 Open Exchange
Open Exchange
I'm excited to announce a major update to SQL Data Lens – a powerful database client and metadata explorer – that opens up new, free possibilities for the InterSystems community.
SQL Data Lens is now completely FREE to use with InterSystems IRIS Community Edition!
No more “localhost only” restrictions
No more limits on the number of connections
No license? No problem.
You can now connect to InterSystems IRIS Community Edition—completely license-free—using the fully functional Free Edition of SQL DATA LENS. Explore all the features, no strings attached.
Discover hidden insights with SQL DATA LENS:
Instantly uncover detailed information about your IRIS tables—no deep dives or guesswork required: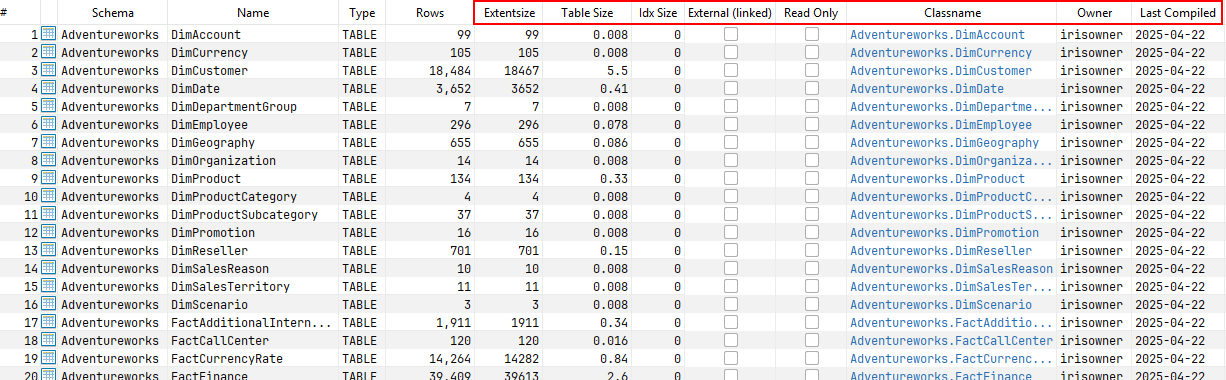
SQL DATA LENS helps with:
Detecting and Resolving Metadata Inconsistencies in InterSystems IRIS
Focus on your database objects and hide all the system objects
Easily Copy Tables Between Databases and Servers
Curious what's under the hood?
Instantly explore native global values directly within SQL DATA LENS—see what your data is really doing behind the scenes.
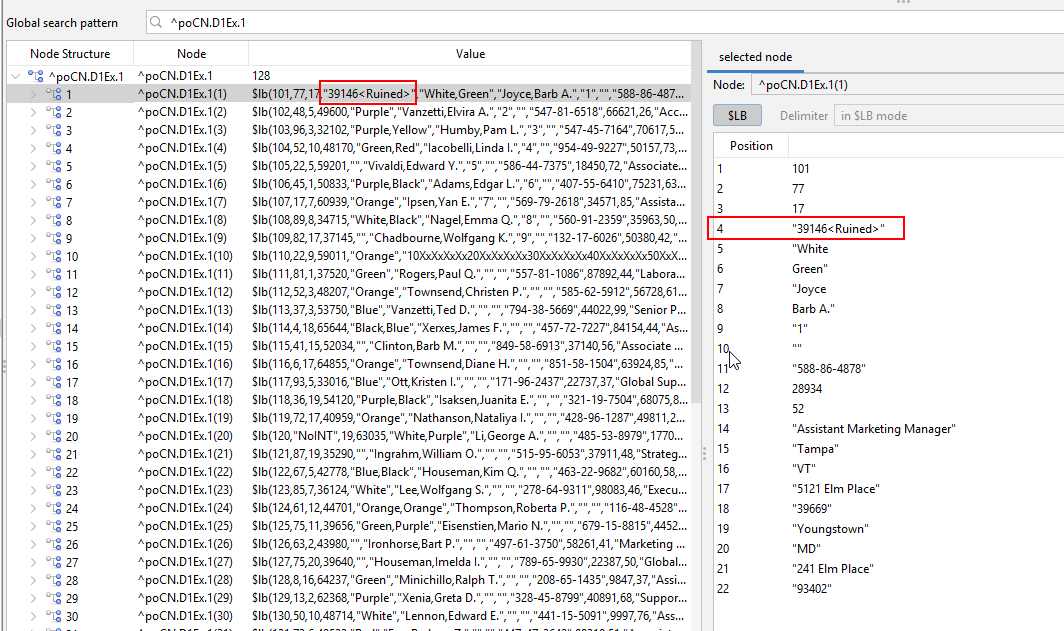
Ready to explore your data like never before?
🚀 Download SQL Data Lens and get started today. Also available via Microsoft Store
💬 Got feedback, ideas, or ran into something odd? I’d love to hear from you—let’s make it even better together!
Happy querying!
