Limpiar filtro
Artículo
Luis Angel Pérez Ramos · 23 nov, 2022
**Antecedentes**
| Versión | Fecha | Cambios |
|:------- |:---------- |:------------------------------------------------------------------------------------------------------------------------------------------ |
| V1 | 08/02/2022 | Lanzamiento Inicial |
| V1.1 | 06/04/2022 | Generación de certificados con un archivo sh en vez de un pki-scriptUso de variables de entorno en los archivos de configuración |
¡Hola Comunidad!
¿Ya habéis configurado un entorno en mirror? ¿Tenéis una red privada, una dirección IP virtual y una configuración SSL? Después de hacer esto un par de veces, me di cuenta de que es muy largo, y hay muchos pasos que hay que realizar manualmente para generar certificados y configurar cada instancia de IRIS. Es un dolor de cabeza para cualquiera que tenga que hacer esto a menudo.
Por ejemplo, un equipo de control de calidad podría necesitar un nuevo entorno por cada nueva versión de la aplicación que tenga que probar mientras que el equipo de soporte puede necesitar crear un entorno para reproducir un problema complejo.
Definitivamente, necesitamos herramientas para crearlos rápidamente.
En este artículo crearemos una muestra para configurar un *mirror* con:
- Arbiter.
- Primary.
- Miembro failover del backup.
- Miembro asíncrono de lectura-escritura de informes.
- Configuración SSL para transferencias de *journal* entre nodos.
- Red privada para el *mirror*.
- Dirección IP virtual.
- Una base de datos en mirror.
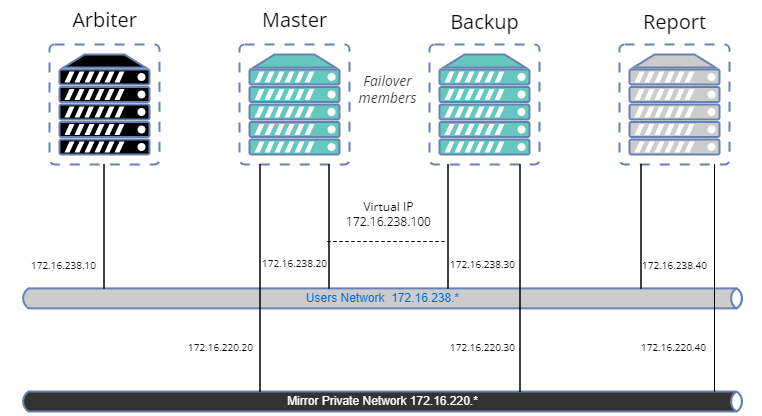
A primera vista, parece un poco complejo y parece que hace falta una gran cantidad de código, pero no te preocupes. Hay librerías en OpenExchange para realizar fácilmente la mayoría de las operaciones.
El propósito de este artículo es ofrecer un ejemplo de cómo adaptar el proceso a vuestras necesidades, pero no es una guía de prácticas recomendadas en materia de seguridad.
Así que vamos a crear nuestra muestra.
### Herramientas y librerías
- [config-api](https://openexchange.intersystems.com/package/Config-API): Esta librería se utilizará para configurar IRIS. Es compatible con la configuración del *mirroring* desde la versión 1.1.0. No vamos a dar una descripción detallada de cómo utilizar esta librería. Ya hay varios artículos [aquí](https://community.intersystems.com/post/environment-setup-config-api). En resumen, config-api se utilizará para crear archivos de configuración de plantillas IRIS (formato JSON) y cargarlos fácilmente.
- [ZPM](https://openexchange.intersystems.com/package/ObjectScript-Package-Manager).
- Docker.
- OpenSSL.
### Página de Github
Podéis encontrar todos los archivos de recursos necesarios en el repositorio [iris-mirroring-samples](https://github.com/lscalese/iris-mirroring-samples/).
### Preparación del sistema
Clonad el repositorio existente:
```bash
git clone https://github.com/lscalese/iris-mirroring-samples
cd iris-mirroring-samples
```
Si preferís crear una muestra desde cero, en vez de clonar el repositorio, simplemente cread un nuevo directorio con subdirectorios: `backup`, y `config-files`. Descargad [irissession.sh](https://raw.githubusercontent.com/lscalese/iris-mirroring-samples/master/session.sh):
```
mkdir -p iris-mirroring-samples/backup iris-mirroring-samples/config-files
cd iris-mirroring-samples
wget -O session.sh https://raw.githubusercontent.com/lscalese/iris-mirroring-samples/master/session.sh
```
Para evitar la incidencia "permiso rechazado" más tarde, tenemos que crear el grupo `irisowner`, el usuario `irisowner`, y cambiar el grupo del directorio del *backup* a `irisowner`
```bash
sudo useradd --uid 51773 --user-group irisowner
sudo groupmod --gid 51773 irisowner
sudo chgrp irisowner ./backup
```
Este directorio se utilizará como volumen para compartir una copia de seguridad de la base de datos después de que se configure el primer miembro *mirror* con los otros nodos.
### Obtención de una licencia de IRIS
*Mirroring* no está disponible con la Edición Community de IRIS. Si aún no tenéis una licencia válida para el contenedor de IRIS, conectaos al [Centro de Soporte Internacional (WRC)](https://wrc.intersystems.com) con vuestras credenciales. Haced clic en "Actions" --> "Online distribtion", después en el botón "Evaluations" y seleccionad "Evaluation License". Completad el formulario. Copiad vuestro archivo de licencia `iris.key` en este directorio.
### Inicio de sesión en el Registro de Contenedores de Intersystems
Por comodidad, utilizamos Intersystems Containers Registry (ICR) para extraer imágenes de Docker. Si no sabéis vuestro nombre de usuario\\contraseña de Docker, conectaos a [SSO.UI.User.ApplicationTokens.cls](https://login.intersystems.com/login/SSO.UI.User.ApplicationTokens.cls) con vuestras credenciales del Centro de Soporte Internacional (WRC), y podréis recuperar vuestro Token ICR.
```bash
docker login -u="YourWRCLogin" -p="YourICRToken" containers.intersystems.com
```
### Creación de la base de datos `myappdata` y un mapeo de globales
De momento no vamos a crear la base de datos `myappdata`, únicamente estamos preparando la configuración para crearla al momento de crear el Docker. Para ello, simplemente creamos un archivo sencillo utilizando el formato JSON. La librería config-api se utilizará para cargarlo en las instancias de IRIS.
Cread el archivo [config-files/simple-config.json](https://github.com/lscalese/iris-mirroring-samples/blob/master/config-files/simple-config.json)
```json
{
"Defaults":{
"DBDATADIR" : "${MGRDIR}myappdata/",
"DBDATANAME" : "MYAPPDATA"
},
"SYS.Databases":{
"${DBDATADIR}" : {}
},
"Databases":{
"${DBDATANAME}" : {
"Directory" : "${DBDATADIR}"
}
},
"MapGlobals":{
"USER": [{
"Name" : "demo.*",
"Database" : "${DBDATANAME}"
}]
},
"Security.Services" : {
"%Service_Mirror" : { /* Enable the mirror service on this instance */
"Enabled" : true
}
}
}
```
Este archivo de configuración permite crear una nueva base de datos con la configuración predeterminada y hacer un mapeo del global `demo.*` en el *namespace* USER.
Para más información sobre las funciones del archivo de configuración [config-api](https://openexchange.intersystems.com/package/config-api) consulta el [artículo](https://community.intersystems.com/post/environment-setup-config-api), relacionado o la [página de github](https://community.intersystems.com/post/environment-setup-config-api).
### El archivo Docker
El archivo Docker se basa en la plantilla existente de [Docker](https://github.com/intersystems-community/objectscript-docker-template), pero necesitamos hacer algunos cambios para crear un directorio de trabajo, instalar las herramientas para el uso de la IP virtual, instalar ZPM, etc…
Nuestra imagen IRIS es la misma para cada miembro *mirror*. El *mirroring* se establecerá en el contenedor empezando con la configuración correcta dependiendo de su función (primer miembro, backup de respaldo/failover o informe de lectura-escritura). Observa los comentarios en el Dockerfile:
```Dockerfile
ARG IMAGE=containers.intersystems.com/intersystems/iris:2021.1.0.215.0
# No es necesario descargar la imagen desde WRC, se hará automáticamente desde ICR cuando se despliegue el contenedor.
FROM $IMAGE
USER root
COPY session.sh /
COPY iris.key /usr/irissys/mgr/iris.key
# /opt/demo será nuestro directorio de trabajo y en el que almacenaremos nuestros archivos de configuración así como otros archivos de instalación.
# Instalamos iputils-arping para hacer uso del comando arping. Es necesario para configurar una IP Virtual.
# Descargamos la última versión de ZPM (o IPM, incluida en las versiones a partir de la 2023.1).
RUN mkdir /opt/demo && \
chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/demo && \
chmod 666 /usr/irissys/mgr/iris.key && \
apt-get update && apt-get install iputils-arping gettext-base && \
wget -O /opt/demo/zpm.xml https://pm.community.intersystems.com/packages/zpm/latest/installer
USER ${ISC_PACKAGE_MGRUSER}
WORKDIR /opt/demo
# Configuramos el rol del mirror por defecto a master.
# Se sobreescribirá en el archivo docker-compose en el momento de la ejecución (master para la primera instancia, backup, y report)
ARG IRIS_MIRROR_ROLE=master
# Copiamos el contenido del directorio de archivos de configuración en /opt/demo.
# Únicamente hemos creado una configuración simple de nuestra base de datos y los mapeos de globales.
# Posteriormente en este mismo artículo incluiremos otros archivos de configuración para desplegar el mirror.
ADD config-files .
SHELL [ "/session.sh" ]
# Instalamos el ZPM (no será necesario para versiones a partir de 2023.1)
# Usamos ZPM para instalar config-api
# Cargamos el archivo de configuración simple-config.json con config-api para:
# - crear la base de datos "myappdata",
# - añadirmos un mapeo de globales en el namespace "USER" para los globales "demo.*" a la base de datos "myappdata".
# Basicamente, el punto de entrada para instalar tu aplicación de ObjectScript es este.
# Para este ejemplo cargaremos simple-config.json para crear una base de datos simple y un mapeo de globals.
RUN \
Do $SYSTEM.OBJ.Load("/opt/demo/zpm.xml", "ck") \
zpm "install config-api" \
Set sc = ##class(Api.Config.Services.Loader).Load("/opt/demo/simple-config.json")
# Copiamos el script de arranque del mirror.
COPY init_mirror.sh /
```
### Creación de la imagen IRIS
El Dockerfile está listo, podemos crear la imagen:
```
docker build --no-cache --tag mirror-demo:latest .
```
Esta imagen se utilizará para ejecutar los nodos primarios, los de copias de seguridad y los de informes.
### El archivo .env
Los archivos de configuración JSON y docker-compose utilizan variables de entorno. Sus valores se almacenan en un archivo llamado `.env`. Para este ejemplo, nuestro archivo env es:
```
APP_NET_SUBNET=172.16.238.0/24
MIRROR_NET_SUBNET=172.16.220.0/24
IRIS_HOST=172.16.238.100
IRIS_PORT=1972
IRIS_VIRTUAL_IP=172.16.238.100
ARBITER_IP=172.16.238.10
MASTER_APP_NET_IP=172.16.238.20
MASTER_MIRROR_NET_IP=172.16.220.20
BACKUP_APP_NET_IP=172.16.238.30
BACKUP_MIRROR_NET_IP=172.16.220.30
REPORT_APP_NET_IP=172.16.238.40
REPORT_MIRROR_NET_IP=172.16.220.40
```
### Preparación del archivo de configuración del primer miembro del mirror
La librería config-api permite configurar un *mirror*, por lo que debemos crear un archivo de configuración específico para el primer miembro *mirror* `config-files/mirror-master.json`
Para mayor comodidad, los comentarios se sitúan directamente en el JSON. Podéis descargar el [mirror-master.json sin comentarios aquí](https://raw.githubusercontent.com/lscalese/iris-mirroring-samples/master/config-files/mirror-master.json).
```json
{
"Security.Services" : {
"%Service_Mirror" : {
"Enabled" : true
}
},
"SYS.MirrorMaster" : {
"Demo" : {
"Config" : {
"Name" : "Demo", /* El nombre de nuestro mirror */
"SystemName" : "master", /* El nombre de esta instancia en el mirror */
"UseSSL" : true,
"ArbiterNode" : "${ARBITER_IP}|2188", /* Dirección IP y puerto para el nodo del arbiter */
"VirtualAddress" : "${IRIS_VIRTUAL_IP}/24", /* Dirección IP Virtual IP */
"VirtualAddressInterface" : "eth0", /* Interfaz de red usada para la dirección IP Virtual. */
"MirrorAddress": "${MASTER_MIRROR_NET_IP}", /* Dirección IP de este nodo en la red privada del mirror */
"AgentAddress": "${MASTER_APP_NET_IP}" /* Dirección IP de este nodo (Agent está instalado en la misma máquina) */
},
"Databases" : [{ /* Lista de bases de datos añadidas al mirror */
"Directory" : "/usr/irissys/mgr/myappdata/",
"MirrorDBName" : "MYAPPDATA"
}],
"SSLInfo" : { /* Configuración SSL */
"CAFile" : "/certificates/CA_Server.cer",
"CertificateFile" : "/certificates/master_server.cer",
"PrivateKeyFile" : "/certificates/master_server.key",
"PrivateKeyPassword" : "",
"PrivateKeyType" : "2"
}
}
}
}
```
### Preparación del archivo de configuración del miembro failover
Creamos un archivo de configuración para los miembros de backup de respaldo (failover) `config-files/mirror-backup.json`.
Se parece al primer miembro del mirror:
```json
{
"Security.Services" : {
"%Service_Mirror" : {
"Enabled" : true
}
},
"SYS.MirrorFailOver" : {
"Demo" : { /* Datos del mirror al que se va a unir */
"Config": {
"Name" : "Demo",
"SystemName" : "backup", /* Nombre de esta instancia en el mirror */
"InstanceName" : "IRIS", /* Nombre de la instancia de IRIS del primer miembro del mirror */
"AgentAddress" : "${MASTER_APP_NET_IP}", /* Dirección IP del Agent del primer miembro del mirror */
"AgentPort" : "2188",
"AsyncMember" : false,
"AsyncMemberType" : ""
},
"Databases" : [{ /* Base de datos en mirror */
"Directory" : "/usr/irissys/mgr/myappdata/"
}],
"LocalInfo" : {
"VirtualAddressInterface" : "eth0", /* Interfaz de red usada por la dirección IP Virtual. */
"MirrorAddress": "${BACKUP_MIRROR_NET_IP}" /* Dirección IP de este nodo en la red privada del mirror */
},
"SSLInfo" : {
"CAFile" : "/certificates/CA_Server.cer",
"CertificateFile" : "/certificates/backup_server.cer",
"PrivateKeyFile" : "/certificates/backup_server.key",
"PrivateKeyPassword" : "",
"PrivateKeyType" : "2"
}
}
}
}
```
### Preparación del archivo de configuración del miembro en modo lectura-escritura asíncrono
Es bastante similar al archivo de configuración de failover. Las diferencias son los valores de `AsyncMember`, `AsyncMemberType`, y `MirrorAddress`. Creamos el archivo `./config-files/mirror-report.json`:
```json
{
"Security.Services" : {
"%Service_Mirror" : {
"Enabled" : true
}
},
"SYS.MirrorFailOver" : {
"Demo" : {
"Config": {
"Name" : "Demo",
"SystemName" : "report",
"InstanceName" : "IRIS",
"AgentAddress" : "${MASTER_APP_NET_IP}",
"AgentPort" : "2188",
"AsyncMember" : true,
"AsyncMemberType" : "rw"
},
"Databases" : [{
"Directory" : "/usr/irissys/mgr/myappdata/"
}],
"LocalInfo" : {
"VirtualAddressInterface" : "eth0",
"MirrorAddress": "${REPORT_MIRROR_NET_IP}"
},
"SSLInfo" : {
"CAFile" : "/certificates/CA_Server.cer",
"CertificateFile" : "/certificates/report_server.cer",
"PrivateKeyFile" : "/certificates/report_server.key",
"PrivateKeyPassword" : "",
"PrivateKeyType" : "2"
}
}
}
}
```
### Generación de certificados y configuración de los nodos IRIS y
¡Todos los archivos de configuración están listos!
Ahora tenemos que añadir un *script* para generar certificados para asegurar la comunicación entre cada uno de los nodos. En el repositorio [gen-certificates.sh](https://raw.githubusercontent.com/lscalese/iris-mirroring-samples/master/gen-certificates.sh) hay un script listo para ser usado
```
# sudo es obligatorio debido al uso de chown, chgrp chmod.
sudo ./gen-certificates.sh
```
Para configurar cada nodo `init_mirror.sh` se realizará al iniciar los contenedores. Se configurará posteriormente en `docker-compose.yml` en la sección de comandos `command: ["-a", "/init_mirror.sh"]` :
```bash
#!/bin/bash
# Base de datos usada para probar el mirror.
DATABASE=/usr/irissys/mgr/myappdata
# Directorio que contiene myappdata copiada por el master para restaurar en los otros nodos y hacer el mirror.
BACKUP_FOLDER=/opt/backup
# Archivo de configuración del mirror en json con formato de config-api para el nodo master.
MASTER_CONFIG=/opt/demo/mirror-master.json
# Archivo de configuración del mirror en json con formato de config-api para el nodo de backup.
BACKUP_CONFIG=/opt/demo/mirror-backup.json
# Archivo de configuración del mirror en json con formato de config-api para el nodo asíncrono.
REPORT_CONFIG=/opt/demo/mirror-report.json
# El nombre del mirror...
MIRROR_NAME=DEMO
# Lista de miembros del mirror.
MIRROR_MEMBERS=BACKUP,REPORT
# Ejecutado en el master.
# Carga de la configuración del mirror usando config-api con el archivo /opt/demo/simple-config.json.
# Iniciamos un Job para auto-aceptar otros miembros llamados "backup" y "report" se unan al mirror (evitando la validación manual desde el portal de gestión).
master() {
rm -rf $BACKUP_FOLDER/IRIS.DAT
envsubst < ${MASTER_CONFIG} > ${MASTER_CONFIG}.resolved
iris session $ISC_PACKAGE_INSTANCENAME -U %SYS
Artículo
Alberto Fuentes · 28 abr, 2021
## Introducción
Si resuelves problemas complejos en ObjectScript, probablemente tienes mucho código que funciona con los valores de %Status. Si has interactuado con clases persistentes desde una perspectiva de objetos (%Save, %OpenId, etc.), casi seguro que las ha visto.
Un %Status proporciona una envoltura alrededor de un mensaje de error localizable en las plataformas de InterSystems. Un estado OK (`$$$OK`) simplemente es igual a 1, mientras que un mal estado (`$$$ERROR(errorcode,arguments...)`) se representa como un 0 seguido de un espacio seguido de una lista `$ListBuild` con información estructurada sobre el error.
[$System.Status (mira la referencia de clase)](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.Status) proporciona varias APIs útiles para trabajar con los valores de %Status; la referencia de clase es útil y no os molestaré duplicándola aquí. También ha habido algunos otros artículos/preguntas útiles sobre el tema (consulta los enlaces al final de esta publicación). En este artículo me centraré en algunas técnicas de depuración en vez de escribir las prácticas recomendadas (de nuevo, si las estás buscando, consulta los enlaces al final).
## Ejemplo de código motivador
Nota: **¡nunca escribas un código como este!** :) Revisa siempre tus estados y devuélvelos/lánzalos como excepciones (por ejemplo, `$$$ThrowStatus(someErrorStatus)`) y hará que la depuración sea MUY sencilla.
Class DC.Demo.MaskedErrorStatus Extends %Persistent
{
Property Answer As %TinyInt;
ClassMethod Run() As %Status
{
Set instance = ..%New()
Set instance.Answer = 9000
Do instance.%Save()
Set instance = ..%OpenId(1,,.sc)
Set instance.Answer = 42
Do instance.%Save()
Quit $$$OK
}
}
Cuando se ejecuta desde el terminal, se lanza una excepción; es evidente que algo salió mal.
USER>d ##class(DC.Demo.MaskedErrorStatus).Run()
Set instance.Answer = 42
^
<INVALID OREF>zRun+5^DC.Demo.MaskedErrorStatus.1
## Truco #1 de depuración con %Status: $System.OBJ.DisplayError()
Siempre puedes ejecutar `$System.OBJ.DisplayError()` para imprimir el último estado de error que se creó. Esto funciona porque cada vez que se crea un estado de error (por ejemplo, por medio de $System.Status.Error), la variable `%objlasterror` se establece en ese estado. También puedes utilizar `zwrite %objlasterror` (de forma equivalente). En el caso anterior:
USER 2d1>d $system.OBJ.DisplayError()
ERROR #5809: Object to Load not found, class 'DC.Demo.MaskedErrorStatus', ID '1'
## Truco #2 de depuración con %Status: seguimiento de stacks
Dentro de cada %Status hay un seguimiento del stack (pila de llamadas) en el que se creó el error. Se puede ver esto al utilizar el estado zwrite:
USER 2d1>zw %objlasterror %objlasterror="0 "_$lb($lb(5809,"DC.Demo.MaskedErrorStatus","1",,,,,,,$lb(,"USER",$lb("e^%LoadData+18^DC.Demo.MaskedErrorStatus.1^1","e^%Open+16^%Library.Persistent.1^1","e^%OpenId+1^%Library.Persistent.1^1","e^zRun+4^DC.Demo.MaskedErrorStatus.1^1","d^^^0"))))/* ERROR #5809: Object to Load not found, class 'DC.Demo.MaskedErrorStatus', ID '1' */
¿Quieres ver el seguimiento de stacks en el texto de error (que es más sencillo de utilizar) para cada estado (por ejemplo, utilizando `$System.OBJ.DisplayError()` o `$System.Status.GetErrorText(someStatus))`? Puedes hacerlo al establecer `%oddENV("callererrorinfo",$namespace)' a valores 1 o 2. Puedes ver el efecto aquí:
USER>set ^%oddENV("callererrorinfo",$namespace)=1
USER>d $system.OBJ.DisplayError()
ERROR #5809: Object to Load not found, class 'DC.Demo.MaskedErrorStatus', ID '1' [%LoadData+18^DC.Demo.MaskedErrorStatus.1:USER]
USER>set ^%oddENV("callererrorinfo",$namespace)=2
USER>d $system.OBJ.DisplayError()
ERROR #5809: Object to Load not found, class 'DC.Demo.MaskedErrorStatus', ID '1' [e^%LoadData+18^DC.Demo.MaskedErrorStatus.1^1 e^%Open+16^%Library.Persistent.1^1 e^%OpenId+1^%Library.Persistent.1^1 e^zRun+4^DC.Demo.MaskedErrorStatus.1^1 d^^^0:USER]
USER>k ^%oddENV("callererrorinfo",$namespace)
USER>d $system.OBJ.DisplayError()
ERROR #5809: Object to Load not found, class 'DC.Demo.MaskedErrorStatus', ID '1'
Ten en cuenta que esto sólo es apropiado en un entorno de desarrollo - no querrás que tus usuarios vean el interior de tu código -. En realidad, es mejor evitar mostrar los valores de %Status directamente a los usuarios. Son preferibles los mensajes de error específicos de la aplicación, más fáciles de utilizar. Pero ese es un tema para otro día.
## Truco #3 de depuración con %Status: el elegante zbreak
Aquí es donde se pone difícil - en el caso de este fragmento de código, la causa raíz es un %Status no verificado de `%Save()` que antes estaba en el fragmento de código. Es fácil imaginar un ejemplo mucho más complicado en el que encontrar lo que ha fallado es realmente difícil, especialmente si se trata de un error que se produce en algún punto del código de la plataforma. Mi método preferido para gestionar esto, sin saltar a un depurador interactivo, es utilizar un comando [zbreak](https://cedocs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=TCOS_ZBreak) en el terminal:
USER>zbreak *%objlasterror:"N":"$d(%objlasterror)#2":"set ^mtemptl($i(^mtemptl))=%objlasterror"
...¿qué quiere decir eso?
zbreak <cada vez que %objlasterror cambie>:<no haga nada en el depurador mismo>:<mientras %objlasterror esté definido y tenga un valor (por ejemplo, no ha pasado de estar definido a estar indefinido)>:<ejecuta el código para establecer el siguiente subíndice de un global con un subíndice entero que no está en journal (porque comienza con mtemp, en caso de que estemos en una transacción cuando se crea %Status y se haya revertido para cuando observemos el registro; también, con mis iniciales como parte del global para que si alguien lo encuentra en el código comprometido o en una base de datos inflada sepa que debe llamarme) al estado de error>
Nota adicional sobre zbreak: puedes ver los breakpoints/watchpoints definidos actualmente si ejecutas "zbreak" sin argumentos, y puedes/debes desactivar estos breakpoints cuando hayas terminado con ellos ejecutando break "off", por ejemplo:
USER>zbreak
BREAK:
No breakpoints
%objlasterror F:E S:0 C:"$d(%objlasterror)#2" E:"set ^mtemptl($i(^mtemptl))=%objlasterror"
USER>break "off"
USER>zbreak
BREAK:
No breakpoints
No watchpoints
Entonces, ¿qué sucede cuando el método problemático se ejecuta con el watchpoint establecido?
USER>zbreak *%objlasterror:"N":"$d(%objlasterror)#2":"set ^mtemptl($i(^mtemptl))=%objlasterror"
USER>d ##class(DC.Demo.MaskedErrorStatus).Run()
Set instance.Answer = 42
^
<INVALID OREF>zRun+5^DC.Demo.MaskedErrorStatus.1
USER 2d1>zw ^mtemptl
^mtemptl=6
^mtemptl(1)="0 "_$lb($lb(7203,9000,127,,,,,,,$lb(,"USER",$lb("e^zAnswerIsValid+1^DC.Demo.MaskedErrorStatus.1^1","e^%ValidateObject+3^DC.Demo.MaskedErrorStatus.1^4","e^%SerializeObject+3^%Library.Persistent.1^1","e^%Save+4^%Library.Persistent.1^2","d^zRun+3^DC.Demo.MaskedErrorStatus.1^1","d^^^0"))))/* ERROR #7203: Datatype value '9000' greater than MAXVAL allowed of 127 */
^mtemptl(2)="0 "_$lb($lb(7203,9000,127,,,,,,,$lb(,"USER",$lb("e^zAnswerIsValid+1^DC.Demo.MaskedErrorStatus.1^1","e^%ValidateObject+3^DC.Demo.MaskedErrorStatus.1^4","e^%SerializeObject+3^%Library.Persistent.1^1","e^%Save+4^%Library.Persistent.1^2","d^zRun+3^DC.Demo.MaskedErrorStatus.1^1","d^^^0")),"0 "_$lb($lb(5802,"DC.Demo.MaskedErrorStatus:Answer",9000,,,,,,,$lb(,"USER",$lb("e^EmbedErr+1^%occSystem^1"))))))/* ERROR #7203: Datatype value '9000' greater than MAXVAL allowed of 127- > ERROR #5802: Datatype validation failed on property 'DC.Demo.MaskedErrorStatus:Answer', with value equal to "9000" */
^mtemptl(3)="0 "_$lb($lb(7203,9000,127,,,,,,,$lb("zAnswerIsValid+1^DC.Demo.MaskedErrorStatus.1","USER",$lb("e^zAnswerIsValid+1^DC.Demo.MaskedErrorStatus.1^1","e^%ValidateObject+3^DC.Demo.MaskedErrorStatus.1^4","e^%SerializeObject+3^%Library.Persistent.1^1","e^%Save+4^%Library.Persistent.1^2","d^zRun+3^DC.Demo.MaskedErrorStatus.1^1","d^^^0"))))/* ERROR #7203: Datatype value '9000' greater than MAXVAL allowed of 127 */
^mtemptl(4)="0 "_$lb($lb(5802,"DC.Demo.MaskedErrorStatus:Answer",9000,,,,,,,$lb("EmbedErr+1^%occSystem","USER",$lb("e^EmbedErr+1^%occSystem^1"))))/* ERROR #5802: Datatype validation failed on property 'DC.Demo.MaskedErrorStatus:Answer', with value equal to "9000" */
^mtemptl(5)="0 "_$lb($lb(7203,9000,127,,,,,,,$lb("zAnswerIsValid+1^DC.Demo.MaskedErrorStatus.1","USER",$lb("e^zAnswerIsValid+1^DC.Demo.MaskedErrorStatus.1^1","e^%ValidateObject+3^DC.Demo.MaskedErrorStatus.1^4","e^%SerializeObject+3^%Library.Persistent.1^1","e^%Save+4^%Library.Persistent.1^2","d^zRun+3^DC.Demo.MaskedErrorStatus.1^1","d^^^0")),"0 "_$lb($lb(5802,"DC.Demo.MaskedErrorStatus:Answer",9000,,,,,,,$lb("EmbedErr+1^%occSystem","USER",$lb("e^EmbedErr+1^%occSystem^1"))))))/* ERROR #7203: Datatype value '9000' greater than MAXVAL allowed of 127- > ERROR #5802: Datatype validation failed on property 'DC.Demo.MaskedErrorStatus:Answer', with value equal to "9000" */
^mtemptl(6)="0 "_$lb($lb(5809,"DC.Demo.MaskedErrorStatus","1",,,,,,,$lb(,"USER",$lb("e^%LoadData+18^DC.Demo.MaskedErrorStatus.1^1","e^%Open+16^%Library.Persistent.1^1","e^%OpenId+1^%Library.Persistent.1^1","e^zRun+4^DC.Demo.MaskedErrorStatus.1^1","d^^^0"))))/* ERROR #5809: Object to Load not found, class 'DC.Demo.MaskedErrorStatus', ID '1' */
Hay un poco de ruido ahí, pero el problema clave salta a la vista:
/\* ERROR #7203: Datatype value '9000' greater than MAXVAL allowed of 127 \*/
¡Debería haber sabido que no debería utilizar %TinyInt! (Y, lo que es más importante, siempre debes verificar los valores de %Status devueltos por los métodos que llamas).
## Lecturas relacionadas
[Mis patrones de codificación preferidos para la gestión y reporte de errores](https://community.intersystems.com/post/try-catch-block-i-usually-use-intersystems-objectscript#comment-7751)
[%Status frente a otros valores de retorno en los métodos ObjectScript de Caché](https://community.intersystems.com/post/status-vs-other-return-values-cach%C3%A9-objectscript-methods)
[Sobre %objlasterror](https://community.intersystems.com/post/about-objlasterror)
[Cómo configurar $$$envCallerErrorInfoGet](https://community.intersystems.com/post/how-set-envcallererrorinfoget-windows-get-location-information-within-exception#comment-95586)
[Fragmentos de código para gestión de errores de ObjectScript](https://community.intersystems.com/post/objectscript-error-handling-snippets)
[Comando ZBREAK](https://cedocs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=TCOS_ZBreak) Este artículo está etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Mario Sanchez Macias · 13 mayo, 2021
Aunque la [integridad](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_integrity) de las bases de datos Caché e InterSystems IRIS está completamente protegida de las consecuencias de un fallo de sistema, los dispositivos de almacenamiento físico sí que pueden fallar, corrompiendo los datos que almacenan.
Por esa razón, muchos sitios optan por realizar chequeos o verificaciones periódicas de integridad de bases de datos, sobre todo en coordinación con las copias de seguridad, para validar que se pueda confiar en una determinada copia de seguridad en caso de que ocurra algún desastre. El chequeo de integridad también puede ser muy necesario para el administrador del sistema, como respuesta a un desastre que implique la corrupción del almacenamiento. El chequeo de integridad ha de leer todos los bloques de los *globals* que están en el proceso de verificación (si actualmente no están en los *buffers*), y en el orden dictado por la estructura del global. Esto lleva mucho tiempo, **pero el chequeo de integridad es capaz de leer tan rápido como el subsistema de almacenamiento pueda soportar**. En algunas situaciones, es aconsejable ejecutarlo de esta manera para obtener resultados lo más rápido posible. En otras situaciones, el chequeo de integridad debe ser más conservador para evitar consumir demasiado ancho de banda del subsistema de almacenamiento.
## Plan de Ataque
El siguiente esquema se adapta a la mayoría de las situaciones. El análisis detallado del resto de este artículo proporciona la información necesaria para actuar sobre cualquiera de ellos, o para derivar otras líneas de acción.
1. Si utilizas Linux y el chequeo de integridad es lento, consulta la información que encontrarás más abajo sobre la activación de la E/S asíncrona.
2. Si el chequeo de integridad debe completarse lo más rápido posible (ejecutándose en un entorno aislado, o porque los resultados se necesitan urgentemente), utiliza el chequeo de Integridad Multiproceso para comprobar varios *globals* o bases de datos en paralelo. El número de procesos multiplicado por el número de lecturas asíncronas simultáneas que cada proceso realizará (8 de forma predeterminada, o 1 si se utiliza Linux con la E/S asíncrona deshabilitada) es el límite del número de lecturas simultáneas sostenidas. Considera que el promedio puede ser la mitad de eso y después compara con las características del subsistema de almacenamiento. Por ejemplo, con el almacenamiento dividido en 20 unidades y las 8 lecturas simultáneas predeterminadas por proceso, pueden ser necesarios cinco o más procesos para capturar toda la capacidad del subsistema de almacenamiento (5*8/2=20).
3. Al equilibrar la velocidad del chequeo de integridad contra su impacto en producción, primero ajusta el número de procesos en el chequeo de integridad multiproceso; después, si es necesario, consulta el ajuste SetAsyncReadBuffers. Consulta el chequeo de Integridad de Aislamiento indicado más abajo para obtener una solución a largo plazo (y para eliminar falsos positivos).
4. Si ya está limitado a un solo proceso (por ejemplo, hay un *global* extremadamente grande u otras restricciones externas) y la velocidad de el chequeo de integridad necesita un ajuste hacia arriba o hacia abajo, consulta más abajo el ajuste SetAsyncReadBuffers.
## Chequeo de Integridad Multiproceso
La solución general para obtener un chequeo de integridad que se complete más rápido (usando recursos del sistema a un mayor ritmo) es dividir el trabajo entre varios procesos paralelos. Algunas de las interfaces de usuario y APIs de chequeo de integridad lo hacen, mientras que otras utilizan un solo proceso. La asignación a los procesos es una por global, por lo que el chequeo de un único *global* siempre se realiza mediante un solo proceso (las versiones anteriores a Caché 2018.1 dividían el trabajo por base de datos en vez de por *global*).
La API principal para verificar la integridad de varios procesos es **CheckLIst Integrity** (consulta [la documentación](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCDI_integrity#GCDI_integrity_verify_utility) para más detalles). Recopila los resultados en un *global* temporal para ser mostrados por Display^Integrity. El siguiente es un ejemplo de verificación de tres bases de datos usando cinco procesos. Si se omite el parámetro de la lista de bases de datos, se verifican todas las bases de datos.
set dblist=$listbuild(“/data/db1/”,”/data/db2/”,”/data/db3/”)
set sc=$$CheckList^Integrity(,dblist,,,5)
do Display^Integrity()
kill ^IRIS.TempIntegrityOutput(+$job)
/* Note: evaluating ‘sc’ above isn’t needed just to display the results, but...
$system.Status.IsOK(sc) - ran successfully and found no errors
$system.Status.GetErrorCodes(sc)=$$$ERRORCODE($$$IntegrityCheckErrors) // 267
- ran successfully, but found errors.
Else - a problem may have prevented some portion from running, ‘sc’ may have
multiple error codes, one of which may be $$$IntegrityCheckErrors. */
El uso de CheckLIst^Integrity de esta manera es la forma más sencilla de lograr el nivel de control que nos interesa. Tanto la interfaz del Portal de administración como la Tarea de Chequeo de Integridad (incorporada, pero no programada) utilizan varios procesos, pero puede que no ofrezca un control suficiente para nuestros propósitos.*
Otras interfaces de chequeo de integridad, especialmente la interfaz de usuario del terminal, ^INTEGRIT o ^Integrity, así como Silent^Integrity, realizan el chequeo de integridad en un solo proceso. Por lo tanto, estas interfaces no completan el chequeo tan rápido como es posible conseguir, y utilizan menos recursos. Sin embargo, una ventaja es que sus resultados son visibles, se registran en un archivo o se envían al terminal, según se verifica cada *global*, y en un orden bien definido.
## E/S asíncronas
Un proceso de chequeo de integridad recorre cada bloque puntero de un *global*, uno cada vez, validando cada uno contra el contenido de los bloques de datos a los que apunta. Los bloques de datos se leen con E/S asíncrona para mantener un número de solicitudes de lectura sostenidos para que el subsistema de almacenamiento las procese, y la validación se va completando cada lectura.
En Linux, la E/S asíncrona solo es efectiva en combinación con la E/S directa, que no está habilitada de forma predeterminada hasta InterSystems IRIS 2020.3. Esto explica un gran número de casos en los que el chequeo de la integridad tarda demasiado tiempo en Linux. Afortunadamente, se puede habilitar en Cache 2018.1, IRIS 2019.1 y posteriores, al establecer **wduseasyncio=1** en la sección [config] del archivo .cpf y reiniciando. Este parámetro se recomienda en general para la escalabilidad de E/S en sistemas con mucha carga y es el predeterminado en plataformas que no son de Linux desde Caché 2015.2. Antes de habilitarlo, asegúrate de que has configurado suficiente memoria de caché de base de datos (global *buffers*) porque con Direct E/S, las bases de datos ya no serán almacenadas en la caché (de forma redundante) por Linux. Si no se activan, las lecturas realizadas por el chequeo de integridad se completan de forma sincróna y no se puede utilizar el almacenamiento de forma eficiente.
En todas las plataformas, el número de lecturas que un proceso de chequeo activa esta fijado en 8 por defecto. Si tienes que alterar la velocidad a la que un solo proceso de chequeo lee del disco, este parámetro se puede ajustar: hacia arriba para conseguir que un solo proceso se complete más rápido o hacia abajo para utilizar menos ancho de banda de almacenamiento. Ten en cuenta que:
* Este parámetro se aplica a cada proceso de chequeo de integridad. Cuando se utilizan varios procesos, el número de procesos multiplica este número de lecturas sostenidas. Cambiar el número de procesos de chequeo de integridad paralelos tiene un impacto mucho mayor y, por tanto, normalmente es lo primero que se hace. Cada proceso también está limitado por el tiempo computacional (entre otras cosas), por lo que aumentar el valor de este parámetro tiene un beneficio limitado.
* Esto solo funciona dentro de la capacidad del subsistema de almacenamiento para procesar lecturas simultáneas. Valores más altos no tienen ningún beneficio si las bases de datos se almacenan en una sola unidad local, mientras que una matriz de almacenamiento con striping a lo largo de docenas de unidades, puede procesar docenas de lecturas de forma simultánea.
Para ajustar este parámetro desde el namespace %SYS, **do SetAsyncReadBuffers^Integrity(**value**)**. Para ver el valor actual, **write $$GetAsyncReadBuffers^Integrity()**. El cambio tiene efecto cuando se verifica el siguiente *global*. La configuración no persiste tras un reinicio del sistema, aunque se puede añadir a SYSTEM^%ZSTART.
Hay un parámetro similar para controlar el tamaño máximo de cada lectura cuando los bloques son contiguos (o cercanos) en el disco. Este parámetro se necesita con menos frecuencia, aunque los sistemas con alta latencia de almacenamiento o bases de datos con tamaños de bloque más grandes podrían beneficiarse de un ajuste más fino. El valor tiene unidades de 64KB, por lo que un valor de 1 es 64KB, 4 es 256KB, etc. 0 (el valor predeterminado) permite que el sistema seleccione automáticamente,y, actualmente selecciona 1 (64KB). La función ^Integrity para este parámetro, paralela a las mencionadas anteriormente, son **SetAsyncReadBufferSize** y **GetAsyncReadBufferSize**.
## Aislamiento del Chequeo de integridad
Muchos sitios realizan chequeos periódicos de integridad directamente en el sistema de producción. Esto es lo más sencillo de configurar, pero no es lo ideal. Además de las preocupaciones sobre el impacto de el chequeo de integridad en el ancho de banda de almacenamiento, la actualización simultánea de la base de datos a veces puede conducir a errores de falsos positivos (a pesar de las mitigaciones incorporadas en el algoritmo de verificación). Como resultado, los errores reportados por una chequeo de integridad ejecutado en producción deben ser evaluados y/o verificados de nuevo por un administrador.
Con frecuencia, existe una mejor opción. Un snapshot del almacenamiento o una imagen de la copia de seguridad se pueden montar en otro servidor, donde una instancia aislada de Caché o IRIS ejecuta el chequeo de integridad. Esto no solo evita cualquier posibilidad de falsos positivos, sino que si el almacenamiento también se aísla de la producción, el chequeo de integridad se puede ejecutar para utilizar completamente el ancho de banda del almacenamiento y completarse mucho más rápido. Este enfoque encaja bien en el modelo donde el chequeo de integridad se utiliza para validar copias de seguridad; una copia de seguridad validada ratifica de forma efectiva la producción, desde el momento en que se hizo la copia de seguridad. Las plataformas en la nube y de virtualización también pueden facilitar el establecimiento de un entorno aislado utilizable a partir de un snapshot.
* * *
*La interfaz del Portal de Gestión, la tarea de Chequeo de integridad y el método IntegrityCheck de SYS.Database, seleccionan un número bastante grande de procesos (igual al número de núcleos de la CPU), sin que exista un control que puede ser necesario en muchas situaciones. El Portal de Gestión y la tarea también hacen un doble chequeo de cualquier global que haya informado de un error, en un intento por identificar falsos positivos, que pueden ser debidos a actualizaciones simultáneas. Este nuevo chequeo va más allá de la mitigación de falsos positivos incorporada en los algoritmos de verificación de integridad, y puede ser molesta en algunas situaciones, debido al tiempo adicional que requiere (el nuevo chequeo se ejecuta en un solo proceso y verifica todo el global). Este comportamiento se podrá modificar en el futuro.
Este artículo está etiquetado como "Mejores prácticas" ("Best practices")
(Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).
Artículo
Henry Pereira · 26 sep, 2021

Calma, calma, no estoy promoviendo una guerra contra las máquinas como en las películas de ciencia ficción, para evitar la dominación mundial de Ultron o Skynet.
Todavía no, todavía no 🤔
Os invito a retar a las máquinas a través de la creación de un juego muy sencillo usando ObjectScript con Python embebido.
Tengo que deciros que me emocioné mucho con la función de Python integrado en InterSystems IRIS. Es increíble el montón de posibilidades que se abren para crear aplicaciones fantásticas.
Vamos a construir un juego "tres en raya". Las reglas son bastante sencillas y creo que todo el mundo sabe jugar.
Es lo que me salvó del tedio en mi infancia, durante los largos viajes en coche con la familia antes de que los niños tuvieran teléfonos móviles o tabletas. ¡Nada como retar a mis hermanos a jugar unas partidas en el cristal borroso!
Así que... ¡abrochaos el cinturón y vámonos!
## Normas
Como he comentado, las reglas son bastante simples:
- solo 2 jugadores por set
- se juega por turnos en una cuadrícula de 3x3
- el jugador humano siempre será la letra X y la computadora la letra O
- los jugadores solo podrán poner las letras en los espacios vacíos
- el primero en completar una secuencia de 3 letras iguales en horizontal, o en vertical o en diagonal, es el ganador
- cuando se ocupen los 9 espacios, será un empate y el final de la partida

Todo el mecanismo y las reglas lo escribiremos en ObjectScript, el mecanismo del jugador de la máquina se escribirá en Python.
## Vamos a trabajar
Controlaremos el tablero en un *global*, en el que cada fila estará en un nodo y cada columna en una pieza.
Nuestro primer método es iniciar el tablero, para que sea fácil iniciaré el global ya con los nodos (filas A, B y C) y con las 3 piezas:
```
/// Iniciar un juego nuevo
ClassMethod NewGame() As %Status
{
Set sc = $$$OK
Kill ^TicTacToe
Set ^TicTacToe("A") = "^^"
Set ^TicTacToe("B") = "^^"
Set ^TicTacToe("C") = "^^"
Return sc
}
```
en este momento crearemos un método para añadir las letras en los espacios vacíos, para esto cada jugador dará la ubicación del espacio en el tablero.
Cada fila una letra y cada columna un número, para poner la X en el medio, por ejemplo, pasamos B2 y la letra X al método.
```
ClassMethod MakeMove(move As %String, player As %String) As %Boolean
{
Set $Piece(^TicTacToe($Extract(move,1,1)),"^",$Extract(move,2,2)) = player
}
```
Vamos a comprobar si la coordinación es válida, la forma más simple que veo es usando una expresión regular:
```
ClassMethod CheckMoveIsValid(move As %String) As %Boolean
{
Set regex = ##class(%Regex.Matcher).%New("(A|B|C){1}[0-9]{1}")
Set regex.Text = $ZCONVERT(move,"U")
Return regex.Locate()
}
```
Necesitamos garantizar que el espacio seleccionado está vacío.
```
ClassMethod IsSpaceFree(move As %String) As %Boolean
{
Quit ($Piece(^TicTacToe($Extract(move,1,1)),"^",$Extract(move,2,2)) = "")
}
```
¡Muy bien!
Ahora comprobamos si algún jugador ganó el set o si el juego ya está terminado, para esto creemos el método CheckGameResult.
Primero verificamos si hubo algún ganador completando por la horizontal, usaremos una lista con las filas y un simple $ Find resuelve
```
Set lines = $ListBuild("A","B","C")
// Check Horizontal
For i = 1:1:3 {
Set line = ^TicTacToe($List(lines, i))
If (($Find(line,"X^X^X")>0)||($Find(line,"O^O^O")>0)) {
Return $Piece(^TicTacToe($List(lines, i)),"^", 1)_" won"
}
}
```
Con otro *For* comprobamos la vertical
```
For j = 1:1:3 {
If (($Piece(^TicTacToe($List(lines, 1)),"^",j)'="") &&
($Piece(^TicTacToe($List(lines, 1)),"^",j)=$Piece(^TicTacToe($List(lines, 2)),"^",j)) &&
($Piece(^TicTacToe($List(lines, 2)),"^",j)=$Piece(^TicTacToe($List(lines, 3)),"^",j))) {
Return $Piece(^TicTacToe($List(lines, 1)),"^",j)_" won"
}
}
```
para comprobar la diagonal:
```
If (($Piece(^TicTacToe($List(lines, 2)),"^",2)'="") &&
(
(($Piece(^TicTacToe($List(lines, 1)),"^",1)=$Piece(^TicTacToe($List(lines, 2)),"^",2)) &&
($Piece(^TicTacToe($List(lines, 2)),"^",2)=$Piece(^TicTacToe($List(lines, 3)),"^",3)))||
(($Piece(^TicTacToe($List(lines, 1)),"^",3)=$Piece(^TicTacToe($List(lines, 2)),"^",2)) &&
($Piece(^TicTacToe($List(lines, 2)),"^",2)=$Piece(^TicTacToe($List(lines, 3)),"^",1)))
)) {
Return ..WhoWon($Piece(^TicTacToe($List(lines, 2)),"^",2))
}
```
por fin, comprobamos si hubo un empate
```
Set gameStatus = ""
For i = 1:1:3 {
For j = 1:1:3 {
Set:($Piece(^TicTacToe($List(lines, i)),"^",j)="") gameStatus = "Not Done"
}
}
Set:(gameStatus = "") gameStatus = "Draw"
```
¡Genial!
## Es hora de construir la máquina
Vamos a crear a nuestro oponente, necesitamos crear un algoritmo capaz de calcular todos los movimientos disponibles y usar una métrica para saber cuál es el mejor movimiento.
Lo ideal es utilizar un algoritmo de decisión llamado MiniMax ([Wikipedia: MiniMax](https://en.wikipedia.org/wiki/Minimax#Minimax_algorithm_with_alternate_moves))

El algoritmo MiniMax es una regla de decisión utilizada en teoría de juegos, teoría de decisiones e inteligencia artificial.
Básicamente, necesitamos saber cómo jugar asumiendo cuáles serán los posibles movimientos del oponente y coger el mejor escenario posible.
En detalle, tomamos la escena actual y comprobamos de forma recurrente el resultado del movimiento de cada jugador. En caso de que la máquina gane el juego, puntuamos con +1, en caso de que pierda, puntuamos con -1 y con 0 si empata.
Si no es el final del juego, abrimos otro árbol con el estado actual del juego. Después de eso, encontramos la jugada con el valor máximo para la máquina y el mínimo para el oponente.
Mira el siguiente gráfico - hay 3 movimientos disponibles: B2, C1 y C3.
Al elegir C1 o C3, el oponente tiene la oportunidad de ganar en el siguiente turno, pero si elige B2 no importa el movimiento que elija el oponente, la máquina gana la partida.
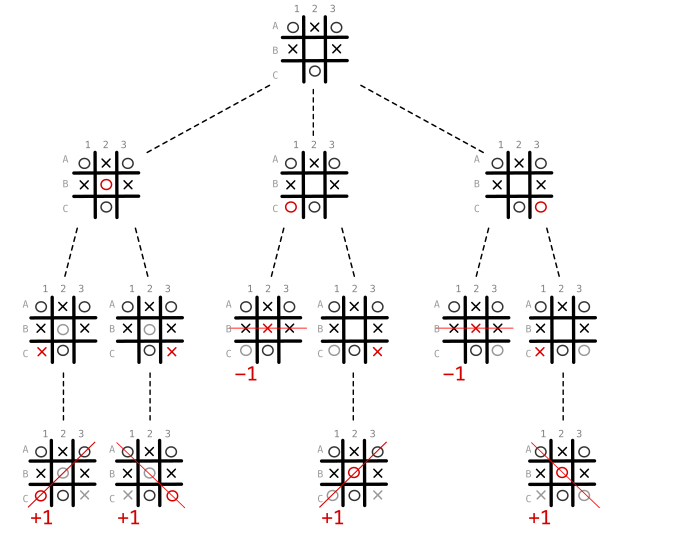
Es como tener la gema del tiempo en nuestras manos e intentar encontrar la mejor línea de tiempo.

Convirtiendo a Python
```python
ClassMethod ComputerMove() As %String [ Language = python ]
{
import iris
from math import inf as infinity
computerLetter = "O"
playerLetter = "X"
def isBoardFull(board):
for i in range(0, 8):
if isSpaceFree(board, i):
return False
return True
def makeMove(board, letter, move):
board[move] = letter
def isWinner(brd, let):
# check horizontals
if ((brd[0] == brd[1] == brd[2] == let) or \
(brd[3] == brd[4] == brd[5] == let) or \
(brd[6] == brd[7] == brd[8] == let)):
return True
# check verticals
if ((brd[0] == brd[3] == brd[6] == let) or \
(brd[1] == brd[4] == brd[7] == let) or \
(brd[2] == brd[5] == brd[8] == let)):
return True
# check diagonals
if ((brd[0] == brd[4] == brd[8] == let) or \
(brd[2] == brd[4] == brd[6] == let)):
return True
return False
def isSpaceFree(board, move):
#Retorna true se o espaco solicitado esta livre no quadro
if(board[move] == ''):
return True
else:
return False
def copyGameState(board):
dupeBoard = []
for i in board:
dupeBoard.append(i)
return dupeBoard
def getBestMove(state, player):
done = "Done" if isBoardFull(state) else ""
if done == "Done" and isWinner(state, computerLetter): # If Computer won
return 1
elif done == "Done" and isWinner(state, playerLetter): # If Human won
return -1
elif done == "Done": # Draw condition
return 0
# Minimax Algorithm
moves = []
empty_cells = []
for i in range(0,9):
if state[i] == '':
empty_cells.append(i)
for empty_cell in empty_cells:
move = {}
move['index'] = empty_cell
new_state = copyGameState(state)
makeMove(new_state, player, empty_cell)
if player == computerLetter:
result = getBestMove(new_state, playerLetter)
move['score'] = result
else:
result = getBestMove(new_state, computerLetter)
move['score'] = result
moves.append(move)
# Find best move
best_move = None
if player == computerLetter:
best = -infinity
for move in moves:
if move['score'] > best:
best = move['score']
best_move = move['index']
else:
best = infinity
for move in moves:
if move['score'] < best:
best = move['score']
best_move = move['index']
return best_move
lines = ['A', 'B', 'C']
game = []
current_game_state = iris.gref("^TicTacToe")
for line in lines:
for cell in current_game_state[line].split("^"):
game.append(cell)
cellNumber = getBestMove(game, computerLetter)
next_move = lines[int(cellNumber/3)]+ str(int(cellNumber%3)+1)
return next_move
}
```
Primero, convierto el *global* en una matriz simple, ignorando columnas y filas, dejándolo plano para facilitar.
En cada movimiento analizado llamamos al método copyGameState que, como su nombre indica, copia el estado del juego en ese momento, donde aplicamos el MiniMax.
El método getBestMove que se llamará repetidamente hasta que finalice el juego encontrando un ganador o un empate.
Primero se mapean los espacios vacíos y verificamos el resultado de cada movimiento, cambiando entre los jugadores.
Los resultados se almacenan en *move* ['puntuación'] para, después de comprobar todas las posibilidades, encontrar el mejor movimiento.
¡Espero que os haya divertido! Es posible mejorar la inteligencia usando algoritmos como Alpha-Beta Pruning ([Wikipedia: AlphaBeta Pruning](https://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning)) o redes neuronales. ¡Solo tened cuidado de no darle vida a Skynet!

No dudeis en dejar cualquier comentario o pregunta.
¡Esto es todo, amigos!
Código fuente completo:
[InterSystems Iris version 2021.1.0PYTHON](https://gist.github.com/henryhamon/5be7e2147955bec0f623b718cfd83a9d) Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Luis Angel Pérez Ramos · 25 mayo, 2023
# Introducción
El propósito de este artículo es ofrecer una visión general de InterSystems IRIS FHIR Accelerator Service (FHIRaaS), motivado por la implementación de la aplicación iris-on-fhir, disponible en OEX y desarrollada para el concurso FHIRaaS.
Es un tutorial básico que os guiará en la configuración de una función para la implementación de FHIRaaS, incluyendo una clave API y un servidor OAuth 2.0.
También mostraré brevemente una librería para utilizar recursos FHIR a través de FHIRaaS.
Por último, en artículos posteriores explicaré algunas características de la aplicación iris-on-fhir. Podéis consultar el código completo en el repositorio github de la aplicación.
Este contenido se presentará en una serie de 3 artículos.
Este primer artículo parece un poco largo, pero no os preocupéis - es porque coloqué muchas imágenes, para ayudaros con los pasos de la configuración.
# FHIRaaS
IRIS ya proporciona un entorno API FHIR [integrado en IRIS for Health e IRIS Health Connect](https://www.intersystems.com/fhir/#our-products-support-fhir).
Pero, si queréis aprovechar el entorno fiable, seguro y de bajo mantenimiento que pueden ofrecer los servicios en la nube, ahora podéis contar con [InterSystems IRIS FHIR Accelerator Service (FHIRaaS)](https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=FAS_intro).
FHIRaaS es una infraestructura FHIR lista para usarse, basada en servicios en la nube. Solo hay que configurar una implementación y empezar a utilizar la API FHIR en las aplicaciones dondequiera que estén: cliente JS (SMART en FHIR), backend tradicional o aplicaciones sin servidor.
Para solicitar una prueba gratuita de FHIRaaS, poneos en contacto con InterSystems.
## Configurar una implementación
Después de iniciar sesión, haced clic en el botón “CREATE NEW DEPLOYMENT”.
Hay que seguir varios pasos. El primero es seleccionar el tamaño de la implementación. En el momento de escribir este artículo, FHIRaaS solo ofrece una opción. Así que simplemente hay que pulsar el botón “CONTINUE”.
El siguiente paso es elegir el proveedor de servicios en la nube que se va a utilizar. De nuevo, solo había una opción disponible cuando se redactó este artículo: AWS.
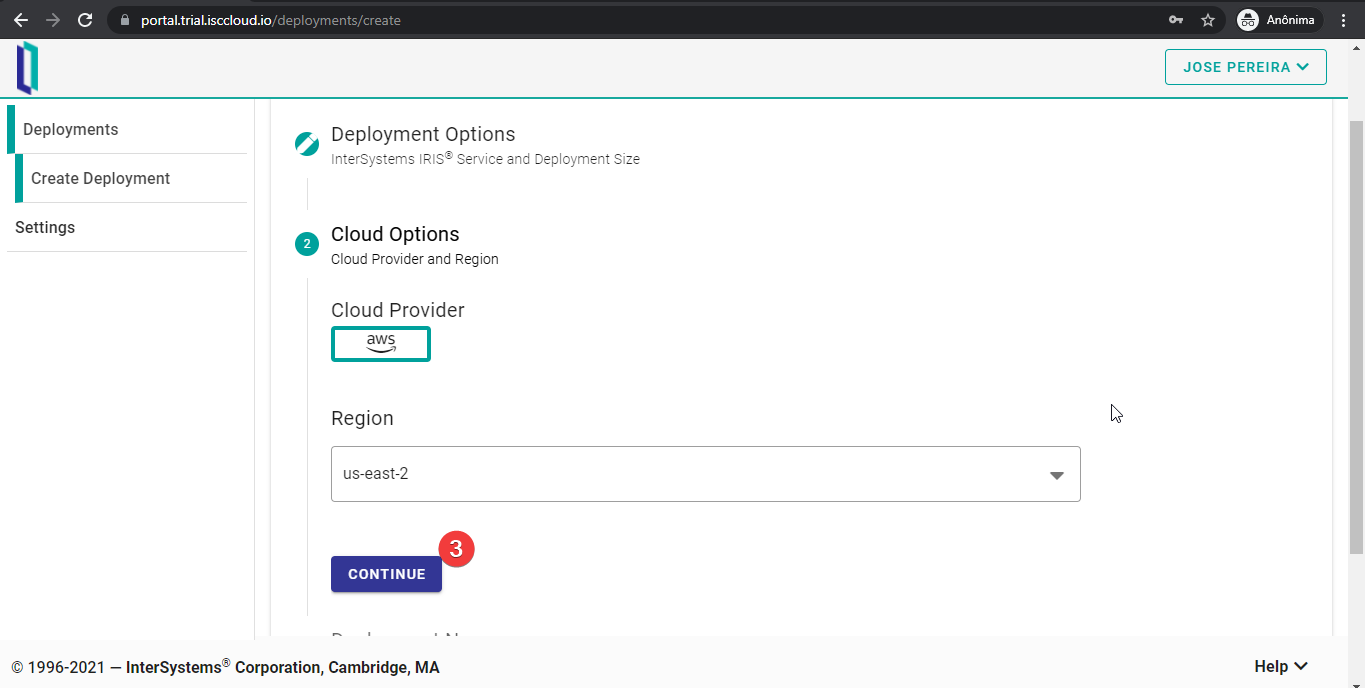
La última configuración es tan solo el nombre de la implementación. Hay algunas reglas para este nombre, de las que la interfaz de usuario de FHIRaaS alerta cuando se pone un nombre que no sea válido. Además, tened en cuenta que no se puede cambiar este nombre después de esta configuración. Pulsad el botón “CONTINUE” después de elegir el nombre.
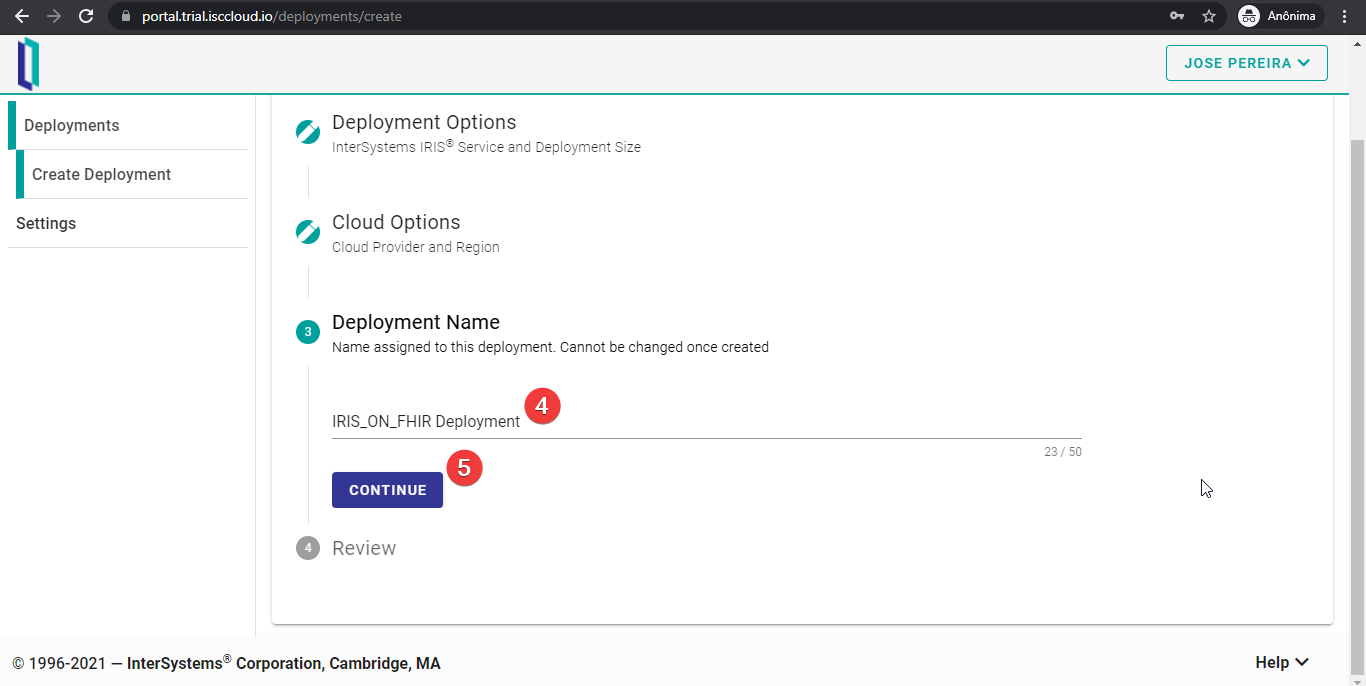
Por último, revisad la configuración e iniciad la implementación de FHIRaaS pulsando el botón “CREATE”.
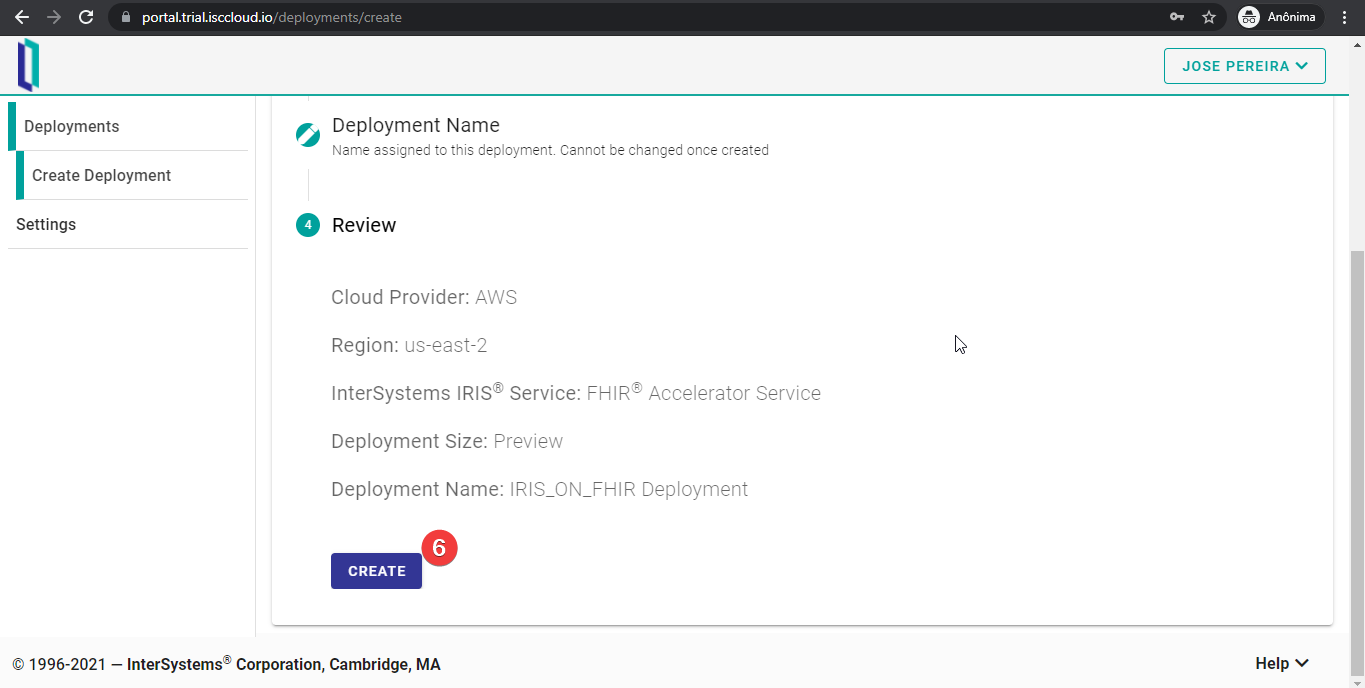
Si todo funciona correctamente, recibiréis un agradable mensaje, indicando que vuestra implementación de FHIRaaS se está generando. Esperad unos minutos hasta que finalice este proceso.
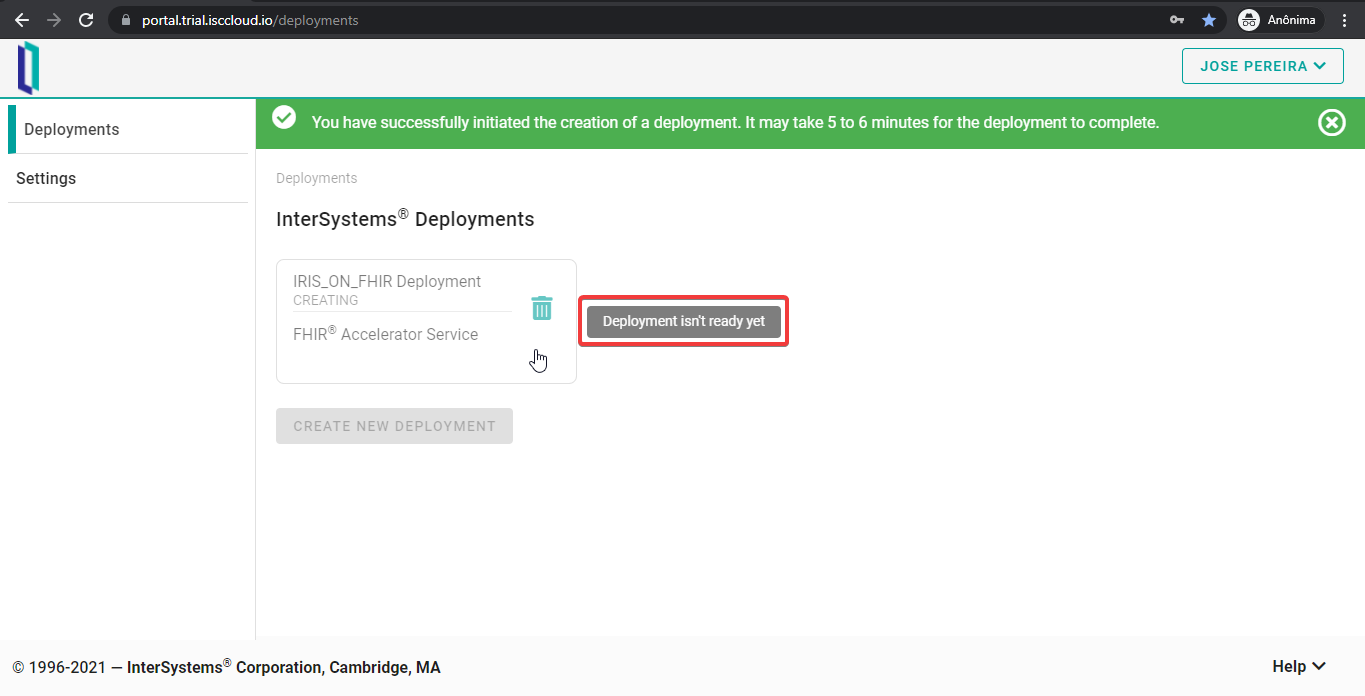
Después de unos minutos, vuestra implementación de FHIRaaS está lista para su uso. Simplemente pulsad el botón de implementación y empezad a utilizarlo.
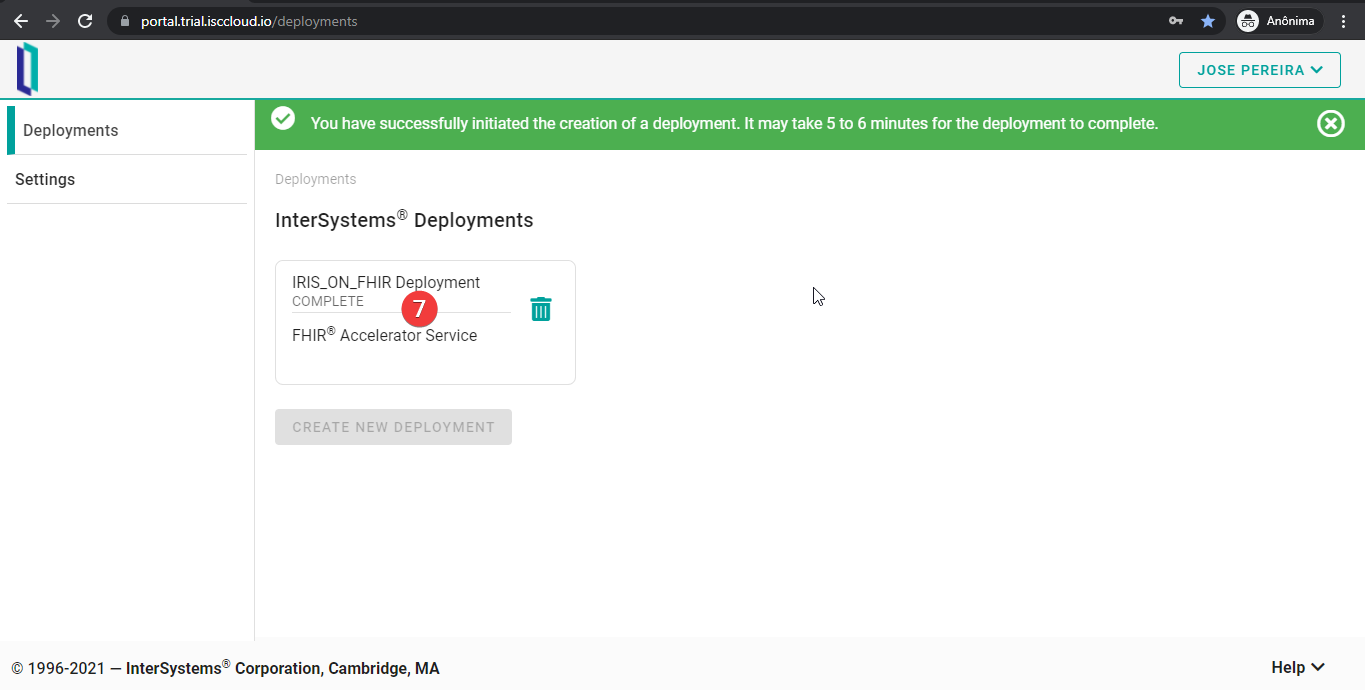
Después de pulsar el botón de implementación, aparecerá la pestaña “Overview”. Tened en cuenta que hay varias pestañas. En este artículo solo trataremos las pestañas “OAuth 2.0”, “Credentials” y “API Development”. Pero esto solo es debido a un tema de alcance del artículo - las otras no son complicadas en absoluto y las podéis explorar fácilmente.
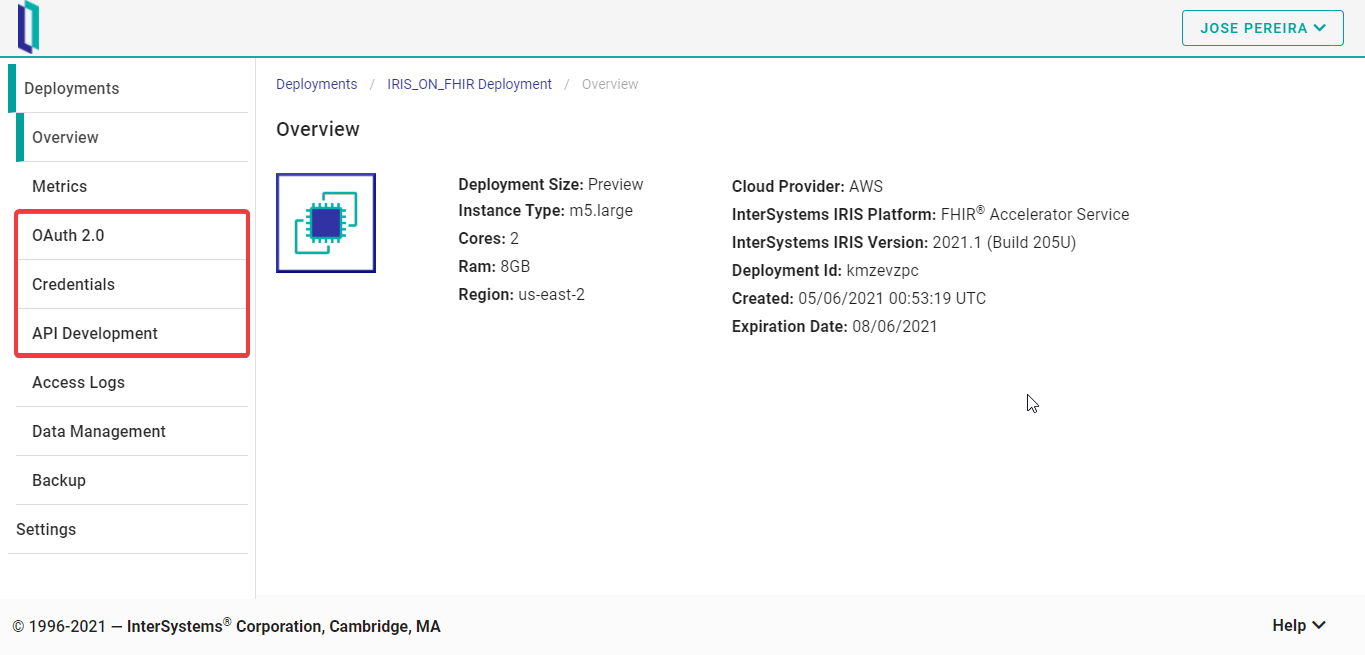
## Control de acceso
FHIRaaS es compatible con dos formas de controlar el acceso: API Key y OAuth 2.0. Veamos cada una de ellas.
### Claves API (API Key)
Las claves API son *tokens* generados por FHIRaaS que permiten que las aplicaciones interactúen con la API sin la interacción del usuario. Esto hace que sea el método ideal para la comunicación entre el servidor FHIRaaS y aplicaciones autorizadas de terceros, como una API de chatbot, por ejemplo.
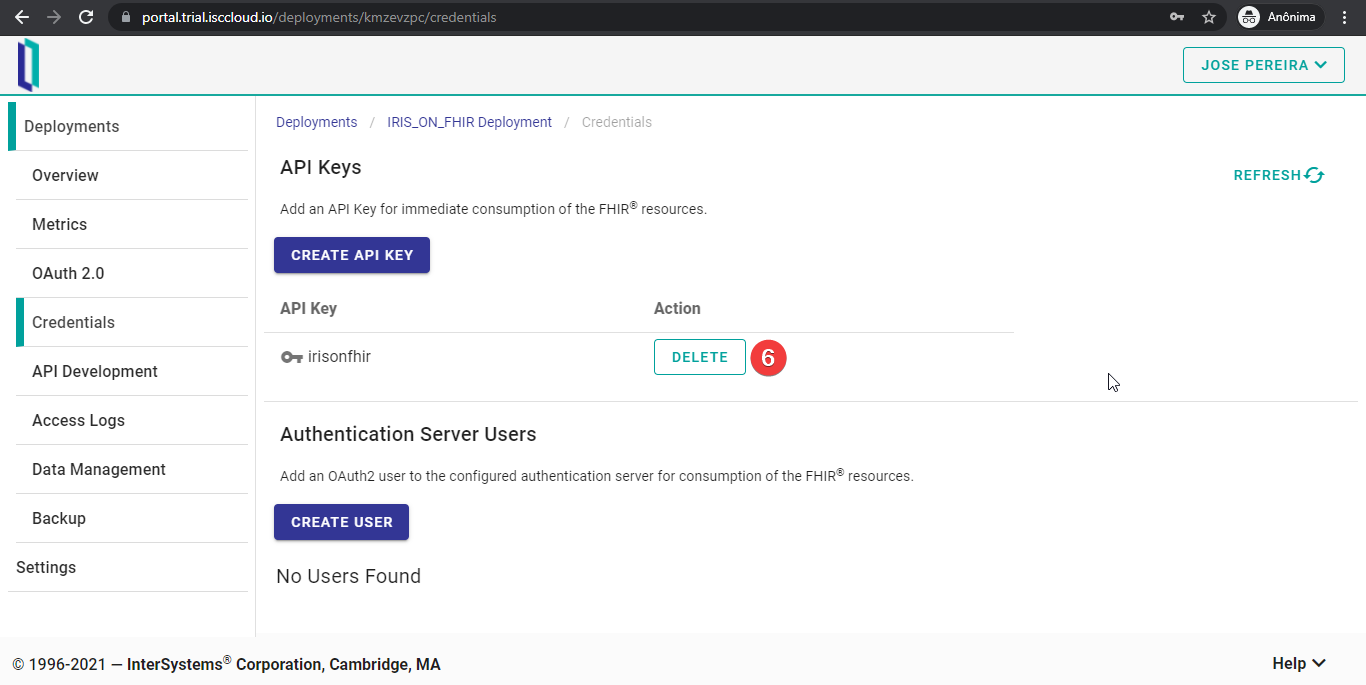
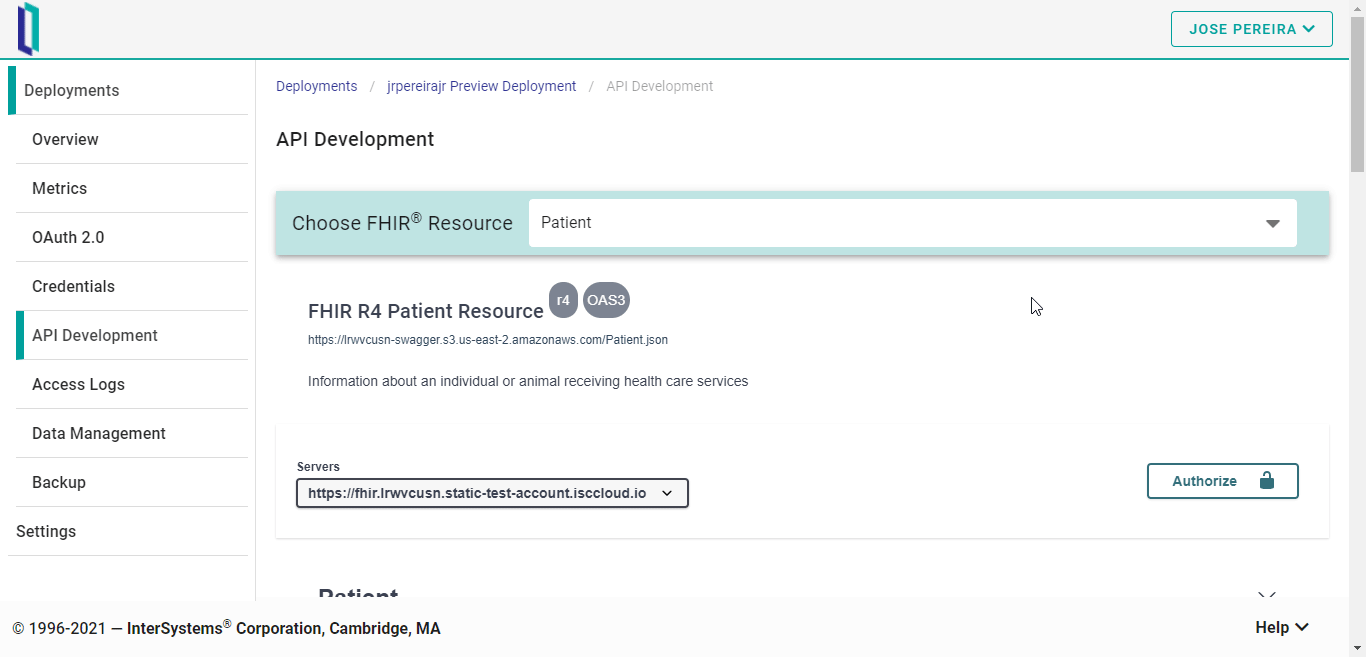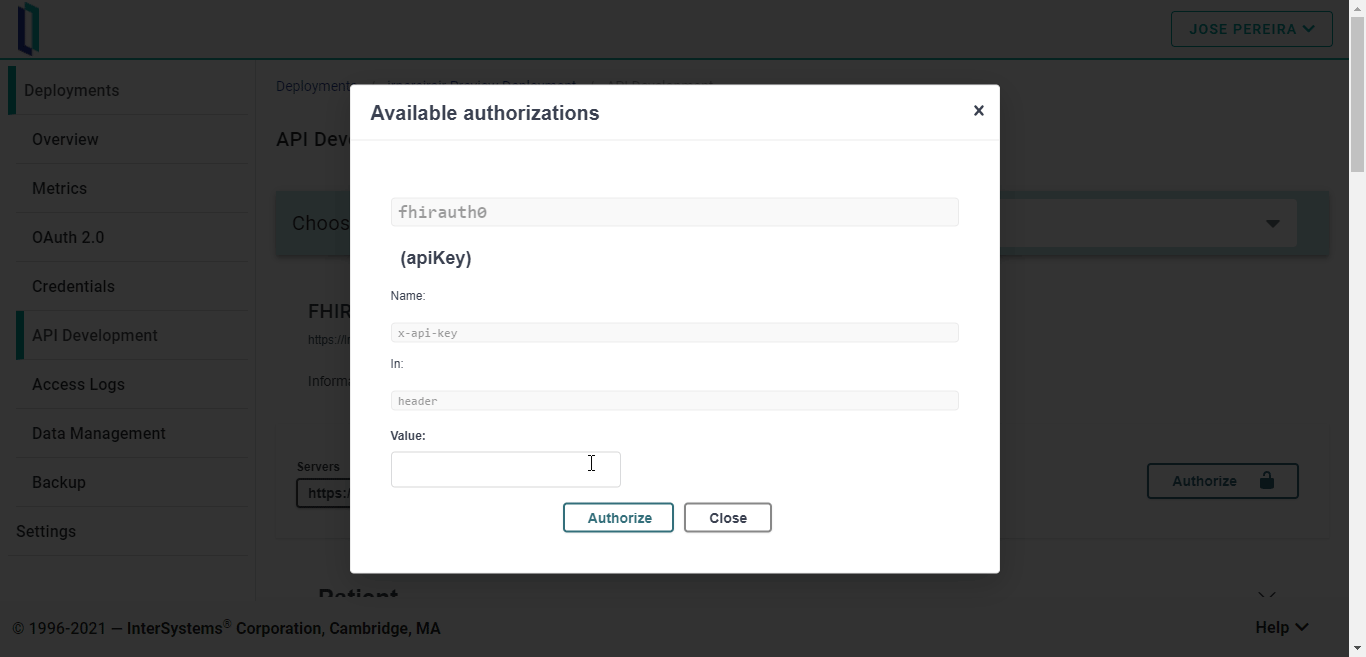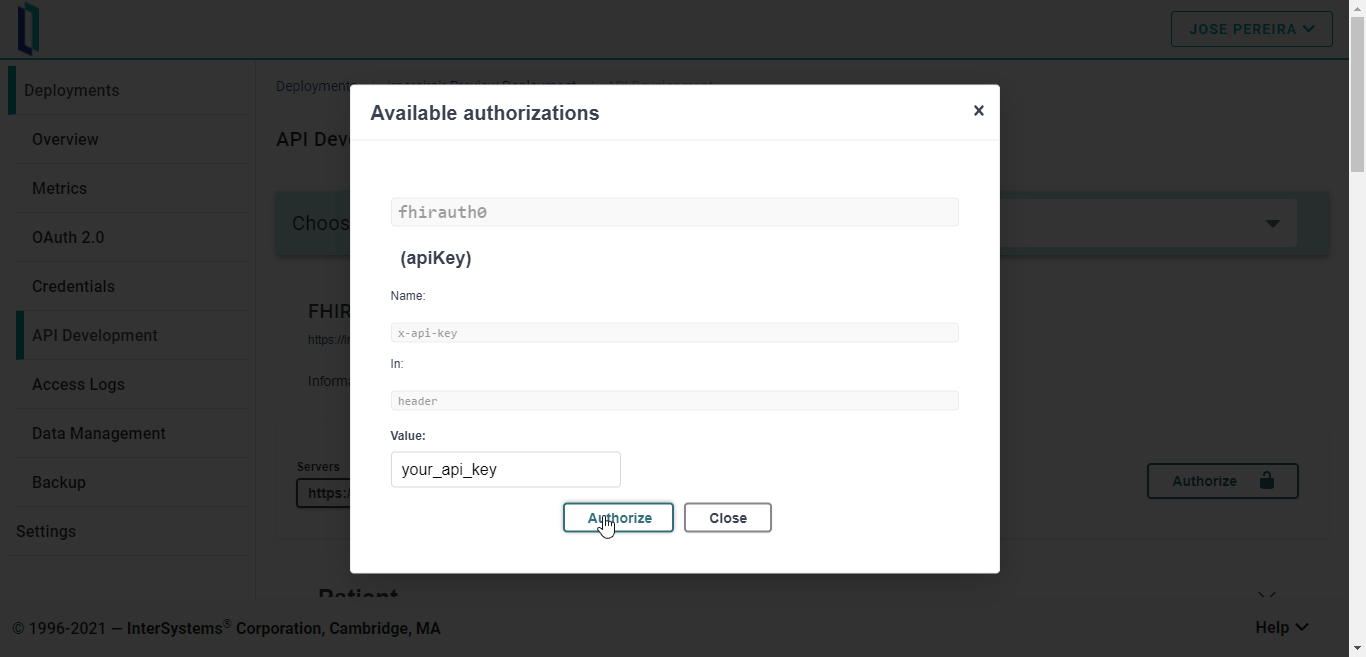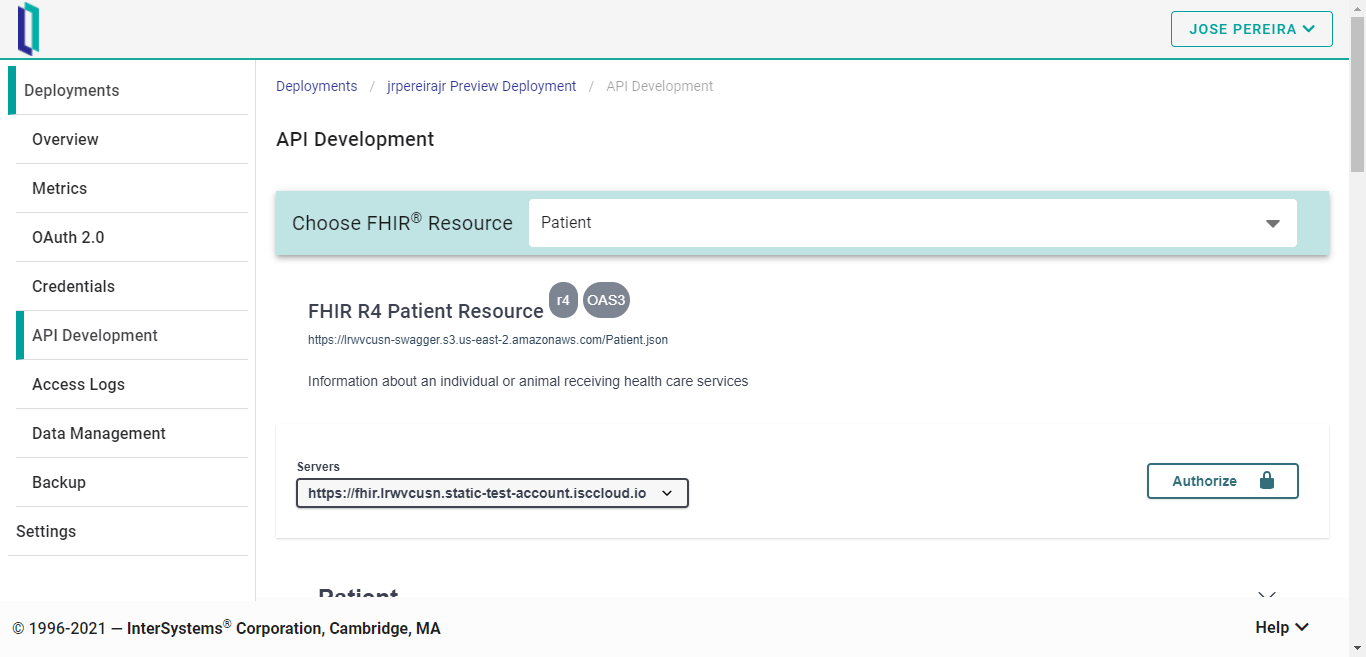
Para crear una clave API, hay que ir a la pestaña “Credentials” y hacer clic en “CREATE API KEY”.
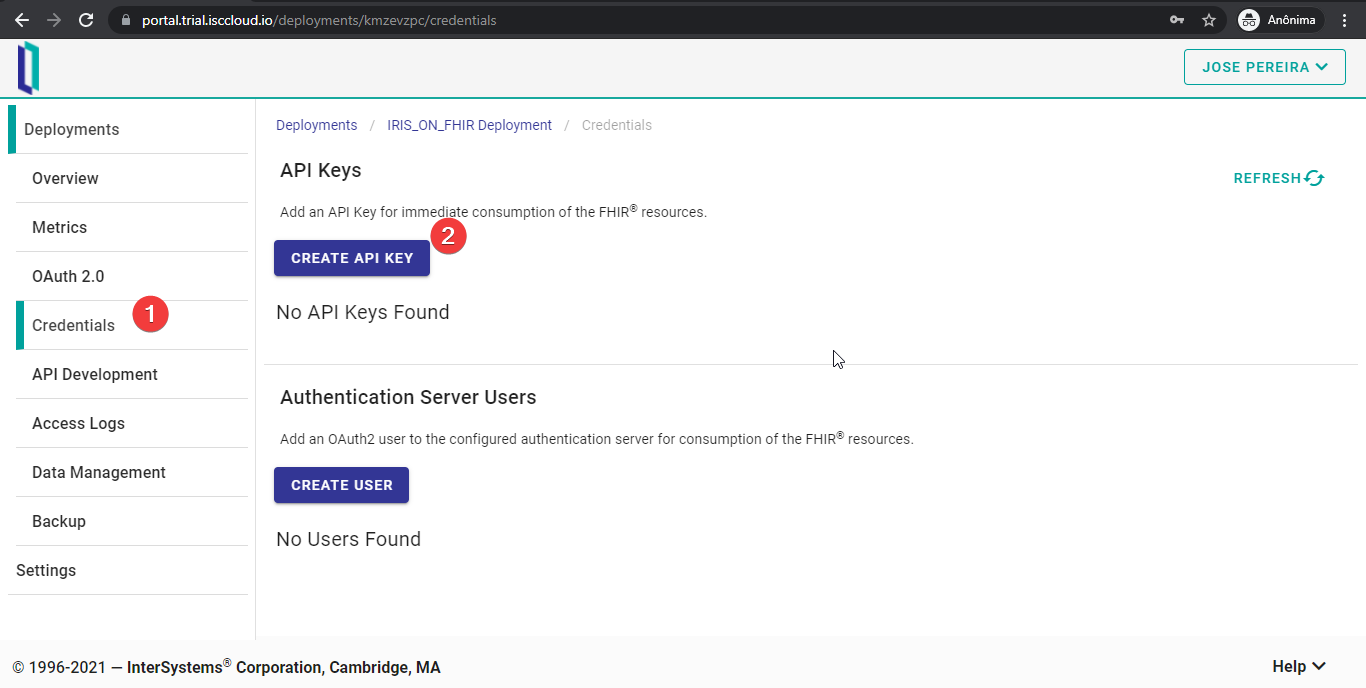
Después, hay que elegir un nombre para la clave API y presionar “ADD”.
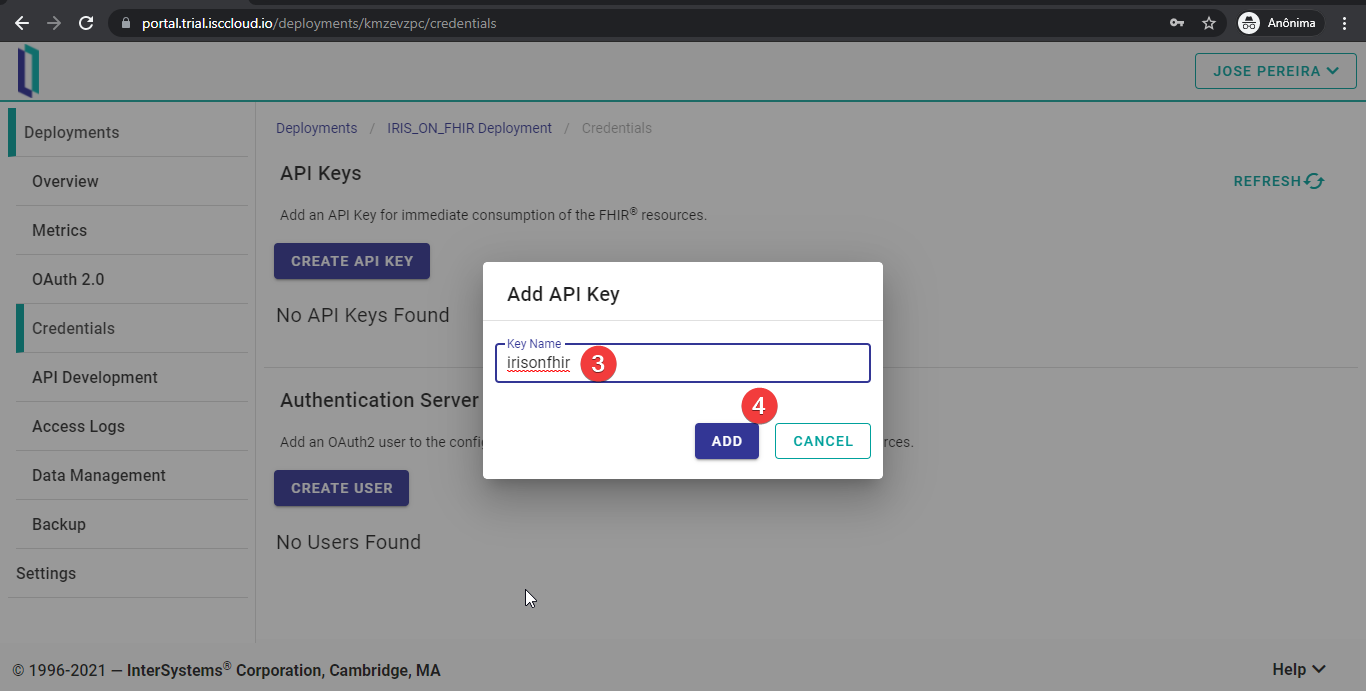
¡Genial! ¡Ya está creada la clave API! Copiadla y guardadla en un lugar seguro, ya que ya no podréis volver a acceder a esta información.
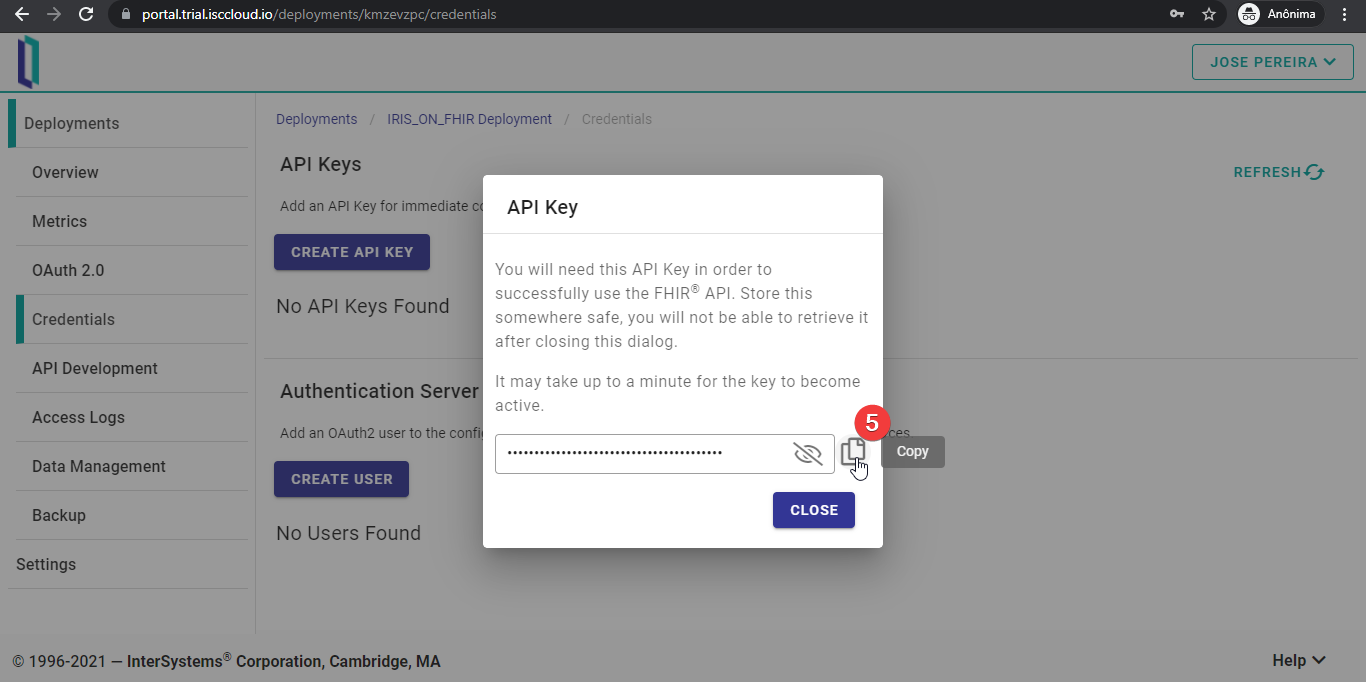
Después de creada, una clave API solo se puede eliminar.
Para utilizar esta clave API, solo hay que añadir un encabezado x-api-key a una solicitud HTTP. Por ejemplo:
```
curl -X GET "https://fhir.lrwvcusn.static-test-account.isccloud.io/Patient" -H "accept: application/fhir+json" -H "x-api-key: your-apy-key"
```
### OAuth 2.0 - Crear un servidor OAuth 2.0 y añadir usuarios a él
Como comenté anteriormente, una clave API es adecuada cuando se necesita utilizar la API sin la interacción del usuario. Pero cuando se crea una aplicación para los usuarios, OAuth 2.0 y OpenID Connect son actualmente el estándar del sector para la autenticación y la autorización.
Solo un comentario: a pesar de que OAuth 2.0 y OpenID Connect se pueden utilizar de forma independiente, es muy habitual ver ambos funcionando uno junto al otro. Así que cuando menciono OAuth 2.0 aquí, me refiero a OAuth 2.0 para la autorización y OpenID connect para la autenticación.
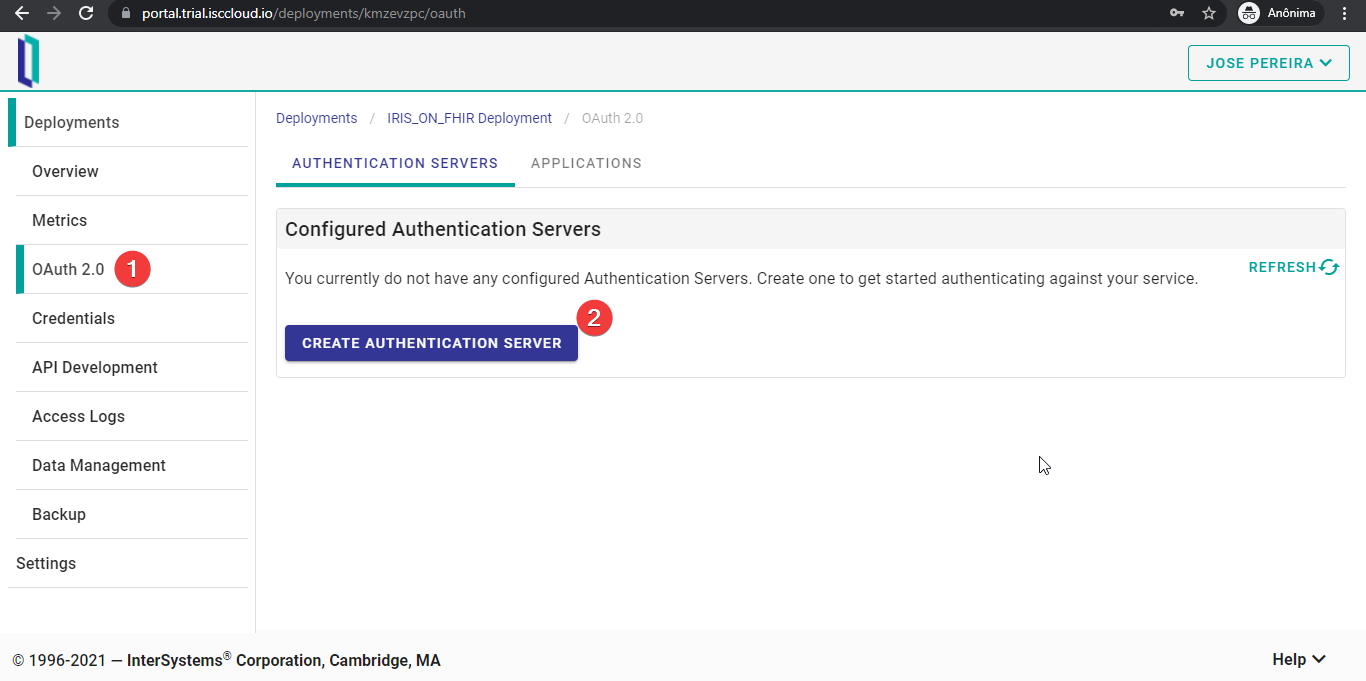
Vamos a configurar un servidor OAuth 2.0. Primero, hay que ir a la pestaña “OAuth 2.0” y hacer clic en “CREATE AUTHENTICATION SERVER”.
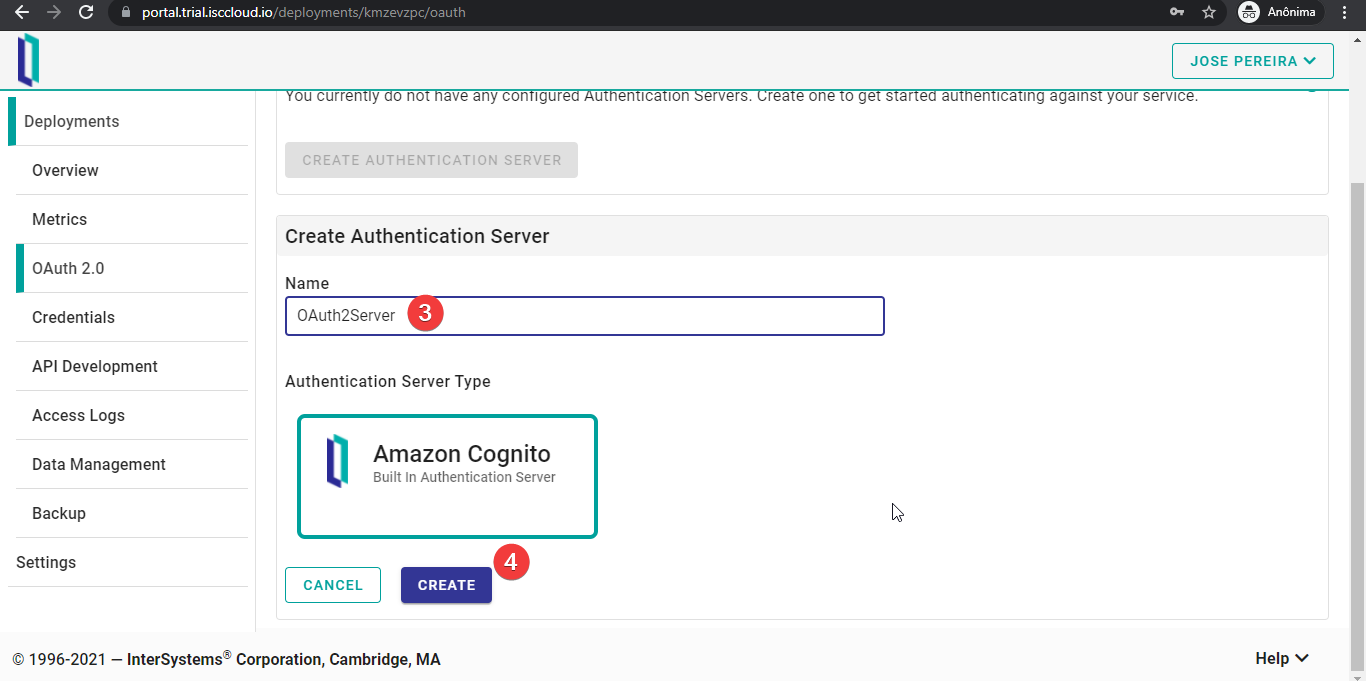
El siguiente paso es elegir un nombre para el servidor OAuth 2.0 y seleccionar qué proveedor de identidad (IdP) se quiere utilizar. En el momento que escribo este artículo, FHIRaaS solo admite AWS Cognito como IdP. Así que solamente hay que hacer clic en "CREATE".
Si la solicitud se completó correctamente, recibiréis un mensaje como el de la imagen siguiente. Ahora podéis añadir usuarios a vuestro IdP haciendo clic en “ADD USER”.
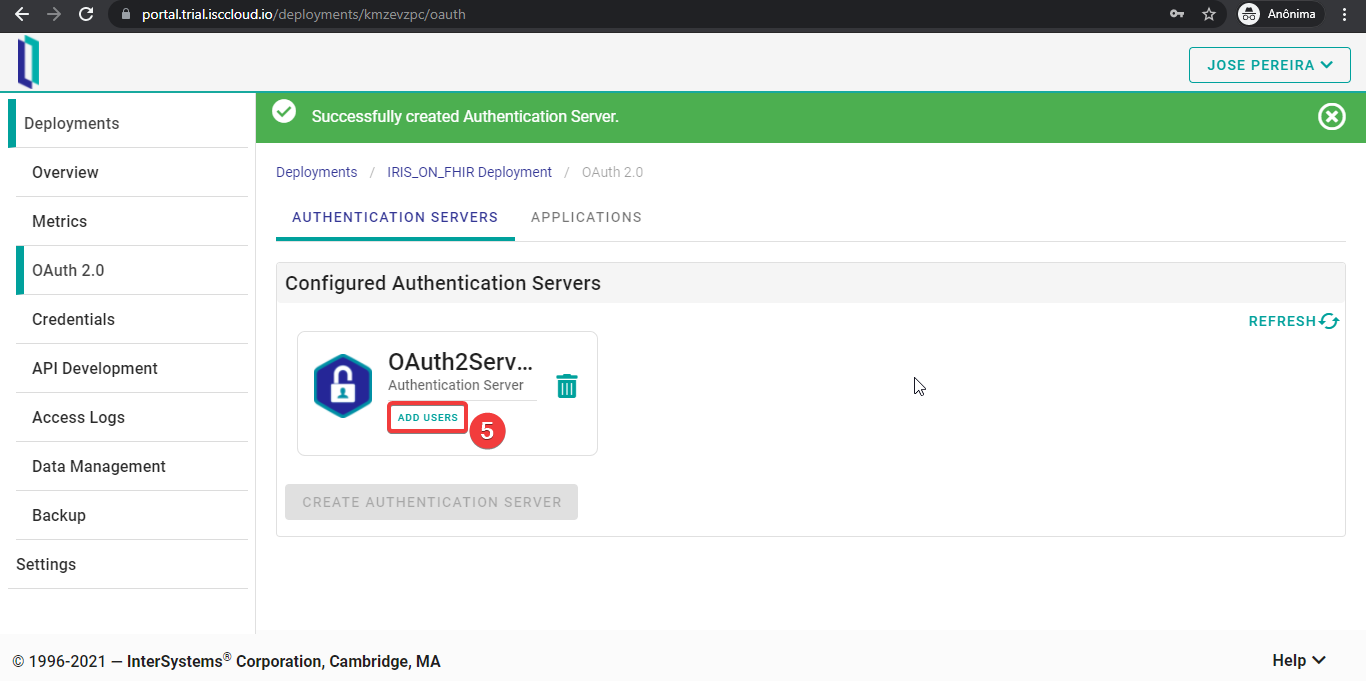
Seréis redirigidos a la pestaña “Credentials”. Para añadir un usuario, pulsad el botón “CREATE USER”.
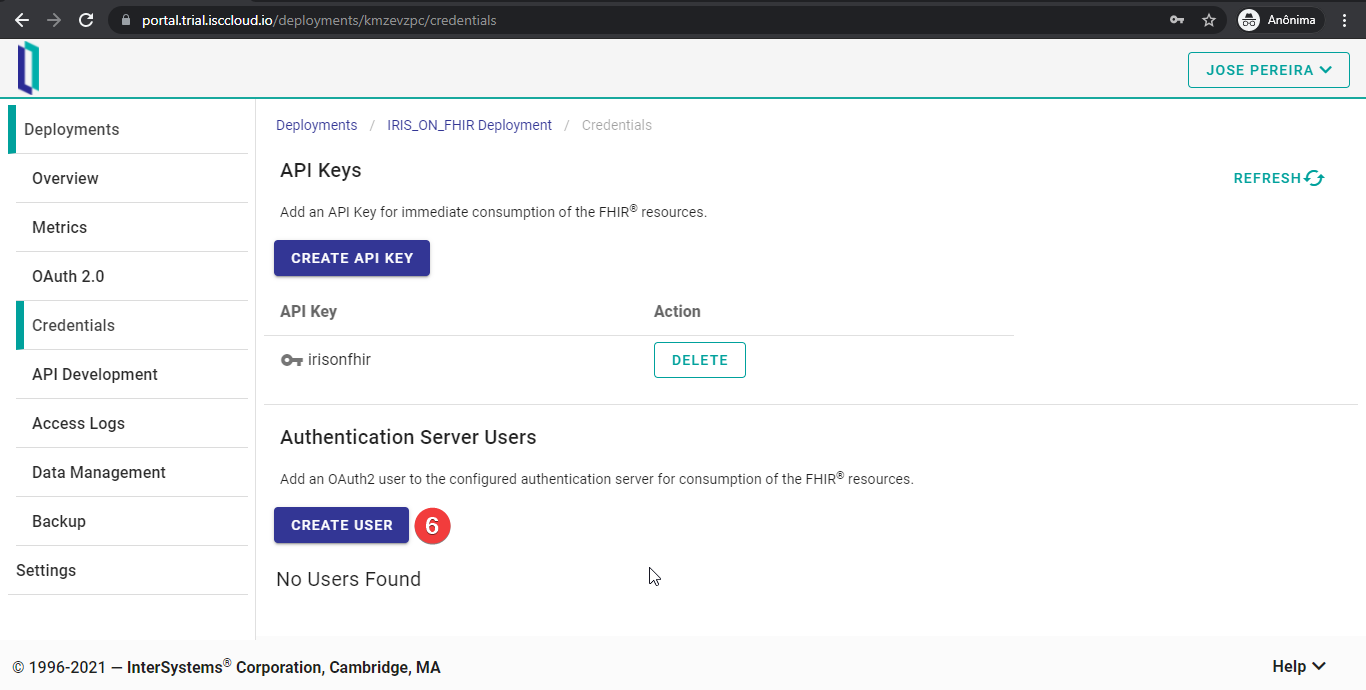
Introducid el nombre de usuario y la contraseña y haced clic en "CREATE".
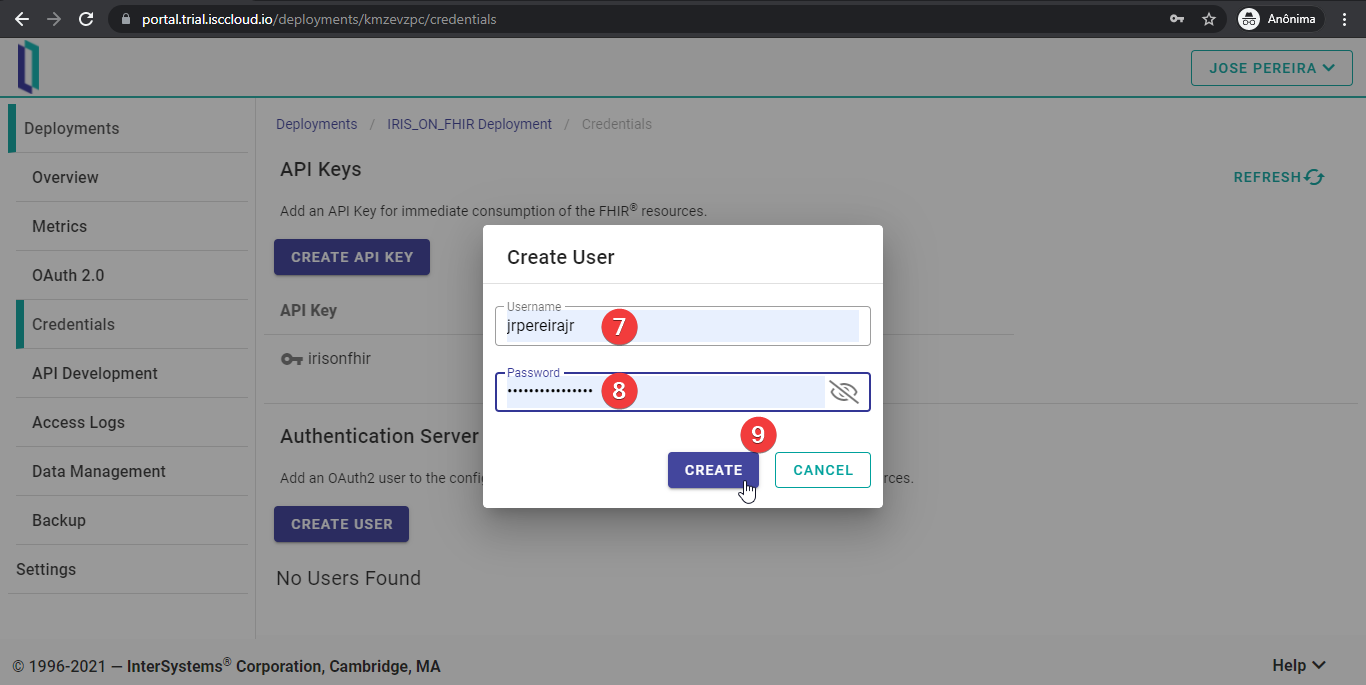
Si todo se ejecuta correctamente, podréis ver un usuario creado en vuestro IdP. Este usuario ya puede iniciar sesión en las aplicaciones autorizadas por este servidor OAuth 2.0.
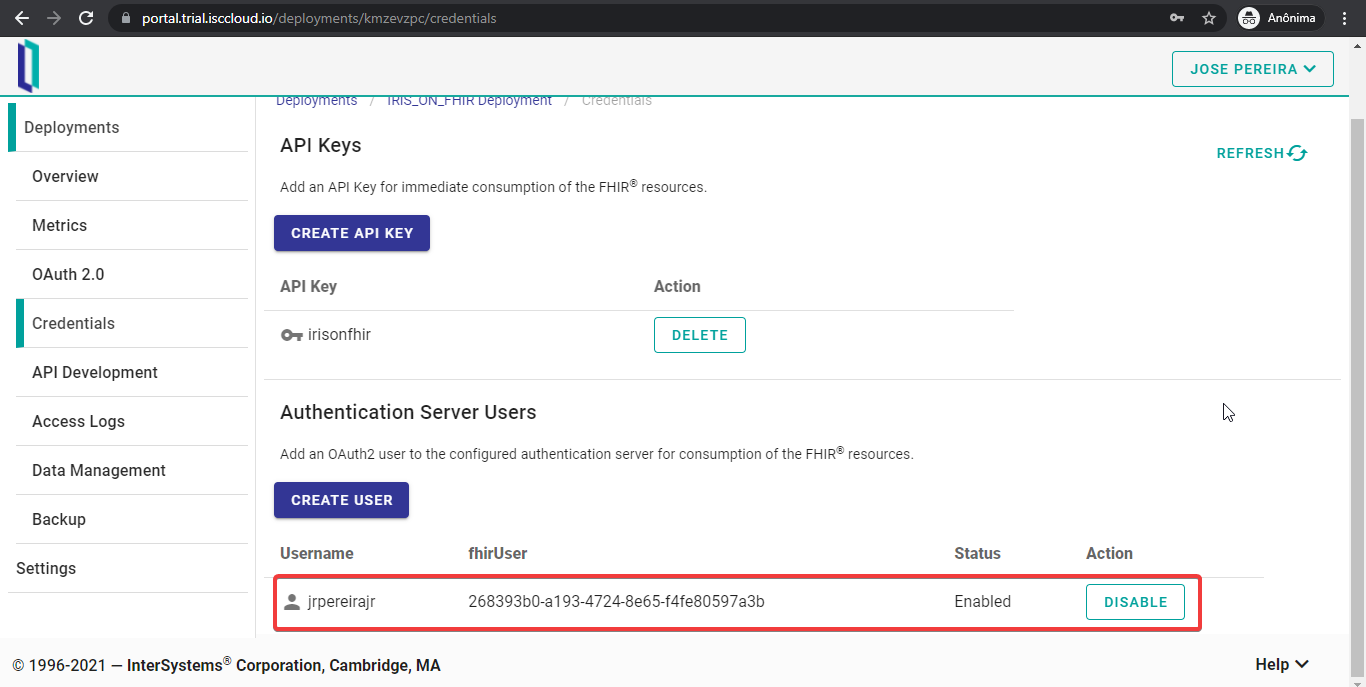
### OAuth 2.0 - Añadir aplicaciones al servidor OAuth 2.0
Después de crear un servidor OAuth 2.0 y añadir usuarios al mismo, dichos usuarios podrán utilizar las aplicaciones autorizadas por este servidor. Ahora, añadiremos una aplicación al servidor.
Primero, hay que ir a la pestaña “OAuth 2.0”, después a la pestaña “Application” y hacer clic en “CREATE APPLICATION”.
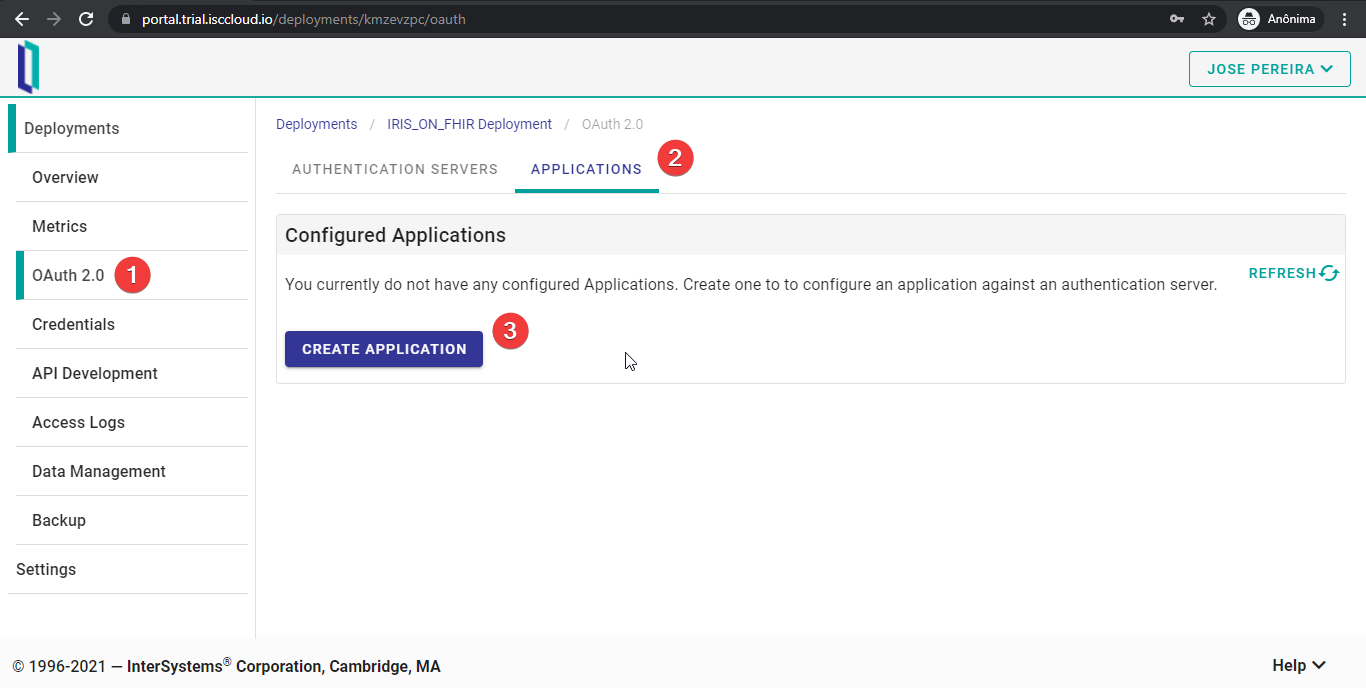
Después, elegid un nombre para vuestra aplicación en el servidor y el servidor OAuth 2.0 que se acaba de crear. Las URL deben apuntar a vuestra aplicación. “Redirect URL” es la dirección de destino cuando los usuarios inician sesión correctamente. “Logout URL” es la página a la que se redirecciona a los usuarios cuando utilicen el IdP para cerrar sesión.
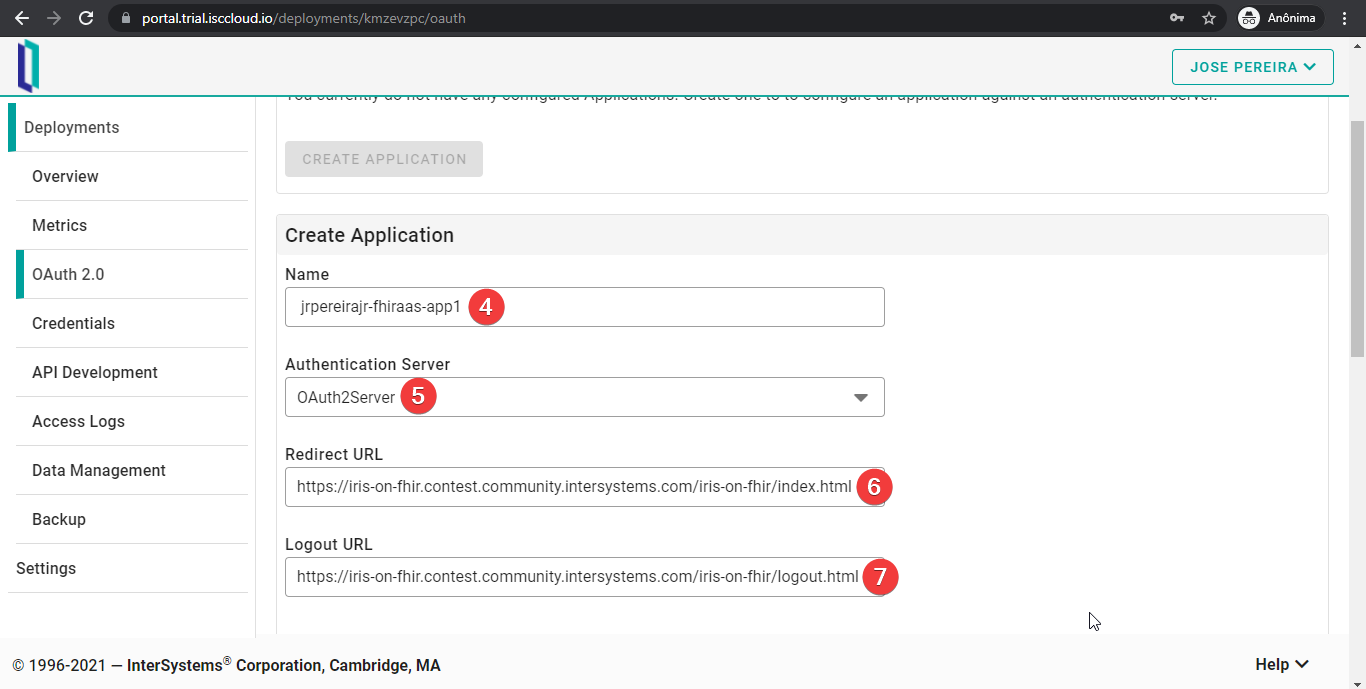
Durante el desarrollo, podéis redirigir a localhost, pero, por supuesto, para producción tenéis que proporcionar una URL accesible desde Internet.
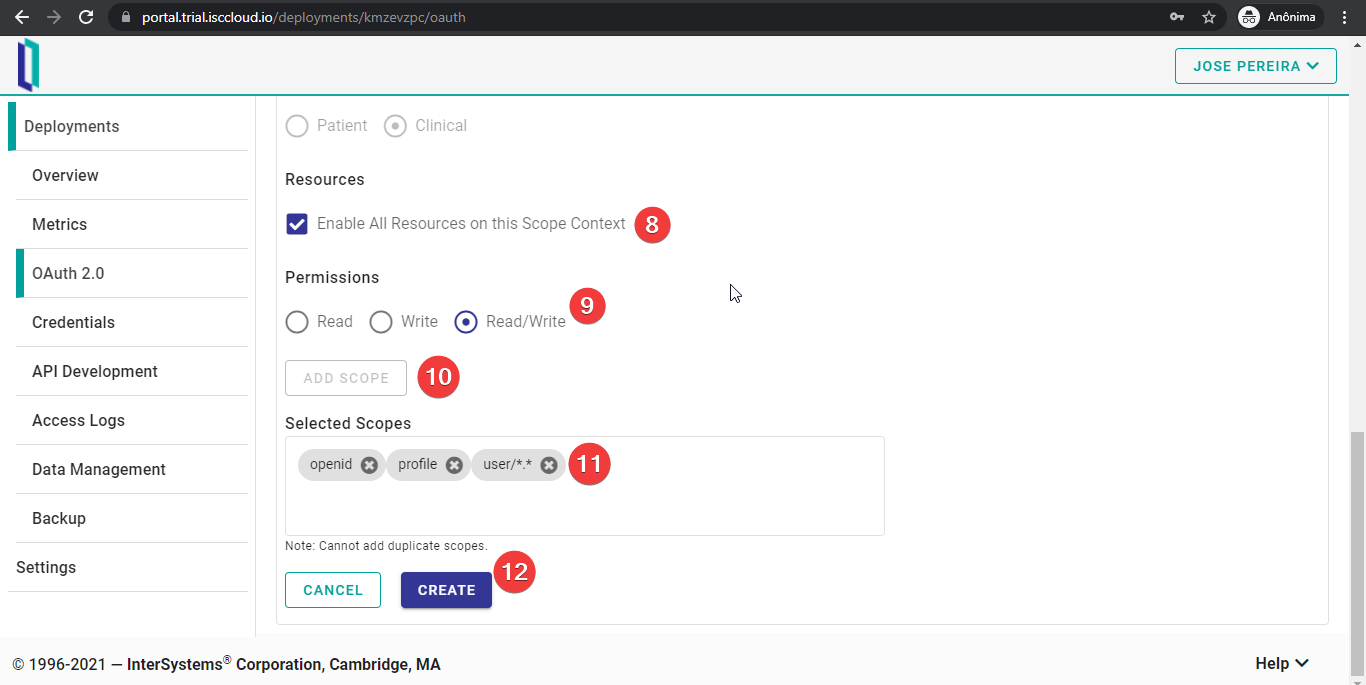
Los pasos finales consisten en elegir los recursos FHIR ("scopes") que los usuarios deben aceptar compartir con la aplicación. Para esta sencilla prueba, se solicitan todos los recursos, pero en las aplicaciones reales, se puede controlar cada recurso FHIR, como si la aplicación solo pudiera leer, solo escribir o ambas opciones. Si los usuarios no están de acuerdo con esta solicitud de autorización, el servidor OAuth 2.0 rechazará el acceso a dichos recursos.
Después de configurar correctamente los recursos, haced clic en “CREATE”.
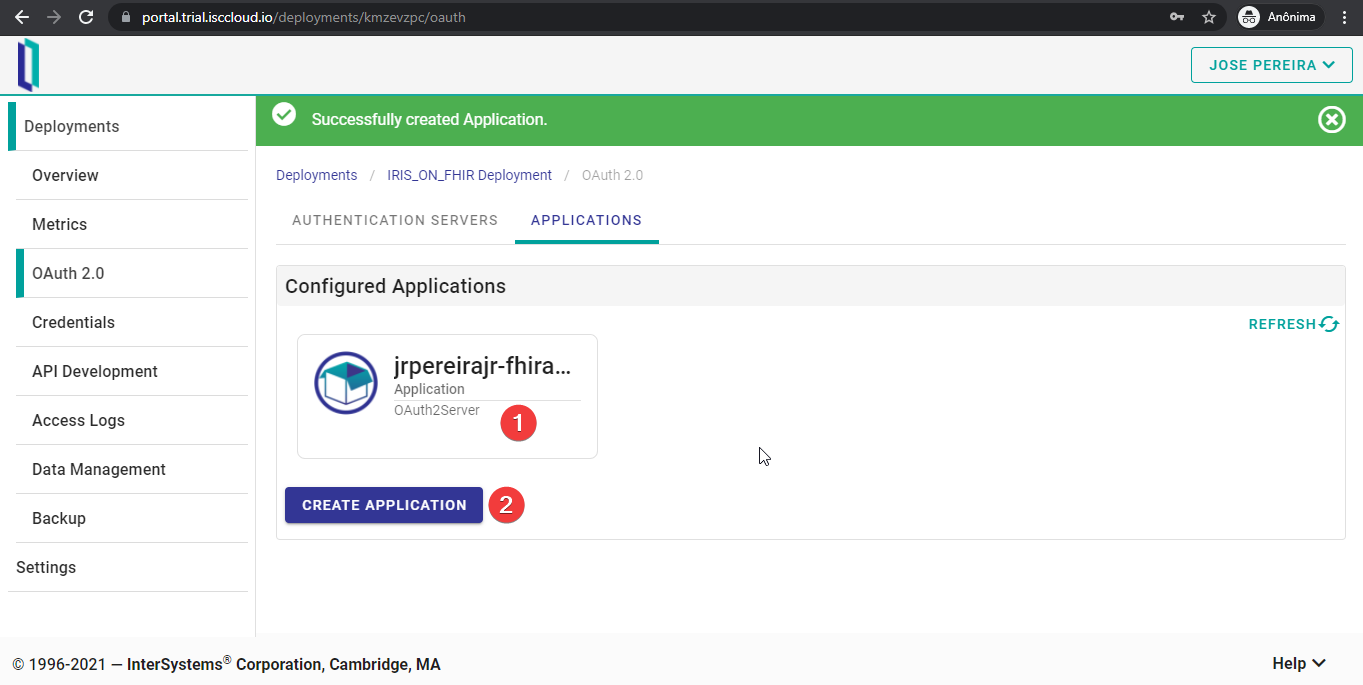
Si todo funciona correctamente, veréis un mensaje en color verde. Ahora, podéis comprobar los parámetros de vuestra nueva aplicación o eliminarla haciendo clic en la casilla de la aplicación. También podéis crear más aplicaciones si lo necesitáis.
## Desarrollo de API
Una excelente funcionalidad de FHIRaaS es la pestaña Desarrollo de API. Ofrece un explorador de especificaciones OpenAPI de la API FHIR, lo que permite probar fácilmente todas las funciones de FHIR.
Para acceder a ella, haced clic en “API Development”. Cuando se haya cargado, podréis seleccionar qué recurso FHIR queréis explorar. Tened en cuenta que FHIRaaS ofrece la versión R4 para los recursos FHIR.
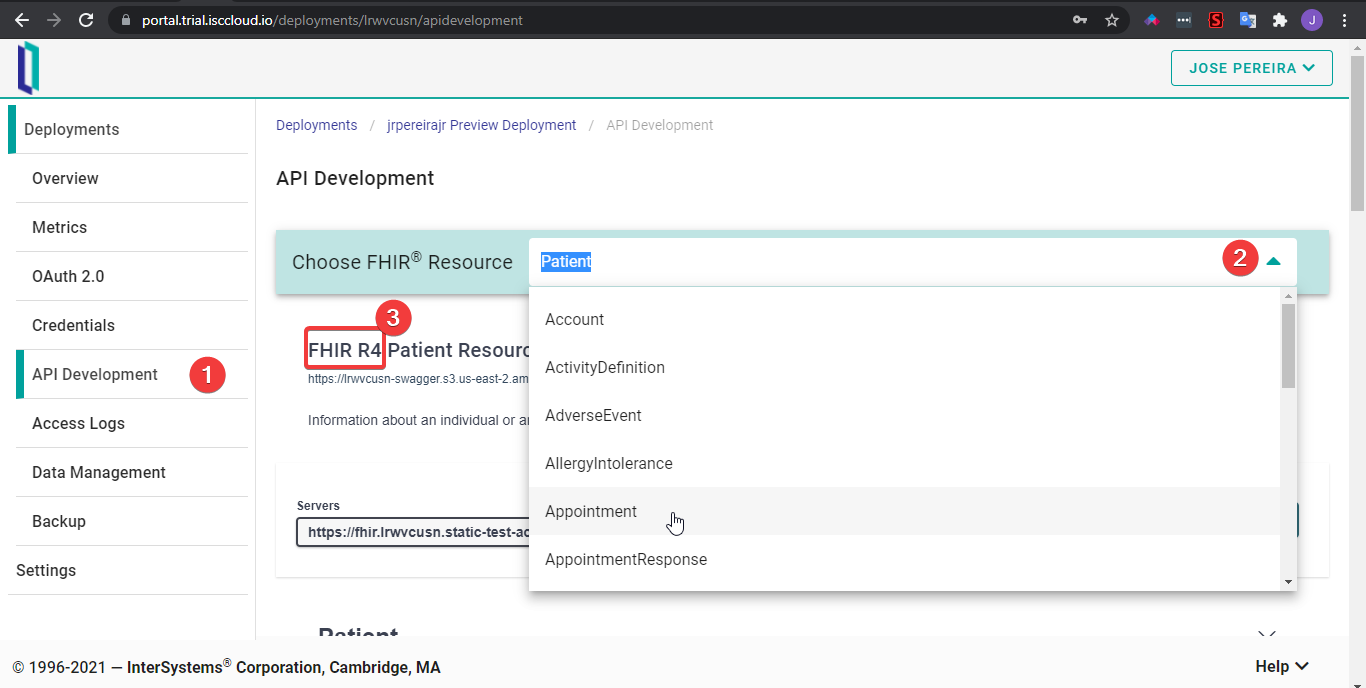
Después, hay que autenticarse para utilizar la herramienta. Y primero hay que crear una clave API.
Bien, ahora, pongamos a todos los pacientes en esta instancia de FHIRaaS:
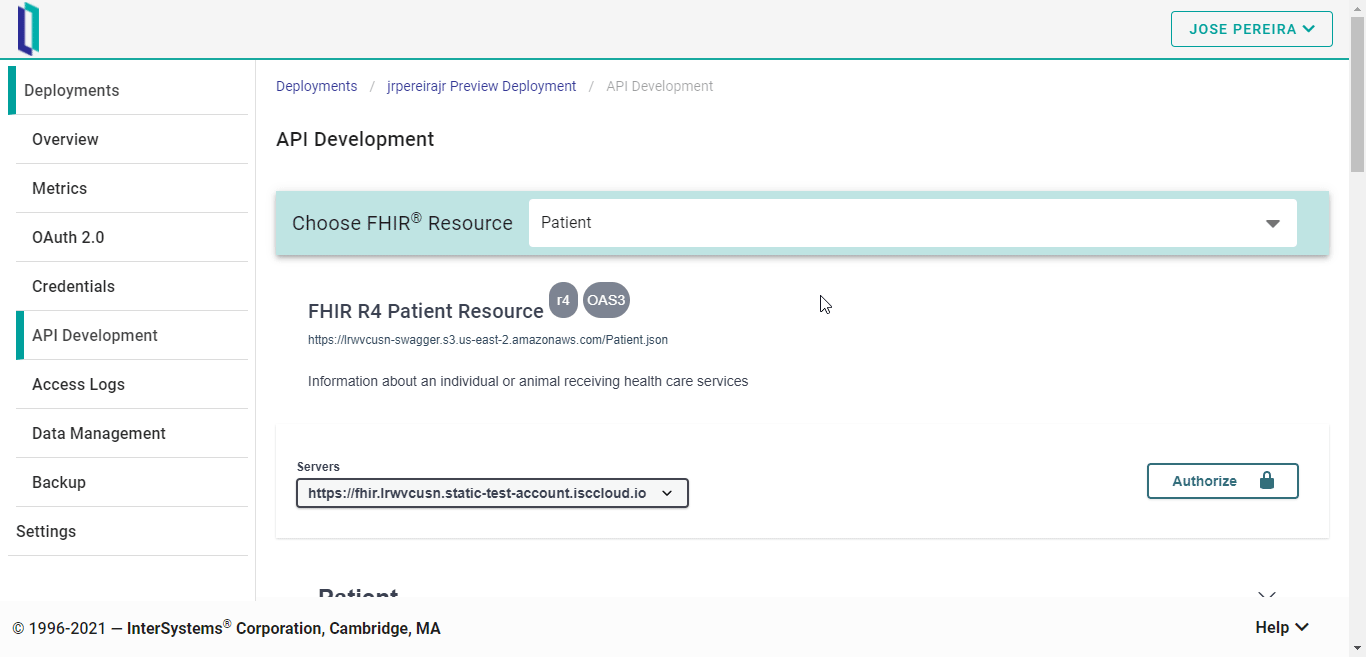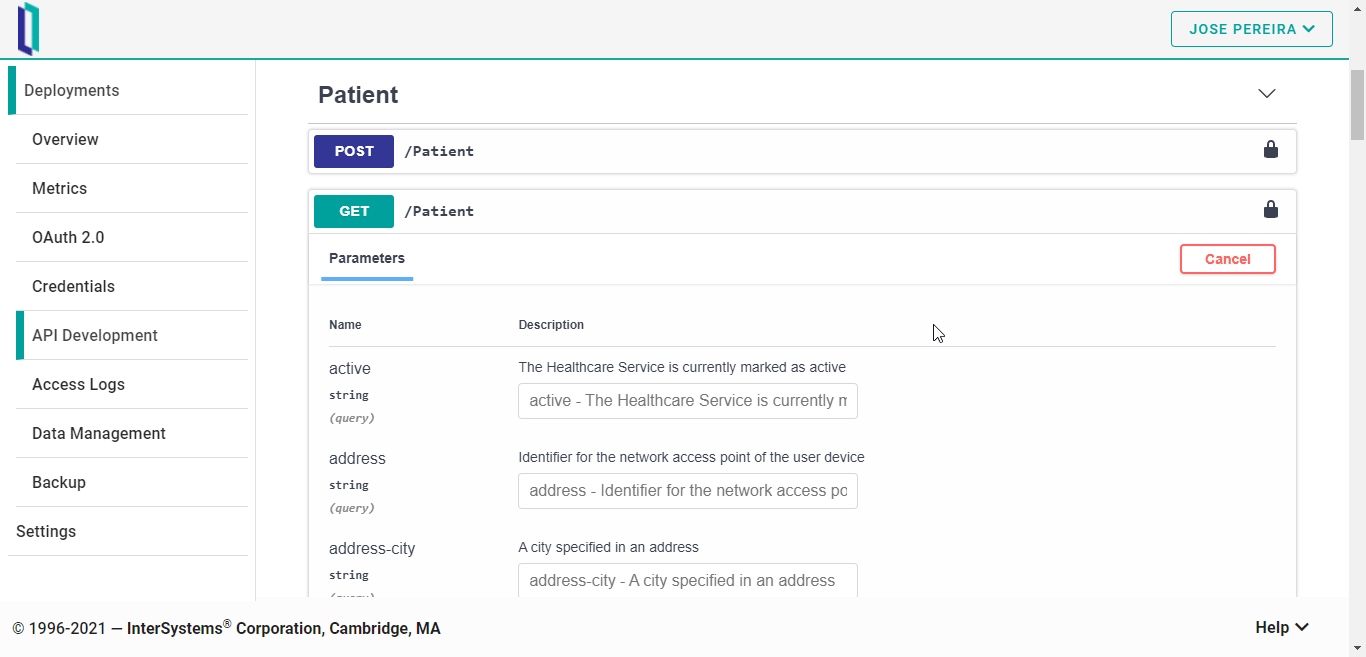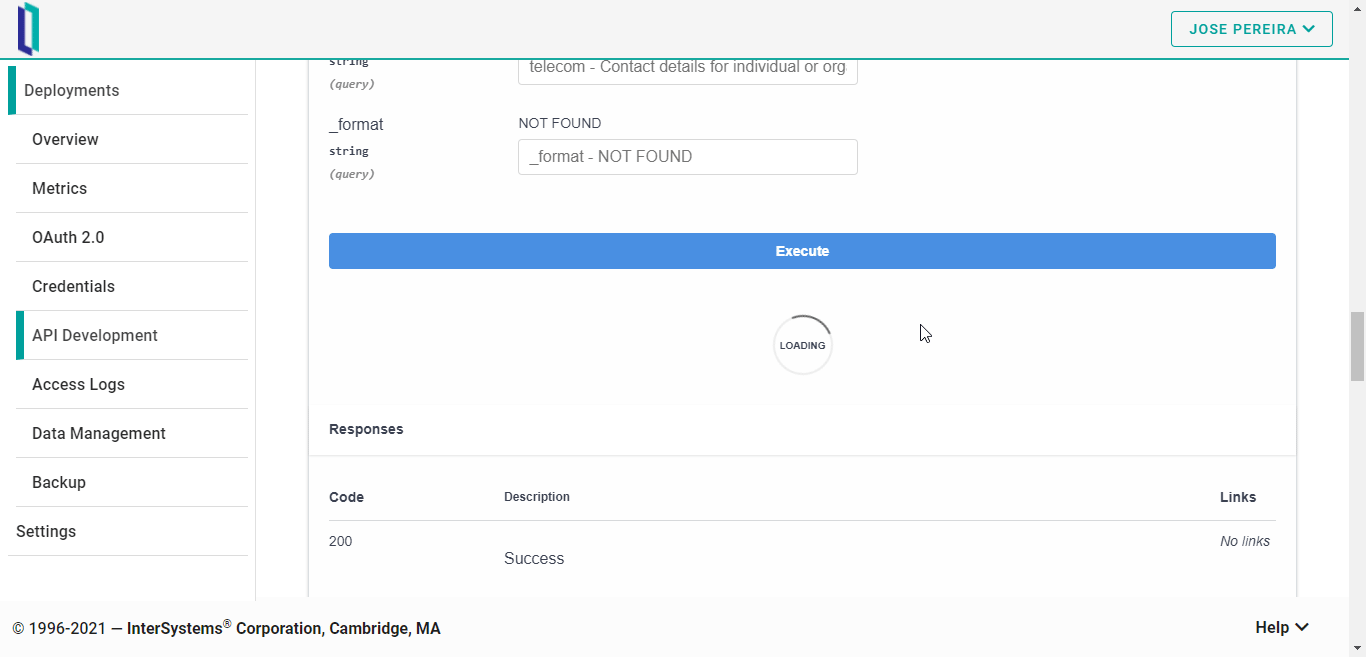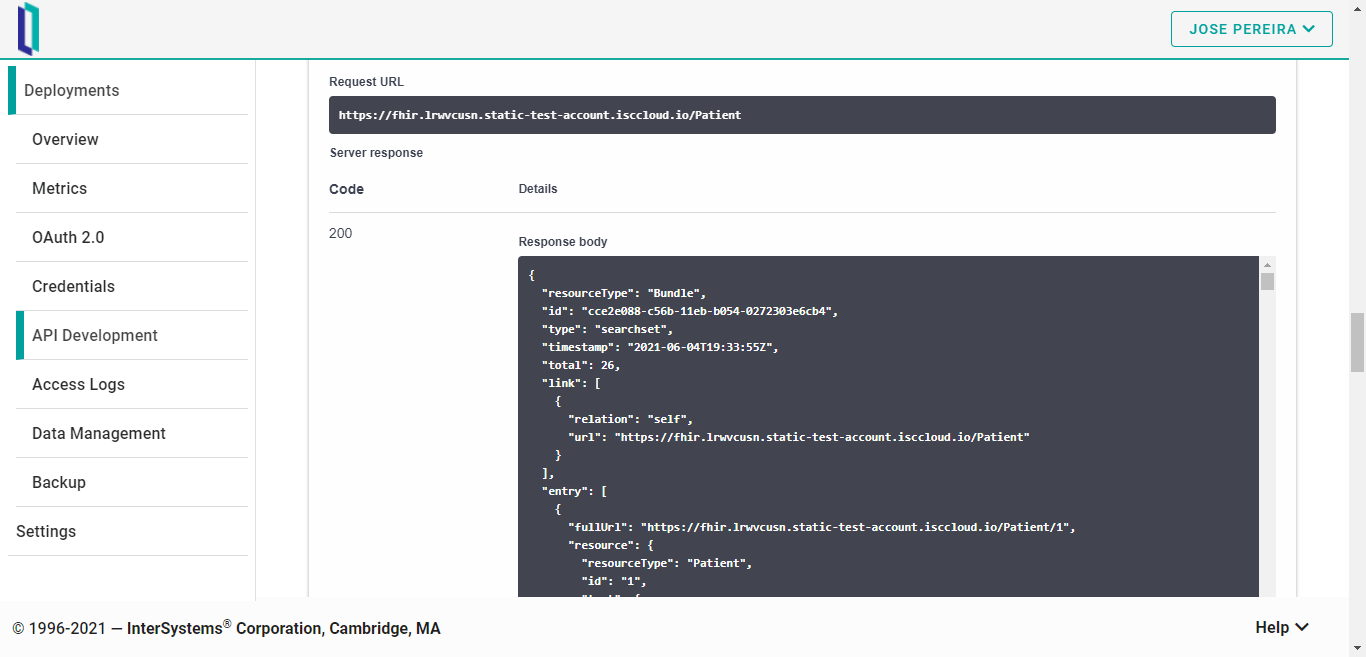
Como podéis ver en la animación anterior, se pueden realizar todas las operaciones CRUD sobre el recurso Patient - lo mismo para el resto de recursos disponibles.
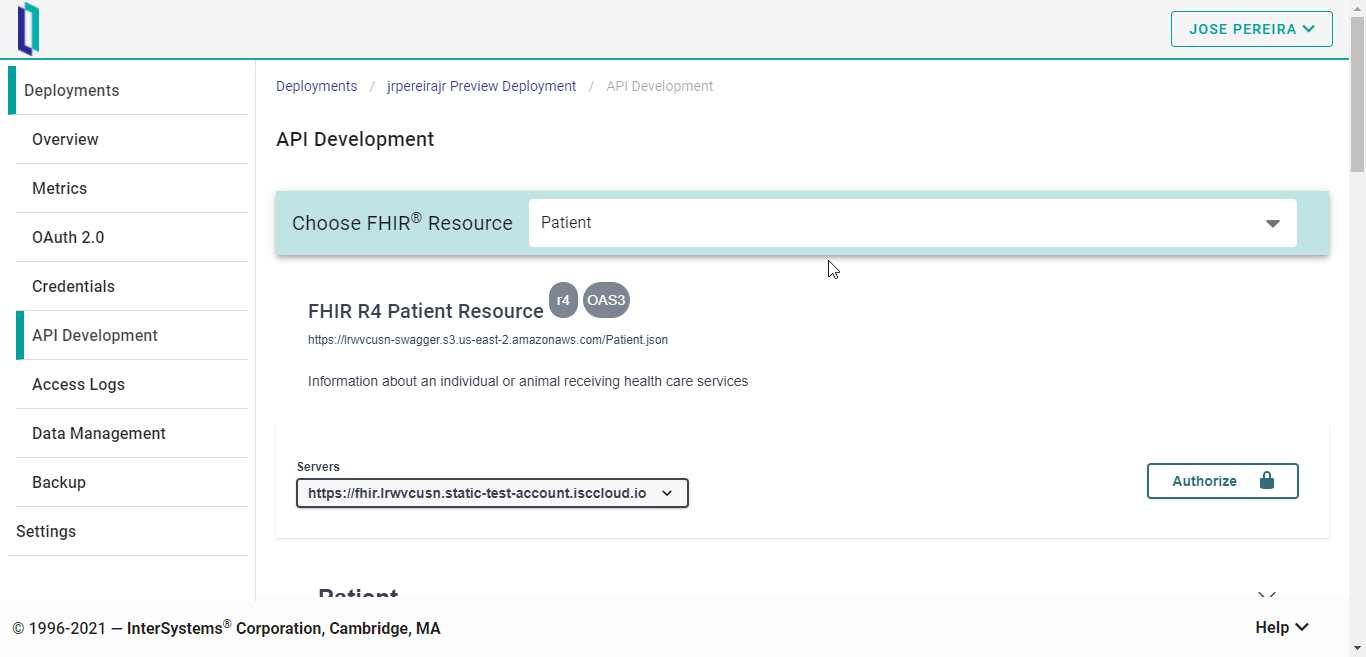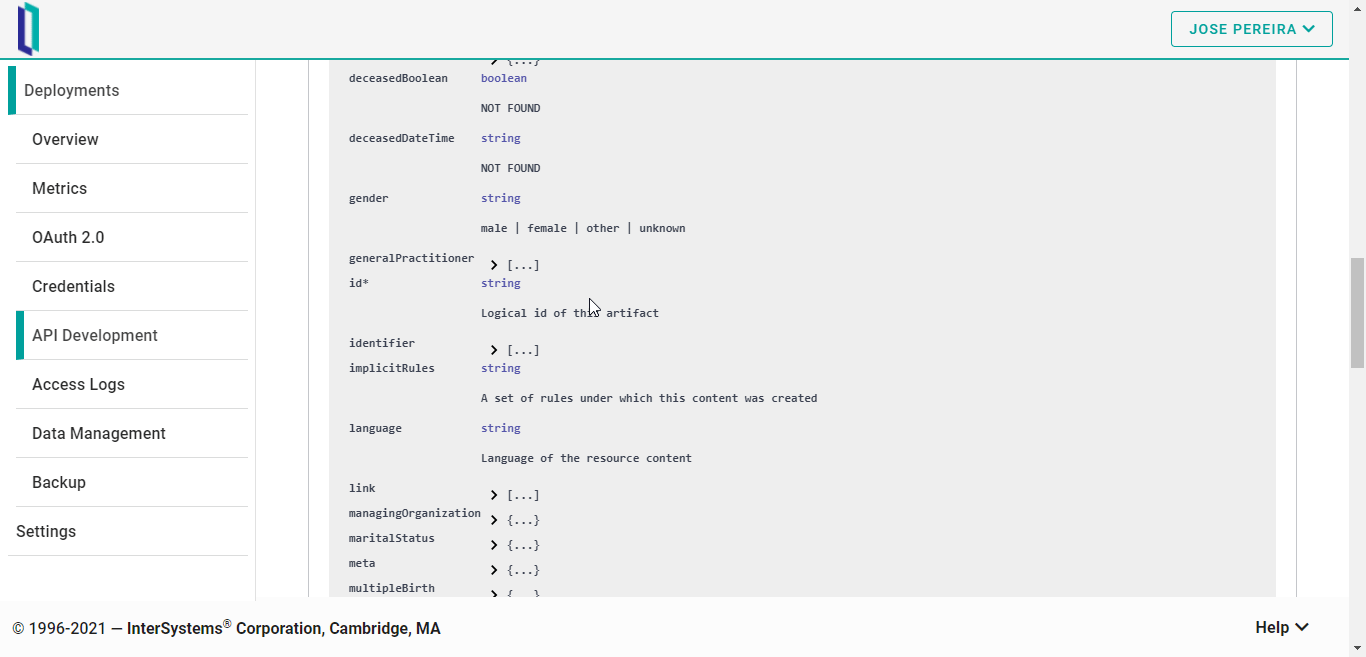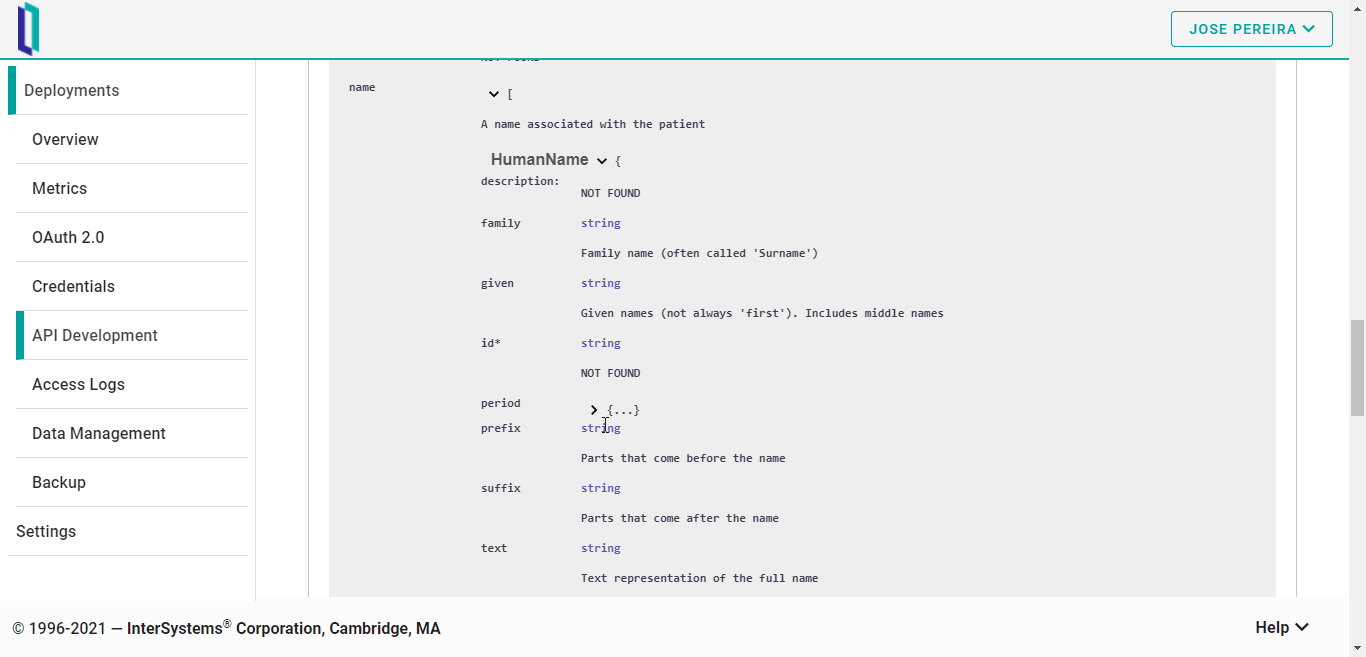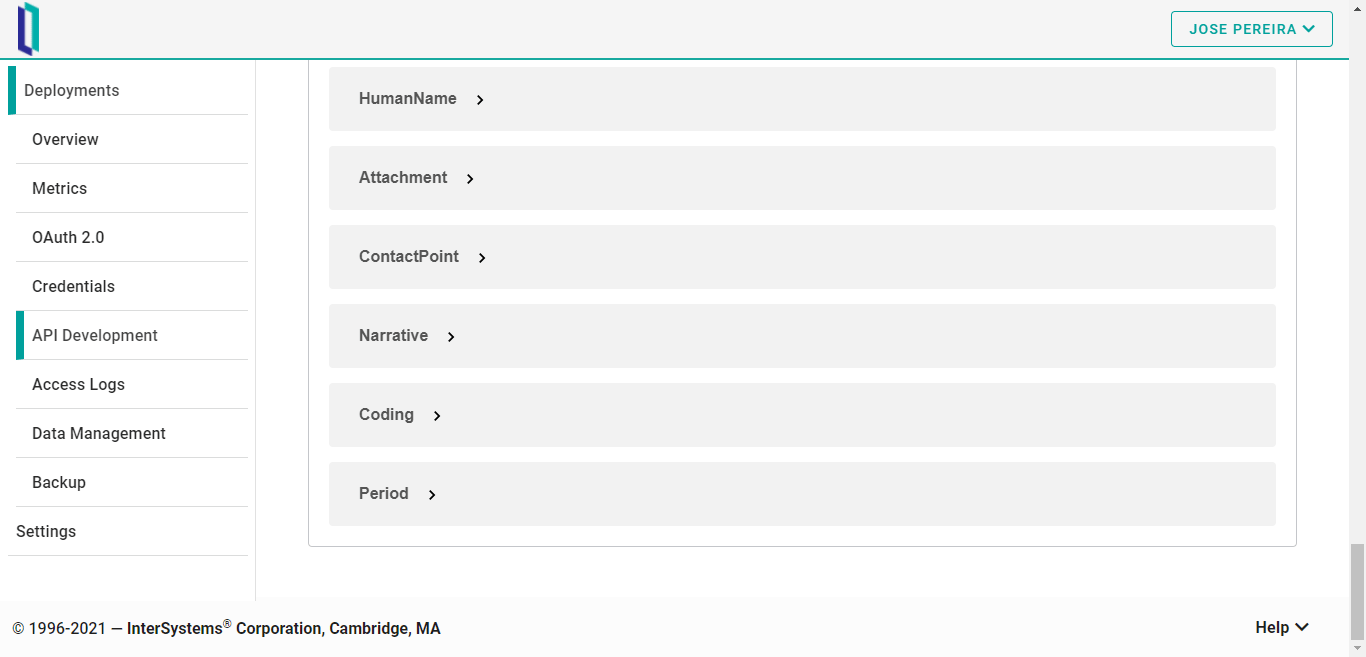
Lo bueno de esto es que no es necesario conocer toda la estructura de los recursos para poder realizar operaciones directamente sobre ellos. Por ejemplo, si queréis intentar crear un nuevo paciente, la herramienta ofrece una plantilla para dicho recurso:
Tenéis la misma funcionalidad para otros recursos FHIR.
Al final de la página, la herramienta ofrece una agradable vista de todos los recursos relacionados, en forma de esquemas:
# Conclusión
En este artículo repasamos algunos aspectos de FHIRaaS y configuramos una implementación de forma práctica.
En el próximo artículo, veremos algunos ejemplos sencillos sobre cómo utilizarlo en aplicaciones.
Artículo
Ricardo Paiva · 9 sep, 2019
¡Hola desarroladores!
¿Os parece que las consultas sobre el rango de fechas son demasiado lentas? ¿Os parece que el rendimiento de SQL es bajo? ¡Tengo un curioso truco que podría ayudaros a solucionar estos problemas! (¡Los desarrolladores de SQL odian que sepáis estas cosas!)*
Si tenéis una clase que guarda los registros de hora cuando se añaden datos, entonces esos datos se ordenarán con vuestros valores IDKEY, es decir, TimeStamp1 < TimeStamp2 si y solo si la condición ID1 < ID2 se cumple para todos los valores ID y TimeStamp en la tabla - entonces podéis utilizar esta información para aumentar el rendimiento de las consultas en relación con los rangos de TimeStamp. Echad un vistazo a la siguiente tabla:
Class User.TSOrder extends %Persistent
{
Property TS as %TimeStamp;
Property Data as %String (MAXLEN=100, MINLEN=200);
Index TSIdx on TS;
Index Extent [type=bitmap, extent];
}
Si añadimos 30 000 000 de filas aleatorias con las fechas de los últimos 30 días, se obtendrán 1 000 000 de filas por día. Ahora, si queremos consultar la información de un día específico, hay que escribir lo siguiente:
SELECT ID, TS, Data
FROM TSOrder
WHERE
TS >= '2016-07-01 00:00:00.00000' AND
TS <= '2016-07-01 23:59:59.999999'
Es una consulta razonable. Sin embargo, en mi sistema tomó 2 171 792 referencias globales y 7,2 segundos. Pero si sabemos que los IDs y los TimeStamps están en el mismo orden, podemos utilizar los TimeStamps para obtener un rango de los ID. Mirad la siguiente consulta:
SELECT ID, TS, Data
FROM TSOrder
WHERE
ID >= (SELECT TOP 1 ID FROM TSOrder WHERE TS >='2016-07-01 00:00:00.00000' ORDER BY TS ASC) AND
ID <= (SELECT TOP 1 ID FROM TSOrder WHERE TS <='2016-07-01 23:59:59.999999' ORDER BY TS DESC)
La nueva consulta se completa en 5,1 segundos, ¡y solo necesita 999 985 referencias globales**!
Esta técnica puede aplicarse de una manera más práctica a las tablas con más campos indexados y a las consultas que tengan varias condicionales WHERE. El rango del ID que se genera a partir de las subconsultas puede ponerse en un formato de mapa de bits, el cual genera una velocidad increíble cuando se obtiene una solución con varios índices. La tabla Ens.MessageHeader es un excelente ejemplo en la que se podría aplicar este truco.
Este es el resultado de un EJEMPLO. Si se tienen muchas sentencias del condicional WHERE en la misma tabla (y están indexadas, ¡obvio!), ¡entonces esta técnica puede ofrecer resultados mucho MEJORES! ¡Probadla en vuestras consultas!
* En realidad, los desarrolladores de SQL no odian que sepáis estas cosas, pero si algo nos ha enseñado Internet es que las frases llamativas atraen más tráfico.
** Cuando se prueban consultas que devuelven tantas filas, el SMP no puede gestionarlas, y la mayor parte del tiempo se dedica a mostrar los datos. La manera correcta de probarlas es con los métodos Embedded o Dynamic SQL, comprobando los resultados, pero sin generarlos en función del tiempo, y usando SQL Shell para los recuentos globales. También se puede utilizar las estadísticas de SQL para hacerlo. Este artículo está etiquetado como "Mejores prácticas" ("Best practices")
(Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).
Artículo
Javier Lorenzo Mesa · 11 dic, 2020
Estoy pensando en implementar Business Intelligence basada en los datos existentes en mis instancias. ¿Cuál es la mejor manera de configurar mis bases de datos y mi entorno para utilizar DeepSee?
En este tutorial se responde esta pregunta mostrando tres ejemplos de la arquitectura que se utiliza en DeepSee. Comenzaremos con un modelo de arquitectura básico y resaltaremos sus limitaciones. El siguiente modelo se recomienda para las aplicaciones de Business Intelligence con una complejidad intermedia, y debería ser suficiente para la mayoría de los casos de uso. Terminaremos el tutorial describiendo cómo mejorar la flexibilidad de la arquitectura para administrar implementaciones avanzadas.
Cada ejemplo del tutorial presenta una nueva base de datos y sus correspondientes mapeos globales (global mappings), junto con una discusión sobre por qué y cuándo deben establecerse. Conforme se construye la arquitectura, también se señalarán los beneficios que proporciona mediante diversos ejemplos flexibles.
Antes de empezar
Servidores principales y analíticos
Para hacer que los datos tengan una alta disponibilidad, por lo general, InterSystems recomienda usar "mirrroring" o "shadowing", y basar la implementación de DeepSee en el servidor de mirror/shadow. La máquina que aloja la copia original de los datos se llama "Servidor principal" ("Primary server"), mientras que las máquinas que alojan las copias de los datos y las aplicaciones de Business lntelligence suelen llamarse "Servidores analíticos" ("Analytics servers") o, a veces, "Servidores de informes" ("Reporting servers").
Es muy importante tener Servidores principales y de análisis, ya que esto permitirá evitar problemas de rendimiento en cualquiera de los dos servidores. Puedes consultar la documentación sobre Arquitectura recomendada.
Los datos y el código de la aplicación
Almacenar los datos y el código fuente en la misma base de datos normalmente funciona bien, pero solo para aplicaciones a pequeña escala. Para aplicaciones más grandes, es recomendable almacenar los datos y el código fuente en dos bases de datos dedicadas, lo que te permitirá compartir el código con todos los namespaces en los que se ejecute DeepSee, mientras se conservan los datos por separado. La base de datos para los datos de origen debe replicarse desde el servidor en producción. Esta base de datos puede ser solamente de lectura, o de lectura y escritura. También es recomendable mantener el "journaling" activado para esta base de datos.
Las clases de origen y las aplicaciones personalizadas deben almacenarse en una base de datos dedicada tanto en el servidor de producción como en el de análisis. Ten en cuenta que estas dos bases de datos para el código fuente no necesitan estar sincronizadas o incluso ejecutar la misma versión de Caché. Por lo general, no es necesario tener activado "journaling", siempre y cuando se realicen con frecuencia copias de seguridad del código en otro sitio.
En este tutorial tendremos la siguiente configuración. El namespace APP en el servidor de análisis tiene el APP-DATA y el APP-CODE como las bases de datos predeterminadas. La base de datos APP-DATA tiene acceso a los datos que se encuentran en la base de datos de origen (la tabla de la clase de origen y sus datos) del servidor primario. La base de datos APP-CODE almacena el código de Caché (archivos de tipo .cls y .INT) y otros tipos de código personalizado. Esta separación de los datos y el código es una arquitectura típica y permite que el usuario, por ejemplo, implemente de manera eficiente el código de DeepSee y la aplicación personalizada.
Cómo ejecutar DeepSee en diferentes namespaces
Las implementaciones de la Business Intelligence usando DeepSee con frecuencia se ejecutan desde diferentes namespaces. En esta publicación mostraremos cómo configurar un namespace APP único, pero este mismo procedimiento es válido para todos los namespaces donde se ejecute la aplicación de Business Intelligence.
Documentación
Es recomendable estar familiarizado con esta página: Cómo establecer la configuración inicial. En esta página se incluye la configuración de las aplicaciones web, cómo colocar los globales de DeepSee en bases de datos separadas y una lista de mapeos alternativos para los globales de DeepSee.
* * * En la segunda parte de esta serie de artículos mostraremos cuál es la implementación de un modelo con una arquitectura básica.
Artículo
Ricardo Paiva · 11 ago, 2021
Me encontré con un interesante caso de uso de ObjectScript con una solución general que quería compartir.
## Caso de uso:
Tengo una matriz JSON (específicamente, en mi caso, una matriz de problemas de *Jira*) que quiero agregar en algunos campos, por ejemplo: categoría, prioridad y tipo de problema. Después quiero combinar los agregados en una lista simple con el total de cada uno de los grupos. Por supuesto, para la agregación, tiene sentido utilizar una matriz local en el formulario:
agg(category, priority, type) = total
De tal manera que para cada registro en la matriz de entrada simplemente puedo hacer lo siguiente:
Do $increment(agg(category, priority, type))
Pero, cuando haya hecho la agregación, quiero conseguir un formulario más fácil sobre el que iterar, como una matriz con subíndices enteros:
summary = n
summary(1) = $listbuild(total1, category1, priority1, type1)
...
summary(n) = $listbuild(totalN, categoryN, priorityN, typeN)
## Solución básica:
El enfoque sencillo es simplemente tener tres bucles "For" anidados con $Order, por ejemplo:
Set category = ""
For {
Set category = $Order(agg(category))
Quit:category=""
Set priority = ""
For {
Set priority = $Order(agg(category,priority))
Quit:priority=""
Set type = ""
For {
Set type = $Order(agg(category,priority,type),1,total)
Quit:type=""
Set summary($i(summary)) = $listbuild(total,category,priority,type)
}
}
}
Esto es lo que empecé a hacer, pero es mucho código, y si tuviera más dimensiones que agregar se volvería difícil de manejar rápidamente. Esto me hizo preguntarme: ¿hay una solución general para conseguir lo mismo? ¡Resulta que sí la hay!
## Mejor solución con $Query:
Decidí que usar $query podría ayudar. Ten en cuenta que esta solución asume una capacidad uniforme de los subíndices/valores en toda la matriz local, sucederían cosas extrañas si se vulnerara esta suposición.
ClassMethod Flatten(ByRef deep, Output flat) [ PublicList = deep ]
{
Set reference = "deep"
For {
Set reference = $query(@reference)
Quit:reference=""
Set value = $listbuild(@reference)
For i=1:1:$qlength(reference) {
Set value = value_$listbuild($qsubscript(reference,i))
}
Set flat($i(flat)) = value
}
}
Así que el fragmento de código anterior se sustituye por:
Do ..Flatten(.agg,.summary)
Hay que tener en cuenta algunas cosas sobre esta solución:
* _deep_ necesita estar en la PublicList de $query para ser capaz de operar en ella
* en cada iteración, _reference_ se cambia para hacer referencia al siguiente conjunto de subíndices que tenga un valor en _deep_, por ejemplo el valor podría ser: _deep("foo","bar")_
* $qlength devuelve el número de subíndices en _reference_
* $qsubscript devuelve el valor del enésimo subíndice de _reference_
* Cuando las listas $listbuild están concatenadas, el resultado es una lista $listbuild válida con las listas combinadas (¡esto es mucho mejor que usar cualquier otro separador!)
## Resumen
$query, $qlength y $qsubscript son útiles para lidiar con matrices globales/locales de capacidad arbitraria.
## Lecturas adicionales
$Query: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_FQUERY
$QSubscript: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=RCOS_fqsubscript
$QLength: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=RCOS_fqlength Este artículo está etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Muhammad Waseem · 26 abr, 2022
#datasets{
font-family: Arial, Helvetica, sans-serif;
border-collapse: collapse;
width: 100%;
}
#datasets td, #datasets th {
border: 1px solid #ddd;
padding: 8px;
}
#datasets tr:nth-child(even){background-color: #f2f2f2;}
#datasets th {
padding-top: 12px;
padding-bottom: 12px;
text-align: left;
background-color: #2b3589;
color: white;
}
#datasets tr {
line-height: 10px; }
Con el lanzamiento de InterSystems IRIS 2021.2 Preview y la nueva funcionalidad LOAD DATA, los conjuntos de datos se pueden añadir con Objectscript Package Manager (ZPM)
Medical Datasets contiene los siguientes 12 conjuntos de datos. Para tablas de conjuntos de datos y detalles de datos, echa un vistazo a la Demo online, usando SuperUser | SYS
ID
Dataset Name
Tables
Licence
1
Synthetic Medical Data
11
Public Domain
2
Health Care Analytics - 1
8
Public Domain
3
Global Suicide Data
7
Public Domain
4
COVID-19 Polls1
7
CC-BY
5
Cancer Rates by U.S. State
2
Public Domain
6
Opioid Overdose Deaths
2
Public Domain
7
Heart Disease Prediction
1
Public Domain
8
Yellowpages medical services dataset
1
Public Domain
9
Hospital ratings
1
Public Domain
10
Heart Failure Prediction
1
(CC BY 4.0)
11
Diabetes Dataset
1
Public Domain
12
Chronic Kidney Disease
1
Public Domain
Para usar cualquiera de los conjuntos de datos de la tabla anterior, podemos añadirlo a nuestro namespace usando la ID del conjunto de datos. Así que vamos a añadir el conjunto de datos "Synthetic Medical Data"
En primer lugar, tenemos que instalar el paquete dataset-medical, usando el siguiente comando:
zpm "install dataset-medical
Ahora ya podemos importar el conjunto de datos. El conjunto de datos se puede añadir o eliminar por Terminal o por Aplicación web.
AÑADIR DATASET DESDE EL TERMINAL
Podemos añadir un conjunto de datos llamando a la función ImportDS de la clase dc.data.medical.utility pasando la ID del conjunto de datos desde el Terminal:
do ##class(dc.data.medical.utility).ImportDS(1)
¡Eso es todo! Se ha creado nuestro primer conjunto de datos.
Se crea un conjunto de datos "sintético" con 11 tablas y 83 341 registros, que pueden ser confirmados por el Management Portal
Eliminar conjuntos de datos
Utiliza el siguiente comando para eliminar un conjunto de datos en particular pasando su ID
do ##class(dc.data.medical.utility).RemoveDS(1)
Añadir TODOS los conjuntos de datos
Para instalar todos los conjuntos de datos, pasa 999 a la función ImportDS
do ##class(dc.data.medical.utility).ImportDS(999)
Eliminar TODOS los conjuntos de datos
Y para eliminar todos los conjuntos de datos, pasa 999 a la función RemoveDS
do ##class(dc.data.medical.utility).RemoveDS(999)
AÑADIR DATASET DESDE EL TERMINAL
Ve a http://localhost:52773/csp/datasets/index.csp y haz clic en "Install DataSet":
Ver datos desde la aplicación web
Ve a http://localhost:52773/csp/datasets/index.csp y haz clic en cualquier tabla de la columna lateral
Eliminar Conjuntos de datos desde la aplicación web
Ve a http://localhost:52773/csp/datasets/index.csp y haz clic en "Remove dataset":
El conjunto de datos se eliminó con éxito.
¡Espero que os resulte útil!
Artículo
Heloisa Paiva · 11 abr, 2023
Introducción
Este artículo tiene la intención de ser un sencillo tutorial de cómo crear conexiones ODBC y trabajar con ellas, ya que me pareció que empezar con ellas es un poco confuso. Yo tuve la ayuda de unas personas increíbles, y creo que todos merecemos ese apoyo.
Voy dividir cada pequeña parte en sesiones, así que puedes ir directamente a la que necesites, aunque recomiendo leerlo todo.
Voy a usar los datos de ejemplo creados en un artículo previo, Tutorial rápido para crear bases de datos de ejemplo: Samples.PersistentData, con las propiedades Name y Age.
Creando la conexión
Abre el ODBC Data Sources - busca ODBC en la barra de búsqueda de tu ordenador y lo encontrarás.
Selecciona la pestaña System DNS
Haz clic en Add
Selecciona el driver adecuado - para este ejemplo, estoy usando InterSystems IRIS ODBC35
Elige un nombre para la conexión
Escribe el servidor, puerto y namespace que quieres conectar (por ejemplo: IP 12.0.0.1, puerto 1972 y namespace SAMPLE)
Escribe el usuario y contraseña que vas a usar para conectar
Haz clic en "try connection" para comprobar si todo funciona bien - si no, verifica otra vez el usuario y contraseña, servidor, puerto y namespace, y también verifica si tu IRIS está iniciado (para este ejemplo), o si necesitas una VPN para esta conexión.
Nota: No sé si esto funciona de forma similar en Linux o iOS, ¡lo siento!
Usando tu conexión en una Business Operation en producción
Este es solo uno de ejemplos de cómo puedes poner en práctica esta conexión, pero es uno muy utilizado.
Con una Business Operation con adaptador "EnsLib.SQL.OutboundAdapter" en producción, abre la pestaña de configuración y expande la parte de Parámetros Básicos. Vas a ver un DSN input como este:
Expande el input y encuentra la conexión que acabamos de crear. Si no esta ahí, verifica si la creaste en el ODBC Data Source correcto (32-bit o 64-bit).
Si no esta ahí, sigue los pasos otra vez de la otra opción y verifica el input DSN otra vez.
Credenciales
IRIS puede necesitar un usuario y contraseña para acceder a esta conexión, por lo que tienes que proporcionarlo.
Justo debajo del input DSN, vas a encontrar un input Credenciales con una lupa a su lado.
Haz clic en la lupa y verás el menú de credenciales.
En la pestaña a la derecha, haz clic en "Nuevo", escribe un ID que te ayudará a identificar la credencial, el usuario y contraseña necesarios y guárdalo.
¡Genial! Ahora que tienes tus credenciales, puedes volver a la producción y seleccionarlas por el ID que has elegido.
P.D.: un ejemplo para que pruebes
Para ese sencillo tutorial, he creado la siguiente clase en un namespace diferente de aquel en el que está "Sample.PersistentData":
Class Sample.ODBC.Operation Extends Ens.BusinessOperation
{
Parameter ADAPTER = "EnsLib.SQL.OutboundAdapter";
Property Adapter As EnsLib.SQL.OutboundAdapter;
Parameter INVOCATION = "Queue";
Method LegalAge(Request As Sample.request, Response As Sample.response) As %Status
{
// instanciate the response
Do Request.NewResponse(.Response)
// Execute the query and select the first result
Do ..Adapter.ExecuteQuery(.result, "SELECT Name, Age from Sample.PersistentData where Age > 20")
Do result.%Next()
// just for visualizing, sets the first result in the response
Set Response.result = result.%Get("Name")_" "_result.%Get("Age")
Quit 1
}
XData MessageMap
{
<MapItems>
<MapItem MessageType="Sample.request">
<Method>LegalAge</Method>
</MapItem>
</MapItems>
}
}
Gracias por leerme y espero que os resulte útil.
No dudéis en escribirme si tenéis alguna duda o comentario.
Artículo
Laura Blázquez García · 13 mayo, 2025
No sé a vosotros, pero a mi me ha pasado varias veces que creo un contenedor Docker (me gusta hacerlo con un docker-compose.yml, me resulta más ordenado 😊) con una versión de IRIS, voy haciendo mis pruebas y llega un día en el que la licencia de ese contenedor ya no es válida, y no funciona...
Si os ha pasado, puede que alguno de vosotros, igual que yo, haya pensado "pues con subir la versión de IRIS en el docker-compose/Dockerfile, suficiente". Pues... no 😅 Al hacerlo, da problemas y no arranca bien el contenedor.
Así que, pregunté a InterSystems (gracias @Wojciech.Czyz por tu ayuda!!) sobre cómo sería el proceso de actualización de versión en contenedores. Y aquí os dejo una guía paso a paso de cómo hacerlo.
NOTA: Esta guía también es válida si se necesita subir de versión el contenedor en el que estamos trabajando por nuevas funcionalidades o lo que se quiera. Es decir, no es necesario tener que esperar a que el contenedor no arranque para actualizar 😉
Paso a paso
1. Parar la instancia de IRIS (que no el contenedor)
Con el contenedor de IRIS en marcha, accedemos a la instancia de IRIS a través del terminal de docker y la paramos.
Primero, consultamos la lista de contenedores que tenemos en marcha:
docker ps
Buscamos el nombre del contenedor de IRIS:
Ejecutamos la siguiente instrucción para abrir un terminal dentro del contenedor:
docker exec -it irishealth sh
Cuando veamos el símbolo $ estaremos dentro:
Escribimos:
iris stop IRIS
Pulsamos Intro en todas las opciones que aparecen (es decir, dejamos los valores por defecto):
Pulsamos CMD+D para salir de este terminal
Si volvemos a ejecutar:
docker ps
Veremos que el contenedor sigue en marcha:
Pero no entra al portal:
2. Parar el stack de contenedores
Con la instancia de IRIS parada, ahora, paramos el stack de contenedores.
Paramos todos los contenedores que tenemos en marcha con la siguiente instrucción:
docker stop $(docker ps -q)
Comprobamos que están parados con:
docker ps
Si tenemos más contenedores en marcha, podemos pararlos por nombre:
docker stop <nombre_contenedor>
3. Borrar contenedores
Tenemos que posicionarnos en la carpeta donde tenemos el docker-compose.yml de IRIS:
Ejecutamos la siguiente instrucción desde terminal:
docker-compose down
4. Subir versión
Editamos el archivo docker-compose.yml y aumentamos la versión de IRIS, tanto del propio IRIS como del webgaeway (si lo tenemos).
En este caso, editaremos los archivos Dockerfile de las carpetas irishealth y webgateway, subiendo la versión de la 2024.2 a la 2024.3:
5. Levantar contenedor
Posicionados en la carpeta donde tenemos el docker-compose.yml de IRIS, construimos los contenedores:
docker-compose build
Esto descarga las nuevas versiones y construye todo lo necesario:
Después, levantamos todo:
docker-compose up
6. Comprobar progreso de actualización
Si en el terminal vemos que el contenedor de IRIS se ha quedado en la siguiente línea:
Tendremos que comprobar si realmente se está actualizando la versión.
Ejecutamos la siguiente instrucción para abrir un terminal dentro del contenedor:
docker exec -it irishealth sh
Cuando veamos el símbolo $ estaremos dentro:
Escribimos:
iris list
Veremos lo siguiente:
Esto significa que se está actualizando. Tendremos que esperar un rato hasta que termine (le cuesta varios minutos actualizarse).
Podemos ir ejecutando la misma instrucción cada cierto tiempo, hasta que veamos lo siguiente:
En el terminal donde hemos lanzado el docker-compose up, veremos lo siguiente:
7. Reiniciar contenedor
Cuando haya terminado, accedemos al portal y comprobamos que tenemos la nueva versión instalada:
Ahora vamos a reiniciar el contenedor.
Primero paramos la ejecución de la instrucción que tenemos en marcha con CMD + C.
Ejecutamos la siguiente instrucción desde el terminal:
docker-compose up -d
Pregunta
Laura Blázquez García · 4 abr, 2025
Tenemos un servidor OAuth configurado como proveedor de identidades, y tenemos una aplicación externa (de otro proveedor) que se conecta correctamente con el OAuth.
Por necesidades del proyecto, lo que queremos hacer es lo siguiente:
Si el usuario no está autenticado, mostrar la página de login del OAuth, que haga el login y que le redirija a la aplicación de terceros --> Esta parte funciona
Si el usuario ya está autenticado (ya ha iniciado sesión y ya tiene un access_token válido), que exista una cookie con el access_token generado en el login, y al entrar a la URL de la aplicación de terceros, en lugar de mostrar el login del OAuth, si el access_token es válido, redirigirle directamente a la aplicación de terceros --> Esta parte es la que no conseguimos hacer funcionar
Qué tenemos?
Hemos creado una clase custom "test.oauth.server.Authenticate" que extiende de %OAuth2.Server.Authenticate.
Hemos añadido el método BeforeAuthenticate. Aquí somos capaces de leer las cookies de la petición, encontrar la que hemos creado, obtener el access_token, validarlo y obtener el token como tal:
Include Ensemble
Class test.oauth.server.Authenticate Extends %OAuth2.Server.Authenticate
{
ClassMethod BeforeAuthenticate(scope As %ArrayOfDataTypes, properties As %OAuth2.Server.Properties) As %Status
{
$$$LOGINFO("Entrando en BeforeAuthenticate")
set currentNS = $Namespace
Set httpRequest = %request
Set tokenCookie = httpRequest.GetCookie("SessionToken")
If tokenCookie '= "" {
$$$LOGINFO("Token encontrado en Cookie: "_tokenCookie)
// Llamar manualmente a GetAccessToken con el token de la cookie
If ..GetAccessToken(tokenCookie) {
Set isValid = ##class(%SYS.OAuth2.Validation).ValidateJWT("ValidarToken", tokenCookie, , , .jsonObject, .securityParameters, .sc)
$$$LOGINFO(isValid_" ("_sc_"): "_$System.Status.GetErrorText(sc))
$$$LOGINFO(jsonObject.%ToJSON())
set $Namespace = "%SYS"
Set token=##class(OAuth2.Server.AccessToken).OpenByToken(tokenCookie,.sc)
set $Namespace = currentNS
$$$LOGINFO(token_" ("_sc_"): "_$System.Status.GetErrorText(sc))
Quit 1 // Continuar sin mostrar login
} Else {
$$$LOGINFO("GetAccessToken rechazó el token")
Quit $$$OK
}
}
$$$LOGINFO("No se encontró token en Cookie")
Quit $$$OK
}
ClassMethod GetAccessToken(ByRef AccessToken As %String) As %Boolean
{
$$$LOGINFO("Entrando en GetAccessToken")
// Si ya recibimos un token desde BeforeAuthenticate
If AccessToken '= "" {
// Token recibido en GetAccessToken
// Llamar a la función de validación de token
Set sc = ##class(%SYS.OAuth2.Validation).ValidateJWT("ValidarToken", AccessToken, , , .jsonObject, .securityParameters)
Set user = jsonObject.sub
$$$LOGINFO("Token válido. Usuario: "_user)
If user '= "" {
$$$LOGINFO("Usuario autenticado: "_user)
Quit $$$OK
} Else {
$$$LOGINFO("El usuario está vacío.")
Quit 0 // Retorna 0 si el usuario es vacío
}
}
Quit 0 // Asegúrate de retornar 0 si no se obtiene el token
}
}
Pero sea como sea, aunque tengamos el access_token, abramos el objeto Token del OAuth, etc, sigue mostrando el login. Creemos que nos falta algo, pero no sabemos el qué...
Qué podemos hacer? Alguna idea?
Gracias! ¿Es posible que estéis almacenando la cookie en el explorador de internet pero no la estéis enviando al servidor de OAuth en la request? La cookie llega, conseguimos leerla con esta instrucción:
Set tokenCookie = httpRequest.GetCookie("SessionToken")
El nombre es inventado, no sé si quizá esté ahí el problema... O si se debe generar una cabecera o alguna historia para que funcione.
Lo que no sabemos es qué hacer una vez leída la cookie y obtenido el token. Buenas @Laura.BlázquezGarcía, no soy muy experto en temas de OAuth2 pero quizás este artículo os pueda resultar de utilidad:
https://community.intersystems.com/post/oauth-authorization-and-intersystems-iris-taming-trust-protocols Finalmente encontramos una solución. Mi colega @Miguelio lo resolvió. Lo ha documentado, así que aquí dejo el enlace: https://es.community.intersystems.com/post/persistencia-de-sesi%C3%B3n-oauth-con-token-openid-en-cookie
Artículo
Alberto Fuentes · 14 oct, 2019
¡Hola a tod@s!
Me gustaría comentar con vosotros algunas de las mejoras en procesamiento JSON que incorpora IRIS desde la versión 2019.1. Utilizar JSON como formato de serialización es muy común a la hora de construir aplicaciones hoy en día, especialmente si desarrollamos o interactuamos con servicios REST.
Dar formato a cadenas a JSON
Ayuda mucho poder dar un formato fácilmente interpretable por una persona a una cadena JSON. Especialmente cuando queremos depurar código y acabamos teniendo que examinar por ejemplo una respuesta JSON de un tamaño considerable. Al principio, las estructuras simples son fáciles de leer, pero a medida que comenzamos a tener múltiples elementos anidados unos en otros puede complicarse.
Aquí tenemos un ejemplo sencillo:
{"name":"Gobi","type":"desert","location":{"continent":"Asia","countries":["China","Mongolia"]},"dimensions":{"length":1500,"length_unit":"km","width":800,"width_unit":"km"}}
Si la tuviésemos formateada de manera que nos facilitase la lectura, nos permitiría explorar de forma sencilla su contenido. Echemos un vistazo a la misma cadena JSON pero formateada de forma más apropiada:
{
"name":"Gobi",
"type":"desert",
"location":{
"continent":"Asia",
"countries":[
"China",
"Mongolia"
]
},
"dimensions":{
"length":1500,
"length_unit":"km",
"width":800,
"width_unit":"km"
}
}
Incluso con este ejemplo tan simple ya vemos como el resultado es un bastante más largo, así que nos hacemos a la idea de por qué en muchas ocasiones este formato no es el que se utiliza por defecto en muchos sistemas. Pero sin embargo, con este formato tan "explicativo" podemos identificar muy fácilmente subestructuras y hacernos una idea rápidamente de si algo no está del todo bien.
En InterSystems IRIS 2019.1 se incluye un paquete con el nombre %JSON donde podemos encontrar un conjunto de herramientas, entre ellas un formateador, que nos ayudará a conseguir lo que acabamos de ver en el ejemplo anterior. Dar formato a nuestros objetos dinámicos, arrays y cadenas JSON para obtener una representación más fácilmente interpretable por una persona. %JSON.Formatter es una clase con una interfaz muy simple. Todos los métodos son métodos de instancia, así que el primer paso es obtener una instancia de la clase:
USER>set formatter = ##class(%JSON.Formatter).%New()
La razón para desarrollarlo de esta forma es que así podremos configurar nuestra instancia del formateador de manera que incluyamos por ejemplo ciertos caracteres para la indentación (espacios en blanco o tabuladores), caracteres de fin de línea, etc. y después lo podremos reutilizar donde nos haga falta.
El método Format()recibe bien un objeto dinámico / array o una cadena JSON. Echemos un vistazo a un ejemplo sencillo utilizando un objeto dinámico
USER>do formatter.Format({"type":"string"})
{
"type":"string"
}
Ahora el mismo ejemplo pero utilizando una cadena JSON:
USER>do formatter.Format("{""type"":""string""}")
{
"type":"string"
}
El método Format()devuelve la cadena formateada al dispositivo actual, pero también tenemos disponibles los métodos FormatToString() y FormatToStream()en caso de necesitar el resultado en una variable.
Algo más complicado
Lo que hemos visto hasta ahora está bien, pero no merece un artículo solamente para ello :). InterSystems IRIS 2019.1 incluye también una manera muy sencilla de serializar objetos persistentes y no-persistentes hacia o desde JSON.
La clase que nos interesa para este fin es %JSON.Adaptor. El concepto es muy similar al de %XML.Adaptor, de ahí el nombre. Cualquier clase que quisiéramos serializar hacia o desde JSON necesita heredar de %JSON.Adaptor. La clase herederá entonces unos cuantos métodos, de los cuales cabe reseñar %JSONImport() y %JSONExport(). Para explicarlos, lo mejor es verlo con un ejemplo.
Asumamos como punto de partida que tenemos las siguientes clases:
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
}
y
Class Model.Location Extends (%Persistent, %JSON.Adaptor)
{
Property City As %String;
Property Country As %String;
}
Tenemos una clase Event persistente, que se relaciona con una Location. Ambas clases heredan de %JSON.Adaptor. Esto les permite instanciar, rellenar un objeto y exportarlo directamente como una cadena JSON:
USER>set event = ##class(Model.Event).%New()
USER>set event.Name = "Global Summit"
USER>set location = ##class(Model.Location).%New()
USER>set location.City = "Boston"
USER>set location.Country = "United States of America"
USER>set event.Location = location
USER>do event.%JSONExport()
{"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
Por supuesto, también podemos ir en sentido inverso utilizando %JSONImport():
USER>set jsonEvent = {"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
USER>set event = ##class(Model.Event).%New()
USER>do event.%JSONImport(jsonEvent)
USER>write event.Name
Global Summit
USER>write event.Location.City
Boston
Los métodos para importar y exportar funcionan para estructuras de datos anidadas arbitrariamente. De forma análoga a %XML.Adaptor puedes especificar la lógica de mapeo para cada propiedad individual a través de su correspondiente parámetro. Vamos a cambiar la definición de la clase Model.Event para ver cómo funciona:
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String(%JSONFIELDNAME = "eventName");
Property Location As Model.Location(%JSONINCLUDE = "INPUTONLY");
}
Asumiendo que tenemos la misma estructura de objeto asignado a la variable event que en el ejemplo anterior, una llamada a %JSONExport() retornaría lo siguiente:
USER>do event.%JSONExport()
{"eventName":"Global Summit"}
La propiedad Name se mapea al campo eventName y la propiedad Location se excluye de la exportación que hace %JSONExport(), pero sin embargo estará presente cuando se carguen datos a partir de una cadena JSON cuando se llame a %JSONImport() . Hay además otros parámetros que nos permitirán ajustar el mapeo:
%JSONFIELDNAME corresponde al nombre del campo en el contenido JSON.
%JSONIGNORENULL permite sobreescribir el comportamiento por defecto a la hora de manejar cadenas vacías para las propiedades tipo string.
%JSONINCLUDE controla si la propiedad se incluirá o no en la salida / entrada JSON.
Si %JSONNULL es true (=1), entonces las propiedades sin rellenar son exportadas con valor null. En otro caso, el campo correspondiente a la propiedad simplemente se ignorará durante la exportación.
%JSONREFERENCE especifica cómo se tratan las referencias a objetos. "OBJECT" es el valor por defecto e indica que las propiedades de las clases referenciadas se utilizan para representar al objeto referenciado. Otras opciones disponibles son "ID", "OID" y "GUID".
De esta forma tenemos un gran nivel de control de forma muy cómoda. Quedan atrás los días en que manualmente tenías que mapear tus objetos a JSON.
Una cosa más
En lugar de configurar los parámetros de mapeo a nivel de las propiedades, puedes configurar tu mapeo JSON también en un bloque XData. El siguiente bloque XData con el nombre OnlyLowercaseTopLevel tiene la misma configuración que nuestra clase Event anterior.
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
XData OnlyLowercaseTopLevel
{
<Mapping xmlns="http://www.intersystems.com/jsonmapping">
<Property Name="Name" FieldName="eventName"/>
<Property Name="Location" Include="INPUTONLY"/>
</Mapping>
}
}
Sin embargo, aquí hay una diferencia importante: los mapeos JSON en bloques XData no cambian el comportamiento por defecto, y además, para utilizarlos, tienes que referenciarlos en el correspondiente %JSONImport() y %JSONExport() como último argumento, por ejemplo:
USER>do event.%JSONExport("OnlyLowercaseTopLevel")
{"eventName":"Global Summit"}
Si no existe un bloque XData con el nombre que le hemos pasado, utilizará el mapeo por defecto. Con esta aproximación, podemos tener configurados diferentes mapeos y referenciar aquel que nos haga falta en cada caso, permitiendo aún mayor control a la vez que nos permite tener mapeos más flexibles y reutilizables.
Artículo
Ricardo Paiva · 28 jul, 2022
Estos días he estado trabajando con la excelente y nueva funcionalidad: [LOAD DATA](https://docs.intersystems.com/iris20212/csp/docbook/DocBook.UI.Page.cls?KEY=RSQL_loaddata). Con este artículo me gustaría compartir mis primeras experiencias con todos. Los siguientes puntos no contienen ningún orden ni ningún otro análsis. Son solo cosas que observé al utilizar el comando **LOAD DATA**. Y se debe tener en cuenta que estos puntos se basan en la versión 2021.2.0.617 de IRIS, que es una versión de prueba. Por ello, es posible que mis observaciones no apliquen a las nuevas versiones de IRIS. Pero quizás sean útiles para otros.
#### 1) La ruta del archivo está en el lado del servidor
He hecho mis primeras pruebas mediante JDBC. La primera sorpresa que me encontré: ¡El archivo y la ruta del archivo deben, _por supuesto ;-)_ estar en el lado del servidor! El controlador JDBC **no** se encarga de esto en el lado del cliente. Probablemente esto es obvio, pero no lo había considerado al principio.
#### 2) El sufijo del archivo no es relevante
Los documentos dicen:
> "_Los nombres de los archivos deben incluir un sufijo .txt o .csv (valores separados por comas)._"
Según mis observaciones, el comportamiento no es así. El sufijo no es relevante.
#### 3) ¡Lee los documentos! ... o ¿dónde están las filas con errores?
Cuando cargué algunos archivos de datos, perdí filas. Si hay algún problema con una línea, la línea se ignora. Esto sucede silenciosamente en segundo plano y no se notifica activamente al cliente. Después de consultar me di cuenta de que tengo que revisar %SQL\_Diag.Result y %SQL\_Diag.Message para ver los problemas de forma detallada. También me di cuenta de que este comportamiento ya está descrito en esta página: ... así que hay que leer los manuales ;-)
Algunos ejemplos de lo que se puede ver:
SELECT * FROM %SQL_Diag.Result ORDER BY createTime DESC
Revisa la columna errorCount de tu descarga.
Se pueden ver los detalles (de la fila) en %SQL_Diag.Message
SELECT * FROM %SQL_Diag.Message ORDER BY messageTime DESC
Se puede filtrar por un _diagResult_ específico (%SQL\_Diag.Result.ID = %SQL\_Diag.Message.diagResult)
SELECT * FROM %SQL_Diag.Message
WHERE diagResult=4
ORDER BY messageTime DESC
#### 4) LOAD DATA no es compatible con $SYSTEM.SQL.Schema.ImportDDL
Para mi aplicación de prueba [Openflights Dataset](https://openexchange.intersystems.com/package/openflights_dataset) intenté cargar todos los archivos externos con LOAD DATA. Las sentencias se agrupan dentro de un archivo de texto (sql) donde anteriormente también creé las tablas.
Aprendí que no se puede hacer eso mediante $SYSTEM.SQL.Schema.ImportDDL.
Por cierto, la documentación de [ImportDDL](https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_IMPORT) señala que no todas las sentencias SQL son compatibles. Solo unas pocas sentencias SQL aparecen en esta página.
LOAD DATA lamentablemente no es una de ellas... Y, por cierto, USE DATABASE tampoco.
#### 5) Para administrar unicode hay que cambiar una configuración
Para evitar problemas con el código de los datos durante la carga, hay que poner esta configuración en el servidor de %Java: -Dfile.encoding=UTF-8
Consulta más detalles en esta [publicación](https://community.intersystems.com/post/load-data-sqlcode-any-idea#comment-177086). Este problema debería desaparecer en la próxima versión de IRIS.
#### 6) El proceso de carga se detiene con un error, pero los datos se cargan
La carga de datos mediante JDBC se para por un error %qparsets. Se ve así:
Error: [SQLCODE: <-400>:<Fatal error occurred>]
[Error: <<UNDEFINED>zExecute+83^%sqlcq.OPENFLIGHTS.cls10.1 *%qparsets>]
[Location: <ServerLoop>]
Pero hay que preocuparse, los datos se cargaron :-) Consulta más detalles en esta [publicación](https://community.intersystems.com/post/load-data-sqlcode-any-idea#comment-177076).
Este problema debería desaparecer en la próxima versión de IRIS.
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Alberto Fuentes · 12 mar, 2021
Una cuestión muy común es cuál es la configuración ideal para el servidor web Apache HTTPD cuando se utiliza con HealthShare. El propósito de este artículo es describir la configuración inicial recomendada del servidor web para cualquier producto HealthShare.
Como punto de partida, se recomienda la versión 2.4.x (64-bit) de Apache HTTPD. Existen versiones anteriores como la 2.2.x, pero no se recomienda esta versión por rendimiento y escalabilidad de HealthShare.
## Configuración de Apache
### Módulo de la API de Apache sin NSD
HealthShare requiere la opción de instalación del módulo de la API de Apache sin NSD. La versión de los módulos vinculados de forma dinámica depende de la versión de Apache:
* CSPa24.so (Apache versión 2.4.x)
Es mejor dejar que la configuración de las Caché Server Pages (CSP) en el httpd.conf de Apache sea realizada por la instalación de HealthShare, la cual se explica en detalle más adelante en este documento. Sin embargo, la configuración puede realizarse manualmente. Para más información, consulta la Guía de Configuración de Apache que se encuentra en la documentación de InterSystems: Opción recomendada: módulo de la API de Apache sin NSD (CSPa24.so)
## Recomendaciones del Módulo de multiprocesamiento (MPM) de Apache
### MPM Prefork de Apache vs. MPM Worker {#ApacheWebServer-ApachePreforkMPMVs.WorkerMPM}
El servidor web de Apache HTTPD incluye tres módulos de multiprocesamiento (*Multi-Processsing Modules - MPM*): Prefork, Worker y Event. Los MPM son responsables de conectar los equipos con los puertos de red, aceptar solicitudes y generar procesos hijos o secundarios que se encarguen de administrarlos. Por defecto, Apache se suele configurar con MPM Prefork, que no escala muy bien para un número de transacciones elevadas o altas cargas de trabajo de usuarios concurrentes.
En los sistemas de producción de HealthShare, el MPM **_Worker_** de Apache debería habilitarse por razones de rendimiento y escalabilidad. Se prefiere el MPM Worker por las siguientes razones:
* El MPM Prefork utiliza varios procesos secundarios con un hilo de ejecución (*thread*) cada uno, y cada proceso controla una conexión a la vez. Al utilizar Prefork, las solicitudes concurrentes se ven afectadas porque como cada proceso solo puede manejar una sola solicitud a la vez, las solicitudes se quedan esperando en cola hasta que se libere un proceso del servidor. Además, para escalar, son necesarios más procesos secundarios de Prefork, que consumen una gran cantidad de memoria.
* El MPM Worker utiliza varios procesos secundarios con muchos hilos de ejecución (*thread*) cada uno. Cada hilo de ejecución maneja una conexión al mismo tiempo, lo que es de gran ayuda para la concurrencia y reduce el uso de la memoria. Worker gestiona mejor la concurrencia que Prefork, ya que generalmente habrá hilos de ejecución libres disponibles para atender las solicitudes, en lugar de los procesos de Prefork con un solo hilo que podría estar ocupado.
### Parámetros del MPM Worker de Apache {#ApacheWebServer-ApacheWorkerMPMParameters}
Utilizando hilos de ejecución para atender las solicitudes, Worker puede atender una gran cantidad de solicitudes empleando menos recursos del sistema que el Prefork utilizando procesos.
Las directivas más importantes utilizadas para controlar el MPM Worker son **ThreadsPerChild**, que controla el número de hilos de ejecución desplegados por cada proceso hijo y **MaxRequestWorkers**, que controla el número total máximo de hilos que se pueden lanzar.
Los valores comunes de la directiva que se recomiendan para el MPM Worker se especifican en la siguiente tabla:
Parámetros recomendados para el servidor web Apache HTTPD
Directivas del MPM Worker de Apache
Valor recomendado
Comentarios
MaxRequestWorkers
Número máximo de usuarios simultáneos en el Visor Clínico de HealthShare, o el de otros componentes de HealthShare que se configuraron como la suma de todos los tamaños de grupo (*Pool Size*) de Business Services entrantes a todos los productos definidos por las producciones.
* Nota: Si no se cuenta con esta información al momento de realizar la configuración, podemos comenzar con un valor de “1000”
MaxRequestWorkers establece el límite en la cantidad de solicitudes concurrentes que se atenderán, es decir, limita la cantidad total de hilos de ejecución que estarán disponibles para atender a los clientes. Es importante configurar correctamente MaxRequestWorkers porque si se ajusta con un nivel muy bajo, entonces se desperdiciarán los recursos; y si se configura con un nivel muy alto, entonces el rendimiento del servidor se verá afectado. Hay que tener en cuenta que cuando se intentan más conexiones que workers disponibles, las conexiones se situarán en una cola de espera. La cola de espera predeterminada se puede ajustar con la directiva ListenBackLog.
MaxSpareThreads
250
MaxSpareThreads atiende los hilos de ejecución inactivos en todo el servidor. Si hay demasiados hilos inactivos en el servidor, se finalizan los procesos secundarios hasta que el número de hilos inactivos sea menor que este número. El aumento en la cantidad de hilos libres por encima de los predeterminados, tiene como objetivo reducir la probabilidad de que se tengan que recrear procesos.
MinSpareThreads
75
MinSpareThreads atiende los hilos inactivos del servidor. Si no hay suficientes hilos inactivos en el servidor, se crean procesos hijo hasta que el número de hilos inactivos sea mayor que este número. La reducción en la cantidad de hilos libres por debajo del valor predeterminado, tiene como objetivo reducir la probabilidad de que se tengan que recrear procesos.
ServerLimit
MaxRequestWorkers se divide por ThreadsPerChild
El valor máximo de MaxRequestWorkers durante la vida útil del servidor. ServerLimit es un límite estricto en el número de procesos secundarios activos, y debe ser mayor o igual que la directiva MaxRequestWorkers dividida por la directiva ThreadsPerChild. Con worker, sólo se usa esta directiva si la configuración de MaxRequestWorkers y ThreadsPerChild necesita más de 16 procesos en el servidor (predeterminado).
StartServers
20
La directiva StartServers establece el número de procesos del servidor secundario creados al inicio. Como la cantidad de procesos es controlada de forma dinámica dependiendo de la carga, por lo general hay pocas razones para ajustar este parámetro, excepto para asegurar que el servidor esté listo para administrar una gran cantidad de conexiones justo cuando se inicia.
ThreadsPerChild
25
Esta directiva establece el número de hilos creados por cada proceso secundario, 25 de forma predeterminada. Se recomienda mantener el valor predeterminado, porque si aumenta podría llevar a la dependencia excesiva de un solo proceso.
Para más información, consulta la documentación correspondiente a la versión de Apache:
* [Directivas comunes de Apache 2.4 MPM](http://httpd.apache.org/docs/2.4/mod/mpm_common.html)
### Ejemplo para configurar el MPM Worker de Apache 2.4
En esta sección se especifica cómo configurar el MPM Worker para un servidor web Apache 2.4 de RHEL7, necesario para permitir hasta 500 usuarios simultáneos de TrakCare.
1. Primero, verificar el MPM mediante el siguiente comando:
2. Edita el archivo de configuración /etc/httpd/conf.modules.d/00-mpm.conf cuando sea necesario, agregando y eliminando el signo # para que solo se carguen los módulos MPM Worker. Modifica la sección MPM Worker con los siguientes valores, en el mismo orden que se indica a continuación:
3. Reinicia Apache
4. Después de que reinicie Apache correctamente, valida los procesos de worker ejecutando los siguientes comandos. Deberías ver algo parecido a lo siguiente, validando el proceso httpd.worker:
## **Fortalecimiento de Apache**
### Módulos requeridos de Apache
La instalación del paquete de distribución oficial de Apache habilitará, por defecto, un conjunto específico de módulos de Apache. Esta configuración predeterminada de Apache cargará estos módulos en cada proceso httpd. Se recomienda deshabilitar todos los módulos que no sean necesarios para HealthShare, por las siguientes razones:
* reducir el consumo de recursos del proceso httpd daemon,
* reducir la posibilidad de que falle la segmentación desde un módulo problemático,
* reducir las vulnerabilidades de la seguridad.
En la siguiente tabla se describen los módulos de Apache recomendados para HealthShare. Cualquier módulo que no se encuentre en la lista, se puede deshabilitar:
| Nombre del módulo | Descripción |
| ----------------- | ---------------------------------------------------------------------------------------------------------------------- |
| alias | Mapea diferentes partes del sistema de archivos al equipo principal en el árbol de documentos y redirecciona la URL. |
| authz_host | Proporciona un control de acceso basado en el nombre del equipo principal del cliente y la dirección IP. |
| dir | Proporciona una redirección de la barra final que aloja un directorio con archivos índice. |
| headers | Controla y modifica los encabezados de las solicitudes y respuestas de HTTP |
| log_config | Registra las solicitudes que se le hicieron al servidor. |
| mime | Asocia las extensiones para los nombres de los archivos solicitados con el comportamiento y el contenido de los mismos |
| negotiation | Permite seleccionar el contenido del documento que mejor se ajuste a las funciones del cliente. |
| setenvif | Permite configurar variables de entorno basadas en las características de la solicitud |
| status | Muestra el estado del servidor y las estadísticas de rendimiento |
### Cómo deshabilitar los módulos
Los módulos que no sean necesarios deben deshabilitarse para fortalecer la configuración y de esta manera reducir los puntos vulnerables en la seguridad. El cliente es responsable de las políticas de seguridad del servidor web. Por lo menos, deben deshabilitarse los siguientes módulos.
| Nombre del módulo | Descripción |
| ----------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
| asis | Envía archivos que contienen sus propios encabezados HTTP |
| autoindex | Genera un directorio con índices, y muestra la lista de directorios cuando ningún archivo index.html está presente |
| env | Modifica la variable de entorno que se transfirió a los scripts CGI y a las páginas SSI |
| cgi | cgi, ejecución de scripts CGI |
| actions | Ejecuta scripts CGI basados en el tipo de medios o método solicitado, o una acción que se desencadena en las solicitudes |
| include | Documentos HTML analizados por el servidor (incluidos los que están del lado del servidor) |
| filter | Filtrado inteligente de solicitudes |
| version | Manejo de la información en las versiones de los archivos de configuración mediante IfVersion |
| userdir | Mapeo de solicitudes a directorios específicos de los usuarios. Es decir, el ~username que se encuentra en la URL se traducirá a un directorio en el servidor |
## **Apache SSL/TLS** {#ApacheWebServer-ApacheSSL/TLS}
InterSystems recomienda que todas las comunicaciones que se realizan mediante TCP/IP entre los servidores y los clientes de HealthShare se cifren con SSL/TLS para proteger los datos durante las transferencias y garantizar la confidencialidad y la autenticación. Además, InterSystems también recomienda que se utilice HTTPS para llevar a cabo las comunicaciones entre los navegadores (clientes) de los usuarios y la capa del servidor web de la arquitectura propuesta. Asegúrate de consultar las políticas de seguridad de tu empresa, para garantizar que cumple con cualquier requisito de seguridad específico que tenga.
El cliente es responsable de suministrar y administrar los certificados SSL/TLS.
Si utilizas certificados SSL, agrega ssl_module (mod_ssl.so).
## Parámetros adicionales para el fortalecimiento de Apache
Para fortalecer aún más la configuración de Apache, realiza los siguientes cambios en httpd.conf:
* TraceEnable debe desactivarse para evitar posibles problemas de seguimiento entre sitios.

* ServerSignature debe desactivarse para que no se visualice la versión del servidor web.

## Parámetros de configuración suplementarios de Apache {#ApacheWebServer-SupplementalApacheConfigurationParameters}
### Keep-Alive {#ApacheWebServer-Keep-Alive}
La configuración de Apache Keep-Alive permite utilizar la misma conexión TCP para la comunicación mediante HTTP, en vez de abrir una nueva conexión para cada nueva solicitud, es decir, Keep-Alive mantiene una conexión persistente entre el cliente y el servidor. Cuando la opción Keep-Alive está habilitada, la mejora en el desempeño proviene de la descongestión de la red, la reducción de la latencia en las subsiguientes solicitudes y el menor uso del CPU ocasionado por la apertura simultánea de las conexiones. Keep-Alive está ACTIVO por defecto y el estándar HTTP v1.1 requiere que se asuma.
Sin embargo, hay ciertas condiciones para habilitar Keep-Alive; Internet Explorer debe ser la versión 10 o superior para evitar problemas como el tiempo de espera, que se presenta en las versiones anteriores de Internet Explorer. Además, intermediarios como firewalls, balanceadores de cargas y proxies, etc., pueden interferir con las “conexiones TCP persistentes” y pueden ocasionar el cierre imprevisto de las conexiones.
Cuando se habilita Keep-Alive, su tiempo de espera también debe ser ajustarse. El tiempo de espera predeterminado de Keep-Alive para Apache es excesivamente bajo, y debe aumentarse en la mayoría de las configuraciones debido a que pueden surgir incidencias asociadas con la interrupción de las solicitudes AJAX (es decir, hipereventos). Estas incidencias pueden evitarse si se asegura que el tiempo de espera de Keep-Alive en el servidor es mayor que para el cliente. En otras palabras, el cliente debe cumplir con el tiempo de espera y cerrar la conexión en vez de que lo haga el servidor. La mayoría de las veces los problemas ocurren (en Internet Explorer más que en otros navegadores), cuando el navegador intenta utilizar una conexión (particularmente para una PUBLICACIÓN) que se supone que estaría abierta.
Consulta los siguientes valores recomendados de KeepAlive y KeepAliveTimeout para un servidor web HealthShare.
Para habilitar KeepAlive en Apache, realiza los siguientes cambios en httpd.conf:

### CSP Gateway
Para el parámetro KeepAlive de CSP Gateway, deja el valor predeterminado de No Action, porque el estado de KeepAlive se determina por los encabezados de respuesta HTTP de cada solicitud.