Limpiar filtro
Artículo
Ricardo Paiva · 11 mar, 2021
Quería escribirlo como comentario al [artículo](https://community.intersystems.com/post/useful-commands-you-day-day-development-docker-containers) de @Evgeny.Shvarov. Pero resultó demasiado largo, así que decidí publicarlo por separado.

Me gustaría añadir una pequeña aclaración sobre cómo utiliza Docker el espacio en disco y como limpiarlo. Yo uso macOS, por lo tanto todo lo que explico aplica principalmente a macOS, pero los comandos de Docker se adaptan a cualquier plataforma.
Cuando Docker se incluye en Linux, por defecto funciona en el mismo sistema de archivos. Pero en Windows y macOS, funciona en una pequeña máquina virtual con su propio Linux dentro. Y el espacio del disco está limitado por mi configuración en Docker. En mi caso, lo configuré para utilizar hasta 112 GB.
.png)
Por lo tanto, cuando trabajes de forma activa con Docker, tu espacio interior dejará de usarse. Puedes comprobar como Docker emplea todo ese espacio con el comando:
$ docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 84 6 66.02GB 55.6GB (84%)
Containers 6 5 4.914GB 0B (0%)
Local Volumes 19 4 1.812GB 342.7MB (18%)
Build Cache 0 0 0B 0B
En macOS con las últimas versiones de Docker, se utiliza el formato en bruto del disco (anteriormente era qcow2). Y junto con el sistema de archivos APFS en macOS, este archivo puede ocupar menos espacio físico que el propio tamaño del archivo. Observa estos dos comandos.
$ ls -lh ~/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
-rw-r--r--@ 1 daimor staff 104G Jul 13 15:49 /Users/daimor/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
$ du -h ~/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
88G /Users/daimor/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
El comando `ls` muestra el tamaño de mi archivo Docker.raw como 104Gb, mientras que el comando `du` muestra el tamaño real en el disco, que es de 88Gb.
Bien, `docker system df` me mostró que puedo recuperar algo de espacio. Vamos a hacerlo.
$ docker system prune -f
Deleted Containers:
79b3d54ae5a881e37771cfdc1d651db9ce036abc297dc55bdd454eb287f0e329
Deleted Images:
deleted: sha256:298d555976effb112428ed3f6bcc2f4d77ab02b4f287a230d9535001184078f5
deleted: sha256:adb2c64ce6e44d837fce8067c7498574822bff90ed599d1671c126539fe652ac
deleted: sha256:9695172139cec16f1071449daf29bd1c424353044088b92b8acbf33f59952e67
deleted: sha256:24d834b252e25e645b8b5d9194360f5ab1a26ffd2b5c03b6593b9a2c468f59fa
deleted: sha256:1b4e3e73fe0b7d88d5ec718bdc6dc6d17d9fe8ba00988eb72690d76f2da3d1a3
deleted: sha256:9f218f6c7aca9c21760ae43590a2d73b35110e10b6575125ed3ccd12c4495d6e
deleted: sha256:b2fa3335d672a0dc60ea7674c45ee3c85b9fc86584a0e21cc7f1900c368ceec3
deleted: sha256:2ecace396ab65fd393dfb2e330bece974cd952e7a41364352f9c867d9ea4c34e
deleted: sha256:16b894351fe53b95dd43d7437bbbcd5104b8613bc1fa8480826e843d65fc92a3
deleted: sha256:b00d9c05035eac62f3ed99a814cd6feea3e4b68797b6d1203e2f41538c78c2aa
deleted: sha256:5a3d0d9f36b356cb47d3838585da6450c60e2860ef143d1406b48d3a5e72b92b
deleted: sha256:998e719368ff74d13b3a8c096ce81f8f2c4bb28bd1ccd169bfa173b4a78d2e74
deleted: sha256:a74d7ff2ca7d623134f9ce1db40da476134a733935a3f322ba34b99653c6273d
deleted: sha256:4d0dcd2bdad2cf0cb91d13313afff29326771bdac27fcb8780545687dbd39ae4
deleted: sha256:29a8989eed3d4002053f98bf562654910ee5f8836940daaa2f2344a8f29a52a2
deleted: sha256:12d34fbf938d19b193199ea6cce5d690fd0d57ec3f4d1630e1d4b3790379c9ec
deleted: sha256:75aba481bb5ccaa52a3aadf311ae22485fb2a82d69be864fe2f45f2834c5e515
deleted: sha256:326efafee9b92e06876878b21a2931ba771bc0e0b2b359f906ef6cca1d297905
deleted: sha256:913937f4ea932fcb00b6c6b3007970296955aa4f488d6fbaa1a575a5aa4ff5ab
deleted: sha256:f3fc0c75858a36ff9d3f4e8eb7a96f511158bbac92d128760b0d3340d828c5da
deleted: sha256:c002dde1ea6a02ae3e3037442a5c556a925e3e4750a6b2aa923c51fa3d11f5ac
deleted: sha256:e763f6e226613c67aaf5984e4c74b9f6e9e28e0490a4f3286885f498a57d3fa0
deleted: sha256:e7daf0a1574376c8602515dc70e44392d16e1b79013d6e81a9b697794432e660
deleted: sha256:ce33670f78109dcacc73a7c6d70f4b5cd4a13bcfe7878b9df5e4e16b812e5df4
deleted: sha256:95bf79e86f83ed16943f9c34035bf8167a4b89466a05d6793c2957d6d46bab2d
deleted: sha256:056d184391613b33303ccf3818a95a17398e9da813d093a6ee5d87952539380c
Total reclaimed space: 5.537GB
Este comando elimina cualquier contenedor detenido y cualquier imagen no etiquetada que no se esté utilizando por cualquier imagen etiquetada. Y se puede eliminar de forma segura.
Tal vez has notado que solo se recuperaron 5.5 GB, mientras que `docker system df` hablaba de unos 55 GB. Eso es porque df cuenta todas las imágenes no activas, no solo las activas. Si también quieres eliminar todas esas imágenes, puedes utilizar este comando, lo que elimina cualquier imagen que no se utilice en los contenedores que estén ejecutándose en este momento. Por lo tanto, si no tienes ningún contenedor funcionando, eliminará todas las imágenes locales.
docker system prune -a
Acabo de recuperar solo las imágenes activas y los contenedores detenidos. Cuánto espacio utiliza mi docker ahora.
$ docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 83 5 60.48GB 50.1GB (82%)
Containers 5 5 4.914GB 0B (0%)
Local Volumes 19 3 1.812GB 342.7MB (18%)
Build Cache 0 0 0B 0B
Como puedes ver, ya utiliza menos tamaño. `ls` mostrará el mismo resultado. El tamaño del archivo principalmente crece.
$ ls -lh ~/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
-rw-r--r--@ 1 daimor staff 104G Jul 13 16:07 /Users/daimor/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
Pero para macOS es más importante cuánto espacio se utiliza en un disco físico.
$ du -h ~/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
69G /Users/daimor/Library/Containers/com.docker.docker/Data/vms/0/Docker.raw
Y como puedes ver ahora son 69 GB, que son aproximadamente 19 GB menos de los que eran anteriormente.
Así que, para los usuarios de macOS, realmente no importa el tamaño del archivo, con las optimizaciones de APFS en realidad puede ser menor.
Otra forma es reducir las imágenes antiguas con algún filtro por fecha de creación. Al igual que este ejemplo, se eliminarán todas las imágenes creadas hace más de 10 días, pero se mantendrán las imágenes que actualmente utilizan los contenedores.
$ docker image prune --all --filter until=240h
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Alberto Fuentes · 19 oct, 2021
¡Hola desarrolladores!
Últimamente he estado probando el módulo [csvgen](https://openexchange.intersystems.com/package/csvgen) y buscaba un fichero CSV para probar. Resulta que encontré un fichero [muy interesante](https://data.world/datasaurusrex/game-of-thones-deaths) en Data.World con estadísticas sobre los episodios de *Game of Thrones* (Juego de Tronos). Estadísticas sobre muertes 😱.
¡Han documentado todos los asesinatos a lo largo de las 8 temporadas y han anotado dónde, quién, qué clan y con qué arma ha matado a otro personaje!
Así que lo he importado para hacer un cuadro de mando con IRIS Analytics.
No te preocupes, Jon. Con este cuadro de mando podremos hacer que averigües algo. Como resultado de esta «investigación» tenemos este [cuadro de mando](http://35.205.133.201:52773/dsw/index.html#/USER/Overview.dashboard):
**Algunos datos**
El «nivel de sangre» crece de temporada en temporada y alcanza su máximo en la Temporada 8.
Hay 68 armas, y la más peligrosa es el fuego de dragón siendo Daenerys Targaryen la heroína más sangrienta con +1000 víctimas.
Si excluimos el fuego de dragón como arma, entonces Cersei Lannister encabeza la lista de asesinos con 199 víctimas a lo largo de las 8 temporadas.
Lo que me ha sorprendido es que la Casa Stark ha matado a más soldados Lannister que viceversa: 34 Vs. 14.
**¿Cómo funciona todo esto?**
Puede montarse más o menos en media hora.
En primer lugar, se puede partir de un repositorio de plantilla como [objectscript-docker-template](https://openexchange.intersystems.com/package/objectscript-docker-template).
El módulo [csvgen](https://openexchange.intersystems.com/package/csvgen) te da la opción de procesar un CSV y generar la clase correspondiente en IRIS para luego importar los datos, y todo en un solo comando. En nuestro caso, lo que nos ha hecho falta es lo siguiente:
```
set fn="/irisdev/app/data/game_of_thrones_deaths_collecti.csv"
set status=##class(community.csvgen).Generate(fn,",",1,,.tResults)
```
Esta [línea](https://github.com/evshvarov/csvtest/blob/a489b7064773c4fe1ac212a1fda638505bf1603d/src/shvarov/csvtest.cls#L6) en el código.
Como resultado, obtenemos [la clase generada](https://github.com/evshvarov/got-analytics/blob/master/src/shvarov/GOT/Deaths.cls), donde como ves csvgen nos ha incluido los tipos de datos también:
```
Class shvarov.GOT.Deaths Extends %Library.Persistent [ Not Abstract, DdlAllowed, Not LegacyInstanceContext, ProcedureBlock ]
{
Property name As %Library.String(MAXLEN = 250) [ SqlColumnNumber = 2 ];
Property allegiance As %Library.String(MAXLEN = 250) [ SqlColumnNumber = 3 ];
Property season As %Library.Integer(MAXVAL = 2147483647, MINVAL = -2147483648) [ SqlColumnNumber = 4 ];
Property episode As %Library.Integer(MAXVAL = 2147483647, MINVAL = -2147483648) [ SqlColumnNumber = 5 ];
Property location As %Library.String(MAXLEN = 250) [ SqlColumnNumber = 6 ];
Property killer As %Library.String(MAXLEN = 250) [ SqlColumnNumber = 7 ];
Property killershouse As %Library.String(MAXLEN = 250) [ SqlColumnNumber = 8, SqlFieldName = killers_house ];
Property method As %Library.String(MAXLEN = 250) [ SqlColumnNumber = 9 ];
Property deathno As %Library.Integer(MAXVAL = 2147483647, MINVAL = -2147483648) [ SqlColumnNumber = 10, SqlFieldName = death_no ];
```
Lo único que hay que cambiar manualmente es una modificación para añadir [una comprobación después del %Save()](https://github.com/evshvarov/got-analytics/blob/0d0e1266c98e4799aae0865231d8fc9ddd0b9672/src/shvarov/GOT/Deaths.cls#L76) en el método Import() generado. Sin esa modificación, nunca sabrías el motivo por el que no has logrado importar datos.
A continuación, se han creado [la clase del cubo](https://github.com/evshvarov/got-analytics/blob/master/src/shvarov/GOT/BI/GOTDeaths.cls) — con el *Architect* — , [pivot queries](https://github.com/evshvarov/got-analytics/tree/master/src/dfi) — con el *Analyzer* — y un [cuadro de mando](https://github.com/evshvarov/got-analytics/blob/master/src/dfi/Overview.dashboard.xml) — con el *IRIS Analytics Portal* —.
Finalmente se visualiza el cuadro de mando con [DSW](https://openexchange.intersystems.com/package/DeepSeeWeb).
Se cocina todo junto en una imagen Docker utilizando este [Dockerfile](https://github.com/evshvarov/got-analytics/blob/master/Dockerfile), donde se utiliza ZPM para instalar:
* [csvgen](https://openexchange.intersystems.com/package/csvgen) - para generar CSV e importar datos.
* [isc-dev](https://openexchange.intersystems.com/package/ISC-DEV) - para exportar fácilmente artefactos de IRIS Analytics.
* [dsw](https://openexchange.intersystems.com/package/DeepSeeWeb) - para visualizar los datos.
Todo ello desarrollado en VSCode utilizando el [plugin de ObjectScript para VSCode](https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript) y una imagen Docker de InterSystems IRIS Community Edition 2020.2
Y además en este caso ha sido desplegado — con cada *push* — al *GCP Kubenertes Engine (GKE)* — utilizando el [Workflow de GitHub Actions](https://github.com/evshvarov/got-analytics/blob/master/.github/workflows/workflow.yaml). En particular, este cuadro de mando se re-despliega con cada *push* que se hace en la rama *master*.
Como resultado, podéis echarle un vistazo al [cuadro de mando interactivo](http://35.205.133.201:52773/dsw/index.html#!/d/Overview.dashboard?ns=IRISAPP) en funcionamiento.
La calidad del código ObjectScript se evalúa continuamente utilizando [ObjectScript Quality](https://openexchange.intersystems.com/package/CachéQuality) vía este [archivo de workflow](https://openexchange.intersystems.com/package/CachéQuality) y puede [ser examinado aquí](https://community.objectscriptquality.com/dashboard?id=intersystems_iris_community%2Fgot-analytics).
¡Cualquier colaboración es bienvenida!
P.D: había 68 personas en la lista de Arya 😎
Artículo
Guillaume Rongier · 28 nov, 2022
# 1. iris-dollar-list
[](https://pypi.org/project/iris-dollar-list/)
[](https://pypi.org/project/iris-dollar-list/)
[](https://github.com/grongierisc/iris-dollar-list/blob/main/LICENSE)
[](https://github.com/grongierisc/iris-dollar-list/actions)
Intérprete de $list para python llamado DollarList.
He hecho este intérprete porque:
* Quería usar $list en python
* Python Embebido no es compatible con $list
* La versión de API nativa no es compatible con $list embebido en $list
Este es un trabajo en desarrollo. Hasta ahora, solo es compatible con $list embebido en $list, int y string.
Trabajo en progreso: float, decimal, double
**Este módulo está disponible en Pypi:**
```sh
pip3 install iris-dollar-list
```
Es compatible con Python Embebido y API nativa.
## 1.1. Índice
- [1. iris-dollar-list](#1-iris-dollar-list)
- [1.1. Índice](#11-table-of-contents)
- [1.2. Uso](#12-usage)
- [1.3. funciones](#13-functions)
- [1.3.1. append](#131-append)
- [1.3.2. from_bytes](#132-from_bytes)
- [1.3.3. from_list](#133-from_list)
- [1.3.4. to_bytes](#134-to_bytes)
- [1.3.5. to_list](#135-to_list)
- [2. $list](#2-list)
- [2.1. ¿Qué es $list?](#21-what-is-list-)
- [2.2. ¿Cómo funciona?](#22-how-it-works-)
- [2.2.1. Header](#221-header)
- [2.2.1.1. Size](#2211-size)
- [2.2.1.2. Type](#2212-type)
- [2.2.2. Body](#222-body)
- [2.2.2.1. Ascii](#2221-ascii)
- [2.2.2.2. Unicode](#2222-unicode)
- [2.2.2.3. Int](#2223-int)
- [2.2.2.4. Negative Int](#2224-negative-int)
- [2.2.2.5. Float](#2225-float)
- [2.2.2.6. Negative Float](#2226-negative-float)
- [2.2.2.7. Double](#2227-double)
- [2.2.2.8. Compact Double](#2228-compact-double)
- [2.3. Development](#23-development)
## 1.2. Uso
Ejemplo:
```objectscript
set ^list = $lb("test",$lb(4))
```
Ejemplo de uso con API nativa:
```python
import iris
from iris_dollar_list import DollarList
conn = iris.connect("localhost", 57161,"IRISAPP", "SuperUser", "SYS")
iris_obj = iris.createIRIS(conn)
gl = iris_obj.get("^list")
my_list = DollarList.from_bytes(gl.encode('ascii'))
print(my_list.to_list())
# ['test', [4]]
```
Ejemplo de uso con Python Embebido:
```python
import iris
from iris_dollar_list import DollarList
gl = iris.gref("^list")
my_list = DollarList.from_bytes(gl[None].encode('ascii'))
print(my_list.to_list())
# ['test', [4]]
```
## 1.3. Funciones
### 1.3.1. append
Añade un elemento a la lista.
Este elemento puede ser:
* un *string*
* un int
* un DollarList
* un DollarItem
```python
my_list = DollarList()
my_list.append("one")
my_list.append(1)
my_list.append(DollarList.from_list(["list",2]))
my_list.append(DollarItem(dollar_type=1, value="item",
raw_value=b"item",
buffer=b'\x06\x01item'))
print(DollarList.from_bytes(my_list.to_bytes()))
# $lb("one",1,$lb("list",2),"item")
```
### 1.3.2. from_bytes
Crea un DollarList desde bytes.
```python
my_list = DollarList.from_bytes(b'\x05\x01one')
print(my_list)
# $lb("one")
```
### 1.3.3. from_list
Crea un DollarList desde una lista.
```python
print(DollarList.from_list(["list",2]))
# $lb("list",2)
```
### 1.3.4. to_bytes
Convierte DollarList en bytes.
```python
my_list = DollarList.from_list(["list",2])
print(my_list.to_bytes())
# b'\x06\x01list\x03\x04\x02'
```
### 1.3.5. to_list
Convierte DollarList en una lista.
```python
my_list = DollarList.from_bytes(b'\x05\x01one')
print(my_list.to_list())
# ['one']
```
# 2. $list
## 2.1. ¿Qué es $list?
$list es formato binario para almacenar datos. Se usa en InterSystems IRIS. Es un formato que es fácil de leer y escribir. También es sencillo de analizar.
Lo genial de $list es que no está limitado por el almacenamiento. También se usa para comunicación en el puerto SuperServer de IRIS.
## 2.2. ¿Cómo funciona?
$list es un formato binario que almacenta una lista de valores. Cada valor se almacena en un bloque. Cada bloque está compuesto de un *header* y un *body*. El *header* se compone de un tamaño y un tipo. El *body* se compone del valor.
### 2.2.1. Header
El header o cabecera se compone de un tamaño y un tipo.
#### 2.2.1.1. Size
El tamaño indica el tamaño del bloque. El tamaño se almacena en `N` bytes.
`N` está determinado por el número de bytes que son cero en los primeros bytes del *header*.
El tamaño se almacena en *little endian*.
#### 2.2.1.2. Type
El tipo es un byte que representa el tipo del valor.
El tipo se almacena justo después del tamaño.
Lista de tipos:
* ascii: 0x01
* unicode: 0x02
* int: 0x04
* negative int: 0x05
* float: 0x06
* negative float: 0x07
* double: 0x08
* compact double: 0x09
### 2.2.2. Body
El cuerpo se compone del valor.
Para analizar el cuerpo, hay que saber el tipo del valor.
#### 2.2.2.1. Ascii
Descodifica el valor como ascii.
Si la descodificación falla, considera el valor como una sub-list.
Si descodificar la sub-lista falla, considera el valor como un binario.
#### 2.2.2.2. Unicode
Descodifica el valor como unicode.
#### 2.2.2.3. Int
Analiza el valor como un número entero en little endian y sin signo.
#### 2.2.2.4. Negative Int
Analiza el valor como un número entero en little endian y con signo.
Artículo
Ricardo Paiva · 26 dic, 2022
Se han publicado en la Comunidad varios artículos muy útiles que muestran cómo usar Grafana con IRIS (o Cache/Ensemble) usando una base de datos intermedia.
Pero yo quería llegar directamente a las estructuras de IRIS. En particular, quería acceder a los datos del Cache History monitor, que es accessible a través de SQL, como se describe aquí:
https://community.intersystems.com/post/apm-using-cach%C3%A9-history-monitor
y no quería nada entre los datos y yo.Ya tenía consultas de clase que devuelven los datos que quiero, así que solo necesitaba embeberlos en una clase REST que devolviera JSON. No he incluido mi clase Grafana.MonitorData porque podría ser cualquier cosa, pero puedo hacerlo si la gente lo quiere.
Solo había dos puntos difíciles. Uno era asegurarse de que el tiempo local y el tiempo UTC cuadraban en cada punto. El otro era que a Grafana no le gustan los valores como .25 sin el cero inicial y da errores de javascript - “t.dataList.map no es a función”. Que es por lo que tengo la línea con $FN(tValue,,4).
He simplificado mi código de producción para aclarar los principios. Podría ponerlo en github, pero de tan simple que es, aquí os lo dejo.
Solución
Class Grafana.SYSHistory Extends %CSP.REST{XData UrlMap{<Routes> <Route Url="/" Method="GET" Call="testAvailability" Cors="true" /> <Route Url="/search" Method="POST" Call="metricFindQuery" Cors="true" /> <Route Url="/query" Method="POST" Call="query" Cors="true" /> </Routes>}ClassMethod testAvailability() As %Status{ write "ok" quit $$$OK}/// This method returns list of available metrics.ClassMethod metricFindQuery() As %Status{ do ##class(Grafana.MonitorData).GetSupportedMetrics(.metrics) w "[" set sub="" set firsttime=1 do { set sub=$o(metrics(sub)) quit:sub="" if firsttime=0 w "," set firsttime=0 w """",sub,"""" } while sub'=""write "]"quit $$$OK}/// Data format for Grafana - http://docs.grafana.org/plugins/developing/datasources/ClassMethod query() As %Status{ set obj = {}.%FromJSON(%request.Content) if obj="" { write "no object found" quit $$$OK } set iter=obj.targets.%GetIterator() set tMetrics=0 while iter.%GetNext(.key,.value) { set tMetrics=tMetrics+1 set tMetrics(tMetrics) = value.target } set from = obj.range.from set to = obj.range.to#define classname 1#define queryname 2set (className,queryName)=""//hard code the class and use 'NamedQuery' items so we don't allow any access to any data via any query...set className="Grafana.MonitorData"set queryName="SysMonHistorySummary"write "["for i=1:1:tMetrics {if i>1 w ","w "{""target"":"""_tMetrics(i)_""",""datapoints"":["do ..ExportJSON(className,queryName,from,to,tMetrics(i))write "]}"}write "]"quit $$$OK}/// The className and QueryName determing the query to be executed./// from and to are local time in %Date (a.k.k. $horolog) format./// The query must return a value for the metric. This code assumes the values are returned/// as Avg_Metric and RunDate, but you could change that
ClassMethod ExportJSON(className As %String, queryName As %String, from, to, pMetric As %String) As %Status{if className="" quit $$$OKif queryName="" quit $$$OKset rs=##class(%ResultSet).%New(className_":"_queryName)if rs="" quit $$$ERROR($$$QueryDoesNotExist,className_":"_queryName)// use this just for param infoset sc=$classmethod(className,queryName_"GetInfo",.colinfo,.paraminfo,.idinfo,.QHandle,0,.extinfo) //The request must contain data with names matching the parameters of the query.//Convert date and time parameters from strings to $hset from=$e(from,1,19)set to=$e(to,1,19)set RunDateUTCFromH=$zdth(from,3)set RunDateFromH=$zdth(RunDateUTCFromH,-3)set RunDateUTCToH=$zdth(to,3)set RunDateToH=$zdth(RunDateUTCToH,-3)set tSc=rs.Execute(RunDateFromH,RunDateToH,"live",pMetric) //param(1),param(2))if $$$ISERR(tSc) quit tScset rowcnt=0while rs.Next() {set rowcnt=rowcnt+1if rowcnt>1 write ","write "["set tRunDate=rs.Data("RunDate")set tUtcRunDate=$zdt(tRunDate,-3)set tValue=rs.Data("Avg_Metric")set tPosixTime=##class(%Library.PosixTime).OdbcToLogical($zdt(tUtcRunDate,3,3))set tUnixTime=##class(%Library.PosixTime).LogicalToUnixTime(tPosixTime)_"000"write $fn(tValue,,4),",",tUnixTimewrite "]"}quit $$$OK}}
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Muhammad Waseem · 15 jul, 2022
¡Hola Comunidad!
En este artículo voy a explicar cómo acceder a la información y a las tablas del dashboard (cuadro de mando) del sistema del Portal de Administración mediante el uso de Python Embebido.
Cómo acceder al dashboard del sistema del Portal de Administración
Estos son los pasos para acceder a la información del dashboard del sistema:
Paso 1: cambiar el namespace a %SYS
Paso 2: importar el módulo iris python y crear una instancia de la clase "SYS.Stats.Dashboard"
Paso 3: acceder a las propiedades de la clase instanciada
¡Empezamos!
Paso 1: Cambiar el namespace a %SYS
Para obtener la información del dashboard del sistema, debemos acceder a la clase "SYS.Stats.Dashboard" desde el namespace %SYS.Si no está en el namespace %SYS, entonces tenemos que cambiar el namespace.
Crea la clase Embedded.Utils para obtener o establecer el namespace:
///Esta clase se usará para obtener o establecer el espacio de nombres
Class Embedded.Utils
{
//Obtener espacio de nombres
ClassMethod GetNameSpace() As %Status
{
Return $namespace
}
//Establecer espacio de nombres
ClassMethod SetNameSpace(pNameSpace) As %Status
{
zn pNameSpace
Return $namespace
}
}
Desde el código de Python, escribe el siguiente script para cambiar el namespace:
#Importar biblioteca de iris
import iris
#Establezca Namespoace en %SYS si el espacio de nombres actual no es %SYS
if iris.cls("Embedded.Utils").GetNameSpace() != "%SYS":
iris.cls("Embedded.Utils").SetNameSpace("%SYS")
Paso 2: Importar el módulo iris python y crear una instancia
Ahora podemos acceder a las propiedades de "SYS.Stats.Dashboard" llamando al método de clase 'Sample':
#Importar biblioteca de iris
import iris
#Establecer Namespoace en %SYS si el espacio de nombres actual no es %SYS
if iris.cls("Embedded.Utils").GetNameSpace() != "%SYS":
iris.cls("Embedded.Utils").SetNameSpace("%SYS")
#Se puede crear una instancia de una clase llamando al método de clase 'Muestra', y luego se puede acceder al valor actual de cada propiedad.
ref = iris.cls("SYS.Stats.Dashboard").Sample()
Paso 3: Acceder a las propiedades de la clase instanciada
Esta clase contiene las siguientes propiedades, a las que se puede acceder mediante el siguiente código:
#Importar biblioteca de iris
import iris
#Establezca Namespoace en %SYS si el espacio de nombres actual no es %SYS
if iris.cls("Embedded.Utils").GetNameSpace() != "%SYS":
iris.cls("Embedded.Utils").SetNameSpace("%SYS")
#Se puede crear una instancia de una clase llamando al método de clase 'Muestra', y luego se puede acceder al valor actual de cada propiedad.
ref = iris.cls("SYS.Stats.Dashboard").Sample()
#Mostrar errores de aplicación
print(ref.ApplicationErrors)
#mostrar sesiones de CSP
print(ref.CSPSessions)
Para obtener más detalles, consulta la aplicación iris-python-apps en Open Exchange
Mostar los datos de la tabla Caché en una página web con la ayuda de jquery datatable
Estos son los pasos para mostrar la tabla Security.Users en una página web
Paso 1: Cambiar el namespace a %SYS
Paso 2: Importar el módulo iris python y usar la función iris.sql.exec() para ejecutar una sentencia SQL SELECT para obtener un resultset
Paso 3: Obtener el dataframe llamando a la función resultset dataframe
Paso 4: Obtener datos JSON de encabezado y columnas del dataframe y pasarlos a la web
Paso 5: Mostrar datos en jquery datatable
¡Empezamos!
Paso 1: Cambiar el namespace a %SYS
La misma clase Embedded.Utils anterior se puede usar para obtener o establecer el namespace
#Importar biblioteca de iris
import iris
#Establezca Namespoace en %SYS si el espacio de nombres actual no es %SYS
if iris.cls("Embedded.Utils").GetNameSpace() != "%SYS":
iris.cls("Embedded.Utils").SetNameSpace("%SYS")
Paso 2: Importar el módulo iris python y usar la función iris.sql.exec() para ejecutar una sentencia SQL SELECT para obtener un resultset
Después de importar el módulo iris, usaremos iris.sql.exec() para ejecutar una sentencia SQL SELECT y obtener un resultset
import iris
statement = '''SELECT
ID, AccountNeverExpires, AutheEnabled, ChangePassword, CreateDateTime AS DateCreated, Enabled, ExpirationDate, Flags, Name
FROM Security.Users'''
#Llamar a la clase python incrustada iris.sql.exec para obtener el conjunto de resultados
resultSet = iris.sql.exec(mySql)
Paso 3: Obtener el dataframe llamando a la función resultset dataframe
#Obtenga el marco de datos llamando a la función de marco de datos del conjunto de resultados
dataframe = statement.dataframe()
Paso 4: Obtener datos JSON de encabezado y columnas del dataframe y pasarlos a la web
#Convierta y envíe datos a Json utilizando el método de marco de datos to_json y la función de carga json
my_data=json.loads(dataframe.to_json(orient="split"))["data"]
#Obtener detalles de las columnas
my_cols=[{"title": str(col)} for col in json.loads(df.to_json(orient="split"))["columns"]]
#renderice html pasando las variables my_data y my_cols que se utilizarán para generar la tabla de datos
return render_template('tablesdata.html', my_data = my_data, my_cols = my_cols)
Paso 5: Mostrar datos en jquery datatableDefinir la tabla con id "myTable" y usar javascript para completar los datos de encabezado y columnas pasados
<table id="myTable" class="table table-bordered table-striped">
</table>
<script>
$(document).ready(function() {
// analizar los datos a la variable local pasada desde el archivo app.py
let my_data = JSON.parse('{{ my_data | tojson }}');
let my_cols = JSON.parse('{{ my_cols | tojson }}');
$('#myTable').DataTable( {
"data": my_data,
"columns": my_cols,"} );
} );
Eso es todo. Para obtener más detalles, consulta la aplicación iris-python-apps en Open Exchange.
Echa un vistazo a esta documentación (en inglés): Resumen de Python Embebido.
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Ricardo Paiva · 22 sep, 2022
¡Hola Comunidad!
Durante años he trabajado en muchos proyectos diferentes y he podido encontrar muchos datos interesantes.
Pero la mayoría de las veces el conjunto de datos con el que trabajaba era de los clientes. Cuando hace un par de años empecé a participar en los Concursos de Programación de InterSystems, comencé a buscar conjuntos de datos web específicos.
Yo mismo he ido seleccionando algunos datos, pero he pensado: "¿Este conjunto de datos es suficiente para ayudar a otras personas?"
Y discutiendo estas ideas con @José.Pereira, decidimos enfocar este tema usando *una perspectiva diferente*.
Pensamos en ofrecer una variedad de conjuntos de datos que provengan de dos famosas fuentes de datos. De este modo, podemos facilitar que los usuarios encuentren e instalen el conjunto de datos que quieran, de forma rápida y sencilla.
## Socrata
La API de datos abiertos de Socrata permite acceder mediante programación a una gran cantidad de recursos de datos abiertos de gobiernos, organizaciones sin ánimo de lucro y ONGs de todo el mundo.
Para esta versión inicial, utilizamos las API de Socrata para buscar y descargar un conjunto de datos específicos.
Abre la herramienta de la API de tu preferencia, como [Postman](https://www.postman.com/), [Hoppscotch](https://hoppscotch.io/)
```
GET> https://api.us.socrata.com/api/catalog/v1?only=dataset&q=healthcare
```
Este *EndPoint* devolverá todos los conjuntos de datos relacionados con la atención sanitaria, como en la siguiente imagen: 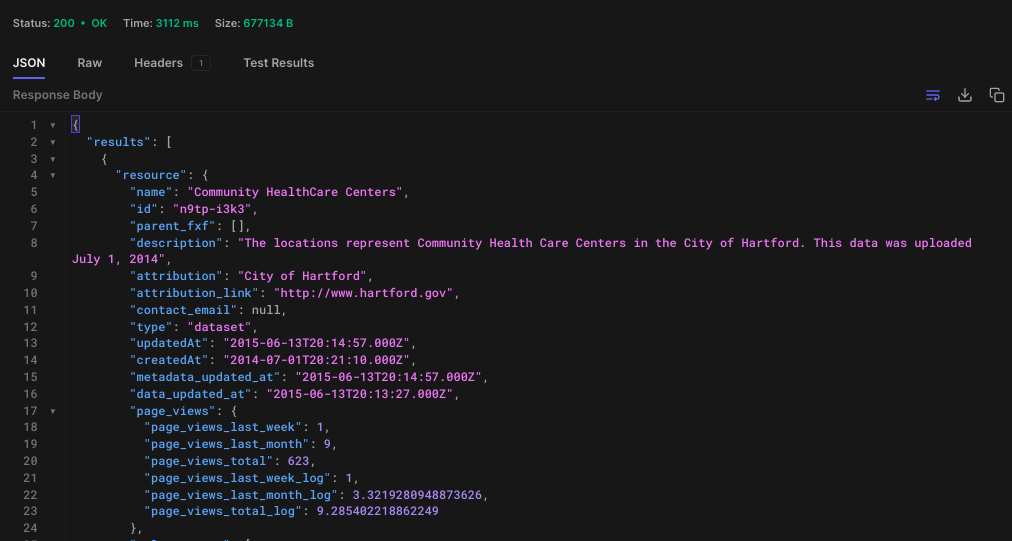
Ahora, consigue el ID. En este caso el ID es: "n9tp-i3k3"
Ve al terminal
```
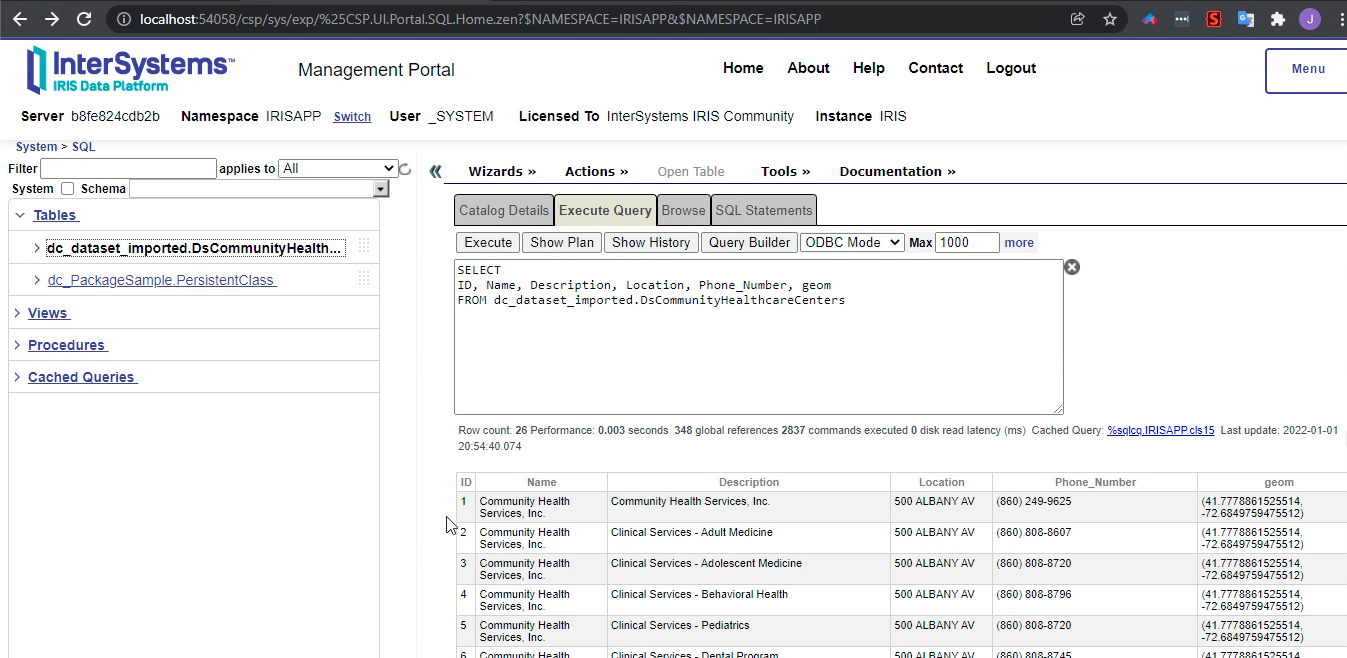
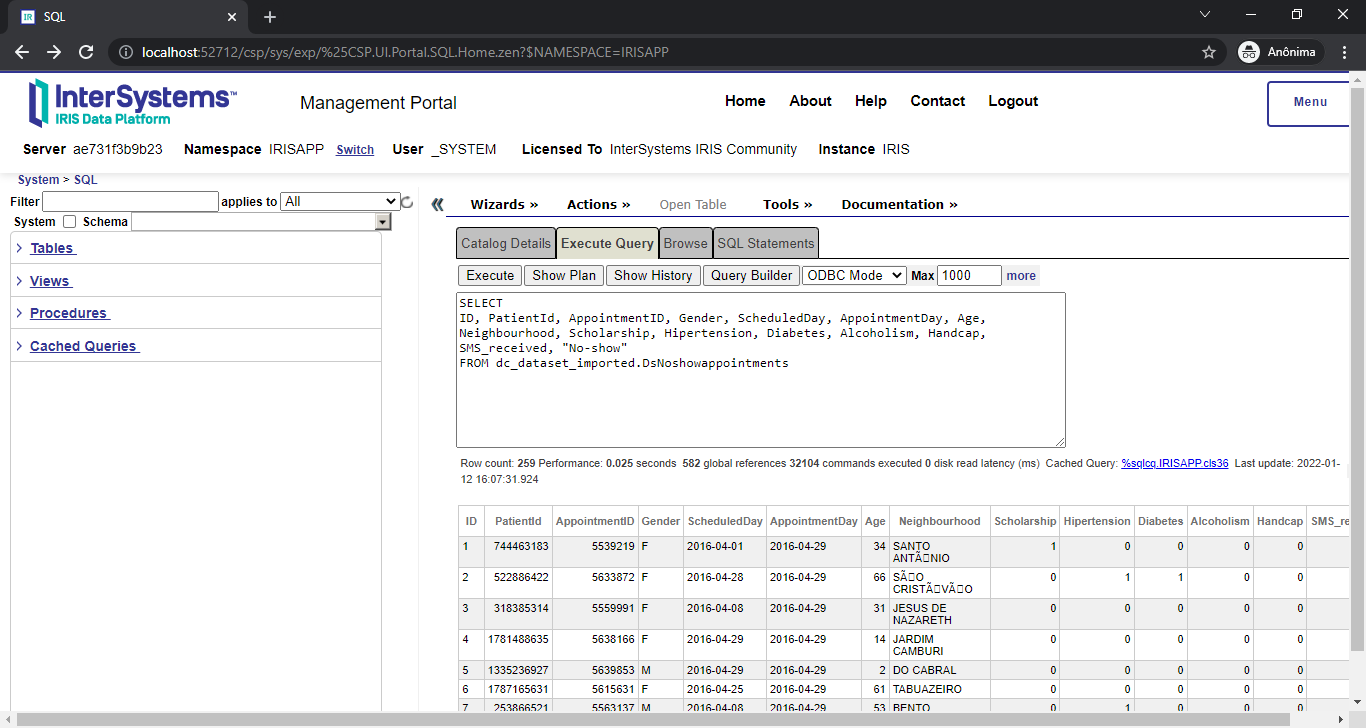
IRISAPP>set api = ##class(dc.dataset.importer.service.socrata.SocrataApi).%New()
IRISAPP>do api.InstallDataset({"datasetId": "n9tp-i3k3", "verbose":true})
Compilation started on 01/07/2022 01:01:28 with qualifiers 'cuk'
Compiling class dc.dataset.imported.DsCommunityHealthcareCenters
Compiling table dc_dataset_imported.DsCommunityHealthcareCenters
Compiling routine dc.dataset.imported.DsCommunityHealthcareCenters.1
Compilation finished successfully in 0.108s.
Class name: dc.dataset.imported.DsCommunityHealthcareCenters
Header: Name VARCHAR(250),Description VARCHAR(250),Location VARCHAR(250),Phone_Number VARCHAR(250),geom VARCHAR(250)
Records imported: 26
```
Después del comando anterior, tu conjunto de datos estará listo para utilizarse!
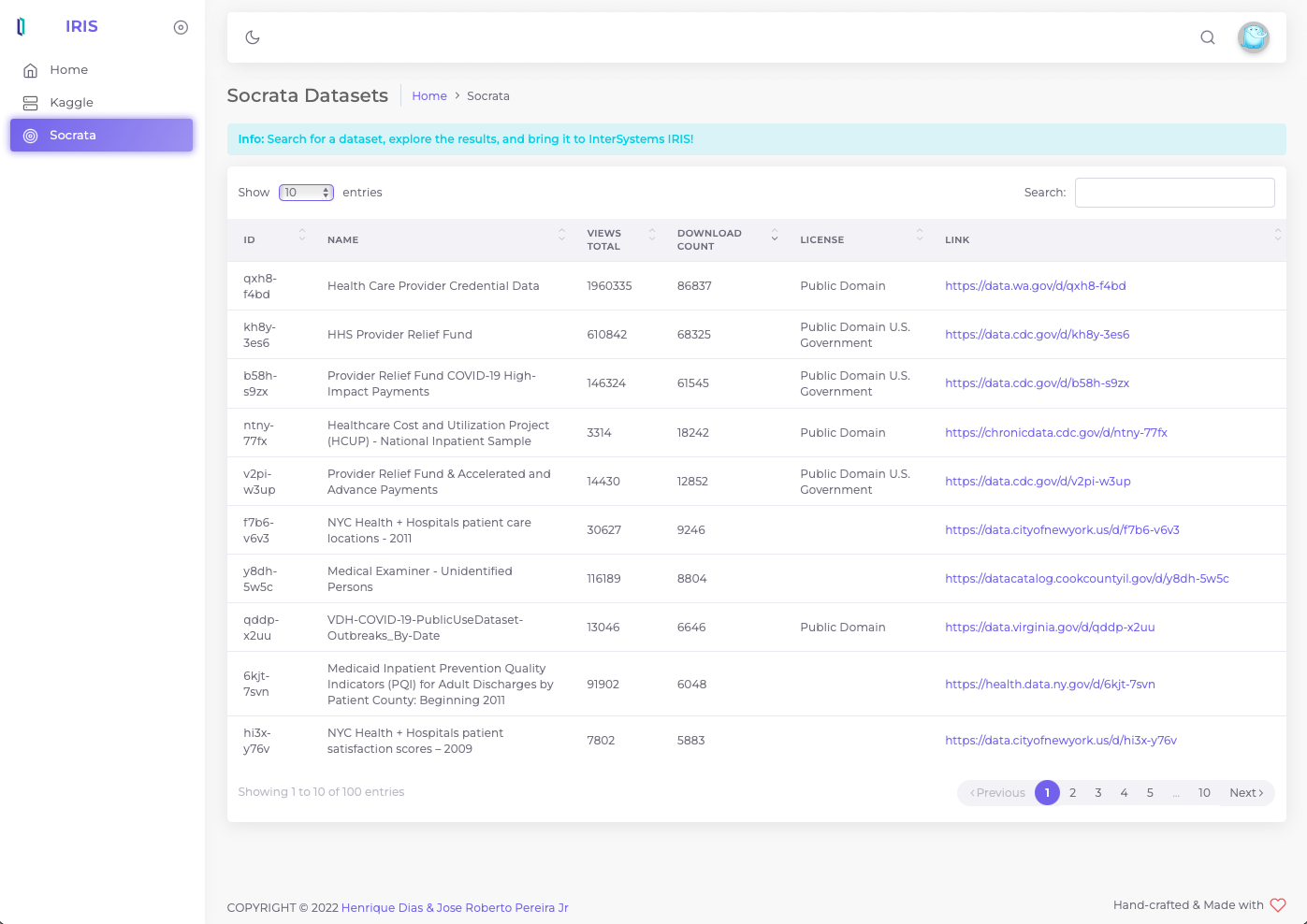
## Kaggle
Kaggle, una filial de Google LLC, es una comunidad en línea de científicos de datos y profesionales del Machine Learning. Kaggle permite que los usuarios encuentren y publiquen conjuntos de datos, exploren y construyan modelos en un entorno de ciencia de datos basados en la web, trabajen con otros científicos de datos e ingenieros de Machine Learning y participen en competiciones para resolver retos de la ciencia de datos.
En junio de 2017 Kaggle anunció que había superado el millón de usuarios registrados, o Kagglers, y desde 2021 cuenta con más de **8 millones de usuarios registrados**. La comunidad abarca **194 países**. Se trata de una comunidad diversa, que va desde los que acaban de empezar hasta muchos de los investigadores más conocidos del mundo.
Esto es lo que yo llamo una gran comunidad, ¡¿cierto?!
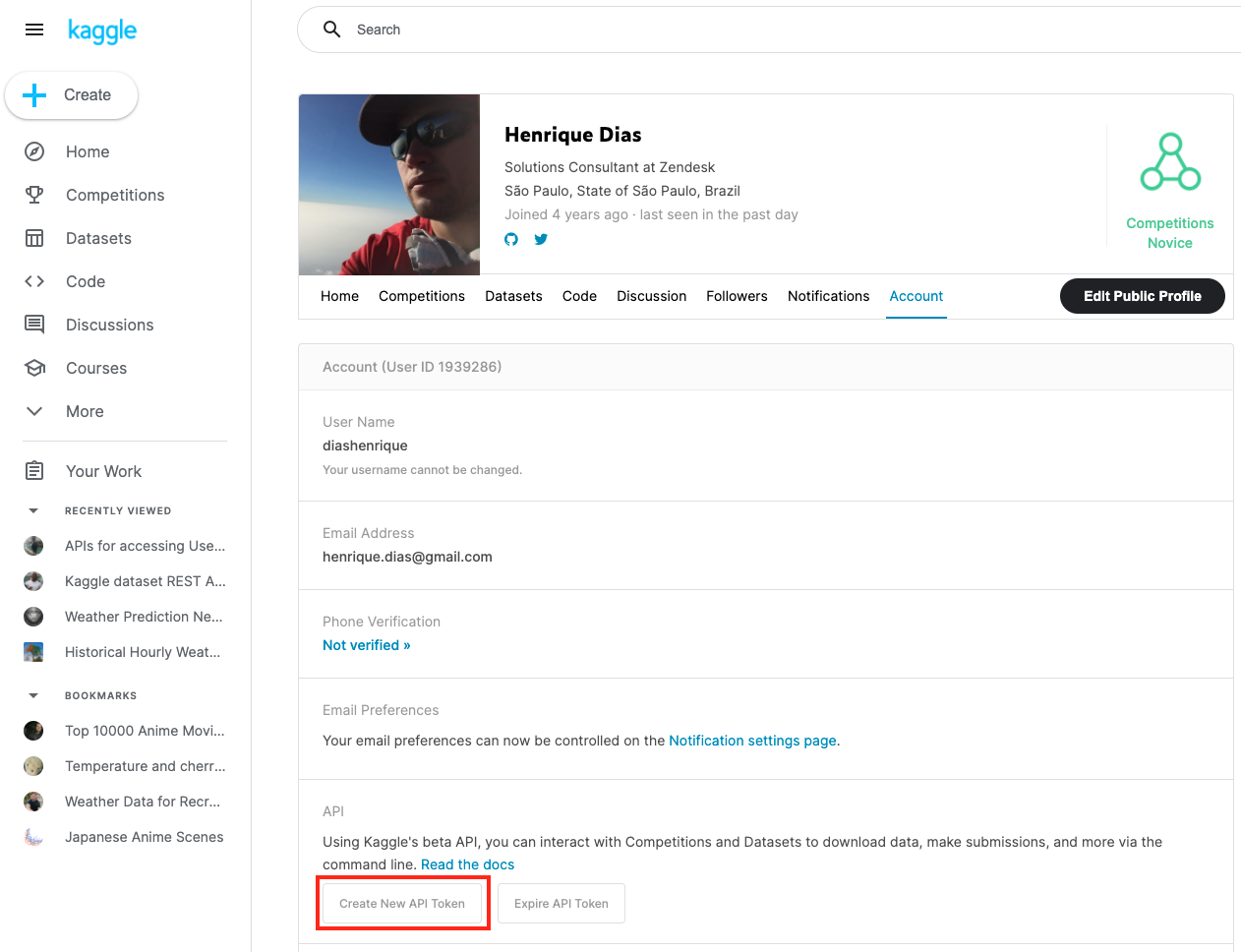
Para utilizar los conjuntos de datos de Kaggle, hay que registrarse en [su página web](https://www.kaggle.com/). Después, hay que crear un token de API para utilizar la API de Kaggle.
Ahora, igual que con Socrata, puedes utilizar la API para buscar y descargar el conjunto de datos.
```
GET> https://www.kaggle.com/api/v1/datasets/list?search=appointments
```
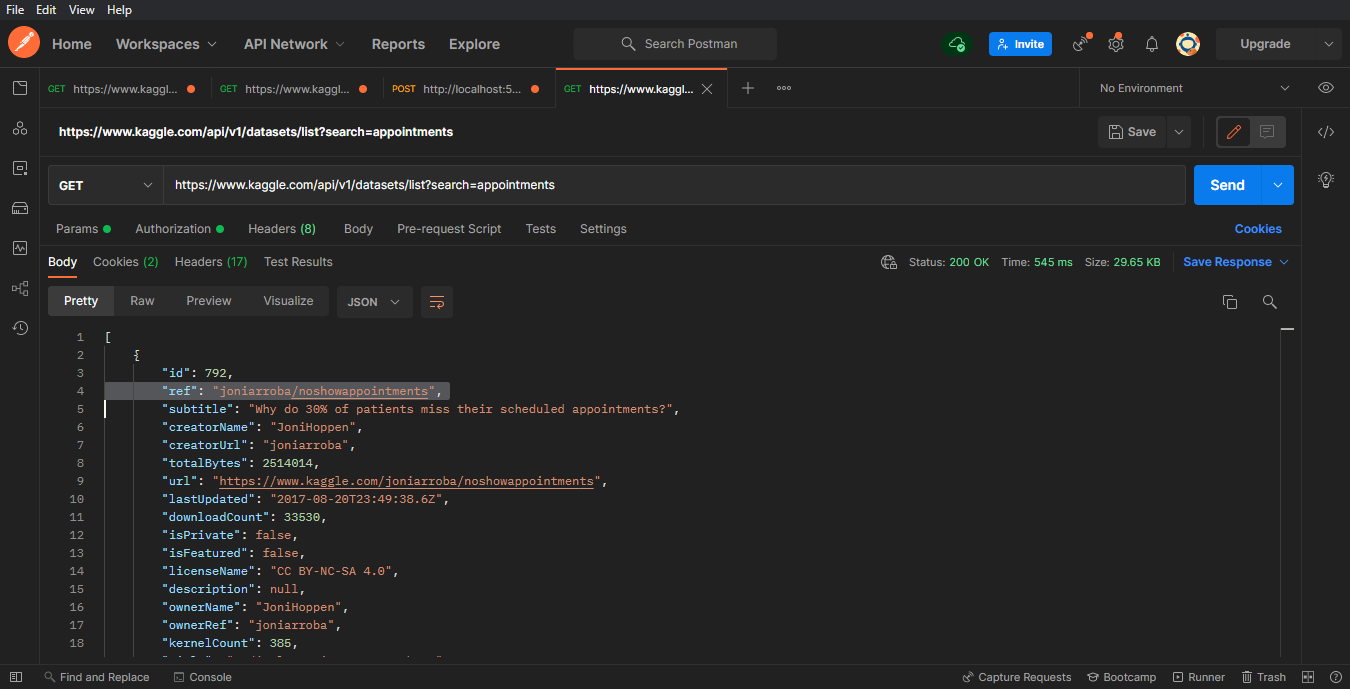
Ahora, obtén el valor de la referencia. En este caso, la referencia es: "joniarroba/noshowappointments"
Los parámetros de abajo "_your-username_" y "_your-password_" son los parámetros que proporciona Kaggle cuando creas el token de API.
```
IRISAPP>Set crendtials = ##class(dc.dataset.importer.service.CredentialsService).%New()
IRISAPP>Do crendtials.SaveCredentials("kaggle", "", "")
IRISAPP>Set api = ##class(dc.dataset.importer.service.kaggle.KaggleApi).%New()
IRISAPP>Do api.InstallDataset({"datasetId":"joniarroba/noshowappointments", "credentials":"kaggle", "verbose":true})
Class name: dc.dataset.imported.DsNoshowappointments
Header: PatientId INTEGER,AppointmentID INTEGER,Gender VARCHAR(250),ScheduledDay DATE,AppointmentDay DATE,Age INTEGER,Neighbourhood VARCHAR(250),Scholarship INTEGER,Hipertension INTEGER,Diabetes INTEGER,Alcoholism INTEGER,Handcap INTEGER,SMS_received INTEGER,No-show VARCHAR(250)
Records imported: 259
```
Después del comando anterior, tu conjunto de datos estará listo para utilizarse!
## Interfaz gráfica de usuario
Para facilitar las cosas, ofrecemos una Interfaz gráfica de usuario para instalar el conjunto de datos. Pero esto es algo que nos gustaría discutir en nuestro próximo artículo. Mientras tanto, a continuación puedes ver un adelanto mientras pulimos algunas cosas antes del lanzamiento oficial:
## Video de demostración
¿Cómo es el funcionamiento para descargar un conjunto de datos más grande? +¡¿Más de 400,000 registros no son suficientes?! ¡¿Qué tal 1 MILLÓN DE REGISTROS?! ¡Vamos a verlo!
Voting
Artículo
Ricardo Paiva · 7 jul, 2022
Si tuvieras la oportunidad de cambiar algo en el Visualizador de Mensajes de Interoperabilidad en IRIS, ¿qué harías?
Después de publicar el artículo Panel de Control "IRIS History Monitor", recibí algunos comentarios muy interesantes y varias peticiones. Una de ellas fue un Visualizador de Mensajes mejorado.
Si aún no lo has hecho, echa un vistazo al proyecto: merece la pena que le dediques un rato, y además ganó el 3er premio (Bronce) a Los mejores desarrolladores y aplicaciones de InterSystems Open Exchange en 2019.
Empecé a pensar algunas ideas sobre lo que me gustaría incluir en el "nuevo" Visualizador de Mensajes pero ¿cómo podría mostrar estos recursos de la forma más rápida y sencilla?
Bueno, antes de nada. Por lo general, se empieza configurando una producción de interoperabilidad, y después se exporta y se implementa en el sistema de destino, como se indica en la documentación. Este es un proceso que realmente no me gusta. En realidad, no es que haya algo malo en él. Solo que he idealizado hacer todo mediante el código.
Espero que cada vez que alguien ejecute este tipo de proyectos, empiece de esta manera:
$ docker-compose build
$ docker-compose up -d
¡¡¡Y eso es todo!!!
Con estos sencillos pasos en mente, comencé a buscar en la comunidad de InterSystems y encontré algunos consejos. En una de las publicaciones surgió la pregunta que me estaba haciendo: ¿Cómo crear producciones desde una rutina?
En esa publicación, @Eduard.Lebedyuk respondió, mostrando cómo crear una producción mediante el uso de un código.
"Para crear la clase de producción de forma automática es necesario:
Crear el objeto %Dictionary.ClassDefinition para tu producción de prueba
Crear el objeto Ens.Config.Production
Crear %Dictionary.XDataDefinition
Serializar (2) en (3)
Insertar XData (3) en (1)
Guardar y compilar (1)"
También encontré un comentario de @jennifer.ames:
"Una de las prácticas que recomendamos on frecuencia es crear hacia atrás. Crea las business operations primero, después los business processes, después los business services…"
Así que, ¡hagámoslo!
Solicitudes, Business operations y Business services
La clase diashenrique.messageviewer.util.InstallerProduction.cls es, como su nombre lo indica, la clase que se encarga de instalar nuestra producción. El manifiesto del instalador invoca el ClassMethod **Install** desde esa clase:
/// Helper to install a production to display capabilities of the enhanced viewer
ClassMethod Install() As %Status
{
Set sc = $$$OK
Try {
Set sc = $$$ADDSC(sc,..InstallProduction()) quit:$$$ISERR(sc)
Set sc = $$$ADDSC(sc,..GenerateMessages()) quit:$$$ISERR(sc)
Set sc = $$$ADDSC(sc,..GenerateUsingEnsDirector()) quit:$$$ISERR(sc)
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
El ClassMethod InstallProduction reúne la estructura principal que permite crear una producción mediante la creación de:
una solicitud
una business operation
un business service
una producción de interoperabilidad
Dado que la idea es crear una producción de interoperabilidad mediante código, vamos al modo de codificación completa para crear todas las clases para la solicitud, la business operation y los business services. Al hacer eso, haremos un amplio uso de algunos paquetes de librerías de InterSystems:
%Dictionary.ClassDefinition
%Dictionary.PropertyDefinition
%Dictionary.XDataDefinition
%Dictionary.MethodDefinition
%Dictionary.ParameterDefinition
El ClassMethod InstallProduction crea dos clases que se extienden desde Ens.Request, por medio de las siguientes líneas:
Set sc = $$$ADDSC(sc,..CreateRequest("diashenrique.messageviewer.Message.SimpleRequest","Message")) quit:$$$ISERR(sc)
Set sc = $$$ADDSC(sc,..CreateRequest("diashenrique.messageviewer.Message.AnotherRequest","Something")) quit:$$$ISERR(sc)
ClassMethod CreateRequest(classname As %String, prop As %String) As %Status [ Private ]
{
New $Namespace
Set $Namespace = ..#NAMESPACE
Set sc = $$$OK
Try {
Set class = ##class(%Dictionary.ClassDefinition).%New(classname)
Set class.GeneratedBy = $ClassName()
Set class.Super = "Ens.Request"
Set class.ProcedureBlock = 1
Set class.Inheritance = "left"
Set sc = $$$ADDSC(sc,class.%Save())
#; create adapter
Set property = ##class(%Dictionary.PropertyDefinition).%New(classname)
Set property.Name = prop
Set property.Type = "%String"
Set sc = $$$ADDSC(sc,property.%Save())
Set sc = $$$ADDSC(sc,$System.OBJ.Compile(classname,"fck-dv"))
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
Ahora vamos a crear la clase para una business operation que se extiende desde Ens.BusinessOperation:
Set sc = $$$ADDSC(sc,..CreateOperation()) quit:$$$ISERR(sc)
Además de crear la clase, creamos MessageMap y el método Consume:
ClassMethod CreateOperation() As %Status [ Private ]
{
New $Namespace
Set $Namespace = ..#NAMESPACE
Set sc = $$$OK
Try {
Set classname = "diashenrique.messageviewer.Operation.Consumer"
Set class = ##class(%Dictionary.ClassDefinition).%New(classname)
Set class.GeneratedBy = $ClassName()
Set class.Super = "Ens.BusinessOperation"
Set class.ProcedureBlock = 1
Set class.Inheritance = "left"
Set xdata = ##class(%Dictionary.XDataDefinition).%New()
Set xdata.Name = "MessageMap"
Set xdata.XMLNamespace = "http://www.intersystems.com/urlmap"
Do xdata.Data.WriteLine("<MapItems>")
Do xdata.Data.WriteLine("<MapItem MessageType=""diashenrique.messageviewer.Message.SimpleRequest"">")
Do xdata.Data.WriteLine("<Method>Consume</Method>")
Do xdata.Data.WriteLine("</MapItem>")
Do xdata.Data.WriteLine("<MapItem MessageType=""diashenrique.messageviewer.Message.AnotherRequest"">")
Do xdata.Data.WriteLine("<Method>Consume</Method>")
Do xdata.Data.WriteLine("</MapItem>")
Do xdata.Data.WriteLine("</MapItems>")
Do class.XDatas.Insert(xdata)
Set sc = $$$ADDSC(sc,class.%Save())
Set method = ##class(%Dictionary.MethodDefinition).%New(classname)
Set method.Name = "Consume"
Set method.ClassMethod = 0
Set method.ReturnType = "%Status"
Set method.FormalSpec = "input:diashenrique.messageviewer.Message.SimpleRequest,&output:Ens.Response"
Set stream = ##class(%Stream.TmpCharacter).%New()
Do stream.WriteLine(" set sc = $$$OK")
Do stream.WriteLine(" $$$TRACE(input.Message)")
Do stream.WriteLine(" return sc")
Set method.Implementation = stream
Set sc = $$$ADDSC(sc,method.%Save())
Set sc = $$$ADDSC(sc,$System.OBJ.Compile(classname,"fck-dv"))
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
En el último paso antes de realmente crear la producción de interoperabilidad, vamos a crear la clase responsable del business service:
Set sc = $$$ADDSC(sc,..CreateRESTService()) quit:$$$ISERR(sc)
Esta clase tiene UrlMap y Routes para recibir solicitudes Http.
ClassMethod CreateRESTService() As %Status [ Private ]
{
New $Namespace
Set $Namespace = ..#NAMESPACE
Set sc = $$$OK
Try {
Set classname = "diashenrique.messageviewer.Service.REST"
Set class = ##class(%Dictionary.ClassDefinition).%New(classname)
Set class.GeneratedBy = $ClassName()
Set class.Super = "EnsLib.REST.Service, Ens.BusinessService"
Set class.ProcedureBlock = 1
Set class.Inheritance = "left"
Set xdata = ##class(%Dictionary.XDataDefinition).%New()
Set xdata.Name = "UrlMap"
Set xdata.XMLNamespace = "http://www.intersystems.com/urlmap"
Do xdata.Data.WriteLine("<Routes>")
Do xdata.Data.WriteLine("<Route Url=""/send/message"" Method=""POST"" Call=""SendMessage""/>")
Do xdata.Data.WriteLine("<Route Url=""/send/something"" Method=""POST"" Call=""SendSomething""/>")
Do xdata.Data.WriteLine("</Routes>")
Do class.XDatas.Insert(xdata)
Set sc = $$$ADDSC(sc,class.%Save())
#; create adapter
Set adapter = ##class(%Dictionary.ParameterDefinition).%New(classname)
Set class.GeneratedBy = $ClassName()
Set adapter.Name = "ADAPTER"
Set adapter.SequenceNumber = 1
Set adapter.Default = "EnsLib.HTTP.InboundAdapter"
Set sc = $$$ADDSC(sc,adapter.%Save())
#; add prefix
Set prefix = ##class(%Dictionary.ParameterDefinition).%New(classname)
Set prefix.Name = "EnsServicePrefix"
Set prefix.SequenceNumber = 2
Set prefix.Default = "|demoiris"
Set sc = $$$ADDSC(sc,prefix.%Save())
Set method = ##class(%Dictionary.MethodDefinition).%New(classname)
Set method.Name = "SendMessage"
Set method.ClassMethod = 0
Set method.ReturnType = "%Status"
Set method.FormalSpec = "input:%Library.AbstractStream,&output:%Stream.Object"
Set stream = ##class(%Stream.TmpCharacter).%New()
Do stream.WriteLine(" set sc = $$$OK")
Do stream.WriteLine(" set request = ##class(diashenrique.messageviewer.Message.SimpleRequest).%New()")
Do stream.WriteLine(" set data = {}.%FromJSON(input)")
Do stream.WriteLine(" set request.Message = data.Message")
Do stream.WriteLine(" set sc = $$$ADDSC(sc,..SendRequestSync(""diashenrique.messageviewer.Operation.Consumer"",request,.response))")
Do stream.WriteLine(" return sc")
Set method.Implementation = stream
Set sc = $$$ADDSC(sc,method.%Save())
Set method = ##class(%Dictionary.MethodDefinition).%New(classname)
Set method.Name = "SendSomething"
Set method.ClassMethod = 0
Set method.ReturnType = "%Status"
Set method.FormalSpec = "input:%Library.AbstractStream,&output:%Stream.Object"
Set stream = ##class(%Stream.TmpCharacter).%New()
Do stream.WriteLine(" set sc = $$$OK")
Do stream.WriteLine(" set request = ##class(diashenrique.messageviewer.Message.AnotherRequest).%New()")
Do stream.WriteLine(" set data = {}.%FromJSON(input)")
Do stream.WriteLine(" set request.Something = data.Something")
Do stream.WriteLine(" set sc = $$$ADDSC(sc,..SendRequestSync(""diashenrique.messageviewer.Operation.Consumer"",request,.response))")
Do stream.WriteLine(" return sc")
Set method.Implementation = stream
Set sc = $$$ADDSC(sc,method.%Save())
Set sc = $$$ADDSC(sc,$System.OBJ.Compile(classname,"fck-dv"))
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
Usando Visual Studio Code
Crear las clases mediante el paquete %Dictionary puede ser difícil, y difícil de leer también, pero es práctico. Para mostrar un procedimiento un poco más sencillo con una mejor comprensión del código, también crearé nuevas clases de solicitud, business service y business operations por medio de Visual Studio Code:
diashenrique.messageviewer.Message.SimpleMessage.cls
diashenrique.messageviewer.Operation.ConsumeMessageClass.cls
diashenrique.messageviewer.Service.SendMessage.cls
Class diashenrique.messageviewer.Message.SimpleMessage Extends Ens.Request [ Inheritance = left, ProcedureBlock ]
{
Property ClassMessage As %String;
}
Class diashenrique.messageviewer.Operation.ConsumeMessageClass Extends Ens.BusinessOperation [ Inheritance = left, ProcedureBlock ]
{
Method Consume(input As diashenrique.messageviewer.Message.SimpleMessage, ByRef output As Ens.Response) As %Status
{
Set sc = $$$OK
$$$TRACE(pRequest.ClassMessage)
Return sc
}
XData MessageMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<MapItems>
<MapItem MessageType="diashenrique.messageviewer.Message.SimpleMessage">
<Method>Consume</Method>
</MapItem>
</MapItems>
}
}
Class diashenrique.messageviewer.Service.SendMessage Extends Ens.BusinessService [ ProcedureBlock ]
{
Method OnProcessInput(input As %Library.AbstractStream, ByRef output As %Stream.Object) As %Status
{
Set tSC = $$$OK
// Create the request message
Set request = ##class(diashenrique.messageviewer.Message.SimpleMessage).%New()
// Place a value in the request message property
Set request.ClassMessage = input
// Make a synchronous call to the business process and use the response message as our response
Set tSC = ..SendRequestSync("diashenrique.messageviewer.Operation.ConsumeMessageClass",request,.output)
Quit tSC
}
}
Desde el punto de vista de la legibilidad del código, la diferencia es enorme.
Creando la Producción de Interoperabilidad
Vamos a terminar la creación de nuestra producción de interoperabilidad. Para ello, crearemos una clase de producción, y después la asociaremos con las Business Operation y Business Services.
Set sc = $$$ADDSC(sc,..CreateProduction()) quit:$$$ISERR(sc)
ClassMethod CreateProduction(purge As %Boolean = 0) As %Status [ Private ]
{
New $Namespace
Set $Namespace = ..#NAMESPACE
Set sc = $$$OK
Try {
#; create new production
Set class = ##class(%Dictionary.ClassDefinition).%New(..#PRODUCTION)
Set class.ProcedureBlock = 1
Set class.Super = "Ens.Production"
Set class.GeneratedBy = $ClassName()
Set xdata = ##class(%Dictionary.XDataDefinition).%New()
Set xdata.Name = "ProductionDefinition"
Do xdata.Data.Write("<Production Name="""_..#PRODUCTION_""" LogGeneralTraceEvents=""true""></Production>")
Do class.XDatas.Insert(xdata)
Set sc = $$$ADDSC(sc,class.%Save())
Set sc = $$$ADDSC(sc,$System.OBJ.Compile(..#PRODUCTION,"fck-dv"))
Set production = ##class(Ens.Config.Production).%OpenId(..#PRODUCTION)
Set item = ##class(Ens.Config.Item).%New()
Set item.ClassName = "diashenrique.messageviewer.Service.REST"
Do production.Items.Insert(item)
Set sc = $$$ADDSC(sc,production.%Save())
Set item = ##class(Ens.Config.Item).%New()
Set item.ClassName = "diashenrique.messageviewer.Operation.Consumer"
Do production.Items.Insert(item)
Set sc = $$$ADDSC(sc,production.%Save())
Set item = ##class(Ens.Config.Item).%New()
Set item.ClassName = "diashenrique.messageviewer.Service.SendMessage"
Do production.Items.Insert(item)
Set sc = $$$ADDSC(sc,production.%Save())
Set item = ##class(Ens.Config.Item).%New()
Set item.ClassName = "diashenrique.messageviewer.Operation.ConsumeMessageClass"
Do production.Items.Insert(item)
Set sc = $$$ADDSC(sc,production.%Save())
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
Utilizamos la clase Ens.Config.Item para asociar la clase de producción con las clases Business Operation y Business Service. Puedes hacer esto tanto si creaste tu clase usando el paquete %Dictionary como con VS Code, Studio o Atelier.
En cualquier caso, ¡lo conseguimos! Creamos una producción de interoperabilidad por medio de código.
Pero recuerda el propósito original de todo este código: crear una producción y mensajes para mostrar las funcionalidades del Visualizador de Mensajes mejorado. Usando los métodos de clase siguientes, ejecutaremos los dos business services y generaremos los mensajes.
Generando mensajes con %Net.HttpRequest:
ClassMethod GenerateMessages() As %Status [ Private ]
{
New $Namespace
Set $Namespace = ..#NAMESPACE
Set sc = $$$OK
Try {
Set action(0) = "/demoiris/send/message"
Set action(1) = "/demoiris/send/something"
For i=1:1:..#LIMIT {
Set content = { }
Set content.Message = "Hi, I'm just a random message named "_$Random(30000)
Set content.Something = "Hi, I'm just a random something named "_$Random(30000)
Set httprequest = ##class(%Net.HttpRequest).%New()
Set httprequest.SSLCheckServerIdentity = 0
Set httprequest.SSLConfiguration = ""
Set httprequest.Https = 0
Set httprequest.Server = "localhost"
Set httprequest.Port = 9980
Set serverUrl = action($Random(2))
Do httprequest.EntityBody.Write(content.%ToJSON())
Set sc = httprequest.Post(serverUrl)
Quit:$$$ISERR(sc)
}
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
Generando mensajes con EnsDirector:
ClassMethod GenerateUsingEnsDirector() As %Status [ Private ]
{
New $Namespace
Set $Namespace = ..#NAMESPACE
Set sc = $$$OK
Try {
For i=1:1:..#LIMIT {
Set tSC = ##class(Ens.Director).CreateBusinessService("diashenrique.messageviewer.Service.SendMessage",.tService)
Set message = "Message Generated By CreateBusinessService "_$Random(1000)
Set tSC = tService.ProcessInput(message,.output)
Quit:$$$ISERR(sc)
}
}
Catch (err) {
Set sc = $$$ADDSC(sc,err.AsStatus())
}
Return sc
}
}
Eso todo lo que se necesita para el código. Encontrarás el proyecto completo en https://github.com/diashenrique/iris-message-viewer.
Ejecutando el proyecto
Ahora veamos el proyecto en marcha.
Primero, git clone o git pull el repositorio en cualquier directorio local:
git clone https://github.com/diashenrique/iris-message-viewer.git
Después, abre el terminal en este directorio y ejecuta:
docker-compose build
Finalmente, ejecuta el contenedor IRIS con tu proyecto:
docker-compose up -d
Ahora accederemos al Portal de Administración por medio de la página http://localhost:52773/csp/sys/UtilHome.csp. Deberás ver nuestro namespace de interoperabilidad MSGVIEWER, como en esta imagen:
Esta es nuestra pequeña producción, con dos business services y dos business operations:
Tenemos muchos mensajes:
Con todo en marcha en nuestro Visualizador de Mensajes personalizado, vamos a echar un vistazo a algunas de sus funcionalidades.
El Visualizador de Mensajes mejorado
Ten en cuenta que solo se mostrarán los namespaces que estén habilitados para las producciones de interoperabilidad.
http://localhost:52773/csp/msgviewer/messageviewer.csp
El Visualizador de Mensajes mejorado incorpora funcionalidades y la flexibilidad que permite crear diferentes filtros, agrupar las columnas en n niveles, exportar a Excel y muchas cosas más.
Se pueden utilizar diferentes filtros para conseguir los resultados que se necesitan. También se pueden ordenar las columnas de forma múltiple pulsando la tecla Mayúsculas y haciendo clic en el encabezado de las columnas. ¡Incluso se puede exportar la tabla de datos a Excel!
Además, se pueden crear filtros complejos con la opción Generador de filtros.
Se pueden agrupar los datos con cualquier columna disponible, agrupando la información mediante los n niveles que se desee. De forma predeterminada, el grupo se establece a partir del campo Fecha de creación (Date Created).
Y hay una funcionalidad que permite seleccionar columnas. La siguiente página tiene todas las columnas de Ens.MessageHeader, y muestra solo las columnas predeterminadas en la visualización inicial. Pero se pueden elegir las otras columnas mediante el botón "Seleccionador de columnas" (Column Chooser).
Se pueden contraer o expandir todos los grupos con un solo clic.
La información del campo SessionID incluye un enlace a la función Visual Trace.
Se pueden reenviar mensajes si se necesita. Tan solo hay que seleccionar los mensajes que se necesitan y hacer clic para volver a enviarlos. Esta función utiliza el siguiente método de clase:
##class(Ens.MessageHeader).ResendDuplicatedMessage(id)
Por último, como se mencionó, se puede exportar la tabla de datos a Excel:
El resultado en Excel mostrará el mismo formato, contenido y grupo definidos en las páginas del servidor de caché (CSP).
P.D.: Quiero dar un agradecimiento especial a @Renan.Lourenco, que me ayudó mucho en este viaje.
Artículo
Estevan Martinez · 27 nov, 2019
++ Update: August 1, 2018
El uso de la dirección IP virtual (VIP) de InterSystems incorporada en Mirroring de la base de datos de Caché tiene ciertas limitaciones. En particular, solo puede utilizarse cuando los miembros Mirror se encuentran en la misma subred. Cuando se utilizan varios centros de datos, las subredes normalmente no se “extienden” más allá del centro de datos físico debido a la complejidad añadida de la red (puede obtener más información aquí). Por las mismas razones, la IP virtual con frecuencia no puede utilizarse cuando la base de datos se aloja en la nube.
Los dispositivos para la administración del tráfico de red, como los balanceadores de carga (físicos o virtuales), pueden utilizarse para lograr el mismo nivel de transparencia, presentando una dirección única para las aplicaciones o dispositivos del cliente. El administrador para el tráfico de red redirige automáticamente a los clientes hacia la dirección IP real de la Mirror principal actual. La automatización tiene por objeto satisfacer las necesidades tanto de la tolerancia contra fallos de HA como para la promoción de la DR después de un desastre.
Integración de un Administrador de Tráfico de la Red
Hoy en día existen numerosas opciones en el mercado que son compatibles con la redirección del tráfico de red. Cada una de ellas admite metodologías similares e incluso varias para controlar el flujo de la red basada en los requisitos de la aplicación. Para simplificar estas metodologías, consideramos tres categorías: API llamada por el servidor de base de datos, el Sondeo de la Red de Aplicaciones, o una combinación de ambos.
En la siguiente sección se describirá cada una de estas metodologías y se proporcionará orientación sobre la forma en que cada una de ellas puede integrarse con los productos de InterSystems. En todos los escenarios, el árbitro se utiliza para proporcionar decisiones seguras de la tolerancia contra fallos cuando los miembros Mirror no pueden comunicarse directamente. Puede encontrar más información sobre el árbitro aquí .
Para cumplir con los objetivos de este artículo, en los diagramas de ejemplo se mostrarán 3 miembros Mirror: principal, copia de seguridad y DR asíncronos. Sin embargo, reconocemos que su configuración puede ser más grande o menor a esto.
Opción 1: Sondeo de la Red de Aplicaciones (Recomendado)
En este método, el dispositivo de red con carga equilibrada utiliza el mecanismo de sondeo incorporado para comunicarse con ambos miembros Mirror con el fin de determinar al miembro Mirror principal.
El método de sondeo que utiliza la página mirror_status.cxw de CSP Gateway está disponible en la versión 2017.1, puede utilizarse como método de sondeo en el supervisor de estado del ELB para cada miembro Mirror que se añadió al grupo de servidores del ELB. Únicamente la miembro Mirror principal responderá ‘SUCCESS’, dirigiendo así el tráfico de red solo al miembro Mirror principal que esté activo.
En este método no es necesario agregar cualquier lógica a ^ZMIRROR. Tenga en cuenta que la mayoría de los dispositivos de red con carga equilibrada tienen un límite en la frecuencia de ejecución de la comprobación de estado. Normalmente, la frecuencia más alta no es menor de 5 segundos, lo cual es aceptable para admitir la mayoría de los acuerdos en el nivel de servicio para el tiempo de actividad.
Una solicitud HTTP para el siguiente recurso probará cuál es el estado del miembro espejo para la configuración LOCAL de Caché.
/csp/bin/mirror_status.cxw
Para todos los demás casos, la ruta hacia estas solicitudes de estado de réplica deben resolverse en el servidor de Caché y en el Namespace apropiados, mediante el mismo mecanismo jerárquico, como el que se utiliza para solicitar páginas reales en el CSP.
Por ejemplo, para probar el estado de configuración de la Mirror que presenta a las aplicaciones en la ruta /csp/user/, se utiliza:
/csp/user/mirror_status.cxw
Note: Una licencia CSP no se consume cuando se llama a la comprobación de estado de la Mirror.
Dependiendo de si la instancia de destino es o no un miembro principal activo, la puerta de enlace devolverá alguna de las siguientes respuestas del CSP:
** Éxito (Es el Miembro Principal)
===============================
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 7
SUCCESS
** Se produjo un error (no es el Miembro Principal)
===============================
HTTP/1.1 503 Service Unavailable
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
** Se produjo un error (El servidor de Caché no es compatible con la solicitud Mirror_Status.cxw)
===============================
HTTP/1.1 500 Internal Server Error
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
Considere los siguientes diagramas como un ejemplo de sondeo.
La tolerancia contra fallos se produce automáticamente entre los miembros Mirror síncronos de una tolerancia contra fallos:
En el siguiente diagrama se muestra la promoción de los miembros Mirror asíncronos en la DR dentro del grupo con cargas equilibradas, esto normalmente asume que el mismo dispositivo de red con carga equilibrada brinda servicio a todos los miembros Mirror (los escenarios que están divididos geográficamente se analizan más adelante en este artículo). Según el procedimiento estándar de la DR, la promoción del miembro de recuperación en caso de desastres implica una decisión humana y luego una simple acción administrativa a nivel de la base de datos. Sin embargo, una vez tomada esta acción, no es necesaria ninguna opción administrativa en el dispositivo de red: descubra automáticamente el nuevo principal.
Opción 2: API llamada por el servidor de base de datos
En este método se utiliza el dispositivo para administrar el tráfico de red y tiene un grupo de servidores definido tanto con miembros Mirror de una tolerancia contra fallos como miembros Mirror de una DR asíncrona.
Cuando un miembro Mirror se convierte en el miembro Mirror principal se realiza una llamada de API al dispositivo de red para ajustar la prioridad o ponderación e indicar inmediatamente al dispositivo de red que dirija el tráfico al nuevo miembro Mirror principal.
El mismo modelo se aplica a la promoción de un miembro Mirror de una DR asíncrona en el caso de que los miembros Mirror principal y copia de seguridad dejen de estar disponibles.
Esta API se define en la rutina ^ZMIRROR, específicamente como parte de la llamada al procedimiento: $$CheckBecomePrimaryOK^ZMIRROR()
Dentro de esta llamada de procedimiento, inserte cualquier lógica de API y métodos disponibles para el dispositivo de red correspondiente, como API REST, interfaz de línea de comandos, etc. Al igual que con la IP virtual, este es un cambio abrupto en la configuración de la red y no implica ninguna lógica en las aplicaciones para informar a los clientes que ya existen y están conectados al miembro Mirror principal que el error está sucediendo en la tolerancia contra fallos. Dependiendo de la naturaleza del error, esas conexiones pueden terminar como resultado del error en sí mismo, debido al tiempo de espera o error de la aplicación, debido a que el principal nuevo obliga al principal antiguo a detenerse, o debido al vencimiento del temporizador de mantenimiento TCP utilizado por el cliente.
Como resultado, es posible que los usuarios tengan que volver a conectarse e iniciar sesión. El comportamiento de su aplicación determinaría este comportamiento.
Opción 3: Implementaciones Geográficamente Dispersas
En configuraciones con varios centros de datos y posiblemente implementaciones geográficamente dispersas, tales como implementaciones en nube con varias zonas de disponibilidad y zonas geográficas, surge la necesidad de tener en cuenta las prácticas de redireccionamiento geográfico en un modelo simple y fácilmente compatible que utiliza tanto el balanceo de cargas basado en DNS como el balanceo de cargas local.
Con este modelo de combinación, se introduce un dispositivo de red adicional que funciona con servicios DNS como Amazon Route 53, F5 Global Traffic Manager, Balanceador de carga global del servidor Citrix NetScaler o Cisco Global Site Selector en combinación con balanceadores de carga de red en cada centro de datos, zona de disponibilidad o georregión de nube.
En este modelo, el sondeo (recomendado ) o los métodos de API descritos anteriormente se utilizan de forma local para ubicar la operación de cualquiera de los miembros Mirror (tolerancia contra fallos o DR asíncrono). Se utiliza para informar al dispositivo de red geográfica/global si puede dirigir el tráfico a cualquiera de los centros de datos. También, en esta configuración, el dispositivo de administración para el tráfico de la red local presenta su propio VIP al dispositivo de red geográfica/global.
En un estado normal de equilibrio, el miembro Mirror principal activo informa al dispositivo de red local que es principal y proporciona un estado “Up”. Este estado “Up” se transmite al dispositivo geográfico/global para ajustar y mantener el registro DNS con el fin de reenviar todas las solicitudes a este miembro Mirror principal activo.
En un escenario de tolerancia contra fallos dentro del mismo centro de datos (el miembro Mirror síncrono de la copia de seguridad se convierte en principal), se utiliza una API o un método de sondeo con el balanceador de cargas local para ahora redirigirlo al nuevo miembro Mirror principal dentro del mismo centro de datos. No se realizan cambios en el dispositivo geográfico/global ya que el balanceador de carga local sigue respondiendo con el estado “Up” porque el nuevo miembro espejo principal está activo.
Con el fin de cumplir los objetivos de este ejemplo, el método API se utiliza en el siguiente diagrama para la integración local en el dispositivo de red.
En un escenario de tolerancia contra fallos a un centro de datos diferente (ya sea una miembro Mirror síncrona o un miembro Mirror de una DR asíncrona en un centro de datos alternativo) que utiliza la API o los métodos de sondeo, el miembro Mirror principal recién promovido comienza a informar como principal al dispositivo de red local.
Durante la tolerancia contra fallos, el centro de datos que antes contenía al principal ya no reporta “Up” desde el balanceador de carga local al geográfico/global. El dispositivo geográfico/global no dirigirá el tráfico a ese dispositivo local. El dispositivo local del centro de datos alternativo reportará “Up” al dispositivo geográfico/global e llamará la actualización del registro DNS ahora directamente a la IP virtual presentada por el balanceador de carga local del centro de datos alternativo.
Opción 4: Implementaciones geográficamente dispersas y en varios niveles
Para llevar la solución un paso más allá, la introducción de un nivel de servidor web separado se realiza como una WAN interna a privada o accesible mediante Internet. Esta opción puede ser un modelo de implementación normal para aplicaciones de grandes empresas.
En el siguiente ejemplo se visualiza una muestra de configuración que utiliza varios dispositivos de red para aislar y dar soporte de forma segura a la web y los niveles de las base de datos. En este modelo se utilizan dos ubicaciones geográficamente dispersas, una de las cuales se considera la ubicación “principal” y la otra es puramente de “recuperación en caso de desastres” para el nivel de la base de datos. La ubicación de la recuperación en caso de desastres del nivel de la base de datos debe utilizarse en caso de que la ubicación principal esté fuera de servicio por cualquier motivo. Además, el nivel web de este ejemplo se ilustrará como activo-activo, lo cual significa que los usuarios son dirigidos a cualquiera de las dos ubicaciones basándose en varias reglas como la menor latencia, las conexiones menores, los rangos de direcciones IP u otras reglas de enrutamiento que usted considere apropiadas.
Como se muestra en el ejemplo anterior, en el caso de una tolerancia contra fallos dentro de la misma ubicación, se produce una tolerancia contra fallos automática y el dispositivo de red local apunta ahora al nuevo principal. Los usuarios aún se conectan a los servidores web de cualquiera de las dos ubicaciones y los servidores web con su CSP Gateway asociada continúan apuntando a la Ubicación A.
En el siguiente ejemplo, considere una tolerancia contra fallos o una interrupción completa en la Ubicación A en la que tanto el principal o los miembros Mirror de la tolerancia contra fallos en la copia de seguridad estén fuera de servicio. Los miembros Mirror de la DR asíncrona entonces serían promovidos manualmente a principal y miembros Mirror de la tolerancia contra fallos de la copia de seguridad. A partir de esa promoción, el nuevo miembro Mirror principal designado permitirá que el dispositivo de balanceo de carga que se encuentra en la Ubicación B informe “Up” mediante el método API discutido anteriormente (el método de sondeo también es una opción). Como resultado del balanceador de carga local que ahora informa “Up”, el dispositivo basado en DNS reconocerá y redirigirá el tráfico de la ubicación A a la ubicación B para los servicios en el servidor de base de datos.
Conclusión
Existen muchas permutaciones posibles para diseñar Mirror de una tolerancia contra fallos sin una IP virtual. Estas opciones pueden aplicarse tanto a los escenarios de alta disponibilidad más simples como a las implementaciones en regiones multigeográficas con varios niveles, incluidos los miembros espejo de la DR asíncrona para obtener una solución altamente disponible y tolerante a los desastres que tenga el objetivo de mantener los más altos niveles de resiliencia operativa en sus aplicaciones.
Esperamos que este artículo haya proporcionado algo de conocimiento acerca de las diferentes combinaciones y casos de uso posibles para implementar con éxito Mirror de bases de datos con tolerancia contra fallos que sean adecuados para sus necesidades de aplicación y disponibilidad.
Artículo
Luis Angel Pérez Ramos · 27 jun, 2023
Como sabréis, si leeis habitualmente los artículos que se publican en la Comunidad, el pasado mes de mayo InterSystems organizó el Hackaton del JOnTheBeach2023 celebrado en Málaga. El tema que se propuso fue el del uso de las herramientas de análisis predictivo que InterSystems IRIS pone a disposición de todos los desarrolladores con IntegratedML. Debemos agradecer tanto a @Thomas.Dyar como a @Dmitry.Maslennikov todo el trabajo y el empeño que pusieron para que fuese un rotundo éxito.
Introduzcamos brevemente IntegratedML:
IntegratedML
IntegratedML es una herramienta de análisis predictivo que permite a cualquier desarrollador simplificar las tareas necesarias para el diseño, elaboración y prueba de modelos predictivos.
Nos permite pasar de un modelo de diseño así:
A uno mucho más rapido y sencillo como este:
Y lo hace utilizando comandos SQL, de tal forma que todo sea mucho más sencillo y cómodo de utilizar. IntegratedML también nos permite elegir qué motor vamos a usar en la creación de nuestro modelo, pudiendo así elegir el que más adecuado nos resulte.
¿Cómo verlo en acción?
Siempre que he visto presentaciones de IntegratedML me ha encantado su sencillez, pero me quedaba la duda de cómo traspasar esa sencillez de su uso a un caso real. Pensando un poco en nuestros clientes habituales recordé lo común que es el uso de IRIS para integrar los datos de las aplicaciones departamentales de los hospitales con un HIS y la gran cantidad de información de episodios clínicos disponible en todos ellos, así que me puse manos a la obra para montar un ejemplo completo.
Tenéis el código fuente en Open Exchange. El proyecto se arranca con Docker y sólo deberéis alimentar la producción desplegada con los archivos adjuntos que iremos mostrando.
Como podéis ver el proyecto contiene clases de ObjectScript que se van a cargar automáticamente en el momento de construir la imagen. Para ello sólo necesitáis abrir el terminal de VS Code y ejecutar los siguientes comandos (con Docker arrancado).
docker-compose build
docker-compose up -d
Al arrancar el contenedor se va a crear un namespace llamado MLTEST y se arrancará una producción en el que encontraremos todos los componentes del negocio necesarios para la ingesta de los datos en crudo, la creación del modelo, su entrenamiento y su posterior puesta en práctica mediante la recepción de mensajería HL7.
Pero no nos adelantemos aún y sigamos el gráfico del análisis predictivo.
Adquisición de los datos
Muy bien, acotemos el objetivo de nuestra predicción. Rebuscando por páginas de la Administración Pública de España encontré unos cuantos CSV que encajaban perfectamente con el universo de integraciones con origen y destino en un HIS. En este caso el fichero que elegí fue el relativo a los datos de ingresos y altas hospitalarias por rotura de cadera en Castilla y León entre los años 2020 y 2022.
Como véis tenemos datos como la edad y sexo del paciente, fechas de ingreso y alta y centro hospitalario. Perfecto, con estos datos podríamos intentar predecir la estancia hospitalaria de cada paciente, es decir, el número de días entre ingreso y alta.
Tenemos un CSV pero necesitamos almacenarlo en nuestro IRIS y nada más sencillo que usar el Record Mapper de IRIS. El resultado del uso de Record Mapper lo podéis ver en la columna de Business Services de la producción de MLTEST:
CSVToEpisodeTrain es el BS encargado de leer el CSV y enviar los datos al BP MLTEST.BP.RecordToEpisodeTrain que explicaremos más adelante. Los datos obtenidos por este BS serán los usados para entrenar nuestro modelo.
CSVToEpisode es el BS que leera los datos del CSV que usaremos posteriormente para lanzar predicciones de prueba antes de poner en marcha nuestras predicciones obtenidas a partir de mensajes HL7.
Ambos BS van a crear por cada línea del CSV un objeto de la clase User.IctusMap.Record.cls que se lo enviarán a sus respectivos BP donde se realizarán las transformaciones necesarias para finalmente obtener registros de nuestras tablas MLTEST_Data.Episode y MLTEST_Data.EpisodeTrain, esta última será la tabla que usaremos para generar el modelo de predicción, mientras que la anterior es donde almacenaremos nuestros episodios.
Preparación de los datos
Antes de crear nuestro modelo deberemos transformar la lectura del CSV en objetos que sean fácilmente utilizables por el motor de predicciones y para ello usaremos los siguientes BP:
MLTEST.BP.RecordToEpisode: que nos realizará la transformación del registro de CSV a nuestra tabla de episodios MLTEST_Data.Episode
MLTEST.BP.RecordToEpisodeTrain: que realiza la misma transformación que en el caso anterior pero almacenando el episodio en MLTEST_Data.EpisodeTrain.
Podríamos haber usado un sólo BP para el registro en ambas tablas, pero para que sea más claro el proceso lo dejaremos así. En la transformación realizada por los BP hemos reemplazado todos los campos de texto por valores numéricos para agilizar el entrenamiento del modelo.
Muy bien, tenemos nuestros BS y nuestros BP funcionando, alimentemoslos copiando en el proyecto el archivo /shared/train-data.csv a la ruta /shared/csv/trainIn:
Aquí tenemos todos los registros de nuestro archivo consumidos, transformados y registrados en nuestra tabla de entrenamiento. Repitamos la operación con los registros que vamos a usar para una primera prueba de predicciones. Copiando /shared/test-data.csv a la ruta /shared/csv/newIn ya tendríamos todo preparado para crear nuestro modelo.
En este proyecto no sería necesario que ejecutáseis las instrucciones de creación y entrenamiento, ya que se encuentran incluidas en el BO que gestiona el registro de los datos recibidos por mensajería HL7, pero para que lo podáis ver con más detalle vamos a hacerlo antes de probar la integración con los mensajes HL7.
AutoML
Tenemos nuestros datos de entrenamiento y nuestros datos de prueba, creemos nuestro modelo. Para ello accederemos desde el namespace MLTEST a la pantalla SQL de nuestro IRIS (System Explorer --> SQL) y ejecutaremos los siguientes comandos:
CREATE MODEL StayModel PREDICTING (Stay) FROM MLTEST_Data.EpisodeTrain
En esta query estamos creando un modelo de predicción llamado StayModel que va a predecir el valor de la columna Stay (estancia) de nuestra tabla con episodios de entrenamiento. La columna de estancia no venía en nuestro CSV pero la hemos calculado en el BP encargado de la transformación del registro de CSV.
A continuación procedemos a entrenar el modelo:
TRAIN MODEL StayModel
Esta instrucción como el lógico le llevará un tiempo pero una vez que concluya el entrenamiento podremos validar el modelo con nuestros datos de prueba ejecutando la siguiente instrucción:
VALIDATE MODEL StayModel FROM MLTEST_Data.Episode
Esta instrucción nos calculará como de aproximadas son nuestras estimaciones. Como podréis imaginar con los datos que tenemos, estas no serán precisamente para tirar cohetes. Podéis visualizar el resultado de la validación con la siguiente consulta:
SELECT * FROM INFORMATION_SCHEMA.ML_VALIDATION_METRICS
A partir de las metricas que obtenemos con esa consulta podemos inferir que el el modelo elegido automáticamente por AutoML es de clasificación en lugar de un modelo de regresión. Expliquemos que significan los resultados obtenidos (¡gracias @Yuri.Gomes por tu artículo!):
Precision: se calcula dividiendo la cantidad de verdaderos positivos por la cantidad de positivos previstos (suma de verdaderos positivos y falsos positivos).
Recall: se calcula dividiendo el número de verdaderos positivos por el número de positivos reales (suma de verdaderos positivos y falsos negativos).
F-Measure: calculado por la siguiente expresión: F = 2 * (Precision * Recall) / (Precision + Recall)
Accuracy: calculado por la división del número de positivos verdaderos y negativos verdaderos por el numero total de filas (suma de positivos verdaderos, falsos positivos, negativos verdaderos y falsos negativos) de todo el conjunto de datos.
Con esta explicación ya podemos entender como de bueno es el modelo generado:
Como véis, en números generales nuestro modelo es bastante malo, apenas alcanzamos un 35% de aciertos, si entramos en más detalle vemos que para estancias cortas la precisión anda entre el 35% y el 50%, por lo que seguramente necesitaríamos ampliar los datos que tenemos con información a cerca de posibles patologías que pueda tener el paciente y el triaje respecto a la fractura.
Como no disponemos de esos datos que afinarían mucho más nuestro modelo vamos a imaginar que con lo que tenemos es más que suficiente para nuestro objetivo, así que ya podemos empezar a alimentar nuestra producción con mensajes ADT_A01 de admisión de pacientes y veremos las predicciones que obtenemos.
Puesta en producción
Con el modelo ya entrenado sólo nos resta preparar la producción para crear un registro en nuestra tabla MLTEST_Data.Episode por cada mensaje recibido. Veamos los componentes de nuestra producción:
HL7ToEpisode: es el BS que capturará el archivo con mensajes HL7. Este BS redirigirá los mensajes al BP MLTEST.BP.RecordToEpisodeBPL
MLTEST.BP.RecordToEpisodeBPL: este BPL tendrá los siguientes pasos.
Transformación del HL7 en un objeto MLTEST.Data.Episode
Registro en la base de datos del objeto Episodio.
Consulta al BO MLTEST.BO.PredictStayEpisode para obtener la predicción de días de hospitalización.
Escritura de traza con la predicción obtenida.
MLTEST.BO.PredictStayEpisode: BO encargado de lanzar de forma automática las consultas necesarias al modelo de predicción. Si este no existe se encargará de crearlo y entrenarlo automáticamente, de tal forma que no será necesario ejecutar los comandos de sql. Echemos un vistazo al código.
Class MLTEST.BO.PredictStayEpisode Extends Ens.BusinessOperation
{
Property ModelName As %String(MAXLEN = 100);
/// Description
Parameter SETTINGS = "ModelName";
Parameter INVOCATION = "Queue";
/// Description
Method PredictStay(pRequest As MLTEST.Data.PredictionRequest, pResponse As MLTEST.Data.PredictionResponse) As %Status
{
set predictionRequest = pRequest
set pResponse = ##class("MLTEST.Data.PredictionResponse").%New()
set pResponse.EpisodeId = predictionRequest.EpisodeId
set tSC = $$$OK
// CHECK IF MODEL EXISTS
set sql = "SELECT MODEL_NAME FROM INFORMATION_SCHEMA.ML_MODELS WHERE MODEL_NAME = '"_..ModelName_"'"
set statement = ##class(%SQL.Statement).%New()
set status = statement.%Prepare(sql)
if ($$$ISOK(status)) {
set resultSet = statement.%Execute()
if (resultSet.%SQLCODE = 0) {
set modelExists = 0
while (resultSet.%Next() '= 0) {
if (resultSet.%GetData(1) '= "") {
set modelExists = 1
// GET STAY PREDICTION WITH THE LAST EPISODE PERSISTED
set sqlPredict = "SELECT PREDICT("_..ModelName_") AS PredictedStay FROM MLTEST_Data.Episode WHERE %ID = ?"
set statementPredict = ##class(%SQL.Statement).%New(), statement.%ObjectSelectMode = 1
set statusPredict = statementPredict.%Prepare(sqlPredict)
if ($$$ISOK(statusPredict)) {
set resultSetPredict = statementPredict.%Execute(predictionRequest.EpisodeId)
if (resultSetPredict.%SQLCODE = 0) {
while (resultSetPredict.%Next() '= 0) {
set pResponse.PredictedStay = resultSetPredict.%GetData(1)
}
}
}
else {
set tSC = statusPredict
}
}
}
if (modelExists = 0) {
// CREATION OF THE PREDICTION MODEL
set sqlCreate = "CREATE MODEL "_..ModelName_" PREDICTING (Stay) FROM MLTEST_Data.EpisodeTrain"
set statementCreate = ##class(%SQL.Statement).%New()
set statusCreate = statementCreate.%Prepare(sqlCreate)
if ($$$ISOK(status)) {
set resultSetCreate = statementCreate.%Execute()
if (resultSetCreate.%SQLCODE = 0) {
// MODEL IS TRAINED WITH THE CSV DATA PRE-LOADED
set sqlTrain = "TRAIN MODEL "_..ModelName
set statementTrain = ##class(%SQL.Statement).%New()
set statusTrain = statementTrain.%Prepare(sqlTrain)
if ($$$ISOK(statusTrain)) {
set resultSetTrain = statementTrain.%Execute()
if (resultSetTrain.%SQLCODE = 0) {
// VALIDATION OF THE MODEL WITH THE PRE-LOADED EPISODES
set sqlValidate = "VALIDATE MODEL "_..ModelName_" FROM MLTEST_Data.Episode"
set statementValidate = ##class(%SQL.Statement).%New()
set statusValidate = statementValidate.%Prepare(sqlValidate)
if ($$$ISOK(statusValidate)) {
set resultSetValidate = statementValidate.%Execute()
if (resultSetValidate.%SQLCODE = 0) {
// GET STAY PREDICTION WITH THE LAST EPISODE PERSISTED
set sqlPredict = "SELECT PREDICT("_..ModelName_") AS PredictedStay FROM MLTEST_Data.Episode WHERE %ID = ?"
set statementPredict = ##class(%SQL.Statement).%New(), statement.%ObjectSelectMode = 1
set statusPredict = statementPredict.%Prepare(sqlPredict)
if ($$$ISOK(statusPredict)) {
set resultSetPredict = statementPredict.%Execute(predictionRequest.EpisodeId)
if (resultSetPredict.%SQLCODE = 0) {
while (resultSetPredict.%Next() '= 0) {
set pResponse.PredictedStay = resultSetPredict.%GetData(1)
}
}
}
else {
set tSC = statusPredict
}
}
}
else {
set tSC = statusValidate
}
}
}
else {
set tSC = statusTrain
}
}
}
else {
set tSC = status
}
}
}
}
else {
set tSC = status
}
quit tSC
}
XData MessageMap
{
<MapItems>
<MapItem MessageType="MLTEST.Data.PredictionRequest">
<Method>PredictStay</Method>
</MapItem>
</MapItems>
}
}
Como podéis observar, tenemos una propiedad que nos servirá para definir el nombre que queremos para nuestro modelo de predicción e inicialmente lanzaremos una consulta a la tabla ML_MODELS para asegurarnos de que el modelo exista.
Pues bien, ya estamos listos para lanza nuestros mensajes, para ello copiaremos el fichero del proyecto /shared/messagesa01.hl7 a la carpeta /shared/hl7/in esta acción nos enviará 50 mensajes de datos generados a nuestra producción. Veamos algunas de las predicciones.
Para nuestra paciente Sonia Martínez con 2 meses de edad tendremos una estancia de...
¡8 días! Le deseamos una pronta recuperación.
Veamos a otro paciente:
Ana Torres Fernández, de 50 años de edad...
9 días de estancia para ella.
Pues por hoy es todo. Lo menos importante de este ejemplo es el valor numérico de la predicción, ya véis que es bastante pobre por las estadísticas que hemos obtenido, pero os podrá resultar muy útil para casos en los que tengáis un buen conjunto de datos sobre el que aplicar esta funcionalidad tan genial de IntegratedML.
Si tenéis ganas de trastear con ella podéis descargaros la versión Community o usar la configurada en el proyecto de OpenExchange asociada a este artículo.
Si tenéis cualquier duda o necesitais alguna aclaración no dudéis en preguntar en los comentarios.
Artículo
Luis Angel Pérez Ramos · 17 jul, 2023
Hola de nuevo a todos.
En nuestro artículo anterior vimos como configurar nuestro EMPI para recibir mensajería FHIR. Para ello instalábamos el Adaptador FHIR que InterSystems pone a nuestra disposición que configuraba un endpoint REST al que podíamos enviar nuestro mensaje FHIR. A continuación obteníamos el mensaje y lo transformábamos a un %String que enviábamos vía TCP a la producción de nuestro EMPI configurada en nuestro namespace HSPIDATA.
Muy bien, es el momento de ver como recuperamos el mensaje, lo transformamos nuevamente a un %DynamicObject y lo parseamos a la clase usada por el EMPI para almacenar la información.
Recepción de mensaje por TCP
Como hemos indicado, desde la producción que tiene configurada la recepción de recursos FHIR hemos enviado un mensaje a un puerto específico TCP en el que tenemos escuchando un Business Service, en nuestro caso este Business Service será un simple EnsLib.TCP.PassthroughService cuyo objetivo es capturar el mensaje y reenviarlo a un Business Process donde realizaremos la transformación de datos precectiva.
Aquí tenemos nuestro Business Service:
Y aquí la configuración básica de la misma:
Transformación de nuestro mensaje FHIR
Como podéis ver sólo hemos configurado el puerto en el que se va a recibir nuestro mensaje vía TCP y el componente al que vamos a enviar nuestro mensaje, en nuestro caso lo hemos llamado Local.BP.FHIRProcess, echemos un vistazo a dicha clase para ver como recuperamos la información de nuestro recurso FHIR:
Class Local.BP.FHIRProcess Extends Ens.BusinessProcess [ ClassType = persistent ]
{
Method OnRequest(pRequest As Ens.StreamContainer, Output pResponse As Ens.Response) As %Status
{
set tDynObj = {}.%FromJSON(pRequest.Stream)
If (tDynObj '= "") {
set hubRequest = ##class(HS.Message.AddUpdateHubRequest).%New()
// Create AddUpdateHub Message
// Name, sex, DOB
set givenIter = tDynObj.name.%Get(0).given.%GetIterator()
while givenIter.%GetNext(, .givenName){
if (hubRequest.FirstName '= "")
{
Set hubRequest.FirstName=givenName
}
else {
Set hubRequest.FirstName=hubRequest.FirstName_" "_givenName
}
}
Set hubRequest.FirstName=tDynObj.name.%Get(0).given.%Get(0)
Set hubRequest.LastName=tDynObj.name.%Get(0).family
Set hubRequest.Sex=tDynObj.gender
Set hubRequest.DOB=hubRequest.DOBDisplayToLogical(tDynObj.birthDate)
// Inserts full birth name information for the patient
set nameIter = tDynObj.name.%GetIterator()
while nameIter.%GetNext(, .name){
Set tName = ##class(HS.Types.PersonName).%New()
if (name.prefix '= "")
{
Set tName.Prefix = name.prefix.%Get(0)
}
Set tName.Given = name.given.%Get(0)
Set tName.Middle = ""
Set tName.Family = name.family
Set tName.Suffix = ""
Set tName.Type=^Ens.LookupTable("TypeOfName",name.use)
Do hubRequest.Names.Insert(tName)
}
set identIter = tDynObj.identifier.%GetIterator()
while identIter.%GetNext(, .identifier){
if (identifier.type'=""){
if (identifier.type.coding.%Get(0).code = "MR") {
Set hubRequest.MRN = identifier.value
Set hubRequest.AssigningAuthority = ^Ens.LookupTable("hospital",identifier.system)
Set hubRequest.Facility = ^Ens.LookupTable("hospital",identifier.system)
}
elseif (identifier.type.coding.%Get(0).code = "SS") {
Set hubRequest.SSN = identifier.value
}
else {
Set tIdent=##class(HS.Types.Identifier).%New()
Set tIdent.Root = identifier.system // refers to an Assigning Authority entry in the OID Registry
Set tIdent.Extension = identifier.value
Set tIdent.AssigningAuthorityName = identifier.system
Set tIdent.Use = identifier.type.coding.%Get(0).code
Do hubRequest.Identifiers.Insert(tIdent)
}
}
}
// Address
set addressIter = tDynObj.address.%GetIterator()
while addressIter.%GetNext(, .address){
Set addr=##class(HS.Types.Address).%New()
Set addr.City=address.city
Set addr.State=address.state
Set addr.Country=address.country
Set addr.StreetLine=address.line.%Get(0)
Do hubRequest.Addresses.Insert(addr)
}
//Telephone
set identTel = tDynObj.telecom.%GetIterator()
while identTel.%GetNext(, .telecom){
if (telecom.system = "phone") {
Set tel=##class(HS.Types.Telecom).%New()
Set tel.PhoneNumber=telecom.value
Do hubRequest.Telecoms.Insert(tel)
}
}
}
Set tSC = ..SendRequestSync("HS.Hub.MPI.Manager", hubRequest, .pResponse)
Quit tSC
}
Storage Default
{
<Type>%Storage.Persistent</Type>
}
}
Veamos un poco más en detalle qué estamos haciendo:
Primeramente recibimos el mensaje enviado desde el Business Service:
Method OnRequest(pRequest As Ens.StreamContainer, Output pResponse As Ens.Response) As %Status
{
set tDynObj = {}.%FromJSON(pRequest.Stream)
Como podemos ver en la firma del método OnRequest el mensaje de entrada corresponde a una clase del tipo Ens.StreamContainer, esta transformación de nuestro mensaje de tipo %String se ha realizado en el Business Service. En la primera línea del método lo que haremos será recuperar el mensaje que se encuentra como un Stream dentro de la variable pRequest. A continuación lo transformamos a un %DynamicObject mediante la instrucción %FromJSON.
Con nuestro mensaje mapeado a un objeto dinámico podremos acceder a cada uno de los campos del recurso FHIR que hemos enviado:
set tDynObj = {}.%FromJSON(pRequest.Stream)
If (tDynObj '= "") {
set hubRequest = ##class(HS.Message.AddUpdateHubRequest).%New()
// Create AddUpdateHub Message
// Name, sex, DOB
set givenIter = tDynObj.name.%Get(0).given.%GetIterator()
while givenIter.%GetNext(, .givenName){
if (hubRequest.FirstName '= "")
{
Set hubRequest.FirstName=givenName
}
else {
Set hubRequest.FirstName=hubRequest.FirstName_" "_givenName
}
}
Set hubRequest.FirstName=tDynObj.name.%Get(0).given.%Get(0)
Set hubRequest.LastName=tDynObj.name.%Get(0).family
Set hubRequest.Sex=tDynObj.gender
Set hubRequest.DOB=hubRequest.DOBDisplayToLogical(tDynObj.birthDate)
En este fragmento vemos como creamos un objecto de la clase HS.Message.AddUpdateHubRequest que es el que enviaremos al Business Operation HS.Hub.MPI.Manager encargado de realizar las operaciones correspondientes dentro del EMPI, ya sea la creación del nuevo paciente o la actualización del mismo, así como vincularlo con las posibles coincidencias que pueda haber con otros pacientes ya dentro del EMPI.
El siguiente paso es poblar el nuevo objeto con los datos recibidos desde el Business Service, como podéis observar lo único que hacemos es recuperar los datos de los diferentes campos del objecto dinámico que acabamos de crear. El formato del objeto dinámico corresponde exáctamente con el definido por HL7 FHIR para el recurso paciente, podéis ver ejemplos directamente en la página de HL7 FHIR
Para nuestro ejemplo hemos elegido este paciente de la lista que nos proporciona la propia página de HL7 FHIR:
{
"resourceType": "Patient",
"id": "example",
"text": {
"status": "generated",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\">\n\t\t\t<table>\n\t\t\t\t<tbody>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Name</td>\n\t\t\t\t\t\t<td>Peter James \n <b>Chalmers</b> ("Jim")\n </td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Address</td>\n\t\t\t\t\t\t<td>534 Erewhon, Pleasantville, Vic, 3999</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Contacts</td>\n\t\t\t\t\t\t<td>Home: unknown. Work: (03) 5555 6473</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Id</td>\n\t\t\t\t\t\t<td>MRN: 12345 (Acme Healthcare)</td>\n\t\t\t\t\t</tr>\n\t\t\t\t</tbody>\n\t\t\t</table>\n\t\t</div>"
},
"identifier": [
{
"use": "usual",
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0203",
"code": "MR"
}
]
},
"system": "urn:oid:1.2.36.146.595.217.0.1",
"value": "12345",
"period": {
"start": "2001-05-06"
},
"assigner": {
"display": "Acme Healthcare"
}
}
],
"active": true,
"name": [
{
"use": "official",
"family": "Chalmers",
"given": [
"Peter",
"James"
]
},
{
"use": "usual",
"given": [
"Jim"
]
},
{
"use": "maiden",
"family": "Windsor",
"given": [
"Peter",
"James"
],
"period": {
"end": "2002"
}
}
],
"telecom": [
{
"use": "home"
},
{
"system": "phone",
"value": "(03) 5555 6473",
"use": "work",
"rank": 1
},
{
"system": "phone",
"value": "(03) 3410 5613",
"use": "mobile",
"rank": 2
},
{
"system": "phone",
"value": "(03) 5555 8834",
"use": "old",
"period": {
"end": "2014"
}
}
],
"gender": "male",
"birthDate": "1974-12-25",
"_birthDate": {
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/patient-birthTime",
"valueDateTime": "1974-12-25T14:35:45-05:00"
}
]
},
"deceasedBoolean": false,
"address": [
{
"use": "home",
"type": "both",
"text": "534 Erewhon St PeasantVille, Rainbow, Vic 3999",
"line": [
"534 Erewhon St"
],
"city": "PleasantVille",
"district": "Rainbow",
"state": "Vic",
"postalCode": "3999",
"period": {
"start": "1974-12-25"
}
}
],
"contact": [
{
"relationship": [
{
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v2-0131",
"code": "N"
}
]
}
],
"name": {
"family": "du Marché",
"_family": {
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/humanname-own-prefix",
"valueString": "VV"
}
]
},
"given": [
"Bénédicte"
]
},
"telecom": [
{
"system": "phone",
"value": "+33 (237) 998327"
}
],
"address": {
"use": "home",
"type": "both",
"line": [
"534 Erewhon St"
],
"city": "PleasantVille",
"district": "Rainbow",
"state": "Vic",
"postalCode": "3999",
"period": {
"start": "1974-12-25"
}
},
"gender": "female",
"period": {
"start": "2012"
}
}
],
"managingOrganization": {
"reference": "Organization/1"
}
}
Antes de nada hemos creado 2 tablas Lookup para el mapeo de los tipos de nombre y de la autoridad de asignación del número de historia clínica (MR), la primera para que sea compatible con los tipos manejados por el EMPI y el segundo para que se reconozca la autoridad de asignación que generó el identificador:
Set tName.Type=^Ens.LookupTable("TypeOfName",name.use)
Set hubRequest.AssigningAuthority = ^Ens.LookupTable("hospital",identifier.system)
Set hubRequest.Facility = ^Ens.LookupTable("hospital",identifier.system)
Lanzando un mensaje de pruebas
Perfecto, lancemos nuestro mensaje FHIR contra nuestro endpoint que definimos en el artículo anterior:
Como véis hemos recibido un 200 de respuesta, esto sólo significa que el EMPI ha recibido correctamente el mensaje, veamos ahora la traza que se ha generado en nuestra producción:
Aquí tenemos a nuestro paciente, como podéis ver se ha realizado la transformación con éxito y se han asignado correctamente todos los campos que venían informados en el mensaje FHIR. Como podemos observar se ha generado un mensaje de notificación IDUpdateNotificationRequest, este tipo de notificaciones se generan cuando se realizar alguna operación de creación o actualización de pacientes en el sistema.
Muy bien, comprobemos que el paciente está correctamente registrado en nuestro sistema realizando una búsqueda del mismo por su nombre y apellidos:
¡BINGO! Veamos más en detalle los datos de nuestro querido Peter:
Perfecto, ya tenemos en nuestro EMPI toda la información necesaria del paciente. Como véis el mecanismo es bastante sencillo, repasemos los pasos que hemos realizado:
Hemos instalado la herramienta de FHIR Adapter que nos proporciona InterSystems en un NAMESPACE configurado para trabajar con interoperabilidad (un namespace diferente el generado por el EMPI que en mi caso he llamado WEBINAR).
Hemos creado en este namespace un Business Operation que transforma el mensaje recibido de tipo HS.FHIRServer.Interop.Request a un %String que enviará a un Business Service configurado en la producción del namespace del EMPI (HSPIDATA).
A continuación hemos añadido el Business Service de la clase EnsLib.TCP.PassthroughService que recibe el mensaje enviado desde la producción del namespace WEBINAR y redirige al Business Process Local.BP.FHIRProcess.
En el BP Local.BP.FHIRProcess hemos transformado el Stream recibido a un objeto del tipo HS.Message.AddUpdateHubRequest y lo hemos enviado al Business Operation HS.Hub.MPI.Manager que se encargará de registrarlo en nuestro EMPI.
Como véis, la unión de las funcionalidades del EMPI con las proporcionadas por motor de integración de IRIS nos permite trabajar prácticamente con cualquier tipo de tecnología.
Espero que os haya resultado útil este artículo. Si tenéis alguna pregunta o sugerencia ya sabéis, dejad un comentario y estaré encantado de contestaros.
Artículo
Ricardo Paiva · 12 sep, 2022

En primer lugar, ¿qué es la anonimización de datos?
Según la [Wikipedia](https://en.wikipedia.org/wiki/Data_anonymization):
> **La anonimización** es un tipo de [sanitización de información](https://en.wikipedia.org/wiki/Sanitization_(classified_information)) cuya intención es la protección de la privacidad. Es el proceso de eliminar [información personal](https://es.wikipedia.org/wiki/Informaci%C3%B3n_personal) de los conjuntos de datos, de modo que las personas que son descritas por los datos permanecen en el anonimato.
>
En otras palabras, la anonimización de datos es un proceso que conserva los datos pero mantiene la fuente anónima.
Según la técnica de anonimización que se adopte, los datos son editados, ocultados o sustituidos.
Y ese es el propósito de iris-Disguise, ofrecer un conjunto de herramientas de anonimización.
Lo puedes usar de dos formas diferentes, por método de ejecución o especificar tu estrategia de anonimización dentro de la definición de la clase persistente en sí misma.
La actual versión de iris-Disguise ofrece 6 estrategias para anonimizar datos:
- ***Destruction* (Destrucción)**
- ***Scramble* (Codificación)**
- ***Shuffling* (Reorganización)**
- ***Partial masking* (Ocultación parcial)**
- ***Randomization* (Distribución aleatoria)**
- ***Faking* (Falsificación)**
Vamos a explicar cada estrategia. Mostraré un método de ejecución con un ejemplo como he mecionado, y también mostraré cómo aplicarlo dentro de la definición de la clase persistente.
Para usar **iris-Disguise** de esta forma, necesitaréis "*llevar unas gafas de disfraz"*.
En la clase persistente, se puede extender la clase **dc.Disguise.Glasses** y cambiar cualquier propiedad con los tipos de datos con la estrategia que prefieras.
Tras ello, en cualquier momento, simplemente llama al método **DisguiseProcess** en la clase. Todos los valores serán sustituidos usando la estrategia del tipo de datos.
Así que... abrochaos el cinturón que empezamos!
### *Destruction* (Destrucción)
Esta estrategia reemplazará una columna entera con una palabra ('CONFIDENTIAL' (CONFIDENCIAL) por defecto).
```
Do ##class(dc.Disguise.Strategy).Destruction("classname", "propertyname", "Word to replace")
```
El tercer parámetro es opcional. Si no se aporta, se usará la palabra 'CONFIDENTIAL' (CONFIDENCIAL).
```
Class packageSample.FictionalCharacter Extends (%Persistent, dc.Disguise.Glasses)
{
Property Name As dc.Disguise.DataTypes.String(FieldStrategy = "DESTRUCTION");
}
```
```
Do ##class(packageSample.FictionalCharacter).DisguiseProcess()
```
.png)
### *Scramble* (Codificación)
Esta estrategia codificará todos los caracteres de una propiedad.
```
Do ##class(dc.Disguise.Strategy).Scramble("classname", "propertyname")
```
```
Class packageSample.FictionalCharacter Extends (%Persistent, dc.Disguise.Glasses)
{
Property Name As dc.Disguise.DataTypes.String(FieldStrategy = "SCRAMBLE");
}
```
```
Do ##class(packageSample.FictionalCharacter).DisguiseProcess()
```
.png)
### *Shuffling* (Reorganización)
*Shuffling* reorganizará todos los valores de una propiedad dada. No es una estrategia de ocultación porque trabaja "verticalmente".
Esta estrategia es útil para relaciones, porque se mantendrá la integridad referencial.
Hasta esta versión, este método solo funciona en **relaciones de uno a muchos**.
```
Do ##class(dc.Disguise.Strategy).Shuffling("classname", "propertyname")
```
```
Class packageSample.FictionalCharacter Extends (%Persistent, dc.Disguise.Glasses)
{
Property Name As %String;
Property Weapon As dc.Disguise.DataTypes.String(FieldStrategy = "SHUFFLING");
}
```
```
Do ##class(packageSample.FictionalCharacter).DisguiseProcess()
```
.png)
### Partial Masking (Ocultación parcial)
Esta estrategia ocultará parte de los datos. Por ejemplo, el número de una tarjeta de crédito puede ser sustituido por 456X XXXX XXXX X783
```
Do ##class(dc.Disguise.Strategy).PartialMasking("classname", "propertyname", prefixLength, suffixLength, "mask")
```
PrefixLength, suffixLength y mask son opcionales. Si no se aporta, se usarán los valores por defecto.
```
Class packageSample.FictionalCharacter Extends (%Persistent, dc.Disguise.Glasses)
{
Property Name As %String;
Property SSN As dc.Disguise.DataTypes.PartialMaskString(prefixLength = 2, suffixLength = 2);
Property Weapon As %String;
}
```
```
Do ##class(packageSample.FictionalCharacter).DisguiseProcess()
```
.png)
### *Randomization* (Distribución aleatoria)
Esta estrategia generará sencillamente datos aleatorios. Hay tres tipos de distribución aleatoria: integer, numeric y date.
```
Do ##class(dc.Disguise.Strategy).Randomization("classname", "propertyname", "type", from, to)
```
**type**: "integer", "numeric" o "date". "integer" es el predeterminado.
"from" y "to" son opcionales. Es para definir el rango de distribución aleatoria.
Para el tipo "integer" el rango por defecto es de 1 a 100. Para el tipo "numeric" el rango por defecto es de 1.00 a 100.00.
```
Class packageSample.FictionalCharacter Extends (%Persistent, dc.Disguise.Glasses)
{
Property Name As %String;
Property Age As dc.Disguise.DataTypes.RandomInteger(MINVAL = 10, MAXVAL = 25);
Property SSN As %String;
Property Weapon As %String;
}
```
```
Do ##class(packageSample.FictionalCharacter).DisguiseProcess()
```
.png)
### Faking (Falsificación)
La idea de la falsificación es reemplazar datos con valores aleatorios pero plausibles.
**iris-Disguise** proporciona una pequeño conjunto de métodos para generar datos falsos.
```
Do ##class(dc.Disguise.Strategy).Fake("classname", "propertyname", "type")
```
**type**: "firstname", "lastname", "fullname", "company", "country", "city" y "email"
```
Class packageSample.FictionalCharacter Extends (%Persistent, dc.Disguise.Glasses)
{
Property Name As dc.Disguise.DataTypes.FakeString(FieldStrategy = "FIRSTNAME");
Property Age As %Integer;
Property SSN As %String;
Property Weapon As %String;
}
```
```
Do ##class(packageSample.FictionalCharacter).DisguiseProcess()
```
.png)
### ¿Qué os parece?
Me gustaría conocer vuestra opinión y leer vuestros comentarios - qué os parece, si se ajusta a vuestras necesidades y qué funcionalidades echais de menos.
Y quería agradecer de forma especial a @Henrique.GonçalvesDias, @Oliver.Wilms, @Robert.Cemper1003, @Yuri.Gomes y @Evgeny.Shvarov sus comentarios, revisiones, sugerencias y valiosos aportes, que me han inspirado tanto y ayudado a crear y mejorar iris-Disguise.
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Yaron Munz · 23 sep, 2022
Resumen
Empezamos a usar Azure Service Bus (ASB) como solución de mensajería empresarial hace tres años. La hemos usado para publicar y consumir datos entre muchas aplicaciones de la organización. Como el flujo de datos es complejo, y normalmente se necesitan los datos de una aplicación en muchas otras aplicaciones, el modelo publicador -> múltiples subscriptores resultó muy adecuado. El uso de ASB en la organización es de docenas de millones de mensajes por día, mientras que la plataforma IRIS tiene unos 2-3 millones de mensajes/día.
El problema con ASB
Cuando empezamos con la integración de ASB, encontramos que el protocolo AMQP no tiene la configuración predeterminada para la implementación de IRIS, por lo que estuvimos buscando una solución alternativa para poder comunicar con ASB.
La solución
Desarrollamos un servicio local en Windows (.NET y Swagger) que se encargaba de la comunicación con ASB. Se instaló en la misma máquina que IRIS. Enviamos los mensajes a ASB dirigidos a este servicio local en Windows (usando: localhost y haciendo una API REST) y el propio servicio hacía el resto. Esta solución funcionó bien durante años, pero era muy difícil monitorizar el tráfico, depurar los mensajes "perdidos" y medir el rendimiento general. El hecho de tener este servicio local en Windows como un agente intermedio no resultaba la mejor arquitectura.
Programa de Acceso Preferente a Python Embebido (EAP)
Me pidieron (o me presenté voluntario, no lo recuerdo bien) participar en el Programa de Acceso Preferente a Python Embebido. Fue muy interesante para mí, porque pude poder probar nuevas funcionalidades y dar feedback al equipo de desarrollo. También me gustó mucho participar de forma activa e influir en el desarrollo de este producto. En esa fase, empezamos a probar Python Embebido para el ERP y decidimos comprobar si podíamos utilizar Python Embebido para resolver problemas “reales”. Nos plantearnos entonces intentar resolver la conectividad directa de IRIS a ASB.
El POC (prueba de concepto)
Empezamos a programar la solución y vimos que usar la librería ASB de Microsoft para Python nos haría nuestra vida (y nuestro trabajo) mucho más fácil. El primer paso fue desarrollar una función que pueda conectar con un topic específico en ASB y recibir mensajes. Esto se hizo bastante rápido (1 día de desarrollo) y avanzamos a la fase publicar (enviar mensajes a ASB).
Nos llevó varios días desarrollar toda la cubierta para esas funciones enviar y recibir. Preparamos lo siguiente:
Un “área de preparación” entrante y saliente adecuada, para controlar el flujo de mensajes entrantes/salientes.
Un mecanismo central para almacenar el tráfico ASB entrante y saliente para poder tener estadísticas adecuadas y medidas del rendimiento.
Una página de monitorización CSP para activar/desactivar servicios, mostrar estadísticas y dar alertas sobre cualquier incidencia.
La implementación
Configuración Preliminar
Antes de usar las librerías ASB de Microsoft para Python, hay que instalarlas en un directorio ..\python dedicado.Nosotros elegimos usar ../mge/python/ pero se puede usar cualquier carpeta que se quiera (inicialmente era una carpeta vacía)Los siguientes comandos hay que ejecutarlos bien con una sesión CMD con privilegios (Windows) o con un usuario con los privilegios suficientes (Linux):
..\bin\irispip install --target ..\mgr\python asyncio
..\bin\irispip install --target ..\mgr\python azure.servicebus
Recibir mensajes desde ASB (consumo)
Tenemos una ClassMethod con varios parámetros:
The topiId - El ASB se divide en topics de los cuales se consumen los mensajes
subscriptionName - Nombre de la subscripción Azure
connectionString - Para poder conectar con el topic al que estás suscrito
Ten en cuenta que se está usando [ Language = python ] para indicar que este ClassMethod está escrito en Python (!)
ClassMethod retrieveASB(topicId As %Integer = 1, topicName As %String = "", subscriptionName As %String = "", connectionString As %String = "", debug As %Integer = 1, deadLetter As %Integer = 0) As %Integer [ Language = python ]
Para usar la librería ASB, primero necesitamos importar las librerías ServiceBusClient y ServiceBusSubQueue:
from azure.servicebus import ServiceBusClient,ServiceBusSubQueue
para poder interactuar con IRIS (por ejemplo, ejecutar código) también necesitamos:
import iris
En este punto, podemos usar las librerías ASB:
with ServiceBusClient.from_connection_string(connectionString) as client:
with client.get_subscription_receiver(topicName, subscriptionName, max_wait_time=1, sub_queue=subQueue) as receiver:
for msg in receiver:
En este punto, tenemos un objeto Python "msg" (stream) donde podemos pasarlo (como un stream, por supuesto) a IRIS y almacenarlo directamente en la base de datos:
result = iris.cls("anyIRIS.Class").StoreFrom Python(stream)
Enviar mensajes a ASB (publicación)
Tenemos un ClassMethod con varios parámetros:
topicName - El Topic en el que queremos publicar (aquí tenemos que pasar el nombre, no el id)
connectionString - Para poder conectar con el topic al que se está suscrito
JSONmessage - el mensaje que queremos enviar (publicar)
Ten en cuenta que se está usando [ Language = python ] para indicar que este ClassMethod está escrito en Python (!)
ClassMethod publishASB(topicName As %String = "", connectionString As %String = "", JSONmessage As %String = "") As %Status [ Language = python ]
Para usar la librería ASB, primero necesitamos importar las librerías ServiceBusClient y ServiceBusMessage:
from azure.servicebus import ServiceBusClient, ServiceBusMessage
Usar las librerías ASB es muy sencillo:
try:
result=1
with ServiceBusClient.from_connection_string(connectionString) as client:
with client.get_queue_sender(topicName) as sender:
single_message = ServiceBusMessage(JSONmessage)
sender.send_messages(single_message)
except Exception as e:
print(e)
result=0
return result
Beneficios de usar la conectividad ASB directa
Mucho más rápida que usar la antigua alternativa del servicio local en Windows
Fácil de monitorizar, recoger estadísticas, resolver incidencias
Retirar el agente intermedio (servicio local en Windows) reduce un potencial punto de fallo
Posibilidad de gestionar mensajes perdidos para cualquier topic automáticamente y hacer que ASB re-envíe esos mensajes a los subscriptores del topic
Agradecimientos
Me gustaría dar las gracias a @David.Satorres5186 (Senior Developer para IRIS) por su enorme contribución en el diseño, programación y pruebas. Sin su ayuda este proyecto no hubiera sido posible.
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Bernardo Linarez · 30 mar, 2020
¡Hola Comunidad!
En este artículo hablaré sobre las pruebas y la depuración de las aplicaciones web de Caché (principalmente REST) con herramientas externas. La segunda parte trata sobre las herramientas de Caché.
Usted escribió el código del lado del servidor y quiere probarlo con un cliente, o ya tiene una aplicación web pero no funciona. Aquí es donde entra la depuración. En este artículo abarcaré desde las herramientas más fáciles de utilizar (el navegador), hasta las más completas (el analizador de paquetes), pero primero conversemos un poco sobre los errores más comunes y cómo pueden resolverse.
Los errores
Error 401 No autorizado
Creo que este error es el que encontramos con más frecuencia durante la implementación de la producción. El servidor de desarrollo local normalmente tiene una configuración de seguridad mínima o normal pero muy convencional. Sin embargo, el servidor de producción puede tener un esquema con más restricciones. Entonces:
Compruebe que ha iniciado sesión
Compruebe que el usuario tiene acceso a la base de datos/tabla/procedimiento/fila/columna a la que desea acceder
Compruebe que la solicitud para las OPCIONES puede realizarse por un usuario no autorizado
Error 404 No encontrado
Compruebe:
Que la URL es correcta
Si es una nueva aplicación y está utilizando un servidor web externo, cargar nuevamente el servidor web puede ser útil
Errores en la aplicación
En cierto modo estos son los más fáciles de encontrar - realizar un seguimiento del stack será muy útil. La resolución es totalmente específica para la aplicación.
Herramientas de depuración
Navegador web
La primera herramienta de depuración que siempre está disponible es un navegador web, es preferible que utilice Chrome, pero Firefox también sería suficiente. Las solicitudes GET pueden probarse al ingresar en la URL que se encuentra en la barra de direcciones, todas las demás solicitudes necesitan de una aplicación web o que estén escritas en un código js. El método general es el siguiente:
Presione F12 para abrir las herramientas del desarrollador
Vaya a la pestaña Network
Marque la casilla Preserve Log, si no está marcada
Despliegue únicamente las solicitudes XHR
Realice una acción para depurar errores en la aplicación web
Desde aquí, puede examinar las solicitudes y enviarlas nuevamente. En Firefox también pueden editarse las solicitudes antes de repetirlas.
Ventajas:
Siempre está disponible
Es fácil de utilizar (los usuarios finales pueden enviar capturas de pantalla de la red y las pestañas de la consola)
Este es el entorno del usuario final
Desventajas:
No muestra respuestas parciales como send/broken/ etc.
Es lento con las respuestas que son grandes
Es lento cuando hay una gran cantidad de respuestas
Todo se hace manualmente
Cliente REST
El cliente REST es una aplicación web independiente o un complemento del navegador, que se diseñó específicamente para probar aplicaciones web. Aquí utilicé Postman, pero existen muchos otros. Así es como se ven las depuraciones en Postman:
Postman funciona mediante solicitudes agrupadas en colecciones. La solicitud puede enviarse a un entorno. El entorno es una colección de variables. Por ejemplo, en mi entorno CACHE@localhost la variable del host está configurada como localhost y el usuario como _SYSTEM. Cuando se envía una solicitud, las variables se reemplazan por sus valores en el entorno seleccionado y entonces la solicitud se envía.
Aquí puede consultar una recopilación de ejemplos y del entorno para el proyecto MDX2JSON.
Ventajas:
Solo es necesario escribirlo una vez y podrá utilizarlo en todas partes
Mejor control de las solicitudes
Optimización de respuestas
Desventajas:
La depuración de solicitudes encadenadas sigue siendo manual (la respuesta a la solicitud 1 puede forzar una respuesta, ya sea, en la solicitud 2 o en la solicitud 2B)
Algunas veces tiene errores en las respuestas parciales como send/broken/etc.
Proxy de depuraciones HTTP
Es una aplicación independiente que registra el tráfico en los HTTP. Las solicitudes registradas pueden modificarse y reenviarse. Yo utilizo Charles y Fiddler.
Ventajas:
Procesa respuestas parciales como send/broken/ etc.
Optimización de respuestas
Mejor soporte técnico para el tráfico HTTPS (que con el analizador de paquetes)
Puede guardar sesiones de captura
Desventajas:
Algunas cosas son necesarias para enviar la solicitud (por ejemplo, aplicaciones web/cliente REST/código JS)
Analizador de paquetes
Es un programa computacional que puede interceptar y registrar el tráfico que pasa por una red. Conforme el flujo de datos fluye a través de la red, el rastreador captura cada paquete y, si es necesario, decodifica los datos sin procesar del paquete. Esta es la opción más completa, pero también requiere de ciertas habilidades para funcionar correctamente. Yo utilizo WireShark. Aquí tiene una pequeña guía sobre cómo instalarlo y utilizarlo:
Si va a capturar paquetes locales, lea acerca del loopback e instale los requisitos previos del software (npcap para Windows)
Instale WireShark
Configure los filtros de captura (por ejemplo, un filtro para capturar únicamente el tráfico de la dirección 57772: con el puerto 57772
Inicie la captura
Configure los filtros de visualización (por ejemplo, un filtro para mostrar únicamente el tráfico http para una IP específica: ip.addr == 1.2.3.4 && http
A continuación, se muestra un ejemplo de captura para el tráfico http (filtro de visualización) en el puerto 57772 (filtro de captura):
Ventajas:
Procesa respuestas parciales como send/broken/ etc.
Puede capturar grandes cantidades de tráfico
Puede capturar cualquier cosa
Puede guardar sesiones de captura
Desventajas:
Algunas cosas son necesarias para enviar la solicitud (por ejemplo, aplicaciones web/cliente REST/código JS)
Qué utilizar
Bueno, eso depende de cuál sea el objetivo. En primer lugar, podemos registrar (depurar el proxy, analizar paquetes) o generar solicitudes (navegadores, clientes REST).
Si está desarrollando una API Web para REST, el cliente REST es la forma más rápida de probar que funciona.
Sin embargo, si las solicitudes del cliente REST funcionan, pero la aplicación web del cliente no, posiblemente necesite un navegador, un proxy de depuraciones http y un analizador de paquetes.
Si tiene clientes y necesita desarrollar una API del lado del servidor para trabajar con ellos, necesitará un proxy de depuraciones http o un analizador de paquetes.
Lo mejor es estar familiarizado con los 4 tipos de herramientas y cambiar rápidamente entre una y otra si la que utiliza actualmente no es suficiente para realizar el trabajo.
Algunas veces resulta evidente cuál es la herramienta correcta.
Por ejemplo, recientemente desarrollé una API en el lado del servidor para un protocolo de extensión http muy popular, los requisitos fueron:
No podemos cambiar el código que ya habían escrito los clientes
Clientes diferentes se comportan de distintas maneras
El comportamiento entre http y https es diferente
El comportamiento con distintos tipos de autenticación es diferente
Es posible procesar hasta cien solicitudes por segundo, por cliente
Todo el mundo ignora el RFC
Aquí solamente existe una solución, el analizador de paquetes.
O si estoy desarrollando una API REST para el consumo de JS, el cliente REST es la herramienta perfecta para realizar pruebas.
Cuando depure la aplicación web, siempre comience con el navegador.
En la parte 2 discutiremos todas las cosas (muchas) que puede hacer para depurar la web en el lado de Caché.
¿Qué métodos utiliza para depurar las comunicaciones entre el cliente y el servidor?
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Kurro Lopez · 11 feb, 2022
El tiempo dirá, siempre lo hace.
El Doctor.
No es una tarea facil dominar fechas y horas, siempre es un problema y a veces confuso en cualquier lenguaje de programación, vamos a aclarar y a poner unos cuantos tips para que esta tarea sea lo mas sencilla posible.
Súbete a la TARDIS que te voy a convertir en un Señor del tiempo
Empecemos por lo básico
Si vienes de otros lenguajes, comentar que las fechas en Intersystems Object Script (en adelante IOS, no confundir con los móviles) son un poco peculiares.Cuando ejecutamos el comando $HOROLOG en el terminal, para tener la fecha y hora actual, verás que se divide en dos partes:
WRITE $HOROLOG
> 66149,67164
El primer valor es el día, para ser exactos el número de días desde el 31 de diciembre de 1840, osea, que el valor 1 es el 1 de enero de 1841 y el segundo los segundos desde la 00:00 de ese día.
En este ejemplo, 66149 corresponde con 09/02/2022 y 67164 con las 18:39:24 horas. A este formato, lo vamos a llamar formato interno de fecha y hora.
¿Confuso? pues vamos a empezar a desvelar los grandes secretos del universo (de fechas y horas)
¿Cómo puedo convertir el formato interno en formato mas claro?
Para ello vamos a usar el comando $ZDATETIME
El comando básico sería
SET AhoraMismo = $HOROLOG
WRITE AhoraMismo
> 66149,67164
WRITE $ZDATETIME(AhoraMismo)
> 02/09/2022 18:39:24
Por defecto, utiliza el formato americano (mm/dd/yyyy). Si quieres utilizar la fecha en otro formato, vamos a utilizar el segundo parámetro, como por ejemplo el europeo (dd/mm/yyyy), en ese caso le vamos a dar el valor 4 (para mas formatos, ver la documentación $ZDATETIME.dformat)
SET AhoraMismo = $HOROLOG
WRITE AhoraMismo
> 66149,67164
WRITE $ZDATETIME(AhoraMismo,4)
> 09/02/2022 18:39:24
Esta opción utiliza como separador y formato de año lo que tengamos definido en las variables locales
Si queremos además poner otro formato la hora, por ejempo en formato 12 horas (AM/PM) en lugar de formato 24 horas, utilizamos el tercer parámetro con el valor 3, si no queremos que muestre los segundos, usaremos el valor 4 (ver la documentación $ZDATETIME.tformat)
SET AhoraMismo = $HOROLOG
WRITE AhoraMismo
> 66149,67164
WRITE $ZDATETIME(AhoraMismo,4,3)
> 09/02/2022 06:39:24PM
WRITE $ZDATETIME(AhoraMismo,4,4)
> 09/02/2022 06:39PM
¿Ahora está mas claro? pues vamos a profundizar mas
Formato ODBC
Este formato es independiente de tu configuración local, siempre se mostrará como yyyy-mm-dd, su valor es 3. Se recomiendo utilizarlo si queremos crear datos que se van a exportar en ficheros, como ficheros CSV, HL7, etc..
SET AhoraMismo = $HOROLOG
WRITE AhoraMismo
> 66149,67164
WRITE $ZDATETIME(AhoraMismo,3)
> 2022-02-09 18:39:24
Día de la semana, nombre del día, día del año
Valor
Descripción
10
El día de la semana será un valor entre 0 y 6, siendo el 0 el domingo y el 6 el sábado.
11
El nombre del día de la semana abreviado, lo devolverá según la configuración local definda, la instalación por defecto de IRIS es enuw (English, United States, Unicode)
12
El nombre del día de la semana en formato largo. Igual que 11
14
El día del año, pues eso, el número de días desde el 1 de enero
Si solo queremos tratar fechas y horas por separado, debes de usar los comandos $ZDATE y $ZTIME respectivamente. El parámetro para los formatos son los mismos que define en $ZDATETIME.dformat y $ZDATETIME.tformat
SET AhoraMismo = $HOROLOG
WRITE AhoraMismo
> 66149,67164
WRITE $ZDATE(AhoraMismo,10)
> 3
WRITE $ZDATE(AhoraMismo,11)
> Wed
WRITE $ZDATE(AhoraMismo,12)
> Wednesday
¿Y cómo convierto una fecha en formato interno?
Pues ahora vamos a ver el paso contrario, es decir, tener un texto con una fecha y lo convertimos en formato IOS. Para ello vamos a usar el comando $ZDATETIMEH
Esta vez, tenemos que indicar en que formato está la fecha y la hora (si usamos $ZDATETIMEH) o la fecha ($ZDATEH) o la hora ($ZTIMEH) por separado.
Los formatos siguen siendo los mismos, es decir si tenemos una cadena con la fecha en formato ODBC (yyyy-mm-dd), pues utilizaremos el valor 3
SET MiFecha = "2022-02-09 18:39:24"
SET FechaInterna1 = $ZDATETIMEH(MiFecha, 3, 1) // Formato ODBC
SET MiFecha = "09/02/2022 18:39:24"
SET FechaInterna2 = $ZDATETIMEH(MiFecha, 4, 1) // Formato europeo
SET MiFecha = "02/09/2022 06:39:24PM"
SET FechaInterna3 = $ZDATETIMEH(MiFecha, 1, 3) // Formato Americano con hora en 12h AM/PM
WRITE FechaInterna1,!,FechaInterna2,!,FechaInterna3
> 66149,67164
66149,67164
66149,67164
Lógicamente, si le decimos que es un formato y le damos el valor erroneo, puede pasar cualquier cosa, como que en lugar de 9 de febrero lo entiende como 2 de septiembre.
No mezclar formatos que luego vienen los problemas.
SET MiFecha = "09/02/2022"
/// Formato Americano
SET FechaInterna = $ZDATEH(MiFecha, 1)
/// Formato Europeo
SET OtraFecha = $ZDATETIME(FechaInterna, 4)
WRITE FechaInterna,!,OtraFecha
> 66354
02/09/2022
Ni que decir, si intentamos poner fecha europea e intentar transformarlo en americano... ¿Que pasaría en San Valentín?
SET MiFecha = "14/02/2022"
SET FechaInterna = $ZDATEH(MiFecha, 1) // Formato Americano. OJO, el mes 14 no existe
^
<ILLEGAL VALUE>
Pues como todos los San Valentín.. corazones rotos, bueno... mas bién código roto.
Pues vamos a hacer algo con esto que ya has aprendido
READ !,"Por favor, indica tu fecha de nacimiento (dd/mm/yyyy): ",fechaNacimiento
SET formatoInterno = $ZDATEH(fechaNacimiento, 4)
SET diaSemana = $ZDATE(formatoInterno, 10)
SET nombreDia = $ZDATE(formatoInterno, 12)
WRITE !,"El día de la semana de tu nacimiento es: ",nombreDia
IF diaSemana = 5 WRITE "Siempre te ha gustado la fiesta!!!" // Nació un viernes
Pero mas adelante veremos otras formas de hacer las cosas, y como controlar los errores.
Próximo capítulo: Cómo viajar en el tiempo
Curiosidad
Si quieres saber porque se toma el valor de 01/01/1841 como el valor 1, viene porque fué elegido esta fecha por ser el año no bisiesto anterior al nacimiento del ciudadano estadounidense de mayor edad vivo, que era un veterano de la guerra civil con 121 años, cuando se diseñó el lenguaje de programación MUMPS, del cual extiende Object Script
Artículo
Ricardo Paiva · 31 mayo, 2022
Hola desarrolladores,
En el artículo anterior, describimos cómo utilizar config-api para configurar IRIS.
Ahora, vamos a intentar combinar la biblioteca con el cliente ZPM.
El objetivo es cargar un documento de configuración durante `zpm install` en la `configure phase`.
Para realizar este ejercicio, hay un repositorio de plantillas disponible [aquí](https://github.com/lscalese/objectscript-docker-template-with-config-api) (está basado en [objectscript-docker-template](https://github.com/intersystems-community/objectscript-docker-template)).
Tratamos de:
* Crear una base de datos `MYAPPDATA`.
* Configurar el mapeo de Globals para `dc.PackageSample.*`.
* Añadir un usuario llamado `SQLUserRO` con acceso a la función SQL de solo lectura.
* Añadir una configuración SSL denominada `SSLAppDefault`.
* Crear una aplicación REST `/rest/myapp`.
El archivo de configuración [`iris-config.json`](https://github.com/lscalese/objectscript-docker-template-with-config-api/blob/master/config-api/iris-config.json) se encuentra en el subdirectorio `config-api`. Es una plantilla vacía que se puede completar con el siguiente contenido:
```json
{
"Security.Roles":{
"MyRoleRO" : {
"Descripion" : "SQL Read Only Role for dc_PackageSample schema.",
"Resources" : "%Service_SQL:U",
"GrantedRoles" : "%SQL"
}
},
"Security.SQLPrivileges": [{
"Grantee": "MyRoleRO",
"PrivList" : "s",
"SQLObject" : "1,dc_PackageSample.*"
}],
"Security.SQLAdminPrivilegeSet" : {
"${namespace}": [
]
},
"Security.Users": {
"${sqlusr}": {
"Name":"${sqlusr}",
"Password":"$usrpwd$",
"AccountNeverExpires":true,
"AutheEnabled":0,
"ChangePassword":false,
"Comment":"Demo SQLUserRO",
"EmailAddress":"",
"Enabled":true,
"ExpirationDate":"",
"FullName":"Demo SQLUserRO",
"NameSpace":"${namespace}",
"PasswordNeverExpires":false,
"PhoneNumber":"",
"PhoneProvider":"",
"Roles":"MyRoleRO",
"Routine":""
}
},
"Security.SSLConfigs": {
"SSLAppDefault":{}
},
"Security.Applications" : {
"/rest/myapp": {
"NameSpace" : "${namespace}",
"Enabled" : 1,
"DispatchClass" : "Your.Dispatch.class",
"CSPZENEnabled" : 1,
"AutheEnabled": 32
}
},
"SYS.Databases":{
"${mgrdir}myappdata" : {
"ExpansionSize":64
}
},
"Databases":{
"MYAPPDATA" : {
"Directory" : "${mgrdir}myappdata"
}
},
"MapGlobals":{
"${namespace}": [{
"Name" : "dc.PackageSample.*",
"Database" : "MYAPPDATA"
}]
},
"Library.SQLConnection": {
}
}
```
Puedes ver el uso de `${namespace}`, `${mgrdir}`. Se trata de variables predefinidas y se evaluarán en el tiempo de ejecución con el *namespace* actual y el directorio de IRIS mgr. Otras variables predefinidas son:
* `${cspdir}`: subdirectorio CSP en el directorio de instalación de IRIS.
* `${bindir}`: directorio bin `$SYSTEM.Util.BinaryDirectory()`
* `${libdir}`: subdirectorio LIB en el directorio de instalación de IRIS.
* `${username}`: nombre de usuario actual `$USERNAME`
* `${roles}`: funciones actuales otorgadas `$ROLES`
Además, utilizamos `${sqlusr}`, no es una variable predefinida y debemos establecer el valor desde `module.xml`. Realmente no lo necesitamos, pero es solo para demostrar cómo los desarrolladores pueden definir y establecer variables desde modules.xml y transmitirlas al archivo de configuración.
Para ayudarte a crear tu propio archivo de configuración, una guía rápida ([cheat sheet `config-api.md`])(https://github.com/lscalese/objectscript-docker-template-with-config-api/blob/master/config-api.md) también está disponible en el repositorio de plantillas.
El archivo de configuración ya está listo, el siguiente paso es el archivo `module.xml`.
Tenemos que:
* Añadir el módulo `config-api` como una dependencia.
* Invocar un método para cargar nuestro archivo de configuración `./config-api/iris-config.json` con el argumento `${sqlusr}`.
```xml
objectscript-template-with-config-api
0.0.1
module
${root}config-api/iris-config.json
sqlusr
SQLUserRO
src
config-api
1.0.0
```
Echa un vistazo a la etiqueta Invoke:
```xml
${root}config-api/iris-config.json
sqlusr
SQLUserRO
```
El primer argumento es la ruta al archivo de configuración, `${root}` contiene el directorio del módulo usado por zpm durante la implementación.
Después de eso, todos los demás argumentos deben emparejarse. En primer lugar, una cadena con el nombre de la variable seguido del valor relacionado.
En nuestro ejemplo `sqlusr` para la variable `${sqlusr}` seguido del valor `SQLUserRO`.
Puedes pasar tantos argumentos emparejados como necesites.
Ten en cuenta que hay una etiqueta FileCopy: `` Esta etiqueta existe solo para forzar al zpm a empaquetar el archivo de configuración. Deberíamos agregar una etiqueta Invoke para eliminar el directorio que se va a limpiar, así:
```xml
${libdir}config-api/
```
Module.xml está listo, es hora de probarlo. Compila e inicia el contenedor `docker-compose up -d --build`.
Deberías ver estos registros durante la fase de configuración:
```
[objectscript-template-with-config-api] Configure START
2021-04-08 19:24:43 Load from file /opt/irisbuild/config-api/iris-config.json ...
2021-04-08 19:24:43 Start load configuration
2021-04-08 19:24:43 {
"Security.Roles":{
"MyRoleRO":{
"Descripion":"SQL Read Only Role for dc_PackageSample schema.",
"Resources":"%Service_SQL:U",
"GrantedRoles":"%SQL"
}
},
"Security.SQLPrivileges":[
{
"Grantee":"MyRoleRO",
"PrivList":"s",
"SQLObject":"1,dc_PackageSample.*"
}
],
"Security.SQLAdminPrivilegeSet":{
"USER":[
]
},
"Security.Users":{
"SQLUserRO":{
"Name":"SQLUserRO",
"Password":"$usrpwd$",
"AccountNeverExpires":true,
"AutheEnabled":0,
"ChangePassword":false,
"Comment":"Demo SQLUserRO",
"EmailAddress":"",
"Enabled":true,
"ExpirationDate":"",
"FullName":"Demo SQLUserRO",
"NameSpace":"USER",
"PasswordNeverExpires":false,
"PhoneNumber":"",
"PhoneProvider":"",
"Roles":"MyRoleRO",
"Routine":""
}
},
"Security.SSLConfigs":{
"SSLAppDefault":{
}
},
"Security.Applications":{
"/rest/myapp":{
"NameSpace":"USER",
"Enabled":1,
"DispatchClass":"Your.Dispatch.class",
"CSPZENEnabled":1,
"AutheEnabled":32
}
},
"SYS.Databases":{
"/usr/irissys/mgr/myappdata":{
"ExpansionSize":64
}
},
"Databases":{
"MYAPPDATA":{
"Directory":"/usr/irissys/mgr/myappdata"
}
},
"MapGlobals":{
"USER":[
{
"Name":"dc.PackageSample.*",
"Database":"MYAPPDATA"
}
]
},
"Library.SQLConnection":{
}
}
2021-04-08 19:24:43 * Security.Roles
2021-04-08 19:24:43 + Create MyRoleRO ... OK
2021-04-08 19:24:43 * Security.SQLPrivileges
2021-04-08 19:24:43 + Create {"Grantee":"MyRoleRO","PrivList":"s","SQLObject":"1,dc_PackageSample.*"} ... OK
2021-04-08 19:24:43 * Security.SQLAdminPrivilegeSet
2021-04-08 19:24:43 * Security.Users
2021-04-08 19:24:43 + Create SQLUserRO ... OK
2021-04-08 19:24:43 * Security.SSLConfigs
2021-04-08 19:24:43 + Create SSLAppDefault ... OK
2021-04-08 19:24:43 * Security.Applications
2021-04-08 19:24:43 + Create /api/config ... OK
2021-04-08 19:24:43 * SYS.Databases
2021-04-08 19:24:43 + Create /usr/irissys/mgr/myappdata ... OK
2021-04-08 19:24:43 * Databases
2021-04-08 19:24:43 + Create MYAPPDATA ... OK
2021-04-08 19:24:44 * MapGlobals
2021-04-08 19:24:44 + Create USER dc.PackageSample.* ... OK
2021-04-08 19:24:44 * Library.SQLConnection
[objectscript-template-with-config-api] Configure SUCCESS
```
Tu configuración se aplicó y el archivo de configuración se empaquetará cuando se publique. Puedes comprobarlo en el Portal de administración.
¡Gracias!