Limpiar filtro
Artículo
Esther Sanchez · 6 jun, 2023
¡Hola Comunidad!
Estoy segura de que a muchos de vosotros os hubiera encantado asistir al Global Summit 2023, pero no habéis podido por una razón u otra. Por eso haré un resumen de cada día aquí en Florida, empezando por el domingo y el lunes.
Aunque la ceremonia de inauguración oficial no era hasta el domingo por la tarde, había muchas actividades interesantes antes del inicio de la Convención. Algunas de las más destacadas, especialmente para los aficionados a los deportes, fueron los torneos de golf y de fútbol. No puedo comentar nada del fútbol porque no estuve allí, aunque me contaron que fue muy interesante. Y si alguno de vosotros estuvo en el torneo, podéis contarnos vuestra experiencia y/o añadir fotos en los comentarios!). Yo os puedo hablar del torneo de golf 😊
Empezó a las 6 (!) de la mañana y continuó hasta las 2 de la tarde. Al principio, el cielo estaba nublado e incluso llovió un rato. Pero un par de horas después, el sol apareció y hasta hizo falta usar el protector solar.
Para hacerlo incluso más interesante, la fauna local decidió salir a jugar también.
Después de anunciar los ganadores de cada torneo y comer, volvimos al hotel para asistir a otros eventos.
Por ejemplo, por la tarde hubo un evento para mujeres.
Lo que nos llevó a la actividad principal del domingo - ¡la recepción de bienvenida! Fue el mejor momento para reencontrarse con caras conocidas y volver a hablar con colegas y amigos.
Por ejemplo, estuve con @Muhammad.Waseem y @Dmitry.Maslennikov, moderadores de la Comunidad en inglés:
Y con @Lorenzo.Scalese, @Dmitry.Maslennikov y @Guillaume.Rongier7183, de la Comunidad en francés:
Y esto fue todo el día "previo". ¡Lo más importante empezaba el lunes!
El Presidente de InterSystems, Terry Ragon, inauguró el Global Summit 2023. En su discurso, recordó a todos que cualquier empresa de éxito tiene que innovar para seguir siendo relevante. ¡E InterSystems es una de esas empresas!
Además, felicitó a todos por el 45 aniversario de InterSystems y el 30 aniversario de los Global Summits! ¿No es increíble? No sé vosotros, pero yo ni había nacido cuando se fundó la empresa!
Tras el discurso inaugural, las primeras ponencias estaban dedicadas a la atención sanitaria. @Donald.Woodlock, entre otras cosas, habló sobre IA y cómo puede acercar a los desarrolladores a los clientes y no al revés.
Después de la comida, todos nos dispersamos en diferentes sesiones, charlas, reuniones etc. Yo volví al stand de la Comunidad de Desarrolladores en el "Tech Exchange".
Si estás en el Global Summit, no te olvides de pasarte por aquí - te daré encantada algún regalito. Y si conoces a alguien que aún no pertenece a la Comunidad, anímale a venir y a recoger su regalo 😉
Estar en el stand de la Comunidad me ha permitido conocer a mucha gente nueva y encontrarme con otros moderadores que se han pasado por aquí, como @Guillaume.Rongier7183 y @Dmitry.Maslennikov
@Lorenzo.Scalese, @Dmitry.Maslennikov y @Francisco.López1549
Si estás interesado en la presentación que se proyecta detrás de nosotros, es esta:
Además, estar en el área "Tech Exchange" significa que puedo asistir a todas las presentaciones que se hacen allí. Puedo aprender de contenedores, por ejemplo 😉
Y tras este ajetreado día, nos dirigimos a la cena y las demos.
Jugamos a algunos juegos y lo pasamos muy bien.
Y esto ha sido todo durante los dos primeros días del Global Summit 2023.
¡Estad atentos a las próximas crónicas! 😁
Pregunta
Ignacio Valdes · 1 dic, 2019
Cuando impiezo una google cloud docker container la port es 52773 pero quiero tener port 9100 9101 tambien. Yo veo en documentos que no es posible cambiarlo ante que esta andado. Que hago? -- IV Los puertos por defecto de IRIS son 52773 (web) y 51773 (tcp superport).
Cuando ejecutas el contenedor Docker puedes elegir cómo exponer estos puertos en tu máquina local para que puedas acceder.
Por ejemplo, si quieres utilizar los puertos 9100 y 9101 que comentas puedes hacer:
docker run --name iris -p 9100:52773 -p 9101:51773 store/intersystems/iris-community:2019.4.0.379.0
De esa forma, tendrías disponible el Portal de Gestión en http://localhost:9100/csp/sys/UtilHome.csp
Puedes echar un vistazo a la documentación o al Container Bootcamp que se hizo para el Global Summit.
Anuncio
Esther Sanchez · 31 mar, 2022
¡Hola Comunidad!
Hemos grabado el webinar que hicimos ayer y lo hemos subido al canal de YouTube de la Comunidad de Desarrolladores en español. Si os perdisteis el webinar o lo queréis volver a ver con más detalle, ya está disponible la grabación!
Eduardo Anglada mostró toda la potencia de Python, el nuevo lenguaje de programación añadido a IRIS. Explicó cómo crear datos anónimos, desarrollar cuadros de mando interactivos... ¡y muchas cosas más! Por eso, si queréis conocer la nueva funcionalidad de InterSystems IRIS, ¡no os perdáis el vídeo!
⏯ Explorando las nuevas funcionalidades de IRIS: Python Embebido
Por cierto, en las listas de reproducción del canal de YouTube de la Comunidad de Desarrolladores en español podéis ver todos los webinars que hemos realizado (¡ya llevamos diecisiete!), varios tutoriales, trucos, demos...
¡Echadle un ojo y dadle al play! ▶️
Anuncio
Esther Sanchez · 12 jul, 2021
¡Hola desarrolladores!
Os invitamos a un nuevo webinar en español: "Continuando con ObjectScript - Persistencia e Integración", el lunes 19 de julio, a las 4:00 PM (CEST).
En este webinar continuaremos introduciendo ObjectScript, el lenguaje de programación de InterSystems. Trabajaremos con Clases Persistentes y comenzaremos a trabajar con Producciones para integrar sistemas.
Es un webinar dirigido a programadores que empiezan a utilizar ObjectScript y también a aquellos que quieren revisar conceptos.
Como en el anterior webinar de ObjectScript, haremos una ginkana en directo para demostrar lo aprendido. ¡Y los tres primeros clasificados ganarán varios premios!
¡Os esperamos!
➡️ Podéis registraros aquí >>
El próximo lunes es el webinar de ObjectScript.
Además de aprender, pasaremos un rato muy divertido jugando a un juego de preguntas y respuestas online sobre lo explicado en el webinar. Competiremos unos contra otros y el podio final mostrará a los ganadores!
¡Apúntate antes de que se te olvide! :D
Empieza la cuenta atrás... ¡hoy es el webinar!
¡Os esperamos!
Artículo
Eduardo Anglada · 30 mar, 2022
¡Hola desarrolladores!
Para el concurso de Opendataset he desarrollado una aplicación, en formato docker, que utiliza InterSystems IRIS y Openflights Dataset en un contenedor y un segundo contenedor con Apache Zeppelin. Puedes encontrar los detalles aquí:
Con esto, se puede consultar el conjunto de datos de Opendflights desde Apache Zepplin sin necesidad de realizar ninguna configuración. Los contenedores están en hub.docker por lo que se puede utilizar de forma muy sencilla.
Si observamos el panel de control de Docker, veremos que hay un grupo llamado **openflights_demo**:
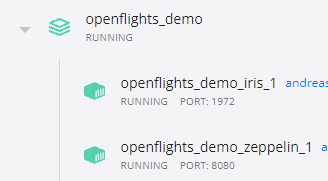
Apache Zeppelin está disponible por medio de:
http://localhost:8080
Como puedes ver en la captura de pantalla, el puerto de la base de datos también está expuesto, así que puedes conectar IRIS directamente como te guste.
Además, echa un vistazo al súper complejo y sofisticado video de youtube! ;-)
Para conectar el sonido, recomiendo un dispositivo Dolby Atmos ;-)
Artículo
Nancy Martínez · 18 ene, 2023
En la Comunidad de Desarrolladores hay muchos artículos interesantes que muestran cómo utilizar Jupyter e InterSystems IRIS juntos, y os animo a echarles un vistazo - al final de esta publicación tenéis un enlace a los artículos.
Este es otro de esos artículos. La diferencia con los otros está en la sencillez. ¿Solo quieres iniciar un contenedor en el que Jupyter ya está conectado a una instancia de IRIS? ¡Entonces esto es para ti!
Solo con ejecutar `docker-compose up` ya podrás acceder a un entorno de trabajo con un par de ejemplos.
No quiero estropear la sencillez, así que probadlo.

Más artículos sobre IRIS y Jupyter:
* En español: [Artículos sobre IRIS y Jupyter](https://es.community.intersystems.com/smartsearch?search=jupyter&type=articles&sort=0&members=&typesearchuser=users)
* En inglés: [Jupyter+IRIS Articles](https://community.intersystems.com/smartsearch?search=jupyter&type=articles&sort=0&members=&typesearchuser=users)
Artículo
Ricardo Paiva · 18 ene, 2023
Schematron es un lenguaje de validación basado en reglas para hacer aserciones/afirmaciones sobre la presencia o ausencia de ciertos patrones en documentos XML. Un Schematron se refiere a una colección de una o más reglas que contienen pruebas. Los Schematron están escritos en una forma de XML, lo que los hace relativamente fáciles de inspeccionar, comprender y escribir para todos, incluso los que no son programadores.
Esencialmente, un Schematron realiza dos acciones en secuencia:
Encuentra nodos de contexto de interés en el documento. Un "nodo de contexto" puede ser un elemento de un tipo particular o un elemento específico en un lugar determinado del documento, un atributo o un valor de atributo. Por ejemplo, supone que quieres verificar si la suma de los elementos <Percent> dentro de cada un nodo contexto es de 100%. En este caso, el nodo de contexto sería el elemento <Total>. Para cada uno de esos nodos de interés, comprueba si una declaración específica es verdadera o falsa. Por ejemplo, puede tener una regla escrita para responder a la pregunta "¿Es la suma total de 100%?".
El recurso idóneo para buscar más detalle sobre el tema sería: https://www.schematron.com/. Para nosotros lo que importa es que podamos validar nuestro documento XML en base a una definición Schematron. Para ello hay que tener en cuenta que hay múltiples proyectos open source con implementaciones de Schematron para XSLT. Uno de los más interesantes lo tenéis disponible en https://github.com/schxslt/schxslt.git.
En este artículo se pretende apalancar las capacidades de Python disponibles en InterSystems IRIS (for Health) o HealthShare (Health Connect).
Para ello necesitamos una instancia de InterSystems IRIS o HealthShare Health Connect. Para nuestro ejemplo usaremos un contenedor con la última community edition de InterSystems IRIS for Health. Hemos de arrancar la instancia publicando las puertas default y mapeando el directorio corriente a la carpeta durable en el container.
$ docker run --name iris4health -d --publish 51773:51773 --publish 52773:52773 --volume $(pwd):/durable containers.intersystems.com/intersystems/irishealth-community:2022.3.0.589.0
Ahora que ya tenemos nuestra instancia en ejecución podremos arrancar una consola en el container.
$ docker exec -it <containerID> bash
Ahora ya nos podemos dedicar al modulo Python. Usaremos lxml. Se trata de un enlace Python para las bibliotecas C libxml2 y libxslt. Es único en el sentido de que combina la velocidad y la integridad de las funciones XML de estas bibliotecas con la simplicidad de una API Python nativa, en su mayoría compatible con la conocida API de ElementTree. Para más información sobre lxml https://lxml.de/index.html
Asumiendo que el gestor de paquetes pip3 (y por supuesto Python 3) ya está instalado en la instancia, habrá que instalar el modulo debido.
$ pip3 install --target /usr/irissys/mgr/python lxml
El método ejemplo que usaremos estará codificado en Python y estará encargado del parseo y validación de las reglas del schematron. El código de la clase que usaremos es el siguiente:
Class dc.schematron Extends %RegisteredObject
{
/// Description
ClassMethod simpleTest() [ Language = python ]
{
from lxml import isoschematron
from lxml import etree
print("Validating File...\n")
# def runsch(rulesFile, xmlFile):
#open files
rules = open('/durable/test-schema.sch', 'rb') # Schematron schema
XMLhere = open('/durable/test-file.xml', 'rb') # XML file to check
#Parse schema
sct_doc= etree.parse(rules)
schematron=isoschematron.Schematron(sct_doc, store_report=True)
#Parse XML
doc = etree.parse(XMLhere)
#Validate against schema
validationResult = schematron.validate(doc)
report = schematron._validation_report
#Check result
if validationResult:
print("passed")
else:
print("failed")
print(report)
}
}
La verdad es que se trata de un método bastante sencillo. Abre 2 ficheros – el fichero con las reglas (schematron) y un fichero ejemplo. La regla es verificar si la suma de los elementos <Percent> dentro de cada nodo <Total> es de 100%. Para ejecutarlo habrá que lanzar el siguiente comando desde la consola:
d ##class(dc.schematron).simpleTest()
El resultado se presentará en la consola. La misma lógica se podrá usar en una producción de interoperabilidad.
El código fuente conteniendo todos los elementos esta disponible aquí.
Artículo
Ricardo Paiva · 22 mayo, 2020
¡Hola desarrollador!
En este articulo repasaremos una publicación original de Maks Atygaev sobre la Implementación de una API de MongoDB, basada en InterSystems Caché - MonCaché.
Descargo de responsabilidad: En este artículo se muestra la opinión personal del autor y no tiene ninguna relación con opinión oficial de InterSystems.
Idea
La idea del proyecto es implementar las características básicas de la API en MongoDB (v2.4.9) , con la finalidad de buscar, guardar, actualizar y eliminar documentos de una manera que permita el uso de InterSystems Caché, en lugar de MongoDB, sin cambiar el código del lado del cliente.
Motivación
Probablemente, si tomamos una interfaz basada en MongoDB y utilizamos InterSystems Caché para el almacenamiento de los datos, podríamos ver un aumento en el rendimiento. El proyecto comenzó como un proyecto de investigación durante mis estudios universitarios.
Hey, ¡¿por qué no?! ¯\_(ツ)_/¯
Limitaciones
En el transcurso de este proyecto de investigación se hicieron algunas simplificaciones:
solamente se utilizaron tipos de datos primitivos: nulos, booleanos, numéricos, cadenas de texto, conjuntos, objetos, ObjectId;
el código del lado del cliente funciona con MongoDB mediante un controlador de MongoDB
el código del lado del cliente utiliza el controlador MongoDB Node.js
el código del lado del cliente solamente utiliza las funciones básicas de la API en MongoDB:
find, findOne — para buscar los documentos;
save, insert — para guardar los documentos;
update — para actualizar los documentos;
remove — para eliminar los documentos;
count — para contar los documentos.
Implementación
La tarea finalmente se dividió en las siguientes subtareas:
recrear la interfaz del controlador MongoDB Node.js para las funciones básicas que se seleccionaron,
implementar esta interfaz utilizando InterSystems Caché para el almacenamiento de los datos:
diseñar un esquema que represente las bases de datos en Caché,
diseñar un esquema que represente a las colecciones en Caché,
diseñar un esquema que represente a los documentos en Caché,
diseñar un esquema que permita la interacción con Caché mediante Node.js,
implementar los esquemas que se diseñaron y probarlos brevemente. :)
Detalles sobre la implementación
Realizar la primera subtarea no fue complicado, de modo que iré al grano y describiré la parte de la implementación de la interfaz.
MongoDB define una base datos como un contenedor físico para las colecciones. Una colección como un conjunto de documentos. Un documento como un conjunto de datos. Un documento es similar a los documentos en JSON, pero permite un mayor número de clases - BSON.
En InterSystems Caché todos los datos se almacenan en los globales. Por simplicidad, puede pensarse en ellos como estructuras de datos ordenadas de manera jerárquica.
En este proyecto, todos los datos se almacenarán en un único global: ^MonCache.
Por lo tanto, necesitamos diseñar un esquema que represente a las bases de datos, colecciones y documentos utilizando estructuras de datos ordenadas de manera jerárquica.
Esquema para representar las bases de datos en Caché
Para diseñar el global, únicamente implementé uno de entre los muchos diseños posibles, ya que cada diseño tiene diferentes beneficios y limitaciones.
En MongoDB puede haber varias bases de datos en una sola instancia, lo cual significa que necesitamos diseñar un esquema para representarlas que nos permita almacenar varias bases de datos por separado. Es importante señalar que MongoDB es compatible con bases de datos que no contienen colecciones (me referiré a ellas como bases de datos “vacías”).
Elegí la forma más sencilla y obvia para solucionar este problema. Las bases de datos se representan como un nodo de primer nivel en el global ^MonCache. Además, dicho nodo obtiene un valor "" para permitir que sea compatible con las bases de datos “vacías”. La cosa es que, si no hace este paso y solamente agrega nodos hijo, cuando los elimine también eliminará al nodo padre (esa es la forma en que funcionan los globales).
Por lo tanto, cada base de datos se representa en Caché de la siguiente manera:
^MonCache(<db>) = ""
Por ejemplo, la representación de la base de datos “my_database” se verá de la siguiente manera:
^MonCache("my_database") = ""
Esquema para representar las colecciones en Caché
MongoDB define a una colección como uno de los elementos en una base de datos. Todas las colecciones que estén en una sola base de datos tienen un nombre único, el cual puede utilizarse para identificar de manera precisa a la colección. Este hecho fue lo que me ayudó a encontrar una manera sencilla para representar a las colecciones en un global y, en particular, a utilizar nodos de segundo nivel. Ahora debemos resolver dos pequeños problemas. El primero es que las colecciones, al igual que las bases de datos, pueden estar vacías. El segundo es que una colección es un conjunto de documentos. Y todos estos documentos deben estar separados unos de otros. Para ser honesto, no se me ocurrió una mejor idea que tener un contador, algo similar a un valor que se incrementará de manera automática, como un valor en la colección de nodos. Todos los documentos tienen un número único. Cuando se inserta un nuevo documento, se crea un nuevo nodo con el mismo nombre que tiene el valor del contador actual, y el valor del contador se incrementa en 1.
Por lo tanto, cada una de las colecciones en Caché se representa de la siguiente manera:
^MonCache(<db>) = ""^MonCache(<db>, <collection>) = 0
Por ejemplo, la colección “my_collection” que se encuentra en la base de datos “my_database” se representará de la siguiente manera:
^MonCache("my_database") = ""^MonCache("my_database", "my_collection") = 0
Esquema para representar a los documentos en Caché
En este proyecto, un documento es un documento en JSON, que se amplia mediante una clase adicional: ObjectId. Tuve que diseñar un esquema que representara a los documentos para estructuras de datos ordenadas de manera jerárquica. Ahí fue donde me enfrenté a algunas sorpresas. En primer lugar, no podía usar el valor nulo “nativo“ en Caché, ya que no era compatible. Otra cosa es que los valores booleanos se implementan mediante las constantes 0 y 1. En otras palabras, 1 significa verdadero y 0 significa falso. El problema más grande fue que debía encontrar una forma para almacenar a ObjectId. Al final, todos estos problemas se resolvieron exitosamente y de la manera más sencilla, o al menos eso creía yo. En el siguiente artículo, examinaré cada uno de los tipos de datos y cómo se representan.
Esquema para interactuar con Caché
La elección del controlador Node.js pareció ser una decisión lógica y sencilla para trabajar con InterSystems Caché (puede encontrar otros controladores para interactuar con Caché en los documentos de apoyo que se encuentran disponibles en el sitio web). Sin embargo, tenga en cuenta que la capacidad del controlador puede no ser suficiente. Quería realizar varias inserciones con una sola transacción. Es por eso que decidí desarrollar un conjunto de clases en Caché ObjectScript, que se utilizaron para emular la API de MongoDB en el lado de Caché.
El controlador de Caché, Node.js, no podía acceder a las clases en Caché, pero podía llamar al programa desde Caché. Este hecho resultó en la creación de una pequeña herramienta: Una especie de puente entre el controlador y las clases en Caché.
Al final, el esquema se veía de la siguiente manera:
Mientras trabajaba en el proyecto, establecí un formato especial que llamé NSNJSON (Not So Normal JSON) que me permitió "pasar de contrabando" ObjectId, valores nulos, verdaderos y falsos a través del controlador a Caché. Puede encontrar más información sobre este formato en la página correspondiente de GitHub — NSNJSON.
Funcionalidad de MonCaché
Para la búsqueda de documentos están disponibles los siguientes criterios:
$eq — equivalencia;
$ne — no equivalencia;
$not — negación;
$lt — menor que;
$gt — mayor que;
$exists — existe.
Para las operaciones de actualización de documentos están disponibles los siguientes operadores:
$set — configurar un valor;
$inc — incrementar un valor por un número específico;
$mul — multiplicar un valor por un número específico;
$unset — eliminar un valor;
$rename — cambiar el nombre de un valor.
Ejemplo
Tomé este código de la página oficial del controlador y lo modifiqué un poco.
var insertDocuments = function(db, callback) { var collection = db.collection('documents'); collection.insertOne({ site: 'Habrahabr.ru', topic: 276391 }, function(err, result) { assert.equal(err, null); console.log("Inserted 1 document into the document collection"); callback(result); });}
var MongoClient = require('mongodb').MongoClient , assert = require('assert');
var url = 'mongodb://localhost:27017/myproject';
MongoClient.connect(url, function(err, db) { assert.equal(null, err); console.log("Successfully connected to the server");
insertDocument(db, function() { db.close(); });});
¡Este código se puede modificar fácilmente para hacerlo compatible con MonCaché!
¡Lo único que necesitamos para hacerlo es cambiar el driver!
// var MongoClient = require('mongodb').MongoClientvar MongoClient = require('moncache-driver').MongoClient
Después de ejecutar el código, el global de ^MonCache se verá de la siguiente manera:
^MonCache("myproject","documents")=1^MonCache("myproject","documents",1,"_id","t")="objectid"^MonCache("myproject","documents",1,"_id","v")="b18cd934860c8b26be50ba34"^MonCache("myproject","documents",1,"site","t")="string"^MonCache("myproject","documents",1,"site","v")="Habrahabr.ru"^MonCache("myproject","documents",1,"topic","t")="number"^MonCache("myproject","documents",1,"topic","v")=267391
Demostración
Aparte de todo lo demás, lanzamos una pequeña demostración de la aplicación (código fuente), la cual también se implementó con Node.js para demostrar cómo se realiza el cambio del controlador desde MongoDB Node.js hacia MonCaché Node.js, sin que fuera necesario reiniciar el servidor y cambiar el código fuente. La aplicación es una pequeña herramienta para realizar operaciones CRUD en productos y oficinas, así como una interfaz para cambiar la configuración (modificar el controlador).
El servidor permite crear productos y funciones que se guardan para después almacenarse en la configuración que se seleccionó (Caché o MongoDB).
La pestaña "Órdenes" contiene una lista de las órdenes. Ya establecí los registros, pero el formulario aún no está completo. Usted es bienvenido a colaborar en el proyecto (código fuente).
Puede cambiar la configuración desde la página "Configuración". En esta página hay dos botones: MongoDB y MonCache. Puede seleccionar la configuración que desee al hacer clic sobre el botón correspondiente. Cuando se cambia la configuración, la aplicación del cliente se conectará nuevamente a la fuente de los datos (una abstracción que separa la aplicación del controlador que se utiliza en ese momento).
Conclusión
En resumen, permítanme responder la pregunta más importante. ¡Exacto! Logramos aumentar el rendimiento cuando se realizan las operaciones básicas.
El proyecto MonCaché se publicó en GitHub y está disponible bajo una licencia del MIT.
Guía Breve
Instale Caché
Cargue los componentes que sean necesarios para MonCaché en Caché
Establezca un área en Caché para MONCACHE
En Caché, establezca un usuario que se llame “moncache” con la contraseña “ehcacnom” (es “moncache” al revés)
Establezca una variable de entorno MONCACHE_USERNAME = moncache
Establezca una variable de entorno MONCACHE_PASSWORD = ehcacnom
Establezca una variable de entorno MONCACHE_NAMESPACE = MONCACHE
En su proyecto, modifique la dependencia de 'mongodb' hacia 'moncache-driver'
¡Inicie su proyecto! :-)
Programa Académico de InterSystems
Si está interesado en iniciar su propio proyecto de investigación basado en las tecnologías de InterSystems, puede visitar una página especializada que se dedica a brindar información sobre los programas académicos de InterSystems.
Anuncio
Mario Sanchez Macias · 25 mayo, 2020
InterSystems ha corregido dos defectos que afectan al backup online de grandes bases de datos. Los backups realizados a través de métodos externos, como snapshots o copias directas de ficheros, no están afectados. Estos defectos existen en todas las versiones de los productos de InterSystems.
El primer defecto solo afecta a bases de datos con más de 231 bloques. Da lugar a una base de datos degradada tras recuperarla de un backup online. Por ejemplo, bases de datos que tienen un tamaño de bloque de 8 KB (el valor por defecto) solo se ven afectadas si ocupan más de 16 TB. La corrección a este defecto se identifica como RJF437.
El segundo defecto afecta a bases de datos que tienen un tamaño de bloque de 8 KB y ocupan más de ~29 TB. Con este defecto, el backup online falla debido a un error <DATABASE> impreciso; esto da lugar a un backup que no puede ser recuperado. La corrección a este defecto se identifica como RJF438. Hay que tener en cuenta que este defecto también afecta a las bases de datos que tienen un tamaño de bloques menor de 8 KB.
Las correcciones a estos defectos se incluirán en todas las futuras versiones de los productos. También están disponibles solicitando una distribución ad hoc al Centro de Soporte Internacional (WRC).
Para cualquier pregunta sobre esta alerta, se puede contactar con el Centro de Soporte Internacional (WRC).
Como nota personal a la noticia oficial anterior, me gustaría resaltar que si estáis haciendo backups online de bases de datos tan grandes como las que se mencionan, deberíais replantear la estrategia de Backup. El Backup Online de Caché es genial para bases de datos no muy grandes. Cuando las bases de datos empiezan a ser grandes (por ejemplo más de un 1TB) lo más recomendable es utilizar backup externos, con tecnologías tipo snapshot, que te van a permitir hacer copias en pocos segundos y lo más importante, poder restaurar en mucho menos tiempo. Gracias por el aviso y por la nota Mario... siempre es útil este tipo de recomendaciones
Artículo
Ricardo Paiva · 29 sep, 2022
¡Hola Comunidad!
A lo largo de los años siempre he pensado en crear cosas nuevas, modificar las existentes, experimentar, probar, romper (siempre pasa), construir de nuevo, y empezar otra vez.
Los concursos promovidos por InterSystems son una excelente fuente de motivación. Obviamente los premios llaman la atención y eso no se puede negar. Pero no se trata solo de los premios/regalos - los concursos son un reto creativo, una oportunidad de crear, reimaginar, probar, experimentar... Y lo mejor de todo es que eres libre de hacer todo lo que quieras!
Así que ví estos concursos como una oportunidad de crear mi propio Y si...? (la serie en la que Marvel permite a los autores re-imaginar sus historias como quieran) y he sido muy afortunado de encontrar otra persona que recibe estas ideas con los brazos abiertos ¡Muchas gracias, @José.Pereira!
En el último concurso de Interoperabilidad, creé el visualizador de mensajes Message Viewer y en este concurso de Interoperabilidad traigo de nuevo el Message Viewer, pero esta vez con Visual Trace!
Cualquiera que ya trabaje con la tecnología de InterSystems y conozca la parte de integración (Ensemble / Interoperabilidad), sabe que Visual Trace ha estado ahí durante mucho tiempo, sin cambiar y sin ningún problema.
Funciona, muestra el diagrama de secuencia de tu mensaje, los detalles, presenta la información, XML, etc. Pero... ¿solo porque funciona no puedo re-diseñarlo? Intentando darle una nueva perspectiva y quizá motivando un pequeño cambio?
Steve Rogers (Capitán America) es un example de esto - es uno de los personajes más importantes de Marvel y aun así lo re-diseñaron y re-crearon, probando a Peggy Carter como Capitán, para la serie What if...? 😂
Así que vamos a hablar un poco más de nuestra nueva "Peggy Carter", es decir, Visual Trace!
Este es nuestro viejo y efectivo Visual Trace:
Ahora, imagina tener miles de mensajes aquí y que no puedes re-enviar de forma sencilla un simple mensaje?
Tendrías que volver a la pantalla del Message Viewer, investigar, buscar y re-enviar tu mensaje.
Por eso pensamos que es posible mostrar la información con un nuevo look, ofreciendo una funcionalidad sencilla. Y creo que puede ayudar y hacer la vida un poco más fácil a los desarrolladores.
DEMO
Vídeo en YouTube >>
.
Anuncio
Mario Sanchez Macias · 10 feb, 2023
En InterSystems creemos en la divulgación responsable de vulnerabilidades de seguridad descubiertas recientemente. Ofrecemos información oportuna a nuestros clientes, a la vez que la mantenemos fuera del alcance de las personas que puedan hacer un mal uso. También entendemos que cada cliente puede tener diferentes necesidades relacionadas con la resolución de problemas de seguridad.
Desde el inicio de 2023, hemos realizado dos cambios significativos en nuestro enfoque sobre la corrección de las vulnerabilidades de seguridad que me gustaría destacar:
Los parches de vulnerabilidad de seguridad se incluirán en cada actualización
Notificación a los clientes mejorada
Parches de vulnerabilidad de seguridad en cada actualizaciónEn vez de esperar a entregar los parches en una versión de seguridad, cada actualización puede incluir ahora parches de vulnerabilidades de seguridad. Nuestra cadencia de actualizaciones mejorada entregará parches a tiempo.
Notificación a los clientes mejoradaElementos de impacto medio y bajo, que a menudo incluyen vulnerabilidades como ataques de reconocimiento o ataques de inyección de código (cross-site scripting), serán incluidos en cada actualización y descritos en las notas de la actualización del producto.
Las correcciones para elementos de mayor gravedad también se incluirán en cada actualización según estén listas, pero la información sobre la corrección será retenida hasta que los parches estén en todas las actualizaciones soportadas.
Se publicará una Alerta de Seguridad para problemas con gravedad alta y crítica cuando hayan sido corregidos en todas las actualizaciones soportadas.
¿Por qué ha hecho InterSystems estos cambios?Creemos que estas mejoras:
Permitirán ofrecer más rápidamente parches de seguridad a nuestros clientes
Ayudarán a centrarse en las correcciones de mayor gravedad
Permitirán, en algunos casos, ofrecer correcciones de seguridad como parches en vez de kits completos
Ofrecerán más transparencia sobre cómo las vulnerabilidades de seguridad son gestionadas agrupando las vulnerabilidades por su impacto en la seguridad
Permitirán a los administradores de sistemas aplicar más correcciones basadas en sus necesidades y obligaciones
Por supuesto, el proceso se vuelve mucho más complicado con la noción de las Actualizaciones de Mantenimiento y las Actualizaciones de Entrega Continua. Para ayudar a nuestros clientes a entender cuándo y cómo pueden conseguir correcciones de seguridad, hemos publicado nuestra Política de Gestión de la Vulnerabilidad con más información detallada.
En este 2023 esperamos seguir mejorando vuestra experiencia en relación a nuestro programa de gestión de las vulnerabilidades y la seguridad.
Artículo
Muhammad Waseem · 1 jun, 2022
¡Hola comunidad!
Esta publicación es una introducción a mi aplicación iris-fhir-client en Open Exchange.
Usando Python embebido y con la ayuda de la librería fhirpy, iris-fhir-client puede conectarse a cualquier servidor FHIR abierto.Obten información de recursos por terminal y mediante el uso de la aplicación web CSP.
Ver y activar servidores registrados
Conéctate a la terminal IRIS
docker-compose exec iris iris session iris
La aplicación registrará InterSystems FHIR Accelerator Service y SmartHealthIT Open FHIR Server de manera predeterminada y ambos estarán listos para ser usados.
Usa el siguiente comando para enumerar los servidores registrados
do ##class(dc.FhirClient).ServerList()
InterSystems FHIR Accelerator Service está activo. Para seleccionar SmartHealthIT Open FHIR Server, usa la función SetFhirServer de la clase dc.FhirClient pasando la ID del servidor
do ##class(dc.FhirClient).SetFhirServer(2)
Servidores FHIR registrados
Para registrar un nuevo servidor, utiliza la función RegisterServer() de la clase dc.FhirClientclass(dc.FhirClient).RegsterServer("Server Name","Endpoint","ApiKey"[opcional],"EndpointOAuth"[opcional]
do ##class(dc.FhirClient).RegisterServer("INTERSYSTEMS FHIR Server","http://localhost:52773/csp/healthshare/samples/fhir/r4/","","")
Obtener recursos de los servidores FHIR
Para recuperar todos los recursos para el servidor actual, utiliza el método ListResources() de la clase dc.FhirClient
do ##class(dc.FhirClient).ListResources()
Para mostrar la cantidad de registros de cualquier recurso, usa el método CountResource() pasando Resource de dc.FhirClient.El siguiente comando obtendrá el contador de recursos del paciente contra el servidor FHIR activo
set count = ##class(dc.FhirClient).CountResource("Patient")
write count
Para recuperar todos los recursos creados junto con su recuento, simplemente pasa 1 a la función ListResource()
do ##class(dc.FhirClient).ListResources(1)
Para obtener detalles del recurso, usa GetResource() pasando Resource de la clase dc.FhirClientEl siguiente comando recuperará todos los pacientes del servidor FHIR activo
do ##class(dc.FhirClient).GetResource("Patient")
El siguiente comando recuperará todas las Observaciones del servidor FHIR activo
do ##class(dc.FhirClient).GetResource("Observation")
Obtener recursos de los servidores FHIR para un paciente en particular
El siguiente comando recuperará los detalles de las Observaciones contra Patinet ID 1 del servidor FHIR activo
do ##class(dc.FhirClient).GetPatientResources("Observation","1")
Ver información del servidor FHIR desde la aplicación web CSP
Ir a http://localhost:55037/csp/fhirclient/index.cspLa página Index (Índice) mostrará el recuento de pacientes, observaciones, médicos y encuentros del servidor activo junto con los detalles del paciente y de los servidores registrados
La página Index (Índice) mostrará la lista de servidores FHIR con el servidor activo seleccionado. Selecciona otro servidor de la lista para ver los detalles del servidor seleccionado
Desplázate hasta el ID del paciente y selecciónalo para obtener detalles de los Recursos del paciente
Esta página mostrará el recuento de algunos recursos del paciente junto con los detalles de las observaciones del paciente.
Si encuentra útil esta aplicación, considere votar por mi aplicación
¡Gracias!
Artículo
Ricardo Paiva · 12 ene, 2023
Visual Studio Code (VS Code) es el editor de códigos más popular del mercado. Fue creado por Microsoft y distribuido como IDE gratuito. VS Code es compatible con docenas de lenguajes de programación, incluido ObjectScript.
Hasta 2018, Atelier (basado en Eclipse), se consideraba una de las principales opciones para desarrollar los productos de InterSystems. Sin embargo, en diciembre de 2018, cuando la Comunidad de Desarrolladores de InterSystems lanzó el soporte para VSCode, una parte relevante de los profesionales de InterSystems comenzaron a utilizar este editor y lo siguen haciendo desde entonces, especialmente los desarrolladores que trabajan con nuevas tecnologías (Docker, Kubernetes, NodeJS, Angular, React, DevOps, Gitlab, etc.).
Algunas de las mejores características de VSCode son las funciones de depuración. Por eso, en este artículo mostraré en detalle cómo depurar un código ObjectScript, incluido el código de clase y el código %CSP.REST.
## ¿En qué consiste la depuración?
La depuración es un proceso de detección y resolución de "bugs" - errores en el código. Algunos errores son lógicos, no de compilación. Por eso, para comprenderlos en tu lógica de ejecución del código fuente, es necesario ver el programa ejecutándose línea por línea. Esta es la mejor manera de identificar las condiciones o la lógica de la programación y encontrar errores lógicos. Otros errores son de ejecución. Para que podamos depurar este tipo de problemas, es esencial verificar primero los valores de las variables asignadas.
## Instalación de las extensiones de InterSystems IRIS para VSCode
En primer lugar, hay que instalar las extensiones de InterSystems IRIS en tu IDE de VSCode. Para hacerlo, ve a Extensiones, busca InterSystems e instala estas extensiones de InterSystems:
.png)
La última extensión (InterSystems ObjectScript Extension Pack) debería instalarse la primera, porque es un paquete de extensiones necesarias para conectar, editar, desarrollar y depurar ObjectScript. Las demás extensiones de la lista son opcionales.
## Aplicación de muestra
Utilizaremos una aplicación de mi repositorio de GitHub (https://github.com/yurimarx/debug-objectscript.git) para los ejemplos de depuración de este artículo. Por lo tanto, sigue los siguientes pasos para obtener, ejecutar y depurar la aplicación en VSCode:
1. Crea un directorio local e introduce en él el código fuente del proyecto:
$ git clone https://github.com/yurimarx/debug-objectscript.git
2. Abre el terminal en este directorio (directorio iris-rest-api-template) y ejecuta:
$ docker-compose up -d --build
3. Abre VS Code dentro del directorio iris-rest-api-template usando $code, o haga clic-derecho sobre la carpeta y selecciona Abrir con Code.
4. Abajo, haz clic en ObjectScript para abrir las opciones configuradas en .vscode/launch.json:
.png)
5. Selecciona Toggle Connection (Alternar conexión) para activar la conexión actual:
.png)
6. Después de habilitar esta conexión, obtendrás la conexión que se muestra a continuación:
.png)
7. Si no estás conectado con IRIS en VSCode, no podrás depurar el código ObjectScript. Así que comprueba tu conexión haciendo clic sobre la extensión ObjectScript VSCode:
.png)
8. Abre Person.cls, ve a la línea número 25 y señala con el ratón el número 25 que aparece a la izquierda.
.png)
9. Ahora, señala con el ratón en ClassMethod arriba y haz clic en Debug this method:
.png)
10. VSCode abrirá un diálogo para establecer los valores de los parámetros - defínelos como se muestra a continuación, y haz clic en Enter:
.png)
11. VSCode interrumpirá la ejecución del código en la línea 25:
.png)
12. Ahora, en la parte superior izquierda, se pueden ver los valores actuales de las variables.
.png)
13. En la parte inferior izquierda se puede ver la lista de puntos de interrupción y la pila de llamadas para el punto de interrupción actual.
.png)
14. En la parte superior derecha se puede ver el código fuente con el punto de interrupción y un conjunto de botones para controlar la ejecución de la depuración.
.png)
15. Si necesitas utilizar la Consola de Depuración (Debug Console) para escribir algo allí, escribe: Name\_","\_Title para ver la concatenación de variables usando Debut Console:
.png)
16. Selecciona la variable resultante, pulsa el botón derecho del ratón y selecciona Añadir a Watch (Add to Watch):
.png)
17. Ahora puedes controlar o cambiar el valor actual de la variable resultante en la sección WATCH:
.png)
18. Finalmente, la barra que aparece abajo es de color naranja, e indica la depuración:
.png)
## Uso de la Consola de Depuración
La Consola de Depuración permite escribir expresiones durante la depuración, para que se puedan verificar los valores de diferentes variables (de tipo simple o de tipo objeto) o validar el valor actual y otras condiciones. Puede ejecutar cualquier elemento que pueda devolver algunos valores, por lo que $zv también funcionará. Sigue estos pasos para ver algunas opciones:
1. Escribe Name\_", "\_Title\_" From "\_Company en la línea de comando Debug Terminal y mira los valores concatenados Nombre, Título y Empresa como salida:
.png)
## Uso de la barra de herramientas de depuración
La barra de herramientas de depuración permite controlar la ejecución de la depuración. Vamos a ver las funciones de los botones:
.png)
1. Botón Continue (F9): continúa la ejecución hasta el siguiente punto de interrupción. Si no hay ningún punto de interrupción al que ir, continuará hasta el final.
2. Step Over (F8): pasa a la línea siguiente sin entrar en el código fuente de un método interno (no entra en el método Populate).
3. Step Into (F7): pasa a la siguiente línea dentro del código fuente del método interno (pasa a la primera línea del método Populate).
4. Step Out (Shift + F8): pasa a la línea actual del código fuente que llama a un método.
5. Restart (Crtl + Shift + F5): reinicia la depuración.
6. Stop: detiene la sesión de depuración.
## Depurar los métodos de la clase %CSP.REST
Para depurar métodos de la clase REST, es necesario aplicar un pequeño truco revelado por Fábio Gonçalves (puedes leer el artículo aquí: https://es.community.intersystems.com/post/atelier-depuraci%C3%B3n-adjuntar-al-proceso). Es necesario añadir un HANG (mi recomendación es que dure entre 20 y 30 segundos). Solo sigue estos pasos:
1. Abre el archivo src\dc\Sample\PersonREST.cls y ve al método GetInfo(), añade HANG 30 (esto es necesario para disponer de tiempo, 30 segundos, para iniciar la depuración de este método):
.png)
2. Establece puntos de interrupción en las líneas HANG y SET version (círculos rojos):
.png)
3. Abre un cliente HTTP para llamar a un método REST (llamaré a GetInfo desde la clase PersonREST):
.png)
4. Establece Basic Auth en Autorización (Username _SYSTEM y Contraseña SYS):
.png)
5. Envía un GET http://localhost:52773/crud/.
6. Haz clic en la opción Adjuntar ObjectScript que se encuentra en parte de abajo:
.png)
7. Selecciona Adjuntar ObjectScript:
.png)
8. Selecciona el proceso PersonREST:
.png)
9. Espera un poco de tiempo (unos 30 segundos) para que VS Code interrumpa la ejecución actual en el punto de interrupción:
.png)
Nota 1: Elimina HANG 30 cuando termine la depuración, porque el comando HANG pausará la ejecución.
Nota 2: Si el proceso PersonREST no aparece, reinicia tu VS Code, e inténtalo de nuevo.
10. Ahora puedes llevar a cabo tu proceso de depuración.
## Editar el punto de interrupción
Se puede hacer clic con el botón derecho en el punto de interrupción para eliminar o configurar puntos de interrupción condicionales (la interrupción en el punto de interrupción con una condición es verdadera). El comando break que está embebido en el código también será detectado por el depurador. También se puede hacer esto.
1. Haz clic con el botón derecho en el punto de interrupción y selecciona Editar punto de interrupción (Edit breakpoint):
.png)
2. Introduce la expresión siguiente y pulsa Enter:
.png)
Nota: prueba version = 1.0.5 para ver el breakpoint falso y version 1.0.6 para ver el breakpoint verdadero.
## Configurar la opción de depuración en el archivo .vscode/launch.json
El archivo launch.json se utiliza para configurar las opciones de depuración del proyecto. Para ver las alternativas, ve a este archivo:
.png)
Para esta muestra, tenemos dos opciones para depurar:
1. Podemos iniciar la depuración sobre la clase configurada en el atributo program directamente con un programa. En este ejemplo el depurador se iniciará en la clase PackageSample.ObjectScript, método Test().
2. Podemos adjuntar PickProcess al proceso del programa seleccionado que se quiere depurar. En este ejemplo el depurador abrirá en la parte superior una lista de procesos para seleccionar qué proceso se depurará (cada programa tiene su propio proceso). La segunda opción es más habitual.
De manera general, estos atributos son obligatorios para cualquier configuración de depuración (fuente: https://intersystems-community.github.io/vscode-objectscript/rundebug/):
* type - Identifica el tipo de depurador que se utilizará. En este caso, ObjectScript se suministra mediante la extensión InterSystems ObjectScript.
* request - Identifica el tipo de acción para esta configuración de inicio. Los posibles valores son iniciar (launch) y adjuntar (attach).
* name - Un nombre arbitrario para identificar la configuración. Este nombre aparece en la lista desplegable "Iniciar depuración".
Además, para una configuración de inicio en ObjectScript, es necesario proporcionar el atributo program, que especifica la rutina o Método de clase que se ejecutará al iniciar el depurador, como se muestra en el siguiente ejemplo:
"launch": {
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "launch",
"name": "ObjectScript Debug HelloWorld",
"program": "##class(Test.MyClass).HelloWorld()",
},
{
"type": "objectscript",
"request": "launch",
"name": "ObjectScript Debug GoodbyeWorld",
"program": "##class(Test.MyOtherClass).GoodbyeWorld()",
},
]
}
Para adjuntar una configuración en ObjectScript, se pueden proporcionar los siguientes atributos:
* processId - Especifica el ID del proceso para adjuntar a una cadena o un número. El valor predeterminado "${command:PickProcess}" proporciona una lista desplegable de los ID de los procesos para adjuntar durante la ejecución.
* system - Especifica si se permiten o no archivos adjuntos en el proceso del sistema. Establece la configuración predeterminada en falso.
El siguiente ejemplo muestra varias configuraciones válidas para adjuntar ObjectScript:
"launch": {
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "attach",
"name": "Attach 1",
"processId": 5678
},
{
"type": "objectscript",
"request": "attach",
"name": "Attach 2",
"system": true
},
]
}
Ahora, puedes seleccionar una configuración de depuración de la lista que VS Code proporciona en el campo Run and Debug en la parte superior de la barra lateral de depuración (fuente: https://intersystems-community.github.io/vscode-objectscript/rundebug/):
.png)
Si haces clic en la flecha verde, se ejecutará la configuración de depuración seleccionada en ese momento.
Al iniciar la sesión de depuración de ObjectScript, asegúrate de que el archivo que contiene el programa que estás depurando está abierto en tu editor y se encuentra en la pestaña activa. VS Code iniciará una sesión de depuración con el servidor del archivo en el editor activo (la pestaña en la que está centrado el usuario). Esto también se aplica a las sesiones de depuración ObjectScript adjuntas.
Esta extensión utiliza WebSockets para comunicarse con el servidor de InterSystems durante la depuración. Si tienes problemas al intentar iniciar una sesión de depuración, comprueba que el servidor web de InterSystems permite las conexiones WebSocket.
Los comandos de depuración y los elementos del menú Run funcionan prácticamente igual que en otros lenguajes compatibles con VS Code. Para más información sobre la depuración de VS Code, consulta la documentación enumerada al final de este artículo.
## Establecer la sincronización entre un código fuente local y un código fuente del servidor (en IRIS Server)
También es importante tener una estructura de carpetas para el código fuente, que puede adoptarse mediante la configuración de "objectscript.export". Esta información se utilizará para convertir los nombres de clase del servidor en archivos locales. Si es incorrecto, puede abrir clases en el modo de solo lectura aunque solo existan de forma local.
1. Abre el archivo .vscode\settings.json y configura objectscript.export:
.png)
2. Pasa el ratón por encima de la carpeta y añade Categoría y otros parámetros para ver la documentación sobre ella.
## Otras técnicas para complementar el proceso de depuración
Además de depurar tu programa, recuerdaa documentar bien tu código fuente, registrar las operaciones realizadas por el código importante y realizar pruebas unitarias y herramientas de análisis estático en el código fuente. De esta manera, la calidad de tus programas será mucho mejor, reduciendo el tiempo y el coste de ajustes y mantenimiento.
## Para saber más
1.
2.
3.
4.
5.
Artículo
Alberto Fuentes · 9 mayo, 2019
Me gustaría compartir un trabajo de André-Claude Gendron del CIUSSS de l'Estrie - CHUS (Canadá) presentado en un InterSystems Summit. Consiste en un framework de generación de objetos simulados (mocks) que puede utilizarse para construir UnitTests.Un objeto simulado (o mock) no es más que un objeto que imita el comportamiento de objetos reales de forma controlada. Estos objetos simulados se utilizan en las pruebas unitarias (UnitTest) para simular objetos o dependencias que sean necesarias para la clase que se quiera probar. Lo explica muy bien su presentación:La presentación detalla varios conceptos sobre inyección de dependencias, definiciones y UnitTest además de mostrar ejemplos concretos del framework (si os interesa, YouTube tiene la opción de generar automáticamente subtítulos en español). El código está disponible aquí :https://gitlab.com/ciussse-drit-srd-public/Mocking-Framework No olvidéis habilitar la opción %UnitTest en el Portal de Gestión . Las instrucciones para hacerlo se encuentran on-line: en: http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=...
Pregunta
Yunier Gonzalez · 31 oct, 2019
Saludos comunidad. Me gustaría saber cómo migrar un BD en producción a un entorno local. Cuando tengo un sistema en producción (Servidor BD Sql), lo que hacemos es montar una copia local para hacer el análisis con los datos y no ocupar los recursos del sistema en producción. Mi pregunta es: ¿cómo se hace con la tecnología Intersystems? Ya probé el conector PowerBi y se ve muy bien, pero ahí es donde surgió la pregunta. Hola @Yunier Gonzalez hay varias opciones. Una es hacer como dices un Backup/Restore de la BD para "jugar" con una imagen sin perjudicar los datos reales. Otra cosa que se puede hacer es utilizar un Shadow. Un Shadow replica todo lo que sucede en una BD a otra BD en otra instancia mediante el uso del journal. De esta forma tienes datos "casi" en tiempo real. En el caso de un Mirror se puede usar una replicación asíncrona para uso como Reporting. @David Reche . Me pondre a investigar entonces sobre los temas que me comentas. Muchas gracias!!! El cambio es grande y son muchas las dudas, asi que cualquier cosa no dudare en volver a este hilo a preguntar. Una vez mas Muchas gracias.