Dify ahora admite IRIS como almacén vectorial — Guía de configuración
Por qué esta integración es importante
InterSystems sigue impulsando las capacidades de IA de forma nativa en IRIS — búsqueda vectorial, compatibilidad con MCP y capacidades de IA agéntica. Esa hoja de ruta es importante y no hay ninguna intención de dar un paso atrás en ella.
Pero el panorama de la IA también está evolucionando de una manera que hace que la integración con el ecosistema sea cada vez más esencial. Herramientas como Dify — una plataforma de orquestación de LLM de código abierto y lista para producción — se han convertido en una parte importante de los stacks de IA empresariales. En Japón en particular, la adopción de Dify ya no es solo cosa de startups o aficionados; ha llegado a grandes empresas, cuyos empleados la utilizan como base de sus flujos de trabajo internos de IA. Encontraros con desarrolladores y equipos allí donde ya están es tan valioso como crear nuevas capacidades de forma aislada.
Esa es la motivación detrás de esta integración: IRIS se encarga de lo que mejor sabe hacer — datos fiables, consultables y accesibles mediante SQL con lógica de procesamiento integrada — mientras que Dify se ocupa de la orquestación de LLM, los pipelines de RAG y los flujos de trabajo agénticos. Juntas, forman una pila en la que los usuarios de IRIS no tenéis que elegir entre vuestra infraestructura de datos y las herramientas de IA que están ganando impulso a vuestro alrededor.
Esta integración se aportó a Dify como una pull request de código abierto y se integró en Dify v1.11.2 (#29480). Desde entonces se han integrado varias correcciones adicionales, que se detallan a continuación. En este artículo os explicamos la configuración paso a paso.
En primer lugar, me gustaría dar las gracias a @Megumi Kakechi por animarme a publicar esto en la Comunidad de Desarrolladores en inglés — sin ese impulso, habría sido un artículo solo en japonés. También quiero expresar mi agradecimiento a @Tomohiro Iwamoto y @Mihoko Iijima, que se tomaron el tiempo de probar esta integración de primera mano y aportaron comentarios muy valiosos que ayudaron a dar forma a las correcciones incluidas en versiones posteriores.
Contexto OSS: Si tenéis curiosidad por el proceso de contribución en sí, escribí sobre ello en Zenn: «¿No debería conocerse más esta base de datos?» — Cómo llegué a contribuir a un proyecto OSS (en japonés)
Requisitos previos
| Herramienta | Notas |
|---|---|
| Docker / Docker Compose | Cualquier versión reciente |
| Git | Para clonar el repositorio de Dify |
Configuración
1. Clonad el repositorio de Dify
> git clone https://github.com/langgenius/dify.git
> cd dify/docker2. Preparad el archivo de entorno
> cp .env.example .env3. Activad IRIS como almacén vectorial
Abrid el archivo .env y modificad una línea:
# Before (default)
VECTOR_STORE=weaviate
# After
VECTOR_STORE=irisEso es lo mínimo. Los valores predeterminados de conexión de IRIS están preconfigurados para uso local. Para conectaros a una instancia existente de IRIS o personalizar la configuración, los parámetros relevantes son:
| Parámetro | Predeterminado | Descripción |
|---|---|---|
IRIS_HOST |
iris |
Nombre del servicio del contenedor |
IRIS_SUPER_SERVER_PORT |
1972 |
Puerto de SuperServer |
IRIS_WEB_SERVER_PORT |
52773 |
Puerto del Portal de Gestión |
IRIS_USER |
_SYSTEM |
Nombre de usuario para iniciar sesión |
IRIS_PASSWORD |
Dify@1234 |
Se establece automáticamente en el primer inicio |
IRIS_DATABASE |
USER |
Espacio de nombres objetivo |
IRIS_SCHEMA |
dify |
Esquema SQL para las tablas de Dify |
IRIS_TEXT_INDEX |
true |
Habilitar índice de texto completo |
IRIS_TEXT_INDEX_LANGUAGE |
en |
Idioma para la indexación de texto |
IRIS_MIN_CONNECTION |
1 |
Mínimo del pool de conexiones |
IRIS_MAX_CONNECTION |
3 |
Máximo del pool de conexiones |
IRIS_TIMEZONE |
UTC |
Configuración de zona horaria |
4.Iniciad los contenedores
> docker compose up -d5. Comprobad que todos los contenedores están en funcionamiento
> docker compose psBuscad el contenedor de iris con un STATUS de Up:
> docker % docker compose ps --format "table {{.Name}}\t{{.Service}}\t{{.Status}}"
NAME SERVICE STATUS
docker-api-1 api Up
docker-db_postgres-1 db_postgres Up (healthy)
docker-nginx-1 nginx Up
docker-plugin_daemon-1 plugin_daemon Up
docker-redis-1 redis Up (healthy)
docker-sandbox-1 sandbox Up (healthy)
docker-ssrf_proxy-1 ssrf_proxy Up
docker-web-1 web Up
docker-worker-1 worker Up
docker-worker_beat-1 worker_beat Up
iris iris Up <-- this oneAcceded a Dify
Acceded a http://localhost/ en vuestro navegador. Al iniciar por primera vez, se os pedirá crear una cuenta de administrador.
Verificad que IRIS está almacenando vuestros vectores
Paso 1 — Cread una Base de Conocimiento
- Iniciad sesión en Dify
- Id a Knowledge → Create Knowledge
- Subid un archivo de texto o PDF
- En el Paso 2, bajo Index Method, seleccionad "High Quality" (recomendado)
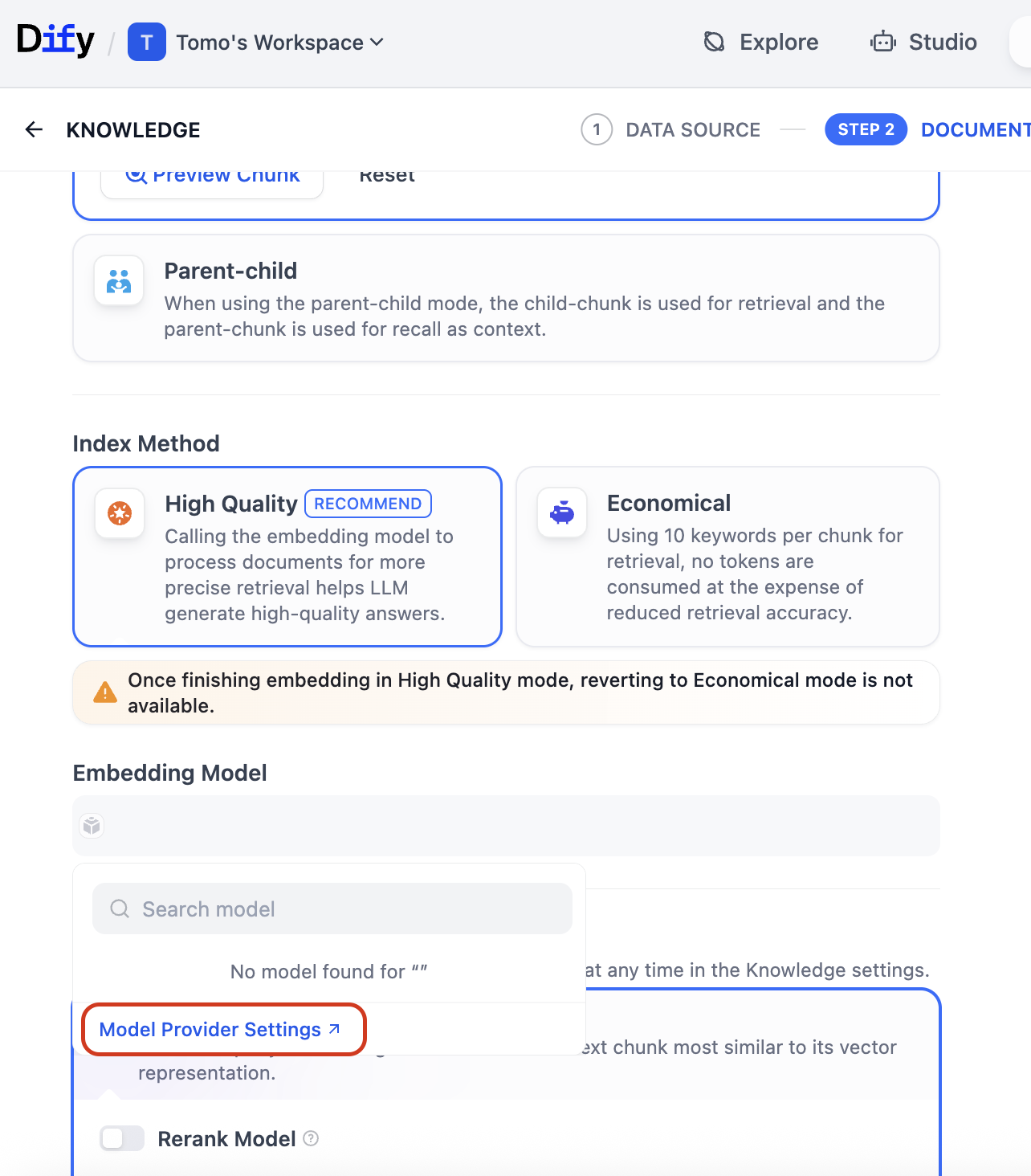
Si aún no se ha configurado ningún modelo de embedding, el desplegable mostrará "No model found." Haced clic en "Model Provider Settings" en la parte inferior del desplegable para continuar.
Paso 2 — Configurad un Proveedor de Modelos (OpenAI)
The Model Provider screen lists available providers. Find OpenAI and click Install.
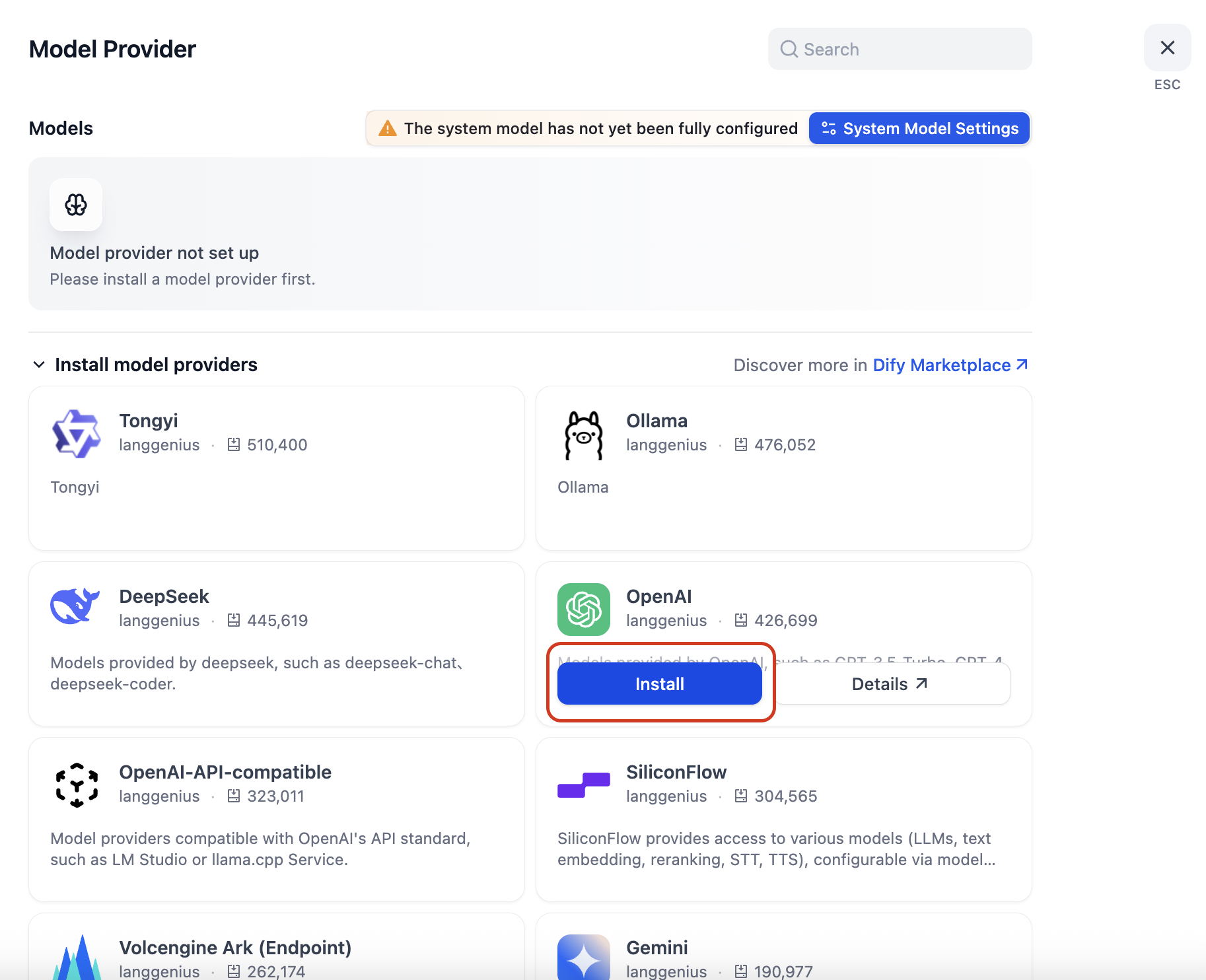
Nota sobre el coste: OpenAI requiere una clave API independiente de la suscripción a ChatGPT Plus — necesitaréis añadir créditos a vuestra cuenta de API de OpenAI. Sin embargo, los costes de embedding son muy bajos; con unos pocos dólares será suficiente. Si preferís una alternativa gratuita, también se admiten modelos locales mediante LM Studio o Ollama (compatibles con la API de OpenAI).
Tras la instalación, OpenAI aparecerá bajo "To be configured". Haced clic en Setup.
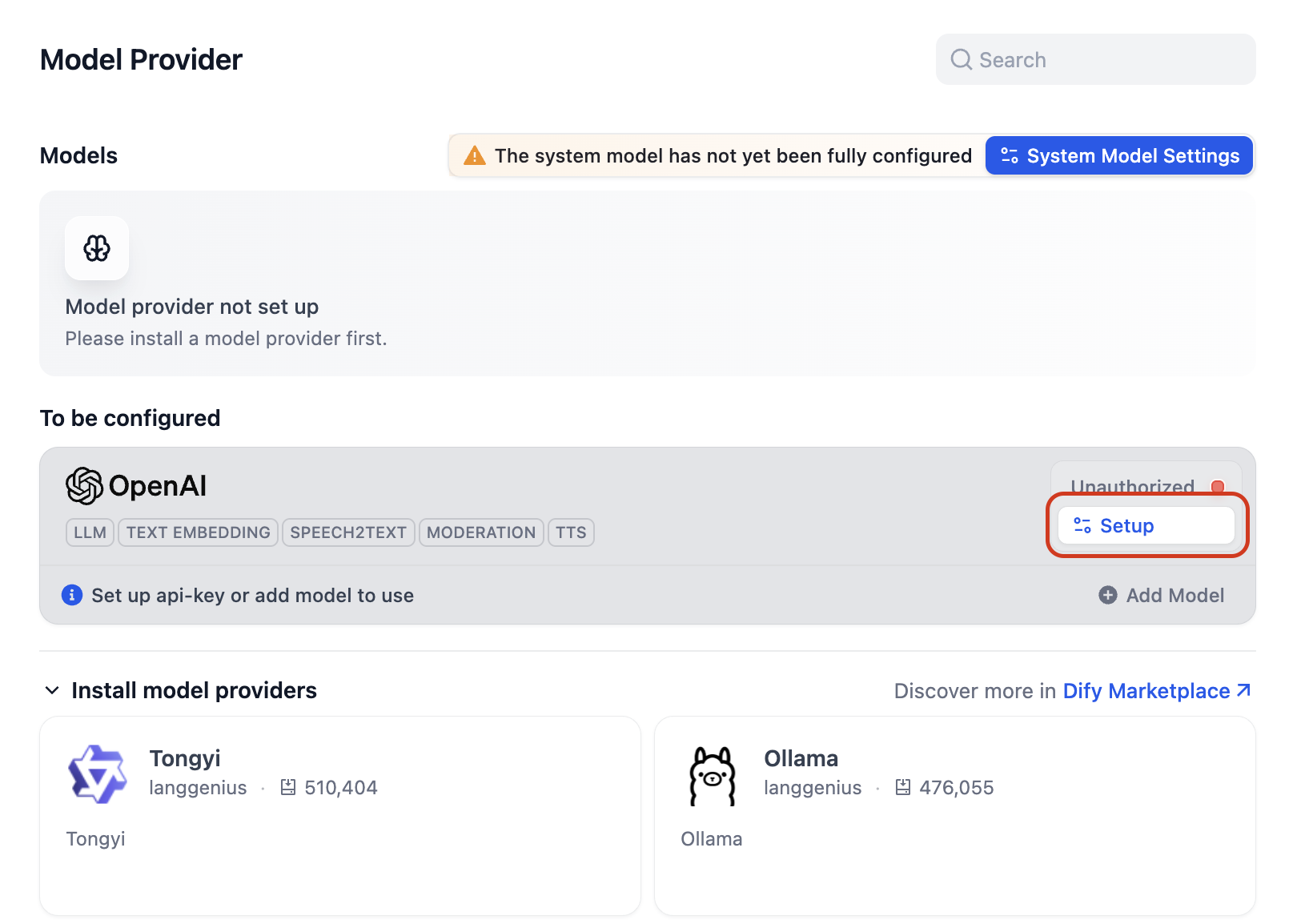
Se abrirá el cuadro de diálogo de Configuración de Autorización de la Clave API. Si aún no tenéis una clave API, haced clic en "Get your API Key from OpenAI" para abrir directamente la página de claves API de OpenAI.
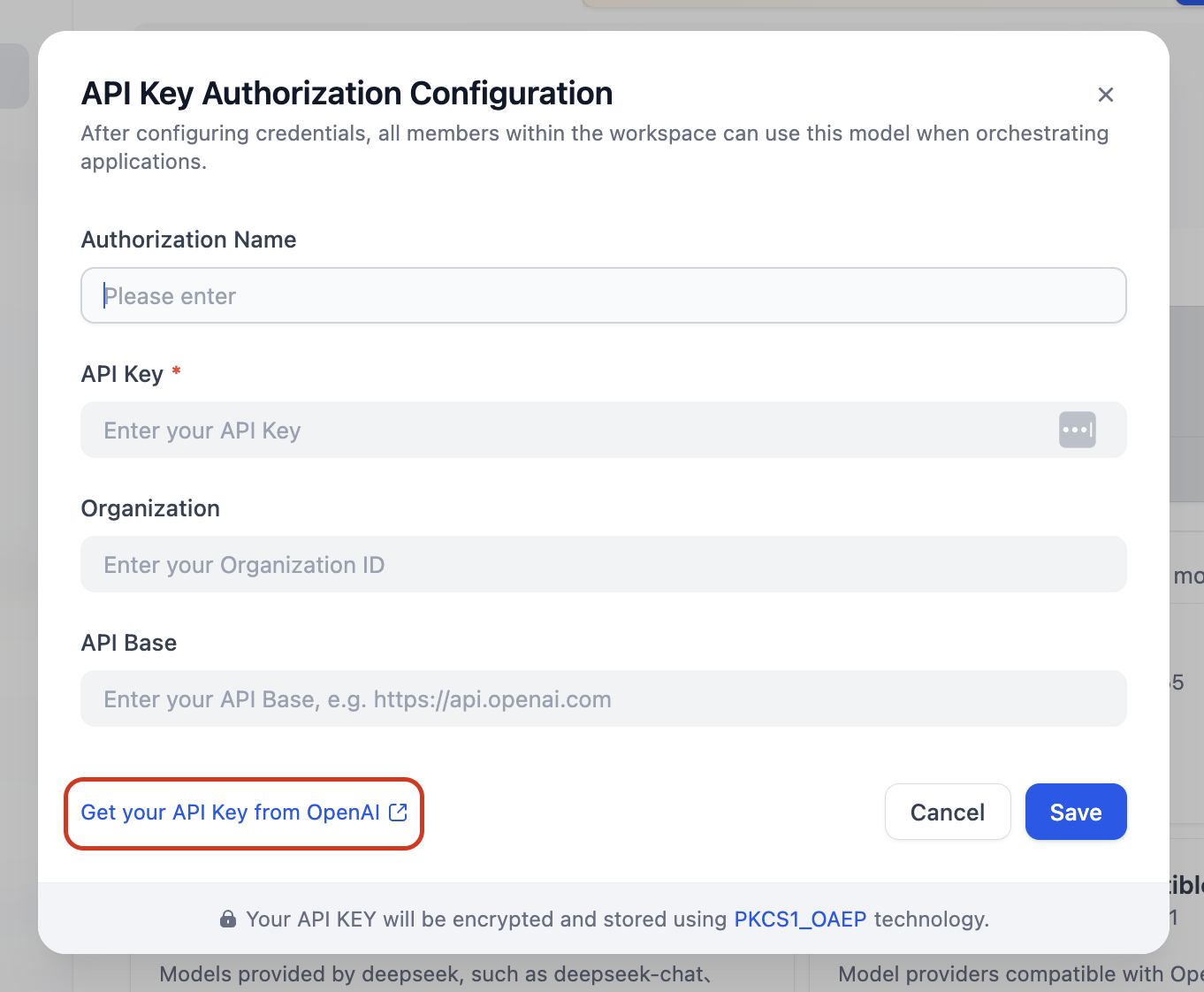
Introducid un nombre (por ejemplo, dify), pegad vuestra clave API y, a continuación, haced clic en Save.
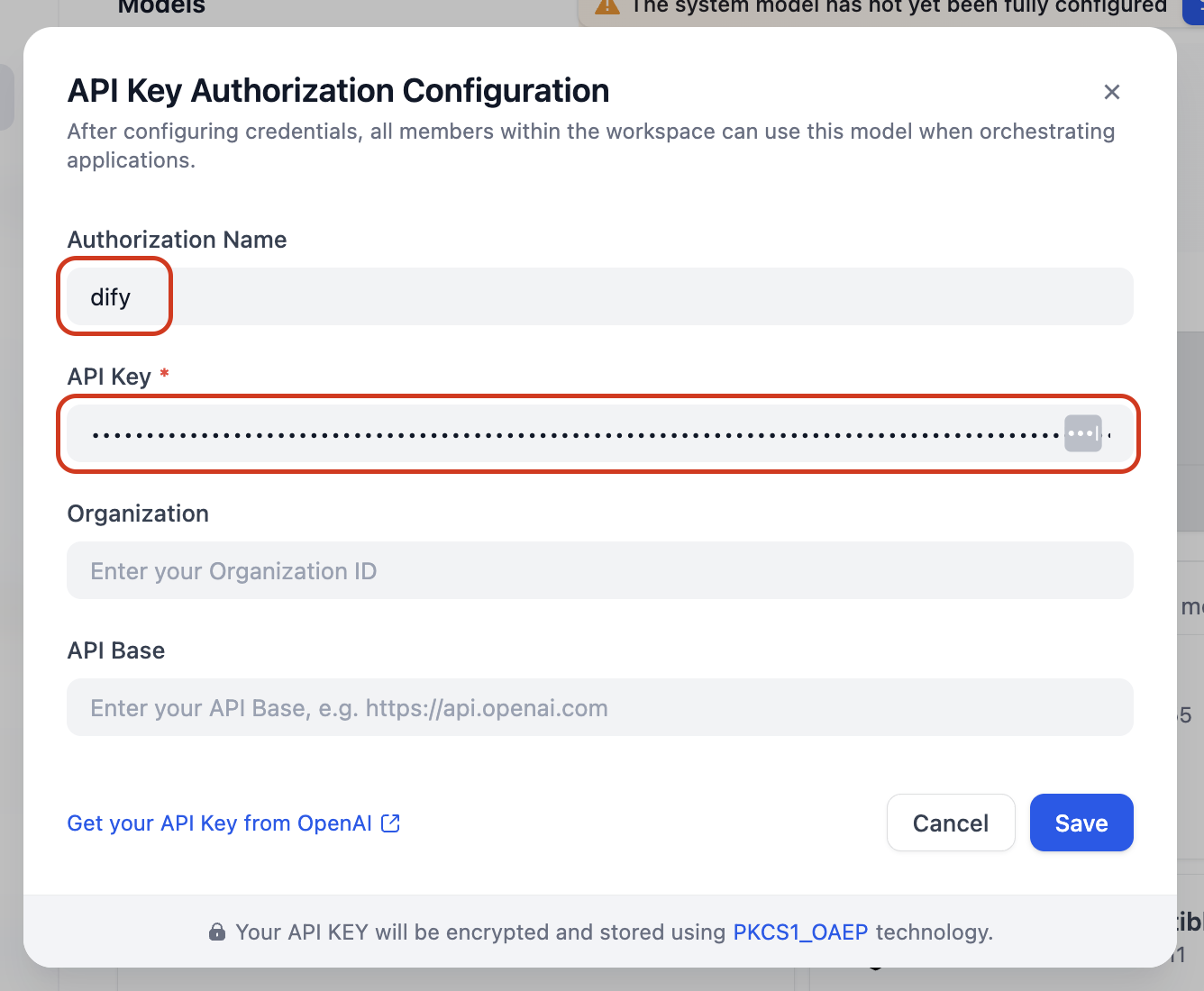
Paso 3 — Seleccionad el Modelo de Embedding
Volved a la pantalla de creación de Knowledge. El desplegable de Embedding Model ahora muestra los modelos disponibles de OpenAI. Seleccionad text-embedding-3-small que ofrece un excelente equilibrio entre coste y calidad de recuperación para la mayoría de los casos.
Haced clic en Save & Process. Cuando aparezca una marca verde junto a vuestro documento, el embedding estará completo — los fragmentos de vuestro documento ya están almacenados como vectores en IRIS.
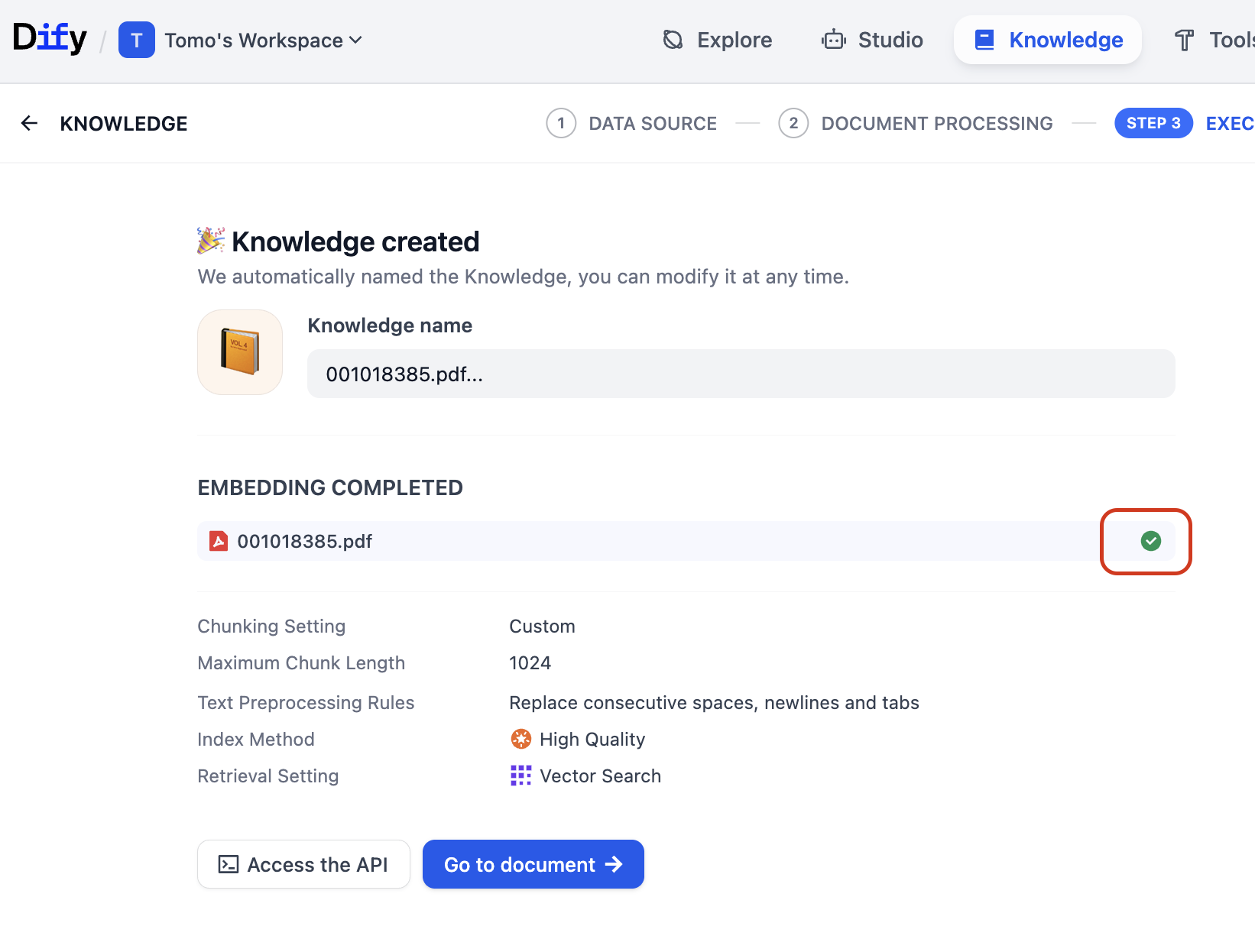
Paso 4 — Inspeccionad los datos a través del Portal de Gestión
Aquí es donde los usuarios de IRIS tenéis una ventaja distintiva. Abrid el Portal de Gestión:
http://localhost:52773/csp/sys/UtilHome.csp?$NAMESPACE=USER| Campo | Valor |
|---|---|
| Nombre de usuario | _SYSTEM |
| Contraseña | Dify@1234 |
Id a System Explorer → SQL, estableced el filtro de esquema en dify, y aparecerán las tablas que Dify creó. Abrid una de ellas y veréis los fragmentos de vuestro documento —incluyendo los embeddings vectoriales en crudo— almacenados exactamente como esperaríais en cualquier tabla de IRIS.
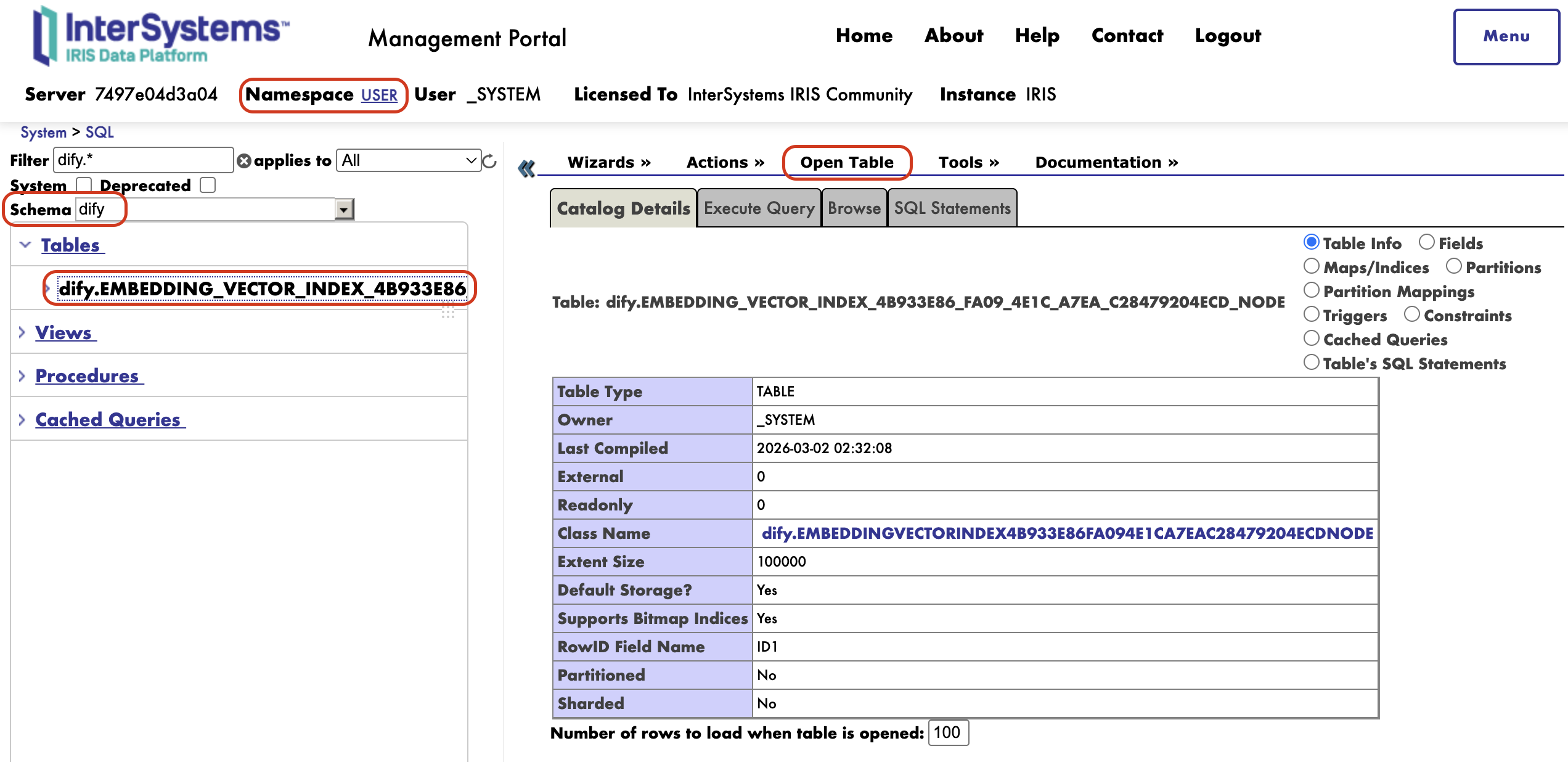
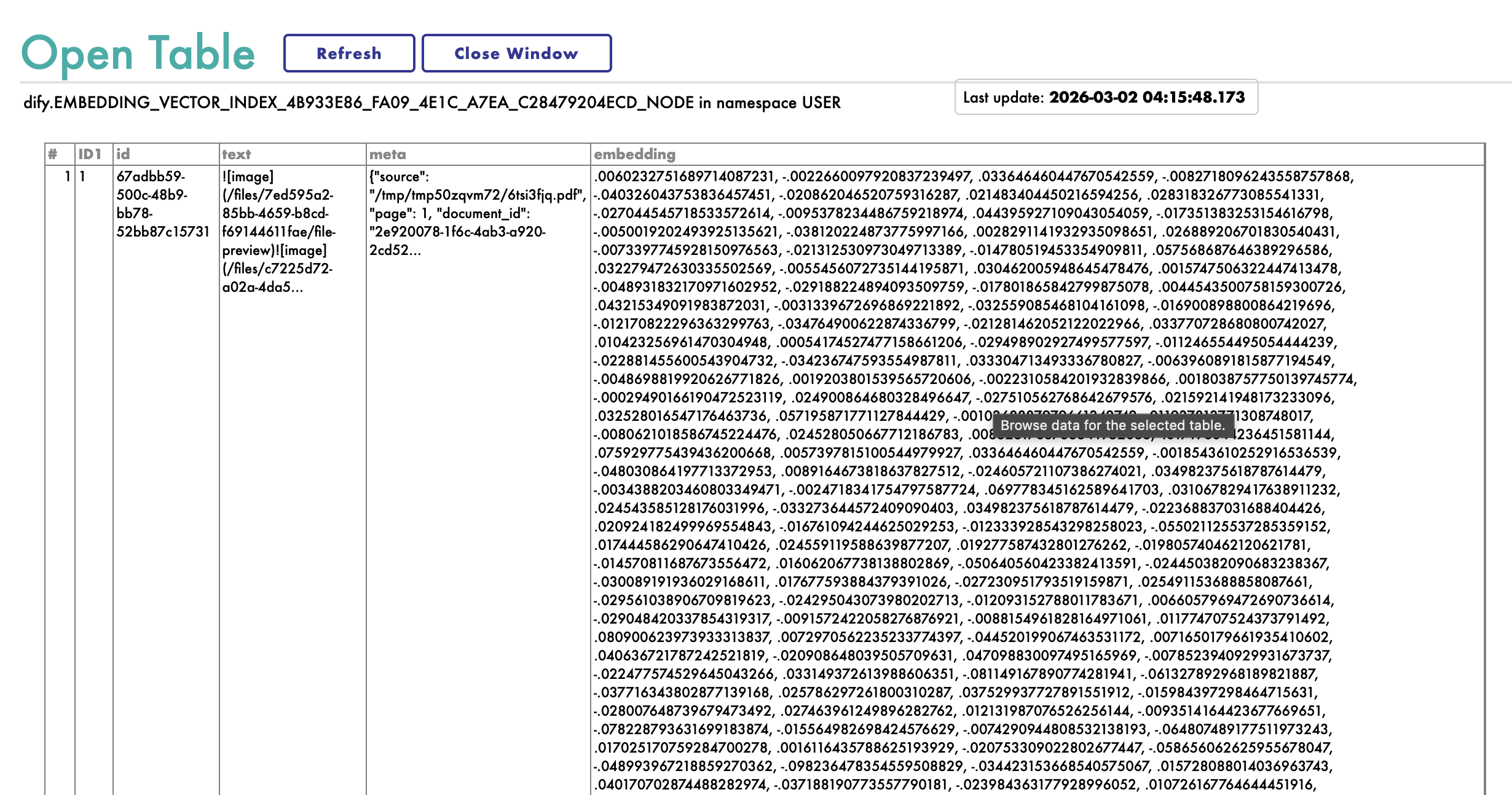
La ventaja de IRIS: Con la mayoría de los almacenes vectoriales, los datos de embedding son opacos —accesibles solo a través de una API propietaria. Con IRIS, tenéis acceso completo mediante SQL. Podéis consultar los datos vectoriales directamente, unirlos con datos operativos que ya están en vuestro espacio de nombres, inspeccionar lo que se ha indexado o construir lógica de recuperación personalizada encima. Esa es una capacidad significativa para equipos que ya están invertidos en el ecosistema de IRIS.
Lo que se ha corregido desde la versión inicial
La integración inicial se lanzó en la v1.11.2 con algunos detalles por pulir. Desde entonces, todos los problemas conocidos se han resuelto y se han integrado en la base de código oficial de Dify.
| PR | Versión | Descripción |
|---|---|---|
| #29480 | v1.11.2 | Soporte inicial de almacén vectorial IRIS |
| #31309 | post-v1.11.2 | Corrección de la búsqueda de texto completo y búsqueda híbrida para el backend de IRIS |
| #31899 | v1.12.1 | Corrección de la persistencia de datos de IRIS al recrear contenedores usando Durable %SYS |
| #31901 | v1.12.1 | Mejoras adicionales en la persistencia de datos de Durable %SYS |
Nota sobre Durable %SYS: Sin las correcciones de #31899 y #31901, los datos de IRIS podían perderse al recrear contenedores — un problema común con la imagen Docker de la Community Edition. Los desarrolladores de IRIS reconocerán Durable %SYS de inmediato; estas correcciones aseguran que la configuración en Docker lo respete correctamente.
Solución de problemas
El contenedor de IRIS no se inicia en Windows
En Windows, el contenedor de IRIS puede no iniciarse debido a problemas de permisos en el directorio de volúmenes. Ejecutad lo siguiente desde el directorio de Docker antes de iniciar los contenedores:
chmod -R 777 ./volumes/irisNota: Esta es una limitación conocida en entornos Windows. Se planea una corrección para eliminar este paso en una versión futura.
El contenedor de IRIS no se inicia (alto número de núcleos)
En máquinas con un alto número de núcleos, se puede activar el límite de 20 núcleos de IRIS Community Edition. Añadid lo siguiente al servicio iris en el archivo docker-compose.yml:
services:
iris:
cpuset: "0-19"Resumen
| Qué | Cómo |
|---|---|
| Activad IRIS en Dify | Estableced VECTOR_STORE=iris en .env |
| Verificad los vectores almacenados | Portal de Gestión → SQL → esquema: dify |
| Persistencia de datos | Gestionado por Durable %SYS (corregido en la v1.12.1) |
| Community Edition | Gratis · 10 GB de datos · Hasta 20 núcleos |
Una publicación posterior os mostrará cómo crear un chatbot RAG completo sobre esta pila. Si tenéis preguntas o problemas, dejadlos en los comentarios a continuación.