This article presents a potential solution for semantic code search in TrakCare using IRIS Vector Search.
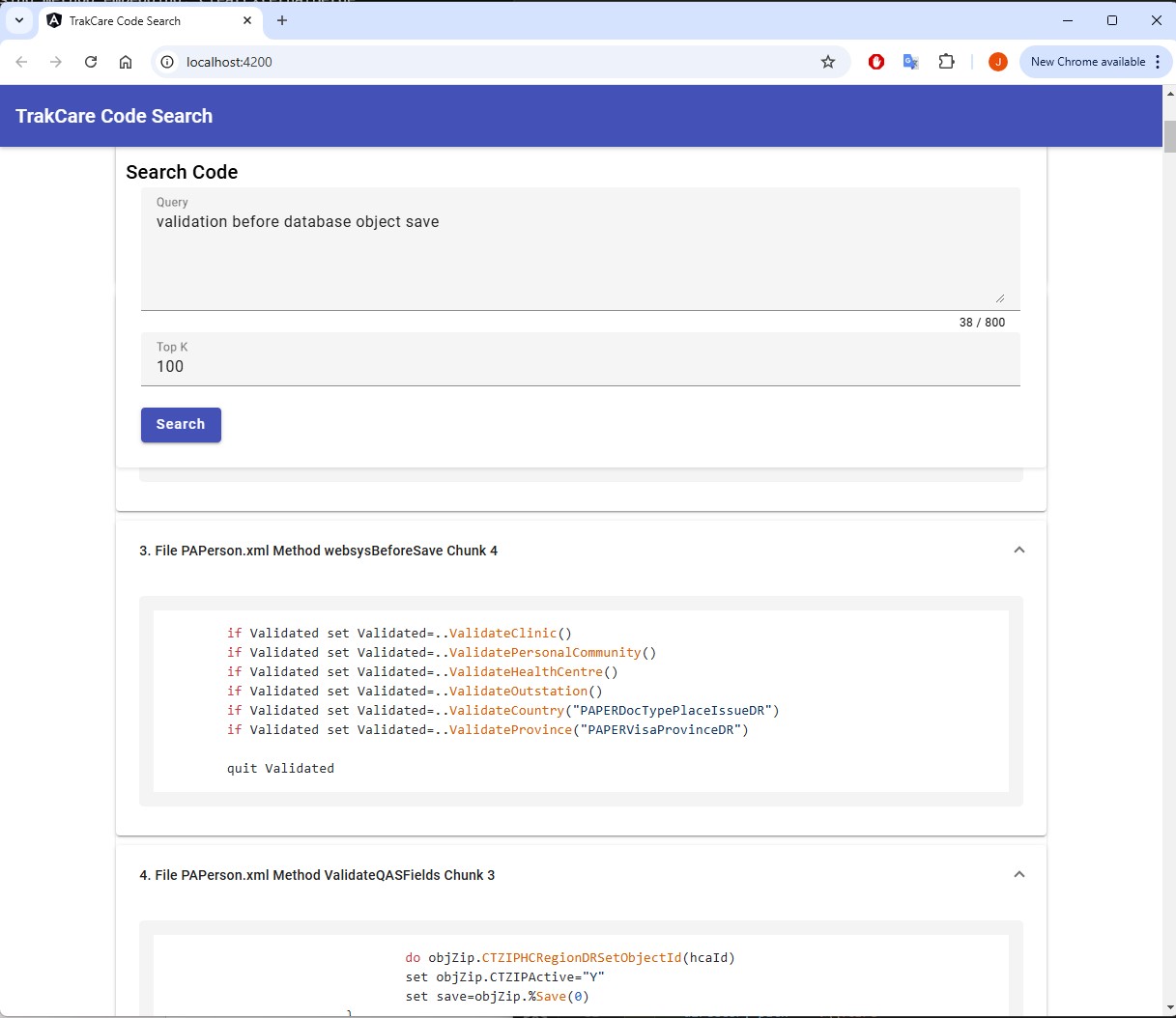
Here's a brief overview of results from the TrakCare Semantic code search for the query: "Validation before database object save".
There are numerous embedding models designed for sentences and paragraphs, but they are not ideal for code specific embeddings.
Three code-specific embedding models were evaluated: voyage-code-2, CodeBERT, GraphCodeBERT. While none of these models were pre-trained for the ObjectScripts language, they still outperformed general-purpose embedding models in this context.
The CodeBERT was chosen as the embedding model for this solution. offering reliable performance without the need for an API key. 😁
class GraphCodeBERTEmbeddingModel:
def __init__(self, model_name="microsoft/codebert-base"):
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.model = RobertaModel.from_pretrained(model_name)
def get_embedding(self, text):
"""
Generate a CodeBERT embedding for the given text.
"""
inputs = self.tokenizer(text, return_tensors="pt", max_length=512, truncation=True, padding="max_length")
with torch.no_grad():
outputs = self.model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return cls_embedding
A table is defined with a VECTOR-typed column to store the embeddings. Please note that COLUMNAR index is not supported for VECTOR-typed column.
CodeBERT embeddings have 768 dimensions. It can process texts of the maximal length of 512 tokens.
CREATE TABLE TrakCareCodeVector (
file VARCHAR(150),
codes VARCHAR(2000),
codes_vector VECTOR(DOUBLE,768)
)
The Python DB-API is used to establish a connection with IRIS instance to execute the SQL statements.
- Build the vector database for Trakcare source code.
- Retrieve the top_K highest DOT_PRODUCT code embeddings from IRIS vector database.
import iris
import os
from dotenv import load_dotenv
load_dotenv()
class IrisConn:
"""Connection with IRIS instance to execute the SQL statements """
def __init__(self) -> None:
connection_string = os.getenv("CONNECTION_STRING")
username = os.getenv("IRISUSERNAME")
password = os.getenv("PASSWORD")
self.connection = iris.connect(
connectionstr=connection_string,
username=username,
password=password,
timeout=10000,
)
self.cursor = self.connection.cursor()
def insert(self, params: list):
try:
sql = "INSERT INTO TrakCareCodeVector (file, codes, codes_vector) VALUES (?, ?, TO_VECTOR(?,double))"
self.cursor.execute(sql,params)
except Exception as ex:
print(ex)
def fetch_query(self, query: str):
self.cursor.execute(query)
return self.cursor.fetchall()
def close_db(self):
self.cursor.close()
self.connection.close()
from transformers import AutoTokenizer, AutoModel, RobertaTokenizer, RobertaModel, logging
import torch
import numpy as np
import os
from db import IrisConn
from GraphcodebertEmbeddings import MethodEmbeddingGenerator
from IRISClassParser import parse_directory
import sys, getopt
class GraphCodeBERTEmbeddingModel:
def __init__(self, model_name="microsoft/codebert-base"):
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.model = RobertaModel.from_pretrained(model_name)
def get_embedding(self, text):
"""
Generate a CodeBERT embedding for the given text.
"""
inputs = self.tokenizer(text, return_tensors="pt", max_length=512, truncation=True, padding="max_length")
with torch.no_grad():
outputs = self.model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return cls_embedding
class IrisVectorDB:
def __init__(self, vector_dim):
"""
Initialize the IRIS vector database.
"""
self.conn = IrisConn()
self.vector_dim = vector_dim
def insert(self, description: str, codes: str, vector):
params=[description, codes, f'{vector.tolist()}']
self.conn.insert(params)
def search(self, query_vector, top_k=5):
query_vectorStr = query_vector.tolist()
query = f"SELECT TOP {top_k} file,codes FROM TrakCareCodeVector ORDER BY VECTOR_COSINE(codes_vector, TO_VECTOR('{query_vectorStr}',double)) DESC"
results = self.conn.fetch_query(query)
return results
class CodeRetrieveChatbot:
def __init__(self, embedding_model, vector_db):
self.embedding_model = embedding_model
self.vector_db = vector_db
def add_to_database(self, description, code_snippet, embedding = None):
if embedding is None:
embedding = self.embedding_model.get_embedding(code_snippet)
self.vector_db.insert(description, code_snippet, embedding)
def retrieve_code(self, query, top_k=5):
"""
Retrieve the most relevant code snippets for the given query.
"""
query_embedding = self.embedding_model.get_embedding(query)
results = self.vector_db.search(query_embedding, top_k)
return results
Since CodeBERT can process texts with the maximal length of 512 tokens. Large classes and methods have to be chunked into smaller parts. Each chunk is then embedded and stored in the vector database.
from transformers import AutoTokenizer, AutoModel, RobertaTokenizer, RobertaModel
import torch
from IRISClassParser import parse_directory
class MethodEmbeddingGenerator:
def __init__(self, model_name="microsoft/codebert-base"):
"""
Initialize the embedding generator with CodeBERT.
:param model_name: The name of the pretrained CodeBERT model.
"""
self.tokenizer = RobertaTokenizer.from_pretrained(model_name)
self.model = RobertaModel.from_pretrained(model_name)
self.max_tokens = self.tokenizer.model_max_length
def chunk_method(self, method_implementation):
"""
Split method implementation into chunks based on lines of code that approximate the token limit.
:param method_implementation: The method implementation as a string.
:return: A list of chunks.
"""
lines = method_implementation.splitlines()
chunks = []
current_chunk = []
current_length = 0
for line in lines:
line_token_estimate = len(self.tokenizer.tokenize(line))
if current_length + line_token_estimate <= self.max_tokens - 2:
current_chunk.append(line)
current_length += line_token_estimate
else:
chunks.append("\n".join(current_chunk))
current_chunk = [line]
current_length = line_token_estimate
if current_chunk:
chunks.append("\n".join(current_chunk))
return chunks
def get_embeddings(self, method_implementation):
"""
Generate embeddings for a method implementation, handling large methods by chunking.
:param method_implementation: The method implementation as a string.
:return: A list of embeddings (one for each chunk).
"""
chunks = self.chunk_method(method_implementation)
embeddings = {}
for chunk in chunks:
inputs = self.tokenizer(chunk, return_tensors="pt", truncation=True, padding=True, max_length=self.max_tokens)
with torch.no_grad():
outputs = self.model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze(0)
embeddings[chunk] = cls_embedding.numpy()
return embeddings
def process_methods(self, methods):
"""
Process a list of methods to generate embeddings for each.
:param methods: A list of dictionaries with method names and implementations.
:return: A dictionary with method names as keys and embeddings as values.
"""
method_embeddings = {}
for method in methods:
method_name = method["name"]
implementation = method["implementation"]
print(f"Processing method embedding: {method_name}")
method_embeddings[method_name] = self.get_embeddings(implementation)
return method_embeddings
The stack uses Angular as the frontend and Python (Flask) as the backend.

The searching result is not perfec because the embedding model is not pre-trained for objectscripts.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
