Limpiar filtro
Anuncio
Esther Sanchez · 25 mar, 2021
Hemos doblado el número de puntos concedidos por cada publicación y cada traducción que realicéis en la Comunidad de Desarrolladores. Así, desde el pasado día 18 de marzo, por cada artículo o pregunta, se obtienen:
✅ 200 puntos en la Comunidad de Desarrolladores en inglés (EN)✅ 400 puntos en las Comunidades de Desarrolladores en español (ES) / portugués (PT) / chino (CN) / japonés (JP)
y✅ ¡100 puntos por cada traducción!
*La promoción estará vigente durante un cierto período de tiempo.Además...
¿sabéis que se obtienen puntos extra por el primer artículo o la primera pregunta que publiquéis, y también por packs de artículos/preguntas? Echad un vistazo:
1er artículo
5 artículos
10 artículos
25 artículos
50 artículos
1 500 puntos extra
7 500 puntos extra
15 000 puntos extra
40 000 puntos extra
75 000 puntos extra
1ª pregunta
5 preguntas
10 preguntas
25 preguntas
50 preguntas
500 puntos extra
2 000 puntos extra
5 000 puntos extra
15 000 puntos extra
30 000 puntos extra
¡Y se obtienen insignias por cada uno de los packs de 5/10/25/50 artículos o preguntas!
Consulta la información adicional sobre Global Masters:
Cómo unirse a Global Masters
Descripción de las Insignias de Global Masters
Descripción de los Niveles de Global Masters
Si aún no perteneces al Programa de Fidelización de InterSystems, ¡te puedes dar de alta ahora mismo!
Si tienes alguna duda, puedes dejarnos un comentario en esta publicación y te responderemos al momento.
Anuncio
Esther Sanchez · 27 abr, 2021
¡Hola Comunidad!
Lo habéis pedido... y ya está aquí - ¡insignias por traducciones en Global Masters!
Nombre de la insignia
Reglas
DC Translator
Conseguida por 1 traducción
Insignia del 2º nivel (Advocate)
Traducciones de inglés a cualquier otro idioma de la Comunidad (español, portugúes, chino y japonés).
Publicaciones con una valoración positiva (votos) o sin votos
No cuentan las publicaciones con la etiqueta Feedback sobre la Comunidad de Desarrolladores.
Hay un retardo de 3 días entre la publicación de la traducción y la concesión de la insignia.
Advanced Translator
Conseguida por 5 traducciones
Insignia del 3er nivel (Specialist)
Bronze Translator
Conseguida por 15 traducciones
Insignia del 4º nivel (Expert)
Silver Translator
Conseguida por 25 traducciones
Insignia del 5º nivel (Ambassador)
Gold Translator
Conseguida por 50 traducciones
Insignia del 6º nivel (VIP)
¿Cómo puedes saber en qué nivel de Global Masters estás y las insignias que tienes? Sigue estos sencillos pasos:
1. En la página de inicio de Global Masters, haz clic en la foto de tu perfil, en la parte superior derecha > después, haz clic en tu nombre
2. Ahí ya puedes ver en qué nivel estás, las insignias que has ganado y lo que te falta para pasar al siguiente nivel
2. Si haces clic en "See available badges" verás todas las insignias y niveles del programa
¿Quieres saber más sobre Global Masters?
Echa un vistazo a estas otras publicaciones:
Cómo unirse a Global Masters
Descripción de los niveles de Global Masters
Cómo conseguir puntos en Global Masters
Si aún no perteneces al Programa de Fidelización de InterSystems, ¡te puedes dar de alta ahora mismo!
Si tienes alguna duda, puedes dejarnos un comentario en esta publicación y te responderemos al momento.
Artículo
Alberto Fuentes · 29 jun, 2022
¡Hola Comunidad!
Me gustaría anunciaros brevemente tres nuevos paquetes, disponibles en Open Exchange / a través de ZPM, que pueden realmente ayudaros a acelerar el desarrollo en IRIS de aplicaciones full-stack modernas. Todo esto se anunció la semana pasada en una sesión del Global Summit, pero muchos no pudisteis asistir. Además, me acabo de enterar de que justo ahora está en marcha un concurso de desarrollo de aplicaciones full-stack!
En el corazón de todo esto está isc.rest: una continuación de apps-rest con un uso más amplio dentro de InterSystems y varias nuevas funcionalidades geniales - especialmente, la generación de especificaciones OpenAPI. isc.rest hace posible el acceso REST sencillo a tus datos: extiende una clase, sobreescribe un parámetro y especifica seguridad para el nuevo recurso REST que estás creando. Esto está respaldado por isc.json, un subproyecto autorizado del paquete IRIS %JSON, desarrollado para ayudar a potenciar el soporte a JSON en IRIS a través del feedback de la Comunidad.
Del lado de la interfaz de usuario (UI), isc.ipm.js adapta el gestor de paquetes de IRIS para simplificar la creación y desarrollo de modernas interfaces de usuario, junto con código del lado del servidor, incluyendo la generación de código cliente basada en las especificaciones de la Open API de isc.rest y una nueva fase "generate" del ciclo de vida del gestor de paquetes. Con isc.ipm.js puedes publicar tu paquete en un registro privado (usando zpm-registry) y distribuir tu código del lado del servidor y crear artefactos UI sin necesidad de reconstruir el cliente (o hacer commit de tus artefactos construidos al sistema de control de código).
Por último, isc.perf.ui sirve como una demo para todo lo anterior - y una demo práctica, empleando el monitor de línea por línea (^%SYS.MONLBL) y ofreciendo acceso a resultados a través de una sencilla UI Angular.
Publicaré más artículos sobre esto en las próximas semanas - ¡estad atentos!
Artículo
Eduardo Anglada · 29 dic, 2021
Hablando con mi amigo @Renato.Banzai, especialista en Machine Learning, me comentó uno de los mayores retos a los que se enfrentan las empresas hoy en día: implementar el Machine Learning (ML) o la Inteligencia Artificial (IA) en entornos reales.
InterSystems IRIS ofrece IntegratedML. IntegratedML es una excelente funcionalidad para formarse, probar e implementar modelos de ML/IA.
La parte más difícil al crear ML/IA es el tratamiento de los datos, su limpieza, hacerlos fiables.
¡Y ahí es donde podemos sacar ventaja del potente estándar FHIR!
La idea del proyecto muestra cómo podemos crear/entrenar/validar modelos de ML/IA con FHIR y utilizarlos con datos de diferentes fuentes.
Creemos que este proyecto tiene un gran potencial y se pueden explorar varias ideas:
Reutilizar/extender las transformaciones DTL en otras bases de datos FHIR para modelos de ML a medida
Usar transformaciones DTL para normalizar mensajes FHIR y publicar modelos de ML como servicios
Crear un tipo de modelos + repositorio de reglas de transformación para usar dentro de cualquier conjunto de datos FHIR
Explorando nuevas posibilidades con este proyecto, podemos imaginar datos de diferentes fuentes.
En la imagen arribla, el Recurso FHIR (FHIR Resource), consumiendo la API REST, puede ser usado con una FHIRaaS.
Y no solo usando FHIRaaS en AWS, sino que también podemos usar el nuevo servicio HealthShare Message Transformation Services, que automatiza la conversión de HL7v2 a FHIR® para ingresar datos en Amazon HealthLake, donde puedes extraer más valor de tus datos.
Con estas pequeñas demostraciones, veo que estos recursos se pueden utilizar muy bien en escenarios más grandes, permitiendo y ofreciendo implementaciones más sencillas en producción en entornos realmente innovadores, como AWS Healthlake. ¿Por qué no?! 😃
Artículo
Alberto Fuentes · 16 ene, 2023
cAdvisor (abreviatura de contenedor Advisor) analiza y muestra el uso de recursos y los datos de rendimiento desde los contenedores en ejecución. cAdvisor ya viene preparado para publicar métricas en formato Prometheus.
https://prometheus.io/docs/guides/cadvisor/
Prometheus está integrado en SAM. Esto permite aprovechar las métricas de cAdvisor y mostrarlas a través de Prometheus y Grafana.
Como cAdvisor escucha en el puerto 8080, que entra en conflicto con el puerto de Nginx, puedes cambiar el puerto Nginx para solucionarlo:
Pasos para realizar la configuración:
1. Cambia el puerto nginx.
modifica nghix.conf:
server { listen 9991;
Esto te permite acceder al IU de cAdvisor a través de http://server:8080/, que incluye muchos cuadros de mando (dashboards) de ejemplo.
2. Configura docker-compose para añadir el contenedor cAdvisor:
en docker-compose.yml, añade lo siguiente:
cadvisor: image: google/cadvisor:latest ports: - 8080:8080 volumes: - /:/rootfs:ro - /var/run:/var/run:rw - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro
3. Configura prometheus para añadir un trabajo para cAdvisor:
modifica isc_prometheus.yml y añade:
- job_name: cadvisor scrape_interval: 5s static_configs: - labels: cluster: "1" group: node targets: - cadvisor:8080
¡Ya está! Para asegurarse de que prometheus está cogiendo las métricas de cAdvisor, ve al IU de prometheus http://server:9090/. En Status->Targets, deberías ver el endpoint y el estado de cAdvisor.
Puedes descargar unos excelentes cuadros de mando (dashboards) predefinidos con métricas de cAdvisor. Solo necesitas añadir el parámetro del cluster en cada consulta.
Este artículo está etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Evgeny Shvarov · 18 jul, 2022
¡Hola Comunidad!
@Joan.Pérez publicó una reseña en la que comentó que no está muy claro qué aplicaciones están disponibles para InterSystems Package Manager. ¡Gracias por tu pregunta, Joan! De hecho, la respuesta merece una publicación.
Existen al menos dos formas de conocer las aplicaciones con ZPM:
1. Ejecutar el comando find en zpm:
IRISAPP>zpm
=============================================================================
|| Welcome to the Package Manager Shell (ZPM). ||
|| Enter q/quit to exit the shell. Enter ?/help to view available commands ||
=============================================================================
zpm:IRISAPP>find
registry https://pm.community.intersystems.com:
analytics-okr 1.0.0
analyzethis 1.2.4
aoc-2021-uvg 0.0.2
aoc2021-rcc 0.0.2
appmsw-dbdeploy 1.0.3
appmsw-docbook 1.0.5
appmsw-forbid-old-passwd 1.0.4
....
O find -d para que aparezca el listado con sus descripciones:
zpm:IRISAPP>find -d
registry https://pm.community.intersystems.com:
analytics-okr 1.0.0
analyzethis 1.2.4 Description: Module that helps to
generate cubes, pivots and
dashboards vs IRIS data
aoc-2021-uvg 0.0.2 Description: Advent of code 2021 in
COS classes
aoc2021-rcc 0.0.2 Description: AoC-2021 full Embedded
Python demo
appmsw-dbdeploy 1.0.3 Description: An example of deploying
solutions with prepared databases,
even without source code.
appmsw-docbook 1.0.5 Description: Importing docbook
...
2. La segunda forma es filtrar las aplicaciones con ZPM en Open Exchange:
¿Compartís vuestra forma de conocer los paquetes públicos?
Esto está relacionado con repositorios públicos. Por supuesto, hay muchos repositorios privados que no sabemos lo que hay allí. ¿Vosostros cómo mostráis los paquetes?
Pregunta
Jose-Tomas Salvador · 21 oct, 2022
Buenos días, tardes, noches,...
Una pequeña reflexión/pregunta para hoy... es una realidad que las nuevas versiones de IRIS for Health son cada vez más potentes en cuanto a capacidades FHIR. Permiten consumir recursos FHIR con extrema facilidad, podemos crear conexiones con end-points de servidores FHIR externos muy facilmente y hacer que IRIS actúe de passthrough o que consuma esos recursos... o, más aún, podemos definir y poner en funcionamiento un repositorio FHIR, literalmente, en menos de 5 minutos.
Sin embargo, hay una cosa que hecho en falta en proyectos de tipo FHIR Façade, cuando tenemos que implementar una capa FHIR sobre un sistema que "no habla" FHIR. Se trata de la posiblidad de tener ayuda en nuestro IDE (Studio o VS Code) a la hora de codificar la lógica que crearía el o los objetos dinámicos (%DynamicObject) que representan los recursos FHIR que queremos definir...
Creo que sería de mucha ayuda disponer de estructuras/objetos que representasen los recursos de la versión FHIR con la que estemos trabajando, de modo que el intellisense de nuestro Studio o VS Code nos pudiera ofrecer ayuda en cuando a propiedades, objetos referenciados, etc,... y, no sólo eso, sino que también pudieramos utilizar esos objetos como base a la hora de definir nuestras transformaciones en el editor DTL, para crear recursos/objetos FHIR a partir de otros datos persistentes.
No sé si es algo que sólo yo hecho en falta o es más comun, por eso quería lanzar la pregunta a la comunidad. ¿Os habéis encontrado con esta situación? ¿Pensáis que es una funcionalidad interesante? ¿Tenéis algún workaround que queráis compartir?
Lo planteé en su día en el Portal de Ideas/Sugerencias que InterSystems pone a disposición de la comunidad. Aquí está la entrada por si queréis votar por ella, o aportar ideas/workarounds, etc...
Bueno, pues ahí queda la reflexión/pregunta.
¡¡Happy Coding!!
Artículo
Esther Sanchez · 8 jun, 2023
¡Hola Comunidad!
Hemos llegado al final del #GlobalSummit23 - ¡último día! Y es nuestro día - el día del desarrollador. Todas las ponencias estuvieron dedicadas a los desarrolladores, su crecimiento, aspiraciones e innovaciones.
Durante su presentación, @Dean.Andrews2971 habló sobre la Comunidad de Desarrolladores, entre otras cosas. Podéis ver la ponencia en Youtube tal como la grabé yo, o esperar a que publiquen la grabación oficial:
Después de comer, todos los moderadores de la Comunidad que habían ido al Global Summit se reunieron en una sesión llamada "Cómo aprovechar al máximo la Comunidad de Desarrolladores de InterSystems". Este año había mucha más gente que el año pasado!
@Dean.Andrews2971 mostró las novedades y funcionalidades de la Comunidad, Global Masters, Open Exchange y el Portal de Ideas; y cómo aprovecharlos.
Y después hubo una sesión abierta para comentar lo que cualquiera quisiera preguntar 😊
@Dmitry.Maslennikov, de la Comunidad de Desarrolladores en inglés.
@José.Pereira, de la Comunidad de Desarrolladores en portugués.
@Muhammad.Waseem, de la Comunidad de Desarrolladores en inglés.
@Francisco.López1549, de la Comunidad de Desarrolladores en español.
@Lorenzo Scalese, de la Comunidad de Desarrolladores en francés.
@Scott Roth, de la Comunidad de Desarrolladores en inglés.
Y la foto final con todos los moderadores que asistieron al Global Summit. De izquierda a derecha: @José.Pereira, @Muhammad.Waseem, @Djeniffer.Greffin7753, @Scott.Roth, @Dean.Andrews2971, @John.Murray, @Irène.Mykhailova, @Lorenzo.Scalese, @Francisco.López1549.
¡Qué grupo de personas tan agradable!
Espero que todos disfrutaran de esos 45 minutos.
Tras la sesión, ya era casi la hora del último helado y café! Pero antes eché un vistazo a @Guillaume.Rongier7183, que estaba terminando su ponencia sobre su tema favorito: Python.
Me junté con @Dmitry.Maslennikov, @Murray.Oldfield y nuestro nuevo miembro de la Comunidad - @Vladimir.Babarykin.
Y literalmente atrapé a @Vita.Tsareva, de Caelestinus, tras el adiós final.
Y esto ha sido todo. Espero que os hayan gustado mis crónicas de cómo fue mi Global Summit.
Podéis compartir vuestros comentarios en esta publicación. ¿Y dónde creéis que será el Global Summit de 2024? Ese es un tema interesante 😀
¡Allí nos veremos!
Artículo
Estevan Martinez · 29 ago, 2019
¡Hola a tod@s de nuevo!En este tercer artículo (consulte la Parte 1 y la Parte 2) continúo con la presentación de la estructura interna de las bases de datos en Caché. Esta vez, les contaré algunas cosas interesantes y les explicaré cómo mi proyecto sobre el Explorador de bloques en Caché puede ayudarles a hacer que su trabajo sea más productivo.Creo que muchos de ustedes reconocerán lo que se muestra en la imagen (sobre la que se puede hacer clic). Cuando necesité visualizar la fragmentación de los globales, lo primero que pasó por mi mente fueron varias herramientas para desfragmentar el disco. Y, tengo la esperanza, de que conseguí elaborar un producto que es tan útil como dichas herramientas para hacerlo.En esta herramienta se muestra un diagrama de bloques. Donde cada cuadro representa un bloque, y su color corresponde a un global determinado, el cual se muestra mediante una lista en la sección de leyendas. Cada uno de los bloques, por sí mismo, también muestra que tan saturado de datos está. Esto les ayudaría a calcular rápidamente la capacidad de toda la base de datos con tan solo echar un vistazo en el diagrama. La visualización del global y niveles del diagrama de bloques aún no se han implementado, al igual que todos los bloques vacíos, por lo que estos se mostrarán en color blanco.Puede seleccionar una base de datos y el diagrama de bloques comenzará a cargarlos inmediatamente. La información no se carga de manera consecutiva, sino que lo hace de acuerdo al orden que tengan los bloques en el árbol de bloques, de modo que el proceso puede verse muy similar al que se muestra en la siguiente imagen.Continuaremos trabajando con la base de datos que utilizamos en el artículo anterior. Eliminé todos los globales, ya que no los necesitaremos. También generé nuevos datos mediante el paquete de la clase Sample, la cual se encuentra en la base de datos SAMPLES. Para hacerlo, configuré el mapeo de paquetes con mi namespace llamado HAB.Después, ejecuté un comando para generar datos.
do ##class(Sample.Utils).Generate(20000)
En nuestro mapa, obtuve el siguiente resultado:
Observe que los bloques no comienzan a llenarse desde el inicio del archivo. Comienzan a llenarse a partir del bloque 16 y vemos los bloques puntero en el nivel superior desde el bloque 50, en los bloques de datos. Tanto el 16 como el 50 son valores predeterminados pero, si es necesario, pueden modificarse. El inicio del bloque puntero se define en la propiedad NewGlobalPointerBlock de la clase SYS.Database, en esta se establece el valor predeterminado para los nuevos globales. Para los globales que ya existen, esto se puede modificar desde la clase %Library.GlobalEdit mediante la propiedad PointerBlock. El bloque que iniciará la secuencia de bloques de datos se especifica en la propiedad NewGlobalGrowthBlock de la clase SYS.Database. La propiedad GrowthBlock de la clase %Library.GlobalEdit hace lo mismo para los globales individuales. La modificación de estas propiedades únicamente tiene sentido para aquellos globales que todavía no contienen datos, ya que estos cambios no tienen efecto sobre la posición actual del bloque puntero que se encuentra en el nivel superior o de los bloques de datos.
Aquí podemos ver que el global ^Sample.PersonD cuenta con 989 bloques y está lleno en un 83%, seguido por el global ^Sample.PersonI que tiene 573 bloques (y está lleno en un 70% de su capacidad). Podemos escoger cualquiera de los globales para ver los bloques que están asignados para él. Y si seleccionamos el global ^Sample.PersonI, veremos que algunos de sus bloques están casi vacíos. También podemos ver que los bloques que pertenecen a estos dos globales están mezclados. Pero existe una razón para esto. Cuando se crean nuevos objetos, ambos globales se llenan: uno con los datos y el otro con los índices para la tabla Sample.Person.
Ahora que tenemos algunos datos para hacer una prueba, podemos aprovechar las funciones de administración de la base de datos que ofrece Caché y ver el resultado. Para comenzar, ajustemos un poco nuestros datos para crear una ilusión de actividad, en la que se puedan añadir y eliminar datos. Ejecutaremos un código que eliminará algunos datos de manera aleatoria.
set id=""
set first=$order(^Sample.PersonD(""),1)
set last=$order(^Sample.PersonD(""),-1)
for id=first:$random(5)+1:last {
do ##class(Sample.Person).%DeleteId(id)
}
Cuando ejecute este código, verá el resultado que se muestra a continuación. Tenemos algunos bloques vacíos, mientras que otros están llenos entre un 64% y un 67% de su capacidad.
Podemos utilizar la herramienta ^DATABASE desde el namespace %SYS para trabajar con nuestra base de datos. Utilizaremos algunas de sus funciones.
En primer lugar, ya que apenas llenamos los bloques, vamos a comprimir todos los globales de la base de datos y veamos lo que ocurre.
Como puede ver, la compresión nos permitió acercarnos, tanto como fue posible, al valor que necesitábamos del 90% de la capacidad. Y como resultado, los bloques que antes estuvieron vacíos ahora están llenos de los datos que se reubicaron desde los otros bloques. Los globales de la base de datos pueden comprimirse utilizando la herramienta ^DATABASE (función 7) o mediante el siguiente comando con la ruta hacia la base de datos que se aprobó como el primer parámetro:
do ##class(SYS.Database).CompactDatabase("c:\intersystems\ensemble\mgr\habr\")
También podemos mover todos los bloques vacíos hacia el final de la base de datos. Esto puede ser necesario, por ejemplo, cuando elimine una gran cantidad de datos y posteriormente desee compactar la base de datos. Para demostrar esto, repetiremos la eliminación datos desde la base de datos con la que hicimos nuestra prueba.
set gn=$name(^Sample.PersonD)
set first=$order(@gn@(""),1)
set last=$order(@gn@(""),-1)
for i=1:1:10 {
set id=$random(last)+first
write !,id
set count=0
for {
set id=$order(@gn@(id))
quit:id=""
do ##class(Sample.Person).%DeleteId(id)
quit:$increment(count)>1000
}
}
Esto es lo que obtuve después de la eliminación de datos.
Aún podemos ver algunos bloques vacíos aquí. Caché le permite mover estos bloques vacíos al final del archivo de la base de datos y después compactarlos. Para mover los bloques vacíos, utilizaremos el método FileCompact desde la clase SYS.Database, que se encuentra en el namespace del sistema o podemos recurrir a la herramienta ^DATABASE (función 13). En este método se aceptan tres parámetros: la ruta hacia la base de datos, la cantidad de espacio libre que deseamos obtener al final del archivo (0 como valor predeterminado), y el parámetro de retorno (la cantidad de espacio libre resultante).
do ##class(SYS.Database).FileCompact("c:\intersystems\ensemble\mgr\habr\",999)
Y esto es lo que obtenemos: no hay ningún bloque vacío. Los únicos bloques vacíos que aparecen al principio no cuentan, ya que se encuentran allí debido a la configuración (el lugar donde comienza el puntero del nivel superior más alto y los bloques de datos).
Desfragmentación
Ahora podemos realizar la desfragmentación de nuestros globales. En este proceso se reordenarán los bloques de cada global con una distribución diferente. Para la desfragmentación puede requerirse que haya algo de espacio libre al final del archivo de la base de datos, de modo que este espacio puede añadirse si la situación así lo requiere. El proceso puede iniciarse mediante la función 14 de la herramienta ^DATABASE o utilizando el siguiente comando:
d ##class(SYS.Database).Defragment("c:\intersystems\ensemble\mgr\habr\")
Liberación de espacio en disco
Ahora podemos ver nuestros globales alineados. Sin embargo, parece que la desfragmentación utilizó un poco más de espacio adicional en el archivo de la base de datos. Podemos liberar este espacio utilizando la función 12 de la herramienta ^DATABASE o mediante el siguiente comando:
d ##class(SYS.Database).ReturnUnusedSpace("c:\intersystems\ensemble\mgr\habr\")
Ahora, nuestra base de datos ocupa mucho menos espacio y solo queda 1 Mb de espacio libre en el archivo de la base de datos. La posibilidad de desfragmentar a los globales en una base de datos y administrar el espacio libre que tienen disponible al mover los bloques y crear espacio para liberar otros se introdujo recientemente. Antes de eso, cada vez que era necesario desfragmentar la base de datos y reducir el tamaño del archivo de la base de datos se tenía que utilizar la herramienta ^GBLOCKCOPY . Esta realizaba una copia "bloque por bloque" desde la base de datos de origen hacia otra que se hubiera creado recientemente, y permitía que el usuario seleccionara los globales específicos que se iban a transferir. La herramienta todavía está disponible.
Artículo
Ricardo Paiva · 9 abr, 2021
### Objetivo
Esta herramienta se usa para generar una Entrada/Salida (E/S) de lectura aleatoria desde dentro de la base de datos. La finalidad de esta herramienta es llevar la mayor cantidad de tareas posibles para conseguir las IOPS objetivo y asegurar que se mantienen tiempos de respuesta de disco aceptables. Los resultados recopilados de las pruebas de E/S variarán de configuración a configuración, de acuerdo con el subsistema de E/S. Antes de ejecutar estas pruebas, asegúrate de que el sistema operativo y la monitorización del nivel de almacenamiento estén configurados para capturar métricas de desempeño de E/S para su posterior análisis.
### Metodología
Empieza con una cantidad reducida de procesos y 10 000 iteraciones por proceso. Usa 100 000 iteraciones por proceso para matrices de almacenamiento basadas íntegramente en tecnología flash. A continuación, aumenta el número de procesos, por ejemplo, empieza con 10 trabajos y aumenta en 10, 20, 40, etc. Sigue ejecutando pruebas individuales hasta que el tiempo de respuesta esté por encima de 10 ms de forma constante, o las IOPS calculadas ya no aumenten de forma lineal.
Como guía, los siguientes tiempos de respuesta para lecturas aleatorias de bases de datos de 8KB y 64KB (sin cache) normalmente son aceptables para las matrices íntegramente flash:
* Promedio <= 2ms
* No debe exceder <= 5ms
La herramienta necesita una base de datos IRIS.DAT pre-expandida vacía, de un tamaño de al menos el doble del espacio de memoria en el servidor y de al menos cuatro veces el tamaño del la cache del controlador de almacenamiento. La base de datos debe ser mayor que la memoria, para asegurar que las lecturas no se guarden en la cache del sistema de archivos.
La herramienta usa el comando VIEW de ObjectScript, que lee bloques de bases de datos en memoria, así que si no estás logrando los resultados esperados, puede que todos los bloques de la base de datos ya estén en memoria.
### Especificaciones y objetivos
Completa la siguiente tabla con tus objetivos y especificaciones de entorno:
| Especificación | Ejemplo |
| ---------------------------- | -------------------------------------------------------------------------------------------------------------------------- |
| Almacenamiento | Especificación de la matriz de almacenamiento |
| Servidor físico | CPU, especificación de la memoria |
| Máquina virtual | Red Hat Enterprise Linux 7 24 vCPU, 40GB vRAM |
| Tamaño de la base de datos | 200GB |
| Memoria compartida | Memoria compartida asignada de 26,956MB usando Huge Pages: búferes globales de 24,000MB, búferes de rutina de 1,000MB |
| IOPS objetivo | 2,000 |
| Tiempo de respuesta objetivo | <=5ms |
### Instalación
Descarga la herramienta **PerfTools.RanRead.xml** de GitHub [aquí](https://github.com/intersystems/random-read-performance-tool).
Importa **PerfTools.RanRead.xml** en el namespace USER.
USER> do $system.OBJ.Load("/tmp/PerfTools.RanRead.xml","ckf")
Ejecuta el método Help para ver todos los puntos de acceso. Todos los comandos se ejecutan en %SYS.
USER> do ##class(PerfTools.RanRead).Help()
InterSystems Random Read IO Performance Tool
--------------------------------------------
do ##class(PerfTools.RanRead).Setup(Directory,DatabaseName,SizeGB,LogLevel)
- Creates database and namespace with the same name. The log level must be in the range of 0 to 3, where 0 is “none” and 3 is “verbose”.
do ##class(PerfTools.RanRead).Run(Directory,Processes,Iterations)
- Run the random read IO test.
do ##class(PerfTools.RanRead).Stop()
- Terminates all background jobs.
do ##class(PerfTools.RanRead).Reset()
- Deletes all random read history stored in ^PerfTools.RanRead*
do ##class(PerfTools.RanRead).Export(directory)
- Exports a summary of all random read test history to tab delimited text file.
### Configuración
Crea una base de datos vacía (preexpandida) llamada ZRANREAD de aproximadamente el doble de tamaño de la memoria del servidor físico a probar. Asegúrate de que la base de datos vacía tenga al menos cuatro veces el tamaño de la cache del controlador de almacenamiento. Para crear automáticamente un namespace y una base de datos, puedes hacerlo manualmente o usar el siguiente método.
USER> do ##class(PerfTools.RanRead).Setup("/usr/iris/db/zranread","ZRANREAD",100,1)
Creating 100GB database in /usr/iris/db/zranread/
Database created in /usr/iris/db/zranread/
Run %Installer Manifest...
2016-05-23 13:33:59 0 PerfTools.RanRead: Installation starting at 2016-05-23 13:33:59, LogLevel=1
2016-05-23 13:33:59 1 CreateDatabase: Creating database ZRANREAD in /usr/iris/db/zranread// with resource
2016-05-23 13:33:59 1 CreateNamespace: Creating namespace ZRANREAD using ZRANREAD/ZRANREAD
2016-05-23 13:33:59 1 ActivateConfiguration: Activating Configuration
2016-05-23 13:34:00 1 EnableEnsemble: Enabling ZRANREAD
2016-05-23 13:34:00 1 ActivateConfiguration: Activating Configuration
2016-05-23 13:34:00 0 PerfTools.RanRead: Installation succeeded at 2016-05-23 13:34:00
2016-05-23 13:34:00 0 %Installer: Elapsed time 1.066633s
Database /usr/iris/db/zranread/ ready for testing.
do ##class(PerfTools.RanRead).Run(directory,processes,iterations) e.g.
do ##class(PerfTools.RanRead).Run("/usr/iris/db/zranread/",1,10000)
### Ejecución
Ejecuta el método Run aumentando la cantidad de procesos y tomando nota, cada vez, del tiempo de respuesta.
Si las pruebas son demasiado rápidas o los resultados no son los esperados, aumenta entonces el número de iteraciones a 10 000.
USER> do ##class(PerfTools.RanRead).Run("/usr/iris/db/zranread",20,10000)
InterSystems Random Read IO Performance Tool
--------------------------------------------
Starting 20 jobs in the background.
To terminate jobs run: do ##class(PerfTools.RanRead).Stop()
Waiting for jobs to finish.........................
Random read background jobs finished.
20 processes (1000 iterations) average response time = 7.18ms
Calculated IOPS = 2787
### Resultados
Los resultados para cada ejecución se guardan en USER en la tabla SQL PerfTools.RanRead. Ejecuta la siguiente consulta SQL para ver un resumen de resultados.
SELECT RunDate,RunTime,Database,Iterations,Processes,
{fn ROUND(AVG(ResponseTime),2)} As ResponseTime,
{fn ROUND(AVG(IOPS),0)} As IOPS
FROM PerfTools.RanRead
GROUP BY Batch
Para exportar el conjunto de resultados a un archivo de texto delimitado por tabulaciones, ejecuta lo siguiente:
USER> do ##class(PerfTools.RanRead).Export("/usr/iris/db/zranread/")
Exporting summary of all random read statistics to /usr/iris/db/zranread/PerfToolsRanRead_20160523-1408.txt
Done.
### Análisis
Abre en Excel el archivo de texto exportado. Luego, copia y pega los datos en la hoja de cálculo PerfToolsRandomRead\_Analysis\_Template.xlsx para hacer un gráfico.
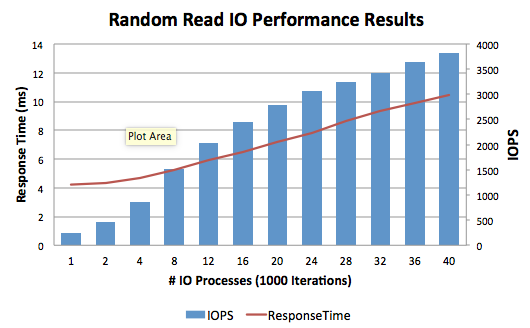
La hoja de cálculo de muestra se puede descargar desde GitHub [aquí](https://github.com/intersystems/random-read-performance-tool).
### Limpieza
Cuando se terminen de ejecutar las pruebas, elimina el historial ejecutando:
%SYS> do ##class(PerfTools.RanRead).Reset()
Pregunta
Yone Moreno · 25 nov, 2022
Buenos días,
Hemos estado indagando de qué manera activar un Servidor para Generar Tokens y un Servidor de Recursos asociado para Validar el Token. Este paso, actualmente lo hemos averiguado con el inestimable apoyo de @Alberto Fuentes de Intersystems.
A continuación la necesidad es la siguiente: Para centralizar en 1 único Entorno ( PREPRODUCCION ) y en 1 único Namespace el Servidor de Recursos ( por ejemplo en un NAMESPACE dedicado llamado AUTHSERVER ) ; necesitaríamos de alguna manera "llamar", "invocar", "comunicar" desde los otros entornos ( por ejemplo INTEGRACION ) con el Servidor de Recursos de PREPRODUCCION con el fin de Validar el Token. ¿Por favor, ustedes nos podrían orientar, guiar, pautar, instruir al respecto?
📍¿Qué vía existe para "llamar", "invocar", "comunicar" desde los otros entornos ( por ejemplo INTEGRACION ) con el Servidor de Recursos de PREPRODUCCION con el fin de Validar el Token?
En concreto, disponemos en Integracion de un Servicio REST llamado "Servicios.REST.Radiologia.CConcertadosv01r00", y dentro un método denominado "ResServer". Nuestras pesquisas nos han llevado a profundizar en el siguiente código:
ClassMethod ResServer(accessToken As %String(MAXLEN="")) As %Status
{
$$$LOGINFO("Entra en método ResServer")
// This is a dummy resource server which just gets the access token from the request
// and uses the introspection endpoint to ensure that the access token is valid.
// Normally the response would not be security related, but would contain some interesting
// data based on the request parameters.
// retrieve access token from HTTP request
;set accessToken = ##class(%SYS.OAuth2.AccessToken).GetAccessTokenFromRequest(.status) /*
if $$$ISERR(status) {
set %response.Status = ..#HTTP401UNAUTHORIZED
write "[Error] GetAccessTokenFromRequest: "_$system.Status.GetErrorText(status),!
quit $$$OK
}
*/ $$$LOGALERT("Antes de set isJWTValid = ##class(%SYS.OAuth2.Validation).ValidateJWT('resserver',accessToken,'','',.jwtPayload ,.securityParameters,.sc)")
// validate token
;set isJWTValid = ##class(%SYS.OAuth2.Validation).ValidateJWT("resserver",accessToken,"","",.jwtPayload ,.securityParameters,.sc)
set isJWTValid = ##class(%SYS.OAuth2.Validation).ValidateJWT("https://[Servidor de PRE]:57773/resserver/",accessToken,"","",.jwtPayload ,.securityParameters,.sc)
$$$LOGALERT("Despues de isJWTValid ... apuntando a https://[Servidor de PRE]:57773/resserver/")
$$$LOGINFO("Antes de if (('isJWTValid) || ($$$ISERR(sc))) {")
$$$LOGINFO("Imprimir ('isJWTValid): "_('isJWTValid))
$$$LOGINFO("Imprimir ($$$ISERR(sc): "_($$$ISERR(sc)))
$$$LOGINFO("Imprimir $system.Status.GetErrorText(sc): "_$system.Status.GetErrorText(sc))
if (('isJWTValid) || ($$$ISERR(sc))) {
/*
set %response.Status = ..#HTTP401UNAUTHORIZED
write "Error Getting Access Token="_$system.Status.GetErrorText(sc),!
*/
quit '$$$OK
} $$$LOGINFO("Antes de set sc = ##class(%SYS.OAuth2.AccessToken).GetIntrospection('resserver', accessToken, .jsonObject)")
// introspection
set sc = ##class(%SYS.OAuth2.AccessToken).GetIntrospection("resserver", accessToken, .jsonObject)
if $$$ISERR(sc) {
/*
set %response.Status = ..#HTTP401UNAUTHORIZED
write "Introspection Error="_..EscapeHTML($system.Status.GetErrorText(sc)),!
*/
quit '$$$OK
}
$$$LOGINFO("Antes de write 'OAuth 2.0 access token used to authorize resource server (RFC 6749)<br>'")
/*
write "OAuth 2.0 access token used to authorize resource server (RFC 6749)<br>"
write "Access token validated using introspection endpoint (RFC 7662)<br>"
write " scope='"_jsonObject.scope_"'<br>"
write " user='"_jsonObject.username_"'",!
*/
$$$LOGINFO("Antes del final quit $$$OK")
quit $$$OK
}
Seguidamente nuestras indagaciones nos llevan a:
Ésta línea si llama desde PREPRODUCCION al Servidor de Recursos de PREPRODUCCION y Valida el Token de manera correcta:
set isJWTValid = ##class(%SYS.OAuth2.Validation).ValidateJWT("resserver",accessToken,"","",.jwtPayload ,.securityParameters,.sc)
Sin embargo si nosotros tratamos invocar desde INTEGRACION al Servidor de Recursos de PREPRODUCCION calificando el primer parámetro, el "client" con la Dirección completa del Servidor de Recursos de PRE ; da Excepción:
set isJWTValid = ##class(%SYS.OAuth2.Validation).ValidateJWT("https://[DNS de PRE]:57773/resserver/",accessToken,"","",.jwtPayload ,.securityParameters,.sc)
En particular la Excepción que observamos en los LOGS del Servicio REST es:
ERROR #5002: Error de cache: <UNDEFINED>zValidateJWT+22^%SYS.OAuth2.Validation.1 *client
Lo cual parece que se debe al hecho de que en la función interna de la clase: "%SYS.OAuth2.Validation" titulada: "ValidateJWT" ; en la llamada "Set client=##class(OAuth2.Client).Open(applicationName,.sc)"
Se genera una Excepción basada en el hecho de que le cuesta abrir el Servidor de Recursos; en la clase: OAuth2.Client en el método Open en la línea Set client=##class(OAuth2.Client).%OpenId(applicationName,,.sc)
¿Por favor, ustedes nos podrían orientar, guiar, pautar, instruir al respecto?
📍 La cuestión es ¿Qué vía existe para "llamar", "invocar", "comunicar" desde los otros entornos ( por ejemplo INTEGRACION ) con el Servidor de Recursos de PREPRODUCCION con el fin de Validar el Token?
Muchísimas gracias de antemano a ustedes por su tiempo, apoyo y auxilio.
Un saludo
Adicionalmente hemos leído con atención:
https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GOAUTH_CERTS
https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GOAUTH_background
https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GOAUTH_certs#GOAUTH_certs_client
https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GOAUTH_certs#GOAUTH_certs_resource
https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GOAUTH_jwt_headers
https://community.intersystems.com/post/making-jwtoauth20
Sin embargo, sí seguimos con la misma cuestión:
¿Qué vía existe para "llamar", "invocar", "comunicar" desde los otros entornos ( por ejemplo INTEGRACION ) con el Servidor de Recursos de PREPRODUCCION con el fin de Validar el Token?
Es decir la pregunta de otra forma sería:
¿Qué mecanismo existe para desde un Entorno A (Integración) se comunique con un Entorno B (Preproducción) con la misión de Validar el Token desde el Entorno A empleando el Servidor de Recursos centralizados disponible en el Entorno B?
Muchísimas gracias por su atención, y gracias por sus respuestas.
Un saludo Hola Yone,
Entiendo que quieres montar lo siguiente:
* Cliente externo (e.g. Postman) que solicite token a servidor de autorización.
* Servidor de autorización en PREPRODUCCIÓN.
* Servicio REST en INTEGRACIÓN que actúe como servidor de recursos, que reciba y valide el token.
En principio estás en un escenario como el de *Client Credentials* del [workshop-iris-oauth2](https://github.com/intersystems-ib/workshop-iris-oauth2).
En resumen, tendrías que configurar lo siguiente:
* Definir servidor autorización OAuth en PREPRODUCCIÓN.
* Registrar cliente en servidor de autorización en PREPRODUCCIÓN: tendrás ClientID y ClientSecret. Lo necesitarás para solicitar token.
* Definir servidor de recursos en INTEGRACIÓN como se hacía en este [paso](https://github.com/intersystems-ib/workshop-iris-oauth2#a3-resource-server).
* Cuando defines el servidor de recursos, tienes que indicar cuál es el endpoint del servidor de autorización.
* Tienes que asignarle un nombre, e.g. "resserver"
* En el [código](https://github.com/intersystems-ib/workshop-iris-oauth2/blob/4c0143af52606686d105b81c29fa35649e4fcc63/oauth-resource-server/src/res/Server.cls#L33) del servidor de recursos, en INTEGRACIÓN, en el método `ValidateJWT ` sólo necesitas referirte al nombre que le hayas puesto al servidor de recursos (e.g. "resserver").
* El método `ValidateJWT` ya se encarga de utilizar tu definición de servidor de recursos "resserver", donde tenías el endpoint del servidor de autorización, y validar el token que le pases.
Hola Alberto,
Gracias por la respuesta.
Lo estudiamos internamente, probamos concienzudamente y te respondemos en cuanto nos sea posible.
Muchas gracias de antemano.
Un saludo.
Artículo
Ricardo Paiva · 4 sep, 2019
¡Hola a tod@s!
Con el lanzamiento de la plataforma de datos InterSystems IRIS, podemos ofrecer nuestro producto incluso en un contenedor Docker. Pero... ¿qué es un contenedor?
La principal definición de un contenedor es que se trata de un entorno protegido para un proceso.
Los contenedores son paquetes definidos por un software, que tienen algunas similitudes con las máquinas virtuales (MV), como por ejemplo, que pueden ejecutarse.
Los contenedores proporcionan aislamiento sin la necesidad de emular completamente al sistema operativo (SO). Por lo tanto, los contenedores son mucho más ligeros que una MV.
En esencia, los contenedores son una respuesta a la cuestión de cómo trasladar de forma fiable una aplicación desde un sistema/entorno a otro y garantizar que funcione. Cuando todas las dependencias de la aplicación se encierran dentro de un contenedor y crean un espacio para aislar un proceso, hay más posibilidades de garantizar que la solución de la aplicación se ejecutará al moverse entre las plataformas.
El sistema operativo nos permite ejecutar procesos. Estos procesos comparten espacios de direcciones, namespaces, grupos de control (cgroups)... y, en general, tienen acceso a todo el entorno del sistema operativo, a su programación y también los administran. Todo esto es positivo. Sin embargo, ¿qué pasaría si quisiéramos aislar un proceso en particular o un número de procesos para ejecutar una tarea, operación o servicio específicos? Los contenedores nos brindan la capacidad de aislar un proceso. Por lo tanto, podríamos definir un contenedor como el entorno protegido para un proceso.
Entonces ¿qué es un entorno protegido? Es un grado de aislamiento en el cual un contenedor guarda sus procesos. Esta característica se implementa mediante la función central de Linux llamada namespaces (https://en.wikipedia.org/wiki/Linux_namespaces), la cual también permite que otras partes importantes del sistema se aíslen, como la interfaz de red, los puntos de montaje, comunicaciones entre procesos (IPC) y tiempo compartido universal (uts).
El contenedor o entorno protegido también puede dirigirse o controlarse mediante otra función central llamada grupos de control o cgroups (https://en.wikipedia.org/wiki/Cgroups). Las reglas que damos a los contenedores sirven para garantizar que el contenedor sea un buen vecino cuando comparta recursos con otros contenedores y con el servidor.
Para entender cuál es la diferencia entre un contenedor y una MV, podríamos utilizar la analogía de que una MV es como una casa, mientras que el contenedor es como un piso.
Las máquinas virtuales son autónomas e independientes como una casa. Todas las casas tienen su propia infraestructura: tuberías, calefacción, electricidad, etc. Además, una casa tiene requerimientos mínimos (al menos 1 dormitorio, 1 techo, etc.)
En cambio, los contenedores se construyeron para aprovechar una infraestructura compartida y por ello podemos compararlos con un piso. El complejo de pisos comparte las tuberías, la calefacción, el sistema eléctrico, la entrada principal, los ascensores, etc. De la misma forma, los contenedores aprovechan los recursos disponibles del servidor mediante el kernel de Linux. También, hay que considerar que los pisos son de diferentes tamaños y formas.
Debido a que los contenedores no tienen un sistema operativo completo, sino únicamente las características mínimas para acoplarse a Linux, como algunos ejecutables en /bin, algunos archivos de configuración y definición en /etc y algunos otros archivos, estos pueden ser de tamaño pequeño, lo cual los hace más rápidos al momento de moverlos o ejecutarlos en segundo plano. Esto se traduce en mayor velocidad a partir del momento en que se construyen, desde el canal de suministro de la fábrica de software hasta la ejecución final en producción. Por cierto, los contenedores se ajustan perfectamente al contexto de la arquitectura de microservicios CI/CD, pero esa es otra historia.
Los procesos en el contenedor están estrechamente relacionados con el ciclo de vida del contenedor. Cuando inicializo un contenedor, normalmente quiero que todos los servicios de mi aplicación se ejecuten y funcionen correctamente (por ejemplo, piense en el puerto 80 para el contenedor de un servidor web y en los puertos 57772 y 1972 para un contenedor de InterSystems IRIS). Cuando detengo el contenedor, también se detienen todos los procesos.
Lo que describí en esta publicación es la noción fundamental del tiempo de ejecución de un contenedor, es decir, un entorno protegido que aísla sus procesos del servidor y de otros contenedores.
Hay otra parte para entender mejor el trabajo que realizan los contenedores, el cual hace referencia a sus imágenes. Pero esto lo veremos en una siguiente publicación.
Artículo
Fabiano Sanches · 18 feb, 2020
¡Hola a todos!
Quiero compartir un proyecto personal que comenzó con una simple solicitud en el trabajo:
¿Es posible saber cuántas licencias de Caché estamos usando?
Leyendo otros artículos en la Comunidad, encontré este excelente artículo de David Loveluck:
APM - Utilizando "Caché History Monitor"https://community.intersystems.com/post/apm-using-cach%C3%A9-history-monitor
Siguiendo el artículo de David, empezé a usar Caché History Monitor para mostrar toda esa información.
Al considerar la pregunta: ¿Qué tecnología genial debo usar?
Mi decisión fue CSP, simple y potente, para que mi cliente se diera cuenta de que Caché es mucho más que MUMPS/Terminal.
Después de crear las páginas para mostrar el historial de Licencias, Crecimiento de la base de datos y Sesiones CSP, he decidido crear un nuevo diseño para las páginas del Panel de Control y de los Procesos del Sistema.
Todo funciona muy bien con mi instancia de Caché.
Sin embargo, ¿qué pasa con IRIS?
Siguiendo el artículo de Evgeny Shvarov:
Utilizando Docker con tu repositorio de desarrollo de InterSystems IRIShttps://community.intersystems.com/post/using-docker-your-intersystems-iris-development-repository
Yo lo "dockerizé" y subí los códigos a GitHub, así que ahora todo el mundo puede intentarlo con unos pocos pasos.
Cómo ejecutarlo
Para comenzar a codificar con este repositorio, sigue estos pasos:
1. Clona el repositorio en cualquier directorio local:$ git clone https://github.com/diashenrique/iris-history-monitor.git
2. Abre el terminal en este directorio y ejecútalo:$ docker-compose build
3. Ejecuta el contenedor IRIS con tu proyecto:$ docker-compose up -d
Cómo probarlo
Abre el navegador y ve a:
Ejemplo: http://localhost:52773/csp/irismonitor/dashboard.csp
El usuario _SYSTEM puede ejecutar el Panel de Control y las otras funciones.
Panel de Control del Sistema
El Panel de Control del Sistema muestra los siguientes elementos:
Licencias (Licensing)
Hora del sistema (System Time)
Errores de la aplicación (Application Errors)
Procesos de Cache (Cache Processes)
Sesiones de CSP (CSP Sessions)
Bloqueos de tablas (Lock Table)
Espacio del Diario (Journal Space)
Estado del Diario (Journal Status)
Servidor de aplicaciones ECP (ECP AppServer)
Servidor de datos ECP (ECP DataServer)
Write Daemon
Eficiendia de Cache (Cache Efficiency)
Alertas graves (Serious Alerts)
Los widgets de gráficos de líneas trazan un punto cada 5 segundos.
Menu del Sistema
Procesos del Sistema
Filtros de Procesos
Utiliza diferentes filtros para obtener los resultados que necesites. También podrás utilizar hacer Ordenaciones Múltiples (Multiple Sorts), presionando Shift + click en el encabezado de la columna. ¡E incluso exportar la cuadrícula de datos a Excel!
History Monitor
El "History Monitor" para Sesiones CSP y Licencias muestran la información entre tres secciones:
Cada 5 minutos
Diariamente
A cada hora
El Crecimiento de la Base de Datos (Database Growth) solo muestra información diaria.
Las páginas de historial comparten las siguientes características:
Selector de Rango de Fechas (Date Range Picker)
El valor predeterminado es "Últimos 7 Días" (Last 7 Days).
Gráficos / Tablas de Datos
En la parte superior derecha de cada pantalla, hay dos botones: Gráfico / Tabla de Datos (Chart / Data Tables)
La tabla de datos muestra la información con la que se crea el gráfico, y también se puede descargar en formato Excel.
Excel muestra el mismo formato, contenido y grupo definidos en el CSP.
Zoom
Todos los gráficos tienen la opción "Zoom" para visualizar la información con más detalle.
Promedio y Máximo
Para las sesiones "por hora" o "por día", los gráficos muestran los valores Promedio y Máximo.
AVG (Promedio)
MAX (Máximo)
¡Espero que os resulte útil!
Artículo
Jose-Tomas Salvador · 20 abr, 2021
Palabras clave: Python, JDBC, SQL, IRIS, Jupyter Notebook, Pandas, Numpy y aprendizaje automático
*Hoy me he encontrado con este artículo de Zphong Li, que publicó en Enero de 2020 pero que creo que es muy interesante y aún útil a día de hoy. Así que... para los que estéis haciendo vuestros primeros pinitos en Machine Learning con InterSystems IRIS, Python y Jupyter... aquí lo tenéis!!*
## 1. Objetivo
Esta es una nota sencilla de 5 minutos, donde os muestro cómo invocar el controlador JDBC de IRIS con la ayuda de Python 3, por ejemplo desde un Jupyter Notebook, para leer y escribir datos en una instancia de la base de datos de IRIS vía SQL.
El año pasado Zhong Li publicó una nota breve sobre como [Enlazar Python con una base de datos Caché](https://community.intersystems.com/post/deep-learning-demo-kit-python3-binding-healthshare-part-i) (sección 4.7). Ahora podría ser el momento de recapitular algunas opciones y discusiones sobre el uso de Python para acceder a una base de datos de IRIS, para leer sus datos en un dataframe de Pandas y una matriz de NumPy para realizar un análisis básico, y después escribir algunos datos pre-procesados o normalizados de nuevo en IRIS y que esté listo para canalizaciones (*pipelines*) adicionales de ML/DL.
Inmediatamente se me ocurren varias **opciones**:
1. **ODBC**: ¿Cómo hacerlo con PyODBC para Python 3 y SQL nativo?
2. **JDBC**: ¿Cómo hacerlo con JayDeBeApi para Python 3 y SQL nativo?
3. **Spark**: ¿Cómo hacerlo con PySpark y SQL?
4. **API nativa de Python para IRIS**: ¿Qué hay más allá del anterior Python Binding para Caché?
5. ** ¿IPtyhon Magic SQL %%sql**? ¿Podría [](https://github.com/catherinedevlin/ipython-sql) funcionar con IRIS?
¿Hay alguna otra opción que se me haya escapado? También estoy interesado en probarla.
## 2. Alcance
¿Comenzamos con un enfoque JDBC común? En la siguiente nota breve recapitularemos ODBC, Spark y la API nativa de Python.
### En el alcance:
Los siguientes componentes comunes se abordan en esta demostración rápida:
Anaconda
Jupyter Notebook
Python 3
JayDeBeApi
JPyPe
Pandas
NumPy
Una instancia de IRIS 2019.x
### Fuera del alcance:
En esta nota rápida NO se abordarán los siguientes aspectos - son importantes y pueden tratarse por separado con soluciones, implementaciones y servicios específicos:
Seguridad de extremo a extremo.
Rendimiento no funcional, etc.
Solución de problemas y soporte.
Licencias.
## 3. Demostración
### 3.1 Ejecución de una instancia de IRIS:
Simplemente ejecuté un contenedor IRIS 2019.4 como servidor "remoto" de la base de datos. Puedes utilizar cualquier instancia de IRIS a la que tengas acceso autorizado.
zhongli@UKM5530ZHONGLI MINGW64 /c/Program Files/Docker Toolbox$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESd86be69a03ab quickml-demo "/iris-main" 3 days ago Up 3 days (healthy) 0.0.0.0:9091->51773/tcp, 0.0.0.0:9092->52773/tcp quickml
### 3.2 Anaconda y Jupyter Notebook:
Reutilizaremos el mismo enfoque de configuración descrito [aquí](https://community.intersystems.com/post/deep-learning-demo-kit-python3-binding-healthshare-part-i) para Anaconda (sección 4.1) y [aquí](https://community.intersystems.com/post/run-deep-learning-demo-python3-binding-healthshare-part-ii) para Jupyter Notebook (sección 4) en un ordenador portátil. Python 3.x se instala junto con este paso.
### 3.3 Instalar JayDeBeApi y JPyPe:
Inicié mi JupyterNotebook, y luego simplemente ejecuté lo siguiente en sus celdas para configurar un puente desde Python-a-JDBC/Java:
!conda install --yes -c conda-forge jaydebeapi
JayDeBeApi utiliza JPype 0.7 en el momento de escribir este artículo (enero del 2020), pero no funciona debido a un error conocido, por lo que tuve que utilizar la 0.6.3
!conda install --yes -c conda-forge JPype1=0.6.3 --force-reinstall
### 3.4 Conectar a una base de datos de IRIS por medio de JDBC
Hay una [documentación oficial de JDBC en IRIS](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_jdbc) aquí.
Para las ejecuciones de Python SQL sobre JDBC, utilicé los siguientes códigos como ejemplo. Se conecta a una tabla de datos llamada "`DataMining.IrisDataset`" dentro del namespace "USER" de esta instancia de IRIS.
### 1. Establezca las variables de entorno, si es necesario
#importa os
#os.environ['JAVA_HOME']='C:\Progra~1\Java\jdk1.8.0_241'
#os.environ['CLASSPATH'] = 'C:\interSystems\IRIS20194\dev\java\lib\JDK18\intersystems-jdbc-3.0.0.jar'
#os.environ['HADOOP_HOME']='C:\hadoop\bin'
#winutil binary must be in Hadoop's Home
### 2. Obtiene la conexión JDBC y el cursor
import JayDeBeApi
url = "jdbc:IRIS://192.168.99.101:9091/USER"
driver = 'com.intersystems.jdbc.IRISDriver'
user = "SUPERUSER"
password = "SYS"
#libx = "C:/InterSystems/IRIS20194/dev/java/lib/JDK18"
jarfile = "C:/InterSystems/IRIS20194/dev/java/lib/JDK18/intersystems-jdbc-3.0.0.jar"
conn = jaydebeapi.connect(driver, url, [user, password], jarfile)
curs = conn.cursor()
### 3. Especifica la fuente de la tabla de datos
dataTable = "DataMining.IrisDataset"
### 4. Obtiene el resultado y visualiza
curs.execute("select TOP 20 * from %s" % dataTable)
result = curs.fetchall()
print("Total records: " + str(len(result)))
for i in range(len(result)):
print(result[i])
### 5. Cerrar y limpiar - Los mantendre abiertos para los próximos accesos.
#curs.close()
#conn.close()
Total records: 150
(1, 1.4, 0.2, 5.1, 3.5, 'Iris-setosa')
(2, 1.4, 0.2, 4.9, 3.0, 'Iris-setosa')
(3, 1.3, 0.2, 4.7, 3.2, 'Iris-setosa')
... ...
(49, 1.5, 0.2, 5.3, 3.7, 'Iris-setosa')
(50, 1.4, 0.2, 5.0, 3.3, 'Iris-setosa')
(51, 4.7, 1.4, 7.0, 3.2, 'Iris-versicolor')
... ...
(145, 5.7, 2.5, 6.7, 3.3, 'Iris-virginica')
... ...
(148, 5.2, 2.0, 6.5, 3.0, 'Iris-virginica')
(149, 5.4, 2.3, 6.2, 3.4, 'Iris-virginica')
(150, 5.1, 1.8, 5.9, 3.0, 'Iris-virginica')
Ahora hemos verificado que Python en JDBC estaba funcionando. Lo siguiente es solo un poco de análisis de datos de rutina y preprocesamiento para los canales habituales de ML que deberíamos mencionar una y otra vez para demostraciones y comparaciones posteriores, por lo que se adjunta para mayor comodidad.
### 3.5 Convertir los resultados de SQL al DataFrame de Pandas y después a las matrices de NumPy
Instala los paquetes Pandas y NumPy a través de Conda si aún no están instalados, como se explicó en el punto 3.3.
A continuación, ejecute lo siguiente como un ejemplo:
### Transforma los resultados de SQL "sqlData" en un dataframe de Pandas "df", y después en una matriz de NumPy "arrayN" para otras canalizaciones (*pipelines*) de ML
import pandas as pd
sqlData = "SELECT * from DataMining.IrisDataset"
df= pd.io.sql.read_sql(sqlData, conn)
df = df.drop('ID', 1)
df = df[['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']]
# Establece las etiquetas en 0, 1, 2, para la matriz NumPy
df.replace('Iris-setosa', 0, inplace=True)
df.replace('Iris-versicolor', 1, inplace=True)
df.replace('Iris-virginica', 2, inplace=True)
# Convierte el dataframe en una matriz Numpy
arrayN = df.to_numpy()
### 6. Cierra y limpia - ¿si la conexión ya no es necesaria?
#curs.close()
#conn.close()
Echemos un vistazo rutinario a los datos actuales:
df.head(5)
df.describe()
Ahora tenemos un DataFrame, y una matriz NumPy normalizada de una tabla de datos fuente a nuestra disposición.
Ciertamente, ¿podemos probar varios análisis de rutina con los que comenzaría un experto en ML, como se indica a continuación, en Python para reemplazar a [R, como en el enlace que se encuentra aquí](http://www.lac.inpe.br/~rafael.santos/Docs/CAP394/WholeStory-Iris.html)?
La fuente de datos se cita aquí
### 3.6 Dividir los datos y volver a escribirlos en la base de datos de IRIS por medio de SQL:
Ciertamente, podemos dividir los datos en un conjunto de Entrenamiento y otro de Validación o Prueba, como es habitual, y después escribirlos de nuevo en tablas temporales de la base de datos, para algunas emocionantes funciones ML de IRIS:
import numpy as np
from matplotlib
import pyplot
from sklearn.model_selection import train_test_split
# mantiene, por ejemplo, el 20% = 30 filas como datos de prueba, y el 80% = 120 filas para entrenamiento
X = arrayN[:,0:4]
y = arrayN[:,4]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1, shuffle=True)
# Hace que el 80% de las filas, escogidas aleatoriamente, estén en el conjunto Entrenamiento
labels1 = np.reshape(Y_train,(120,1))
train = np.concatenate([X_train, labels1],axis=-1)
# Hace que el 20% de las filas, escogidas eleatoriamente, estén en el conjunto Prueba,
lTest1 = np.reshape(Y_validation,(30,1))
test = np.concatenate([X_validation, lTest1],axis=-1)
# Escribe el conjunto de datos de entrenamiento en un dataframe de Pandas
dfTrain = pd.DataFrame({'SepalLength':train[:, 0], 'SepalWidth':train[:, 1], 'PetalLength':train[:, 2], 'PetalWidth':train[:, 3], 'Species':train[:, 4]})
dfTrain['Species'].replace(0, 'Iris-setosa', inplace=True)
dfTrain['Species'].replace(1, 'Iris-versicolor', inplace=True)
dfTrain['Species'].replace(2, 'Iris-virginica', inplace=True)
# Escribe los datos de pruebas en un dataframe de Pandas
dfTest = pd.DataFrame({'SepalLength':test[:, 0], 'SepalWidth':test[:, 1], 'PetalLength':test[:, 2], 'PetalWidth':test[:, 3], 'Species':test[:, 4]})
dfTest['Species'].replace(0, 'Iris-setosa', inplace=True)
dfTest['Species'].replace(1, 'Iris-versicolor', inplace=True)
dfTest['Species'].replace(2, 'Iris-virginica', inplace=True)
### 3. Especifica los nombres de las tablas temporales
dtTrain = "TRAIN02"
dtTest = "TEST02"
### 4. Crea 2 tablas temporales - puedes probar eliminar las tablas temporales y volver a crearlas una y otra vez
curs.execute("Create Table %s (%s DOUBLE, %s DOUBLE, %s DOUBLE, %s DOUBLE, %s VARCHAR(100))" %(dtTrain,dfTrain.columns[0],dfTrain.columns[1],dfTrain.columns[2], dfTrain.columns[3], dfTrain.columns[4]))
curs.execute("Create Table %s (%s DOUBLE, %s DOUBLE, %s DOUBLE, %s DOUBLE, %s VARCHAR(100))" %(dtTest,dfTest.columns[0],dfTest.columns[1],dfTest.columns[2],dfTest.columns[3],dfTest.columns[4]))
### 5. Escribe el conjunto de Entrenamiento y el conjunto de Prueba en las tablas. Se puede intentar borrar cada vez el registro anterior y luego insertarlo otra vez.
curs.fast_executemany = True
curs.executemany( "INSERT INTO %s (SepalLength, SepalWidth, PetalLength, PetalWidth, Species) VALUES (?, ?, ?, ? ,?)" % dtTrain, list(dfTrain.itertuples(index=False, name=None)) )
curs.executemany( "INSERT INTO %s (SepalLength, SepalWidth, PetalLength, PetalWidth, Species) VALUES (?, ?, ?, ? ,?)" % dtTest, list(dfTest.itertuples(index=False, name=None)) )
### 6. Cierra y limpia - ¿si la conexión ya no es necesaria?
#curs.close()
#conn.close()
Ahora, si cambiamos a la Consola de Administración de IRIS, o a la Consola del Terminal SQL, deberíamos ver 2 tablas temporales creadas: TRAIN02 con 120 filas y TEST02 con 30 filas.
Tendré que detenerme aquí, ya que supuestamente este artículo es una nota rápida muy breve.
## 4. Advertencias
* El contenido anterior puede ser modificado o perfeccionado.
## 5. Siguiente
Simplemente reemplazaremos las secciones 3.3 y 3.4 con PyODBC, PySPark y la API nativa de Python para IRIS, a menos que a alguien no le importe contribuir con una nota rápida - también lo agradeceré.
Artículo
Marcio Pereira · 23 feb, 2022
En proyectos de software orientados a objetos son utilizados comúnmente patrones de proyecto para resolución de problemas. Si usted desarrolla en COS, este artículo tendrá sentido para su día a día.
En proyectos de software orientados a objetos son utilizados comúnmente patrones de proyectos para la resolución de problemas que pueden ocurrir con frecuencia en determinados contextos. El presente artículo aborda la implementación de patrones de proyecto utilizando el lenguaje Caché Object Script, teniendo en cuenta que existen limitaciones de la tecnología para implementaciones técnicas de programación orientada a objetos. Serán utilizados algunos de los principales patrones abordados en la literatura para comprender las dificultades encontradas para implementaciones de patrones de proyectos utilizando el lenguaje en cuestión, así como existen posibilidades de entorno para implementaciones imposibilitadas por las limitaciones del lenguaje durante el desarrollo. Por fin, destaca la capacidad del lenguaje utilizado para implementaciones complejas de proyectos de software orientados a objetos.
Palabras llave: Caché, Cache Object Script, Patrones de proyecto, programación orientada a objetos.
Introducción
Intersystems Caché es una base de datos de alto desempeño que entrega un conjunto completo de servicios para la construcción de sistemas complejos de gerenciamiento de bases de datos. Dentro de esos servicios, podemos citar el almacenamiento de datos, gerenciamiento de concurrencias, transacciones y gerenciamiento de procesos.
Dentro de Caché, los datos pueden ser modelados y almacenados como tablas, objetos o arreglos multidimensionales (jerarquías). Diferentes modelos pueden acceder a datos de forma ininterrumpida -sin la necesidad de mapeamiento de desempeño entre modelos. Soporte embutido a objetos de datos dinámicos (como XML y JSON) posibilitan fácil interoperabilidad y desarrollo rápido de aplicaciones web. (INTERSYSTEMS CACHÉ, 2019)
Figura 1 Arquitectura de la base de datos InterSystems Caché, por (INTERSYSTEMS CACHÉ, 2019)
Object Script es un lenguaje de programación de objetos proyectado para desarrollar rápidamente aplicaciones de negocios complejos. (INTERSYSTEMS CACHÉ, 2019)
Según la documentación, COS es un lenguaje de programación completo que ofrece recursos para manipulación de cadenas (strings), entradas y salidas, soporte para matrices espaciales y multidimensionales, soporte para SQL embarcados, comandos de direccionamiento de flujo de control dentro de un aplicativo y soporte nativo para objetos, incluyendo métodos, propiedades y polimorfismo.
Para sistemas complejos basados y proyectados con orientación a objetos, es común depararse con problemas de determinados contextos. Para la resolución de esos problemas, proyectistas de software se apoyan en la utilización de patrones de proyecto (Design Patterns).
Design Patterns (Patrones de proyecto) son patrones de modelado de software representados por principios de modelado de estructuras y códigos fuente que fueron probados diversas veces en diversos escenarios y obtuvieran éxito. (GUERRA, 2015)
Para Buschman (1996), un patrón describe una solución para un problema que ocurre con frecuencia durante el desarrollo de software, pudiendo ser considerado como un par “problema/solución”.
Según Gamma (1995), en general un patrón tiene cuatro elementos esenciales:
El nombre del patrón, que es una referencia para describir un problema de proyecto, sus soluciones y consecuencias.
El problema, que describe en que situación aplicar el patrón.
La solución, que describe los elementos que componen el patrón de proyecto, sus relacionamientos, sus responsabilidades y colaboraciones.
Las consecuencias, que son los resultados y análisis de las ventajas y desventajas de la aplicación patrón.
Figura 2 El espacio de los patrones de proyecto (Gamma, 1995)
Gamma (1995). Catalogó 23 patrones de diseño, conforme presentado en la figura 2, de forma de organizarlos, facilitar y aprender los patrones con mayor rapidez, así como direccionar esfuerzos en el descubrimiento de nuevos. Los patrones fueron clasificados a partir de dos criterios:
Finalidad, reflectando lo que hace el patrón. Los patrones pueden tener finalidad de creación, estructural o comportamental.
Los patrones estructurales lidian con la composición de clases u objetos. Los patrones comportamentales caracterizan las formas por las cuales clases u objetos interactúan y distribuyen las responsabilidades. (GAMMA y otros, 2015).
Alcance, especificando si el patrón se aplica primariamente a clases o a objetos.
Los patrones para clases lidian con los relacionamientos entre clases y subclases. Esos relacionamientos son establecidos a través del mecanismo de herencia, así ellos son estáticos -fijados en tiempo de compilación. Los patrones para objetos lidian con el relacionamiento entre objetos que pueden ser alterados en tiempo de ejecución y son más dinámicos. Casi todos utilizan la herencia en cierta medida. (GAMMA y otros, 2015).
El presente artículo tiene como objetivo implementar patrones de proyecto en el lenguaje COS y verificar si la tecnología soporta implementaciones basadas en patrones para resolución de problemas.
Con la búsqueda, será posible identificar posibles limitaciones y fuerzas de lenguaje para las implementaciones de proyectos de software complejo. Para tal, serán utilizados algunos patrones con complejidad de implementación más baja clasificados con la finalidad de creación, estructural y de alcance de clases y de objetos.
Los patrones utilizados están descritos abajo, así como una breve descripción según Gamma (1995):
Factory Method, define una interface para crear un objeto, pero deja que las subclases decidan cual será instanciada. El Factory Method permite a una clase postergar (aplazar) la instanciación de las subclases.
Builder, separa la construcción de un objeto complejo de su representación, de modo que el mismo proceso de construcción pueda crear diferentes representaciones.
Prototype, especifica los tipos de objetos a ser creados usando una instancia prototípica y crea nuevos objetos copiando ese prototipo.
Singleton, garantiza que una clase tenga solamente una instancia y proporciona un punto global para su acceso.
Facade, proporciona una interface unificada para un conjunto de interfaces en un subsistema. Facade define una interface de nivel mas alto que vuelve el subsistema más fácil de usar.
Desarrollo
La práctica utilizó la versión 2018.1.3 de Caché, implementando y evaluando los patrones de proyectos en los siguientes tópicos utilizando el lenguaje de programación COS.
Factory Method
Las clases abajo ejemplifican la utilización del patrón Factory Method para tratar un problema de negocio relacionado en que es necesario especificar el tipo de ejecución que es lanzada. Fueron definidos tres tipos de excepciones: de negocio, inesperada y no tratada.
Figura 3 Implementación de la clase excecao.ExcecaoFactory (por el autor)
La figura 3 demuestra la implementación de la clase excecao.ExcecaoFactory, que efectivamente implementa el patrón. El método GetObjetoExcecao(), creado en la línea 6, recibe la instancia de un objeto de tipo AbstractException y con base en las implementaciones de los métodos auxiliares, decide cual objeto debe ser retornado de acuerdo con el tipo.
Las figuras 4, 5 y 6, representan la implementación básica de las clases para cada tipo de excepción utilizada en el ejemplo.
Figura 4 Implementación de la clase excecao.ExcecaoNegocio (por el autor)
Figura 5 Implementación de la clase excecao.ExcecaoInesperada (por el autor)
Figura 6 Implementación de la clase excecao.ExcecaoNaoTratada (por el autor)
Builder
Para la implementación del patrón Builder, fue utilizada la entidad Pessoa Jurídica como base. Esa entidad, de forma simple, es compuesta por las propiedades Razão Social, Nome Fantasia y Cnpj. La implementación de la clase puede ser analizada en la figura 7 abajo:
Figura 7 Implementación de la clase builder.PessoaJuridica (por el autor)
La implementación del patrón Builder, demostrado en la figura 8, define una propiedad de clase de tipo builder.PessoaJuridica, que es utilizada para almacenar las informaciones que son definidas para el objeto y para la clase utilizada en el Builder. Los métodos setters, creados en las líneas 21, 28 y 35, reciben un valor por parámetro y hacen el set en la propiedad de la clase y luego retornan la instancia del objeto. Ese retorno es necesario para que, en la utilización de la clase, demostrado en la figura 9, sea posible hacer llamadas a los métodos setter de forma funcional y secuencial, siendo posible en una única línea definir el objeto que es requerido al patrón de forma simple.
Figura 8 Implementación de la clase builder.PessoaJuridicaBuilder (por el autor)
Figura 9 Ejemplo de utilización del patrón builder (por el autor)
Protoype
La clase prototype.CasaPrototype, presentada en la figura 10 abajo, implementa el patrón prototype creando el método abstracto getPrototipe() en la línea 6:
Figura 10 Implementación de la clase prototype.CasaPrototype (pelo autor)
Las figuras 11 y 12 presentan la implementación de las clases prototype.SimplesPrototype e prototype.SobradoPrototype, ambas heredando la clase prototype.CasaPrototype. En las dos clases el método getPrototype() es implementado retornando una nueva instancia de si mismo, una copia del objeto prototipado.
Figura 11 Implementación de la clase prototype.SimplesPrototype
Figura 12 Implementación de la clase prototype.SobradoProtoype (por el autor)
Singleton
El patrón Singleton permite la creación de objetos únicos y con apenas una instancia, ofreciendo un punto de acceso global dentro de la aplicación. Con eso, el patrón tiene como definición garantizar que una clase tenga apenas una instancia de sí y que exista solamente un punto global de acceso, gerenciando la propia instancia y evitando que cualquier clase cree una instancia de ella. De esta forma, ninguna otra clase puede instanciarla además de ella misma.
Como ejemplo, desarrollando en el lenguaje Java y utilizando el modificador synchronized garantiza que el patrón sea implementado, impidiendo que dos instancias de la clase sean creadas. En COS, ese modificador no existe.
Para acceso global utilizando COS, puede accederse directamente a las globales de la base, pero no es posible guardar instancias de objetos en globales.
Por presentar las limitaciones mencionadas arriba, no fue posible implementar el patrón Singleton en el lenguaje COS.
Facade
El patrón Facade tiene la intención de simplificar la utilización de subsistemas complejos implementando una interface única y razonable.
Figura 13 Implementación de la clase facade.SistemasFacade (por el autor)
En la imagen 13, la clase facade.SistemasFacade implementa el patrón creando una interfaz única para la utilización de sistemas de audio e imagen. El constructor instancia los objetos de las dos clases y ejecuta los métodos para definir las configuraciones necesarias. Para las clases que la utilizan, están expuestos los métodos para reproducción de video y audio, unificados y simplificados en una única clase.
Análisis de los resultados
Los resultados encontrados con las búsquedas se mostraron satisfactorios. Algunas dificultades fueron encontradas por falta de algunos modificadores para definiciones de alcance global, como interfaces. Además de los modificadores, técnicas como la sobrecarga de métodos no fueron posibles de ser utilizados por las limitaciones del lenguaje. Sin embargo, el desarrollo en el lenguaje COS es simple, lo que vuelve el trabajo y organización de las clases productiva.
Conclusiones
Es posible afirmar que, para la mayoría de los patrones catalogados, el lenguaje COS ofrece los recursos necesarios para la implementación orientada a objetos.