Limpiar filtro
Pregunta
Kurro Lopez · 30 oct, 2019
Hola,
Necesitamos crear una versión de una API existente, por lo que vamos a establecer una versión predeterminada (hasta ahora) para las conexiones actuales a la versión 1
Mi primer intento es:
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="(?i)/check" Method="GET" Call="CheckApi"/>
<Route Url="(?i)/getcustomer" Method="POST" Call="GetCustomerDefault"/>
<Route Url="(?i)/revoke" Method="DELETE" Call="RevokeDefault"/>
<Route Url="(?i)/:version/getcustomer" Method="POST" Call="GetCustomer"/>
<Route Url="(?i)/:version/revoke" Method="DELETE" Call="Revoke"/>
</Routes>
}
Parameter DEFAULTVERSION = 1;
Parameter CURRENTVERSION = 2;
/// Get customer info (API version default)
ClassMethod GetCustomerDefault() As %Status
{
quit ..GetCustomer(..#DEFAULTVERSION)
}
ClassMethod GetCustomer(pVersion As %Integer) As %Status
{
// This is the code for all version. Get the Id and pass into the message
........
quit $$$OK
}
Además, tengo un parámetro llamado DEFAULTVERSION con valor 1
De esta manera, las llamadas más nuevas tendrán el número de versión y la respuesta según la versión de API
La URL será:
apiserver.com/api/2/getCustomer
Estoy comprobando si la versión es menor que una CURRENTACTUAL, la llamada está bien
Según una nueva especificación, la URL será "api/v2/getCustomer", antes era un número entero, y ahora será una cadena.
¿Cómo puedo verificar si este parámetro está bien formado (v y número), luego puedo evaluar si el número es una versión API válida?
Podemos cambiar nuestra versión, por lo que cualquier sugerencia será bienvenida. Hola,
No es posible porque el cliente tiene instalado una versión Healthcare 2017.2 y no tiene mucha intención de cambiar de aplicación. Además, las dos versiones han de convivir simultaneamente en producción. Hola Francisco,
¿no os podéis plantear trabajar con el API Manager como explican David y Alberto aquí?
https://es.community.intersystems.com/post/nuevo-v%C3%ADdeo-desarrollar-y-gestionar-apis-con-intersystems-iris-data-platform
Así no tendrías que preocuparte de si te están accediendo a la api correcta, solo habría una publicada y tú podrías estar trabajando en las versiones que quisieras y luego pasarla a producción sin cambiar la url de acceso.
Saludos!
Artículo
Mathew Lambert · 25 jun, 2020
El propósito de este artículo es reforzar el perfil de un procedimiento muy potente que ha estado disponible desde hace mucho tiempo para nosotros, y abrir un debate sobre las maneras en que puede utilizarse (o explotarse).
Puedes leer más información sobre el el mecanismo aquí. En resumen, cuando definas una clase puedes utilizar la palabra clave Projection para referirte a una o más clases de proyección. Una clase de proyección permite implementar métodos que se llaman desde puntos clave en el ciclo de vida de tu clase.
Una clase de proyección debe contener %Projection.AbstractProjection y normalmente implementará al menos uno de los siguientes métodos:
CreateProjection
RemoveProjection
Se llamará a CreateProjection una vez que tu clase haya sido compilada. Se llamará a RemoveProjection justo antes de que tu clase se compile nuevamente, o justo antes de que se elimine.
Creo que este procedimiento originalmente se utilizó para generar archivos Java, que implementaron una proyección en Java para una clase de Caché. Desde entonces, este procedimiento se esta usando ampliamente y se esta volviendo cada vez más sofisticado. En la versión 2015.2 conté veinticuatro %-clases que provienen de %Projection.AbstractProjection.
Además de la forma en que InterSystems utiliza el procedimiento, también observé que este se aprovecha de otras maneras. Aquí hay un par de ejemplos:
UMLExplorer se envía como un archivo XML que contiene cuatro clases. Una de ellas es una clase para proyecciones llamada ClassExplorer.WebAppInstaller, la cual se proyecta ingeniosamente a sí misma:
Class ClassExplorer.WebAppInstaller Extends %Projection.AbstractProjection
{
Projection Reference As WebAppInstaller;
...
Por lo tanto, cuando esta clase se compila, se ejecuta su método CreateProjection, realizando cualesquiera sean los pasos que el desarrollador codificó ahí. En este caso añade una aplicación web llamada /CacheExplorer, pero podría hacer cualquier cosa que permitan los permisos de la persona que compiló la clase.
Un sitio que usa la herramienta Deltanji para administrar el código fuente creó una clase para proyectar utilidades. Cada vez que activan una pieza de trabajo que requiere de algunos pasos para instalarse y ejecutarse en un namespace objetivo, ellos implementan esos pasos en una clase de distribución (D), que tiene una proyección que hace referencia a su clase para proyectar utilidades (P). Entonces, ellos hacen un paquete (D) con la pieza de trabajo. Cuando (D) se carga y compila en un namespace objetivo, el método CreateProjection de (P) es llamado automáticamente y se le pasa el nombre de la clase (D), lo que le permite llamar a los métodos de (D)
Si has visto otras maneras de utilizar la proyección, o si tú mismo has diseñado una nueva forma de usarla, compártela como un comentario en esta publicación
Una última reflexión que me gustaría compartir. Este procedimiento significa que probablemente deberíamos pensarlo dos veces antes de realizar una compilación durante la importación de un archivo XML, en especial si no estamos seguros de que podemos confiar en su contenido. El alcance que tiene una proyección maliciosa de clase es grande.
Artículo
Ricardo Paiva · 19 ago, 2021
Este es el ejemplo de un código que funciona en Caché 2018.1.3 e IRIS 2020.2
No se mantendrá sincronizado con las nuevas versiones
¡Además NO cuenta con el servicio de Soporte de InterSystems!
Durante mi búsqueda de un snapshot de un objeto persistente, conocí una característica que me gustaría compartir, ya que podría ser útil en algunas situaciones especiales. Mi objetivo era tener una imagen del antes y el después durante las pruebas unitarias.Una clase persistente típica puede tener una definición de almacenamiento como esta:
Storage Default{ <Data name="kDefaultData"> +<Value name="1"> </Value> </Data> <DataLocation>^rcc.kD</DataLocation> <DefaultData>kDefaultData</DefaultData> <IdLocation>^rcc.kD</IdLocation> <IndexLocation>^rcc.kI</IndexLocation> <StreamLocation>^rcc.kS</StreamLocation> <Type>%Storage.Persistent</Type>}
Ahora apliqué este cambio:
Parameter MANAGEDEXTENT = 0; ;extent manager dislikes this change
Storage Default{ <Data name="kDefaultData"> +<Value name="1"> </Value> </Data> <DataLocation>@(%storage_"D")</DataLocation> <DefaultData>kDefaultData</DefaultData> <IdLocation>@(%storage_"D")</IdLocation> <IndexLocation>@(%storage_"I")</IndexLocation> <StreamLocation>@(%storage_"S")</StreamLocation> <Type>%Storage.Persistent</Type>}
Todo lo que tienes que hacer ahora para utilizarlo:
set %storage="^myGlobal" ;; normal use with ROLLBACKo set %storage="%myLocalVariable" ;; no ROLLBACKoset %storage="^||myPPG" ;; no ROLLBACK
y funciona como estás acostumbrado a que lo haga. Excepto en el caso de ROLLBACK (Reversión) ya que, por supuesto, no hay ningún Journal detrás de PPG o de las variables locales
Una secuencia de uso habitual para preparar una verificación de cambios podría ser similar a la siguiente:
set %storage="^rcc.k" set obj=##class(rcc.k).%OpenId(id) ;; get originaldo obj.%SetModified(1) ;; prepare for %Saveset %storage="^||rcc" ;; location of copyset sc=obj.%Save() ;; write copy to temp storage//// carry on with testing and changes and find what happened
Creo que merece la pena compartirlo.
Artículo
Mario Sanchez Macias · 15 nov, 2021
Trabajando en soporte generalmente me preguntan cuántos días hay que mantener los journals. ¿Debería ser dos días o después de dos copias de seguridad? ¿Más? ¿Menos? ¿Por qué dos?
La respuesta correcta (para la mayoría de los entornos) es que se debería conservar los ficheros de journal desde la última copia de seguridad validada. Es decir, hasta que no verifique si una copia de seguridad es válida (restaurando el archivo y verificándolo con la utilidad Integrity), no puede estar seguro de que haya una buena copia de los datos y no por tanto no se deberían purgar los journals de manera segura.
Por ejemplo, imagina que necesitas restaurar el sistema después de un fallo de hardware que corrompió algunas bases de datos. El primer paso sería coger la última copia de seguridad y restaurarla. Pero, ¿qué sucede si la copia de seguridad está dañada o se guardó en un disco defectuoso? En ese caso, deberíamos buscar una copia de seguridad anterior hasta encontrar una copia correcta y válida. Tras restaurarla, sí quisiésemos recuperar hasta el último momento, deberíamos aplicar los journals desde que se hizo la copia hasta el momento del fallo. Si sólo tenemos uno o dos días, no será suficiente y podríamos perder datos.
Por tanto, ¡La única forma de asegurarse de que sus copias de seguridad sean válidas es verificándolas! Y para verificar, me refiero a restaurar las bases de datos y validar los datos en ellas. La forma de verificar los datos dentro de una base de datos es mediante la utilidad Integrity.
Cuando explico esto, la mayoría de los administradores lo consideran una tarea compleja, que lleva mucho tiempo y que es difícil de automatizar. Por eso he decidido construir un verificador de Backups súper sencillo que permite validar los backups fácilmente.
La utilidad es un verificador de backups sencillo para copias de seguridad realizadas con InterSystems Iris. Restaura el fichero de backup (.cbk) automáticamente y luego ejecuta un chequeo de integridad. Toda la "magia" se realiza en el método restoreAll de la clase Installer. Si quieres mejorar y personalizar la utilidad, puedes tomar prestado el código y mejorarlo enviando un correo electrónico cuando termine con los resultados de la validación (por ejemplo).
Una vez que se haya restaurado la copia de seguridad y se haya ejecutado la verificación de integridad, el log de Docker (y messages.log) contendrá los resultados de la verificación de integridad y restauración. Las bases de datos restauradas aparecerán en una carpeta llamada Restore. No damos la importancia que debemos a las copias de seguridad. Creo que esto va a ahorrar más de un quebradero de cabeza! Cierto!
Sólo nos acordamos cuando nos hacen falta, y, os puedo garantizar que muchísimas veces las copias que pensábamos que están bien, no lo están, con la consiguiente pérdida de tiempo/datos y el estrés que genera. Si te digo la verdad, hice esta aplicación para demostrar lo sencillo que es validar copias y que no haya excusas
Artículo
Muhammad Waseem · 18 abr, 2022
# Antecedentes
En las versiones de InterSystems IRIS >=2021.2 podemos usar [irispython para escribir directamente código python encima de nuestras instancias IRIS](https://docs.intersystems.com/iris20212/csp/docbook/DocBook.UI.Page.cls?KEY=AEPYTHON#AEPYTHON_runpython_script). Esto nos permite usar paquetes de python, llamar a métodos, hacer consultas SQL y hacer casi cualquier cosa en Objectscript excepto pythonic.
Por ejemplo, a continuación compruebo si hay un *namespace*:
```python
#!/usr/irissys/bin/irispython
import iris
# call arbitrary class methods
result = iris.cls('%SYS.Namespace').Exists('USER')
if result == 1:
print(f"Namespace USER is present")
```
> Pero, ¿qué pasa si mi método en IRIS tiene parámetros especiales como `Output` y `ByRef`?
>¿Cómo podemos usar los parámetros de `Salida` en irispython?
Por ejemplo, [Ens.Director](https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=ENSLIB&CLASSNAME=Ens.Director) tiene muchos parámetros de salida en sus métodos, ¿cómo puedo usar estos parámetros en python?
[Ens.Director:GetProductionStatus](https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=ENSLIB&CLASSNAME=Ens.Director#GetProductionStatus)
```cos
// Un código auxiliar de método de ejemplo de Ens.Director
ClassMethod GetProductionStatus(Output pProductionName As %String, Output pState As %Integer...
```
### Probando los métodos de variables normales
A primera vista, puedes intentar lo siguiente:
```python
import os
# Establecer el namespace de forma manual
os.environ['IRISNAMESPACE'] = 'DEMONSTRATION'
import iris
# PRUEBA 1 con variables de salida
productionName, productionState = None, None
status = iris.cls('Ens.Director').GetProductionStatus(productionName, productionState)
print("Success? -- {}".format(productionState != None))
```
_¡Pero ambas pruebas no devolverán las variables de salida! Puedes probar esto por ti mismo en cualquier *namespace* de Ensemble_
# Usando iris.ref
La utilidad irispython `iris.ref` se puede utilizar para capturar las variables `Output` y `ByRef`.
1. Crea un objeto `iris.ref()`
2. Llama a tu Método ObjectScript
3. Utiliza la variable `.value` para obtener el resultado de ese parámetro
```python
import os
# Establecer el namespace de la manera difícil
os.environ['IRISNAMESPACE'] = 'DEMONSTRATION'
import iris
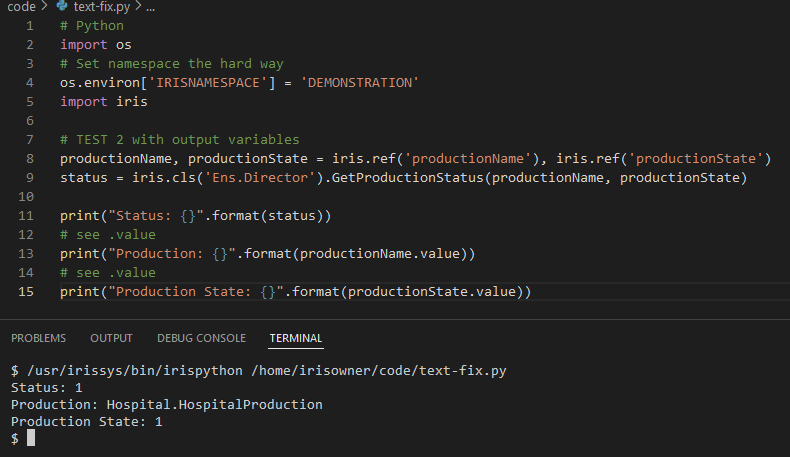
# PRUEBA 2 con variables de salida
productionName, productionState = iris.ref('productionName'), iris.ref('productionState')
status = iris.cls('Ens.Director').GetProductionStatus(productionName, productionState)
print("Status: {}".format(status))
# see .value
print("Production: {}".format(productionName.value))
# see .value
print("Production State: {}".format(productionState.value))
```
Artículo
Alberto Fuentes · 15 jun, 2022
¡Hola desarrolladores! Quería compartir hoy un ejemplo muy interesante por parte de Tani Frankel. Se trata de una aplicación sencilla sobre la utilidad SystemPerfomance.
Repasando nuestra documentación sobre la rutina de monitorización ^SystemPerformance (conocida como ^pButtons en versiones anteriores a IRIS), un cliente me dijo «Entiendo todo esto pero ojalá fuese más simple, más sencillo para definir perfiles y gestionarlos, etc.».
Entonces pensé que sería interesante como ejercicio facilitar una pequeña interfaz para hacer esas tareas más sencillas.
El primer paso era envolver en una API basada en clases la rutina actual de ^SystemPerformance.
Además, aproveché para añadir algunas otras funcionalidades como mostrar qué perfiles están ejecutándose actualmente, el tiempo que les falta, procesos que han estado en ejecución con anterioridad, etc.
El siguiente paso era añadir sobre esta API, una API REST.
Con este artefacto listo, cualquier puede ya lanzarse y construir una pequeña interfaz de usuario moderna.
Por ejemplo:
Así que aquí os comparto algunos de los pasos necesarios:
Dos clases, que son la API básica:
así como la clase que contiene la API REST (incluyendo algunos tests unitarios).
Un JSON con la especificación Swagger para la API REST.
Y una interfaz gráfica sencilla en Angular (basada en http://websystique.com/angularjs/angularjs-crud-application-using-ngresource/)
Algunas notas importantes:
La mayor parte de los métodos de la API básica utilizan puntos de entrada que no están documentados o soportados en ^SystemPerformance o ^pButtons. Algunos de esos métodos manejan estructuras internas. Estos métodos que no están soportados ni documentados pueden dejar de funcionar según próximas versiones sin previo aviso.
El código no intenta de ninguna manera servir como un ejemplo de «mejor práctica» a la hora de crear aplicaciones Angular basadas en APIs REST sobre IRIS. La parte de la interfaz gráfica es un simple ejemplo como punto de partida (de hecho, hay partes sin implementar como el directorio para logs, el refresco de contenidos, etc.)
El código inicial fue escrito hace tiempo, así que:
(a) Se ha modificado para que funcione sobre IRIS (se han tenido que hacer algunos cambios en los nombres).
(b) Inicialmente no se utilizaba el planteamiento spec-first. Ahora sí que lo utiliza.
(c) Es posible que no utilice todas las últimas funcionalidades disponibles a día de hoy.
(d) Se ha añadido también la posibilidad de ejecutarlo en un contenedor Docker.
(e) Se ha añadido también soporte para ser instalado como un paquete ZPM.
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Alberto Fuentes · 30 ene, 2023
# OCR DEMO
Esta es una demo de la funcionalidad OCR utilizando la librería `pero-ocr` de Python.
Utilizaremos la librería en una instancia InterSystems IRIS.
## Demo
Este es un ejemplo de los datos de entrada:

Y este es el resultado del OCR, donde tenemos la siguiente información:
* El texto, que está en la etiqueta `TextEquiv`
* La confianza de la lectura, presente en el atributo `conf` de la etiqueta `TextEquiv`
* Las coordenadas del texto, que están en la etiqueta `Coords`
```xml
Pero OCR
2022-12-13T08:47:12.207893+00:00
2022-12-13T08:47:12.207893+00:00
IN
CONGRESS, JULY 4, 1776.
Dhe unaniwons Declaratton of te Heten maiss States of TNmerica
hen n lí loune z human venl, i kemu nematy k mpeopě toíohohhehttcal bandí uhích have connechdí tem vith ancthet, andíl
o hi ſhwes f he eail, fie rehatal andequal flohon & ufch lhe laav . kalut and Aloil ped entilt ttem, a dant rafech to the ofunin o manknd tequies fhat thep
imuiaa
Qlver
Vbalřew/
17.
```
## Instalación
```bash
git clone
```
⚠️ ¡Importante! Esta demo requiere instalar dos modelos (ambos son requeridos)
Para instalar un modelo, descárgalo desde la página de descargas y descomprímelo en el directorio `misc/pero-ocr-fix-computation-on-cpu` del proyecto:
* https://github.com/grongierisc/iris-pero-ocr/releases/download/v1.0.0/OCR_350000.pt.cpu
* https://github.com/grongierisc/iris-pero-ocr/releases/download/v1.0.0/ParseNet_296000.pt.cpu
Después, ejecuta:
```bash
docker-compose up
```
## Uso
Coloca cualquier imagen de muestra de la carpeta `samples` y cópiala en la carpeta `misc/in` para que sea procesada por el OCR.
Los resultados estarán en la carpeta `misc/out`.
Verás los archivos xml con los resultados y las imágenes con el texto detectado.
Puedes monitorizar el progreso [aquí](http://localhost:53795/csp/irisapp/EnsPortal.ProductionConfig.zen?NAMESPACE=IRISAPP&NAMESPACE=IRISAPP&) y accediendo con `_SYSTEM` y `SYS`.
## Cómo funciona en IRIS
El OCR es un Business Service que analiza todos los ficheros en la carpeta `misc/in` y pone los resultados en una cola de mensajes.
La cola de mensajes es consumida por una Business Operation que pone los resultados en la carpeta `misc/out`.
El código está en la carpeta `src/python/pero-ocr`.
Pregunta
Laura Blázquez García · 24 abr, 2025
Hola!
Recientemente he estado probando a crear nuestro propio repositorio de paquetes con IPM. He podido crearlo sin problemas, y he visto que, al final, nuestro repositorio IPM no deja de ser una instancia de IRIS. En el ejemplo del que he partido, utiliza la versión community. Y mi pregunta es, para tener nuestro repositorio disponible para toda la compañía, ¿podemos seguir con la versión community, o debe ser una versión enterprise con licencia?
Y ya que estoy, ¿hay alguna forma de saber qué paquetes se han descargado, y por quién?
Muchas gracias! ¡Buenas @Laura.BlázquezGarcía !
Por aquí tienes un artíc@Evgeny.Shvarov al respecto de la creación y publicación de proyectos en el IPM, básicamente es añadir el archivo module.xml con determinados parámetros para que capture el código que quieras publicar. Posteriormente le mandas un mensaje y el incluye vuestro proyecto al repositorio del IPM. Hola @LuisAngel.PérezRamos!
No veo el link al artículo, quizá te refieras a alguno de estos?
https://community.intersystems.com/post/why-docker-ipm-and-objectscript-quality-are-important
https://community.intersystems.com/post/installing-objectscript-solutions-without-source-code-or-deploy-mode-using-ipm-package-manager
De todas formas, mi pregunta va sobre tener nuestro propio repositorio IPM, privado. Es decir, crear nuestro propio registro. Lo he conseguido hacer en local, la verdad es que con la template que hay en el github de la comunidad ha sido muy fácil. Pero a la hora de tenerlo disponible para toda la compañía y empezar a subir nuestras propias librerías, antes de arrancarlo con la versión que hay ahora, etc, quería saber si es conveniente crearlo en una versión IRIS enterprise, o vale con que sea una IRIS Community.
Gracias! Perdona, que te contesté desde el móvil y me comí la URL:
https://community.intersystems.com/post/setting-your-own-intersystems-objectscript-package-manager-registry No había visto ese artículo, pero más o menos es lo que he seguido. No he instalado zpm-registry en una instancia de IRIS que ya teníamos, sino que he levantado un contenedor nuevo, con la versión community.
Nuestro caso es que trabajamos para clientes que tienen IRIS, cada uno el suyo, pero tenemos librerías comunes que utilizamos en estos clientes. Mi idea era levantar un registry propio para nuestra compañía, en la que tener estas librerías disponibles para cualquier cliente, y en caso de que cada cliente lo necesite, levantar en sus instancias su registry privado.
Entiendo, entonces, que lo ideal es tener el registry levantado en la instancia de IRIS que ya tengamos, y no utilizar un contenedor aparte con una versión Community. Es así? A priori debería dar igual la versión de IRIS porque la Community me parece que no está limitada, pero si lo que vais a hacer es algo más corporativo deberíais usar vuestra licencia de IRIS licenciada.
Artículo
Ricardo Paiva · 10 nov, 2022
Hace tiempo presenté un nuevo driver para Django for IRIS. Ahora voy a mostrar cómo utilizar Django con IRIS en la práctica.
Nota importante: Django no funciona bien con la Community Edition de IRIS. La Community Edition solo tiene disponibles 5 conexiones, y Django las usará muy rápido. Así que, desafortunadamente por esta razón no puedo recomendar este método para desarrollar nuevas aplicaciones, debido a la dificultad de predecir el uso de la licencia.
Inicio del proyecto Django
Para empezar, tenemos que instalar Django
pip install django
Después, creamos un proyecto llamado demo. Creará una carpeta de proyectos con el mismo nombre
django-admin startproject demo
cd demo
o se puede hacer en una carpeta existente
django-admin startproject main .
Este comando genera unos pocos archivos python para nosotros.
Donde:
manage.py: utilidad de línea de comando que permite interactuar con este proyecto Django de varias maneras
directorio main: es el paquete Python actual para vuestro proyecto
main/__init__.py: un archivo vacío que dice a Python que este directorio debería ser consideredo un paquete Python
main/settings.py: settings/configuración para este proyecto Django
main/urls.py: Las declaraciones URL para este proyecto Django; un “índice” de vuestro sitio con la funcioanlidad de Django
main/asci.py: Un punto de entrada para servidores web compatibles con ASGI para atender vuestro proyecto
main/wsci.py: Un punto de entrada para servidores web compatibles con WSGI para atender vuestro proyecto
Incluso desde este punto podemos empezar nuestro proyecto y, de alguna manera, funcionará
$ python manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced). You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
July 22, 2022 - 15:24:12
Django version 4.0.6, using settings 'main.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Ahora, se puede ir al navegador y abrir la URL http://127.0.0.1:8000 allí
Añadir IRIS
Vamos a añadir acceso a IRIS, y para hacerlo necesitamos instalar unas cuantas dependencias de nuestro proyecto, y la forma correcta de hacerlo es definirlo en el archivo llamado requirements.txt con este contenido, donde deberíamos añadir django como una dependencia
# Django itself
django>=4.0.0
Y después, el driver de IRIS for Django, publicado. Desafortunadamente, InterSystems no quiere publicar drivers propios en PyPI, así que tenemos que definirlo de esta manera más "fea". Estad atentos, pueden eliminarlo en cualquier momento, por lo que puede dejar de funcionar en el futuro. (Si estuviera en pypi, se instalaría como una dependencia de django-iris, no siendo necesaria su definición.)
# InterSystems IRIS driver for Django, and DB-API driver from InterSystems
django-iris==0.1.13
https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/main/DB-API/intersystems_irispython-3.2.0-py3-none-any.whl
Instalar dependencias definidas en este archivo con comando
pip install -r requirements.txt
Ahora, podemos configurar nuestro proyecto para usar IRIS. Para hacerlo, tenemos que actualizar el parámetro DATABASES en el archivo settings.py, con líneas como esta, en la que NAME apunta al Namespace en IRIS, y la puerta al SuperPort donde tenemos IRIS.
DATABASES = {
'default': {
'ENGINE': 'django_iris',
'NAME': 'USER',
'USER': '_SYSTEM',
'PASSWORD': 'SYS',
'HOST': 'localhost',
'PORT': 1982,
}
}
Django tiene ORM, y modelos almacenados en el proyecto, y requiere modelos de Django sincronizados con Database como tablas. Por defecto, hay unos pocos modelos, relacionados con auth. Y podemos ejecutar migrate ahora
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying auth.0012_alter_user_first_name_max_length... OK
Applying sessions.0001_initial... OK
Si vamos a IRIS, encontraremos varias tablas extra allí
Definir más modelos
Es el momento de añadir algunos de nuestros modelos. Para hacerlo, añade un nuevo archivo models.py, con contenido como este
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
dob = models.DateField()
sex = models.BooleanField()
Como puedes ver, tiene diferentes tipos de campos. Entonces este modelo tiene que estar preparado para Database. Antes de hacerlo, añade nuestro proyecto main a INSTALLED_APPS en settings.py
INSTALLED_APPS = [
....
'main',
]
Y podemos makemigrations. Este comando tiene que ser llamado después de cualquier cambio en el modelo, se ocupa de los cambios históricos en el modelo, y no importa qué versión de la aplicación está instalada, la migración sabrá cómo actualizar el esquema en la base de datos
$ python manage.py makemigrations main
Migrations for 'main':
main/migrations/0001_initial.py
- Create model Person
Podemos ejecutar migrate otra vez, ya sabe que las migraciones anteriores ya están hechas, así que solo ejecuta la nueva
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, main, sessions
Running migrations:
Applying main.0001_initial... OK
Y, de hecho, podemos ver cómo se ve la migración desde la vista de SQL.
$ python manage.py sqlmigrate main 0001
--
-- Create model Person
--
CREATE TABLE "main_person" ("id" BIGINT AUTO_INCREMENT NOT NULL PRIMARY KEY, "first_name" VARCHAR(30) NULL, "last_name" VARCHAR(30) NULL, "dob" DATE NOT NULL, "sex" BIT NOT NULL);
Pero es posible acceder a las tablas ya existentes en la base de datos, por ejemplo, si ya tienes una aplicación funcionando. Yo tengo el gestor de paquetes zpm package posts-and-tags instalado, vamos a hacer un modelo para la tabla community.posts
$ python manage.py inspectdb community.post
# This is an auto-generated Django model module.
# You'll have to do the following manually to clean this up:
# * Rearrange models' order
# * Make sure each model has one field with primary_key=True
# * Make sure each ForeignKey and OneToOneField has `on_delete` set to the desired behavior
# * Remove `managed = False` lines if you wish to allow Django to create, modify, and delete the table
# Feel free to rename the models, but don't rename db_table values or field names.
from django.db import models
class CommunityPost(models.Model):
id = models.AutoField(db_column='ID') # Field name made lowercase.
acceptedanswerts = models.DateTimeField(db_column='AcceptedAnswerTS', blank=True, null=True) # Field name made lowercase.
author = models.CharField(db_column='Author', max_length=50, blank=True, null=True) # Field name made lowercase.
avgvote = models.IntegerField(db_column='AvgVote', blank=True, null=True) # Field name made lowercase.
commentsamount = models.IntegerField(db_column='CommentsAmount', blank=True, null=True) # Field name made lowercase.
created = models.DateTimeField(db_column='Created', blank=True, null=True) # Field name made lowercase.
deleted = models.BooleanField(db_column='Deleted', blank=True, null=True) # Field name made lowercase.
favscount = models.IntegerField(db_column='FavsCount', blank=True, null=True) # Field name made lowercase.
hascorrectanswer = models.BooleanField(db_column='HasCorrectAnswer', blank=True, null=True) # Field name made lowercase.
hash = models.CharField(db_column='Hash', max_length=50, blank=True, null=True) # Field name made lowercase.
lang = models.CharField(db_column='Lang', max_length=50, blank=True, null=True) # Field name made lowercase.
name = models.CharField(db_column='Name', max_length=250, blank=True, null=True) # Field name made lowercase.
nid = models.IntegerField(db_column='Nid', primary_key=True) # Field name made lowercase.
posttype = models.CharField(db_column='PostType', max_length=50, blank=True, null=True) # Field name made lowercase.
published = models.BooleanField(db_column='Published', blank=True, null=True) # Field name made lowercase.
publisheddate = models.DateTimeField(db_column='PublishedDate', blank=True, null=True) # Field name made lowercase.
subscount = models.IntegerField(db_column='SubsCount', blank=True, null=True) # Field name made lowercase.
tags = models.CharField(db_column='Tags', max_length=350, blank=True, null=True) # Field name made lowercase.
text = models.CharField(db_column='Text', max_length=-1, blank=True, null=True) # Field name made lowercase.
translated = models.BooleanField(db_column='Translated', blank=True, null=True) # Field name made lowercase.
type = models.CharField(db_column='Type', max_length=50, blank=True, null=True) # Field name made lowercase.
views = models.IntegerField(db_column='Views', blank=True, null=True) # Field name made lowercase.
votesamount = models.IntegerField(db_column='VotesAmount', blank=True, null=True) # Field name made lowercase.
class Meta:
managed = False
db_table = 'community.post'
Está marcado como managed = False, lo que significa que makemigrations y migrate no funcionarán para esta tabla. Omitiendo el nombre de la tabla, producirá una lista larga de módulos, incluyendo las tablas ya creadas con Django previamente.
Artículo
Nancy Martínez · 7 ago, 2019
¡Hola a tod@s!Este artículo es una pequeña descripción general de una herramienta que permitirá entender las clases y su estructura, dentro de los productos de InterSystems: desde IRIS hasta Caché, Ensemble y HealthShare.En resumen, con esta herramienta se visualiza una clase o un paquete completo, se muestran las relaciones que existen entre las clases y proporciona toda la información que se encuentra disponible para los desarrolladores y líderes de equipos sin necesidad examinar el código, utilizando el Studio.Si estás aprendiendo a utilizar los productos de InterSystems, o simplemente estás interesado en aprender algo nuevo sobre las soluciones que ofrece la tecnología de InterSystems, ¡eres más que bienvenido a leer la descripción general de ObjectScript Class Explorer! Introducción a los productos de InterSystemsIRIS (anteriormente conocido como Caché) es una DBMS Base de Datos Multi Modelo. Es posible acceder a los datos mediante consultas SQL o al interactuar con los objetos y procedimientos almacenados por las interfaces que están disponibles para varios lenguajes de programación. Pero la primera opción siempre es desarrollar aplicaciones en el lenguaje nativo e integrado de la DBMS— ObjectScript (COS).Caché es compatible con las clases que se encuentran en el nivel de la DBMS. Existen dos principales tipos de clases: Persistentes (pueden almacenarse en la base de datos) y registradas (no se almacenan en la base de datos y desempeñan el papel de programas y controladores). Además, existen varios tipos de clases especiales: Serial (son clases que pueden integrarse en clases persistentes para crear tipos de datos complejos, como por ejemplo direcciones), DataType (se utiliza para crear tipos de datos definidos por el usuario), Index, View y Stream.Class ExplorerCaché Class Explorer es una herramienta que visualiza la estructura de las clases de Caché como un diagrama, muestra las dependencias que existen entre las clases y toda la información importante, incluido el código de los métodos, consultas, bloques xData, comentarios, documentos de apoyo y palabras clave de varios elementos de las clases.FuncionalidadClass Explorer utiliza una versión extendida del estándar UML para la visualización, debido a que Caché cuenta con un conjunto adicional de entidades que no son compatibles con el estándar UML , pero que son importantes para Caché: consultas, bloques xData, muchas de las palabras clave para los métodos y propiedades (como por ejemplo: System, ZenMethod, Hidden, ProcedureBlock), relaciones padre/ hijo, de uno a muchos, tipos de clase, entre otras.Caché Class Explorer (version 1.14.3) te permitirá hacer lo siguiente:Visualizar la jerarquía de los paquetes, un diagrama de clases o el paquete completo,Editar la apariencia de un diagrama después de visualizarlo,Guardar la imagen actual de un diagrama de clases,Guardar la apariencia actual de un diagrama y recuperarla en el futuro,Realizar búsquedas por cualquier palabra clave que se muestre en un diagrama o árbol de clases,Utilizar la información sobre las herramientas para obtener todos los detalles de las clases, sus propiedades, métodos, parámetros, consultas y bloques xData,Visualizar el código de los métodos, consultas o bloques xData,Activar o desactivar la visualización de cualquiera de los elementos del diagrama, incluidos los iconos gráficosEn la siguiente imagen se puede ver cómo se visualizan las clases en Class Explorer, y así comprender mejor los conceptos mencionados en este artículo. Como ejemplo, veamos el paquete “Cinema” del namespace “SAMPLES”:Descripción general de las funcionesLa barra lateral izquierda contiene un árbol del paquete. Situando el cursor sobre el nombre del paquete y haciendo clic en un botón que aparece en el lado derecho se podrá visualizar el paquete completo. Si se selecciona la clase en el árbol del paquete se representará junto con sus clases vinculadas.Class Explorer puede mostrar varios tipos de dependencias entre las clases:Herencia. Se muestra con una flecha de color blanco que apunta hacia la dirección de la clase que se heredó;“Asociación” o relación entre las clases. Si un campo de alguna de las clases contiene una clase de otro tipo, el generador de diagramas lo mostrará como una relación de asociación;Relaciones padre-hijo y de uno a muchos: contienen las reglas para mantener la integridad de los datos.Si se sitúa el cursor sobre la relación, se resaltarán las propiedades establecidas en ella:Se debe tener en cuenta que Class Explorer no profundizará y no creará dependencias para las clases que se encuentran fuera del paquete actual. Únicamente mostrará las clases que se encuentran en el paquete actual, y si se necesita limitar la profundidad con que Class Explorer realice búsquedas para las clases, se debe utilizar la opción “Nivel de dependencia”:La clase en sí, se muestra como un recuadro que se divide en seis secciones:Nombre de la clase: si posiciona el cursor sobre el nombre de la clase, se podrá saber cuándo fue creada, sus modificaciones, ver los comentarios y todas las palabras clave que se asignaron a la clase. Al hacer doble clic sobre el encabezado de la clase se abrirá su documentación,Parámetros de la clase: todos los parámetros están asignados por tipo, palabras clave y comentarios. Los parámetros en cursivas, al igual que cualquier otra propiedad, contienen información sobre las herramientas y pueden desplazarse,Las propiedades de las clases son similares a las de los parámetros,Métodos: puede hacer clic sobre cualquiera de los métodos para ver su código fuente. La sintaxis de COS se resaltará,Consultas: son similares a los métodos, al hacer clic sobre ellos, se podrá ver su código fuente,Bloques xData: estos bloques contienen principalmente datos de tipo XML. Al hacer clic sobre ellos se mostrará el código fuente con formato en el bloqueDe manera predeterminada, cada clase se visualiza mediante una serie de iconos gráficos. El significado de cada icono puede determinarse al hacer clic en el botón Help que se encuentra en la esquina superior derecha de la pantalla. Si necesita una notación UML más o menos estricta que se muestra de forma predeterminada, así como la visualización de cualquiera de las secciones de la clase, se puede desactivar desde la sección Configuraciones.Si un diagrama es muy grande y no resulta familiar, se puede utilizar la función para buscar diagramas rápidamente. Se resaltarán las clases que contengan cualquier parte de la palabra clave introducida. Para avanzar a la siguiente coincidencia, se presiona Enter o se hace clic nuevamente en el botón de búsqueda:Finalmente, después de hacer todas las ediciones en el diagrama, se eliminarán todas las relaciones innecesarias y los elementos se colocarán en las posiciones correctas para lograr la apariencia deseada, se puede guardar al hacer clic en el botón "Download" que se encuentra en la esquina inferior izquierda: Cuando actives el botón del pin , se guardará la posición de los elementos que se encuentren en el diagrama del conjunto (o de un paquete) de clases actual. Por ejemplo, si selecciona las clases A y B, y después guarda la visualización con el botón del pin, verá exactamente la misma visualización cuando seleccione las clases A y B nuevamente, incluso después de reiniciar el navegador o el equipo. Pero si solamente selecciona la clase A, el diseño será el predeterminado.InstalaciónPara instalar Caché Class Explorer, solamente tendrás que importar la última versión XML del paquete en cualquier namespace. Cuando se complete la importación, notarás que aparece una nueva aplicación web llamada hostname/ClassExplorer/ (la barra que se encuentra al final de la ruta, es necesaria).Instrucciones detalladas sobre la instalaciónDescargar el archivo con la última versión de Caché Class Explorer,Descomprimir el archivo XML llamado Cache/CacheClassExplorer-vX.X.X.xml,Importar el paquete en cualquier namespace mediante alguna de las siguientes formas:Simplemente arrastrando el archivo XML hacia el Studio,Utilizando el Portal de administración del sistema: Explorador del sistema -> Clases -> Importar, y especifique la ruta hacia el archivo local,Utilizando el comando del terminal: do ##class(%Installer.Installer).InstallFromCommandLine(“Path/Installer.cls.xml”),Consultar el registro de importación, si todo se realizó correctamente, se podrá abrir la aplicación web en http://hostname/ClassExplorer/. Si algo salió mal, revisar lo siguiente:Si se tienen los permisos correctos para importar clases hacia este namespace,Si el usuario de la aplicación web tiene suficientes privilegios para acceder a diferentes namespaces,Si aparece el error 404, comprobar si agregó una "/" barra al final de la URL.Algunas capturas de pantalla adicionales[Captura de pantalla 1] Paquete DSVRDemo, desplazamiento del cursor sobre el nombre de la clase.[Captura de pantalla 2] Paquete DataMining, búsqueda de la palabra clave "TreeInput" en el diagrama.[Captura de pantalla 3] Visualización del código del método en la clase JavaDemo.JavaListSample.[Captura de pantalla 4] Visualización del contenido del bloque XData en la clase ClassExplorer.Router.Probad cómo funciona Class Explorer en el namespace estándar SAMPLES: demostración. Y aquí se muestra una evaluación en video del proyecto.Cualquier observación, sugerencia o comentario es bienvenido; podéis dejarlo aquí o en la sección Repositorio de GitHub.¡Espero que os resulte útil!
Artículo
Jose-Tomas Salvador · 14 ago, 2019
La funcionalidad de Sincronización de Objetos no es nueva, estaba presente en Caché, pero quería explorar un poco más en profundidad cómo funciona. Siempre he pensado que la sincronización automática de una base de datos es compleja en sí misma pero, para algunos escenarios muy particulares quizá no sea tan difícil. Así que he considerado un caso de uso muy simple (OK, quizá el caso típico, no descubro nada... pero si es común y funciona, es bueno ). Puedes bajar el código de GitHub y compilarlo en tu sistema, generar automáticamente datos de ejemplo y jugar un poco con ello. Está hecho para InterSystems IRIS pero debería funcionar también en las últimas versiones de Caché y Ensemble.Ahora vayamos al detalle. Mi aplicación de ejemplo, a nivel de clases (lo siento, no hay interfaz de usuario), considera un pequeño modelo de datos donde tenemos Items, Customers, Employees y Orders. Trabajando off-line, si somos comerciales, normalmente limitaremos nuestras operaciones a consultar: Items, Customers y/o Employess (por lo que esos datos los consideramos de solo-lectura); y a añadir o modificar Orders. El registro o modificación de Items, Customers o Employees lo podemos considerar como algo que debe hacerse en el sistema de base de datos MASTER y de ahí transmitido a los sistemas de base de datos CLIENT .Cuando definimos el modelo de clases, tenemos que tener en cuenta que transacciones queremos sincronizar (en nuestro caso Orders) y cuales no. En la definición de las clases debemos añadir Parameter OBJJOURNAL = 1; para indicar que el sistema tiene que mantener la relación de los objetos de dicha clase insertados/borrados/modificados. Igualmente, en el/los sistema(s) cliente, la creación de objetos sucederá en momentos diferentes y, si usamos IDKEYs por defecto, tendremos situaciones en las cuales el mismo objeto (tras la sincronización) tendrá un IDKEY diferente en cada base de datos... Como gestionamos eso? ... Necesitamos una forma de identificar global y univocamente un objeto entre bases de datos... y aquí es cuando el GUID viene en nuestra ayuda. InterSystems IRIS puede generar un ID global unico (Globally Unique ID) para un objeto que puede ser compartido entre sistemas IRIS y todos ellos pueden usarlo para decidir si están tratando o no con el mismo objeto. Hasta aquí bien. Para que una clase pueda generar automáticamente un GUID para cada nuevo objeto, tenemos que incluir Parameter GUIDENABLED = 1; en su definición. Y con esto, todo nuestro trabajo está hecho.En nuestro caso de uso tendremos algo similar a esto (la definición completa en GitHub...aquí recortada): Class SampleApps.Synch.Data.Order Extends (%Persistent,%Populate,%JSON.Adaptor){ /// We don't want to force other classes reference to use %JSON.Adaptor. Then we decide export the /// GUID of referenced objects (by default it will include the JSON of object referenced) Parameter %JSONREFERENCE As STRING [ Constraint = "OBJECT,ID,OID,GUID", Flags = ENUM ] = "GUID"; ///We'll keep track of this class for synchronization (assuming that in off-line mode is not ///allowed by the app to modify master classes Parameter OBJJOURNAL = 1; Parameter GUIDENABLED = 1; ...}Class SampleApps.Synch.Data.Customer Extends (%Persistent, %Populate){ ///This allows the class to be stored with the GUIDs ///Also is a class referenced in Order class which is to be synchronized, ///so this class objects need a GUID to be able to synchronize their references Parameter GUIDENABLED = 1; ...}Class SampleApps.Synch.Data.Item Extends (%Persistent, %Populate){ Parameter GUIDENABLED = 1; ...}Class SampleApps.Synch.Data.Employee Extends (%Persistent,%Populate){ Parameter GUIDENABLED = 1; ...} Como ves, hay una clase: Order; con OBJJOURNAL y GUIDENABLED, y las otras clases sólo tienen GUIDENABLED. ¿Por qué? Porque los objetos de esas clases son referenciadas dentro de cada Order y, aunque no mantenemos sus modificaciones, necesitamos saber que la misma Order referencia a los mismos objetos sin importar en que sistema(s) estemos mirando (IMPORTANTE: si no habilitamos GUID en los objetos referenciados, las Orders serán sincronizadas pero sin ninguna información relacionada a las referencias).OK. Dicho esto, puedes empezar a jugar. He implementado algunas utilidades en SampleApps.Synch.Util para generar datos y ejecutar operaciones básicas de interción/modificación/borrado. También encontrarás una API REST básica (SampleApps.Synch.API.v1.RestLegacy) para poder hacerlo desde un cliente REST o desde ObjectScript indiferentemente.Dispones de más información junto con todo el resto del código del proyecto aqui en GitHub. Puedes clonar el repositorio o descargar un zip con el código fuente. Una vez tengas el código en tu servidor, carga y compila la clase SampleApps.Synch.Config.Installer desde tu terminal (dentro del namespace que elijas), y ejecuta la instalación:TEST>do $system.OBJ.Load("c:/Temp/SampleApps/Synch/Config/Installer.cls","ck")TEST>set args("InstallingFromNS")="TEST"TEST>set args("NamespaceMaster")="CORE"TEST>set args("NamespaceClient")="NODE"TEST>do ##class(SampleApps.Synch.Config.Installer).setup(.args) La mayoría de los argumentos tienen valores por defecto (echa un vistazo a la clase SampleApps.Synch.Config.Installer, pero, como puedes ver en el ejemplo arriba, puedes cambiarlos antes de llamar al método setup).Tras su ejecución, tendrás 2 nuevos namespaces: CORE y NODE (MASTER y CLIENT por defecto si llamas a setup sin argumentos) con datos ya precargados en Orders, Items, Customers y Employees. Ambas bases de datos son idénticas en este punto. Puedes jugar con los servicios REST para cargar nuevos datos, preparar la sincronización de datos de un namespace y después sincronizarlos en el otro. Cualquier conflicto descubierto durante la sincronización será almacenado en SampleApps.Synch.Data.SynchConflict que también puede consultarse a través de un servicio REST (aparte de desde SQL).En GitHub he incluido más información y también ejemplos para llamar a servicios REST para que así puedas empezar a probar facilmente. Simplemente haz click aquí, descarga el código fuente o clone el repositorio y podrás estar probando en 2 minutos.Disfruta!!
Pregunta
Albert Forcadell · 5 mayo, 2023
hola, me es imposible hacer una consulta de forma correcta. he probado con clausulas LIMIT, OVER ... no válidas para Intersystems por lo visto. Tambien probe con HAVING , con TOP, ... incluso con GPT y otras AI, pero nada.
lo siento, pero mi sql no da para mas.
TABLA Comp.AlbLin
COLUMNAS AlbLin.ID , AlbLin.Description , AlbLin.Price , AlbLin.Date
Estoy peleando por una query que me calcule la MEDIA del campo precio AlbLin.Price pero solo de los ultimos/mas recientes 3 registros de fecha
---
i am not able to launch a right instruction in sql , please. LIMIT ... OVER ...no valid for Intersystems. i ve tried all . with HAVING, with TOP ,... paying for Ai and nothing.
my apologises , i am so limited.
TABLE Comp.AlbLin
COLUMNS AlbLin.ID , AlbLin.Description , AlbLin.Price , AlbLin.Date
i fight for a query to get the AVG average of AlbLin.Price for each AlbLin.ID taking only last/recent 3 rows AlbLin.Date
¡Hola Albert! Te agradecería que, para beneficio de todos los usuarios de la comunidad de desarrolladores en español, planteases la pregunta traducida al español si es posible.
Con respecto a tu pregunta, prueba con la siguiente query:
SELECT
a1.ID, AVG(a1.Price)
FROM Comp.AlbLin a1
WHERE a1."Date" in (SELECT TOP 3 a2."Date" FROM Comp.AlbLin a2 WHERE a1.ID = a2.ID ORDER BY a2."Date" DESC )
GROUP BY a1.ID order by a1.ID asc
Entiendo que el campo AlbLin.ID no es único por lo que indicas, por lo que podemos utilizar como criterio la fecha del dato. Te explico un poco la query:
Puedes ver como tenemos dentro del WHERE una subquery que nos extraerá las últimas 3 fechas para cada AlbLin.ID, serán las 3 últimas ya que hemos indicado TOP 3 de una query ordenada por fecha de forma descendiente, así que siempre serán las 3 últimas fechas.
En la SELECT principal hemos sacado el AlbLin.ID que nos servirá como criterio agrupador y hemos usado la función agrupadora AVG para AlbLin.Price.
En la instrucción GROUP BY hemos definido el campo agrupador AlbLin.ID y hemos añadido un ORDER BY, este último no es necesario.
Pues bien, la subquery nos devolverá las 3 últimas fechas que usaremos en la query principal para sólo utilizar aquellos registros relativos al AlbLin.ID que coincidan con esas fechas (la subquery usa dentro de su WHERE el identificador de la query principal).
Prueba la query y coméntanos el resultado.
¿Has podido probar la query que te comenté, Alberto? si, es correcta . y ademas bastante simple cuando las ves. lastima tener que molestar. muy agradecido por la aportacion. es relativamente sencilla , 😅
he intentado ir un poco mas alla , y mejorarla o mas bien complicarla. y he vuelto a ser incapaz de ubicar bien los case when para que funcione.
queria conseguir que si la fecha mas reciente tiene mas de quince dias " ... (a1.FechaLinea > DATE(CURRENT_DATE-15)) ..." solo coja las 2 ultimas fechas . o sea que en lugar de un TOP 3 , sea un TOP 2.
he probado con los CASE WHEN dentro del select y fuera cambiando la instruccion pero no consigo que funcione.
de todas formas , la solucion ofrecida es para mi un gran aporte y cubre casi la totalidad de casos de la consulta. muchas gracias. si , si . acabo de reportar. ¡Nunca molestan vuestras preguntas, Albert! Al revés... gracias por preguntar, para eso estamos, y encantados de poder ayudar :D Pues solo tienes que meter la condición de la subquery entre paréntesis y añadir un And con la condición de la fecha a modo de:
WHERE (date>X AND subquery top 2) OR (date <=X AND subquery top 3) tambien funciona... 😁 . y yo dale que te pego con los CASE. ...
voy a ir desarrollar un poco mas la consulta , a ver si discurro algo mas y no hace falta vuestra atencion. ( seguro que vuelvo , jaja)
vaya ... un placer y muy agradecido de me hayais atendido las consultas tan rapido. ... y tan eficaces.
p.d.
dejo la sentencia completa como ejemplo por si a alguien le sirve de modelo
v.0
SELECT a1.Articulo, a1.DescArticulo, AVG(a1.PrecioCoste)FROM Comp.AlbaranLin a1WHERE a1.FechaLinea in (SELECT TOP 3 a2.FechaLinea FROM Comp.AlbaranLin a2 WHERE a1.Articulo = a2.Articulo ORDER BY a2.FechaLinea DESC ) (*opcional *AND a1.Articulo = '337' AND a1.FechaLinea > DATE(CURRENT_DATE-15) *)GROUP BY a1.Articulo order by a1.Articulo asc ;
v.1
SELECT a1.Articulo, a1.DescArticulo, AVG (a1.PrecioCoste)FROM Comp.AlbaranLin a1WHERE (a1.FechaLinea in (SELECT TOP 3 a2.FechaLinea FROM Comp.AlbaranLin a2 WHERE a1.Articulo = a2.Articulo ORDER BY a2.FechaLinea DESC ) AND a1.Articulo = '337' AND a1.FechaLinea >= DATE(CURRENT_DATE-15))OR(a1.FechaLinea in (SELECT TOP 2 a2.FechaLinea FROM Comp.AlbaranLin a2 WHERE a1.Articulo = a2.Articulo ORDER BY a2.FechaLinea DESC ) AND a1.Articulo = '337' AND a1.FechaLinea < DATE(CURRENT_DATE-15))GROUP BY a1.Articulo order by a1.Articulo asc ; Genial Albert, ¡muchas gracias! Y no te preocupes, para eso estamos. Puedes preguntar todo lo que necesites.
Artículo
Ricardo Paiva · 18 mar, 2021
Demo lista para usar de un servidor FHIR con IRIS for Health 2020.2:
* Transformación HL7v2 al servidor FHIR
* Servidor FHIR que se puede consultar en SQL
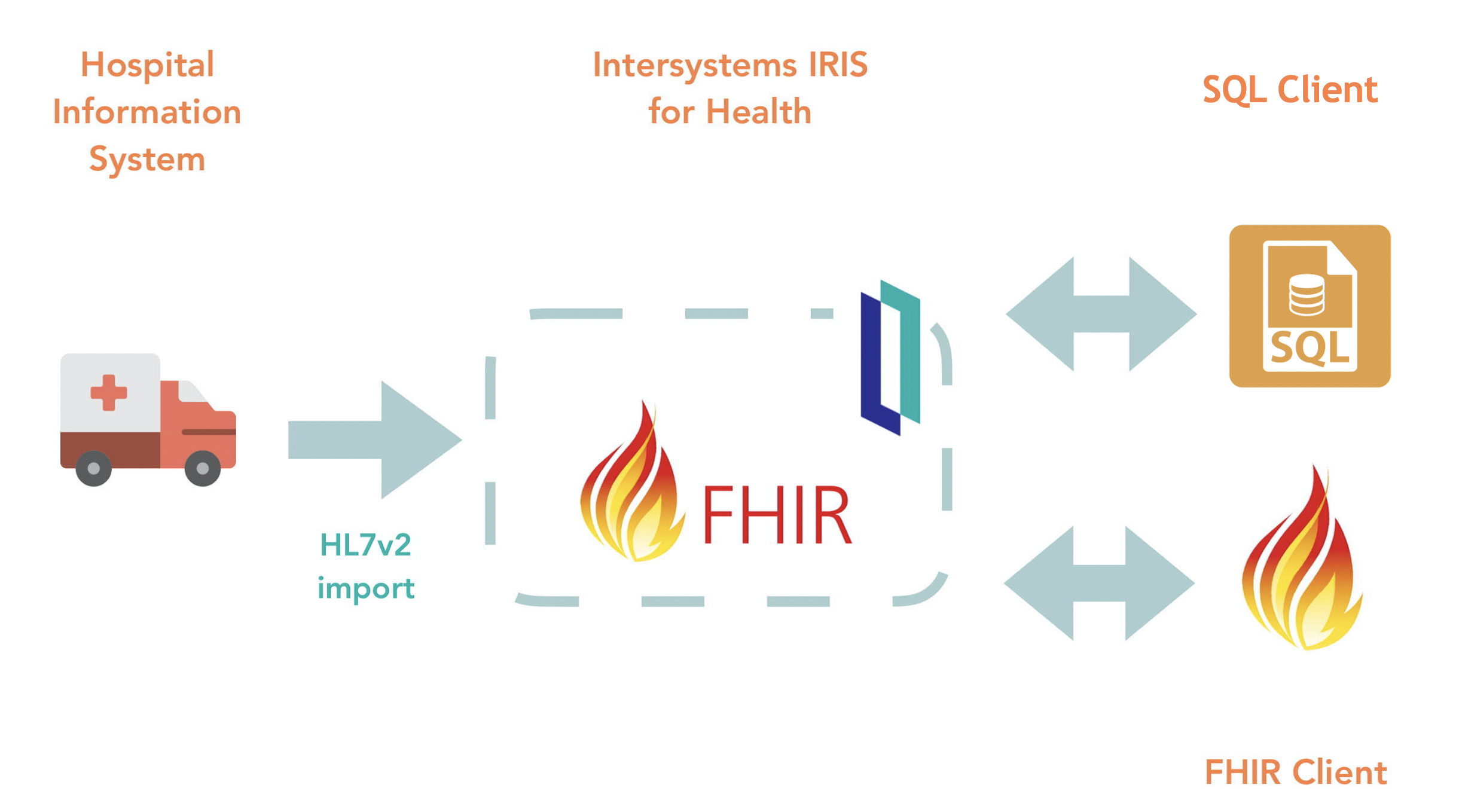
### Instalación
Clona este repositorio
```
git clone https://github.com/grongierisc/FHIR-HL7v2-SQL-Demo.git
```
Docker
```
docker-compose up --build -d
```
### Uso
* Puedes utilizar la configuración de postman en misc/fhirhl7v2demo.postman_collection.json
* Utiliza UX en http://localhost:4201
* ***Inicio de sesión/Contraseña***: SuperUser/password
### Cómo utilizar la demostración
3 pasos para utilizarla:
## Importar mensajes HL7v2
Haz clic en la flecha izquierda que está entre IRIS y la ambulancia.
Esto abre las siguientes ventanas:
Desde aquí se pueden importar muestras desde este directorio en el repositorio de Git:
sampleFiles
Elige uno y haz clic en enviar.
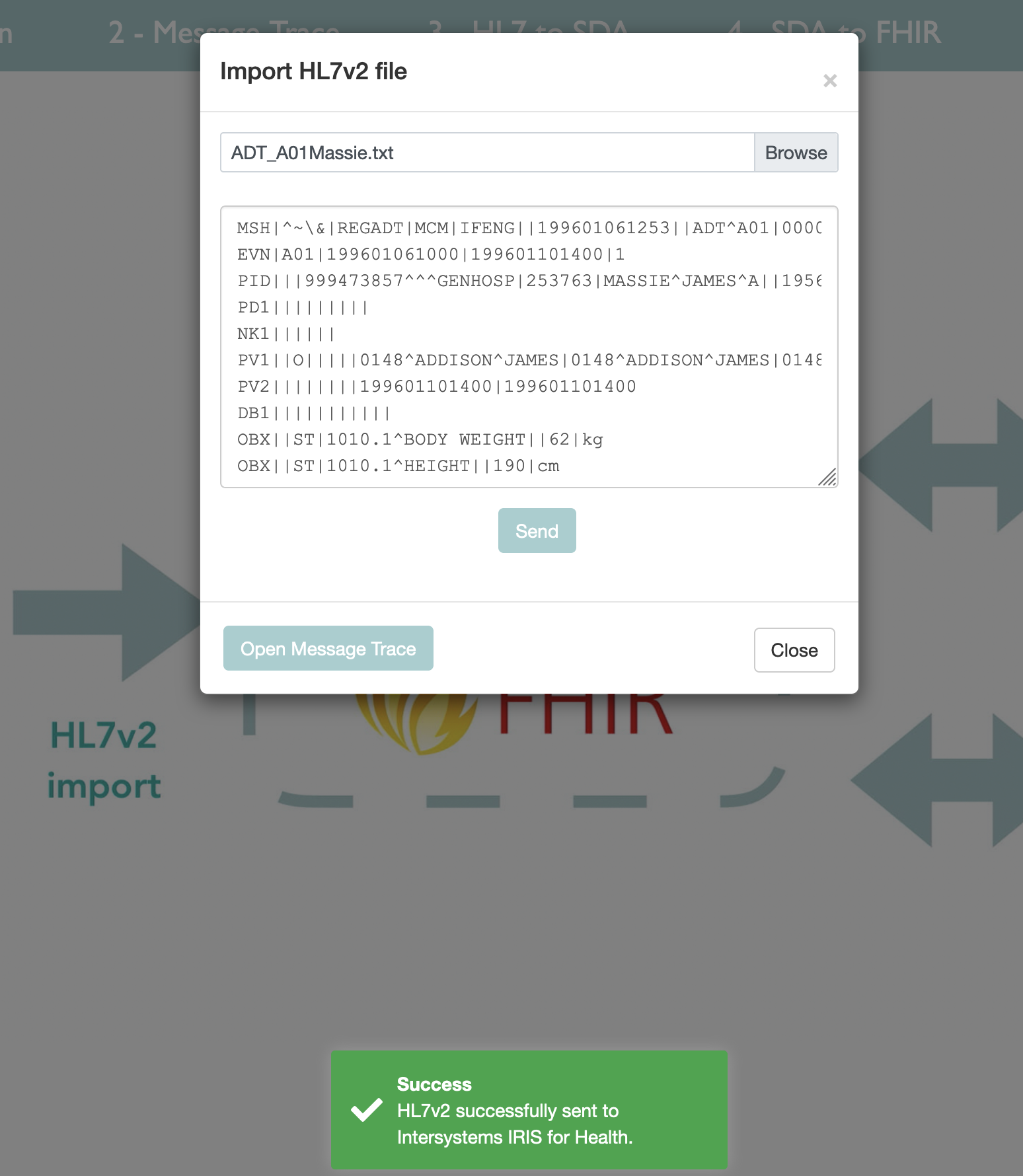
Desde aquí puedes hacer clic en Message Trace:
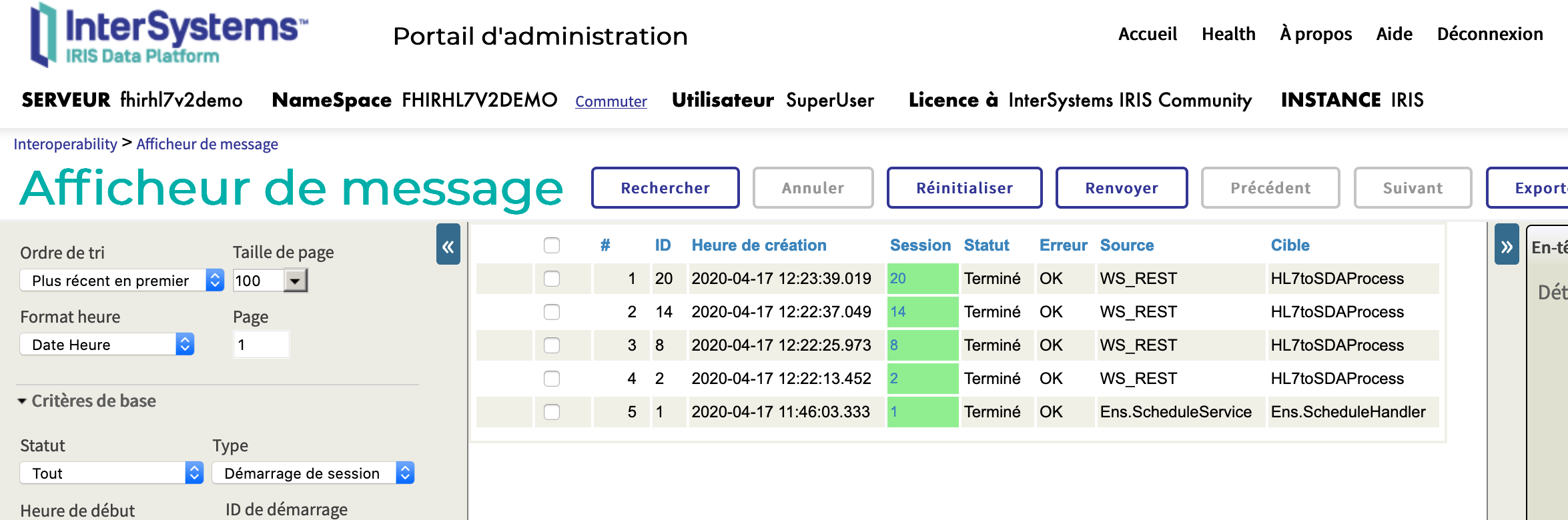
Selecciona el primero:
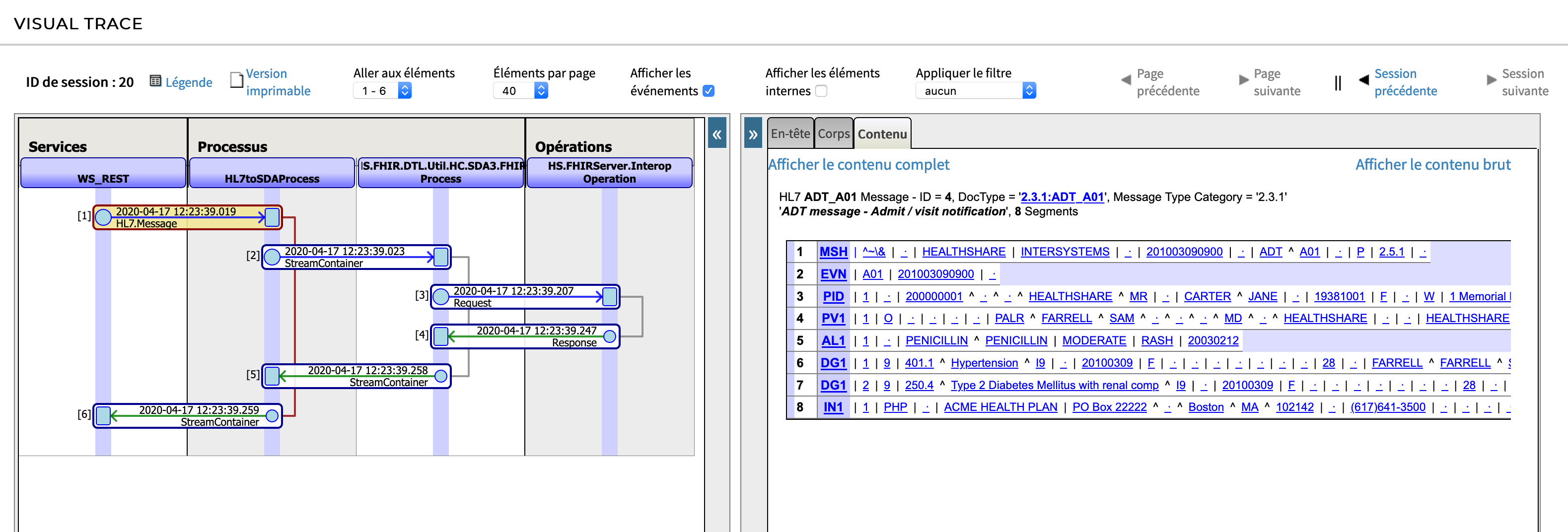
Aquí puedes ver la transformación preparada entre HL7v2, SDA y FHIR.
## Utiliza el cliente FHIR
Haz clic en la flecha entre IRIS y el FHIR client:
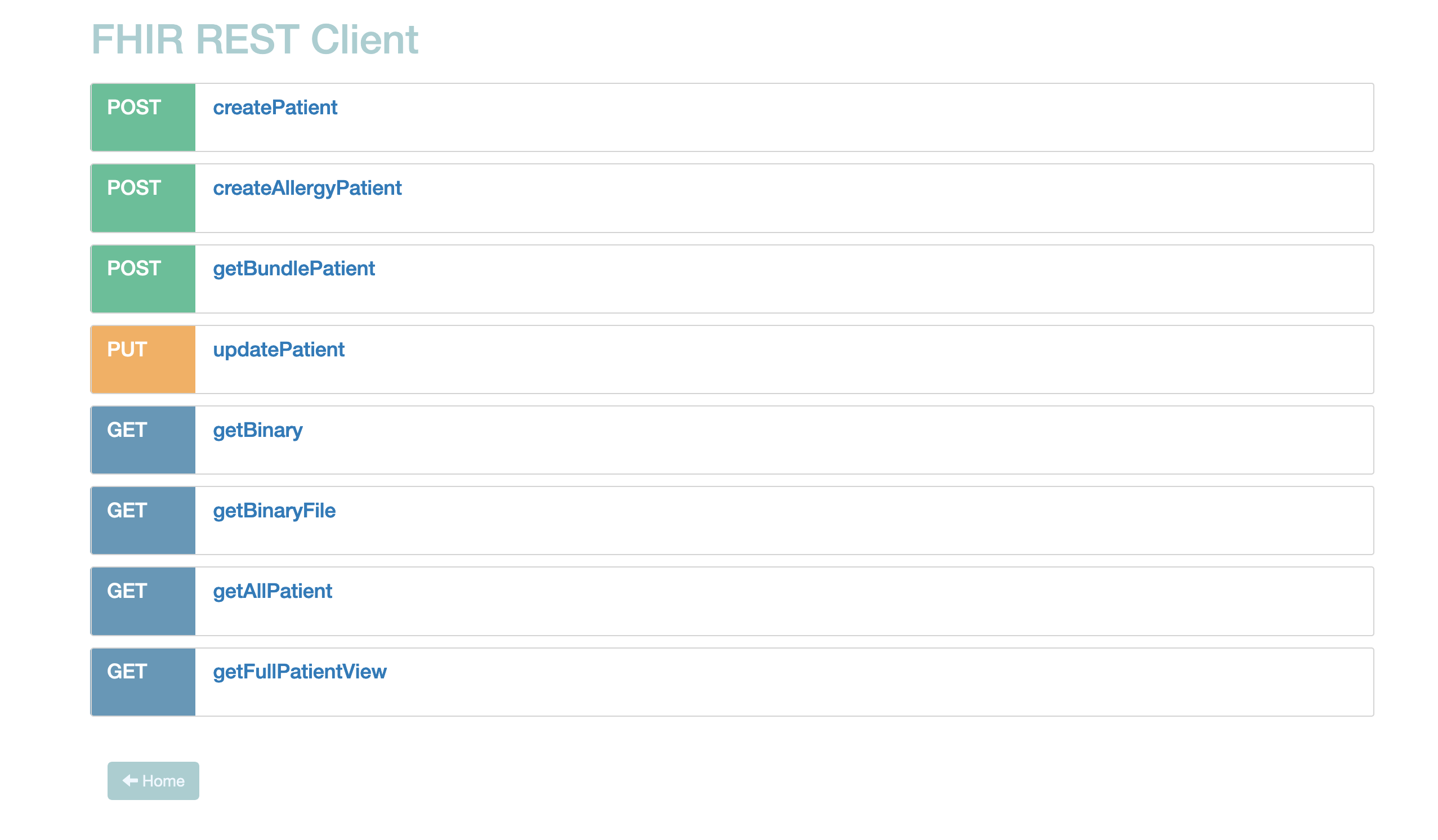
El pequeño swagger te da la oportunidad de consultar en FHIR el repositorio lleno desde el mensaje HL7v2 o desde el FHIR client.
Por ejemplo :
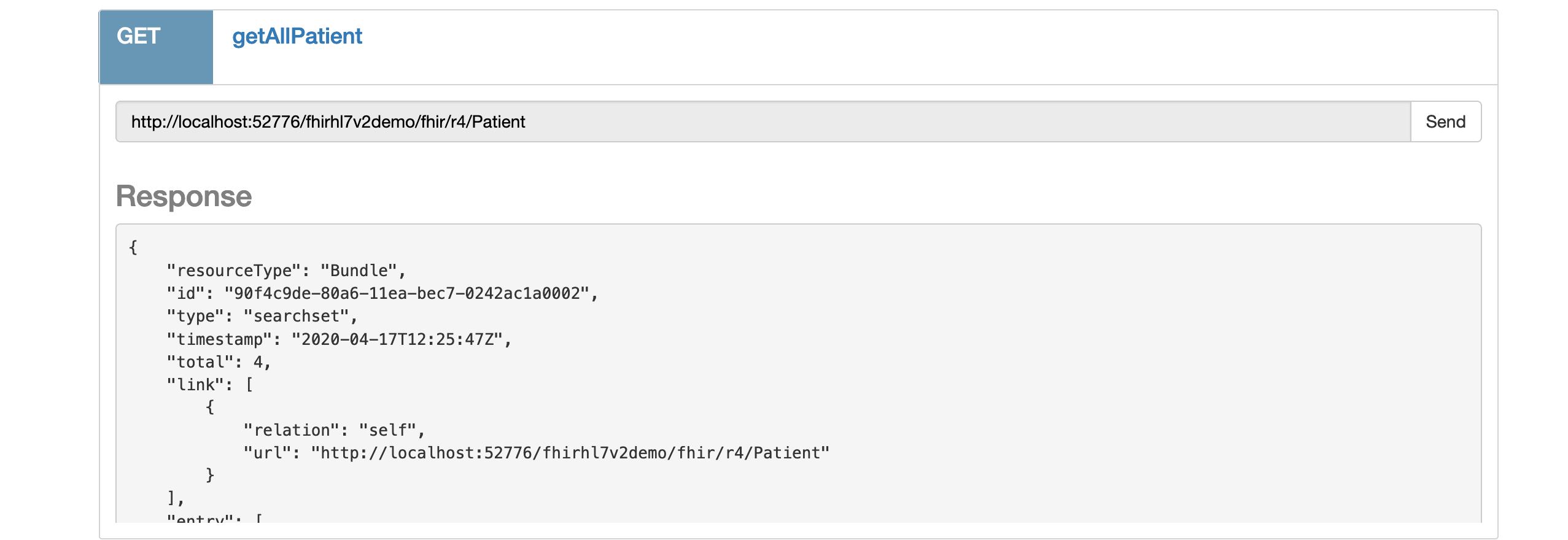
## Utiliza el cliente SQL
Haz clic en la flecha que está entre IRIS y SQL client:
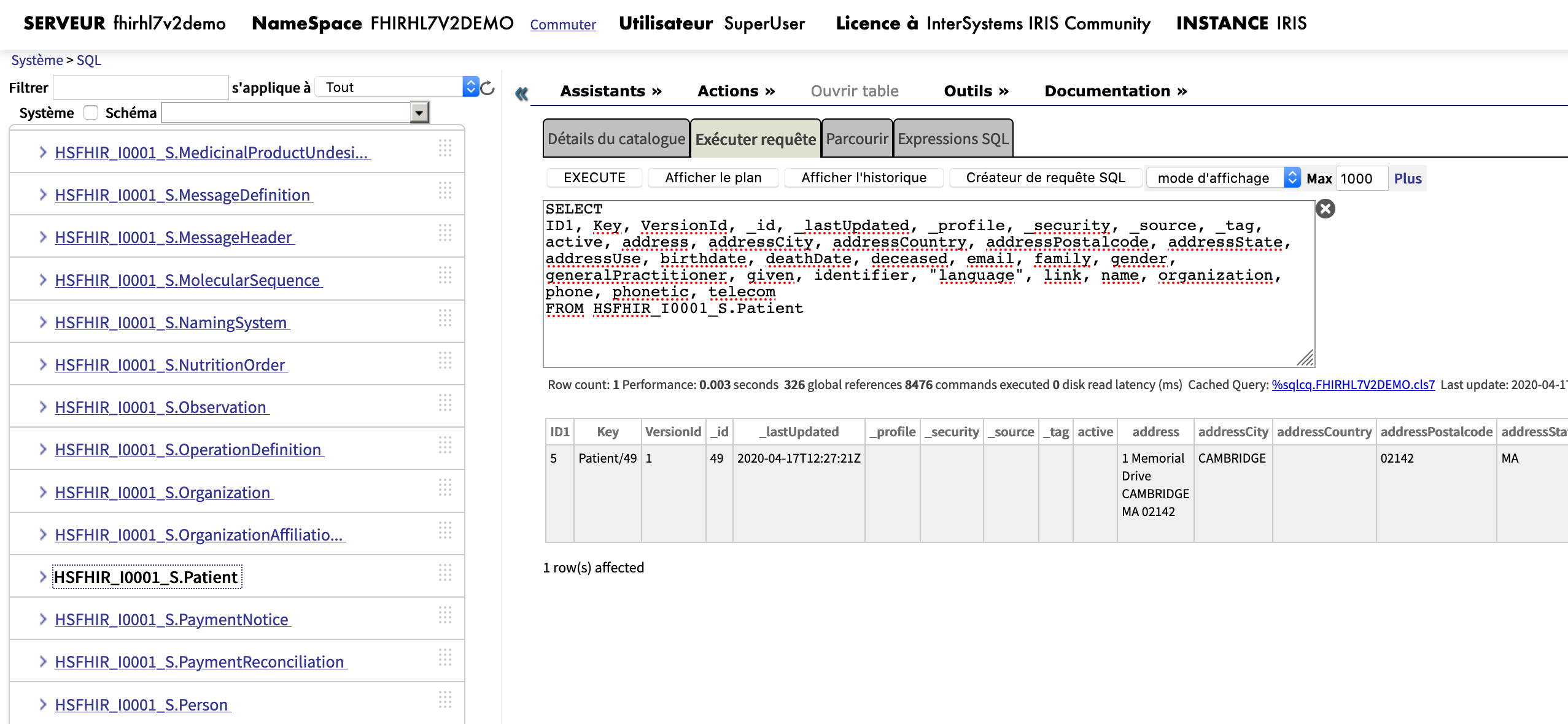
Desde aquí se pueden ver todos los recursos FHIR en una estructura relacional de SQL. Debe quedar claro que esta estructura SQL puede cambiar sin previo aviso. Dicha estructura no está documentada y su uso no tiene el respaldo de InterSystems.
Artículo
Ricardo Paiva · 4 mayo, 2023
En los últimos años, las tecnologías de inteligencia artificial para la generación de texto han avanzado significativamente. Por ejemplo, los modelos de generación de texto basados en redes neuronales pueden producir textos que son casi indistinguibles de los textos escritos por humanos. ChatGPT es uno de estos servicios. Es una enorme red neuronal entrenada con una gran cantidad de textos, que puede generar textos sobre varios temas y adaptarse a un contexto dado.
La nueva tarea para las personas es desarrollar formas de reconocer textos escritos no solo por personas sino también por inteligencia artificial (IA). Esto se debe a que, en los últimos años, los modelos de generación de texto basados en redes neuronales se han vuelto capaces de producir textos que son casi indistinguibles de los textos escritos por humanos.
Hay dos métodos principales para el reconocimiento de texto escrito por inteligencia artificial (IA):
Utilizar algoritmos de machine learning para analizar las características estadísticas del texto;
Utilizar métodos criptográficos que pueden ayudar a determinar la autoría del texto
En general, la tarea de reconocimiento de texto de IA es difícil pero importante.
Me complace presentar una aplicación para el reconocimiento de textos generados por inteligencia artificial (IA). Durante el desarrollo, aproveché los beneficios de InterSystems Cloud SQL e Integrated ML, que incluyen:
Solicitudes de datos rápidas y eficientes, con alto rendimiento y velocidad;
Interfaz amigable para usuarios no expertos en bases de datos y machine learning;
Escalabilidad y flexibilidad para ajustar rápidamente los modelos de ML según los requisitos;
En el desarrollo y entrenamiento posterior del modelo, utilicé un conjunto de datos abierto, concretamente 35 mil textos escritos. La mitad de los textos fueron escritos a mano por un gran número de autores, y la otra mitad fue generada por IA con ChatGPT.
Configuración usada para el modelo GPT:
model="text-curie-001"
temperature=0.7
max_tokens=300
top_p=1
frequency_penalty=0.4
presence_penalty=0.1
A continuación, se establecieron unos 20 parámetros básicos, según los cuales se llevó a cabo el entrenamiento posterior. Estas son algunas de las opciones que utilicé:
Cantidad de caracteres
Cantidad de palabras
Longitud media de las palabras
Cantidad de frases
Longitud media de las frases
Cantidad de palabras únicas
Cantidad de palabras vacías (stop words)
Ratio de palabras únicas
Cantidad de signos de puntuación
Ratio de signos de puntuación
Cantidad de preguntas
Cantidad de exclamaciones
Cantidad de dígitos
Cantidad de letras en mayúscula
Cantidad de palabras repetidas
Cantidad de bigramas únicos
Cantidad de trigramas únicos
Cantidad de cuatrigramas únicos
Como resultado, obtuve una sencilla aplicación que podéis usar para vuestras tareas o para pasarlo bien.
Así es como se ve:
Para probar la aplicación podéis usar la demo online o ejecutarla en local con vuestra cuenta Cloud SQL.
Todos los comentarios sobre la app son bienvenidos!
Anuncio
Esther Sanchez · 25 mar, 2021
¡Hola Comunidad!
En esta publicación, os explicamos las distintas Insignias de Global Masters y qué hay que hacer para conseguirlas.
Información general sobre Niveles e Insignias de Global Masters
Todos los miembros de Global Masters empiezan en el 1er nivel ("Insider"), cuando se registran en el Programa de Fidelización. Para subir de nivel, hay que ganar un número de insignias del siguiente nivel. Las insignias se ganan realizando diferentes "retos".¿Cómo puedes saber en qué nivel estás y las insignias que tienes? Sigue estos sencillos pasos:
1. En la página de inicio de Global Masters, haz clic en la foto de tu perfil, en la parte superior derecha > después, haz clic en tu nombre2. Ahí ya puedes ver en qué nivel estás, las insignias que has ganado y lo que te falta para pasar al siguiente nivel3. Si haces clic en "See available badges" verás todas las insignias y niveles del programa
También puedes ver tus insignias ganadas en tu página de perfil en la Comunidad de Desarrolladores.
Cómo conseguir las insignias en GM
Nombre de la insignia
Reglas
Insignias por número de vistas
Popular Writer - 750 vistas
Insignias conseguidas si cualquiera de tus publicaciones (preguntas o artículos) en la Comunidad de Desarrolladores consiguen más de 750 / 2 000 / 5 000 vistas únicas.
La publicación no debe ser eliminada; tiene que ser publicada.
Solo cuentan las publicaciones con una calificación positiva.
No cuentan las publicaciones con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Cada insignia solo se concede una vez. Los puntos se dan por cada publicación que consigue el número de vistas indicadas.
Notable Writer - 2 000 vistas
Famous Writer - 5 000 vistas
Gold Writer - 15 000 vistas
Insignias por artículos publicados
Reporter - 5 artículos
Insignias conseguidas cuando llegas a 5 / 10 / 25 / 50 artículos (no preguntas) publicados en la Comunidad.
Las publicaciones no deben ser eliminadas; tienen que ser publicadas.
Solo cuentan las publicaciones con una calificación positiva.
No cuentan las publicaciones con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Blogger - 10 artículos
Influencer - 25 artículos
Opinion Maker - 50 artículos
DC Best Practices Author Badge - 1 best practice
Insignias conseguidas cuando llegas a 1 / 10 / 25 / 50 artículos (no preguntas) considerados como Best Practice ("Mejores prácticas") en la Comunidad de Desarrolladores.
Las publicaciones no deben ser eliminadas; tienen que ser publicadas.
Solo cuentan las publicaciones con una calificación positiva.
No cuentan las publicaciones con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
RecognizableBest Practices Author Badge - 2 best practices
Bronze Best Practices Author Badge - 3 best practices
Silver Best Practices Author Badge- 4 best practices
Gold Best Practices Author Badge - 5 best practices
Master of Answers - 5 respuestas aceptadas
Insignias conseguidas cuando tus respuestas en la Comunidad de Desarrolladores son marcadas 5 / 10 / 25 / 50 veces como respuestas aceptadas.
Bronze Master of Answers - 10 respuestas aceptadas
Silver Master of Answers - 25 respuestas aceptadas
Gold Master of Answers - 50 respuestas aceptadas
Insignias por preguntas
Curious Member - 5 preguntas
Insignias conseguidas cuando llegas a 5 / 10 / 25 / 50 preguntas en la Comunidad de Desarrolladores.
Las preguntas no deben ser eliminadas; tienen que ser publicadas.
Solo cuentan las preguntas con una calificación positiva.
No cuentan las preguntas con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Thorough Member - 10 preguntas
Inquisitive Member - 25 preguntas
Socratic Member - 50 preguntas
Insignias por favoritos
Favorite Post - 10 veces
Insignias conseguidas cuando tus publicaciones (preguntas o artículos) en la Comunidad de Desarrolladores, son marcadas 10 / 50 / 100 veces como favoritas.
Las publicaciones no deben ser eliminadas; tienen que ser publicadas.
Solo cuentan las publicaciones con una calificación positiva.
No cuentan las preguntas con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Remarkable Post - 50 veces
Unforgettable Post - 100 veces
Insignias por votos
Insightful Author - 50 votos
Insignias conseguidas cuando tus publicaciones (preguntas o artículos) en la Comunidad de Desarrolladores, consiguen 50 / 100 / 500 / 1 000 votos.
Las publicaciones no deben ser eliminadas; tienen que ser publicadas.
No cuentan las publicaciones con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Expert Author - 100 votos
Recognizable Author - 500 votos
Powerful Author - 1000 votos
Insightful Commenter - 50 votos
Insignias conseguidas cuando tus respuestas (comentarios a preguntas) en la Comunidad de Desarrolladores, consiguen 50 / 100 / 500 / 1 000 votos.
No cuentan las respuestas eliminadas
No cuentan las respuestas con la etiqueta Feedback sobre la Comunidad de Desarrolladores .
Expert Commenter - 100 votos
Recognizable Commenter - 500 votos
Powerful Commenter - 1 000 votos
DC Moderator
Concedida a los Moderadores de la Comunidad de Desarrolladores. Esta insignia no está relacionada con los niveles.
Insignias anuales - Top 10 Autores
Gold Best-Selling Author - 1er puesto
1º / 2º / 3º / 4º-10º puestos en la categoría "DC Best-Selling Author".
Autores cuyos artículos consiguieron el mayor número de visualizaciones en la Comunidad de Desarrolladores durante un año.
Silver Best-Selling Author - 2º puesto
Bronze Best-Selling Author - 3er puesto
DC Best-Selling Author - 4º-10º puestos
Gold Expert - 1er puesto
1º / 2º/ 3º / 4º-10º puestos en la categoría “DC Expert”.
Autores que consiguieron el mayor número de "Respuestas aceptadas" en la Comunidad de Desarrolladores durante un año.
Silver Expert - 2º puesto
Bronze Expert - 3er puesto
DC Expert - 4º-10º puestos
Gold Opinion Leader - 1er puesto
1º / 2º/ 3º / 4º-10º puestos en la categoría “DC Opinion Leader”.
Autores cuyas publicaciones y respuestas obtuvieron el mayor número de votos en la Comunidad de Desarrolladores durante un año.
Silver Opinion Leader - 2º puesto
Bronze Opinion Leader - 3er puesto
DC Opinion Leader - 4º-10º puestos
Insignias por recomendaciones
Gold Recruiter - 100 recomendaciones
Insignias conseguidas cuando se unen a la Comunidad de Desarrolladores 1 /10 / 50 / 100 personas a las que recomendaste la Comunidad.
Silver Recruiter - 50 recomendaciones
Bronze Recruiter - 10 recomendaciones
DC Recruiter - 1 recomendación
Insignias por Contribuciones Básicas
DC Author
Insignia conseguida cuando publicas tu primer artículo en la Comunidad de Desarrolladores.
La publicación no debe ser eliminada; tiene que ser publicada.
No cuentan los artículos con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Debe ser una publicación del tipo "Artículo".
InterSystems Researcher
Insignia conseguida cuando publicas tu primera pregunta en la Comunidad de Desarrolladores.
La pregunta no debe ser eliminada; tiene que ser publicada.
No cuentan las preguntas con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Debe ser una publicación del tipo "Pregunta".
DC Commenter
Insignia conseguida cuando publicas tu primer comentario en la Comunidad de Desarrolladores.
Comentario con algún "Me gusta" o sin ningún "Me gusta"
No cuentan los comentarios realizados con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
DC Problem Solver
Insignia conseguida cuando tu respuesta a la pregunta de alguien es marcada como "Respuesta aceptada" en la Comunidad de Desarrolladores.
La respuesta tiene que ser marcada como "Respuesta aceptada"
No cuentan las respuestas realizadas con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
DC Translator
Insignia conseguida cuando publicas tu primera traducción en la Comunidad de Desarrolladores. Cómo añadir una traducción
Winner of Advent of Code
Insignia concedida a los ganadores del concurso "Advent of Code". Mas info aquí.
Global Master of the Month
Insignia concedida a los "Advocate of the Month" en Global Masters.
Gold Advocate of the Year
Insignias concedidas a los "Best Advocates of the Year" en Global Masters.
Silver Advocate of the Year
Bronze Advocate of the Year
Insignias de Open Exchange
InterSystems Open Exchange Developer
Insignias conseguidas cuando publicas 1 / 5 / 10 / 25 aplicaciones en InterSystems Open Exchange.
Bronze Open Exchange Developer
Silver Open Exchange Developer
Gold Open Exchange Developer
Además...
Consulta la información adicional sobre Global Masters:
Cómo unirse a Global Masters
Descripción de los Niveles de Global Masters
Si tienes alguna duda sobre las Insignias, puedes dejarnos un comentario en esta publicación y te responderemos al momento!