Introducción al Web Scraping con Python Embebido - cómo extraer ofertas de trabajo de Python
Qué es el Web Scraping:
En términos sencillos, el Web scraping, también conocido como recolección de datos de sitios web o extracción de datos de sitios web es un proceso automatizado que permite la recopilación de grandes volúmenes de datos (no estructurados) de los sitios web. El usuario puede extraer datos de sitios web específicos, según sus necesidades. Los datos recopilados se pueden almacenar en un formato estructurado para su posterior análisis.
Pasos necesarios para realizar Web scraping:
- Encontrar la URL de la página web de la que se desean extraer los datos
- Seleccionar ciertos elementos mediante una inspección
- Escribir el código para obtener el contenido de los elementos seleccionados
- Almacenar los datos en el formato requerido
¡¡Así de sencillo!!
Las librerías/herramientas más populares para realizar Web scraping son:
- Selenium: un framework para probar aplicaciones web
- BeautifulSoup: una librería de Python para obtener datos a partir de HTML, XML y otros lenguajes de marcado
- Pandas: una librería de Python para manipulación y análisis de datos
##¿Qué es Beautiful Soup?
Beautiful Soup es una librería de Python que sirve para extraer datos estructurados de un sitio web. Permite analizar datos a partir de archivos HTML y XML. Funciona como un módulo de ayuda e interactúa con HTML de forma similar pero mejor a como interactuarías con una página web utilizando otras herramientas disponibles para desarrolladores.
- Por lo general, ahorra horas o días de trabajo a los programadores, porque funciona con analizadores muy conocidos, como
lxmlyhtml5lib, para ofrecer formas compatibles con Python para navegar, efectuar búsquedas y modificar el árbol de análisis de elementos de la página. - Otra potente y útil característica de Beautiful soup es la inteligencia con la que cuenta para convertir a Unicode los documentos obtenidos y a UTF-8 los documentos de salida. Como desarrollador, no tienes que ocuparse de eso a menos que el documento en sí no especifique una codificación o BeautifulSoup no pueda detectar una.
- También se considera que es más rápido en comparación con otras técnicas generales de análisis o extracción de datos.
En este artículo utilizaremos Python Embebido con ObjectScript para extraer de ae.indeed.com empresas y ofertas de empleo de Python
Paso 1 - Encontrar la URL de la página web de la que se desean extraer los datos
URL = https://ae.indeed.com/jobs?q=python&l=Dubai&start=0
La página web de la que extraeremos los datos se ve así:
.png)
Para simplificar el proceso y con fines educativos, extraeremos los datos "Job" (Puesto de trabajo) y "Company" (Empresa). El resultado sería algo similar esto:
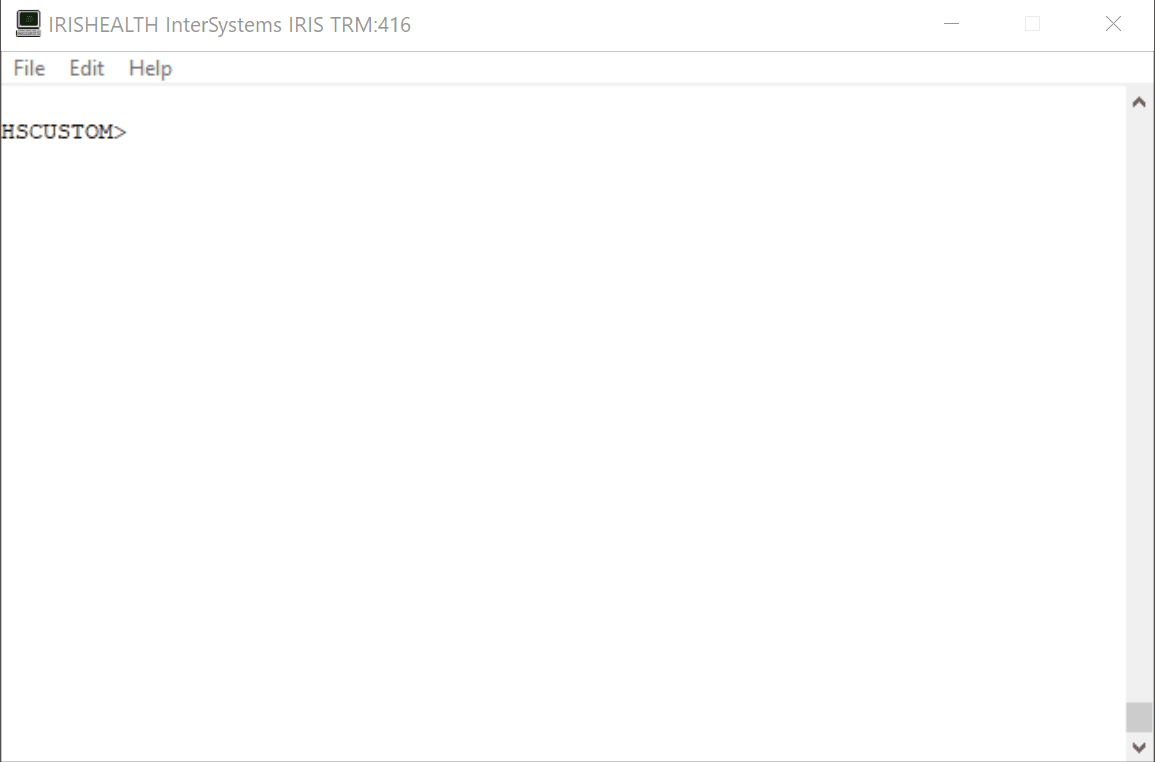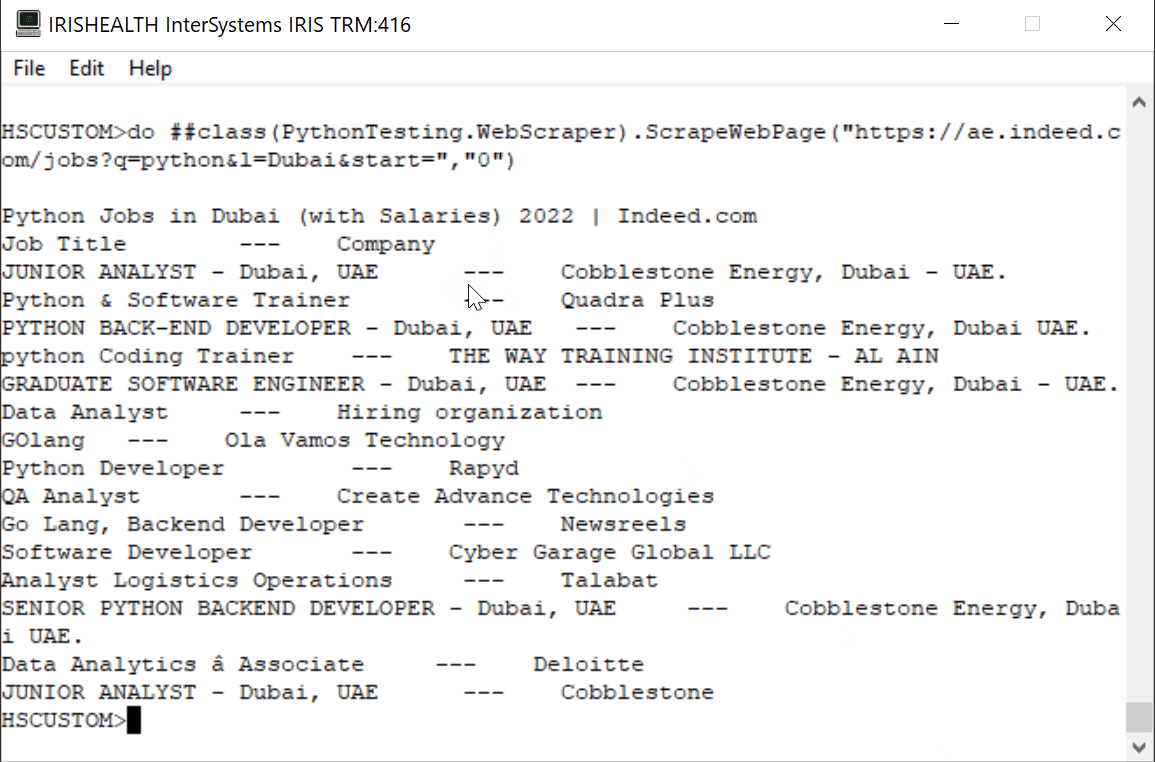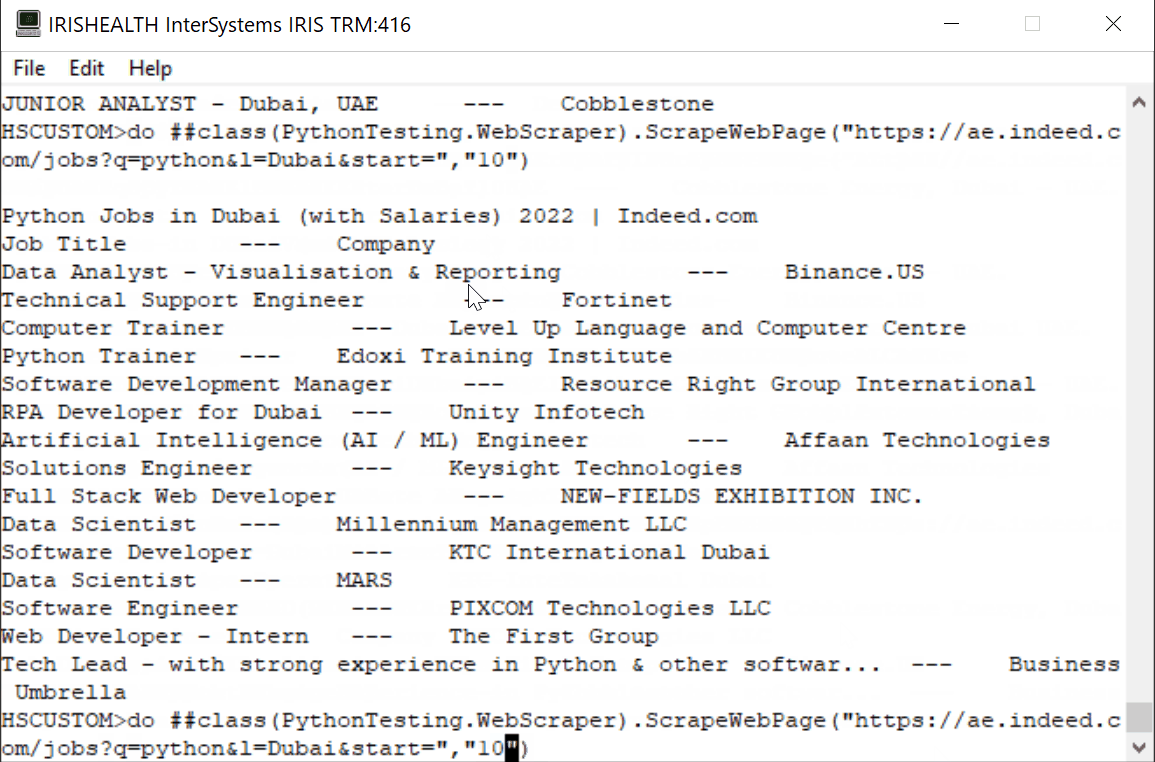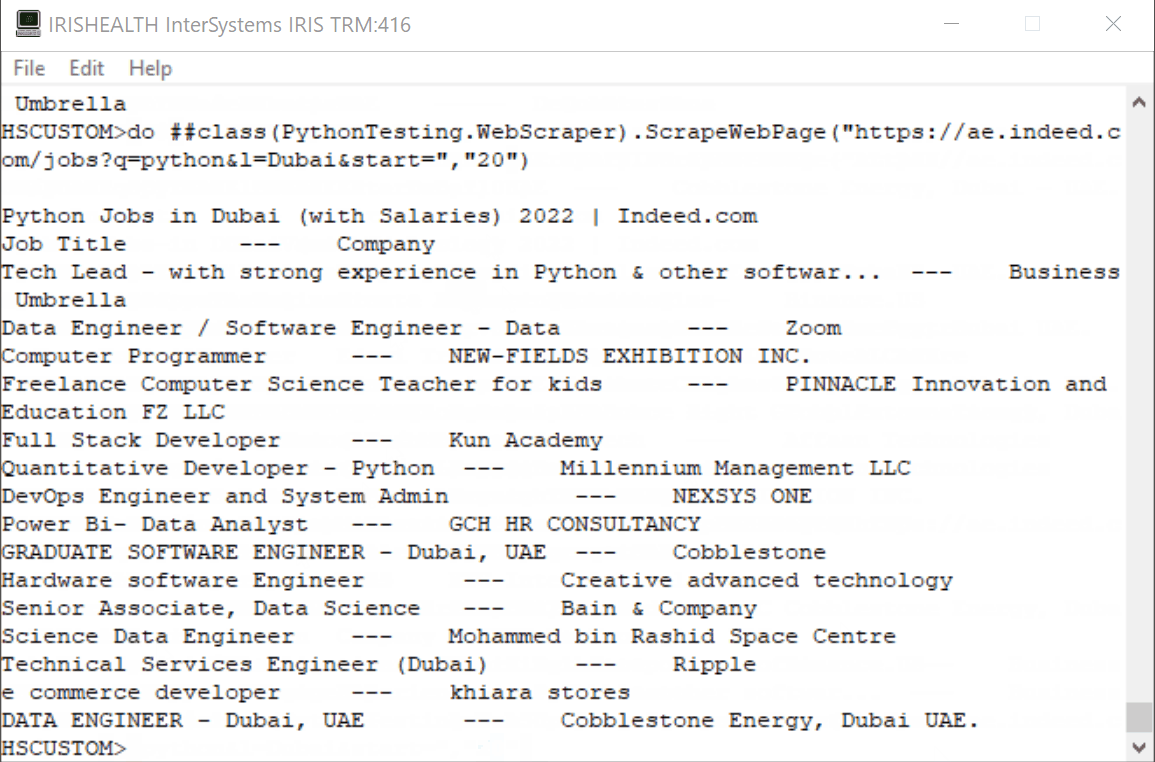
Utilizaremos dos librerías de Python.
- requests Requests es una librería HTTP para el lenguaje de programación Python. El objetivo del proyecto es hacer que las solicitudes HTTP sean más sencillas y amigables para el usuario.
- bs4 para BeautifulSoup BeautifulSoup es un paquete de Python para analizar documentos HTML y XML. Crea un árbol de análisis para las páginas analizadas, que puede utilizarse para extraer datos de HTML, lo que es útil para el proceso de web scraping.
Vamos a instalar estos paquetes de Python (en Windows)
irispip install --target C:\InterSystems\IRISHealth\mgr\python bs4
irispip install --target C:\InterSystems\IRISHealth\mgr\python requests
.png)
Ahora importaremos las librerías de Python a ObjectScript
<span class="hljs-keyword">Class</span> PythonTesting.WebScraper <span class="hljs-keyword">Extends</span> <span class="hljs-built_in">%Persistent</span>
{
<span class="hljs-comment">// pUrl = https://ae.indeed.com/jobs?q=python&l=Dubai&start=&lt;/span>
<span class="hljs-comment">// pPage = 0</span>
<span class="hljs-keyword">ClassMethod</span> ScrapeWebPage(pUrl, pPage)
{
<span class="hljs-comment">// imports the requests python library</span>
<span class="hljs-keyword">set</span> requests = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"requests"</span>)
<span class="hljs-comment">// import the bs4 python library</span>
<span class="hljs-keyword">set</span> soup = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"bs4"</span>)
<span class="hljs-comment">// import builtins package which contains all of the built-in identifiers</span>
<span class="hljs-keyword">set</span> builtins = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"builtins"</span>)
}
Recopilamos los datos HTML utilizando la librería requests
Nota: El "user agent" se encontró buscando en Google "my user agent"
La URL es "https://ae.indeed.com/jobs?q=python&l=Dubai&start=", donde pPage es el número de página
Haremos una solicitud HTTP GET a la URL usando requests y almacenaremos la respuesta en "req"
<span class="hljs-keyword">set</span> headers = {<span class="hljs-string">"User-Agent"</span>: <span class="hljs-string">"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"</span>}
<span class="hljs-keyword">set</span> url = <span class="hljs-string">"https://ae.indeed.com/jobs?q=python&l=Dubai&start="</span>_pPage
&lt;span class="hljs-keyword">set&lt;/span> req = requests.get(url,&lt;span class="hljs-string">"headers="&lt;/span>_headers)
El objeto "req" tendrá el HTML que fue devuelto desde la página web.
Ahora ejecutaremos el analizador de HTML de BeautifulSoup, para que podamos extraer la información del puesto de trabajo.
<span class="hljs-keyword">set</span> soupData = soup.BeautifulSoup(req.content, <span class="hljs-string">"html.parser"</span>)
<span class="hljs-keyword">set</span> title = soupData.title.text
<span class="hljs-keyword">W</span> !,titleEl título se ve de la siguiente manera:
.png)
Paso 2: Seleccionar ciertos elementos mediante una inspección.
En este escenario nos interesa la lista de trabajos que normalmente se encuentra en una etiqueta < div >. En el navegador se puede inspeccionar el elemento para encontrar la clase "div".
.png)
En nuestro caso, la información necesaria se almacena en <div class="cardOutline tapItem ... div >
Paso 3: Escribir el código para obtener el contenido de los elementos seleccionados
Utilizaremos la función find_all de BeautifulSoup para buscar todas las etiquetas < div > que contengan la clase con el nombre "cardOutline".
<span class="hljs-comment">//parameters to python would be sent as a python dictionary</span>
<span class="hljs-keyword">set</span> divClass = {<span class="hljs-string">"class"</span>:<span class="hljs-string">"cardOutline"</span>}
<span class="hljs-keyword">set</span> divsArr = soupData.<span class="hljs-string">"find_all"</span>(<span class="hljs-string">"div"</span>,divClass...)Esto devolverá una lista que podremos examinar para extraer los Puestos de trabajo y la Empresa.
Paso 4: Almacenar los datos en el formato requerido
En el siguiente ejemplo escribiremos los datos en el terminal.
<span class="hljs-keyword">set</span> len = builtins.len(divsArr)
<span class="hljs-keyword">W</span> !, <span class="hljs-string">"Job Title"</span>,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>)<span class="hljs-string">" --- "</span><span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),<span class="hljs-string">"Company"</span>
<span class="hljs-keyword">for</span> i = <span class="hljs-number">1</span>:<span class="hljs-number">1</span>:len {
<span class="hljs-keyword">Set</span> item = divsArr.<span class="hljs-string">"getitem"</span>(i - <span class="hljs-number">1</span>)
<span class="hljs-keyword">set</span> title = <span class="hljs-built_in">$ZSTRIP</span>(item.find(<span class="hljs-string">"a"</span>).text,<span class="hljs-string">"<>W"</span>)
<span class="hljs-keyword">set</span> companyClass = {<span class="hljs-string">"class_"</span>:<span class="hljs-string">"companyName"</span>}
<span class="hljs-keyword">set</span> company = <span class="hljs-built_in">$ZSTRIP</span>(item.find(<span class="hljs-string">"span"</span>, companyClass...).text,<span class="hljs-string">"<>W"</span>)
<span class="hljs-keyword">W</span> !,title,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),<span class="hljs-string">" --- "</span>,<span class="hljs-built_in">$C</span>(<span class="hljs-number">9</span>),company
}
Hay que tener en cuenta que estamos usando la función builtins.len() para obtener la longitud de la lista divsArr
Nombres de los identificadores:
Las reglas para nombrar a los identificadores son diferentes entre ObjectScript y Python. Por ejemplo, el guion bajo (_) está permitido en el nombre de los métodos de Python, y de hecho se utiliza ampliamente para los llamados métodos y atributos “dunder” (“dunder” es la abreviatura de “double underscore”), como getitem o class. Para usar estos identificadores desde ObjectScript, hay que ponerlos entre comillas dobles:
Documentación sobre los nombres de los identificadores
Ejemplo de Método de Clase.
&lt;span class="hljs-comment">// pUrl = https://ae.indeed.com/jobs?q=python&l=Dubai&start=&lt;/span>
<span class="hljs-comment">// pPage = 0</span>
<span class="hljs-keyword">ClassMethod</span> ScrapeWebPage(pUrl, pPage)
{
<span class="hljs-keyword">set</span> requests = <span class="hljs-keyword">##class</span>(<span class="hljs-built_in">%SYS.Python</span>).Import(<span class="hljs-string">"requests"</span>)
&lt;span class="hljs-keyword">set&lt;/span> soup = &lt;span class="hljs-keyword">##class&lt;/span>(&lt;span class="hljs-built_in">%SYS.Python&lt;/span>).Import(&lt;span class="hljs-string">"bs4"&lt;/span>)
&lt;span class="hljs-keyword">set&lt;/span> builtins = &lt;span class="hljs-keyword">##class&lt;/span>(&lt;span class="hljs-built_in">%SYS.Python&lt;/span>).Builtins()
&lt;span class="hljs-keyword">set&lt;/span> headers = {&lt;span class="hljs-string">"User-Agent"&lt;/span>: &lt;span class="hljs-string">"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"&lt;/span>}
&lt;span class="hljs-keyword">set&lt;/span> url = pUrl_pPage
&lt;span class="hljs-keyword">set&lt;/span> req = requests.get(url,&lt;span class="hljs-string">"headers="&lt;/span>_headers)
&lt;span class="hljs-keyword">set&lt;/span> soupData = soup.BeautifulSoup(req.content, &lt;span class="hljs-string">"html.parser"&lt;/span>)
&lt;span class="hljs-keyword">set&lt;/span> title = soupData.title.text
&lt;span class="hljs-keyword">W&lt;/span> !,title
&lt;span class="hljs-keyword">set&lt;/span> divClass = {&lt;span class="hljs-string">"class_"&lt;/span>:&lt;span class="hljs-string">"cardOutline"&lt;/span>}
&lt;span class="hljs-keyword">set&lt;/span> divsArr = soupData.&lt;span class="hljs-string">"find_all"&lt;/span>(&lt;span class="hljs-string">"div"&lt;/span>,divClass...)
&lt;span class="hljs-keyword">set&lt;/span> len = builtins.len(divsArr)
&lt;span class="hljs-keyword">W&lt;/span> !, &lt;span class="hljs-string">"Job Title"&lt;/span>,&lt;span class="hljs-built_in">$C&lt;/span>(&lt;span class="hljs-number">9&lt;/span>)_&lt;span class="hljs-string">" --- "&lt;/span>_&lt;span class="hljs-built_in">$C&lt;/span>(&lt;span class="hljs-number">9&lt;/span>),&lt;span class="hljs-string">"Company"&lt;/span>
&lt;span class="hljs-keyword">for&lt;/span> i = &lt;span class="hljs-number">1&lt;/span>:&lt;span class="hljs-number">1&lt;/span>:len {
&lt;span class="hljs-keyword">Set&lt;/span> item = divsArr.&lt;span class="hljs-string">"__getitem__"&lt;/span>(i - &lt;span class="hljs-number">1&lt;/span>)
&lt;span class="hljs-keyword">set&lt;/span> title = &lt;span class="hljs-built_in">$ZSTRIP&lt;/span>(item.find(&lt;span class="hljs-string">"a"&lt;/span>).text,&lt;span class="hljs-string">"&lt;>W"&lt;/span>)
&lt;span class="hljs-keyword">set&lt;/span> companyClass = {&lt;span class="hljs-string">"class_"&lt;/span>:&lt;span class="hljs-string">"companyName"&lt;/span>}
&lt;span class="hljs-keyword">set&lt;/span> company = &lt;span class="hljs-built_in">$ZSTRIP&lt;/span>(item.find(&lt;span class="hljs-string">"span"&lt;/span>, companyClass...).text,&lt;span class="hljs-string">"&lt;>W"&lt;/span>)
&lt;span class="hljs-keyword">W&lt;/span> !,title,&lt;span class="hljs-built_in">$C&lt;/span>(&lt;span class="hljs-number">9&lt;/span>),&lt;span class="hljs-string">" --- "&lt;/span>,&lt;span class="hljs-built_in">$C&lt;/span>(&lt;span class="hljs-number">9&lt;/span>),company
}
}
Próximos pasos...
Usando Object Script y Python Embebido y creando unas pocas líneas de código, podríamos extraer fácilmente la información de las páginas web más populares para buscar trabajo, recoger el nombre del puesto de trabajo, la empresa, el sueldo, la descripción del trabajo y correos electrónicos/enlaces.
Esta información se puede añadir a un DataFrame de Pandas para eliminar los datos duplicados. Se pueden aplicar filtros basados en ciertas palabras clave que interesen.
Se pueden ejecutar estos datos a través de NumPy y obtener algunos gráficos de líneas.
O realizar una One-Hot encoding de los datos, y crear/entrenar modelos de Machine Learning para que si hay puestos de trabajo que interesan particularmente, envíen una notificación. 😉
¡Feliz desarrollo!