Limpiar filtro
Artículo
Luis Angel Pérez Ramos · 31 ene, 2023
Hola Comunidad:
En este artículo, enumero 5 funciones bastánte útiles de SQL, con sus explicaciones y algunos ejemplos de consultas👇🏻Las 5 funciones son:
COALESCE
RANK
DENSE_RANK
ROW_NUMBER
Función para obtener totales acumulados
¡Empezamos!
#COALESCE
La función COALESCE evalúa una lista de expresiones en orden de izquierda a derecha y devuelve el valor de la primera expresión non-NULL (no nula). Si todas las expresiones se corresponden con NULL (nulo), se devuelve NULL.
La siguiente sentencia devolverá el primer valor no nulo, que es 'intersystems'.
SELECT COALESCE(NULL, NULL, NULL,'intersystems', NULL,'sql')
Vamos a crear una tabla para ver otro ejemplo.
CREATE TABLE EXPENSES(
TDATE DATE NOT NULL,
EXPENSE1 NUMBER NULL,
EXPENSE2 NUMBER NULL,
EXPENSE3 NUMBER NULL,
TTYPE CHAR(30) NULL)
Ahora vamos a insertar algunos valores ficticios para probar nuestra función
INSERT INTO sqluser.expenses (tdate, expense1,expense2,expense3,ttype )
SELECT {d'2023-01-01'}, 500,400,NULL,'Present'
UNION ALL
SELECT {d'2023-01-01'}, NULL,50,30,'SuperMarket'
UNION ALL
SELECT {d'2023-01-01'}, NULL,NULL,30,'Clothes'
UNION ALL
SELECT {d'2023-01-02'}, NULL,50,30 ,'Present'
UNION ALL
SELECT {d'2023-01-02'}, 300,500,NULL,'SuperMarket'
UNION ALL
SELECT {d'2023-01-02'}, NULL,400,NULL,'Clothes'
UNION ALL
SELECT {d'2023-01-03'}, NULL,NULL,350 ,'Present'
UNION ALL
SELECT {d'2023-01-03'}, 500,NULL,NULL,'SuperMarket'
UNION ALL
SELECT {d'2023-01-04'}, 200,100,NULL,'Clothes'
UNION ALL
SELECT {d'2023-01-06'}, NULL,NULL,100,'SuperMarket'
UNION ALL
SELECT {d'2023-01-06'}, NULL,100,NULL,'Clothes'
Consultamos los datos
Ahora, al usar la función COALESCE recuperaremos el primer valor not NULL (no nulo) de las columnas expense1, expense2 y expense 3
SELECT TDATE,
COALESCE(EXPENSE1,EXPENSE2,EXPENSE3),
TTYPE
FROM sqluser.expenses ORDER BY 2
Funciones #RANK vs DENSE_RANK vs ROW_NUMBER
RANK()— asigna un número entero de clasificación (ranking) a cada fila dentro del mismo "marco de ventana" (conjunto de datos obtenidos en la consulta), empezando en 1. Los números del ranking pueden incluir valores duplicados si varias filas contienen el mismo valor en el campo definido para la función de ventana.
ROW_NUMBER() — asigna un número entero único y secuencial a cada fila dentro del mismo "marco de ventana", empezando en 1. Si varias filas contienen el mismo valor para el campo definido en la función de ventana, a cada fila se le asigna un número entero único y secuencial.
DENSE_RANK() no se salta ningún valor en el ranking si hay valores duplicados.
En SQL, hay varias formas de asignar un ranking a una fila, que analizaremos en detalle con un ejemplo. Consideramos de nuevo el mismo ejemplo anterior, pero ahora queremos saber cuál es el gasto mayor.
Queremos saber donde gasto más dinero y para ello tenemos diferentes formas de hacerlo. Podemos usar las tres funciones: ROW_NUMBER() , RANK() y DENSE_RANK() . Ordenaremos la tabla anterior usando las tres funciones y veremos las diferencias entre ellas usando la siguiente consulta:
Esta es nuestra consulta:
La principal diferencia entre las tres funciones es cómo tratan los empates. Vamos a explicar las diferencias un poco más en detalle:
ROW_NUMBER()devuelve un número único para cada fila empezando en el 1. Cuando hay empates, asigna un número de forma arbitraria si no se define un segundo criterio.
RANK()devuelve un número único para cada fila empezando en el 1, excepto cuando hay empates. Entonces asignará el mismo número. Y se saltará un valor en el ranking tras el puesto del ranking duplicado.
DENSE_RANK() asigna el mismo valor del ranking a los valores duplicados, pero no se salta ningún puesto del ranking.
#Calculando Totales Acumulados (Running Totals)
La función running total (total acumulado) es probablemente una de las funciones de ventana más útiles, especialmente cuando se quiere visualizar el crecimiento. Al usar una función de ventana con SUM(), se puede calcular una agregación acumulativa.
Para hacerlo, solo necesitamos sumar una variable usando el agregador SUM() pero ordenar la función usando una columna TDATE.
Esta sería la consulta:
Como se puede ver en la tabla, ahora tenemos la suma acumulada de la cantidad de dinero gastada, según pasan los días.
Conclusión
SQL es excelente. Las funciones utilizadas en este artículo pueden ser útiles para el análisis de datos, la ciencia de datos y cualquier otro campo relacionado con los datos.
Por eso es importante seguir actualizando y mejorando los conocimientos de SQL.
¡Espero que os resulte útil!
Artículo
Dmitrii Kuznetsov · 19 sep, 2022
Una sesión simultánea en IRIS: SQL, Objects, REST y GraphQL
Kazimir Malevich, "Deportistas" (1932)
"¡Pues claro que no lo entiende! ¿Cómo puede una persona que siempre ha viajado en un carruaje tirado por caballos entender los sentimientos e impresiones del viajero expres o del piloto de aviones?"Kazimir Malevich (1916)
Introducción
Ya hemos abordado el tema de por qué la representación de objetos/clases es superior a la de SQL para implementar modelos de áreas temáticas. Y esas conclusiones y hechos son tan ciertos ahora como lo han sido siempre. Entonces, ¿por qué deberíamos dar un paso atrás y hablar sobre las tecnologías que arrastran las abstracciones de vuelta al nivel global, donde habían estado en la era pre-objetos y pre-clases? ¿Por qué debemos fomentar el uso de "código espagueti", que provoca errores que son difíciles de rastrear y se basa en las habilidades de desarrolladores virtuosos?
Hay varios argumentos a favor de la transmisión de datos por medio de APIs basadas en SQL/REST/GraphQL en lugar de representarlos como clases/objetos:
Estas tecnologías están muy bien estudiadas y son bastante fáciles de implementar
Disfrutan de una increíble popularidad y han sido ampliamente implementadas en software accesible y de código abierto
Con frecuencia no hay otra alternativa que utilizar estas tecnologías, especialmente en la web y en las bases de datos
Lo más importante es que las APIs siguen utilizando objetos, ya que ofrecen la forma más apropiada de implementar las APIs en el código
Antes de hablar de la implementación de las APIs, vamos a echar un vistazo a las capas de abstracción por debajo. El siguiente diagrama muestra cómo se mueven los datos entre el lugar donde se almacenan permanentemente y el lugar donde se procesan y se presentan al usuario de nuestras aplicaciones.
Actualmente, los datos se almacenan en discos duros giratorios (HDD) o, para utilizar una tecnología más moderna, en chips de memoria flash en un SSD. Los datos se escriben y se leen utilizando un flujo que consiste en bloques de almacenamiento separados en el HDD/SSD.
La división en bloques no es aleatoria. Más bien, está determinado por la física, la mecánica y la electrónica del medio de almacenamiento de datos. En un disco duro, estas son las pistas/sectores de un disco magnético giratorio. En un SSD, son los segmentos de memoria en un chip de silicio regrabable.
La esencia es la misma: son bloques de información que debemos encontrar y reunir para recuperar los datos que necesitamos. Los datos deben ensamblarse en estructuras que emparejen nuestro modelo/clase de datos con los valores que corresponden al momento de la consulta. El DBMS (Sistema de Administración de Bases de Datos) integrado en el subsistema de archivos del sistema operativo es el responsable del proceso de ensamblaje y recuperación de datos.
Podemos evitar el DBMS dirigiéndonos directamente al sistema de archivos o incluso al HDD/SSD. Pero entonces perdemos dos puentes súper importantes para los datos: entre los bloques de almacenamiento y los flujos de archivos; y entre los archivos y la estructura ordenada en el modelo de base de datos. En otras palabras, asumimos la responsabilidad del desarrollo de todo el código para procesar bloques, archivos y modelos, incluyendo todas las optimizaciones, la depuración minuciosa y las pruebas de fiabilidad a largo plazo.
El DBMS nos ofrece una excelente oportunidad para tratar los datos en un lenguaje de alto nivel, utilizando modelos y representaciones comprensibles. Esta es una de las grandes ventajas de estos sistemas. Los DBMS y las plataformas de datos, como InterSystems IRIS, ofrecen aún más: la capacidad de acceder simultáneamente a los datos ordenados de muy diversas maneras. Y cada uno decide cuál utilizar en su proyecto.
Vamos a aprovechar la variedad de herramientas que nos ofrece IRIS. Vamos a hacer el código más atractivo y limpio. Utilizaremos directamente ObjectScript, el lenguaje orientado a objetos, para utilizar y desarrollar APIs. En otras palabras, por ejemplo, llamaremos al código SQL directamente desde el software ObjectScript. Para otras APIs, utilizaremos librerías listas y herramientas integradas en ObjectScript.
Tomaremos nuestros ejemplos del proyecto de Internet SQLZoo, que ofrece recursos de aprendizaje para SQL. Utilizaremos los mismos datos en nuestros otros ejemplos de API.
Si quieres obtener una visión general de la variedad de enfoques para el diseño de API y aprovechar las soluciones ya hechas, esta es una interesante y útil colección de APIs públicas, que han sido reunidas en un único proyecto en GitHub.
SQL
No hay una forma más natural de empezar que con SQL. ¿Quién no lo conoce?
Hay un enorme cantidad de tutoriales y libros sobre SQL. Nos basaremos en SQLZoo. Es un buen curso de SQL para principiantes, con ejemplos, tutoriales y una referencia del lenguaje SQL.
Vamos a trasladar algunas tareas de SQLZoo a la plataforma de IRIS y a resolverlas utilizando diversos métodos.
¿Con qué rapidez puedes acceder a InterSystems IRIS en tu ordenador? Una de las opciones más rápidas es implementar un contenedor en Docker a partir de una imagen ya preparada de la Community Edition de InterSystems IRIS. La Community Edition es una versión gratuita de InterSystems IRIS Data Platform para desarrolladores.Otras maneras de acceder a la Community Edition de InterSystems IRIS en el Portal de Formación.
Para pasar los datos de SQLZoo a nuestro propia instancia de almacenamiento de IRIS.
Para hacer esto:
Abre el Portal de Administración (el mío, por ejemplo, está en http://localhost:52773/csp/sys/UtilHome.csp),
Cambia al área USER: en el Namespace %SYS haz clic en el enlace “Switch” y selecciona USER
Ve a System > SQL - abre el Explorador del Sistema, luego SQL y haz clic en el botón “Go”.
En la parte derecha se abrirá la pestaña "Execute query" con el botón "Execute", que es lo que necesitamos.
Para obtener más información sobre cómo trabajar con SQL a través del Portal de Administración, consulta esta documentación.
Echa un vistazo a los scripts listos para implementar la base de datos y el conjunto de datos de prueba de SQLZoo en la descripción de la sección Datos.
Aquí hay un par de enlaces directos para la tabla world:
Un script que se utiliza para crear la base de datos world
Los datos que entran en esa tabla
El script para crear la base de datos se puede ejecutar en el formulario Query Executor que está en el Portal de administración de IRIS.
CREATE TABLE world(
name VARCHAR(50) NOT NULL
,continent VARCHAR(60)
,area DECIMAL(10)
,population DECIMAL(11)
,gdp DECIMAL(14)
,capital VARCHAR(60)
,tld VARCHAR(5)
,flag VARCHAR(255)
,PRIMARY KEY (name)
)
Para cargar el conjunto de pruebas para el formulario Query Executor, ve al menú Wizards > Data Import. Ten en cuenta que el directorio con el archivo de datos de prueba debe añadirse previamente, cuando creas el contenedor, o cargarse desde el ordenador por medio del navegador. Esta opción está disponible en el panel de control del asistente de importación de datos.
Revisa si la tabla con los datos está presente ejecutando este script en el formulario del Query Executor:
SELECT * FROM world
Ahora podemos acceder a los ejemplos y las tareas desde la página web de SQLZoo. Los siguientes ejemplos requieren que implementes una consulta SQL en la primera asignación:
SELECT population
FROM world
WHERE name = 'France'
De esta manera, podrás seguir trabajando sin problemas con la API, transfiriendo tareas de SQLZoo a la plataforma IRIS.
Nota: como he descubierto, los datos en la interfaz de SQLZoo son diferentes de los datos exportados. Al menos en el primer ejemplo, los valores para la población de Francia y Alemania difieren. No te preocupes por eso. Utiliza los datos de Eurostat como referencia.
Otra forma práctica de obtener acceso SQL a la base de datos en IRIS es el editor de Visual Studio Code con el plugin SQL Tools y el driver SQLTools para InterSystems IRIS. Esta solución es muy popular entre los desarrolladores - dale una vuelta.
Con el fin de proceder sin problemas al siguiente paso y obtener acceso a través de objetos a nuestra base de datos, vamos a tomar un pequeño desvío desde las consultas SQL "puras" a las consultas SQL embebidas en el código de la aplicación en ObjectScript, que es un lenguaje orientado a objetos integrado en IRIS.
Cómo configurar el acceso a IRIS y desarrollar en ObjectScript en VSCode.
Class User.worldquery
{
ClassMethod WhereName(name As %String)
{
&sql(
SELECT population INTO :population
FROM world
WHERE name = :name
)
IF SQLCODE<0 {WRITE "SQLCODE error ",SQLCODE," ",%msg QUIT}
ELSEIF SQLCODE=100 {WRITE "Query returns no results" QUIT}
WRITE name, " ", population
}
}
Vamos a comprobar el resultado en el terminal:
do ##class(User.worldquery).WhereName("France")
Deberías recibir el nombre del país y el número de habitantes como respuesta.
Objetos/Tipos
Ahora, vamos a la historia de REST/GraphQL. Estamos implementando una API para protocolos web. La mayoría de las veces, tendríamos el código fuente oculto en el lado del servidor en un lenguaje que tiene un buen soporte para clases, o incluso un paradigma totalmente orientado a objetos. Estos son algunos de los lenguajes de los que hablamos: Spring en Java/Kotlin, Django en Python, Ruby en Rails, ASP.NET en C#, o Angular en TypeScript. Y, por supuesto, objetos en ObjectScript, que es nativo de la plataforma IRIS.
¿Por qué esto es importante? Las clases y objetos en tu código se simplificarán a estructuras de datos cuando se envían. Hay que tener en cuenta cómo se simplifican los modelos en el programa, lo que es similar a tener en cuenta las pérdidas en los modelos relacionales. También hay que asegurarse de que, al otro lado de la API, los modelos se restauran adecuadamente y se pueden utilizar sin distorsiones. Esto supone una carga adicional: una responsabilidad adicional para ti como programador. Fuera del código y más allá de la ayuda de traductores, compiladores y otras herramientas automáticas, hay que asegurarse continuamente de que los modelos se transfieren correctamente.
Si nos fijamos en el problema anterior desde una perspectiva diferente, todavía no vemos ninguna tecnología ni herramienta que se pueda utilizar para transferir fácilmente clases/objetos de un programa en un lenguaje a un programa en otro. ¿Qué es lo que queda? Hay implementaciones simplificadas de SQL/REST/GraphQL, y una infinidad de documentación que describen la API en un lenguaje amigable. La documentación más informal (desde la perspectiva del ordenador) para desarrolladores describe exactamente lo que debería ser traducido en código formal utilizando todos los medios disponibles, para que el ordenador pueda procesarlos.
Los programadores desarrollan constantemente diferentes enfoques para resolver los problemas anteriores. Uno de los enfoques exitosos es el paradigma del lenguaje cruzado en el objeto DBMS de la plataforma IRIS.
La siguiente tabla te ayudará a entender la relación entre los modelos OPP y SQL en IRIS:
Programación orientada a objetos (OOP)
Lenguaje de consulta estructurado (SQL)
Paquete
Esquema
Clase
Tabla
Propiedad
Columna
Método
Procedimiento almacenado
Relación entre dos clases
Clave foránea, join
Objeto(en memoria o en disco)
Fila (en el disco)
Puedes obtener más información sobre la visualización de objetos y modelos relacionales en la documentación de IRIS.
Al ejecutar nuestra consulta SQL para crear la tabla world a partir del ejemplo anterior, IRIS generará automáticamente las descripciones del objeto correspondiente en la clase denominada User.world.
Class User.world Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = world ]
{
Property name As %Library.String(MAXLEN = 50) [ Required, SqlColumnNumber = 2 ];
Property continent As %Library.String(MAXLEN = 60) [ SqlColumnNumber = 3 ];
Property area As %Library.Numeric(MAXVAL = 9999999999, MINVAL = -9999999999, SCALE = 0) [ SqlColumnNumber = 4 ];
Property population As %Library.Numeric(MAXVAL = 99999999999, MINVAL = -99999999999, SCALE = 0) [ SqlColumnNumber = 5 ];
Property gdp As %Library.Numeric(MAXVAL = 99999999999999, MINVAL = -99999999999999, SCALE = 0) [ SqlColumnNumber = 6 ];
Property capital As %Library.String(MAXLEN = 60) [ SqlColumnNumber = 7 ];
Property tld As %Library.String(MAXLEN = 5) [ SqlColumnNumber = 8 ];
Property flag As %Library.String(MAXLEN = 255) [ SqlColumnNumber = 9 ];
Parameter USEEXTENTSET = 1;
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
/// DDL Primary Key Specification
Index WORLDPKey2 On name [ PrimaryKey, Type = index, Unique ];
}
Esta es una plantilla que puedes utilizar para desarrollar tu aplicación en un estilo orientado a objetos. Todo lo que necesitas hacer es añadir métodos a la clase en ObjectScript, que tiene paquetes listos para la base de datos. De hecho, los métodos para esta clase son "procedimientos almacenados", para tomar prestada la terminología SQL.
Vamos a intentar implementar el mismo ejemplo que completamos antes de utilizar SQL. Añade el método WhereName a la clase User.world, que desempeñará el papel del diseñador de objetos "Información del país" para el nombre del país introducido:
ClassMethod WhereName(name As %String) As User.world
{
Set id = 1
While ( ..%ExistsId(id) ) {
Set countryInfo = ..%OpenId(id)
if ( countryInfo.name = name ) { Return countryInfo }
Set id = id + 1
}
Return countryInfo = ""
}
Verifica las siguientes líneas de comando en el terminal:
set countryInfo = ##class(User.world).WhereName("France")
write countryInfo.name
write countryInfo.population
De este ejemplo podemos entender que, para encontrar el objeto deseado por el nombre del país, a diferencia de una consulta SQL, necesitamos ordenar manualmente los registros de la base de datos uno por uno. En el peor de los casos, si nuestro objeto está al final de la lista (o no está allí en absoluto), tendremos que ordenar todos los registros. Hay un debate aparte sobre cómo se puede acelerar el proceso de búsqueda mediante la indexación de campos de objeto y la autogeneración de métodos de clase en IRIS. Puedes leer más en la documentación y en este artículo de la Comunidad de Desarrolladores.
Por ejemplo, para nuestra clase, conociendo el nombre del índice generado por IRIS a partir del nombre del país WORLDPKey2, se puede iniciar/diseñar un objeto desde la base de datos utilizando una sola consulta rápida:
set countryInfo = ##class(User.world).WORLDPKey2Open("France")
Revisa también:
write countryInfo.name write countryInfo.population
En esta documentación puedes encontrar algunas pautas para decidir si utilizar acceso a través de objetos o SQL.
Por supuesto, siempre debes tener en cuenta que puede que sólo necesites uno de ellos para realizar tus tareas.
Además, gracias a la disponibilidad de paquetes binarios listos en IRIS que son compatibles con los lenguajes OOP más comunes, como Java, Python, C, C# (.Net), JavaScript, e incluso Julia (consulta GitHub y OpenExchange), que está ganando popularidad rápidamente, siempre podrás elegir las herramientas de desarrollo de lenguajes que más te convengan.
Ahora vamos a profundizar en el debate sobre los datos en la API web.
REST, o la API web RESTful
Vamos a salir de los límites del servidor y del terminal familiar y a utilizar algunos interfaces más convencionales: el navegador y aplicaciones similares. Estas aplicaciones dependen de los protocolos de hipertexto de la familia HTTP para administrar las interacciones entre sistemas. IRIS incorpora varias herramientas adecuadas para este fin, incluyendo un servidor de base de datos real y el servidor HTTP Apache.
La Transferencia de Estado Representacional (REST) es un estilo de arquitectura para diseñar aplicaciones distribuidas y, en particular, aplicaciones web. Aunque es popular, REST solo es un conjunto de principios arquitectónicos, mientras que SOAP es un protocolo estándar preservado por el Consorcio World Wide Web (W3C), y por tanto las tecnologías basadas en SOAP están respaldadas por un estándar.
El ID global en REST es una URL, y define cada unidad de información sucesiva cuando se intercambia con una base de datos o una aplicación back-end. Consulta esta documentación para desarrollar servicios REST en IRIS.
En nuestro ejemplo, el identificador base será algo parecido a la base desde la dirección del servidor IRIS, http://localhost:52773, y la ruta /world/ a nuestros datos que es un subdirectorio de ella. En particular, se trata de nuestro directorio de países /world/France.
En un contenedor Docker tendrá un aspecto similar a este:
http://localhost:52773/world/France
Si estás desarrollando una aplicación completa, asegúrate de revisar las recomendaciones de la documentación de IRIS. Una de ellos se basa en la descripción de la API REST, según la especificación OpenAPI 2.0.
Hagamos esto de la manera fácil, implementando la API manualmente. En nuestro ejemplo, crearemos la solución REST más simple, que solo requiere dos pasos en IRIS:
Crear una clase monitor (API) que se ejecutará al llamar a la URL. Esta clase heredará de la clase del sistema %CSP.REST
Configurar una aplicación web para que invoque a nuestra clase API cuando se llame a la URL.
Paso 1: Clase API
Debería estar claro cómo se puede implementar una clase. Sigue las instrucciones en la documentación para crear una REST "manual".
/// Description
Class User.worldrest Extends %CSP.REST
{
Parameter UseSession As Integer = 1;
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/:name" Method="GET" Call="countryInfo" />
</Routes>
}
}
Asegúrate de incluir un método que gestione la llamada. Debería realizar exactamente la misma función que las llamadas en el terminal del ejemplo anterior:
ClassMethod countryInfo(name As %String) As %Status
{
set countryInfo = ##class(User.world).WhereName(name)
write "Country: ", countryInfo.name
write "<br>"
write "Population: ", countryInfo.population
return $$$OK
}
Como se puede ver, el parámetro que empieza con dos puntos, :name,está indicado para que se pase como variable al método que gestiona la llamada.
Paso 2: Configurando la aplicación web IRIS
En System Administration > Security > Applications > Web Applications, añade una nueva aplicación web con una dirección de entrada URL en /world y este handler o manejador: la clase API que has implementado en el paso anterior.
Después de que se configura, la aplicación web debería responder inmediatamente cuando vayas a http://localhost:52773/world/France. Ten en cuenta que la base de datos distingue entre mayúsculas y minúsculas, por lo que se debe utilizar la letra correcta al transmitir los datos de la solicitud al parámetro del método.
Consejos útiles:
Utiliza las herramientas de depuración si es necesario. Puedes encontrar una buena descripción en este artículo de dos partes (echa un vistazo a los comentarios también)
Si aparece el error "401 Unauthorized", y estás seguro de que la clase monitor está en el servidor y de que no hay errores en el enlace, intenta añadir la función %All en la pestaña Application Roles que se encuentra en la configuración de la aplicación web. Este no es un método totalmente seguro, y es necesario comprender las posibles implicaciones de permitir el acceso para todas las funciones, pero es aceptable para una instalación local.
GraphQL
Este es un terreno nuevo desde el punto de vista de que no encontrarás nada en la documentación actual de IRIS sobre APIs que utilizan GraphQL. Sin embargo, esto no debería impedirnos utilizar esta maravillosa herramienta.
Hace sólo cinco años que GraphQL salió a la luz. Desarrollado por la Fundación Linux, GraphQL es un lenguaje de consulta para APIs. Y probablemente se puede decir que se trata de la mejor tecnología derivada de la mejora de la arquitectura REST y de las distintas APIs web. Aquí hay un breve artículo introductorio para principiantes. Y, gracias a los esfuerzos de los seguidores de InterSystems y a sus ingenieros, IRIS ofrece aplicaciones de ejemplo para GraphQL desde 2018.
Aquí está el artículo relacionado “Cómo implementar GraphQL en las plataformas de InterSystems”.
La aplicación GraphQL se compone de dos módulos: el backend de la aplicación en el lado de IRIS y el frontend que se ejecuta en el navegador. En otras palabras, es necesario configurarlo de acuerdo con las instrucciones para la aplicación web GraphQL y GraphiQL.
Por ejemplo, así se ve la configuración de la aplicación para mí en IRIS dentro de un contenedor Docker. Estas son las configuraciones para una aplicación web GraphQL que actúa como API REST y un gestor de esquemas de base de datos:
Y la segunda aplicación GraphQL es una interfaz de usuario para el navegador, escrita en HTML y JavaScript:
Se puede ejecutar visitando http://localhost:52773/graphiql/index.html.
Sin ninguna configuración restrictiva adicional, la aplicación inmediatamente buscará todos los esquemas de la base de datos que pueda encontrar en el área de instalación. Esto significa que nuestros ejemplos comenzarán a funcionar de inmediato. Además, el frontend proporciona un maravilloso conjunto organizado de pistas de los objetos disponibles.
Este es un ejemplo de una consulta GraphQL en nuestra base de datos:
{
User_world ( name: France ) {
name
population
}
}
Y aquí está la respuesta correspondiente:
{
"data": {
"User_world": [
{
"name": "France",
"population": 65906000
}
]
}
}
Así es como se ve en el navegador:
Resumen
Tecnología
Antiguedad de la tecnología
Ejemplo de consulta
SQL
50 años
Edgar F. Codd
SELECT population
FROM world
WHERE name = 'France'
OOP
40 años
Alan Kay and
Dan Ingalls
set countryInfo = ##class(User.world).WhereName("France")
REST
20 años
Roy Thomas Fielding
http://localhost:52773/world/France
GraphQL
5 años
Lee Byron
{ User_world ( name: France ) {
name
population
}
}
Se está invirtiendo mucha energía en tecnologías como SQL, REST y probablemente también en GraphQL. También hay mucha historia detrás de ellas. Todas funcionan bien entre sí, dentro de la plataforma IRIS, para crear programas que procesan datos
Aunque no se menciona en este artículo, IRIS también es compatible con otras APIs, basadas en XML (SOAP) y JSON, que están bien implementadas
A menos que te ocupes específicamente de, por ejemplo, organizar tus objetos, recuerda que los datos intercambiados con la ayuda de APIs siguen representando una versión incompleta y reducida de una transferencia de objetos. Como desarrollador (no el código), eres responsable de garantizar la correcta transferencia de información sobre el tipo de datos de un objeto
Una pregunta para vosotros, estimados lectores
El propósito de este artículo no era solo comparar las API modernas, y ni siquiera revisar las funciones básicas de IRIS. Era ayudar a que se viera lo fácil que es cambiar de una API a otra cuando se accede a una base de datos, aprender a dar los primeros pasos en IRIS y obtener rápidamente resultados de las tareas.
Por esta razón estoy muy interesado en saber cuál es vuestra opinión:
¿Esta clase de enfoque ayuda a empezar a trabajar con el software?
¿Qué pasos del proceso dificultan el dominio de las herramientas para trabajar con la API en IRIS?
¿Podríais nombrar un obstáculo que no habéis podido prever?
Si conocéis a alguien que está aprendiendo a utilizar IRIS, podéis pedirle que deje un comentario en este artículo. Las preguntas y respuestas siempre son útiles para todos.
Artículo
Nancy Martínez · 16 abr, 2020
A partir de la versión 2019.2, InterSystems IRIS ofrece su API nativa para Python como un método de alto rendimiento para acceso a datos. La API nativa permite interactuar directamente con la estructura de datos nativa de IRIS.
Globals
Como desarrolladores de InterSystems, seguramente ya estais familiarizados con los globals. Vamos a revisar los aspectos básicos por si os apetece un repaso, pero podéis saltar a la siguiente sección si no lo necesitáis.InterSystems IRIS usa globals para almacenar los datos. Un global es una matriz dispersa formada por nodos que pueden, o no, tener un valor y subnodos. Lo que sigue es un ejemplo abstracto de un global:
En este ejemplo, a es un nodo raíz, al que nos referimos con el nombre del global. Cada nodo tiene una dirección de nodo, que consiste en el nombre del global y uno o múltiples subscripts (nombres de subnodos). a tiene los subscripts b y c; la dirección de nodo de esos nodos es s a->b y a->c.
Los nodos a->b y a->c->g tienen un valor (d y h), los nodos a->b->e y a->b->f no tienen valor. El nodo a->b tiene subscripts e y f.
Podéis encontrar una descripción detallada de esta estructura en el libro de InterSystems "Using Globals".Leer y escribir en el Global
La API nativa de Python permite leer y escribir los datos directamente en el global de IRIS. El paquete irisnative está disponible en GitHub - o si tienes InterSystems IRIS instalado de forma local en tu equipo, lo encontrarás en el subdirectorio dev/python de tu directorio de instalación.
La función irisnative.createConnection te permite crear una conexión con IRIS y la función irisnative.createIris te ofrece un objeto de esta conexión con el que se puede manipular el global. Este objeto tiene un método get and set para leer/escribir desde/hacia el global, y un método kill para eliminar un nodo y sus subnodos. También tiene un método isDefined, que devuelve 0 si el nodo solicitado no existe; 1 si tiene un valor, pero ningún descendiente; 10 si no tiene valor y tiene descendientes; u 11 si tiene un valor y descendientes.
import irisnative conn = irisnative.createConnection("127.0.0.1", 51773, "USER", "", "
") iris = irisnative.createIris(conn) iris.set("value", "root", "sub1", "sub2") # sets "value" to root->sub1->sub2 print(iris.get("root", "sub1", "sub2")) print(iris.isDefined("root", "sub1")) iris.kill("root") conn.close()
También tiene un método iterator para hacer un bucle sobre los subnodos de un determinado nodo. (Mostraré su uso en la siguiente sección)
Podéis leer una descripción completa de cada método en la documentación de la API nativa para Python.
Archivos de datos de tránsito del GTFS de San Francisco
Almacenamiento de datos en un global
El General Transit Feed Specification (GTFS) es un formato para horarios y rutas de transporte público. Vamos a ver cómo podemos usar la API nativa de IRIS para trabajar con datos del GTFS de San Francisco a partir del 10 de junio de 2019.
Primero, almacenaremos en el global IRIS la información de los archivos de datos. (En esta demostración no usaremos todos los archivos y columnas). Los archivos están en formato CSV, en el que la primera fila muestra los nombres de las columnas, y las otras filas contienen los datos. En Python, comenzaremos con las importaciones necesarias y estableceremos una conexión con IRIS:
import csv import irisnative conn = irisnative.createConnection("127.0.0.1", 51773, "USER", "", "
") iris = irisnative.createIris(conn)
En base a los nombres de las columnas y los datos, podemos construir una estructura de árbol razonable para cada archivo y usar iris.set para almacenar los datos en el global.
Empecemos con el archivo stops.txt, que contiene todas las paradas (stops) del transporte público en la ciudad. De este archvo, solo usaremos las columnas stop_id y stop_name. Las almacenaremos en un global llamado stops dentro de una estructura de árbol con una capa de nodos, con los IDs de parada como subscripts y los nombres de paradas como valores de nodos. Así, nuestra estructura tendrá este aspecto stops → [stop_id]=[stop_name]. (Para este artículo, usaré los corchetes para indicar cuándo un subscript no es literal, sino que es un valor leído de los archivos de datos).
with open("stops.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # stops -> [stop_id]=[stop_name] for row in reader: iris.set(row[6], "stops", row[4])
csv.reader devuelve un iterador de listas que contienen los valores separados por comas. La primera línea contiene los nombres de las columnas, por lo que la omitiremos connext(reader). Usaremos iris.set para definir el nombre de la parada como valor de stops -> [stop_id].
A continuación viene el archivo routes.txt, del que usaremos las columnas route_type, route_id, route_short_name y route_long_name. Una estructura de global razonable es routes -> [route_type] -> [route_id] -> [route_short_name]=[route_long_name]. (El tipo de ruta (route) es 0 para un tranvía, 3 para un autobús y 5 para un tranvía). Podemos leer el archivo CSV y colocar los datos en el global exactamente de la misma forma.
with open("routes.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # routes -> [route_type] -> [route_id] -> [route_short_name]=[route_long_name] for row in reader: iris.set(row[0], "routes", row[1], row[5], row[8])
Cada ruta tiene viajes (trips), almacenados en trips.txt, del que usaremos las columnas route_id, direction_id, trip_headsign and trip_id. Los viajes se identifican de forma única con su ID de viaje ("trip ID"), que veremos más adelante en el archivo de horarios de parada. Los viajes de una ruta pueden separarse en dos grupos según su dirección, y las direcciones tienen letreros ("head signs") asociados a ellas. Esto nos lleva a la estructura de árbol trips -> [route_id] -> [direction_id]=[trip_headsign] -> [trip_id].
Aquí necesitamos dos llamadas a iris.set - una para definir el valor al nodo ID de dirección, y otra para crear el nodo sin valor del ID del viaje.
with open("trips.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # trips -> [route_id] -> [direction_id]=[trip_headsign] ->[trip_id] for row in reader: iris.set(row[3], "trips", row[1], row[2]) iris.set(None, "trips", row[1], row[2], row[6])
Por último, leeremos y almacenaremos los horarios de las paradas. Se almacenan en stop_times.txt y usaremos las columnas stop_id, trip_id, stop_sequence y departure_time. Una primera opción podría ser usar stoptimes -> [stop_id] -> [trip_id] -> [departure_time] o, si queremos mantener la secuencia de paradas, stoptimes -> [stop_id] -> [trip_id] -> [stop_sequence]=[departure_time].
with open("stop_times.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # stoptimes -> [stop_id] -> [trip_id] -> [stop_sequence]=[departure_time] for row in reader: iris.set(row[2], "stoptimes", row[3], row[0], row[4])
Consultar los datos usando la API nativa
A continuación, nuestro objetivo es encontrar todos los horarios de salida para la parada con el nombre dado.
Primero, recuperamos el ID de parada desde el nombre de parada dado, y luego usaremos ese ID para encontrar los horarios relevantes en stop_times.
La llamada iris.iterator("stops") nos permite iterar sobre los subnodos del nodo raíz de paradas. Queremos iterar sobre los pares de subscripts y valores (para comparar los valores con el nombre dado, e inmediatamente conocer el subscript si coinciden), por lo que llamamos a .items() en el iterador, lo que define la clase de devolución como tuplas (de subscripts, valores). Luego podemos iterar sobre todas estas tuplas y encontrar la parada correcta.
stop_name = "Silver Ave & Holyoke St" iter = iris.iterator("stops").items() stop_id = None for item in iter: if item[1] == stop_name: stop_id = item[0] break if stop_id is None: print("Stop not found.") import sys sys.exit()
Merece la pena observar que buscar una clave por su valor mediante iteración no es muy eficiente si hay muchos nodos. Una forma de evitar esto sería tener otra matriz, en la que los subscripts sean los nombres de las paradas y los valores sean sus ID. El valor --> búsqueda clave consistiría entonces en una consulta a esta nueva matriz.
De forma alternativa, puede usar el nombre de parada como identificador en cualquier parte del código en vez del ID de parada - el nombre de parada también es único.
Como puedes ver, si tenemos una cantidad de paradas significativa, esta búsqueda puede tardar bastante. También se le conoce como "full scan" (análisis completo). Pero podemos aprovecharnos de los globals y construir la matriz invertida, en la que los nombres serán claves con IDs como valores.
iter = iris.iterator("stops").items() stop_id = None for item in iter: iris.set(item[0], "stopnames", item[1])
Tener el global de nombres de paradas (stopnames), en el que el índice es el nombre y el valor es el ID, cambiará el código anterior para encontrar el stop_id por nombre. El código será el siguiente, que se ejecutará sin una búsqueda de análisis completo:
stop_name = "Silver Ave & Holyoke St" stop_id=iris.get("stopnames", stop_name) if stop_id is None: print("Stop not found.") import sys sys.exit()
En este punto, podemos encontrar los horarios de parada. El subárbol stoptimes -> [stop_id] tiene los ID de viajes como subnodos, que tienen los horarios de paradas como subnodos. No nos interesan los ID de los viajes, solo los horarios de parada, por lo que iteraremos sobre todos los ID de viajes y recopilaremos todos los horarios de paradas para cada uno de ellos.
all_stop_times = set() trips = iris.iterator("stoptimes", stop_id).subscripts() for trip in trips: all_stop_times.update(iris.iterator("stoptimes", stop_id, trip).values())
Aquí no estamos usando .items() en el iterador, pero usaremos .subscripts() y .values() porque los IDs de viajes son subscripts (sin valores asociados)([stop_sequence]=[departure_time]), solo nos interesan los valores y horas de salida. La llamada .update agrega todos los elementos del iterador a nuestro conjunto existente. El nuevo conjunto ahora contiene todos los horarios (únicos) de paradas:
for stop_time in sorted(all_stop_times): print(stop_time)
Ahora vamos a hacerlo un poco más complicado. En vez de encontrar todas las horas de salida para una parada, encontraremos únicamente las horas de salida para una parada de una ruta dada (en ambas direcciones), cuyo ID de ruta es dado. El código para encontrar el ID de parada a partir del nombre de parada puede preservarse por completo. Entonces, se recuperarán todos los ID de paradas de la ruta dada. Estos ID se usan entonces como una restricción adicional al recuperar las horas de salida.
El subárbol de trips -> [route_id] se parte en dos direcciones, que tienen todo los ID de viajes como subnodos. Podemos iterar sobre las direcciones como antes, y agregar todos los subnodos de las direcciones a un conjunto.
route = "14334" selected_trips = set() directions = iris.iterator("trips", route).subscripts() for direction in directions: selected_trips.update(iris.iterator("trips", route, direction).subscripts())
En el siguiente paso, queremos encontar los valores de todos los subnodos de stoptimes -> [stop_id] -> [trip_id] donde [stop_id] es el ID de parada recuperado y [trip_id] es cualquiera de los IDs de viaje seleccionados. Iteramos sobre el conjunto selected_trips para encontrar todos los valores relevantes:
all_stop_times = set() for trip in selected_trips: all_stop_times.update(iris.iterator("stoptimes", stop_id, trip).values()) for stop_time in sorted(all_stop_times): print(stop_time)
Un último ejemplo muestra el uso de la función isDefined. Ampliaremos el código escrito anteriormente: en lugar de realizar un "hard-code" del ID de ruta, se ofrece el nombre corto de una ruta y luego el ID de la ruta se deberá recuperar en base a esto. Los nodos con los nombres de rutas están en la capa inferior del árbol. La capa de arriba contiene los ID de rutas. Podemos iterar sobre todos los tipos de rutas, luego sobre todos los ID de rutas y, si el nodo routes -> [route_type] -> [route_id] -> [route_short_name] existe y tiene un valor (isDefined returns 1), sabemos entonces que [route_id] es el ID que buscamos.
route_short_name = "44" route = None types = iris.iterator("routes").subscripts() for type in types: route_ids = iris.iterator("routes", type).subscripts() for route_id in route_ids: if iris.isDefined("routes", type, route_id, route_short_name) == 1: route = route_id if route is None: print("No route found.") import sys sys.exit()
El código sirve como sustituto de la línea route = "14334" en "hard-code".
Una vez finalizadas todas las operaciones de IRIS, podemos cerrar la conexión a la base de datos:
conn.close()
Próximos pasos
Hemos explicado cómo se puede usar la API nativa para Python para acceder a la estructura de datos de InterSystems IRIS. Después, lo hemos aplicado a los datos de transporte público de San Francisco. Para profundizar más en la API, podéis visitar esta documentación. La API nativa también está disponible para Java, .NET y Node.js.
Pregunta
Kurro Lopez · 30 oct, 2019
Hola,
Necesitamos crear una versión de una API existente, por lo que vamos a establecer una versión predeterminada (hasta ahora) para las conexiones actuales a la versión 1
Mi primer intento es:
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="(?i)/check" Method="GET" Call="CheckApi"/>
<Route Url="(?i)/getcustomer" Method="POST" Call="GetCustomerDefault"/>
<Route Url="(?i)/revoke" Method="DELETE" Call="RevokeDefault"/>
<Route Url="(?i)/:version/getcustomer" Method="POST" Call="GetCustomer"/>
<Route Url="(?i)/:version/revoke" Method="DELETE" Call="Revoke"/>
</Routes>
}
Parameter DEFAULTVERSION = 1;
Parameter CURRENTVERSION = 2;
/// Get customer info (API version default)
ClassMethod GetCustomerDefault() As %Status
{
quit ..GetCustomer(..#DEFAULTVERSION)
}
ClassMethod GetCustomer(pVersion As %Integer) As %Status
{
// This is the code for all version. Get the Id and pass into the message
........
quit $$$OK
}
Además, tengo un parámetro llamado DEFAULTVERSION con valor 1
De esta manera, las llamadas más nuevas tendrán el número de versión y la respuesta según la versión de API
La URL será:
apiserver.com/api/2/getCustomer
Estoy comprobando si la versión es menor que una CURRENTACTUAL, la llamada está bien
Según una nueva especificación, la URL será "api/v2/getCustomer", antes era un número entero, y ahora será una cadena.
¿Cómo puedo verificar si este parámetro está bien formado (v y número), luego puedo evaluar si el número es una versión API válida?
Podemos cambiar nuestra versión, por lo que cualquier sugerencia será bienvenida. Hola,
No es posible porque el cliente tiene instalado una versión Healthcare 2017.2 y no tiene mucha intención de cambiar de aplicación. Además, las dos versiones han de convivir simultaneamente en producción. Hola Francisco,
¿no os podéis plantear trabajar con el API Manager como explican David y Alberto aquí?
https://es.community.intersystems.com/post/nuevo-v%C3%ADdeo-desarrollar-y-gestionar-apis-con-intersystems-iris-data-platform
Así no tendrías que preocuparte de si te están accediendo a la api correcta, solo habría una publicada y tú podrías estar trabajando en las versiones que quisieras y luego pasarla a producción sin cambiar la url de acceso.
Saludos!
Artículo
Mathew Lambert · 25 jun, 2020
El propósito de este artículo es reforzar el perfil de un procedimiento muy potente que ha estado disponible desde hace mucho tiempo para nosotros, y abrir un debate sobre las maneras en que puede utilizarse (o explotarse).
Puedes leer más información sobre el el mecanismo aquí. En resumen, cuando definas una clase puedes utilizar la palabra clave Projection para referirte a una o más clases de proyección. Una clase de proyección permite implementar métodos que se llaman desde puntos clave en el ciclo de vida de tu clase.
Una clase de proyección debe contener %Projection.AbstractProjection y normalmente implementará al menos uno de los siguientes métodos:
CreateProjection
RemoveProjection
Se llamará a CreateProjection una vez que tu clase haya sido compilada. Se llamará a RemoveProjection justo antes de que tu clase se compile nuevamente, o justo antes de que se elimine.
Creo que este procedimiento originalmente se utilizó para generar archivos Java, que implementaron una proyección en Java para una clase de Caché. Desde entonces, este procedimiento se esta usando ampliamente y se esta volviendo cada vez más sofisticado. En la versión 2015.2 conté veinticuatro %-clases que provienen de %Projection.AbstractProjection.
Además de la forma en que InterSystems utiliza el procedimiento, también observé que este se aprovecha de otras maneras. Aquí hay un par de ejemplos:
UMLExplorer se envía como un archivo XML que contiene cuatro clases. Una de ellas es una clase para proyecciones llamada ClassExplorer.WebAppInstaller, la cual se proyecta ingeniosamente a sí misma:
Class ClassExplorer.WebAppInstaller Extends %Projection.AbstractProjection
{
Projection Reference As WebAppInstaller;
...
Por lo tanto, cuando esta clase se compila, se ejecuta su método CreateProjection, realizando cualesquiera sean los pasos que el desarrollador codificó ahí. En este caso añade una aplicación web llamada /CacheExplorer, pero podría hacer cualquier cosa que permitan los permisos de la persona que compiló la clase.
Un sitio que usa la herramienta Deltanji para administrar el código fuente creó una clase para proyectar utilidades. Cada vez que activan una pieza de trabajo que requiere de algunos pasos para instalarse y ejecutarse en un namespace objetivo, ellos implementan esos pasos en una clase de distribución (D), que tiene una proyección que hace referencia a su clase para proyectar utilidades (P). Entonces, ellos hacen un paquete (D) con la pieza de trabajo. Cuando (D) se carga y compila en un namespace objetivo, el método CreateProjection de (P) es llamado automáticamente y se le pasa el nombre de la clase (D), lo que le permite llamar a los métodos de (D)
Si has visto otras maneras de utilizar la proyección, o si tú mismo has diseñado una nueva forma de usarla, compártela como un comentario en esta publicación
Una última reflexión que me gustaría compartir. Este procedimiento significa que probablemente deberíamos pensarlo dos veces antes de realizar una compilación durante la importación de un archivo XML, en especial si no estamos seguros de que podemos confiar en su contenido. El alcance que tiene una proyección maliciosa de clase es grande.
Artículo
Ricardo Paiva · 19 ago, 2021
Este es el ejemplo de un código que funciona en Caché 2018.1.3 e IRIS 2020.2
No se mantendrá sincronizado con las nuevas versiones
¡Además NO cuenta con el servicio de Soporte de InterSystems!
Durante mi búsqueda de un snapshot de un objeto persistente, conocí una característica que me gustaría compartir, ya que podría ser útil en algunas situaciones especiales. Mi objetivo era tener una imagen del antes y el después durante las pruebas unitarias.Una clase persistente típica puede tener una definición de almacenamiento como esta:
Storage Default{ <Data name="kDefaultData"> +<Value name="1"> </Value> </Data> <DataLocation>^rcc.kD</DataLocation> <DefaultData>kDefaultData</DefaultData> <IdLocation>^rcc.kD</IdLocation> <IndexLocation>^rcc.kI</IndexLocation> <StreamLocation>^rcc.kS</StreamLocation> <Type>%Storage.Persistent</Type>}
Ahora apliqué este cambio:
Parameter MANAGEDEXTENT = 0; ;extent manager dislikes this change
Storage Default{ <Data name="kDefaultData"> +<Value name="1"> </Value> </Data> <DataLocation>@(%storage_"D")</DataLocation> <DefaultData>kDefaultData</DefaultData> <IdLocation>@(%storage_"D")</IdLocation> <IndexLocation>@(%storage_"I")</IndexLocation> <StreamLocation>@(%storage_"S")</StreamLocation> <Type>%Storage.Persistent</Type>}
Todo lo que tienes que hacer ahora para utilizarlo:
set %storage="^myGlobal" ;; normal use with ROLLBACKo set %storage="%myLocalVariable" ;; no ROLLBACKoset %storage="^||myPPG" ;; no ROLLBACK
y funciona como estás acostumbrado a que lo haga. Excepto en el caso de ROLLBACK (Reversión) ya que, por supuesto, no hay ningún Journal detrás de PPG o de las variables locales
Una secuencia de uso habitual para preparar una verificación de cambios podría ser similar a la siguiente:
set %storage="^rcc.k" set obj=##class(rcc.k).%OpenId(id) ;; get originaldo obj.%SetModified(1) ;; prepare for %Saveset %storage="^||rcc" ;; location of copyset sc=obj.%Save() ;; write copy to temp storage//// carry on with testing and changes and find what happened
Creo que merece la pena compartirlo.
Artículo
Mario Sanchez Macias · 15 nov, 2021
Trabajando en soporte generalmente me preguntan cuántos días hay que mantener los journals. ¿Debería ser dos días o después de dos copias de seguridad? ¿Más? ¿Menos? ¿Por qué dos?
La respuesta correcta (para la mayoría de los entornos) es que se debería conservar los ficheros de journal desde la última copia de seguridad validada. Es decir, hasta que no verifique si una copia de seguridad es válida (restaurando el archivo y verificándolo con la utilidad Integrity), no puede estar seguro de que haya una buena copia de los datos y no por tanto no se deberían purgar los journals de manera segura.
Por ejemplo, imagina que necesitas restaurar el sistema después de un fallo de hardware que corrompió algunas bases de datos. El primer paso sería coger la última copia de seguridad y restaurarla. Pero, ¿qué sucede si la copia de seguridad está dañada o se guardó en un disco defectuoso? En ese caso, deberíamos buscar una copia de seguridad anterior hasta encontrar una copia correcta y válida. Tras restaurarla, sí quisiésemos recuperar hasta el último momento, deberíamos aplicar los journals desde que se hizo la copia hasta el momento del fallo. Si sólo tenemos uno o dos días, no será suficiente y podríamos perder datos.
Por tanto, ¡La única forma de asegurarse de que sus copias de seguridad sean válidas es verificándolas! Y para verificar, me refiero a restaurar las bases de datos y validar los datos en ellas. La forma de verificar los datos dentro de una base de datos es mediante la utilidad Integrity.
Cuando explico esto, la mayoría de los administradores lo consideran una tarea compleja, que lleva mucho tiempo y que es difícil de automatizar. Por eso he decidido construir un verificador de Backups súper sencillo que permite validar los backups fácilmente.
La utilidad es un verificador de backups sencillo para copias de seguridad realizadas con InterSystems Iris. Restaura el fichero de backup (.cbk) automáticamente y luego ejecuta un chequeo de integridad. Toda la "magia" se realiza en el método restoreAll de la clase Installer. Si quieres mejorar y personalizar la utilidad, puedes tomar prestado el código y mejorarlo enviando un correo electrónico cuando termine con los resultados de la validación (por ejemplo).
Una vez que se haya restaurado la copia de seguridad y se haya ejecutado la verificación de integridad, el log de Docker (y messages.log) contendrá los resultados de la verificación de integridad y restauración. Las bases de datos restauradas aparecerán en una carpeta llamada Restore. No damos la importancia que debemos a las copias de seguridad. Creo que esto va a ahorrar más de un quebradero de cabeza! Cierto!
Sólo nos acordamos cuando nos hacen falta, y, os puedo garantizar que muchísimas veces las copias que pensábamos que están bien, no lo están, con la consiguiente pérdida de tiempo/datos y el estrés que genera. Si te digo la verdad, hice esta aplicación para demostrar lo sencillo que es validar copias y que no haya excusas
Artículo
Muhammad Waseem · 18 abr, 2022
# Antecedentes
En las versiones de InterSystems IRIS >=2021.2 podemos usar [irispython para escribir directamente código python encima de nuestras instancias IRIS](https://docs.intersystems.com/iris20212/csp/docbook/DocBook.UI.Page.cls?KEY=AEPYTHON#AEPYTHON_runpython_script). Esto nos permite usar paquetes de python, llamar a métodos, hacer consultas SQL y hacer casi cualquier cosa en Objectscript excepto pythonic.
Por ejemplo, a continuación compruebo si hay un *namespace*:
```python
#!/usr/irissys/bin/irispython
import iris
# call arbitrary class methods
result = iris.cls('%SYS.Namespace').Exists('USER')
if result == 1:
print(f"Namespace USER is present")
```
> Pero, ¿qué pasa si mi método en IRIS tiene parámetros especiales como `Output` y `ByRef`?
>¿Cómo podemos usar los parámetros de `Salida` en irispython?
Por ejemplo, [Ens.Director](https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=ENSLIB&CLASSNAME=Ens.Director) tiene muchos parámetros de salida en sus métodos, ¿cómo puedo usar estos parámetros en python?
[Ens.Director:GetProductionStatus](https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=ENSLIB&CLASSNAME=Ens.Director#GetProductionStatus)
```cos
// Un código auxiliar de método de ejemplo de Ens.Director
ClassMethod GetProductionStatus(Output pProductionName As %String, Output pState As %Integer...
```
### Probando los métodos de variables normales
A primera vista, puedes intentar lo siguiente:
```python
import os
# Establecer el namespace de forma manual
os.environ['IRISNAMESPACE'] = 'DEMONSTRATION'
import iris
# PRUEBA 1 con variables de salida
productionName, productionState = None, None
status = iris.cls('Ens.Director').GetProductionStatus(productionName, productionState)
print("Success? -- {}".format(productionState != None))
```
_¡Pero ambas pruebas no devolverán las variables de salida! Puedes probar esto por ti mismo en cualquier *namespace* de Ensemble_
# Usando iris.ref
La utilidad irispython `iris.ref` se puede utilizar para capturar las variables `Output` y `ByRef`.
1. Crea un objeto `iris.ref()`
2. Llama a tu Método ObjectScript
3. Utiliza la variable `.value` para obtener el resultado de ese parámetro
```python
import os
# Establecer el namespace de la manera difícil
os.environ['IRISNAMESPACE'] = 'DEMONSTRATION'
import iris
# PRUEBA 2 con variables de salida
productionName, productionState = iris.ref('productionName'), iris.ref('productionState')
status = iris.cls('Ens.Director').GetProductionStatus(productionName, productionState)
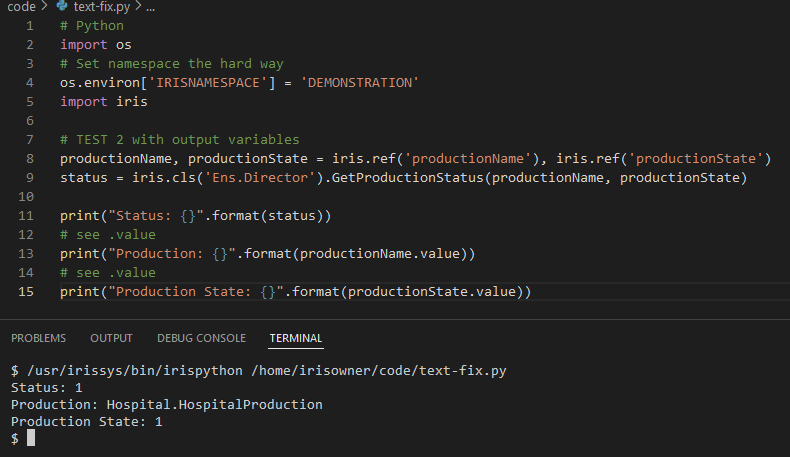
print("Status: {}".format(status))
# see .value
print("Production: {}".format(productionName.value))
# see .value
print("Production State: {}".format(productionState.value))
```
Artículo
Alberto Fuentes · 15 jun, 2022
¡Hola desarrolladores! Quería compartir hoy un ejemplo muy interesante por parte de Tani Frankel. Se trata de una aplicación sencilla sobre la utilidad SystemPerfomance.
Repasando nuestra documentación sobre la rutina de monitorización ^SystemPerformance (conocida como ^pButtons en versiones anteriores a IRIS), un cliente me dijo «Entiendo todo esto pero ojalá fuese más simple, más sencillo para definir perfiles y gestionarlos, etc.».
Entonces pensé que sería interesante como ejercicio facilitar una pequeña interfaz para hacer esas tareas más sencillas.
El primer paso era envolver en una API basada en clases la rutina actual de ^SystemPerformance.
Además, aproveché para añadir algunas otras funcionalidades como mostrar qué perfiles están ejecutándose actualmente, el tiempo que les falta, procesos que han estado en ejecución con anterioridad, etc.
El siguiente paso era añadir sobre esta API, una API REST.
Con este artefacto listo, cualquier puede ya lanzarse y construir una pequeña interfaz de usuario moderna.
Por ejemplo:
Así que aquí os comparto algunos de los pasos necesarios:
Dos clases, que son la API básica:
así como la clase que contiene la API REST (incluyendo algunos tests unitarios).
Un JSON con la especificación Swagger para la API REST.
Y una interfaz gráfica sencilla en Angular (basada en http://websystique.com/angularjs/angularjs-crud-application-using-ngresource/)
Algunas notas importantes:
La mayor parte de los métodos de la API básica utilizan puntos de entrada que no están documentados o soportados en ^SystemPerformance o ^pButtons. Algunos de esos métodos manejan estructuras internas. Estos métodos que no están soportados ni documentados pueden dejar de funcionar según próximas versiones sin previo aviso.
El código no intenta de ninguna manera servir como un ejemplo de «mejor práctica» a la hora de crear aplicaciones Angular basadas en APIs REST sobre IRIS. La parte de la interfaz gráfica es un simple ejemplo como punto de partida (de hecho, hay partes sin implementar como el directorio para logs, el refresco de contenidos, etc.)
El código inicial fue escrito hace tiempo, así que:
(a) Se ha modificado para que funcione sobre IRIS (se han tenido que hacer algunos cambios en los nombres).
(b) Inicialmente no se utilizaba el planteamiento spec-first. Ahora sí que lo utiliza.
(c) Es posible que no utilice todas las últimas funcionalidades disponibles a día de hoy.
(d) Se ha añadido también la posibilidad de ejecutarlo en un contenedor Docker.
(e) Se ha añadido también soporte para ser instalado como un paquete ZPM.
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Alberto Fuentes · 30 ene, 2023
# OCR DEMO
Esta es una demo de la funcionalidad OCR utilizando la librería `pero-ocr` de Python.
Utilizaremos la librería en una instancia InterSystems IRIS.
## Demo
Este es un ejemplo de los datos de entrada:

Y este es el resultado del OCR, donde tenemos la siguiente información:
* El texto, que está en la etiqueta `TextEquiv`
* La confianza de la lectura, presente en el atributo `conf` de la etiqueta `TextEquiv`
* Las coordenadas del texto, que están en la etiqueta `Coords`
```xml
Pero OCR
2022-12-13T08:47:12.207893+00:00
2022-12-13T08:47:12.207893+00:00
IN
CONGRESS, JULY 4, 1776.
Dhe unaniwons Declaratton of te Heten maiss States of TNmerica
hen n lí loune z human venl, i kemu nematy k mpeopě toíohohhehttcal bandí uhích have connechdí tem vith ancthet, andíl
o hi ſhwes f he eail, fie rehatal andequal flohon & ufch lhe laav . kalut and Aloil ped entilt ttem, a dant rafech to the ofunin o manknd tequies fhat thep
imuiaa
Qlver
Vbalřew/
17.
```
## Instalación
```bash
git clone
```
⚠️ ¡Importante! Esta demo requiere instalar dos modelos (ambos son requeridos)
Para instalar un modelo, descárgalo desde la página de descargas y descomprímelo en el directorio `misc/pero-ocr-fix-computation-on-cpu` del proyecto:
* https://github.com/grongierisc/iris-pero-ocr/releases/download/v1.0.0/OCR_350000.pt.cpu
* https://github.com/grongierisc/iris-pero-ocr/releases/download/v1.0.0/ParseNet_296000.pt.cpu
Después, ejecuta:
```bash
docker-compose up
```
## Uso
Coloca cualquier imagen de muestra de la carpeta `samples` y cópiala en la carpeta `misc/in` para que sea procesada por el OCR.
Los resultados estarán en la carpeta `misc/out`.
Verás los archivos xml con los resultados y las imágenes con el texto detectado.
Puedes monitorizar el progreso [aquí](http://localhost:53795/csp/irisapp/EnsPortal.ProductionConfig.zen?NAMESPACE=IRISAPP&NAMESPACE=IRISAPP&) y accediendo con `_SYSTEM` y `SYS`.
## Cómo funciona en IRIS
El OCR es un Business Service que analiza todos los ficheros en la carpeta `misc/in` y pone los resultados en una cola de mensajes.
La cola de mensajes es consumida por una Business Operation que pone los resultados en la carpeta `misc/out`.
El código está en la carpeta `src/python/pero-ocr`.
Artículo
Ricardo Paiva · 10 nov, 2022
Hace tiempo presenté un nuevo driver para Django for IRIS. Ahora voy a mostrar cómo utilizar Django con IRIS en la práctica.
Nota importante: Django no funciona bien con la Community Edition de IRIS. La Community Edition solo tiene disponibles 5 conexiones, y Django las usará muy rápido. Así que, desafortunadamente por esta razón no puedo recomendar este método para desarrollar nuevas aplicaciones, debido a la dificultad de predecir el uso de la licencia.
Inicio del proyecto Django
Para empezar, tenemos que instalar Django
pip install django
Después, creamos un proyecto llamado demo. Creará una carpeta de proyectos con el mismo nombre
django-admin startproject demo
cd demo
o se puede hacer en una carpeta existente
django-admin startproject main .
Este comando genera unos pocos archivos python para nosotros.
Donde:
manage.py: utilidad de línea de comando que permite interactuar con este proyecto Django de varias maneras
directorio main: es el paquete Python actual para vuestro proyecto
main/__init__.py: un archivo vacío que dice a Python que este directorio debería ser consideredo un paquete Python
main/settings.py: settings/configuración para este proyecto Django
main/urls.py: Las declaraciones URL para este proyecto Django; un “índice” de vuestro sitio con la funcioanlidad de Django
main/asci.py: Un punto de entrada para servidores web compatibles con ASGI para atender vuestro proyecto
main/wsci.py: Un punto de entrada para servidores web compatibles con WSGI para atender vuestro proyecto
Incluso desde este punto podemos empezar nuestro proyecto y, de alguna manera, funcionará
$ python manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced). You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
July 22, 2022 - 15:24:12
Django version 4.0.6, using settings 'main.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Ahora, se puede ir al navegador y abrir la URL http://127.0.0.1:8000 allí
Añadir IRIS
Vamos a añadir acceso a IRIS, y para hacerlo necesitamos instalar unas cuantas dependencias de nuestro proyecto, y la forma correcta de hacerlo es definirlo en el archivo llamado requirements.txt con este contenido, donde deberíamos añadir django como una dependencia
# Django itself
django>=4.0.0
Y después, el driver de IRIS for Django, publicado. Desafortunadamente, InterSystems no quiere publicar drivers propios en PyPI, así que tenemos que definirlo de esta manera más "fea". Estad atentos, pueden eliminarlo en cualquier momento, por lo que puede dejar de funcionar en el futuro. (Si estuviera en pypi, se instalaría como una dependencia de django-iris, no siendo necesaria su definición.)
# InterSystems IRIS driver for Django, and DB-API driver from InterSystems
django-iris==0.1.13
https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/main/DB-API/intersystems_irispython-3.2.0-py3-none-any.whl
Instalar dependencias definidas en este archivo con comando
pip install -r requirements.txt
Ahora, podemos configurar nuestro proyecto para usar IRIS. Para hacerlo, tenemos que actualizar el parámetro DATABASES en el archivo settings.py, con líneas como esta, en la que NAME apunta al Namespace en IRIS, y la puerta al SuperPort donde tenemos IRIS.
DATABASES = {
'default': {
'ENGINE': 'django_iris',
'NAME': 'USER',
'USER': '_SYSTEM',
'PASSWORD': 'SYS',
'HOST': 'localhost',
'PORT': 1982,
}
}
Django tiene ORM, y modelos almacenados en el proyecto, y requiere modelos de Django sincronizados con Database como tablas. Por defecto, hay unos pocos modelos, relacionados con auth. Y podemos ejecutar migrate ahora
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying auth.0012_alter_user_first_name_max_length... OK
Applying sessions.0001_initial... OK
Si vamos a IRIS, encontraremos varias tablas extra allí
Definir más modelos
Es el momento de añadir algunos de nuestros modelos. Para hacerlo, añade un nuevo archivo models.py, con contenido como este
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
dob = models.DateField()
sex = models.BooleanField()
Como puedes ver, tiene diferentes tipos de campos. Entonces este modelo tiene que estar preparado para Database. Antes de hacerlo, añade nuestro proyecto main a INSTALLED_APPS en settings.py
INSTALLED_APPS = [
....
'main',
]
Y podemos makemigrations. Este comando tiene que ser llamado después de cualquier cambio en el modelo, se ocupa de los cambios históricos en el modelo, y no importa qué versión de la aplicación está instalada, la migración sabrá cómo actualizar el esquema en la base de datos
$ python manage.py makemigrations main
Migrations for 'main':
main/migrations/0001_initial.py
- Create model Person
Podemos ejecutar migrate otra vez, ya sabe que las migraciones anteriores ya están hechas, así que solo ejecuta la nueva
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, main, sessions
Running migrations:
Applying main.0001_initial... OK
Y, de hecho, podemos ver cómo se ve la migración desde la vista de SQL.
$ python manage.py sqlmigrate main 0001
--
-- Create model Person
--
CREATE TABLE "main_person" ("id" BIGINT AUTO_INCREMENT NOT NULL PRIMARY KEY, "first_name" VARCHAR(30) NULL, "last_name" VARCHAR(30) NULL, "dob" DATE NOT NULL, "sex" BIT NOT NULL);
Pero es posible acceder a las tablas ya existentes en la base de datos, por ejemplo, si ya tienes una aplicación funcionando. Yo tengo el gestor de paquetes zpm package posts-and-tags instalado, vamos a hacer un modelo para la tabla community.posts
$ python manage.py inspectdb community.post
# This is an auto-generated Django model module.
# You'll have to do the following manually to clean this up:
# * Rearrange models' order
# * Make sure each model has one field with primary_key=True
# * Make sure each ForeignKey and OneToOneField has `on_delete` set to the desired behavior
# * Remove `managed = False` lines if you wish to allow Django to create, modify, and delete the table
# Feel free to rename the models, but don't rename db_table values or field names.
from django.db import models
class CommunityPost(models.Model):
id = models.AutoField(db_column='ID') # Field name made lowercase.
acceptedanswerts = models.DateTimeField(db_column='AcceptedAnswerTS', blank=True, null=True) # Field name made lowercase.
author = models.CharField(db_column='Author', max_length=50, blank=True, null=True) # Field name made lowercase.
avgvote = models.IntegerField(db_column='AvgVote', blank=True, null=True) # Field name made lowercase.
commentsamount = models.IntegerField(db_column='CommentsAmount', blank=True, null=True) # Field name made lowercase.
created = models.DateTimeField(db_column='Created', blank=True, null=True) # Field name made lowercase.
deleted = models.BooleanField(db_column='Deleted', blank=True, null=True) # Field name made lowercase.
favscount = models.IntegerField(db_column='FavsCount', blank=True, null=True) # Field name made lowercase.
hascorrectanswer = models.BooleanField(db_column='HasCorrectAnswer', blank=True, null=True) # Field name made lowercase.
hash = models.CharField(db_column='Hash', max_length=50, blank=True, null=True) # Field name made lowercase.
lang = models.CharField(db_column='Lang', max_length=50, blank=True, null=True) # Field name made lowercase.
name = models.CharField(db_column='Name', max_length=250, blank=True, null=True) # Field name made lowercase.
nid = models.IntegerField(db_column='Nid', primary_key=True) # Field name made lowercase.
posttype = models.CharField(db_column='PostType', max_length=50, blank=True, null=True) # Field name made lowercase.
published = models.BooleanField(db_column='Published', blank=True, null=True) # Field name made lowercase.
publisheddate = models.DateTimeField(db_column='PublishedDate', blank=True, null=True) # Field name made lowercase.
subscount = models.IntegerField(db_column='SubsCount', blank=True, null=True) # Field name made lowercase.
tags = models.CharField(db_column='Tags', max_length=350, blank=True, null=True) # Field name made lowercase.
text = models.CharField(db_column='Text', max_length=-1, blank=True, null=True) # Field name made lowercase.
translated = models.BooleanField(db_column='Translated', blank=True, null=True) # Field name made lowercase.
type = models.CharField(db_column='Type', max_length=50, blank=True, null=True) # Field name made lowercase.
views = models.IntegerField(db_column='Views', blank=True, null=True) # Field name made lowercase.
votesamount = models.IntegerField(db_column='VotesAmount', blank=True, null=True) # Field name made lowercase.
class Meta:
managed = False
db_table = 'community.post'
Está marcado como managed = False, lo que significa que makemigrations y migrate no funcionarán para esta tabla. Omitiendo el nombre de la tabla, producirá una lista larga de módulos, incluyendo las tablas ya creadas con Django previamente.
Artículo
Nancy Martínez · 7 ago, 2019
¡Hola a tod@s!Este artículo es una pequeña descripción general de una herramienta que permitirá entender las clases y su estructura, dentro de los productos de InterSystems: desde IRIS hasta Caché, Ensemble y HealthShare.En resumen, con esta herramienta se visualiza una clase o un paquete completo, se muestran las relaciones que existen entre las clases y proporciona toda la información que se encuentra disponible para los desarrolladores y líderes de equipos sin necesidad examinar el código, utilizando el Studio.Si estás aprendiendo a utilizar los productos de InterSystems, o simplemente estás interesado en aprender algo nuevo sobre las soluciones que ofrece la tecnología de InterSystems, ¡eres más que bienvenido a leer la descripción general de ObjectScript Class Explorer! Introducción a los productos de InterSystemsIRIS (anteriormente conocido como Caché) es una DBMS Base de Datos Multi Modelo. Es posible acceder a los datos mediante consultas SQL o al interactuar con los objetos y procedimientos almacenados por las interfaces que están disponibles para varios lenguajes de programación. Pero la primera opción siempre es desarrollar aplicaciones en el lenguaje nativo e integrado de la DBMS— ObjectScript (COS).Caché es compatible con las clases que se encuentran en el nivel de la DBMS. Existen dos principales tipos de clases: Persistentes (pueden almacenarse en la base de datos) y registradas (no se almacenan en la base de datos y desempeñan el papel de programas y controladores). Además, existen varios tipos de clases especiales: Serial (son clases que pueden integrarse en clases persistentes para crear tipos de datos complejos, como por ejemplo direcciones), DataType (se utiliza para crear tipos de datos definidos por el usuario), Index, View y Stream.Class ExplorerCaché Class Explorer es una herramienta que visualiza la estructura de las clases de Caché como un diagrama, muestra las dependencias que existen entre las clases y toda la información importante, incluido el código de los métodos, consultas, bloques xData, comentarios, documentos de apoyo y palabras clave de varios elementos de las clases.FuncionalidadClass Explorer utiliza una versión extendida del estándar UML para la visualización, debido a que Caché cuenta con un conjunto adicional de entidades que no son compatibles con el estándar UML , pero que son importantes para Caché: consultas, bloques xData, muchas de las palabras clave para los métodos y propiedades (como por ejemplo: System, ZenMethod, Hidden, ProcedureBlock), relaciones padre/ hijo, de uno a muchos, tipos de clase, entre otras.Caché Class Explorer (version 1.14.3) te permitirá hacer lo siguiente:Visualizar la jerarquía de los paquetes, un diagrama de clases o el paquete completo,Editar la apariencia de un diagrama después de visualizarlo,Guardar la imagen actual de un diagrama de clases,Guardar la apariencia actual de un diagrama y recuperarla en el futuro,Realizar búsquedas por cualquier palabra clave que se muestre en un diagrama o árbol de clases,Utilizar la información sobre las herramientas para obtener todos los detalles de las clases, sus propiedades, métodos, parámetros, consultas y bloques xData,Visualizar el código de los métodos, consultas o bloques xData,Activar o desactivar la visualización de cualquiera de los elementos del diagrama, incluidos los iconos gráficosEn la siguiente imagen se puede ver cómo se visualizan las clases en Class Explorer, y así comprender mejor los conceptos mencionados en este artículo. Como ejemplo, veamos el paquete “Cinema” del namespace “SAMPLES”:Descripción general de las funcionesLa barra lateral izquierda contiene un árbol del paquete. Situando el cursor sobre el nombre del paquete y haciendo clic en un botón que aparece en el lado derecho se podrá visualizar el paquete completo. Si se selecciona la clase en el árbol del paquete se representará junto con sus clases vinculadas.Class Explorer puede mostrar varios tipos de dependencias entre las clases:Herencia. Se muestra con una flecha de color blanco que apunta hacia la dirección de la clase que se heredó;“Asociación” o relación entre las clases. Si un campo de alguna de las clases contiene una clase de otro tipo, el generador de diagramas lo mostrará como una relación de asociación;Relaciones padre-hijo y de uno a muchos: contienen las reglas para mantener la integridad de los datos.Si se sitúa el cursor sobre la relación, se resaltarán las propiedades establecidas en ella:Se debe tener en cuenta que Class Explorer no profundizará y no creará dependencias para las clases que se encuentran fuera del paquete actual. Únicamente mostrará las clases que se encuentran en el paquete actual, y si se necesita limitar la profundidad con que Class Explorer realice búsquedas para las clases, se debe utilizar la opción “Nivel de dependencia”:La clase en sí, se muestra como un recuadro que se divide en seis secciones:Nombre de la clase: si posiciona el cursor sobre el nombre de la clase, se podrá saber cuándo fue creada, sus modificaciones, ver los comentarios y todas las palabras clave que se asignaron a la clase. Al hacer doble clic sobre el encabezado de la clase se abrirá su documentación,Parámetros de la clase: todos los parámetros están asignados por tipo, palabras clave y comentarios. Los parámetros en cursivas, al igual que cualquier otra propiedad, contienen información sobre las herramientas y pueden desplazarse,Las propiedades de las clases son similares a las de los parámetros,Métodos: puede hacer clic sobre cualquiera de los métodos para ver su código fuente. La sintaxis de COS se resaltará,Consultas: son similares a los métodos, al hacer clic sobre ellos, se podrá ver su código fuente,Bloques xData: estos bloques contienen principalmente datos de tipo XML. Al hacer clic sobre ellos se mostrará el código fuente con formato en el bloqueDe manera predeterminada, cada clase se visualiza mediante una serie de iconos gráficos. El significado de cada icono puede determinarse al hacer clic en el botón Help que se encuentra en la esquina superior derecha de la pantalla. Si necesita una notación UML más o menos estricta que se muestra de forma predeterminada, así como la visualización de cualquiera de las secciones de la clase, se puede desactivar desde la sección Configuraciones.Si un diagrama es muy grande y no resulta familiar, se puede utilizar la función para buscar diagramas rápidamente. Se resaltarán las clases que contengan cualquier parte de la palabra clave introducida. Para avanzar a la siguiente coincidencia, se presiona Enter o se hace clic nuevamente en el botón de búsqueda:Finalmente, después de hacer todas las ediciones en el diagrama, se eliminarán todas las relaciones innecesarias y los elementos se colocarán en las posiciones correctas para lograr la apariencia deseada, se puede guardar al hacer clic en el botón "Download" que se encuentra en la esquina inferior izquierda: Cuando actives el botón del pin , se guardará la posición de los elementos que se encuentren en el diagrama del conjunto (o de un paquete) de clases actual. Por ejemplo, si selecciona las clases A y B, y después guarda la visualización con el botón del pin, verá exactamente la misma visualización cuando seleccione las clases A y B nuevamente, incluso después de reiniciar el navegador o el equipo. Pero si solamente selecciona la clase A, el diseño será el predeterminado.InstalaciónPara instalar Caché Class Explorer, solamente tendrás que importar la última versión XML del paquete en cualquier namespace. Cuando se complete la importación, notarás que aparece una nueva aplicación web llamada hostname/ClassExplorer/ (la barra que se encuentra al final de la ruta, es necesaria).Instrucciones detalladas sobre la instalaciónDescargar el archivo con la última versión de Caché Class Explorer,Descomprimir el archivo XML llamado Cache/CacheClassExplorer-vX.X.X.xml,Importar el paquete en cualquier namespace mediante alguna de las siguientes formas:Simplemente arrastrando el archivo XML hacia el Studio,Utilizando el Portal de administración del sistema: Explorador del sistema -> Clases -> Importar, y especifique la ruta hacia el archivo local,Utilizando el comando del terminal: do ##class(%Installer.Installer).InstallFromCommandLine(“Path/Installer.cls.xml”),Consultar el registro de importación, si todo se realizó correctamente, se podrá abrir la aplicación web en http://hostname/ClassExplorer/. Si algo salió mal, revisar lo siguiente:Si se tienen los permisos correctos para importar clases hacia este namespace,Si el usuario de la aplicación web tiene suficientes privilegios para acceder a diferentes namespaces,Si aparece el error 404, comprobar si agregó una "/" barra al final de la URL.Algunas capturas de pantalla adicionales[Captura de pantalla 1] Paquete DSVRDemo, desplazamiento del cursor sobre el nombre de la clase.[Captura de pantalla 2] Paquete DataMining, búsqueda de la palabra clave "TreeInput" en el diagrama.[Captura de pantalla 3] Visualización del código del método en la clase JavaDemo.JavaListSample.[Captura de pantalla 4] Visualización del contenido del bloque XData en la clase ClassExplorer.Router.Probad cómo funciona Class Explorer en el namespace estándar SAMPLES: demostración. Y aquí se muestra una evaluación en video del proyecto.Cualquier observación, sugerencia o comentario es bienvenido; podéis dejarlo aquí o en la sección Repositorio de GitHub.¡Espero que os resulte útil!
Artículo
Jose-Tomas Salvador · 14 ago, 2019
La funcionalidad de Sincronización de Objetos no es nueva, estaba presente en Caché, pero quería explorar un poco más en profundidad cómo funciona. Siempre he pensado que la sincronización automática de una base de datos es compleja en sí misma pero, para algunos escenarios muy particulares quizá no sea tan difícil. Así que he considerado un caso de uso muy simple (OK, quizá el caso típico, no descubro nada... pero si es común y funciona, es bueno ). Puedes bajar el código de GitHub y compilarlo en tu sistema, generar automáticamente datos de ejemplo y jugar un poco con ello. Está hecho para InterSystems IRIS pero debería funcionar también en las últimas versiones de Caché y Ensemble.Ahora vayamos al detalle. Mi aplicación de ejemplo, a nivel de clases (lo siento, no hay interfaz de usuario), considera un pequeño modelo de datos donde tenemos Items, Customers, Employees y Orders. Trabajando off-line, si somos comerciales, normalmente limitaremos nuestras operaciones a consultar: Items, Customers y/o Employess (por lo que esos datos los consideramos de solo-lectura); y a añadir o modificar Orders. El registro o modificación de Items, Customers o Employees lo podemos considerar como algo que debe hacerse en el sistema de base de datos MASTER y de ahí transmitido a los sistemas de base de datos CLIENT .Cuando definimos el modelo de clases, tenemos que tener en cuenta que transacciones queremos sincronizar (en nuestro caso Orders) y cuales no. En la definición de las clases debemos añadir Parameter OBJJOURNAL = 1; para indicar que el sistema tiene que mantener la relación de los objetos de dicha clase insertados/borrados/modificados. Igualmente, en el/los sistema(s) cliente, la creación de objetos sucederá en momentos diferentes y, si usamos IDKEYs por defecto, tendremos situaciones en las cuales el mismo objeto (tras la sincronización) tendrá un IDKEY diferente en cada base de datos... Como gestionamos eso? ... Necesitamos una forma de identificar global y univocamente un objeto entre bases de datos... y aquí es cuando el GUID viene en nuestra ayuda. InterSystems IRIS puede generar un ID global unico (Globally Unique ID) para un objeto que puede ser compartido entre sistemas IRIS y todos ellos pueden usarlo para decidir si están tratando o no con el mismo objeto. Hasta aquí bien. Para que una clase pueda generar automáticamente un GUID para cada nuevo objeto, tenemos que incluir Parameter GUIDENABLED = 1; en su definición. Y con esto, todo nuestro trabajo está hecho.En nuestro caso de uso tendremos algo similar a esto (la definición completa en GitHub...aquí recortada): Class SampleApps.Synch.Data.Order Extends (%Persistent,%Populate,%JSON.Adaptor){ /// We don't want to force other classes reference to use %JSON.Adaptor. Then we decide export the /// GUID of referenced objects (by default it will include the JSON of object referenced) Parameter %JSONREFERENCE As STRING [ Constraint = "OBJECT,ID,OID,GUID", Flags = ENUM ] = "GUID"; ///We'll keep track of this class for synchronization (assuming that in off-line mode is not ///allowed by the app to modify master classes Parameter OBJJOURNAL = 1; Parameter GUIDENABLED = 1; ...}Class SampleApps.Synch.Data.Customer Extends (%Persistent, %Populate){ ///This allows the class to be stored with the GUIDs ///Also is a class referenced in Order class which is to be synchronized, ///so this class objects need a GUID to be able to synchronize their references Parameter GUIDENABLED = 1; ...}Class SampleApps.Synch.Data.Item Extends (%Persistent, %Populate){ Parameter GUIDENABLED = 1; ...}Class SampleApps.Synch.Data.Employee Extends (%Persistent,%Populate){ Parameter GUIDENABLED = 1; ...} Como ves, hay una clase: Order; con OBJJOURNAL y GUIDENABLED, y las otras clases sólo tienen GUIDENABLED. ¿Por qué? Porque los objetos de esas clases son referenciadas dentro de cada Order y, aunque no mantenemos sus modificaciones, necesitamos saber que la misma Order referencia a los mismos objetos sin importar en que sistema(s) estemos mirando (IMPORTANTE: si no habilitamos GUID en los objetos referenciados, las Orders serán sincronizadas pero sin ninguna información relacionada a las referencias).OK. Dicho esto, puedes empezar a jugar. He implementado algunas utilidades en SampleApps.Synch.Util para generar datos y ejecutar operaciones básicas de interción/modificación/borrado. También encontrarás una API REST básica (SampleApps.Synch.API.v1.RestLegacy) para poder hacerlo desde un cliente REST o desde ObjectScript indiferentemente.Dispones de más información junto con todo el resto del código del proyecto aqui en GitHub. Puedes clonar el repositorio o descargar un zip con el código fuente. Una vez tengas el código en tu servidor, carga y compila la clase SampleApps.Synch.Config.Installer desde tu terminal (dentro del namespace que elijas), y ejecuta la instalación:TEST>do $system.OBJ.Load("c:/Temp/SampleApps/Synch/Config/Installer.cls","ck")TEST>set args("InstallingFromNS")="TEST"TEST>set args("NamespaceMaster")="CORE"TEST>set args("NamespaceClient")="NODE"TEST>do ##class(SampleApps.Synch.Config.Installer).setup(.args) La mayoría de los argumentos tienen valores por defecto (echa un vistazo a la clase SampleApps.Synch.Config.Installer, pero, como puedes ver en el ejemplo arriba, puedes cambiarlos antes de llamar al método setup).Tras su ejecución, tendrás 2 nuevos namespaces: CORE y NODE (MASTER y CLIENT por defecto si llamas a setup sin argumentos) con datos ya precargados en Orders, Items, Customers y Employees. Ambas bases de datos son idénticas en este punto. Puedes jugar con los servicios REST para cargar nuevos datos, preparar la sincronización de datos de un namespace y después sincronizarlos en el otro. Cualquier conflicto descubierto durante la sincronización será almacenado en SampleApps.Synch.Data.SynchConflict que también puede consultarse a través de un servicio REST (aparte de desde SQL).En GitHub he incluido más información y también ejemplos para llamar a servicios REST para que así puedas empezar a probar facilmente. Simplemente haz click aquí, descarga el código fuente o clone el repositorio y podrás estar probando en 2 minutos.Disfruta!!
Pregunta
Albert Forcadell · 5 mayo, 2023
hola, me es imposible hacer una consulta de forma correcta. he probado con clausulas LIMIT, OVER ... no válidas para Intersystems por lo visto. Tambien probe con HAVING , con TOP, ... incluso con GPT y otras AI, pero nada.
lo siento, pero mi sql no da para mas.
TABLA Comp.AlbLin
COLUMNAS AlbLin.ID , AlbLin.Description , AlbLin.Price , AlbLin.Date
Estoy peleando por una query que me calcule la MEDIA del campo precio AlbLin.Price pero solo de los ultimos/mas recientes 3 registros de fecha
---
i am not able to launch a right instruction in sql , please. LIMIT ... OVER ...no valid for Intersystems. i ve tried all . with HAVING, with TOP ,... paying for Ai and nothing.
my apologises , i am so limited.
TABLE Comp.AlbLin
COLUMNS AlbLin.ID , AlbLin.Description , AlbLin.Price , AlbLin.Date
i fight for a query to get the AVG average of AlbLin.Price for each AlbLin.ID taking only last/recent 3 rows AlbLin.Date
¡Hola Albert! Te agradecería que, para beneficio de todos los usuarios de la comunidad de desarrolladores en español, planteases la pregunta traducida al español si es posible.
Con respecto a tu pregunta, prueba con la siguiente query:
SELECT
a1.ID, AVG(a1.Price)
FROM Comp.AlbLin a1
WHERE a1."Date" in (SELECT TOP 3 a2."Date" FROM Comp.AlbLin a2 WHERE a1.ID = a2.ID ORDER BY a2."Date" DESC )
GROUP BY a1.ID order by a1.ID asc
Entiendo que el campo AlbLin.ID no es único por lo que indicas, por lo que podemos utilizar como criterio la fecha del dato. Te explico un poco la query:
Puedes ver como tenemos dentro del WHERE una subquery que nos extraerá las últimas 3 fechas para cada AlbLin.ID, serán las 3 últimas ya que hemos indicado TOP 3 de una query ordenada por fecha de forma descendiente, así que siempre serán las 3 últimas fechas.
En la SELECT principal hemos sacado el AlbLin.ID que nos servirá como criterio agrupador y hemos usado la función agrupadora AVG para AlbLin.Price.
En la instrucción GROUP BY hemos definido el campo agrupador AlbLin.ID y hemos añadido un ORDER BY, este último no es necesario.
Pues bien, la subquery nos devolverá las 3 últimas fechas que usaremos en la query principal para sólo utilizar aquellos registros relativos al AlbLin.ID que coincidan con esas fechas (la subquery usa dentro de su WHERE el identificador de la query principal).
Prueba la query y coméntanos el resultado.
¿Has podido probar la query que te comenté, Alberto? si, es correcta . y ademas bastante simple cuando las ves. lastima tener que molestar. muy agradecido por la aportacion. es relativamente sencilla , 😅
he intentado ir un poco mas alla , y mejorarla o mas bien complicarla. y he vuelto a ser incapaz de ubicar bien los case when para que funcione.
queria conseguir que si la fecha mas reciente tiene mas de quince dias " ... (a1.FechaLinea > DATE(CURRENT_DATE-15)) ..." solo coja las 2 ultimas fechas . o sea que en lugar de un TOP 3 , sea un TOP 2.
he probado con los CASE WHEN dentro del select y fuera cambiando la instruccion pero no consigo que funcione.
de todas formas , la solucion ofrecida es para mi un gran aporte y cubre casi la totalidad de casos de la consulta. muchas gracias. si , si . acabo de reportar. ¡Nunca molestan vuestras preguntas, Albert! Al revés... gracias por preguntar, para eso estamos, y encantados de poder ayudar :D Pues solo tienes que meter la condición de la subquery entre paréntesis y añadir un And con la condición de la fecha a modo de:
WHERE (date>X AND subquery top 2) OR (date <=X AND subquery top 3) tambien funciona... 😁 . y yo dale que te pego con los CASE. ...
voy a ir desarrollar un poco mas la consulta , a ver si discurro algo mas y no hace falta vuestra atencion. ( seguro que vuelvo , jaja)
vaya ... un placer y muy agradecido de me hayais atendido las consultas tan rapido. ... y tan eficaces.
p.d.
dejo la sentencia completa como ejemplo por si a alguien le sirve de modelo
v.0
SELECT a1.Articulo, a1.DescArticulo, AVG(a1.PrecioCoste)FROM Comp.AlbaranLin a1WHERE a1.FechaLinea in (SELECT TOP 3 a2.FechaLinea FROM Comp.AlbaranLin a2 WHERE a1.Articulo = a2.Articulo ORDER BY a2.FechaLinea DESC ) (*opcional *AND a1.Articulo = '337' AND a1.FechaLinea > DATE(CURRENT_DATE-15) *)GROUP BY a1.Articulo order by a1.Articulo asc ;
v.1
SELECT a1.Articulo, a1.DescArticulo, AVG (a1.PrecioCoste)FROM Comp.AlbaranLin a1WHERE (a1.FechaLinea in (SELECT TOP 3 a2.FechaLinea FROM Comp.AlbaranLin a2 WHERE a1.Articulo = a2.Articulo ORDER BY a2.FechaLinea DESC ) AND a1.Articulo = '337' AND a1.FechaLinea >= DATE(CURRENT_DATE-15))OR(a1.FechaLinea in (SELECT TOP 2 a2.FechaLinea FROM Comp.AlbaranLin a2 WHERE a1.Articulo = a2.Articulo ORDER BY a2.FechaLinea DESC ) AND a1.Articulo = '337' AND a1.FechaLinea < DATE(CURRENT_DATE-15))GROUP BY a1.Articulo order by a1.Articulo asc ; Genial Albert, ¡muchas gracias! Y no te preocupes, para eso estamos. Puedes preguntar todo lo que necesites.
Artículo
Ricardo Paiva · 18 mar, 2021
Demo lista para usar de un servidor FHIR con IRIS for Health 2020.2:
* Transformación HL7v2 al servidor FHIR
* Servidor FHIR que se puede consultar en SQL
### Instalación
Clona este repositorio
```
git clone https://github.com/grongierisc/FHIR-HL7v2-SQL-Demo.git
```
Docker
```
docker-compose up --build -d
```
### Uso
* Puedes utilizar la configuración de postman en misc/fhirhl7v2demo.postman_collection.json
* Utiliza UX en http://localhost:4201
* ***Inicio de sesión/Contraseña***: SuperUser/password
### Cómo utilizar la demostración
3 pasos para utilizarla:
## Importar mensajes HL7v2
Haz clic en la flecha izquierda que está entre IRIS y la ambulancia.
Esto abre las siguientes ventanas:
Desde aquí se pueden importar muestras desde este directorio en el repositorio de Git:
sampleFiles
Elige uno y haz clic en enviar.
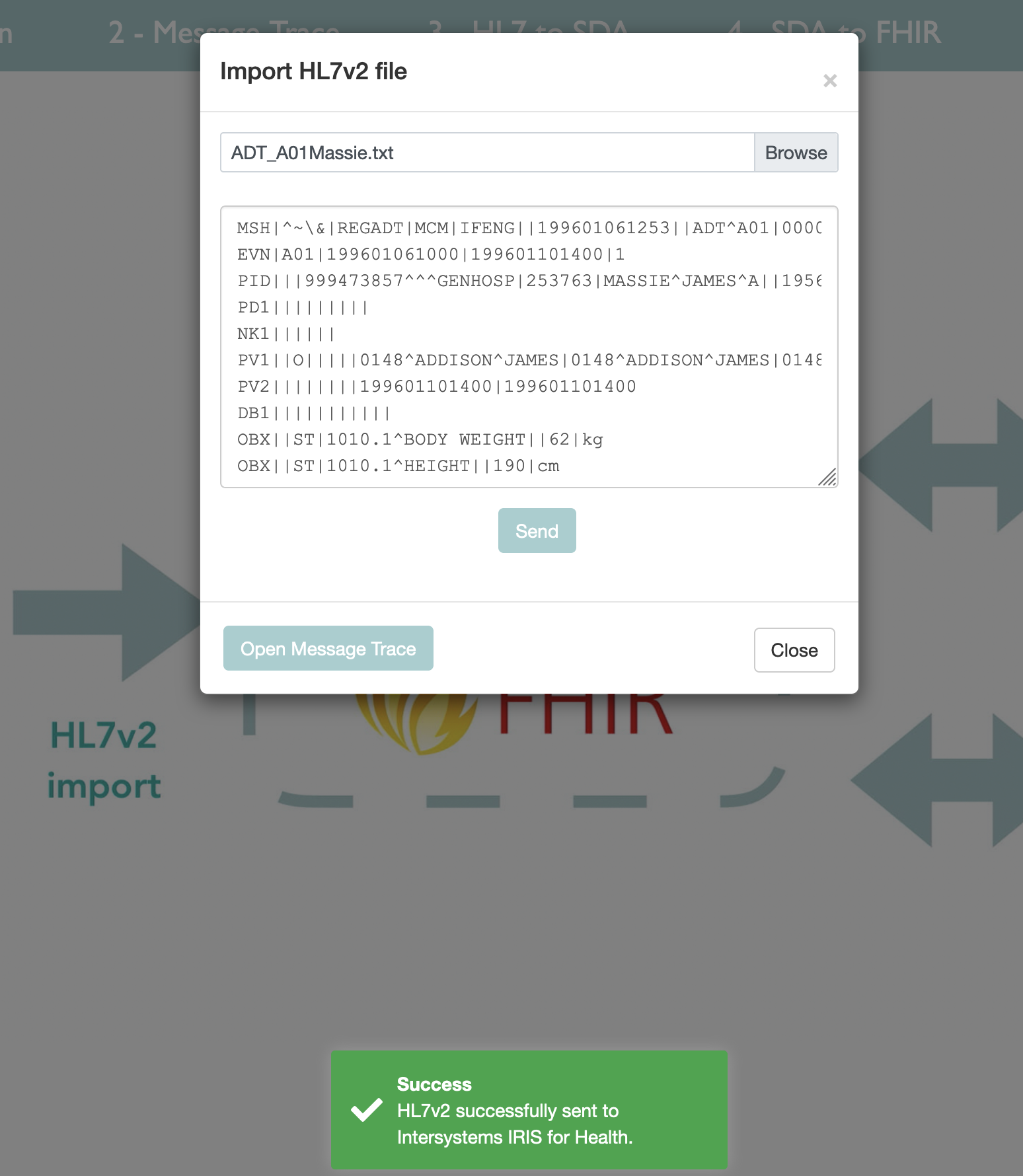
Desde aquí puedes hacer clic en Message Trace:
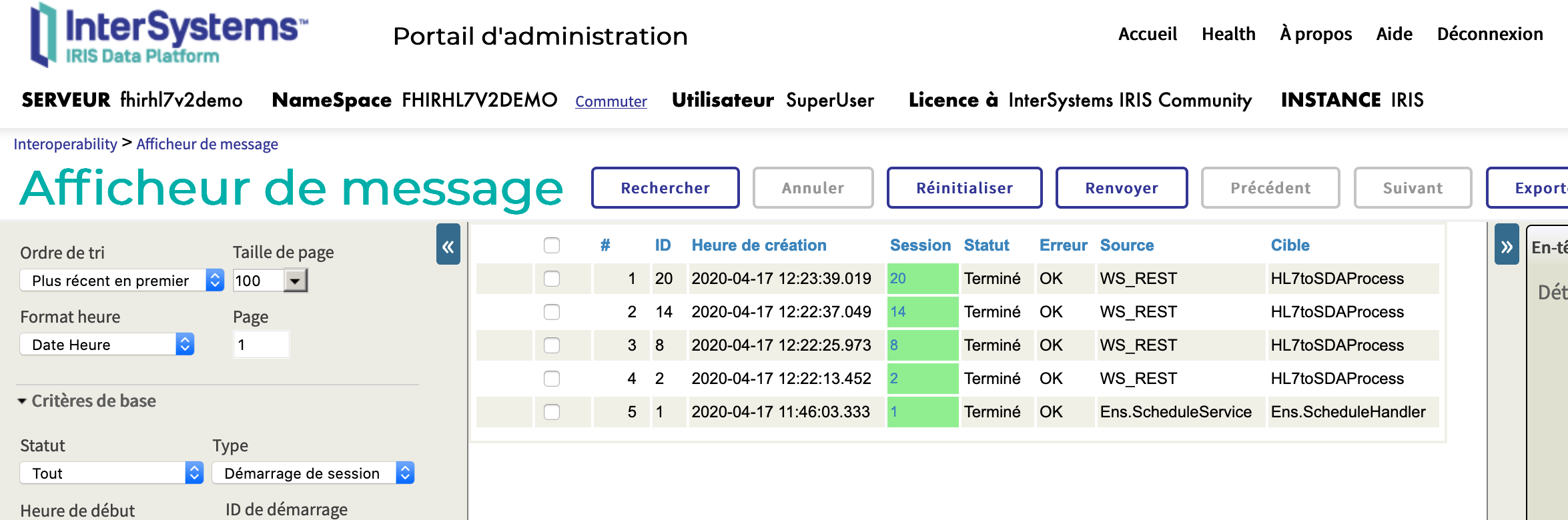
Selecciona el primero:
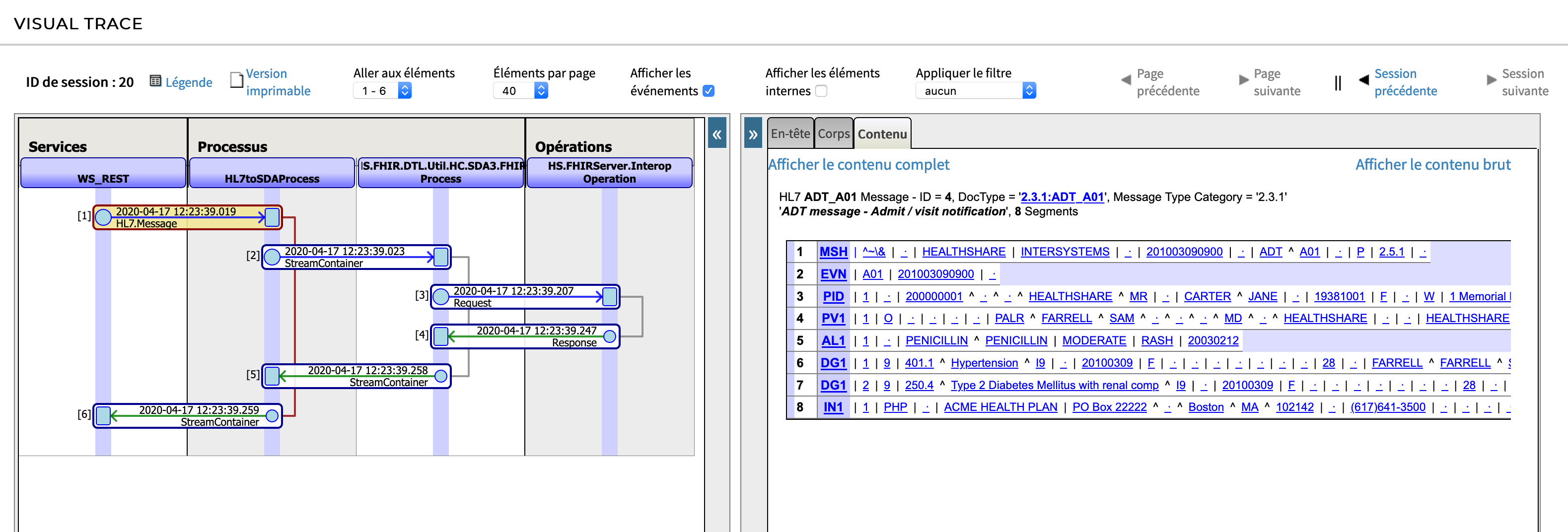
Aquí puedes ver la transformación preparada entre HL7v2, SDA y FHIR.
## Utiliza el cliente FHIR
Haz clic en la flecha entre IRIS y el FHIR client:
El pequeño swagger te da la oportunidad de consultar en FHIR el repositorio lleno desde el mensaje HL7v2 o desde el FHIR client.
Por ejemplo :
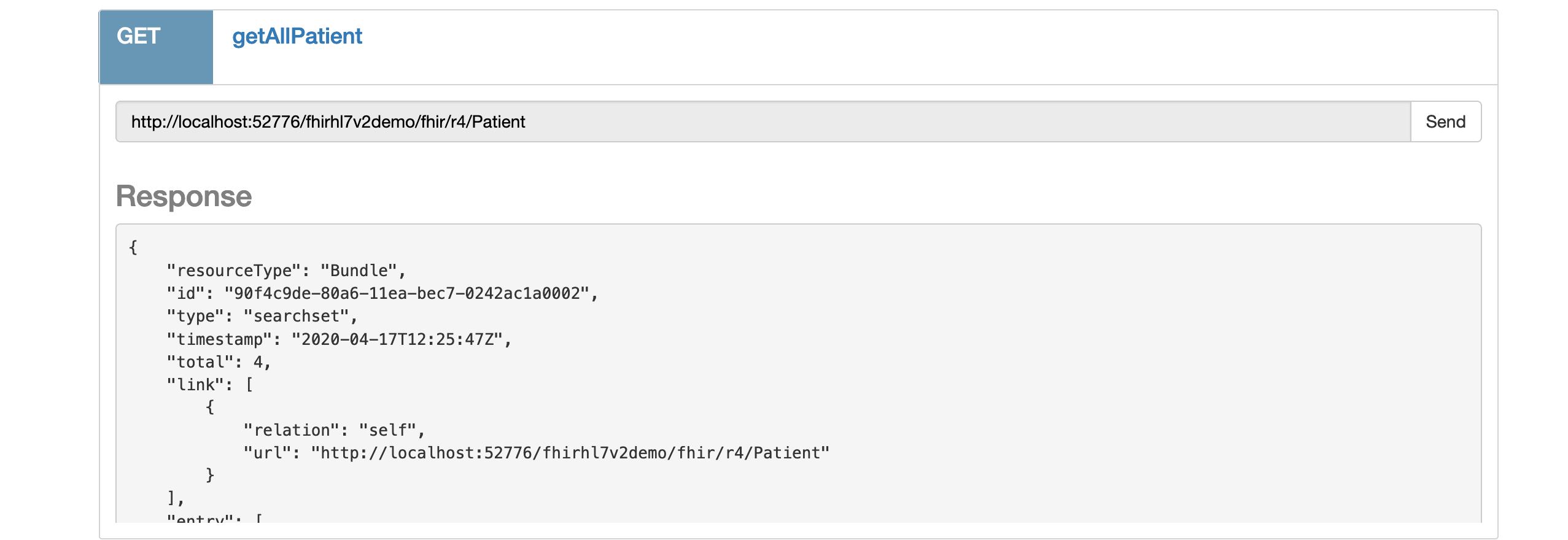
## Utiliza el cliente SQL
Haz clic en la flecha que está entre IRIS y SQL client:
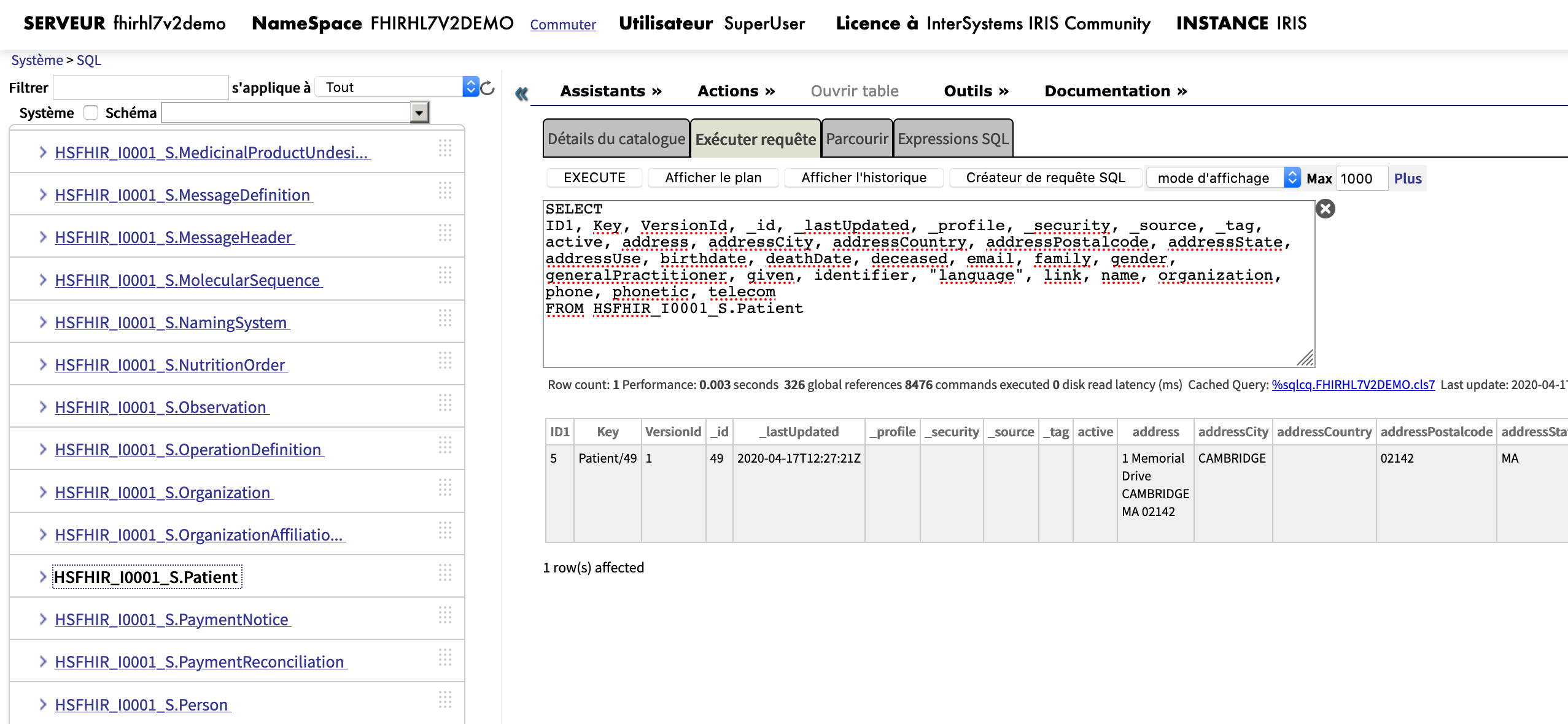
Desde aquí se pueden ver todos los recursos FHIR en una estructura relacional de SQL. Debe quedar claro que esta estructura SQL puede cambiar sin previo aviso. Dicha estructura no está documentada y su uso no tiene el respaldo de InterSystems.