Analyzer""") 6
2020-07-26,1,"*STACK",1,"V","%dsTrackingKeys","N","""Architect""") 7
2020-07-26,1,"*STACK",1,"V","%dsTrackingKeys","N","""DashboardViewer""") 8
2020-07-26,1,"*STACK",1,"V","%dsTrackingKeys","N","""ResultSet""") 9
2020-07-26,1,"*STACK",1,"V","%objcn") 2
2020-07-26,1,"*STACK",3,"V","Task") <OBJECT REFERENCE>[1@%SYS.Task]
2020-07-26,1,"*STACK",3,"V","Task","OREF",1) 142
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,0) 3671
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,1) +----------------- general information ---------------
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,2) | oref value: 1
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,3) | class name: %SYS.Task
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,4) | %%OID: $lb("13","%SYS.Task")
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,5) | reference count: 5
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,6) +----------------- attribute values ------------------
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,7) | %Concurrency =
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,8) 4 <Set>
- - -
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,53) | EmailOutput =
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,54) 0
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,55) | EndDate =
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,56) ""
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,57) | Error =
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,58) "<WRITE>zSend+204^%Net.HttpRequest.1"
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,59) | Expires =
- - -
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,111) | Status =
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,112) "0 "_$lb($lb(5002,"POST to Server Failed",,,,,,,,$lb(,"%SYS",$lb("$^zSend+204^%Net.HttpRequest.1 +1","$^zPost+1^%Net.HttpRequest.1 +1","$^zSendData+20^FT.Collector.1 +1","$^zTransfer+12^FT.Collector.1 +1","$^zOnTask+3^%SYS.Task.FeatureTracker.1 +1","D^zRunTask+74^%SYS.TaskSuper.1 +1","$^zRunTask+54^%SYS.TaskSuper.1 +1","D^zRun+26^%SYS.TaskSuper.1 +1"))),$lb(6085,"ISC.FeatureTracker.SSL.Config","SSL/TLS error in SSL_connect(), SSL_ERROR_SSL: protocol error, error:14090086:SSL routines:ssl3_get_server_certificate:certificate verify failed",,,,,,,$lb(,"%SYS",$lb("e^zSend+303^%Net.HttpRequest.1^1","e^zPost+1^%Net.HttpRequest.1^1","e^zSendData+20^FT.Collector.1^1","e^zTransfer+12^FT.Collector.1^1","e^zOnTask+3^%SYS.Task.FeatureTracker.1^1","e^zRunTask+74^%SYS.TaskSuper.1^1","d^zRunTask+54^%SYS.TaskSuper.1^1","e^zRun+26^%SYS.TaskSuper.1^1","d^^^0"))))/* ERROR #5002: Cache error: POST to Server Failed- ERROR #6085: Unable to write to socket with SSL/TLS configuration 'ISC.FeatureTracker.SSL.Config', error reported 'SSL/TLS error in SSL_connect(), SSL_ERROR_SSL: protocol error, error:14090086:SSL routines:ssl3_get_server_certificate:certificate verify failed' */
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,113) | SuspendOnError =
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,114) 0
2020-07-26,1,"*STACK",3,"V","Task","OREF",1,115) | Suspended =
- - -
2020-07-26,1,"*STACK",6,"V","Status1") 1
2020-07-26,1,"*STACK",6,"V","Task") <OBJECT REFERENCE>[1@%SYS.Task]
2020-07-26,1,"*STACK",6,"V","Task","OREF",1) 142
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,0) 3671
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,1) +----------------- general information ---------------
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,2) | oref value: 1
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,3) | class name: %SYS.Task
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,4) | %%OID: $lb("13","%SYS.Task")
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,5) | reference count: 5
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,6) +----------------- attribute values ------------------
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,7) | %Concurrency =
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,8) 4 <Set>
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,9) | DailyEndTime =
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,10) 0
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,11) | DailyFrequency =
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,12) 0
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,13) | DailyFrequencyTime =
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,14) ""
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,15) | DailyIncrement =
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,16) ""
2020-07-26,1,"*STACK",6,"V","Task","OREF",1,17) | DailyStartTime =
- - -
2020-07-26,1,"*STACK",12,"V","%00000","N","""JournalState""") 12
2020-07-26,1,"*STACK",13,"I") 13^Z^ETNERRB^%ETN^0
2020-07-26,1,"*STACK",13,"L") 13 ERROR TRAP S $ZTRAP="ETNERRB^%ETN"
2020-07-26,1,"*STACK",13,"S") S $ZTRAP="ETNERRB^%ETN"
2020-07-26,1,"*STACK",13,"T") ERROR TRAP
541 row(s) affected
Artículo
Alberto Fuentes · 14 jun, 2023
## Qué es el Web Scraping:
En términos sencillos, el **Web scraping**, también conocido como **recolección de datos de sitios web** o **extracción de datos de sitios web** es un proceso automatizado que permite la recopilación de grandes volúmenes de datos (no estructurados) de los sitios web. El usuario puede extraer datos de sitios web específicos, según sus necesidades. Los datos recopilados se pueden almacenar en un formato estructurado para su posterior análisis.
##
**Pasos necesarios para realizar Web scraping:**
1. Encontrar la URL de la página web de la que se desean extraer los datos
2. Seleccionar ciertos elementos mediante una inspección
3. Escribir el código para obtener el contenido de los elementos seleccionados
4. Almacenar los datos en el formato requerido
¡¡Así de sencillo!!
## **Las librerías/herramientas más populares para realizar Web scraping son:**
* Selenium: un *framework* para probar aplicaciones web
* BeautifulSoup: una librería de Python para obtener datos a partir de HTML, XML y otros lenguajes de marcado
* Pandas: una librería de Python para manipulación y análisis de datos
##¿Qué es Beautiful Soup?
Beautiful Soup es una librería de Python que sirve para extraer datos estructurados de un sitio web. Permite analizar datos a partir de archivos HTML y XML. Funciona como un módulo de ayuda e interactúa con HTML de forma similar pero mejor a como interactuarías con una página web utilizando otras herramientas disponibles para desarrolladores.
* Por lo general, ahorra horas o días de trabajo a los programadores, porque funciona con analizadores muy conocidos, como `lxml` y `html5lib`, para ofrecer formas compatibles con Python para navegar, efectuar búsquedas y modificar el árbol de análisis de elementos de la página.
* Otra potente y útil característica de Beautiful soup es la inteligencia con la que cuenta para convertir a Unicode los documentos obtenidos y a UTF-8 los documentos de salida. Como desarrollador, no tienes que ocuparse de eso a menos que el documento en sí no especifique una codificación o BeautifulSoup no pueda detectar una.
* También se considera que es más **rápido** en comparación con otras técnicas generales de análisis o extracción de datos.
## **En este artículo utilizaremos Python Embebido con ObjectScript para extraer de ae.indeed.com empresas y ofertas de empleo de Python**
**Paso 1 - Encontrar la URL de la página web de la que se desean extraer los datos**
URL = https://ae.indeed.com/jobs?q=python&l=Dubai&start=0
La página web de la que extraeremos los datos se ve así:
.png)
**_Para simplificar el proceso y con fines educativos, extraeremos los datos "Job" (Puesto de trabajo) y "Company" (Empresa). El resultado sería algo similar esto:_**
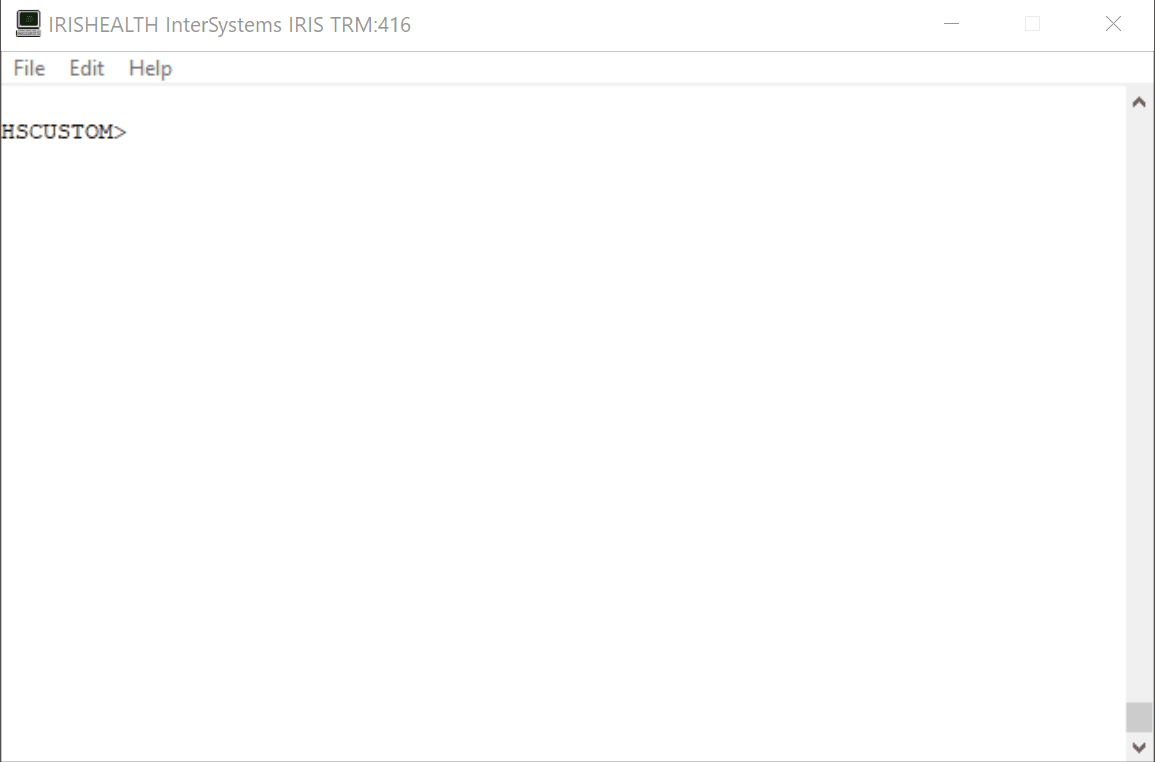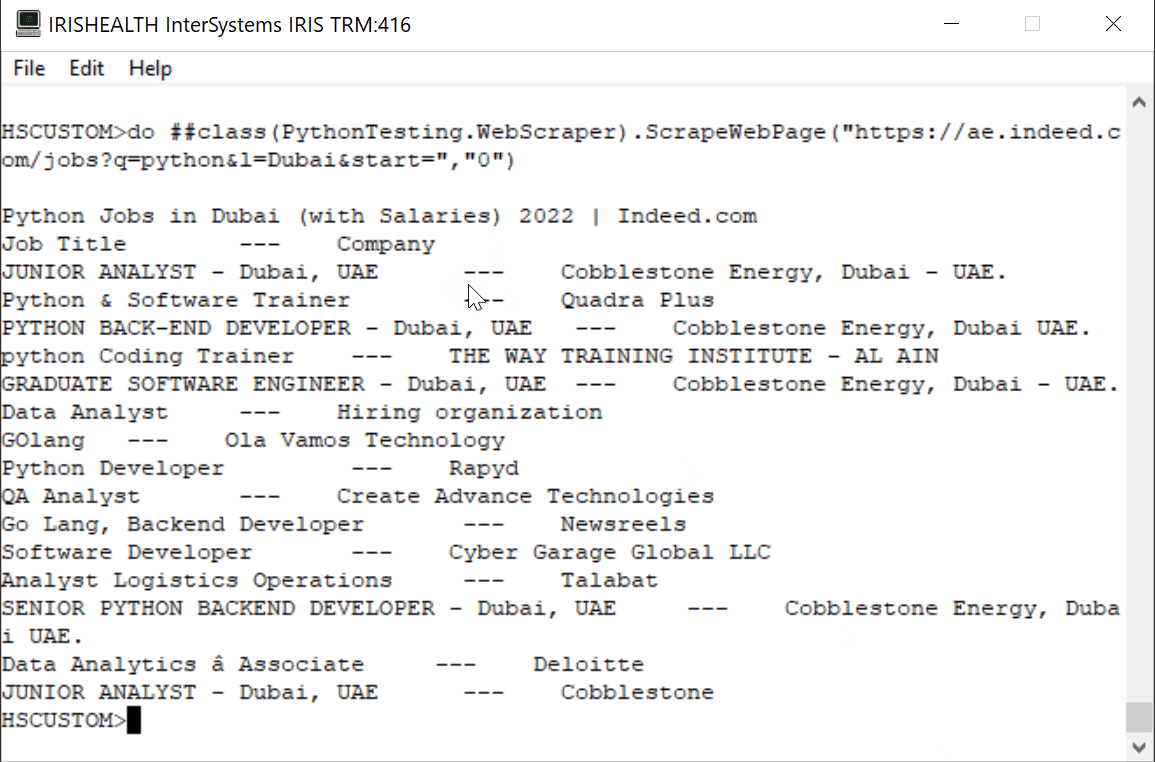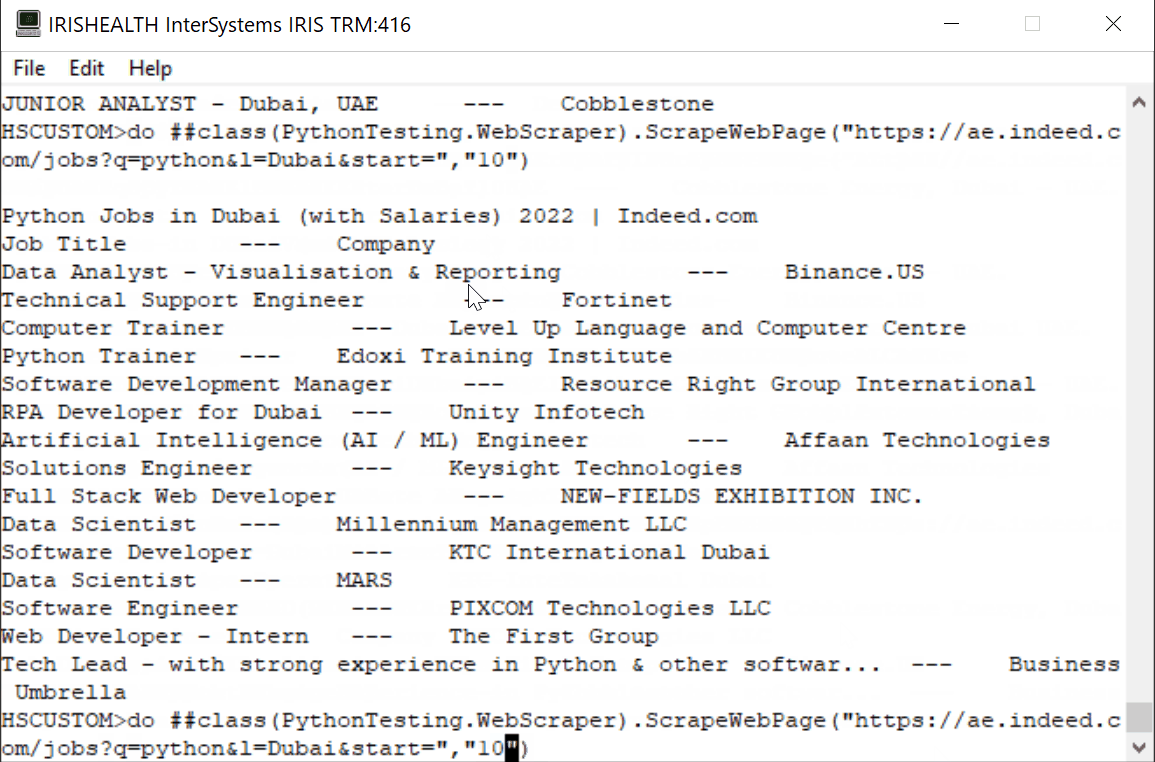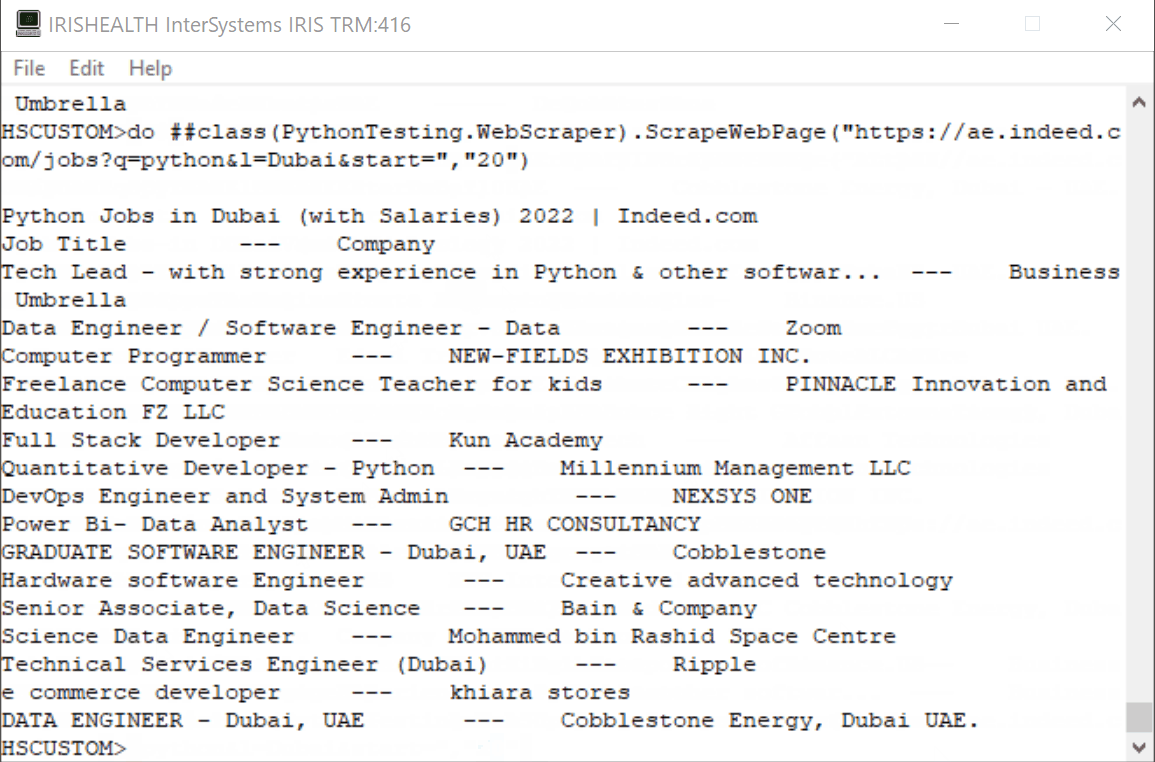
**Utilizaremos dos librerías de Python.**
* **requests** Requests es una librería HTTP para el lenguaje de programación Python. El objetivo del proyecto es hacer que las solicitudes HTTP sean más sencillas y amigables para el usuario.
* **bs4 para BeautifulSoup** BeautifulSoup es un paquete de Python para analizar documentos HTML y XML. Crea un árbol de análisis para las páginas analizadas, que puede utilizarse para extraer datos de HTML, lo que es útil para el proceso de *web scraping*.
**Vamos a instalar estos paquetes de Python (en Windows)**
irispip install --target C:\InterSystems\IRISHealth\mgr\python bs4
irispip install --target C:\InterSystems\IRISHealth\mgr\python requests
.png)
**Ahora importaremos las librerías de Python a ObjectScript**
<span class="hljs-keyword">Class</span> PythonTesting.WebScraper <span class="hljs-keyword">Extends</span> <span class="hljs-built_in">%Persistent</span>
{
<span class="hljs-comment">// pUrl = https://ae.indeed.com/jobs?q=python&l=Dubai&start=</span>
<span class="hljs-comment">// pPage = 0</span>
<span class="hljs-keyword">ClassMethod</span> ScrapeWebPage(pUrl, pPage)
{
<span class="hljs-comment">// imports the requests python library</span>
<span class="hljs-keyword">set</span> requests = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"requests"</span>)
<span class="hljs-comment">// import the bs4 python library</span>
<span class="hljs-keyword">set</span> soup = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"bs4"</span>)
<span class="hljs-comment">// import builtins package which contains all of the built-in identifiers</span>
<span class="hljs-keyword">set</span> builtins = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"builtins"</span>)
}
**Recopilamos los datos HTML utilizando la librería requests**
_Nota: El "user agent" se encontró buscando en Google "my user agent"_
_La URL es "https://ae.indeed.com/jobs?q=python&l=Dubai&start=", donde pPage es el número de página_
Haremos una solicitud HTTP GET a la URL usando requests y almacenaremos la respuesta en "req"
<span class="hljs-keyword">set</span> headers = {<span class="hljs-string">"User-Agent"</span>: <span class="hljs-string">"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"</span>}
<span class="hljs-keyword">set</span> url = <span class="hljs-string">"https://ae.indeed.com/jobs?q=python&l=Dubai&start="</span>_pPage
<span class="hljs-keyword">set</span> req = requests.get(url,<span class="hljs-string">"headers="</span>_headers)
El objeto "req" tendrá el HTML que fue devuelto desde la página web.
**Ahora ejecutaremos el analizador de HTML de BeautifulSoup, para que podamos extraer la información del puesto de trabajo.**
<span class="hljs-keyword">set</span> soupData = soup.BeautifulSoup(req.content, <span class="hljs-string">"html.parser"</span>)
<span class="hljs-keyword">set</span> title = soupData.title.text
<span class="hljs-keyword">W</span> !,title
**El título se ve de la siguiente manera:**
.png)
**Paso 2: Seleccionar ciertos elementos mediante una inspección.**
En este escenario nos interesa la lista de trabajos que normalmente se encuentra en una etiqueta < div >. En el navegador se puede inspeccionar el elemento para encontrar la clase "div".
En nuestro caso, la información necesaria se almacena en <div class="cardOutline tapItem ...
**Paso 3: Escribir el código para obtener el contenido de los elementos seleccionados**
Utilizaremos la función find_all de BeautifulSoup para buscar todas las etiquetas < div > que contengan la clase con el nombre "cardOutline".
<span class="hljs-comment">//parameters to python would be sent as a python dictionary</span>
<span class="hljs-keyword">set</span> divClass = {<span class="hljs-string">"class"</span>:<span class="hljs-string">"cardOutline"</span>}
<span class="hljs-keyword">set</span> divsArr = soupData.<span class="hljs-string">"find_all"</span>(<span class="hljs-string">"div"</span>,divClass...)
Esto devolverá una lista que podremos examinar para extraer los Puestos de trabajo y la Empresa.
Paso 4: Almacenar los datos en el formato requerido
En el siguiente ejemplo escribiremos los datos en el terminal.
<span class="hljs-keyword">set</span> len = builtins.len(divsArr)
<span class="hljs-keyword">W</span> !, <span class="hljs-string">"Job Title"</span>,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>)_<span class="hljs-string">" --- "</span>_<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),<span class="hljs-string">"Company"</span>
<span class="hljs-keyword">for</span> i = <span class="hljs-number">1</span>:<span class="hljs-number">1</span>:len {
<span class="hljs-keyword">Set</span> item = divsArr.<span class="hljs-string">"__getitem__"</span>(i - <span class="hljs-number">1</span>)
<span class="hljs-keyword">set</span> title = <span class="hljs-built_in">$ZSTRIP</span>(item.find(<span class="hljs-string">"a"</span>).text,<span class="hljs-string">"<>W"</span>)
<span class="hljs-keyword">set</span> companyClass = {<span class="hljs-string">"class_"</span>:<span class="hljs-string">"companyName"</span>}
<span class="hljs-keyword">set</span> company = <span class="hljs-built_in">$ZSTRIP</span>(item.find(<span class="hljs-string">"span"</span>, companyClass...).text,<span class="hljs-string">"<>W"</span>)
<span class="hljs-keyword">W</span> !,title,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),<span class="hljs-string">" --- "</span>,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),company
}
Hay que tener en cuenta que estamos usando la función builtins.len() para obtener la longitud de la lista divsArr
Nombres de los identificadores:
Las reglas para nombrar a los identificadores son diferentes entre ObjectScript y Python. Por ejemplo, el guion bajo (_) está permitido en el nombre de los métodos de Python, y de hecho se utiliza ampliamente para los llamados métodos y atributos “dunder” (“dunder” es la abreviatura de “double underscore”), como __getitem__ o __class__. Para usar estos identificadores desde ObjectScript, hay que ponerlos entre comillas dobles:Documentación sobre los nombres de los identificadores
Ejemplo de Método de Clase.
ClassMethod ScrapeWebPage(pUrl, pPage)
<span class="hljs-comment">// pUrl = https://ae.indeed.com/jobs?q=python&l=Dubai&start=</span>
<span class="hljs-comment">// pPage = 0</span>
<span class="hljs-keyword">ClassMethod</span> ScrapeWebPage(pUrl, pPage)
{
<span class="hljs-keyword">set</span> requests = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"requests"</span>)
<span class="hljs-keyword">set</span> soup = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"bs4"</span>)
<span class="hljs-keyword">set</span> builtins = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Builtins()
<span class="hljs-keyword">set</span> headers = {<span class="hljs-string">"User-Agent"</span>: <span class="hljs-string">"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"</span>}
<span class="hljs-keyword">set</span> url = pUrl_pPage
<span class="hljs-keyword">set</span> req = requests.get(url,<span class="hljs-string">"headers="</span>_headers)
<span class="hljs-keyword">set</span> soupData = soup.BeautifulSoup(req.content, <span class="hljs-string">"html.parser"</span>)
<span class="hljs-keyword">set</span> title = soupData.title.text
<span class="hljs-keyword">W</span> !,title
<span class="hljs-keyword">set</span> divClass = {<span class="hljs-string">"class_"</span>:<span class="hljs-string">"cardOutline"</span>}
<span class="hljs-keyword">set</span> divsArr = soupData.<span class="hljs-string">"find_all"</span>(<span class="hljs-string">"div"</span>,divClass...)
<span class="hljs-keyword">set</span> len = builtins.len(divsArr)
<span class="hljs-keyword">W</span> !, <span class="hljs-string">"Job Title"</span>,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>)_<span class="hljs-string">" --- "</span>_<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),<span class="hljs-string">"Company"</span>
<span class="hljs-keyword">for</span> i = <span class="hljs-number">1</span>:<span class="hljs-number">1</span>:len {
<span class="hljs-keyword">Set</span> item = divsArr.<span class="hljs-string">"__getitem__"</span>(i - <span class="hljs-number">1</span>)
<span class="hljs-keyword">set</span> title = <span class="hljs-built_in">$ZSTRIP</span>(item.find(<span class="hljs-string">"a"</span>).text,<span class="hljs-string">"<>W"</span>)
<span class="hljs-keyword">set</span> companyClass = {<span class="hljs-string">"class_"</span>:<span class="hljs-string">"companyName"</span>}
<span class="hljs-keyword">set</span> company = <span class="hljs-built_in">$ZSTRIP</span>(item.find(<span class="hljs-string">"span"</span>, companyClass...).text,<span class="hljs-string">"<>W"</span>)
<span class="hljs-keyword">W</span> !,title,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),<span class="hljs-string">" --- "</span>,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),company
}
}
Próximos pasos...
Usando Object Script y Python Embebido y creando unas pocas líneas de código, podríamos extraer fácilmente la información de las páginas web más populares para buscar trabajo, recoger el nombre del puesto de trabajo, la empresa, el sueldo, la descripción del trabajo y correos electrónicos/enlaces.
Esta información se puede añadir a un DataFrame de Pandas para eliminar los datos duplicados. Se pueden aplicar filtros basados en ciertas palabras clave que interesen.
Se pueden ejecutar estos datos a través de NumPy y obtener algunos gráficos de líneas.
O realizar una One-Hot encoding de los datos, y crear/entrenar modelos de Machine Learning para que si hay puestos de trabajo que interesan particularmente, envíen una notificación. 😉
¡Feliz desarrollo!
Artículo
Ricardo Paiva · 15 mayo, 2020
¡Hola desarrollador!
Si has leído la parte 1 de este artículo, ya tienes una buena idea del tipo de índices que necesitas para tus clases y cómo definirlos. Lo siguiente es saber cómo gestionarlos.
Plan de consultas
(RECUERDA: Al igual que cualquier modificación en una clase, añadir índices en un sistema en producción conlleva riesgos: si los usuarios están actualizando o accediendo a datos mientras se rellena un índice, podrían obtener resultados vacíos o incorrectos a sus consultas, o incluso dañar los índices que se están formando. Ten en cuenta que hay pasos adicionales para definir y usar índices en un sistema en producción. Estos pasos se analizarán en esta sección, y se detallan en nuestra documentación).
Cuando tengas un nuevo índice implementado, podemos ver si el optimizador de SQL decide que es el más eficiente para leer, al ejecutar la consulta. No hay que ejecutar la consulta para verificar el plan. Dada una consulta, puedes verificar el plan de forma programática:
Set query = 1
Set query(1) = “SELECT SSN,Name FROM Sample.Person WHERE Office_State = 'MA'”
D $system.SQL.ShowPlan(.query)
O siguiendo la interfaz en el Portal de Administración del Sistema desde System Explorer -> SQL.
Desde aquí, se puede ver qué índices están siendo usados antes de cargar los datos de la tabla (o "mapa maestro"). Ten en cuenta lo siguiente: ¿tu nueva consulta está en el plan tal como se esperaba? ¿La lógica del plan tiene sentido?
Una vez sepas que el optimizador SQL está usando tus índices, puedes verificar que estos índices están funcionando correctamente.
Construcción de índices
(Si aún estás en las fases de planificación y todavía no tienes datos, los pasos detallados aquí no serán necesarios ahora.)
Definir un índice no lo poblará o "construirá" automáticamente con los datos de tu tabla. Si el plan de consulta usa un índice que aún no se ha construido, corres el riesgo de obtener resultados incorrectos o vacíos a la consulta. Para "desactivar" un índice antes de que esté listo para usar, pon su elegibilidad de mapa en 0 (esto básicamente le indica al optimizador SQL que no puede usar este índice para ejecutar consultas).
write $SYSTEM.SQL.SetMapSelectability("Sample.Person","QuickSearchIDX",0) ; Set selectability of index QuickSearchIDX false
Ten en cuenta que puedes usar la llamada de arriba incluso antes de que añadas un nuevo índice. El optimizador SQL reconocerá este nuevo nombre del índice, sabrá que está inactivo y no lo usará para ninguna consulta.
Puedes rellenar un índice usando el método %BuildIndices (##class(<class>).%BuildIndices($lb("MyIDX"))) o en la página SQL del Portal de Administración del Sistema (bajo el menú desplegable "Actions").
El tiempo necesario para construir índices depende de la cantidad de filas de la tabla y de los tipos de índices que estás construyendo. Los índices bitslices generalmente requieren de más tiempo.
Una vez completado el proceso, puedes usar el método SetMapSelectivity una vez más (esta vez ajuste en 1) para reactivar tu índice ahora poblado.
Ten en cuenta que construir índices significa esencialmente emitir comandos KILL y SET para poblarlos. Puedes considerar desactivar journaling durante este proceso para evitar llenar el espacio de disco.
Puedes encontrar instrucciones más detalladas sobre construir índices, en particular en sistemas en producción, en nuestra documentación:
https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQLOPT_indices#GSQLOPT_indices_build_readwrite
Mantenimiento de índices
¡Ahora ya podemos usar nuestros índices! Algunos puntos a considerar son la eficiencia de ejecución de una consulta, la frecuencia de uso de un índice dado y los pasos a tomar si tus índices entran en un estado inconsistente.
Rendimiento
Primero, podemos evaluar cómo ha afectado este índice el rendimiento de la consulta. Si sabemos que el optimizador SQL está usando un nuevo índice para una consulta, podemos ejecutar la consulta para obtener sus estadísticas de desempeño: número de referencias globales, número de líneas leídas, tiempo para preparar y ejecutar la consulta y tiempo empleado en el disco.
Volvamos al ejemplo anterior:
“SELECT SSN,Name,DOB FROM Sample.Person WHERE Name %STARTSWITH 'Smith,J'”
Tenemos el siguiente índice para ayudar al desempeño de esta consulta:
Index QuickSearchIDX On Name [ Data = (SSN, DOB, Name) ];
Ya tenemos un índice NameIDX en la propiedad Name.
Intuitivamente, nos damos cuenta de que la consulta se ejecutará usando QuickSearchIDX. NameIDX seguramente sería una segunda opción, ya que está basado en la propiedad Name, pero no contiene ninguno de los valores de datos para SSN o DOB.
Para comprobar el rendimiento de esta consulta con QuickSearchIDX, basta con ejecutarla.
(Por otra parte: he depurado las consultas en caché antes de ejecutar estas consultas para mostrar mejor las diferencias de rendimiento. Cuando se ejecuta una consulta SQL, almacenamos el plan usado para ejecutarla, lo que mejora el rendimiento en su próxima ejecución. Los detalles de esto están fuera del alcance de este artículo, pero al final de este artículo incluiré recursos adicionales para otras consideraciones de desempeño de SQL.)
Cantidad de filas: 31 Rendimiento: 0.003 segundos 154 referencias globales 3264 líneas ejecutadas 1 latencia de lectura de disco (ms)
Simple: solo necesitamos QuickSearchIDX para ejecutar la consulta.
Vamos a comparar el desempeño de usar NameIDX en lugar de QuickSearchIDX. Para hacer esto podemos añadir una palabra clave %IGNOREINDEX para la consulta, que evitará que el optimizador SQL elija ciertos índices.
Reescribimos la consulta de la siguiente forma:
“SELECT SSN,Name,DOB FROM %IGNOREINDEX QuickSearchIDX Sample.Person WHERE Name %STARTSWITH 'Smith,J'”
El plan de consulta ahora usa NameIDX, y vemos que debemos leer desde el global de datos (“mapa maestro”) de Sample.Person usando los IDs de filas relevantes, encontrados mediante el índice.
Cantidad de filas: 31 Rendimiento: 0.020 segundos 137 referencias globales 3792 líneas ejecutadas 17 latencia de lectura de disco (ms)
Vemos que es necesario más tiempo para la ejecución, más líneas de código ejecutadas y una mayor latencia de disco.
A continuación, considera ejecutar esta consulta sin ningún índice. Ajustamos nuestra consulta de la siguiente forma:
“SELECT SSN,Name,DOB FROM %IGNOREINDEX * Sample.Person WHERE Name %STARTSWITH 'Smith,J'”
Sin usar índices, debemos comprobar nuestra condición en las filas de datos.
Cantidad de filas: 31 Rendimiento: 0.765 seconds 149999 referencias globales 1202681 líneas ejecutadas 517 latencia de lectura de disco (ms)
Esto muestra que un índice especializado, QuickSearchIDX, permite a nuestra consulta ejecutarse más de 100 veces más rápido que sin índice y casi 10 veces más rápido que con el más general NameIDX, y usar NameIDX permite una ejecución al menos 30 veces más rápido que sin usar índices.
Para este ejemplo específico, la diferencia de rendimiento entre usar QuickSearchIDX y NameIDX puede ser despreciable, pero para consultas que se ejecutan cientos de veces por día con millones de filas a consultar, veríamos que se ahorra un tiempo muy valioso cada día.
Análisis de índices existentes usando SQLUtilites
%SYS.PTools.SQLUtilities incluye procedimientos como IndexUsage, JoinIndices, TablesScans y TempIndices. Estos analizan las consultas existentes en cualquier namespace dado y ofrecen información sobre la frecuencia de uso de cualquier índice dado, qué consultas eligen iterar sobre cada fila de una tabla y qué consultas generan archivos temporales para simular índices.
Puedes usar estos procedimientos para determinar "gaps" (falta de datos) que un índice podría solucionar. De igual manera puedes usar estos procedimientos para eliminar algún indice que no se utilice o que no sea eficiente.
Puedes encontrar detalles de estos procedimientos y ejemplos de su uso en nuestra documentación:
https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQLOPT_optquery_indexanalysis
¿Problemas de índices?
Validar índices confirma si un índice existe y está definido correctamente para cada fila de una clase. Ninguna clase debería entrar en un estado en el que los índices estén dañados, pero si descubres que las consultas están devolviendo conjuntos de resultados vacíos o incorrectos, podrías considerar verificar si los índices de las clases existentes son válidos actualmente.
Puedes validar índices de forma programática así:
Set status = ##class(<class>).%ValidateIndices(indices,autoCorrect,lockOption,multiProcess)
Aquí, el parámetro "índices" es una cadena vacía de forma predeterminada, lo que significa que validamos todos los índices o un objeto $listbuild que contenga los nombres de índices.
Ten en cuenta que autoCorrect tiene como valor predeterminado 0. Si es 1, cualquier error encontrado durante el proceso de validación será corregido. Si bien esta funcionalidad es la misma que reconstruir los índices, el rendimiento de ValidateIndices es más lento comparativamente.
Puedes consultar la documentación de la clase %Library.Storage para más información:
https://docs.intersystems.com/latest/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25Library.Storage#%ValidateIndices
Eliminación de índices
Si ya no necesitas un índice (o si estás planeando hacer una gran cantidad de modificaciones a una tabla y quieres guardar para más tarde el impacto sobre el rendimiento de construir los índices relevantes) puedes simplemente eliminar la definición del índice de la clase en Studio y eliminar el nodo global de índice apropiado. O puedes ejecutar un comando DROP INDEX vía DDL, lo que también limpiará la definición y los datos del índice. Desde ahí, puedes depurar las consultas en caché para asegurarte de que ningún plan existente use el índice ya eliminado.
¿Y ahora qué?
Los índices son solo una parte del desempeño de SQL. En este mismo sentido, existen otras opciones para monitorizar el rendimiento y el uso de tus índices. Para entender el desempeño de SQL, también puedes aprender:Tune Tables – una herramienta que se ejecuta una vez poblada una tabla con datos representativos o si la distribución de los datos cambia radicalmente. Esto llena la definición de tu clase con metadatos. Por ejemplo, qué longitud esperamos que tenga un campo o cuántos valores únicos hay en un campo, lo que ayuda al optimizador SQL a elegir un plan de consulta que permita una ejecución eficiente.
Kyle Baxter escribió un artículo sobre esto: https://community.intersystems.com/post/one-query-performance-trick-you-need-know-tune-table
Query Plans – la representación lógica de cómo nuestro código subyacente ejecuta consultas SQL. Si tienes una consulta lenta, podemos analizar qué plan de consulta se está generando, si tiene sentido para tu consulta y qué se puede hacer para optimizar más este plan.
Cached queries – Declaraciones SQL dinámicas preparadas – las consultas guardadas en caché son esencialmente el código subyacente de los planes de consulta.cached queries are essentially the code underneath query plans.
Para saber más
Parte 1 de este artículo.
Documentación sobre definición y construcción de índices. Incluye pasos adicionales a considerar en sistemas de lectura-escritura en producción. https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQLOPT_indices
Comandos SQL ISC: vea CREATE INDEX y DROP INDEX por referencias sintácticas de manejo de índices vía DDL. Incluye permisos de usuario adecuados para ejecutar estos comandos. https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=RSQL_COMMANDS
Detalles sobre Collation SQL en clases ISC. De forma predeterminada, los valores de cadenas se almacenan en globales de índices como SQLUPPER (“ STRING”): https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_collation
[EDIT 05/06/2020: Corrections on index build performance and the DROP INDEX command.] Este artículo ha sido etiquetado como "Best practices"
(Los artículos con la etiqueta "Best practices" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).