InterSystems para dummies – Machine learning

Como todos sabemos, InterSystems es una gran empresa.
Sus productos pueden ser tan útiles como complejos.
Sin embargo, a veces nuestro orgullo nos impide admitir que quizá no entendamos algunos conceptos o productos que InterSystems nos ofrece.
Hoy comenzamos una serie de artículos que explican, de forma sencilla y clara, cómo funcionan algunos de los complejos productos de InterSystems.
En este ensayo, aclararé qué es el Machine Learning y cómo aprovecharlo... porque esta vez, SABRÁS con certeza de qué estoy hablando.
¿Qué (demonios) es Machine Learning?
El Machine Learning (aprendizaje automático) es una rama de la inteligencia artificial que se centra en el desarrollo de algoritmos y modelos que permiten a las computadoras aprender a realizar tareas específicas basadas en datos, sin necesidad de ser programadas explícitamente para cada tarea. En lugar de seguir instrucciones específicas, las máquinas aprenden a través de la experiencia, identificando patrones en los datos y haciendo predicciones o tomando decisiones basadas en ellos.
El proceso implica alimentar algoritmos con conjuntos de datos (llamados conjuntos de entrenamiento) para que aprendan y mejoren su rendimiento con el tiempo. Estos algoritmos pueden diseñarse para realizar una amplia gama de tareas, como el reconocimiento de imágenes, el procesamiento del lenguaje natural, la predicción de tendencias financieras, el diagnóstico médico y mucho más.
En resumen, el Machine Learning permite a las computadoras aprender de los datos y mejorar con la experiencia, lo que les permite realizar tareas complejas sin necesidad de una programación explícita para cada situación de forma autónoma...
Es una definición muy interesante. Sin embargo, supongo que necesitas un ejemplo, así que aquí vamos:
Bueno, imagina que cada día escribes en algún lugar la hora del amanecer y del atardecer. Si alguien te preguntara si el sol saldrá al día siguiente, ¿qué dirías? Solo has anotado la hora del amanecer y el atardecer.
Al observar tus datos, concluirías que, con un 100% de probabilidad, el sol saldrá mañana. Sin embargo, no puedes ignorar que existe la posibilidad de que, debido a una catástrofe natural, no puedas ver el amanecer al día siguiente. Por eso, deberías decir que la probabilidad de presenciar un amanecer al día siguiente es, de hecho, del 99,99%.
Considerando tu experiencia personal, puedes proporcionar una respuesta que coincida con tus datos. El Machine Learning es lo mismo, pero realizado por una computadora.
Observa la tabla a continuación:
| A | B |
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | 8 |
¿Cómo se relacionan las columnas A y B?
La respuesta es sencilla: el valor de B es el doble del de A. B=A*2 es un patrón.
Ahora, examine la otra tabla:
| A | B |
| 1 | 5 |
| 2 | 7 |
| 3 | 9 |
| 4 | 11 |
Este es un poco más complicado… Si no has descubierto el patrón, es B=(A*2) +3.
Un humano, por ejemplo, puede deducir la fórmula, lo que significa que cuantos más datos tengas, más fácil será adivinar el patrón que se esconde tras este misterio.
Así pues, el Machine Learning utiliza la misma lógica para revelar el patrón oculto en los datos.
¿Cómo empezar?
Primero, necesitarás un ordenador. Sí, dado que este artículo trata sobre Machine Learning, tener solo un cuaderno y un lápiz no será suficiente.
En segundo lugar, necesitará una instancia de IRIS Community. Puede descargar una imagen de Docker y ejecutar su prueba aquí. Tenga en cuenta que debe tener ML integrado, por ejemplo, la última versión de InterSystems IRIS Community.
docker pull intersystems/iris-ml-community:latest-emo
docker pull intersystems/iris-community:latestSi lo necesitas en otra plataforma, consulta en https://hub.docker.com/r/intersystems/iris-ml-community/tags o en https://hub.docker.com/r/intersystems/iris-community/tags.
Luego, crea un contenedor a partir de este contenedor y ejecútalo:
docker run --name iris-ml -d --publish 1972:1972 --publish 52773:52773 intersystems/iris-m
Si eres de la vieja escuela, puedes descargar una versión gratuita para evaluarla. Sin embargo, es importante tener una cuenta de InterSystems. Consúltala en https://login.intersystems.com/login/SSO.UI.Register.cls.
Posteriormente, solicite una copia de evaluación en https://evaluation.intersystems.com/Eval/.
Instálalo y ejecuta tu instancia.
Ahora, accede al portal de IRIS: http://localhost:52773/csp/user/EnsPortal.ProductionConfig.zen
- Usuario: Superusuario
- Contraseña: SYS
Nota: Es posible que se te pida cambiar la contraseña la primera vez. No te preocupes, crea una contraseña que puedas recordar fácilmente.
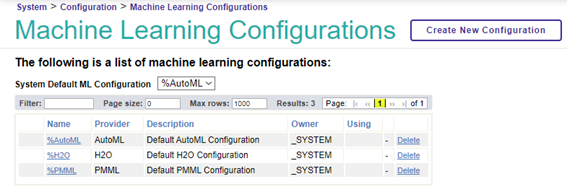
Abre la "Configuración de Machine Learning" para revisar las versiones instaladas.
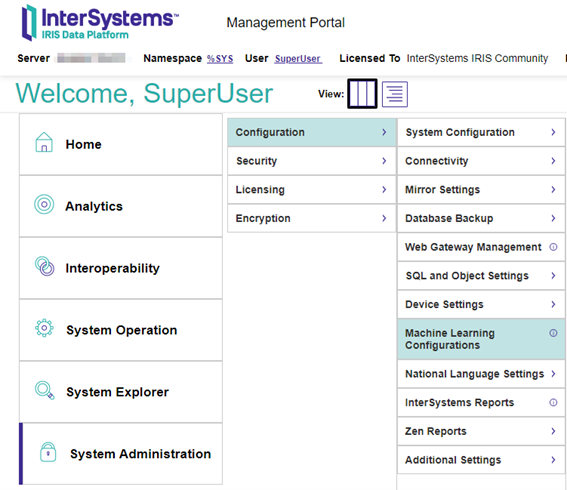
En este punto, puedes ver las configuraciones del proveedor de ML instaladas.
Earth, "water" and fire... ¿Cuál es la mejor?
Todos son buenos. Lo importante es cómo entrenar a tu dragón, es decir... tus datos.
Busca más información sobre los modelos existentes:
AutoML: AutoML es un sistema automatizado de aprendizaje automático desarrollado por InterSystems y alojado en la plataforma de datos InterSystems IRIS®. Está diseñado para crear rápidamente modelos predictivos precisos utilizando tus datos. Automatiza varios componentes clave del proceso de aprendizaje automático.
Haz clic en el siguiente enlace para obtener más información: https://docs.intersystems.com/iris20241/csp/docbook/Doc.View.cls?KEY=GAUTOML_Intro
H2O: Es un modelo de aprendizaje automático de código abierto. El proveedor H2O no admite la creación de modelos de series temporales.
Siga el siguiente enlace para obtener más información: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_Configuration_Providers#GIML_Configuration_Providers_H2O
PMML: (Lenguaje de Marcado de Modelado Predictivo). Es un estándar basado en XML que expresa modelos analíticos. Permite a las aplicaciones definir modelos estadísticos y de minería de datos, de modo que puedan reutilizarse y compartirse fácilmente.
Para más información, consulte el siguiente enlace: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=APMML
¿Cuál es el primer paso?
Al igual que en el ejemplo del amanecer y el atardecer, necesitamos datos para entrenar nuestro modelo.
Es fundamental conocer el objetivo de los datos y los valores que se deben predecir. También es crucial tener datos claros y sin duplicados. También debes averiguar cuál es el conjunto mínimo de datos.
Voy a usar el proveedor AutoML porque es de Intersystems, ¡jaja! 😉
Existen varios tipos de algoritmos:
Árboles de decisión: Primero se clasifica la información y luego se aplica la siguiente pregunta para evaluar la probabilidad. Ejemplo: ¿Lloverá mañana? Comprueba si el cielo está nublado (muy o ligeramente nublado) o despejado. Si está muy nublado, comprueba la humedad. Después, comprueba la temperatura... Si está muy nublado, con alta humedad y baja temperatura, mañana lloverá.
Bosques aleatorios: Se trata de un conjunto de árboles de decisión, cada uno de los cuales "vota" por una clase. La mayoría de los votos define el modelo seleccionado.
Redes neuronales: Esto no significa que Skynet esté por llegar... Sin embargo, es demasiado complejo para explicarlo en pocas palabras. La idea general es "copiar" la función de las neuronas humanas. Esto significa que cada dato de entrada es analizado por una "neurona", que, a su vez, proporciona los datos de entrada a la siguiente "neurona" para analizar los datos de salida.
Si quieres experimentar con redes neuronales usando Python, puedes crear una y comprobar su funcionamiento. Consulta https://colab.research.google.com/drive/1XJ-Lph5auvoK1M4kcHZvkikOqZlmbytI?usp=sharing.
A través del enlace anterior, puedes ejecutar una rutina en Python con la ayuda de la biblioteca TensorFlow. Para obtener el patrón de las tablas A y B, haz lo siguiente:
import tensorflow as tf
import numpy as np
tableA = np.array([1, 2, 3, 4, 5, 6, 7], dtype=float)
tableB = np.array([5, 7, 9, 11, 13, 15, 17], dtype=float)
hidden1 = tf.keras.layers.Dense(units=3, input_shape=[1])
hidden2 = tf.keras.layers.Dense(units=3)
exit = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([hidden1, hidden2, exit])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.1),
loss='mean_squared_error'
)
print("Start training...")
history = model.fit(tableA, tableB, epochs=1000, verbose=False)
print("Model trained!")
import matplotlib.pyplot as plt
plt.xlabel("# Epoch")
plt.ylabel("Loss magnitud")
plt.plot(history.history["loss"])
print("Doing a predicction!")
result = model.predict([100])
print("The result is " + str(result) )
print("Internal variables of the model")
print(hidden1.get_weights())
print(hidden2.get_weights())
print(exit.get_weights())
El código anterior utiliza los valores de A y B para crear un modelo que compara y determina la relación entre ambos valores.
Una vez realizada la predicción, se obtiene el valor correcto; en este ejemplo, la predicción es 203.
¿Cómo funciona en IRIS?
El Machine Learning en IRIS se denomina "integratedML". Se implementó desde InterSystems IRIS 2023.2 como una función experimental, lo que significa que no es compatible con entornos de producción. Sin embargo, esta función ha sido ampliamente probada e InterSystems cree que puede aportar un valor significativo a los clientes. Puede encontrar más información en la documentación sobre el uso de integratedML.
Aun así, dado que esta es una lección de Machine Learning para principiantes, explicaré su funcionamiento de la forma más sencilla posible.
Nota: Estoy utilizando un contenedor con una imagen de containers.intersystems.com/iris-ml-community
docker pull containers.intersystems.com/iris-ml-communityPuede descargar la imagen y ejemplos de IRIS desde https://github.com/KurroLopez/iris-mll-fordummies.
docker-compose exec iris iris session irisEstudio de Sleepland University
La Universidad Sleepland ha realizado una amplia investigación sobre el insomnio, realizando miles de entrevistas y creando una base de datos con diversos parámetros de pacientes con y sin insomnio.
Los datos recopilados incluyen lo siguiente:
- Género (masculino/femenino)
- Edad (edad de la persona en años)
- Ocupación (ocupación o profesión de la persona)
- Duración del sueño (horas que la persona duerme al día)
- Calidad del sueño (puntuación subjetiva de la calidad del sueño, del 1 al 10)
- Nivel de actividad física (minutos que la persona realiza actividad física al día)
- Nivel de estrés (puntuación subjetiva del nivel de estrés que experimenta la persona, del 1 al 10)
- Categoría del IMC (categoría del IMC de la persona: bajo peso, normal, sobrepeso)
- Sistólica (presión arterial sistólica)
- Diastólica (presión arterial diastólica)
- Frecuencia cardíaca (frecuencia cardíaca en reposo de la persona en latidos por minuto)
- Pasos diarios (pasos que la persona da al día)
- Trastorno del sueño (ninguno, insomnio, apnea del sueño)
Para el primer ejemplo, creé una clase (St.MLL.insomniaBase) con las columnas mencionadas anteriormente:
Class St.MLL.insonmniaBase Extends %Persistent
{
/// Gender of patient (male/female)
Property Gender As %String;
/// The age of the person in years
Property Age As %Integer;
/// The occupation or profession of the person
Property Occupation As %String;
/// The number of hours the person sleeps per day
Property SleepDuration As %Numeric(SCALE = 2);
/// A subjective rating of the quality of sleep, ranging from 1 to 10
Property QualitySleep As %Integer;
/// The number of minutes the person engages in physical activity daily
Property PhysicalActivityLevel As %Integer;
/// A subjective rating of the stress level experienced by the person, ranging from 1 to 10
Property StressLevel As %Integer;
/// The BMI category of the person: Underweight, Normal, Overweight
Property BMICategory As %String;
/// Systolic blood pressure
Property Systolic As %Integer;
/// Diastolic blood pressure
Property Diastolic As %Integer;
/// The resting heart rate of the person in BPM
Property HeartRate As %Integer;
/// The number of steps the person takes per day
Property DailySteps As %Integer;
/// None, Insomnia, Sleep Apnea
Property SleepDisorder As %String;
}
Luego, creé algunas clases derivadas de insomniaBase: insomnia01, insomniaValidate01 e insomniaTest01. Esto me permitió tener las mismas columnas para cada tabla.
Eventualmente, necesitaremos rellenar nuestras tablas con valores de muestra, así que diseñé un método de clase para tal fin.
Class St.MLL.insomnia01 Extends St.MLL.insomniaBase
{
/// Populate values
ClassMethod Populate() As %Status
{
write "Init populate "_$CLASSNAME(),!
&sql(TRUNCATE TABLE St_MLL.insomnia01)
……
write $CLASSNAME()_" populated",!
Return $$$OK
}
docker-compose exec iris iris session irisUsando el terminal, llame al método Populate de esta clase
Do ##class(St.MLL.insomnia01).Populate()Si hacemos todo correctamente, tendremos una tabla con los valores para entrenar nuestro ML.
También necesitamos crear una nueva tabla para la validación. Es fácil, ya que solo se necesita una parte de los datos proporcionados para el entrenamiento. En este caso, será el 50% de los elementos.
Por favor, ejecute la siguiente sentencia en la terminal.
Do ##class(St.MLL.insomniaValidate01).Populate()Por último, prepararemos algunos datos de prueba para ver los resultados de nuestro entrenamiento.
Do ##class(St.MLL.insomniaTest01).Populate()Entrena, entrena y entrena... te volverás más fuerte
Ahora tenemos todos los datos necesarios para entrenar nuestro modelo. ¿Cómo hacerlo?
Solo necesitas 4 sencillas instrucciones:
CREATE MODELTRAIN MODELVALIDATE MODELSELECT PREDICT
Creando el modelo
CREATE MODEL crea los metadatos del modelo de Machine Learning especificando el nombre del modelo, el campo de destino que se predecirá y el conjunto de datos que proporcionará el campo de destino.
En nuestra muestra disponemos de algunos parámetros para evaluar los trastornos del sueño por lo que diseñaremos los siguientes modelos:
- insomnia01SleepModel: Por género, edad, duración del sueño y calidad del sueño.
- Comprueba si la edad y los hábitos de sueño afectan a algún tipo de trastorno del sueño.
- insomnia01BMIModel: Por género, edad, ocupación y categoría de IMC.
- Examinar si la edad, la ocupación y el IMC afectan algún tipo de trastorno del sueño.
- insomnia01AllModel: Todos los factores.
- Inspeccione si todos los factores afectan algún tipo de trastorno del sueño.
Ahora vamos a crear todos esos modelos.
Utilizando la gestión de SQL en el portal de IRIS, escriba la siguiente frase:
CREATE MODEL insomnia01AllModel PREDICTING (SleepDisorder) From St_MLL.insomnia01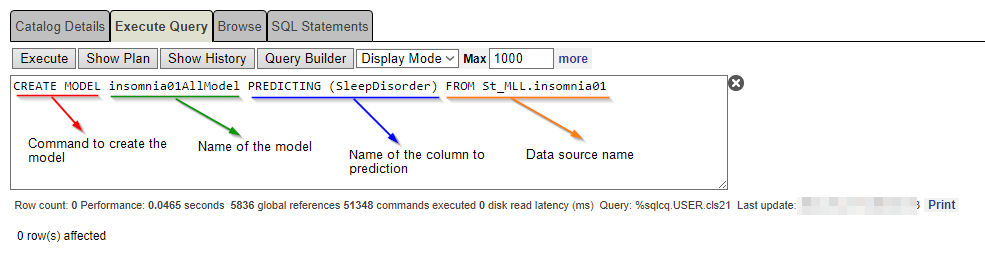
En este punto, nuestro modelo sabe qué columna predecir.
Puede comprobar qué se creó y qué contiene la columna de predicción con la siguiente sentencia:
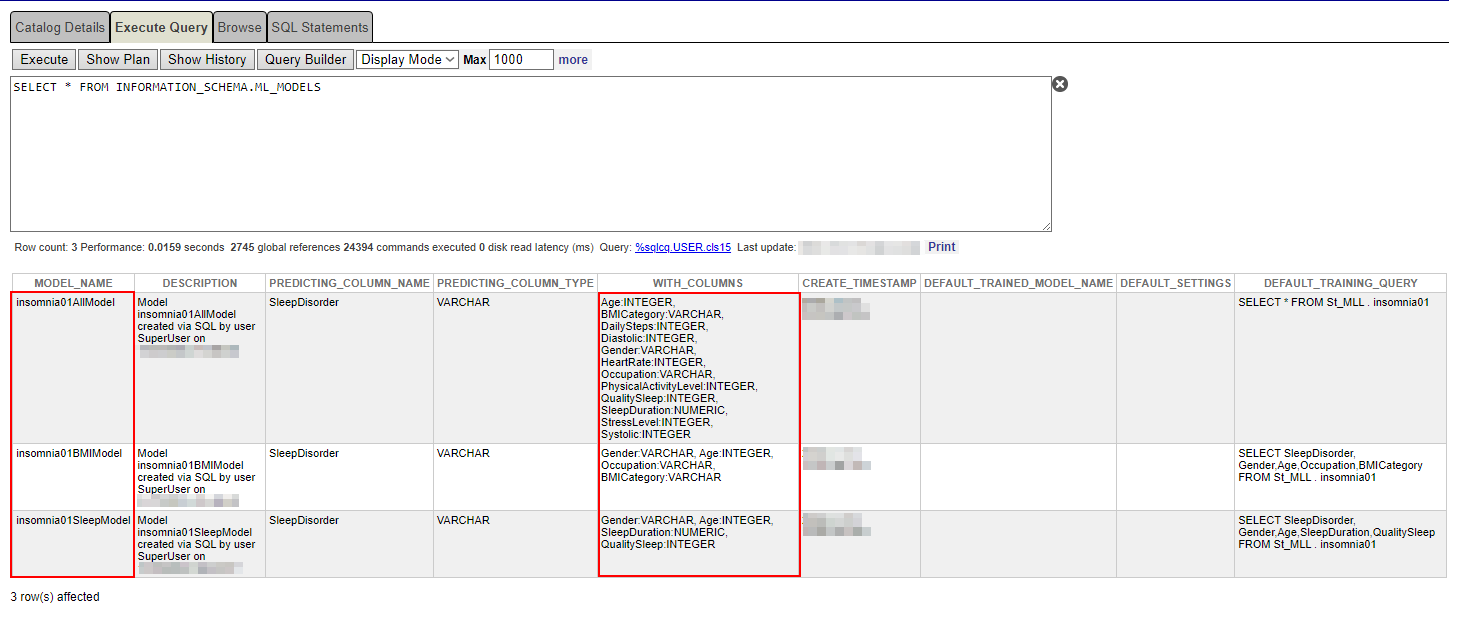
SELECT * FROM INFORMATION_SCHEMA.ML_MODELS 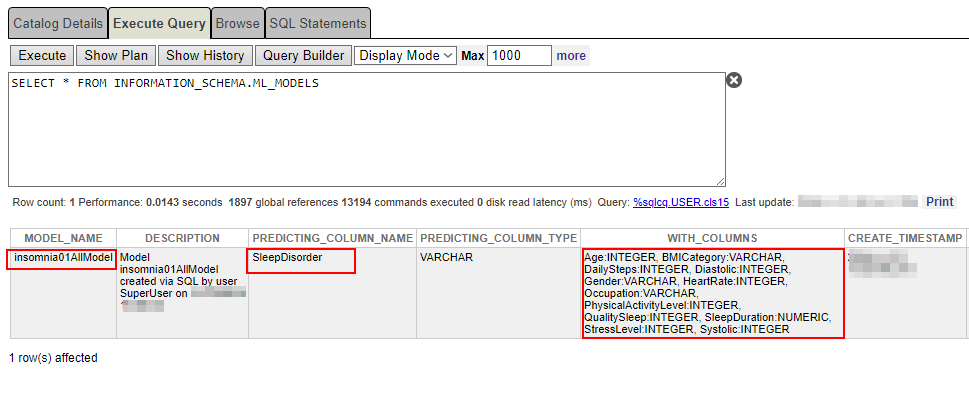
Asegúrese de que el nombre de la columna de predicción y las propias columnas sean correctos.
Sin embargo, también queremos agregar diferentes tipos de modelos, ya que deseamos predecir los trastornos del sueño según otros factores, no todos los campos.
En este caso, usaremos la cláusula "WITH" para especificar las columnas que se usarán como parámetros para realizar la predicción.
Para utilizar la cláusula "WITH", debemos indicar el nombre de las columnas y su tipo.
CREATE MODEL insomnia01SleepModel PREDICTING (SleepDisorder) WITH(Gender varchar, Age integer, SleepDuration numeric, QualitySleep integer) FROM St_MLL.insomnia01CREATE MODEL insomnia01BMIModel PREDICTING (SleepDisorder) WITH(Gender varchar, Age integer, Occupation varchar, BMICategory varchar) FROM St_MLL.insomnia01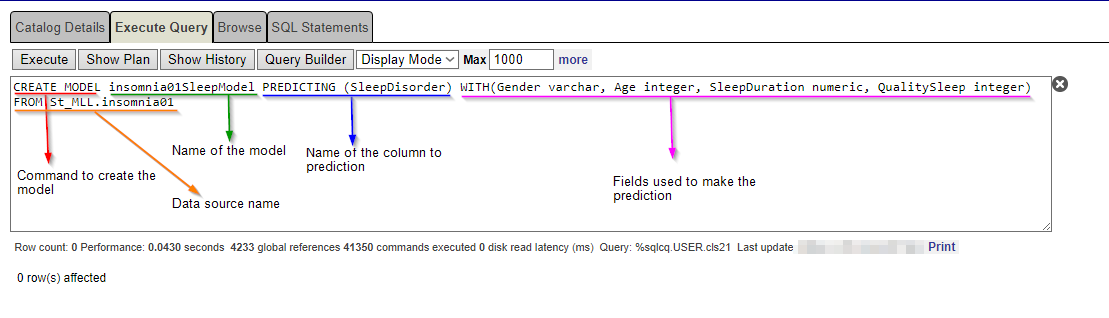 Asegúrese de que todos esos modelos se hayan creado correctamente.
Asegúrese de que todos esos modelos se hayan creado correctamente.
 Entrenando el modelo
Entrenando el modelo
El comando TRAIN MODEL ejecuta el motor AutoML y especifica los datos que se utilizarán para el entrenamiento. La sintaxis FROM es genérica y permite entrenar el mismo modelo varias veces con distintos conjuntos de datos. Por ejemplo, se puede entrenar una tabla con datos de la Universidad Sleepland o la Universidad Napcity. Sin embargo, lo más importante es que el modelo de datos tenga los mismos campos, el mismo nombre y el mismo tipo.
El motor AutoML realiza automáticamente todas las tareas de aprendizaje automático necesarias. Identifica las características candidatas relevantes de los datos seleccionados, evalúa los tipos de modelos viables según los datos y la definición del problema, y establece hiperparámetros para crear uno o más modelos viables.
Como nuestro modelo tiene 50 registros, es suficiente para dicho entrenamiento.
TRAIN MODEL insomnia01AllModel FROM St_MLL.insomnia01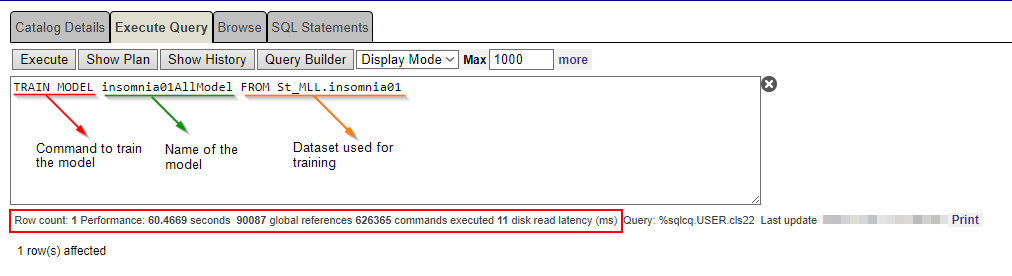
Haz lo mismo con los otros modelos.
TRAIN MODEL insomnia01SleepModel FROM St_MLL.insomnia01
TRAIN MODEL insomnia01BMIModel FROM St_MLL.insomnia01
Puedes saber si tu modelo ha sido entrenado correctamente con la siguiente sentencia:
SELECT * FROM INFORMATION_SCHEMA.ML_TRAINED_MODELS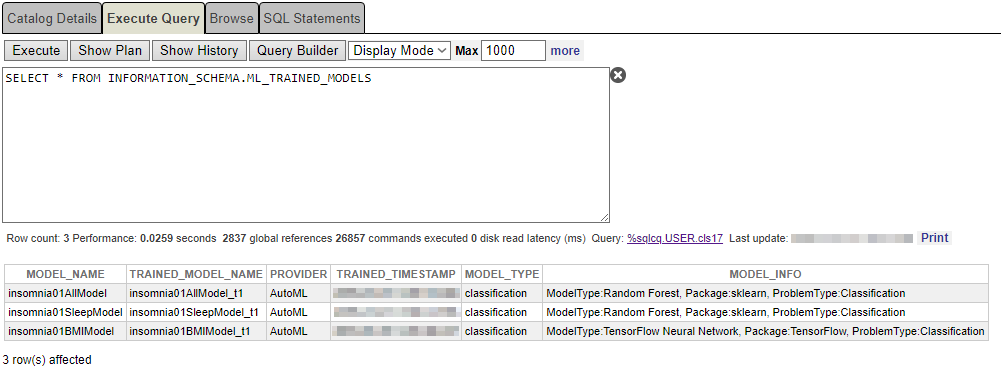
Es necesario validar el modelo y el entrenamiento con el comando VALIDATE MODEL.
Validando el modelo
En esta etapa, necesitamos confirmar que el modelo se haya entrenado correctamente. Por lo tanto, debemos ejecutar el comando VALIDATE MODEL.
VALIDATE MODELdevuelve métricas simples para modelos de regresión, clasificación y series temporales, basándose en el conjunto de pruebas proporcionado.
Compruebe lo que se ha validado con la siguiente sentencia:
VALIDATE MODEL insomnia01AllModel From St_MLL.insomniaValidate01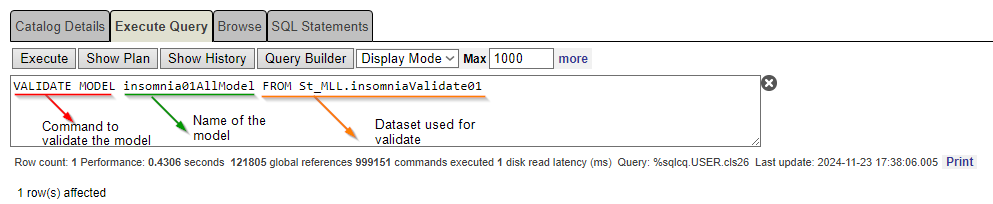
Repítelo con otros modelos.
VALIDATE MODEL insomnia01SleepModel FROM St_MLL.insomniaValidate01
VALIDATE MODEL insomnia01BMIModel FROM St_MLL.insomniaValidate01
Consumiendo el modelo
Ahora, consumiremos este modelo e inspeccionaremos si ha aprendido correctamente cómo generar el valor del resultado.
Con la instrucción "SELECT PREDICT", pronosticaremos el valor del resultado. Para ello, usaremos la tabla test1 que ya se rellenó.
SELECT *, PREDICT(insomnia01AllModel) FROM St_MLL.insomniaTest01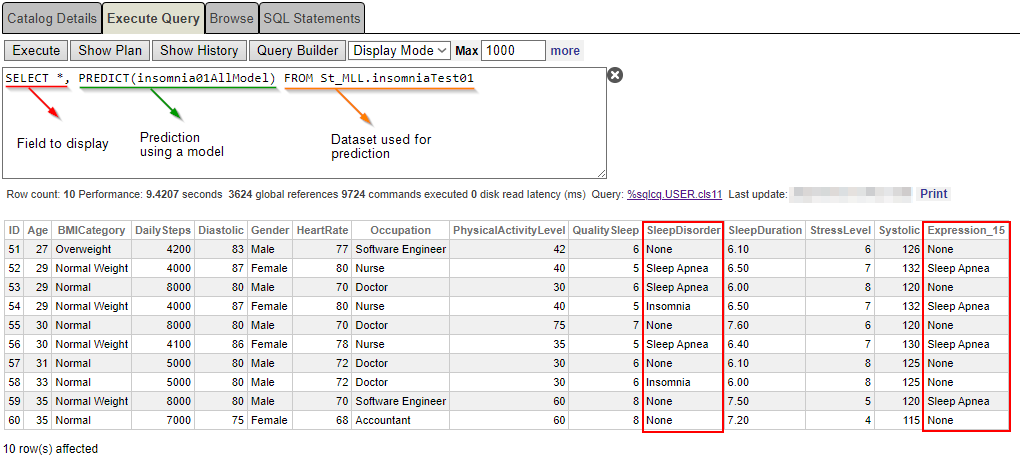 El resultado parece extraño después de utilizar el 50% de los datos explotados para entrenar el modelo... ¿Por qué se le diagnosticó insomnio a una enfermera de 29 años, mientras que el modelo predijo apnea del sueño? (ver ID 54).
El resultado parece extraño después de utilizar el 50% de los datos explotados para entrenar el modelo... ¿Por qué se le diagnosticó insomnio a una enfermera de 29 años, mientras que el modelo predijo apnea del sueño? (ver ID 54).
Deberíamos examinar otros modelos (insomnia01SleepModel e insomnia01BMIModel), creados con diferentes columnas, pero no se preocupen. Te mostraré las columnas utilizadas para diseñarlos.
SELECT Gender, Age, SleepDuration, QualitySleep, SleepDisorder, PREDICT(insomnia01SleepModel) As SleepDisorderPrediction FROM St_MLL.insomniaTest01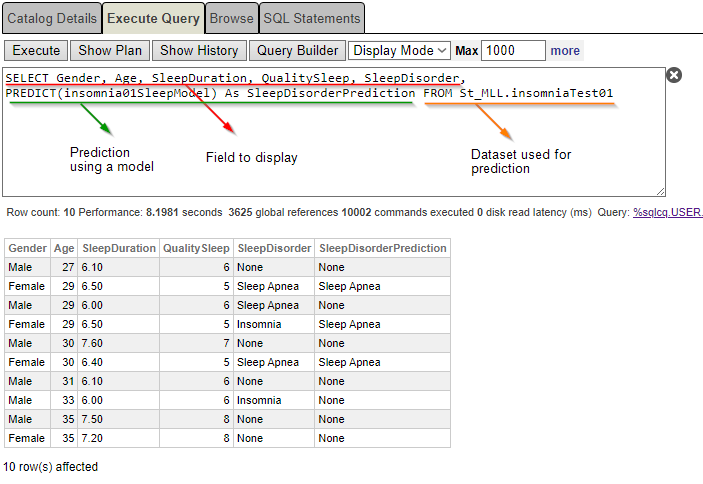
Se puede ver de nuevo que a una mujer de 29 años se le ha diagnosticado «insomnio», mientras que la predicción indica «apnea del sueño».
¡Tienes razón! También necesitamos saber qué porcentaje de la predicción se ha aplicado a este valor final.
¿Cómo podemos saber el porcentaje de una predicción?
Para saber el porcentaje de la predicción, debemos de usar el comando “PROBABILITY”.
Este comando recupera un valor entre 0 y 1. Sin embargo, no se trata de la probabilidad de predicción, sino de la probabilidad de obtener el valor que se desea comprobar.
Este es un buen ejemplo:
SELECT *, PREDICT(insomnia01AllModel) As SleepDisorderPrediction, PROBABILITY(insomnia01AllModel FOR 'Insomnia') as ProbabilityPrediction FROM St_MLL.insomniaTest01Es la probabilidad de padecer “insomnio” como trastorno del sueño.
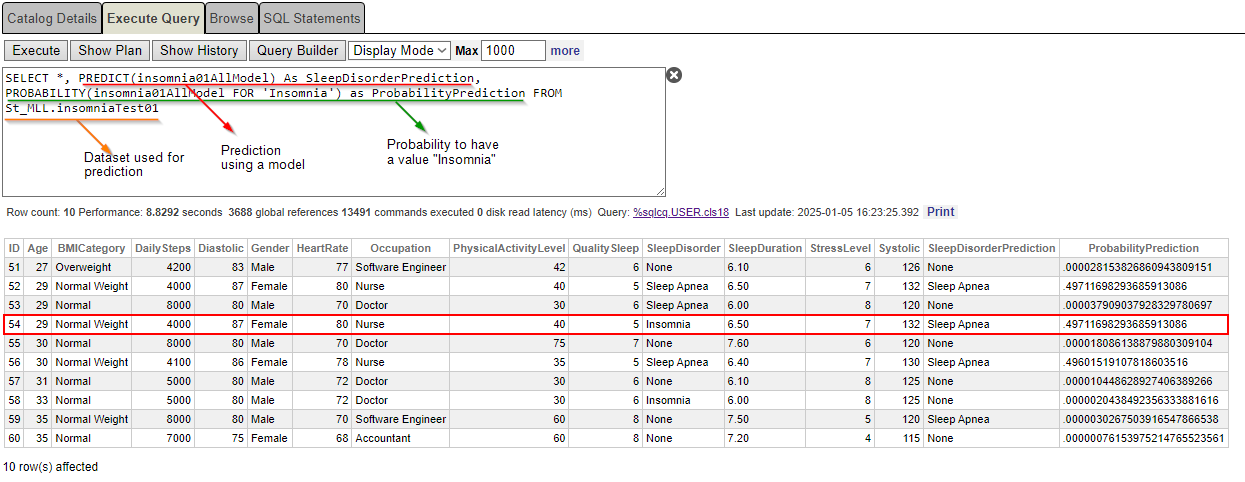
Nuestra enfermera, una mujer de 29 años, diagnosticada con insomnio, tiene un 49,71% de probabilidades de padecerlo. Aun así, la predicción es apnea del sueño… ¿Por qué?
¿Es la misma probabilidad para otros modelos?
SELECT Gender, Age, SleepDuration, QualitySleep, SleepDisorder, PREDICT(insomnia01SleepModel) As SleepDisorderPrediction, PROBABILITY(insomnia01SleepModel FOR 'Insomnia') as ProbabilityInsomnia,
PROBABILITY(insomnia01SleepModel FOR 'Sleep Apnea') as ProbabilityApnea
FROM St_MLL.insomniaTest01
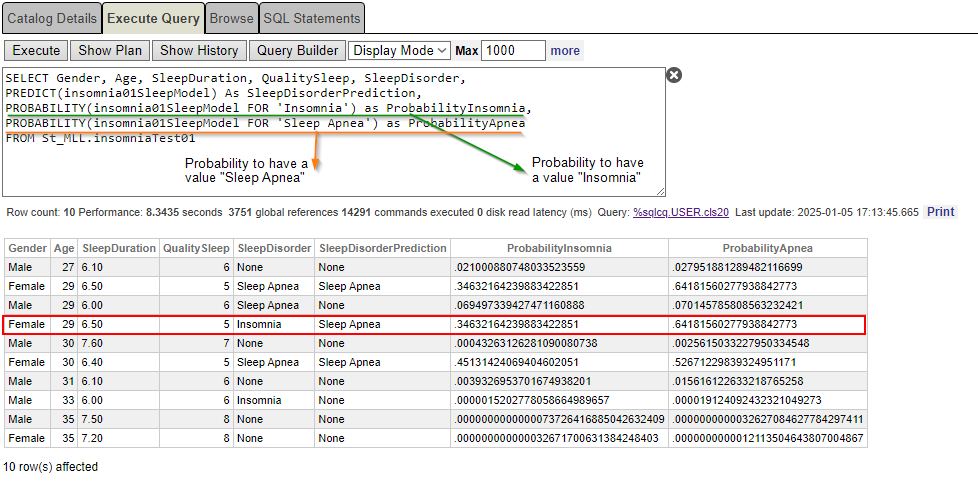
Por fin, ahora está un poco más claro. Según los datos (sexo, edad, calidad y duración del sueño), la probabilidad de tener insomnio es de tan solo el 34,63%, mientras que la de tener apnea del sueño es del 64,18%.
¡Guau! ¡Es muy interesante! Aun así, solo estábamos explotando una pequeña parte de los datos insertados directamente en una tabla con un método de clase... ¿Cómo podemos subir un archivo tan grande con datos?
¡Esperen el próximo artículo! ¡Próximamente!