開発者の皆さん、こんにちは。
(2024/5/30:6月の日時、ウェビナー内容を更新しました)
InterSystems IRIS、InterSystems IRIS for Healthの新バージョン2024.1がリリースされました。
様々な機能の追加や実験的機能としての追加が行われましたが、その中から以下3種類の内容についてウェビナーを開催します!📣
✅4月23日(火)13時半~14時:IRIS 2024.1の管理用Webサーバ(PWS)廃止に備えて
YouTube公開しました👉https://youtu.be/bVwWZt1oNws?list=PLzSN_5VbNaxCeC_ibw2l-xneMCwCVf-Or
✅5月30日(木)13時半~14時:ベクトル検索機能のご紹介
YouTube公開しました👉https://youtu.be/v0G7K2et_Yk?list=PLzSN_5VbNaxB39_H2QMMEG_EsNEFc0ASz
✅6月25日(火)13時半~14時:FHIR新機能のご紹介~2024.1~
オンデマンド配信はこちら👉https://event.on24.com/wcc/r/4597704/ADA161B6446E6BA01623C875CF596FD0
(資料PDFもオンデマンド配信画面よりダウンロードいただけます)
ご参考:リリース案内記事
ウェビナーでご案内する機能以外にも実験的機能も含め多くの機能が追加されていますので、以下簡単に概要をご紹介します。
現在日本語ドキュメントは鋭意翻訳中のため、仕上がるまでの間は英語ドキュメント(IRISリリースノート/IRIS for Healthリリースノート)をご参照ください。
管理系
✔ マルチボリュームデータベース: スケーラビリティとストレージ管理の強化
下図はデータベース新規作成の画面ですが、設定項目に [New Volume Threshold Size] の項目が追加されました。
(ドキュメント:Configuring a Multivolume Database)
この値を 0 より大きい値に設定した場合、DATが指定サイズを超えると指定フォルダ内に IRIS-000x.VOL というデータベースを作ります。(拡張ファイルとして指定サイズで区切ったデータベースファイルが作成できるようになりました)
.png)
✔ ファスト・オンライン・バックアップ(実験的機能): バックアッププロセスの合理化
以前より、外部バックアップ(Backup.GeneralクラスのExternalFreeze()/ExternalThaw()を利用する方法)と、オンラインバックアップを提供していますが、このリリースの実験的機能追加は「オンラインバックアップ」に対しての高速化とクラスAPIの用意です。(Bakcup.Onlineクラスが追加されました)
現段階では、Backup.Onlineクラスを利用したバックアップに対しての高速化が行われています。管理ポータルメニューからの実行やDBACKルーチンを利用した実行には影響がありません。お試しいただく場合は、Early Access Program(EAP)へのお申込みをどうそよろしくお願いします。
✔ 複数のスーパーサーバポート: ネットワーク構成の柔軟性を提供
お馴染みの1972番以外のポート番号をスーパーサーバポートとして追加できるようになりました。(JDBC/ODBC経由のアクセスがある時は別ポートでアクセス、など柔軟に対応できるようになりました)
設定は、管理ポータル > [システム管理] > [セキュリティ] > [Superservers] から行えます。
(ドキュメント:Managing SuperServers)
52774のポートを追加した例:
.png)
import java.sql.*;
import java.util.Scanner;
import com.intersystems.jdbc.*;
public class JDBCTest {
public static void main(String[] args) throws Exception {
String url = "jdbc:IRIS://localhost:52774/USER";
Class.forName("com.intersystems.jdbc.IRISDriver").newInstance();
IRISDataSource ds = new IRISDataSource();
ds.setURL(url);
ds.setUser("SUPERUSER");
ds.setPassword("SYS");
Connection connection = ds.getConnection();
String query = "SELECT ID,Name,Email FROM Test.Person";
PreparedStatement statement = connection.prepareStatement(query);
ResultSet resultSet = statement.executeQuery();
System.out.println("\n*** SELECTの結果 ****");
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + " - " + resultSet.getString(2)+ " - " + resultSet.getString(3));
}
resultSet.close();
statement.close();
connection.close();
}
}
SQL
✔ JSON_TABLE関数、With句のサポート追加
(ドキュメント:JSON_TABLE (SQL)/WITH (SQL))
JSON_TABLE()関数では、%Net.GetJson()を利用して外部サイトからの結果をそのまま使用することもできます。
例)zipcloudのAPIを使用した例です。
〒0790177で取得できる結果のJSONを使用しています(https://zipcloud.ibsnet.co.jp/api/search?zipcode=0790177)
メモ:httpsを使用するため、%Net.GetJson()の第2パラメータに予め管理ポータルで設定したSSL/TLS構成名を指定しています。
設定は、 [システム管理] > [セキュリティ] > [SSL/TLS構成] メニューを開き、「構成名」に任意名を設定し、「保存」ボタンをクリックします(そのほかの構成パラメータは、デフォルト値で作成します)。
例では、”test” の名称で作成した構成名を指定しています。({"SSLConfigration":"test"})
SELECT address1,address2,address3,kana1,kana2,kana3,zipcode
FROM JSON_TABLE(%Net.GetJson('https://zipcloud.ibsnet.co.jp/api/search?zipcode=0790177','{"SSLConfiguration":"test"}')
,
'$.content.results'
COLUMNS ( address1 VARCHAR(100) PATH '$.address1',
address2 VARCHAR(100) PATH '$.address2',
address3 VARCHAR(100) PATH '$.address3',
kana1 VARCHAR(100) PATH '$.kana1',
kana2 VARCHAR(100) PATH '$.kana2',
kana3 VARCHAR(100) PATH '$.kana3',
zipcode VARCHAR(10) PATH '$.zipcode')
) as jt
ORDER BY address3
《結果》
.png)
✔ 安全なクエリ中止(CANCEL QUERY)
このリリースでInterSystems SQL に実行中のステートメントを中止し、実行により使用されていたメモリや一時領域などを安全に開放する新しいコマンド CANCEL QUERY が追加されました。
✔ クエリパフォーマンスを向上させる機能強化
- グローバルイテレータでは、ObjectScriptを使用せずに、インデックスおよびデータマップを参照する処理の多くをカーネル内部モジュールで実行します。
- Adaptive Parallel Execution (APE; アダプティブ並列実行) フレームワークでカラムナーストレージを含むクエリに初めて対応しました。APEでは個別の並列サブクエリをプリペアして実行するのではなく、メインクエリとして同じクエリキャッシュクラスを並列ワーカーコードとして生成します。
Embedded Python
✔ Pythonランタイムが選択可能に(Windowsを除く)
Linuxベースの環境限定となりますが、管理ポータルでPythonランタイムを指定できるようになりました。(ドキュメント:Flexible Python Runtime Feature)
管理ポータル > [システム管理] > [構成] > [追加の設定] > [メモリ詳細] > [PythonRuntimeLibrary]
PythonRuntimeLibrary構成設定詳細(英語)
✔ BPLエディタ内でPythonの記述が可能に
Interoprabilityで使用するビジネス・プロセスのエディタの1つであるBPLエディタ内のCodeアクティビティにEmbedded Pythonが記述できるようになりました。
.png)
✔ Python WSGI標準準拠のWebアプリが作成可能に(実験的機能)
IRISのインスタンス内部でEmbedded Pythonを使用して flask や Django などの WSGI 準拠フレームワークを実行することができるようになりました。
(ドキュメント:Creating WSGI Applications)
WSGIのWebアプリの実行を指定するために、管理ポータルの以下メニューや用意されました。
管理ポータル > [システム管理] > [セキュリティ] > [アプリケーション] > [ウェブ・アプリケーション]
.png)
図の設定では、http://Webサーバ/flaskapp が指定されるとFlaskで記述している flasktest アプリケーションが呼び出されます。
メモ:例では、パスを通過した後に付与されるアプリケーション・ロールを指定しています。本来であれば適切なロールを用意し付与しますが簡易的に試すためフルアクセスできる%Allを付与しています)
この例のWebサーバ(localhost:8080)に対してパスを指定すると以下の画面が表示されます。画面でID番号を入力すると、指定IDを条件にIRISにあるテーブルに対してSELECT文が実行されレコードの中身が表示されます。
.png)
以下ご参考(コード例):
from flask import Flask, render_template, request
import sys
sys.path+=['/usr/irissys/mgr/python','/usr/irissys/lib/python']
def getOnePerson(id):
import iris
sql="select ID,Name,Email,TOCHAR(DOB,'YYYY-MM-DD') from Test.Person WHERE ID=?"
stmt=iris.sql.prepare(sql)
rset=stmt.execute(id)
reco=rset.__next__()
return reco
app = Flask(__name__)
@app.route('/',methods=['GET'])
def person() -> str:
return render_template("start.html",post="")
@app.route('/', methods=['POST'])
def personsearch():
pid=request.form['pid']
post=getOnePerson(pid)
return render_template("start.html",post=post)
if __name__ == '__main__':
app.run(debug=True,host="0.0.0.0",port=8090)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-9ndCyUaIbzAi2FUVXJi0CjmCapSmO7SnpJef0486qhLnuZ2cdeRhO02iuK6FUUVM" crossorigin="anonymous">
<title>IRISのデータ参照する</title>
</head>
<body>
<nav class="navbar navbar-light" style="background-color: #e3f2fd;"">
<a class="navbar-brand pl-3" href="/flasktest/" style="font-size: 2rem;">Person検索!</a>
</nav>
<h2>情報入力</h2>
<div class="form">
<form action="/flasktest/" method='POST'>
<label for="title">PersonのIDを入力してください:
</label>
<input type="text" name="pid" value={{ post[0] }}>
<input type="submit" value="Person検索">
</form>
{% if post != "" %}
<div>
<table class="table table-light table-striped">
<tr><th>名前</th><td>{{post[1]}}</td></tr>
<tr><th>Email</th><td>{{post[2]}}</td></tr>
<tr><th>誕生日</th><td>{{post[3]}}</td></tr>
</table>
</div>
{% endif %}
</div>
</body>
</html>
 Open Exchange
Open Exchange.png)

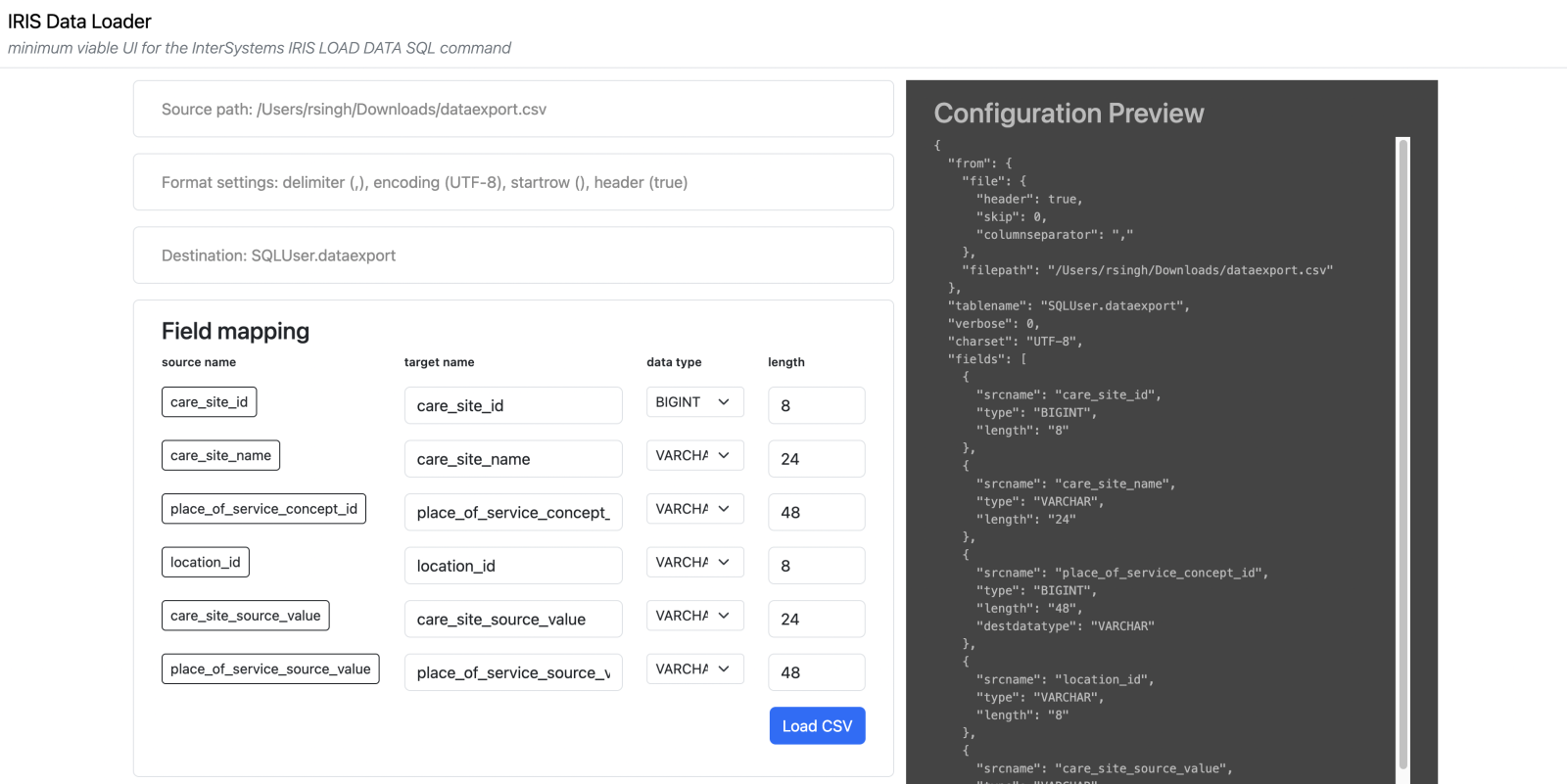
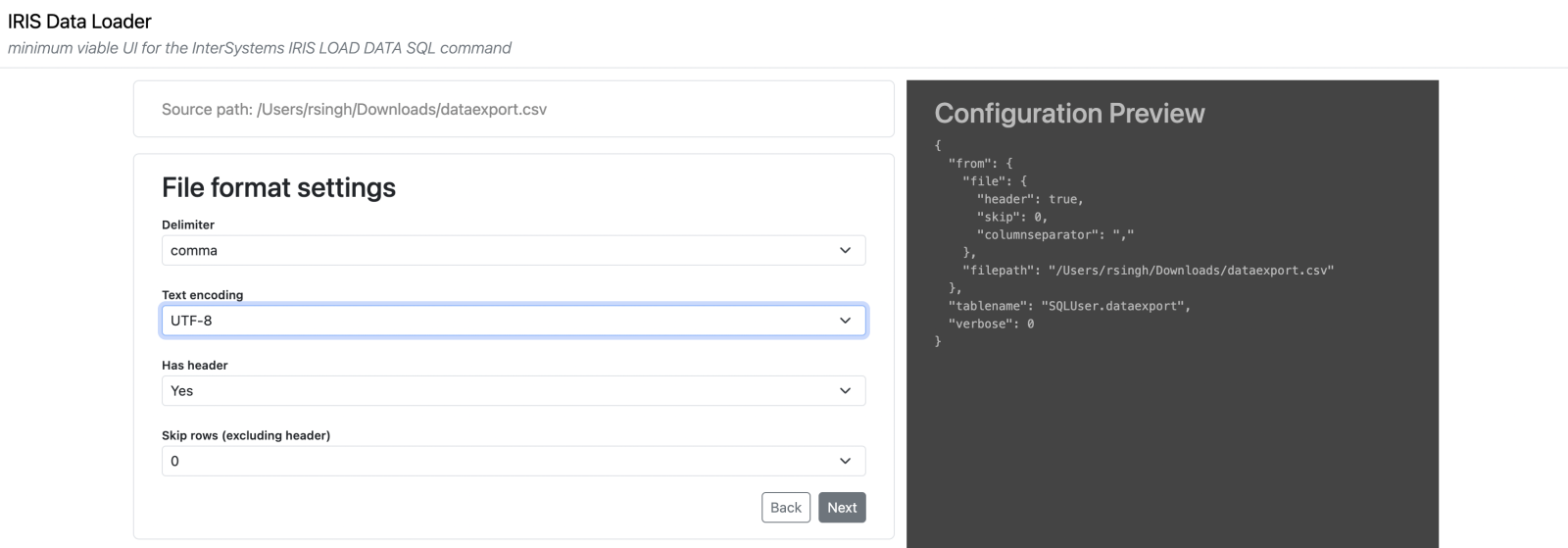 Step 5: Define a destination table name, with the schema name as well
Step 5: Define a destination table name, with the schema name as well

.png) Many Developer Community members have already tested and used InterSystems' new service, InterSystems IRIS Cloud SQL. You must have bright ideas related to this service, and we are waiting for them in the new
Many Developer Community members have already tested and used InterSystems' new service, InterSystems IRIS Cloud SQL. You must have bright ideas related to this service, and we are waiting for them in the new .png) If you are on the lookout for an interesting idea to implement or just want inspiration to create a new application and publish it on the Open Exchange, you can now get to the Ideas Portal directly from the "Applications" item of the Open Exchange main menu.
If you are on the lookout for an interesting idea to implement or just want inspiration to create a new application and publish it on the Open Exchange, you can now get to the Ideas Portal directly from the "Applications" item of the Open Exchange main menu..png)
.png) Since the launch of the Ideas Portal, 54 ideas related to the InterSystems products and resources for developers have already been implemented.
Since the launch of the Ideas Portal, 54 ideas related to the InterSystems products and resources for developers have already been implemented. (*)
(*)