 Open Exchange
Open Exchange如今,关于大语言模型、人工智能等的消息不绝于耳。向量数据库是其中的一部分,并且已经有非IRIS的技术实现了向量数据库。
为什么是向量?
- 相似性搜索:向量可以进行高效的相似性搜索,例如在数据集中查找最相似的项目或文档。传统的关系数据库是为精确匹配搜索而设计的,不适合图像或文本相似性搜索等任务。
- 灵活性:向量表示形式用途广泛,可以从各种数据类型派生,例如文本(通过 Word2Vec、BERT 等嵌入)、图像(通过深度学习模型)等。
- 跨模态搜索:向量可以跨不同数据模态进行搜索。例如,给定图像的向量表示,人们可以在多模式数据库中搜索相似的图像或相关文本。
还有许多其他原因。
因此,对于这次 pyhon 竞赛,我决定尝试实现这种支持。不幸的是我没能及时完成它,下面我将解释原因。
 有几件重要的事情必须完成,才能使其充实
有几件重要的事情必须完成,才能使其充实
- 使用 SQL 接受并存储向量化数据,简单的示例(本例中的 3 是维度数量,每个字段都是固定的,并且该字段中的所有向量都必须具有精确的维度)
create table items(embedding vector( 3 )); insert into items (embedding) values ( '[1,2,3]' ); insert into items (embedding) values ( '[4,5,6]' ); - 相似度函数,相似度有不同的算法,适合对少量数据进行简单搜索,不使用索引
-- Euclidean distance select embedding, vector.l2_distance(embedding, '[9,8,7]' ) distance from items order by distance; -- Cosine similarity select embedding, vector.cosine_distance(embedding, '[9,8,7]' ) distance from items order by distance; -- Inner product select embedding, -vector.inner_product(embedding, '[9,8,7]' ) distance from items order by distance; - 自定义索引,有助于更快地搜索大量数据,索引可以使用不同的算法,并使用与上面不同的距离函数,以及其他一些选项
- 新南威尔士州
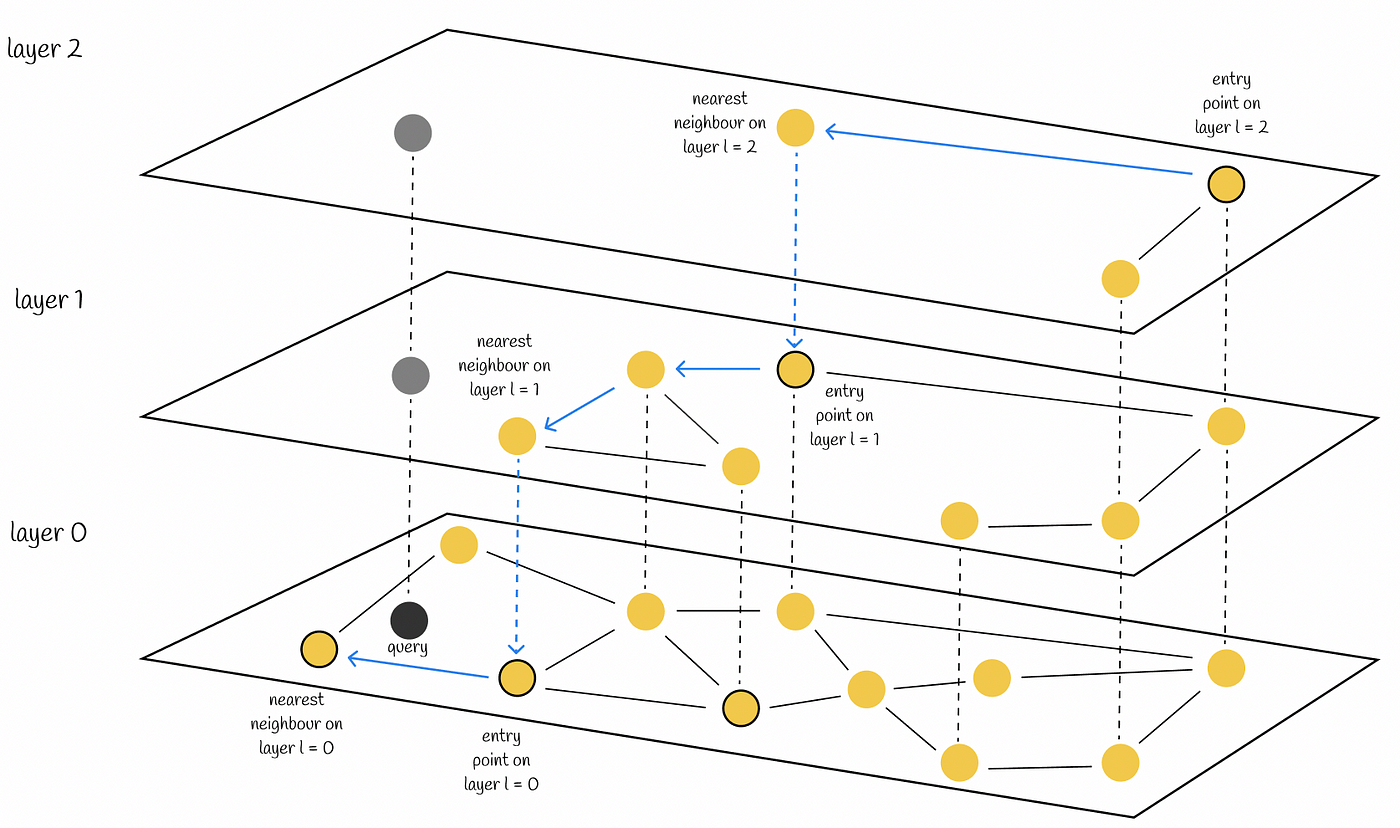
- 倒排文件索引
.png)
- 新南威尔士州
- 搜索将使用创建的索引,其算法将找到所请求的信息。
插入向量
该向量应该是一个数值数组,可以是整数或浮点数,也可以是有符号的或无符号的。在IRIS中我们可以将其存储为$listbuild,它具有良好的表示性,已经支持,只需要实现从ODBC到逻辑的转换。
然后,可以使用外部驱动程序(例如 ODBC/JDBC)或使用 ObjectScript 从 IRIS 内部以纯文本形式插入值
- 普通 SQL
insert into items (embedding) values ( '[1,2,3]' ); - 来自ObjectScript
set rs = ##class ( %SQL.Statement ). %ExecDirect (, "insert into test.items (embedding) values ('[1,2,3]')" ) set rs = ##class ( %SQL.Statement ). %ExecDirect (, "insert into test.items (embedding) values (?)" , $listbuild ( 2 , 3 , 4 )) - 或者嵌入式 SQL
&sql( insert into test.items (embedding ) values ('[ 1 , 2 , 3 ]')) set val = $listbuild ( 2 , 3 , 4 ) &sql( insert into test.items (embedding ) values (:val))
它将始终存储为 $lb(),并在 ODBC 中以文本格式返回
.png)
计算
我们需要向量来支持两个向量之间距离的计算
为了这次比赛,我需要使用嵌入式Python,这就带来了一个问题,如何在嵌入式Python中操作$lb。 %SYS.Class中有一个方法ToList,但Python包IRIS没有内置该方法,需要通过ObjectScript方式调用它
ClassMethod l2DistancePy(v1 As dc.vector.type, v2 As dc.vector.type) As %Decimal (SCALE= 10 ) [ Language = python, SqlName = l2_distance_py, SqlProc ] { import iris import math vector_type = iris.cls('dc.vector.type') v1 = iris.cls(' %SYS.Python ').ToList(vector_type.Normalize(v1)) v2 = iris.cls(' %SYS.Python ').ToList(vector_type.Normalize(v2)) return math.sqrt(sum([(val1 - val2) ** 2 for val1, val2 in zip(v1, v2)])) }它看起来一点也不正确。我希望 $lb 可以在 python 中即时解释为列表,或者在列表内置函数 to_list 和 from_list 中解释
另一个问题是当我尝试使用不同的方式测试此功能时。使用嵌入式Python中的SQL,使用嵌入式Python编写的SQL函数,它会崩溃。因此,我还必须添加 ObjectScript 的功能。
ModuleNotFoundError: No module named 'dc' SQL Function VECTOR.NORM_PY failed with error: SQLCODE=-400,%msg=ERROR #5002: ObjectScript error: <OBJECT DISPATCH>%0AmBm3l0tudf^%sqlcq.USER.cls37.1 *python object not found
目前在 Python 和 ObjectScript 中实现了计算距离的函数
- 欧氏距离
[SQL]_system@localhost:USER> select embedding, vector.l2_distance_py(embedding, '[9,8,7]' ) distance from items order by distance; + -----------+----------------------+ | embedding | distance | + -----------+----------------------+ | [4,5,6] | 5.91607978309961613 | | [1,2,3] | 10.77032961426900748 | + -----------+----------------------+ 2 rows in set Time : 0.011 s [ SQL ]_system@localhost: USER > select embedding, vector.l2_distance(embedding, '[9,8,7]' ) distance from items order by distance; + -----------+----------------------+ | embedding | distance | + -----------+----------------------+ | [4,5,6] | 5.916079783099616045 | | [1,2,3] | 10.77032961426900807 | + -----------+----------------------+ 2 rows in set Time : 0.012 s - 余弦相似度
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance(embedding, '[9,8,7]' ) distance from items order by distance; + -----------+---------------------+ | embedding | distance | + -----------+---------------------+ | [4,5,6] | .034536677566264152 | | [1,2,3] | .11734101007866331 | + -----------+---------------------+ 2 rows in set Time : 0.034 s [ SQL ]_system@localhost: USER > select embedding, vector.cosine_distance_py(embedding, '[9,8,7]' ) distance from items order by distance; + -----------+-----------------------+ | embedding | distance | + -----------+-----------------------+ | [4,5,6] | .03453667756626421781 | | [1,2,3] | .1173410100786632659 | + -----------+-----------------------+ 2 rows in set Time : 0.025 s - 内积
[SQL]_system@localhost:USER> select embedding, vector.inner_product_py(embedding, '[9,8,7]' ) distance from items order by distance; + -----------+----------+ | embedding | distance | + -----------+----------+ | [1,2,3] | 46 | | [4,5,6] | 118 | + -----------+----------+ 2 rows in set Time : 0.035 s [ SQL ]_system@localhost: USER > select embedding, vector.inner_product(embedding, '[9,8,7]' ) distance from items order by distance; + -----------+----------+ | embedding | distance | + -----------+----------+ | [1,2,3] | 46 | | [4,5,6] | 118 | + -----------+----------+ 2 rows in set Time : 0.032 s
另外还实现了数学函数:add、sub、div、mul。 InterSystems 支持创建自己的聚合函数。因此,可以对所有向量求和或求平均值。但不幸的是,InterSystems 不支持使用相同的名称,需要使用自己的名称(和模式)来执行函数。但它不支持聚合函数的非数值结果
简单的 vector_add 函数,返回两个矢量的和
.png)
当用作聚合时,它显示 0,而预期矢量也是
.png)
建立索引
不幸的是,由于我在实现过程中遇到了一些障碍,我没能完成这一部分。
- 缺乏内置的 $lb 到 python 列表转换以及当 IRIS 中的矢量存储在 $lb 中时返回,并且所有具有构建索引的逻辑预计都在 Python 中,从 $lb 获取数据并将其设置回全局变量也很重要
- 缺乏对Global的支持
- IRIS 中的 $Order,支持方向,因此可以反向使用,而Python内嵌的 order 实现没有它,因此需要读取所有键并反转它们或将末尾存储在某处
- 由于对上面提到的从 Python 调用的 Python 的 SQL 函数的不好的体验而产生疑问
- 在构建索引期间,预计会在图形中存储矢量之间的距离,但在global里保存浮点数时遇到了bug
我在工作中发现了11 个嵌入式 Python 问题,所以大部分时间都是在寻找解决方法来解决问题。在名为iris-dollar-list的 @Guillaume Rongier 项目的帮助下,我成功解决了一些问题。
安装
无论如何,它仍然可用,并且可以与 IPM 一起安装,即使功能有限也可以使用
zpm "install vector"或者在开发模式下使用 docker-compose
git clone https://github.com/caretdev/iris-vector.git cd iris-vector docker-compose up -d
.png)


.png)