Limpiar filtro
Anuncio
Esther Sanchez · 1 ago, 2022
¡Hola desarrolladores!
Tenemos nuevos artículos súper interesantes para leer y disfrutar este verano, gracias a los maravillosos participantes del 3er Concurso de Artículos Técnicos: Edición Python. Hemos recibido
🌟 12 ARTÍCULOS INCREÍBLES 🌟
Y ya podemos anunciar los ganadores...
Estos han sido los ganadores de cada categoría:
⭐️ Premios de los expertos – los ganadores han sido elegidos por expertos de InterSystems:
🥇 Primer puesto: IRIS Embedded Python with Azure Service Bus (ASB) use case, escrito por @Yaron.Munz8173
🥈 Segundo puesto: Getting known with Django part 1, escrito por @Dmitry.Maslennikov
🥉 Tercer puesto: Introduction to Web Scraping with Embedded Python - Let’s Extract python job’s, escrito por @Rizmaan.Marikar2583
⭐️ Premio de la Comunidad – el ganador es elegido por los miembros de la Comunidad y es el artículo con mayor número de "likes":
🏆 IRIS Embedded Python with Azure Service Bus (ASB) use case, escrito por @Yaron.Munz8173
Y...
⭐️ Queremos recompensar a @Dmitry.Maslennikov por su serie de 3 artículos para el concurso! Recibirá un altavoz inteligente Apple HomePod mini o un lápiz inteligente Apple Pencil.
Damos la enhorabuena a todos los participantes en el Concurso:
@Yuri.Gomes
@Robert.Cemper1003
@Muhammad.Waseem
@Veerarajan.Karunanithi9493
@Renato.Banzai
@Ramil.TK
¡MUCHAS GRACIAS a todos por vuestro esfuerzo y por contribuir en la Comunidad!!!
Los premios están en producción. Contactaremos con los ganadores para enviárselos lo antes posible.
Artículo
Ricardo Paiva · 28 mayo, 2025
Después de que desplegáramos un nuevo contenedor basado en containers.intersystems.com/intersystems/irishealth:2023.1 esta semana, notasteis de repente que el Repositorio FHIR empezó a responder con un Error 500. Esto se debe a violaciones de PROTECT en el nuevo espacio de nombres y base de datos HSSYSLOCALTEMP, utilizado por esta versión de los componentes FHIR de IRIS for Health.
La solución consiste en añadir "%DB_HSSYSLOCALTEMP" a las Aplicaciones Web que gestionan las solicitudes FHIR. Podéis automatizar esto ejecutando el siguiente método de clase en los espacios de nombres que definen estas Aplicaciones Web.
do ##class(HS.HealthConnect.FHIRServer.Upgrade.MethodsV6).AddLOCALTEMPRoleToCSP()
En nuestro caso, eso no fue suficiente. En parte de nuestro código personalizado necesitamos acceder al token Bearer JWT tal como lo envía el cliente, y antes podíamos obtenerlo desde el elemento AdditionalInfo "USER:OAuthToken", que ya no está presente en la versión 2023.6.1.809, como se describe en la siguiente documentación: https://docs.intersystems.com/upgrade/results?product=ifh&versionFrom=2023.1.0&versionTo=2023.1.6&categories=Business%20Intelligence,Cloud,Core,Development%20Tools,Driver%20Technologies,Embedded%20Python,External%20Languages,FHIR,Healthcare%20Interoperability,Interoperability,Machine%20Learning,Mirroring,Monitoring,Natural%20Language%20Processing,SQL,Security,Sharding,Web%20Applications&audience=All&changes=121
Resolvimos este problema añadiendo la siguiente lógica para obtener el token desde la caché de tokens.
$$$ThrowOnError(##class(HS.HC.Util.InfoCache).GetTokenInfo(pInteropRequest.Request.AdditionalInfo.GetAt("USER:TokenId"), .pTokenInfo))
set OAuthToken = pTokenInfo("token_string")
Artículo
David Reche · 23 jul, 2019
¡Hola a tod@s!
Cuando hablo con alguien de perfil técnico por primera vez acerca de InterSystems IRIS, siempre comienzo hablando de que en el centro de todo InterSystems IRIS es una Base de Datos Multimodelo. En mi opinión, esta es la mayor ventaja (desde la visión de Sistemas de Bases de Datos), ya que:
¿Quieres obtener un resumen o partes específicas de tus datos? Usa SQL!
¿Necesitas trabajar de forma intensiva con un registro? Usa Objetos!
¿Quieres establecer un valor y conoces la clave? Piensalo de nuevo. Usa globals!
Y en todos los casos, el dato está almacenado de forma única. ¡Tú eliges la manera en la que quieres acceder al mismo!!
De un primer vistazo es una bonita historia - corta, concisa y con un mensaje; pero cuando se empieza a trabajar con InterSystems IRIS, comienzan a surgir preguntas: ¿Cómo están relacionados las clases, las tablas y los globals? ¿Qué son cada uno para el otro? ¿Cómo se almacenan realmente los datos?
En este artículo voy a tratar de responder estas preguntas y explicar qué está pasando realmente.
Primera parte. Orientación del Modelo.
Los que trabajan con datos tienden a tener un sesgo diferente dependiendo del modelo con el que usualmente trabajan.
Los desarrolladores piensan en objetos. Para ellos, las bases de datos y las tablas son cajas contra las que se interactua vía Guardar/Recuperar (preferiblemente sobre ORM - Object Relational Mapper). Pero la estructura para ellos siempre son objetos (por supuesto esto es principalmente cierto para desarrolladores en lenguajes orientados a objetos - la mayoría de nosotros).
Por otro lado los DBA suelen pensar en los datos como tablas - consecuencia de trabajar con bases de datos relacionales. Los objetos son solo la representación de una fila en este caso.
Como las clases persistentes de InterSystems IRIS también son una tabla que tienen los datos almacenados en globals, creo que es importante aclarar estos conceptos.
Segunda Parte. Ejemplo.
Digamos que creamos la clase persistente Point:
Class try.Point Extends %Persistent [DDLAllowed]
{
Property X;
Property Y;
}
Podríamos igualmente utilizar este DDL para crearla:
CREATE Table try.Point (
X VARCHAR(50),
Y VARCHAR(50))
Y se crearía la misma clase.
Después de la compilación, nuestra nueva clase debería tener una estructura Storage autogenerada que define el mapeo de globals a los datos en las columnas o propiedades:
Storage Default
{
<Data name="PointDefaultData">
<Value name="1">
<Value>%%CLASSNAME</Value>
</Value>
<Value name="2">
<Value>X</Value>
</Value>
<Value name="3">
<Value>Y</Value>
</Value>
</Data>
<DataLocation>^try.PointD</DataLocation>
<DefaultData>PointDefaultData</DefaultData>
<IdLocation>^try.PointD</IdLocation>
<IndexLocation>^try.PointI</IndexLocation>
<StreamLocation>^try.PointS</StreamLocation>
<Type>%Library.CacheStorage</Type>
}
¿Qué está pasando aquí?
Desde abajo hacia arriba (en negrita está lo importante, puedes ignorar el resto por ahora):
Type: tipo de almacenamiento generado. Een nuestro caso este es el tipo de almacenamiento por defecto para las clases persistentes
StreamLocation - nombre del global donde se almacenan los Streams
IndexLocation - nombre del global donde se almacenan los índices
IdLocation - nombre del global donde almacenamos el contador del ID autoincremental
DefaultData - nombre del elemento de almacenamiento XML que define el mapeo entre las columnas/propiedades y el global
DataLocation - nombre del global donde almacenamos los datos
En este momento nuestro DefaulData es PointDefaultData, así que vamos a verlo. En esencia nos dice qué nodo del global almacena qué valor, con la siguiente estructura:
1 - %%CLASSNAME
2 - X
3 - Y
De forma que podemos esperar que nuestro global tenga esta pinta:
^try.PointD(id) = %%CLASSNAME, X, Y
Si sacamos por pantalla el valor del global, inicialmente estará vacío, porque no hemos añadido ningún dato:
zw ^try.PointD
Vamos a añadir un objeto:
set p = ##class(try.Point).%New()
set p.X = 1
set p.Y = 2
write p.%Save()
Revisamos el global de nuevo y ¿qué tenemos?
zw ^try.PointD
^try.PointD=1
^try.PointD(1)=$lb("",1,2)
Como puedes ver, nuestra estructura esperada (%%CLASSNAME, X, Y) está establecida con $lb("",1,2), que corresponde a las propiedades X e Y de nuestro objeto (%%CLASSNAME es una propiedad del sistema, podemos ignorarla por ahora).
Podemos igualmente añadir una nueva fila mediante SQL:
INSERT INTO try.Point (X, Y) VALUES (3,4)
Ahora nuestro global tiene esta pinta:
zw ^try.PointD
^try.PointD=2
^try.PointD(1)=$lb("",1,2)
^try.PointD(2)=$lb("",3,4)
De esta forma, siempre que añadimos datos vía objetos o SQL, éstos son almacenados de acuerdo a la definición del Storage (eEs posible modificar manualmente la definición del Storage - puedes probar tú mismo y ver qué pasa).
Ahora bien, ¿qué pasa cuando queremos ejecutar una consulta SQL?
SELECT * FROM try.Point
Esta consulta se traduce en código ObjectScript, que itera sobre el global definido y puebla las columnas en base a la definición del Storage.
Ahora vamos a por las modificaciones. Borremos todos los datos de la tabla.
DELETE FROM try.Point
Veamos el global después de esto:
zw ^try.PointD
^try.PointD=2
Fijaos que solo el contador del ID se mantiene, de esta forma el siguiente nuevo objeto/fila tendrá el ID=3. Nuestra clase y tabla continúa existiendo.
Pero ¿qué pasa si hacemos?:
DROP TABLE try.Point
Esto destruye nuestra tabla, clase y borra todo el global.
zw ^try.PointD
Espero que siguiendo este ejemplo ahora entiendas mejor cómo los globals, las clases y las tablas se corresponden unos con otros.
Gracias David, el tema de los globals es algo complejo de asimilar cuando tienes a diferentes actores en la vida de un producto, en nuestro caso debemos poner de acuerdo a desarrolladores, gestores de base de datos y administradores de sistema, cada uno buscando la mejor eficiencia de su tiempo, pero que lamentablemente chocan entre ellos.Por mi parte, ahora que estoy centrado en la administración de sistemas creo que estaría bien un artículo sobre las implicaciones a nivel de almacenamiento de los cambios de desarrollo, me explico, en ocasiones algunos servicios reciben actualizaciones, creando nuevas clases, dejando de utilizar otras, cambiando propiedades de otras... esto se realiza mediante la subida de nuevas producciones. Tengo la impresión de que aquellas clases que ya no se usan en la nueva producción, almacenarán datos en caché ad eternum, ¿es correcto?.Del mismo modo, la purga de datos en BBDD grandes se nos antoja lenta, está bien para una tarea noctura pero en ocasiones es necesario realizar una limpieza pues el espacio compromete la estabilidad del sistema. En este caso he buscado y no encuentro información sobre las implicaciones de borrar directamente algunos globals "innecesarios" desde el Portal de Gestión, hablo principalmente de ^Ens_Util.Log , algunos de traza creados por usuarios y otros con datos temporales. ¿es seguro eliminarlos directamente?¿afecta su eliminación a los journals?. Nos ocurre que en ocasiones estos globals que no aportan información consumen varias decenas de gigas en algún día de errores y una vez solventado el error sería necesario eliminarlos. En la actualidad estamos lanzando instrucciones sql para borrar días concretos.Por tanto, ampliando tu artículo creo que estaría bien:* Globals: cuándo, cómo eliminarlos y cómo se recrean.* Globals y su impacto en sistemas en Mirror.*Globals : ¿es posible almacenarlo en otra base de datos diferente?. Gracias por tus comentarios @JoseAntonio.BenitezCreo que no es demasiado práctico contestar a todo dentro del comentario, por lo que estamos trabajando en publicar estos artículos que comentas, los enlazaré como comentario a este articulo para que el que lea estos comentarios pueda seguir el hilo. Adicionalmente creo que hay que explicar como es el proceso de Journal y para qué sirve. Por último será muy útil entender todos los globals de la parte de Interoperabilidad (Ensemble), y esto también merecería un capítulo aparte :-) Este artículo está etiquetado como "Mejores prácticas" ("Best practices")
(Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems).
Anuncio
Esther Sanchez · 1 mar, 2021
¡Hola Comunidad!
En esta publicación, os mostramos los distintos Niveles de la Comunidad de Desarrolladores y de Global Masters, el Programa de Fidelización de InterSystems.
Todos los miembros de Global Masters pueden conseguir diferentes niveles, dependiendo de su participación en la Comunidad de Desarrolladores y de su actividad en Global Masters.
Cada nuevo nivel abre nuevos tipos de retos/tareas y nuevos tipos de premios.
Para subir de nivel, se deben ganar un número de insignias del siguiente nivel. Las insignias se ganan por completar distintos retos en Global Masters.
Ahora hay 6 Niveles:
Insider
Advocate
Specialist
Expert
Ambassador
VIP
➡️ Pon el ratón sobre cada insignia para saber cómo conseguirla.
Niveles
Normas
Nivel Insider
Se empieza con este nivel cuando te das de alta en Global Masters.
Nivel Advocate
Para acceder al siguiente nivel se requieren 2 de estas insignias:
DC Author 1 500 puntos
InterSystems Researcher 500 puntos
DC Commenter300 puntos
DC Problem Solver1 000 puntos
DC Translator100 puntos
Pull RequestContributor500 puntos
InterSystemsOpen Exchange Developer1 000 puntos
DC Recruiter600 puntos
Best PracticesAuthor1 000 puntos
Global Masterof the Month1 000 puntos
Así que, para pasar a este nivel es suficiente con hacer una pregunta, hacer un comentario, invitar a un colega a la Comunidad,... Fácil, ¿no?
Nivel Specialist
El nivel Specialist requiere 3 de estas insignias:
InsightfulCommenter750 puntos
Insightful Author1 500 puntos
Advanced PullRequest Contributor500 puntos/cada PR
Popular Writer600 puntos
Reporter Badge7 500 puntos
CuriousMember2 000 puntos
Masterof Answers4 000 puntos
PopularApp badge2 500 puntos
Bronze OpenExchange Developer10 000 puntos
BronzeRecruiter600 puntos/cada
RecognizableBest Practices Author3 000 puntos
Annual Achievements Badges
DC Best-SellingAuthor
DC Expert
DC Opinion Leader
InterSystemsDeveloperof the Year
InterSystemsApplicationof the Year
No es tan fácil llegar al nivel Specialist, pero es posible!
Nivel Expert
El nivel Expert requiere 4 de estas insignias:
ExpertCommenter1 500 puntos
Expert Author3 000 puntos
Bronze PullRequest Contributor500 puntos/cada PR
NotableWriter2 500 puntos
Blogger Badge15 000 puntos
Thorough Member5 000 puntos
Bronze Masterof Answers8 000 puntos
Bronze Popular App badge5 000 puntos
Silver OpenExchange Developer25 000 puntos
SilverRecruiter600 puntos/cada
Bronze BestPractices Author7 000 puntos
Annual Achievements Badges
Bronze Best-Selling Author
BronzeExpert
BronzeOpinion Leader
Bronze InterSystemsDeveloper of the Year
Bronze InterSystemsApplication of The Year
Es bastante difícil llegar al nivel Expert, pero unos cuantos lo consiguen!
Nivel Ambassador
El nivel Ambassador requiere 4 de estas insignias:
RecognizableCommenter 7 500 puntos
RecognizableAuthor15 000 puntos
Silver PullRequest Contributor500 puntos/cada PR
FamousWriter7 000 puntos
Influencerbadge40 000 puntos
InquisitiveMember15 000 puntos
Silver Masterof Answers20 000 puntos
Silver Popular App badge7 500 puntos
Gold OpenExchange Developer50 000 puntos
Gold Recruiter600 puntos/cada
Silver BestPractices Author10 000 puntos
Annual Achievements Badges
Silver Best-Selling Author
SilverExpert
SilverOpinion Leader
Silver InterSystemsDeveloper of the Year
Silver InterSystemsApplication of The Year
Nivel VIP
El nivel VIP requiere 5 de estas insignias:
PowerfulCommenter15 000 puntos
PowerfulAuthor 30 000 puntos
Gold PullRequest Contributor500 puntos/cada PR
Gold Writer20 000 puntos
Opinion Maker75 000 puntos
SocraticMember30 000 puntos
Gold Masterof Answers40 000 puntos
Gold PopularApp Badge 12 500 puntos
Platinum Popular App badge100 000 puntos
PlatinumRecruiter600 puntos/cada
Gold BestPractices Author15 000 puntos
Annual Achievements Badges
Gold Best-Selling Author
Gold Expert
Gold Opinion Leader
Gold InterSystemsDeveloper of the Year
Gold InterSystemsApplication of The Year
Bronze Advocateof the Year
Silver Advocateof the Year
Gold Advocateof the Year
Este es el nivel "top"! Solo unos pocos lo consiguen! ¿Te animas?
Además... consulta la información adicional sobre Global Masters:
Cómo unirse a Global Masters
Descripción de las insignias de Global Masters
Cambios en Global Masters
Si aún no perteneces al Programa de Fidelización de InterSystems, ¡te puedes dar de alta ahora mismo!
Si tienes alguna duda, puedes dejarnos un comentario en esta publicación y te responderemos al momento.
Artículo
Alberto Fuentes · 9 abr, 2025
Si queréis saber por ejemplo si ya está implementada una clase sobre un tema en concreto, ahora es posible haciendo una simple pregunta en lenguaje natural. Descargad y ejecutad la aplicación https://openexchange.intersystems.com/package/langchain-iris-tool para conocer todo sobre vuestras clases de proyecto en un chat.
Instalación:
$ git clone https://github.com/yurimarx/langchain-iris-tool.git
$ docker-compose build
$ docker-compose up -d
Uso:
1. Abrid la URL [http://localhost:8501](http://localhost:8501).
2. Revisad el botón de Configuración, que se usa para que el Agente se conecte a InterSystems IRIS.
3. Haced preguntas sobre vuestras clases desarrolladas (por ejemplo: ¿Existen clases que hereden de Persistent?).
Herramientas usadas:
Ollama: herramienta para ejecutar modelos (LLM)
Langchain: plataforma para construir agentes de inteligencia artificial.
Streamlit: framework de frontend.
InterSystems IRIS: servidor para responder preguntas sobre su contenido.
Sobre Ollama
Es una solución gratuita y local de modelos de lenguaje (LLM) que permite ejecutar Inteligencia Artificial Generativa con privacidad y seguridad, ya que los datos se procesarán únicamente en vuestras propias instalaciones. El proyecto Ollama es compatible con muchos modelos, incluyendo Mistral, OpenAI, DeepSeek y otros, ejecutándolos localmente. Este paquete utiliza Ollama a través de Docker Compose con el modelo Mistral.
ollama:
image: ollama/ollama:latest
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: ["gpu"]
count: all # Adjust count for the number of GPUs you want to use
ports:
- 11434:11434
volumes:
- ./model_files:/model_files
- .:/code
- ./ollama:/root/.ollama
container_name: ollama_iris
pull_policy: always
tty: true
entrypoint: ["/bin/sh", "/model_files/run_ollama.sh"] # Loading the finetuned Mistral with the GGUF file
restart: always
environment:
- OLLAMA_KEEP_ALIVE=24h
- OLLAMA_HOST=0.0.0.0
Sobre Langchain:
Langchain es un framework para crear aplicaciones de Inteligencia Artificial Generativa (GenAI) de forma sencilla. Langchain introduce el concepto de herramienta (tool), que son complementos (plug-ins) utilizados en aplicaciones RAG para ampliar las capacidades de los modelos de lenguaje (LLMs). Esta aplicación implementa una herramienta de Langchain para realizar preguntas sobre gestión y desarrollo en vuestro servidor IRIS.
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.document_loaders import CSVLoader
from langchain.embeddings import OllamaEmbeddings
from langchain_iris import IRISVector
def get_insights(question, csv_file, iris_conn, collection_name):
# Load and process the CSV data
loader = CSVLoader(csv_file)
documents = loader.load()
llm = Ollama(
base_url="http://ollama:11434",
model="mistral",
temperature=0,
)
# Create embeddings
embeddings = OllamaEmbeddings(model="mistral", base_url="http://ollama:11434", temperature=0)
db = IRISVector.from_documents(
embedding=embeddings,
documents=documents,
connection_string=iris_conn,
collection_name=collection_name,
pre_delete_collection=True
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever())
return qa({"query": question})
Sobre Streamlit:
La solución Streamlit se utiliza para desarrollar frontends con el lenguaje Python. Esta aplicación incluye una aplicación de chat en Streamlit para interactuar con Ollama, Langchain e IRIS y obtener respuestas relevantes.
import pandas as pd
import streamlit as st
from sqlalchemy import create_engine
import langchain_helper as lch
username = "_system"
password = "SYS"
hostname = "iris"
port = 51972
webport = 52773
namespace = "USER"
st.set_page_config(page_title="InterSystems IRIS Classes Demo", page_icon="📜")
st.title("Langchain IRIS Classes Chat")
with st.popover("Settings"):
with st.spinner(text="Connecting to the IRIS classes"):
engine = create_engine("iris://" + username + ":" + password + "@" + hostname + ":" + str(port) + "/" + namespace)
connection = engine.connect()
query = 'select * from %Dictionary.ClassDefinition where substring(ID,1,1) <> \'%\' and Copyright is null'
df = pd.read_sql(query, con=connection)
df.to_csv("classes.csv")
username = st.text_input("Username:", username)
password = st.text_input("Password:", password)
hostname = st.text_input("Hostname:", hostname)
port = int(st.text_input("Port:", port))
webport = int(st.text_input("Web port:", webport))
namespace = st.text_input("Namespace:", namespace)
# User query input
query = st.text_input(label="Enter your query")
# Submit button
if st.button(label="Ask IRIS Classes", type="primary"):
with st.spinner(text="Generating response"):
iris_conn_str = f"iris://{username}:{password}@{hostname}:{port}/{namespace}"
response = lch.get_insights(query, "classes.csv", iris_conn=iris_conn_str, collection_name="classes")
st.write(response['result'])
Artículo
Bernardo Linarez · 8 oct, 2019
¡Hola a tod@s!
En este artículo me gustaría destacar la importancia de utilizar el Tiempo Universal Coordinado (UTC) para el registro del horario en todos los sistemas y aplicaciones. Especialmente si está desarrollando aplicaciones con un alcance mundial.
Quienes trabajen en ENSEMBLE sabrán que cualquier registro del horario se guarda como la hora correspondiente al UTC. Otros seguramente saben que las funciones de conversión $ZDATETIME y $ZDATETIMEH tienen un parámetro de control-3 , el cual actúa de una manera muy diferente al resto, ya que transforma una cadena con formato $HOROLOG en otra cadena con formato $HOROLOG. Una es la hora local y la otra corresponde al UTC http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fzdatetime#RCOS_fzdatetime_dformat
UTC son las siglas de "Tiempo Universal Coordinado" y originalmente se le llamaba así al Tiempo Medio de Greenwich (GMT). Sin embargo, la hora en Greenwich sigue las reglas del horario de verano británico. El UTC no considera estas reglas y le da al horario una serie de valores con crecimiento uniforme continuo.
De modo que estos cambios desde o hacia el horario de verano ya son una buena razón para alejarse del horario local cuando se realicen cálculos. En caso de que realice una copia de seguridad de sus registros, éstas pueden tardar unos 20 minutos. Si tiene la suerte de hacerlo justo en el momento en que cambia el horario en marzo, la copia de seguridad de su registro mostrará 80 minutos de duración. No muy agradable. Pero durante el cambio hacia el horario de invierno es muy raro que la copia de seguridad muestre -40 minutos.
Si únicamente se trata de un registro, esto podría ser aceptable. Si piensa en que el Administrador de tareas inicie los procesos con intervalos de tiempo específicos entre sí, esto al final causaría algún problema.
La aplicación en la que me enfrenté con este problema fue un calendario que tenía un único servidor, con usuarios distribuidos de manera global. El problema fue sincronizar las citas entre las diferentes zonas horarias y mostrar la hora que fuera más adecuada para todos los participantes en sus respectivas zonas horarias.Como esto (en ese momento) se basó en ZEN, el método más obvio fue preguntar al navegador cuál es su zona horaria local en el momento de iniciar sesión. Los usuarios que no iniciaron sesión tuvieron su zona horaria predeterminada. No hay mucha ciencia en esto.
PERO imaginemos la siguiente situación:
Usted planea realizar una llamada telefónica con su cliente. Cuando llega el momento de la llamada que programó, casualmente ha viajado al "Global Summit" de InterSystems y se encuentra muy lejos de su casa, en una zona horaria diferente. Lo correcto sería que recibiera su recordatorio a tiempo.Esto necesitaría una compensación temporal por el desfase horario que hay respecto a la hora que predeterminó desde su casa para la llamada.
Siguiente: El servidor de su calendario tiene una copia de seguridad oculta en una zona horaria diferente.
Ahora puede tener hasta 5 registros locales diferentes para el horario:- hora del servidor- hora de la copia de seguridad- su hora local- la hora local del lugar en donde vive- la hora local de sus clientes.
Mezclar las zonas horarias y las reglas del horario de verano podría convertirse en un enorme caos si utiliza cualquier otra cosa que no sea el UTC como el único registro válido para almacenar el horario.Estoy seguro de que los profesionales que viven en países grandes y que trabajan a través de varias zonas horarias lo saben, pero sobre todo los europeos agradecen una recomendación sobre este tema. Si su empresa o la de su cliente se extiende por varios países (al utilizar con éxito los productos de InterSystems), se encontrará los problemas con el horario más rápidamente de lo que le gustaría.
Artículo
Esther Sanchez · 30 jun, 2021
¡Hola desarrolladores!
En este artículo, me gustaría mostraros cómo aprovechar algunas de las opciones y funcionalidades de la Comunidad, para aprovecharla al máximo y aprender todo lo posible de los expertos en la tecnología de InterSystems!
¡Echa un vistazo a estos sencillos pasos para convertirte en un super usuario de la Comunidad!
Sigue a los miembros de la Comunidad que te interesen
Puedes seguir a cualquier miembro de la Comunidad del que te interese el contenido que publica. Para seguirle, solo tienes que hacer clic en su nombre y accederás a su perfil. En la barra lateral de la derecha, haz clic en el botón "Seguir" y recibirás una notificación por email cada vez que publique algo (un artículo, una pregunta, un anuncio...) en la Comunidad.
También, dentro del menú principal en la página de inicio de la Comunidad, puedes hacer clic en "Miembros" y buscar a una persona en concreto, o a las personas con más visualizaciones de sus publicaciones... para empezar a seguirles.
Sigue las etiquetas que te interesen
Todas las etiquetas con las que se describen las publicaciones de la Comunidad se encuentran en el menú "Publicaciones" en la página de inicio de la Comunidad, aquí:
Si te interesa un tema en concreto, puedes buscar su etiqueta en el listado de Etiquetas, seleccionarla y hacer clic en el botón "Seguir" que aparece a su lado. Cuando sigues una etiqueta, recibirás en tu correo electrónico todas las publicaciones que tengan esa etiqueta.
Puede ser muy útil seguir las etiquetas "Mejores prácticas" o "Consejos y trucos".
Sigue las publicaciones que te interesen
También puedes seguir las publicaciones que te interesen. Así, recibirás en tu correo electrónico los comentarios que obtenga esa publicación, o si se publica una segunda parte, o cualquier otra acción relacionada con la publicación a la que te suscribes.
Para seguir una publicación, solo tienes que hacer clic en la campana situada debajo de cada publicación:
-> ¿Cómo sé qué miembros, etiquetas y publicaciones sigo?
Para saber los miembros, las etiquetas y las publicaciones a las que sigues, solo tienes que ir a tu cuenta, en la parte superior derecha de la Comunidad:
y después ir a "Suscripciones" en la columna de la izquierda.
En la parte de abajo de esa página hay un cuadro con tres pestañas - cada una muestra los miembros, las etiquetas y las publicaciones que sigues. Por ejemplo, yo sigo a David Reche y las etiquetas "Mejores prácticas" y "Consejos y trucos":
Nota.- si quieres seguir etiquetas o miembros en otros idiomas, aparecerán en tu perfil de la Comunidad en ese idioma. Para acceder a él, tienes que ir al selector de idiomas de la Comunidad, en la parte superior derecha, al lado de tu cuenta; haz clic en ES para desplegar los distintos idiomas, y luego haz clic en el idioma en el que quieres seguir etiquetas, miembros o publicaciones:
Accederás a la Comunidad en ese idioma y, desde ahí puedes repetir los pasos anteriores para empezar a seguir miembros, etiquetas y publicaciones en otros idiomas.
Añade publicaciones a favoritos
Si te gusta mucho una publicación y te puede resultar útil consultarla de vez en cuando, puedes añadirla a tu listado de publicaciones favoritas donde la encontrarás siempre que la necesites, de forma rápida y sencilla.
Para añadir una publicación a tu lista de favoritos, solo tienes que hacer clic en la estrella situada debajo de cada publicación:
Y para acceder a tu listado de favoritos, solo tienes que ir a tu cuenta:
y después ir a "Favoritos" en la columna de la izquierda. Ahí estarán todas tus publicaciones guardadas.
Así que ya podéis empezar a usar todas las funcionalidades que ofrece la Comunidad de Desarrolladores, para convertiros en expertos en la tecnología de InterSystems!
Si tenéis alguna duda sobre cómo funciona la Comunidad de Desarrolladores o queréis compartir algún consejo sobre cómo aprender mejor en ella, dejad vuestros comentarios más abajo. ¡Os leemos!
Artículo
Ricardo Paiva · 20 ene, 2020
¡Hola Comunidad!
Este breve documento describe los pasos para iniciar IRIS community edition usando Docker en MAC. Para quienes sean nuevos con Docker, primero se explica cómo instalar Docker y ejecutar algunos comandos básicos necesarios para poner en funcionamiento IRIS community edition. Los usuarios con más experiencia en Docker pueden saltarse esa parte.
Obtener Docker Desktop para MAC. Éste se puede descargar desde Docker Hub, pero revise primero todos los requerimientos antes de descargarlo para estar seguro de que funcionará correctamente. Puede encontrar las instrucciones y el enlace de descarga aquí: https://docs.docker.com/docker-for-mac/install/ Las instalaciones de Docker en Windows requieren Docker Toolbox, ya que Docker no puede ejecutarse de forma nativa en Windows. Docker Toolbox crea una máquina virtual sobre la que los usuarios de Windows pueden ejecutar Docker. Los usuarios de Windows deben seguir las instrucciones del sitio web de Docker: https://hub.docker.com/editions/community/docker-ce-desktop-windows
Pruebe con Docker. El primer comando lógico es determinar qué imágenes de docker se encuentran en el repositorio local. En el terminal de Mac, escriba: docker images. En esta etapa no encontrará nada, pero podrá ver los siguientes encabezados: Repository, Tag, Image ID, Created y Size. Ahora, para ejecutar un contenedor de prueba, escriba lo siguiente en la línea de comandos: docker run busybox:1.24 echo “hello world”. Como la imagen de busybox no se encontró en el repositorio de docker, se "extrajo" (pull) del hub docker, y el comando echo se ejecutó en el contenedor, para imprimir "hola mundo" en la línea de comandos. Ahora pruebe a ejecutar docker images otra vez. Ahora debería ver la imagen de busybox en el repositorio local. Al usar Docker, es importante especificar tanto el nombre de la imagen como la etiqueta, separándolas con dos puntos. Esto permite a docker saber qué versión de la imagen ejecutar (p. ej. busybox:1.24). Cuando hay un contenedor local, no se volverá a descargar.
Pruebe a ejecutar otro comando en la imagen de Docker. Escriba docker run busybox:1.24 ls /. Debería ver un listado de los directorios y archivos en la raíz del contenedor.
Al ejecutar un contenedor, hay dos opciones importantes. La marca -I inicia un contenedor interactivo, y la marca -t crea un pseudo TTY que adjunta stdin y stdout. Escriba esto: docker run -i -t busybox:1.24. Ahora podrá ejecutar comandos en el intérprete del contenedor, incluyendo añadir archivos. Si escribe exit, saldrá del contenedor y lo apagará. Perderá cualquier archivo creado mientras estuviera en el contenedor.
Los contenedores normalmente se ejecutan en segundo plano (de forma no interactiva). La marca -d, que significa "detach" (separar) ejecuta el contenedor en modo "separado". Escriba este comando: docker run -d busybox:1.24 sleep 1000. Docker devuelve inmediatamente el id del contenedor, y el contenedor se está ejecutando. Para verificarlo, escriba docker ps. Esto mostrará qué contenedores se están ejecutando, lo que en nuestro caso es este único contenedor. Para ver los contenedores que se están ejecutando y que se han ejecutado anteriormente, escriba docker ps -a. Para eliminar un contenedor cuando sale, escriba docker run –rm busybox:1.23 sleep 1. El contenedor se ejecutará pero no aparecerá en el historial que se muestra al usar docker ps -a.
Docker genera "nombres" extraños de contenedores al ejecutar contenedores. Para especificar el nombre que queremos que Docker genere, debemos usar la opción –name. Escriba docker run –-name micontenedor busybox:1.24. Ahora, al usar docker ps -a, podremos ver que el nombre del contenedor es micontenedor.
Docker ofrece una útil función para obtener detalles sobre información de bajo nivel acerca de contenedores como IPAddress y Ports. Escriba docker inspect IDdeContenedor (sustituya IDdeContenedor con uno de los ID de contenedores de docker ps -a).
A menudo, los contenedores ejecutan procesos que "escuchan" en un puerto específico. Para comunicarse con el puerto del contenedor desde el host, debe mapear el puerto del host al contenedor. El formato del comando es -p puerto_host: puerto_contenedor. Si se ejecuta un contenedor de docker localmente, la dirección IP del contenedor es "localhost". En Windows puede ser 127.0.0.1. Un comando útil para resolver errores es consultar el archivo de registro del contenedor. Puede hacer esto fácilmente con el comando docker logs containerId (sustituya ID_contenedor con los ID de los contenedores de docker ps -a)
Los contenedores están hechos de capas. Se comienza con la capa base y se agregan capas adicionales. Docker ofrece el comando history para listar las capas de un contenedor. Escriba docker history busybox:1.24
Docker puede hacer mucho más, incluyendo construir imágenes más complejas con el comando "commit" o un Dockerfile (consulte https://docs.docker.com/ ). Esta breve introducción a Docker ofrece lo básico para poner en funcionamiento el contenedor de IRIS community.
Puesta en funcionamiento del contenedor IRIS
Puede encontrar las instrucciones para usar el contenedor Docker para IRIS Community Edition en: https://hub.docker.com/_/intersystems-iris-data-platform/plans/222f869e-567c-4928-b572-eb6a29706fbd?tab=instructions
Debemos explicar un comando adicional de Docker para configurar el archivo de contraseñas. Los contenedores de Docker no pueden acceder directamente al sistema de archivos del host. El contenedor debe montar un directorio que se pone a su disposición desde el host. Inicialmente, Docker para Mac pone a disposición los siguientes directorios para enlazar/montar en contenedores de Docker: /Users, /Volumes, /private, /tmp. Para almacenar contraseñas fuera del contenedor (recuerde que todos los archivos escritos en el contenedor desaparecerán al salir), necesitamos crear un archivo en /Users/suNombreDeUsuario/external/password.txt. Montar un volumen usa la marca -v y luego el nombre de host, seguido por dos puntos y luego el directorio del contenedor.
Ahora ejecute el contenedor con el siguiente comando: docker run --name irisdb -v ~/external:/external -d store/intersystems/iris:2019.1.0.511.0-community --password-file /external/password.txt. Después de ejecutar este comando y verificar el estado con el comando docker ps -a, debería ver lo siguiente tras un par de minutos:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d74f2b7a48d5 store/intersystems/iris:2019.1.0.511.0-community "/iris-main --passwo…" 2 minutes ago Up 2 minutes (healthy) irisdb
Conéctese al contenedor recién iniciado mediante el comando: docker exec -it irisdb iris session iris. Esta conexión nos permite iniciar una sesión de Iris. El nombre de usuario es SuperUser y la contraseña es SYS. Ahora IRIS le solicitará cambiar la contraseña, como se muestra a continuación:
Node: d74f2b7a48d5, Instance: IRIS
Username: SuperUser
Password: ***
Password change required
Please enter a new password
Password: *********
Please retype your new password
Password: *********
USER>
Ahora podemos escribir comandos directamente en la línea de comandos del terminal IRIS. Como por ejemplo:
USER>set firstname = "Peter"
USER>write firstname
Peter
USER>
Podemos escribir comandos interactivos, ¿pero cómo iniciamos el portal de administración?Normalmente, para hacer esto, abriríamos un navegador y escribiríamos la dirección: http://localhost:52773/csp/sys/UtilHome.csp, pero cuando lo hacemos, se muestra un mensaje de error y el sitio del host local rechaza la conexión. ¿Recuerda la sección sobre mapeo de puertos y cómo los contenedores están aislados de la red externa sin ellos? Debemos mapear dos puertos, el puerto predeterminado de superserver de IRIS en 51773, y el puerto de administración en 52773.
En el caso anterior, primero detenga el proceso de línea de comandos escribiendo Halt. Luego, detenga el contenedor con: docker stop [containerid]
Volvamos a poner este contenedor en funcionamiento con mapeo de puertos: docker run -p 51773:51773 -p 52773:52773 -v ~/external:/external -d store/intersystems/iris:2019.1.0.511.0-community --password-file /external/password.txt
Si ahora abrimos una ventana del navegador con la dirección http://localhost:52773/csp/sys/UtilHome.csp, deberíamos acceder al portal de administración.
A pesar de que logramos usar el archivo de contraseñas en el sistema host, no pudimos mantener el cambio de contraseña que hicimos antes. ¿Por qué no? Debemos indicar a IRIS el directorio donde guardar sus ajustes de configuración persistentes. Es necesario agregar una marca --env ISC_DATA_DIRECTORY=/external/iconfig.
Así, el comando completo es: docker run -p 51773:51773 -p 52773:52773 -v ~/external:/external --env ISC_DATA_DIRECTORY=/external/ifconfig -d store/intersystems/iris:2019.1.0.511.0-community --password-file /external/password.txt
En este punto, no debería tener que cambiar la contraseña del portal de administración que definió inicialmente.
La cadena del comando es difícil de recordar, y otro método es almacenarlo en un archivo que puede utilizar una utilidad de docker relacionada, llamado Docker-compose. El archivo es de tipo yaml o yml, y debe nombrarse docker-compose. El archivo docker-compose ofrece varias formas de configurar cualquier cantidad de contenedores y sus dependencias. Sin embargo, para nuestro objetivo alcanza con un archivo más simple. Aquí están los contenidos (debe nombrar al archivo docker-compose.yml):
version: '3'
services:
I iris:
image: store/intersystems/iris:2019.1.0.511.0-community
ports:
- "51773:51773"
- "52773:52773"
volumes:
- ~/external:/external
environment:
- ISC_DATA_DIRECTORY=/external/ifconfig
entrypoint: /iris-main --password-file /external/password.txt
Tenga en cuenta el parecido con la línea de comandos con unos pocos añadidos. Primero, la versión del archivo docker-compose es la "3". Tenemos un servicio llamado "iris" u otro nombre a elección. La imagen, los puertos, los volúmenes y el entorno son autoexplicativos. La última línea, "entrypoint", es el programa que se ejecuta (incluyendo las opciones, en este caso la ubicación del archivo de contraseñas).
Si ahora escribimos docker-compose up -d. El contenedor se gira hacia arriba igual que antes. Para detener el contenedor, escriba docker-compose down.
Puede encontrar más información sobre las opciones de Docker-compose en: https://docs.docker.com/compose/
Anuncio
David Reche · 16 mar, 2020
Este mensaje contiene cinco Avisos recientes sobre HealthShare.
Estos avisos también se encuentran en la página de Alertas y Avisos de Productos de InterSystems
Aviso: Gap in medications display if generic names not included
Aviso: Updated the Clinical Viewer so that silent encounters do not display
Aviso: Corrected gap in custom lab charts not displaying all results in Clinical Viewer
Aviso: Residual Locks on Late Update
Aviso: Incorrect HealthShare Mirror Upgrade Documentation could lead to Data Integrity issues
Si tenéis alguna pregunta sobre estos avisos, contactad por favor con el Centro de Soporte Internacional (WRC).
March 11, 2020 – Advisory: Gap in medications display if generic names not included
InterSystems has corrected a defect affecting how medications are displayed in the Clinical Viewer, when the generic name is not provided.
This problem exists for:
HealthShare Information Exchange 2018.1
HealthShare Unified Care Record 2019.1
This defect occurs when incoming medication data does not include the generic name within the Unified Care Record and subsequently is not displaying the Clinical Viewer. This has been corrected as of 2019.1.2. This can be resolved by requesting an Ad hoc with the dev key below.
The correction for this defect is identified as dev key WRS1026 and will be included in all future product releases. It is also available via Ad hoc change file (patch) or full kit distribution by contacting the Worldwide Response Center (WRC).
If you have any questions regarding this advisory, please contact the WRC.
March 11, 2020 – Advisory: Updated the Clinical Viewer so that silent encounters do not display
InterSystems has corrected a defect affecting silent encounters in the Clinical Viewer.
This problem exists for:
HealthShare Information Exchange 2018.1
HealthShare Unified Care Record 2019.1
The Unified Care Record creates a silent encounter when incoming data is not associated with an encounter. The defect is that these silent encounters were displaying within the Clinical Viewer, when they should not. This has been corrected as of 2019.1.2. Customers using 2018.1 and 2019.1 can request an ad hoc with the dev keys below.
If customers have not upgraded to HealthShare Information Exchange 2018.1 or Unified Care Record 2019.1, this defect is not present. The Unified Care Record 2019.1.2 release has fixed this defect.
The correction for this defect is identified as dev keys WRS1027, WRS1052 and WRS1067, which will be included in all future product releases. It is also available via Ad hoc change file (patch) or full kit distribution by contacting the Worldwide Response Center (WRC).
If you have any questions regarding this advisory, please contact the WRC.
March 11, 2020 – Advisory: Corrected gap in custom lab charts not displaying all results in Clinical Viewer
InterSystems has corrected a defect affecting custom lab charts.
This problem exists for:
HealthShare Information Exchange 2018.1 HealthShare Unified Care Record 2019.1
This defect occurs when a Unified Care Record customer has created a custom lab chart where not all incoming lab data is tagged with the "lab" category in SDA. This can be resolved by requesting an ad hoc with the dev key below.
If customers have not upgraded to HealthShare Information Exchange 2018.1 or Unified Care Record 2019.1, this defect is not present. The Unified Care Record 2019.1.2 release has fixed this defect.
The correction for this defect is identified as WRS1025 which will be included in all future product releases. It is also available via Ad hoc change file (patch) or full kit distribution by contacting the Worldwide Response Center (WRC).
If you have any questions regarding this advisory, please contact the WRC.
March 11, 2020 – Advisory: Residual Locks on Late Update
InterSystems has corrected a defect when the InactiveMRNHandlingMode is set to Late Update.
This problem exists for:
HealthShare Unified Care Record 2019.1
This defect occurs when the InactiveMRNHandlingMode in the HS.Gateway.ECR.Manager is set to Late Update. In rare situations where the Late Update code is triggered, locks on an MRN can fail to be released. This can result in messages becoming stuck in the ECR Manager.
The correction for this defect is identified as dev key MCZ110 and included in all product releases from Unified Care Record 2019.1.1 onwards. It is also available via Ad hoc change file (patch) or full kit distribution by contacting the Worldwide Response Center (WRC).
If you have any questions regarding this advisory, please contact the WRC.
March 11, 2020 – Advisory: Incorrect HealthShare Mirror Upgrade Documentation could lead to Data Integrity issues
InterSystems has corrected a defect in the steps needed to upgrade a mirrored HealthShare environment.
This problem exists for:
All versions of HealthShare Information Exchange, Unified Care Record, Patient Index, Health Insight, or Personal Community that support mirroring prior to version 2019.2.
This does not affect any versions of Health Connect or IRIS for Health.
In previous versions, the HealthShare mirror upgrade procedure was written in a way that minimized system downtime. Specifically, the mirror upgrade instructions allowed customers to continue processing new data until after the backup mirror member was already successfully upgraded and running the new version. Due to changes in the data model between versions, the recommendation now is to stop processing new data immediately upon beginning the upgrade procedure.
If customers were to follow the previously documented mirror upgrade procedure, it could cause an issue where new data comes in using the data model from the previous version, but then gets mirrored to a backup member without going through the proper conversion steps.
For more information, please see the 2019.2 mirror upgrade documentation.
With each upgrade, it is important to review and follow the upgrade instructions included for the version. The new procedure of turning off data feeds at the beginning of the upgrade should be followed for all upgrades, including those to previous versions such as 2019.1 or 2018.1. The documentation for these version has been updated.
Customers upgrading their mirrored environments should NOT reference the documentation available with their current version. Instead, they should reference the HealthShare 2019.2 online documentation for the correct set of instructions, specifically the section titled Upgrading a Unified Care Record Mirror.
There are no code changes related to this Advisory and an Ad hoc is not required.
If you have any questions regarding this advisory, please contact the Worldwide Response Center (WRC).
Anuncio
David Reche · 30 ene, 2020
¡Hola a tod@s!
Ya está disponible la versión de prueba 2020.1 de HealthShare Health Connect.
Los kits para la instalación, las imágenes del contenedor y las licencias de evaluación están disponibles en la página de descargas para pruebas del Centro de Soporte Internacional (WRC).
El número de compilación de estas versiones es 2020.1.0.199.0. (Nota: número actualizado de 197 a 199 el 12/2/20)
HealthShare Health Connect 2020.1 incluye muchas funcionalidades nuevas:
Healthcare Interoperability
FHIR R4 Support
HL7 Productivity Tools
API Management
InterSystems API Manager
Open API/Swagger Specification-First REST Development
New Look in the Management Portal
SQL Enhancements
Universal Query Cache
Interoperability Production Enhancements
New Framework for Coding Interoperability Business Hosts in Java and .NET
Port Authority for Monitoring Port Usage in Interoperability Productions
X12 Validation Enhancements
Enhanced DTL Support for X12
X12 Import X12 Schemas from XSD Files
MQTT Adapters
Infrastructure and Cloud Deployment Improvements
New Automatic Configuration Customization
Analytics Enhancements
Selective Cube Build
PowerBI Connector
Pivot Table Preview
Other Enhancements and Efficiency Improvements
El borrador de la documentación está disponible aquí:
Documentación de Health Connect 2020.1
Las plataformas en las que Health Connect 2020.1 está soportada para producción y desarrollo se detallan en el Documento de plataformas soportadas.
Artículo
Mathew Lambert · 26 ene, 2021
En los recientes trabajos de benchmarking a gran escala, observamos un tiempo excesivo de uso del CPU %sys que afectó negativamente en la escalabilidad de la aplicación.
**Problema**
Encontramos que gran parte del tiempo se pasó llamando a la llamada _localtime()_ del sistema, debido a que la variable de entorno TZ no estaba configurada. Se creó una rutina de prueba sencilla para confirmar la observación, y las diferencias entre el tiempo transcurrido y los recursos que necesitó la CPU con la variable TZ vs. cuando TZ no estaba establecida, fueron extraordinarios. Se descubrió que el uso hereditario de las llamadas _stat()_ de sistema hacia /etc/local_time desde _localtime()_ es muy costoso cuando la variable TZ no está establecida.
**Recomendación**
InterSystems recomienda encarecidamente que se confirme en cualquier sistema que tenga Linux instalado, ya sea en x86 o Linux on Power, que la variable de entorno TZ está configurada adecuadamente, para obtener un rendimiento óptimo. Para más información, consulta: "man tzset".
La versión de prueba de Caché 2016.1 contiene optimizaciones relacionadas con las funciones de fecha y hora, y las pruebas iniciales indican importantes mejoras. A continuación, se muestran ejemplos de salidas, resultado de probar las nuevas llamadas a funciones internas en un bucle con Linux on Power, donde en ambos casos TZ \*no\* se establece:
Antes de Caché 2016.1 FT:
real 0m22.60s
user 0m1.64s
sys 0m20.89s
Con Caché 2016.1 FT:
real 0m0.40s
user 0m0.37s
sys 0m0.00s
Publica tus comentarios sobre cualquier experiencia que hayas tenido con tu aplicación, relacionada con la variable de entorno TZ, y también sobre el impacto que la versión de prueba de Caché 2016.1 tiene con o sin la variable TZ definida.
Pregunta
Héctor Mancilla · 5 mar, 2021
Hola buen día a todos.
quería saber si existe alguna forma de cambiar el nombre un reporte excel. estas son las propiedades y parámetros de la clase:
/// Nombre de clase de la aplicación a la que pertenece este informe.
Parameter APPLICATION;
Parameter REPORTNAME;
Property RenderTimeOut As %ZEN.Datatype.integer [ InitialExpression = -1 ];
Property ID As %String(ZENURL = "id");
Parameter XSLTMODE = "server";
Property Title(ZENURL = "title");
Principalmente estoy colocando la URI en un anchor en HTML para poder descargar, pero el atributo 'download' en el tag no hace el trabajo, por lo cual quiero hacer el trabajo en la URI misma.
Saludos Hola Hector, la verdad es que no entiendo bien que quieres hacer. Puedes darnos más detalles Hola Hector,
Si lo entiendo bien, estas hablando de ZEN Reports. Ten en cuenta que es una funcionalidad deprecada en Intersystems IRIS, donde se siguen soportando lo Zen reports ya desarrollados con anterioridad, pero se recomienda migrarlos a "InterSystemt Reports" documentado aquí:
https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_reports
En cuanto a la pregunta, parece que puedes sobrescribir el valor del parametro de clase REPORTNAME con un valor de parametro de URL en la petición de Report "?ReportName=MiInforme":
Esto es el código en %ZEN.Report.reportPage que usa el parametr de URL si esta definido:
//JSL4724
set reportnameurlparam = $get(%request.Data("ReportName",1))
set reportname=$s(reportnameurlparam'="":reportnameurlparam,..#REPORTNAME'="":..#REPORTNAME,1:..%ClassName(1))
Lo puedes probar?
Saludos,PYD Muchas gracias por su respuesta, me ayudó mucho!
Artículo
Muhammad Waseem · 9 nov, 2021
En mi artículo anterior, expliqué los pasos para conectarse a Caché desde Appeon PowerBuilder usando ODBC.
En este artículo, mostraré cómo recuperar datos de Caché con Appeon PowerBuilder (https://www.appeon.com/products/powerbuilder) utilizando ODBC.Estoy usando Company.cls de Samples-Data (https://github.com/intersystems/Samples-Data/tree/master/cls/Sample)
Así que comencemos:
Paso 1 : En primer lugar, debemos establecer una conexión. (https://community.intersystems.com/post/connecting-cach%C3%A9-appeon-powerbuilder-using-odbc)
Paso 2 : Necesitamos crear un datawindow object (objeto de ventana de datos) que se vinculará a la clase Company.
En el menú File (Archivo), selecciona New (Nuevo) y después el objeto Grid (cuadrícula) en la pestaña DataWindow (Ventana de datos).
Paso 3 : Selecciona SQL Select de la lista de Data Source (Fuente de datos).
Paso 4 : Selecciona sample.company de la lista de Tables (Tablas).
Paso 5 : Selecciona las columnas deseadas de la lista de columnas y haz clic en Return.
Paso 6 : Esto abrirá una vista de diseño. Guarda datawindow (ventana de datos) como d_company después de los ajustes deseados.
Paso 7 : En window control, añade datawindow object (objeto ventana de datos) d_company, que ya creamos, al datawindow control.
Paso 8 : Ahora todo lo que necesitamos es llamar a la función de control de ventana de datos Retrieve () después de configurar el objeto de transacción..
Eso es todo.
A continuación muestro la captura de pantalla final después de recuperar los datos de Caché con Appeon PowerBuilder utilizando ODBC.
Gracias.
Artículo
Eduardo Anglada · 29 mar, 2022
¡Hola a todos!
Hoy quiero hablar sobre nuestro proyecto y utilizar el tema del conjunto de datos para el concurso.
Nuestra intención nunca fue ser unos gestores de datos, sobre todo porque a veces nuestros preciosos datos significan mucho para nosotros, pero no para el resto del mundo.

Queremos ir un paso más allá y permitir que los usuarios encuentren el conjunto de datos perfecto para satisfacer sus necesidades.
Nuestro proyecto es un puente entre la comunidad de la Ciencia de Datos y la Comunidad de Desarrolladores, utilizando InterSystems IRIS para lograr esta misión.
La imagen que aparece a continuación es la página inicial para vosotros. Se puede buscar cualquier tema y ver los conjuntos de datos relacionados con él.
Solo hay que hacer clic en el icono de la lupa al lado de la mascota de Socrata, aparecerá la barra de búsqueda y ahí se puede buscar cualquier tema.
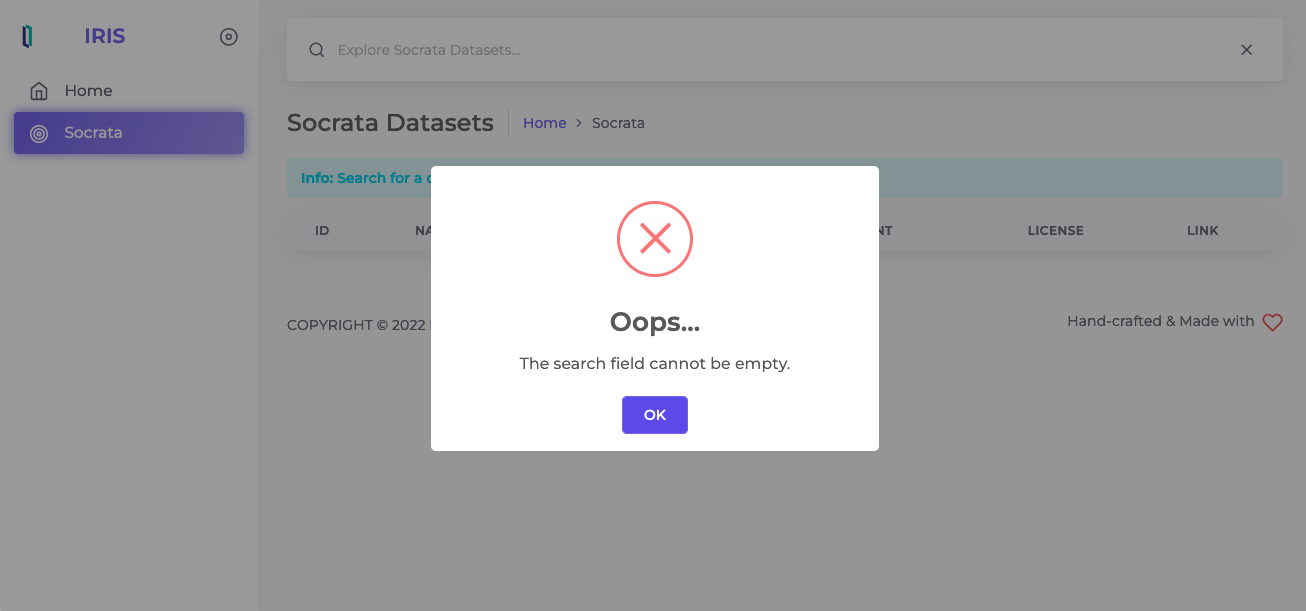
Pero recordad que es obligatorio buscar algo, no se puede buscar "nada". Si no se escribe nada, aparecerá una imagen de alerta similar a esta:
Si se busca un tema específico, se completará la tabla de datos con los conjuntos de datos relacionados con él.
Este es un video de demostración, que explica cómo elegir un conjunto de datos, buscar los detalles, bajarlo e instalarlo.
¡Espero que os resulte útil!
Artículo
Alberto Fuentes · 1 sep, 2022
¡Hola desarrolladores!
Quizá os hayáis encontrado con escenarios donde no tenéis que implementar un repositorio FHIR, sino por ejemplo reenviar peticiones FHIR, gestionar las respuestas y tal vez realizar modificaciones o extraer algunos valores por el camino. Aquí encontraréis algunos ejemplos que pueden implementarse con *InterSystems IRIS For Health* o *HealthShare Health Connect*.
En estos ejemplos he utilizado producciones de interoperabilidad con el [FHIR Interoperability Adapter](https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=HXFHIR_fhir_adapter) y los mensajes tipo `HS.FHIRServer.Interop.Request`.
Si por el contrario estáis interesados en implementar un repositorio FHIR, no dejéis de ver el [Webinar](https://comunidadintersystems.com/webinar-comienza-a-trabajar-con-fhir) que hicimos en su día.
Un primer escenario podría ser tener que construir una petición FHIR de cero quizá a partir de un fichero o tal vez una consulta SQL y a continuación reenviarlo a un servicio FHIR externo:
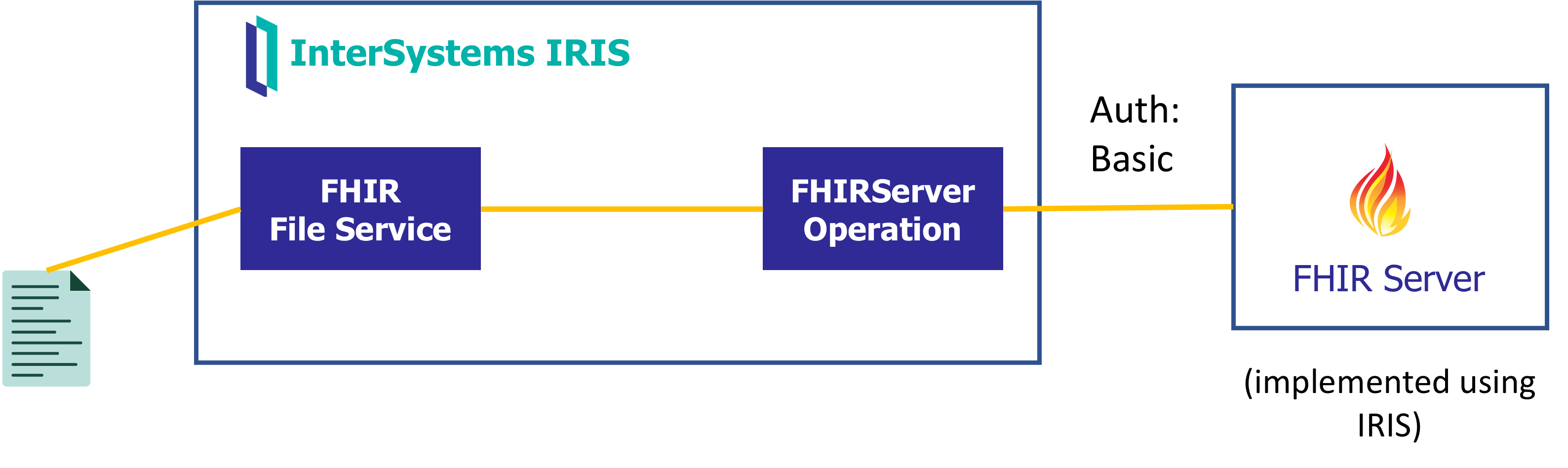
Otro escenario podría ser hacer de pasarela de peticiones / respuestas FHIR contra un repositorio externo, gestionando el paso de tokens OAuth.
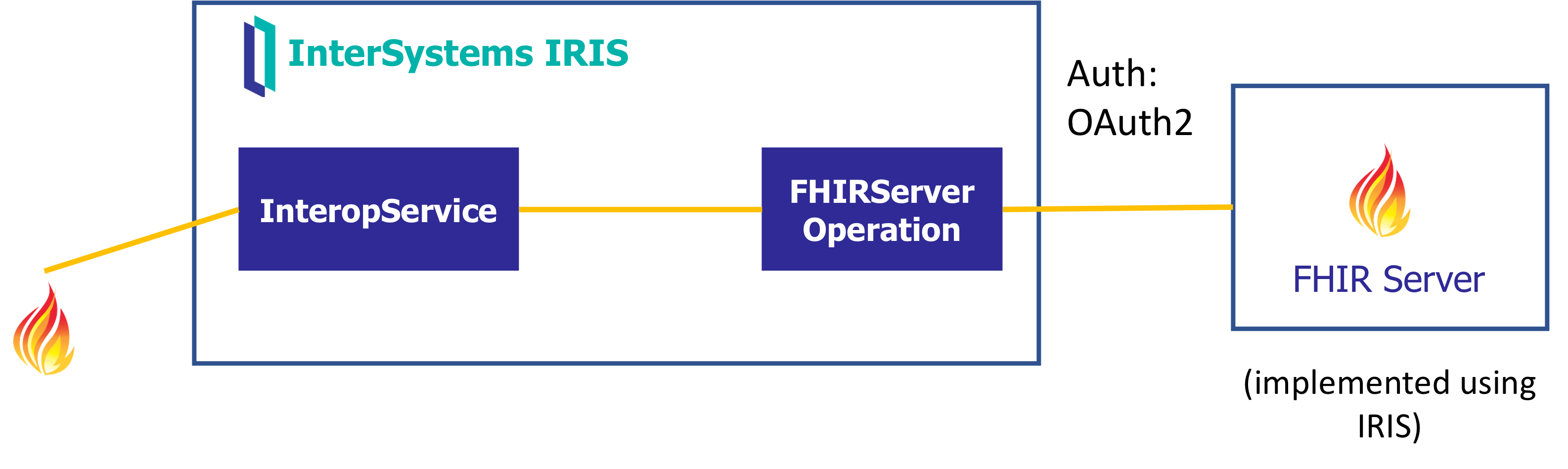
Y finalmente podríamos pensar quizá en recibir peticiones FHIR para reenviarlas a un servicio FHIR externo, pero pudiendo extraer cierta información o manipulando algunos campos el camino.
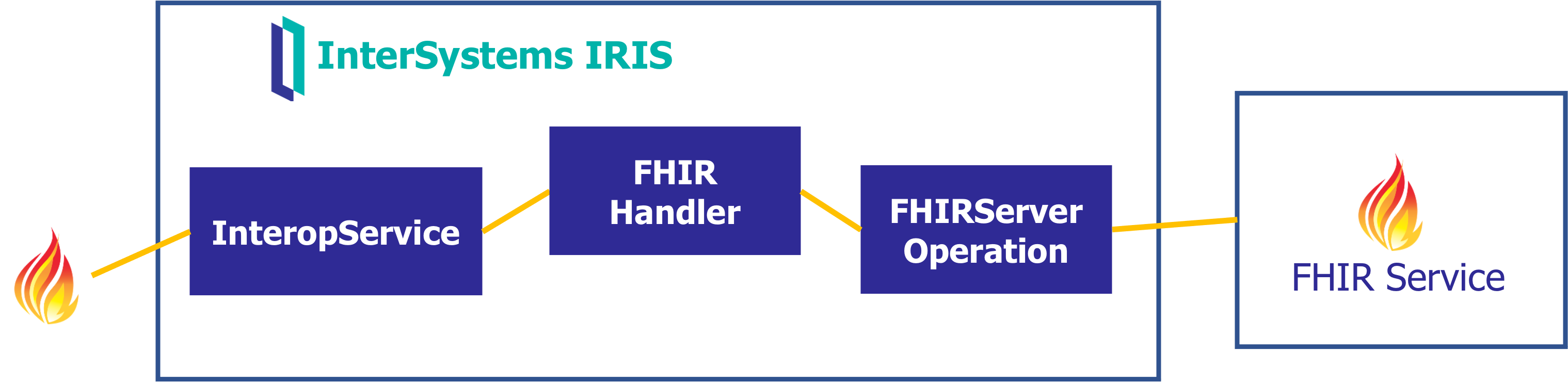
Los detalles de la implementación los encontraréis en la aplicación Open Exchange :)
¡Espero que os sirva!