Limpiar filtro
Pregunta
Héctor Mancilla · 5 mar, 2021
Hola buen día a todos.
quería saber si existe alguna forma de cambiar el nombre un reporte excel. estas son las propiedades y parámetros de la clase:
/// Nombre de clase de la aplicación a la que pertenece este informe.
Parameter APPLICATION;
Parameter REPORTNAME;
Property RenderTimeOut As %ZEN.Datatype.integer [ InitialExpression = -1 ];
Property ID As %String(ZENURL = "id");
Parameter XSLTMODE = "server";
Property Title(ZENURL = "title");
Principalmente estoy colocando la URI en un anchor en HTML para poder descargar, pero el atributo 'download' en el tag no hace el trabajo, por lo cual quiero hacer el trabajo en la URI misma.
Saludos Hola Hector, la verdad es que no entiendo bien que quieres hacer. Puedes darnos más detalles Hola Hector,
Si lo entiendo bien, estas hablando de ZEN Reports. Ten en cuenta que es una funcionalidad deprecada en Intersystems IRIS, donde se siguen soportando lo Zen reports ya desarrollados con anterioridad, pero se recomienda migrarlos a "InterSystemt Reports" documentado aquí:
https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_reports
En cuanto a la pregunta, parece que puedes sobrescribir el valor del parametro de clase REPORTNAME con un valor de parametro de URL en la petición de Report "?ReportName=MiInforme":
Esto es el código en %ZEN.Report.reportPage que usa el parametr de URL si esta definido:
//JSL4724
set reportnameurlparam = $get(%request.Data("ReportName",1))
set reportname=$s(reportnameurlparam'="":reportnameurlparam,..#REPORTNAME'="":..#REPORTNAME,1:..%ClassName(1))
Lo puedes probar?
Saludos,PYD Muchas gracias por su respuesta, me ayudó mucho!
Artículo
Muhammad Waseem · 9 nov, 2021
En mi artículo anterior, expliqué los pasos para conectarse a Caché desde Appeon PowerBuilder usando ODBC.
En este artículo, mostraré cómo recuperar datos de Caché con Appeon PowerBuilder (https://www.appeon.com/products/powerbuilder) utilizando ODBC.Estoy usando Company.cls de Samples-Data (https://github.com/intersystems/Samples-Data/tree/master/cls/Sample)
Así que comencemos:
Paso 1 : En primer lugar, debemos establecer una conexión. (https://community.intersystems.com/post/connecting-cach%C3%A9-appeon-powerbuilder-using-odbc)
Paso 2 : Necesitamos crear un datawindow object (objeto de ventana de datos) que se vinculará a la clase Company.
En el menú File (Archivo), selecciona New (Nuevo) y después el objeto Grid (cuadrícula) en la pestaña DataWindow (Ventana de datos).
Paso 3 : Selecciona SQL Select de la lista de Data Source (Fuente de datos).
Paso 4 : Selecciona sample.company de la lista de Tables (Tablas).
Paso 5 : Selecciona las columnas deseadas de la lista de columnas y haz clic en Return.
Paso 6 : Esto abrirá una vista de diseño. Guarda datawindow (ventana de datos) como d_company después de los ajustes deseados.
Paso 7 : En window control, añade datawindow object (objeto ventana de datos) d_company, que ya creamos, al datawindow control.
Paso 8 : Ahora todo lo que necesitamos es llamar a la función de control de ventana de datos Retrieve () después de configurar el objeto de transacción..
Eso es todo.
A continuación muestro la captura de pantalla final después de recuperar los datos de Caché con Appeon PowerBuilder utilizando ODBC.
Gracias.
Artículo
Eduardo Anglada · 29 mar, 2022
¡Hola a todos!
Hoy quiero hablar sobre nuestro proyecto y utilizar el tema del conjunto de datos para el concurso.
Nuestra intención nunca fue ser unos gestores de datos, sobre todo porque a veces nuestros preciosos datos significan mucho para nosotros, pero no para el resto del mundo.

Queremos ir un paso más allá y permitir que los usuarios encuentren el conjunto de datos perfecto para satisfacer sus necesidades.
Nuestro proyecto es un puente entre la comunidad de la Ciencia de Datos y la Comunidad de Desarrolladores, utilizando InterSystems IRIS para lograr esta misión.
La imagen que aparece a continuación es la página inicial para vosotros. Se puede buscar cualquier tema y ver los conjuntos de datos relacionados con él.
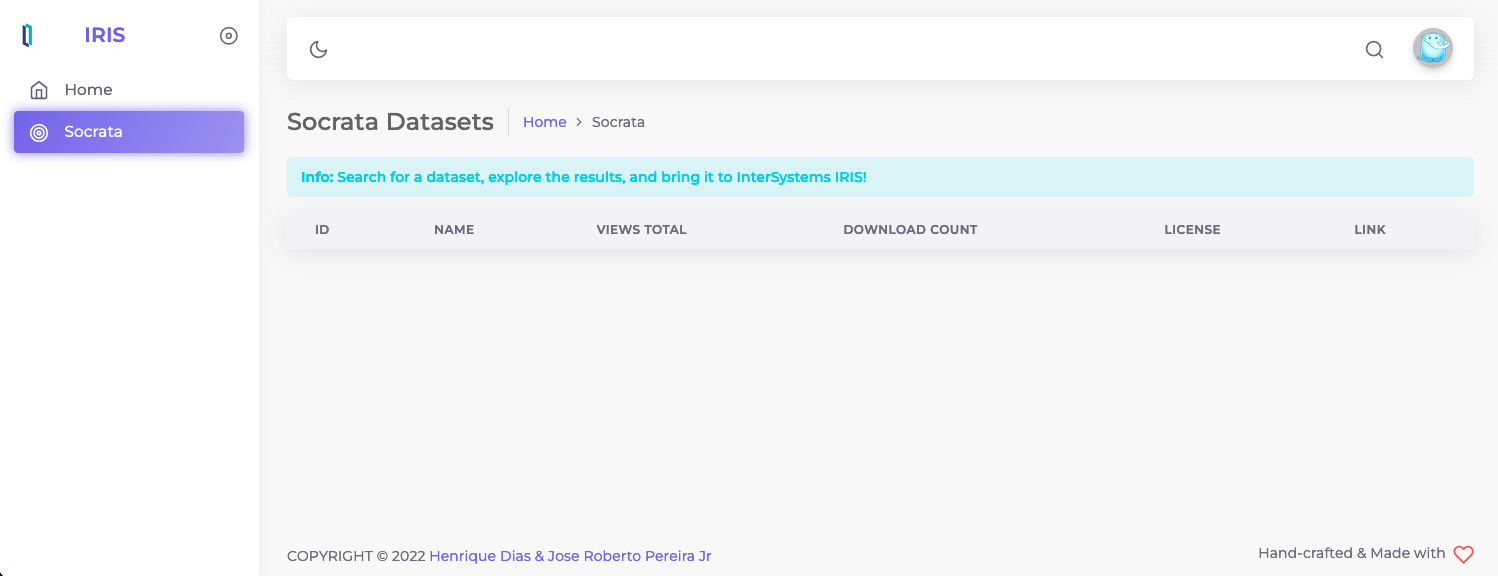
Solo hay que hacer clic en el icono de la lupa al lado de la mascota de Socrata, aparecerá la barra de búsqueda y ahí se puede buscar cualquier tema.
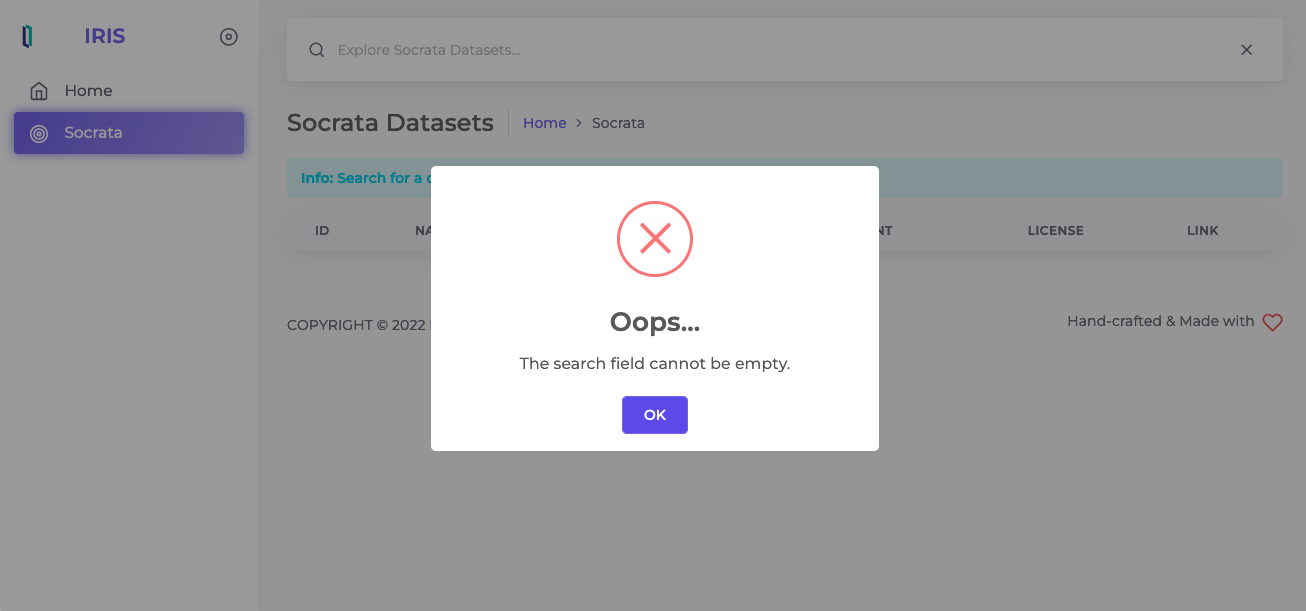
Pero recordad que es obligatorio buscar algo, no se puede buscar "nada". Si no se escribe nada, aparecerá una imagen de alerta similar a esta:
Si se busca un tema específico, se completará la tabla de datos con los conjuntos de datos relacionados con él.
Este es un video de demostración, que explica cómo elegir un conjunto de datos, buscar los detalles, bajarlo e instalarlo.
¡Espero que os resulte útil!
Artículo
Alberto Fuentes · 1 sep, 2022
¡Hola desarrolladores!
Quizá os hayáis encontrado con escenarios donde no tenéis que implementar un repositorio FHIR, sino por ejemplo reenviar peticiones FHIR, gestionar las respuestas y tal vez realizar modificaciones o extraer algunos valores por el camino. Aquí encontraréis algunos ejemplos que pueden implementarse con *InterSystems IRIS For Health* o *HealthShare Health Connect*.
En estos ejemplos he utilizado producciones de interoperabilidad con el [FHIR Interoperability Adapter](https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=HXFHIR_fhir_adapter) y los mensajes tipo `HS.FHIRServer.Interop.Request`.
Si por el contrario estáis interesados en implementar un repositorio FHIR, no dejéis de ver el [Webinar](https://comunidadintersystems.com/webinar-comienza-a-trabajar-con-fhir) que hicimos en su día.
Un primer escenario podría ser tener que construir una petición FHIR de cero quizá a partir de un fichero o tal vez una consulta SQL y a continuación reenviarlo a un servicio FHIR externo:
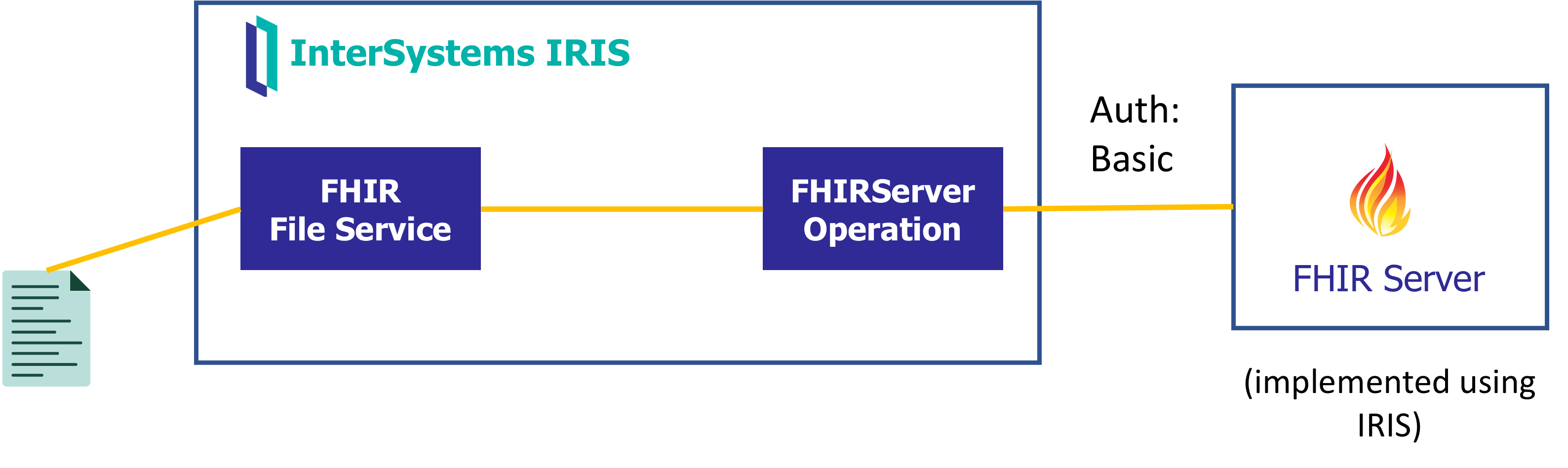
Otro escenario podría ser hacer de pasarela de peticiones / respuestas FHIR contra un repositorio externo, gestionando el paso de tokens OAuth.
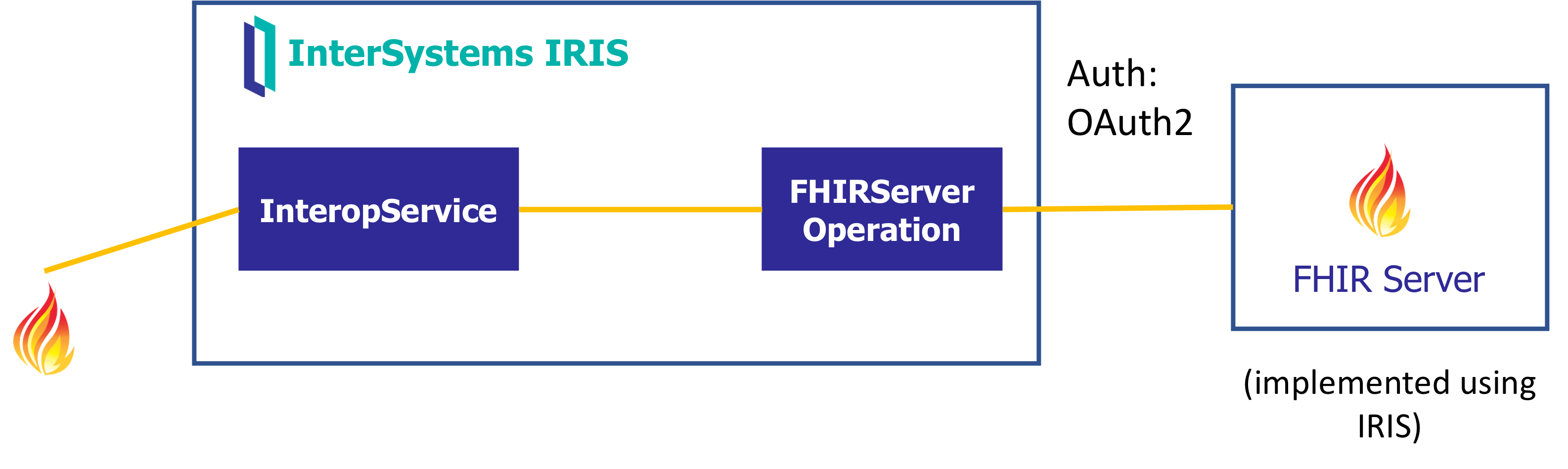
Y finalmente podríamos pensar quizá en recibir peticiones FHIR para reenviarlas a un servicio FHIR externo, pero pudiendo extraer cierta información o manipulando algunos campos el camino.
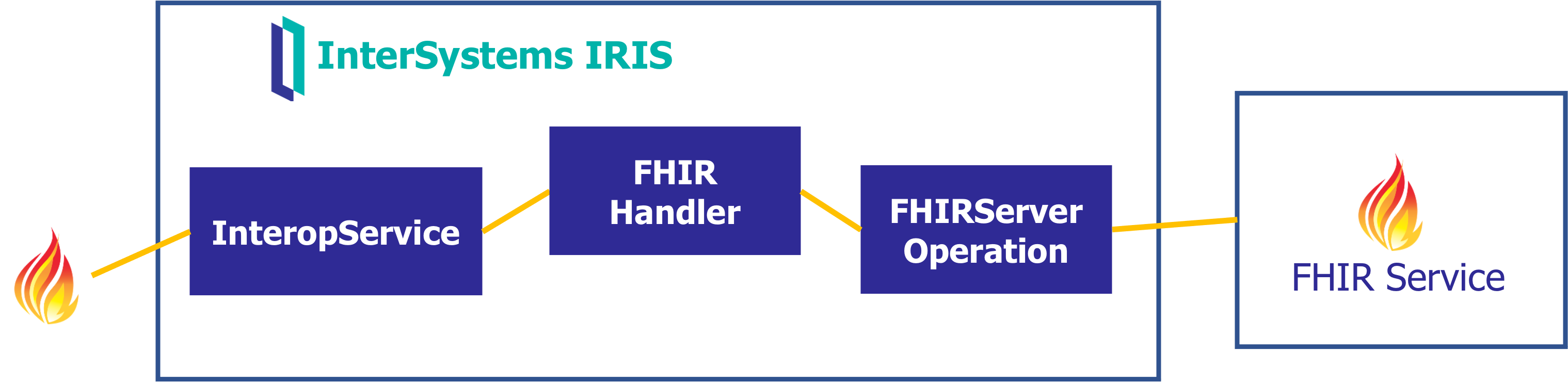
Los detalles de la implementación los encontraréis en la aplicación Open Exchange :)
¡Espero que os sirva!
Anuncio
Esther Sanchez · 24 feb, 2023
Lo habíais pedido... ¡y ya está aquí!
Estamos encantados de compartir con vosotros los cambios que hemos hecho en la página de perfil de los miembros de la Comunidad:
Biografía del usuario
Publicaciones fijas
En primer lugar, hemos añadido una nueva sección llamada "Biografía del usuario" en la parte superior de los perfiles de cada persona. Para cada miembro de la Comunidad, permite:
acceder rápidamente a su página de Certificaciones de InterSystems
ver cuándo se dio de alta en la Comunidad
saber más sobre la persona, si ha añadido una biografía
Así que... Ya podéis añadir vuestra biografía en la sección "Información Básica" – solo tenéis que hacer clic en "Añadir biografía" y escribir lo que queráis contar a los demás sobre vosotros!:
En esa misma página podéis añadir vuestros perfiles en redes sociales, para que puedan contactaros otros miembros de la Comunidad:
Este es el ejemplo de un perfil con la biografía completada:
Publicaciones fijas en vuestro perfil
La segunda mejora es la posibilidad de fijar las publicaciones de las que estéis más orgullosos o queráis mostrar a los demás.
Podéis elegir 3 de vuestras publicaciones para fijarlas en la parte superior de vuestra página de perfil. Solo tenéis que hacer clic en "Seleccionar las publicaciones" y hacer clic en la chincheta que aparece a la derecha del título. Las publicaciones fijadas serán las primeras que se verán cuando alguien abra vuestro perfil.
Del mismo modo, si queréis dejar de fijar una publicación, solo tenéis que pasar el ratón por encima de la chincheta de la publicación fijada y hacer clic de nuevo sobre ella.
¡Así de fácil!
Esperamos que os gusten estas novedades. Hay más mejoras en camino, así que estad atentos a la Comunidad :D
Artículo
Pierre-Yves Duquesnoy · 7 mayo, 2020
Esta serie de artículos describe el uso del Python Gateway para InterSystems IRIS. Python Gateway permite acceder a toda la potencia de las librerías Python y las herramientas de Aprendizaje máquina (IAML) desde InterSystems IRIS y:
Ejecutar cualquier código Python
Transferir datos de forma transparente desde IRIS a Python
Construir procesos de interoperabilidad inteligente con el Adaptador de Python
Guardar, revisar, modificar y restaurar el contexto de Python desde InterSystems IRIS
Índice
El plan para la serie hasta el momento (sujeto a cambios).
Parte I: Resumen, panorama e introducción <-- usted está aquí
Parte II: Instalación y resolución de problemas
Parte III: Funcionalidades básicas
Parte IV: Adaptador de Interoperabidad
Parte V: Cómo ejecutar una función
Parte VI: Puerta de enlace dinámica
Parte VII: Puerta de enlace proxy
Parte VIII: Casos de usos y conjunto de herramientas de aprendizaje automático
Resumen
El aprendizaje automático (ML, por el inglés "Machine Learning") es el estudio de algoritmos y modelos estadísticos para realizar de forma efectiva una tarea específica sin usar instrucciones específicas, confiando en vez en patrones e inferencias.
Los algoritmos y modelos de aprendizaje automático son cada vez más utilizados. Hay una variedad de motivos para eso, pero en el fondo pasa por la economía, la simplicidad y la creación de resultados útiles. ¿El clustering (análisis de grupos) o incluso el modelado de redes neuronales son nuevas tecnologías? Por supuesto que no, pero hoy en día ya no es necesario escribir cientos de líneas de código para ejecutar uno.
Las herramientas están evolucionando. Si bien aún no tenemos herramientas de IA/ML totalmente basadas en una interfaz gráfica, observamos en este caso el mismo desarrollo que vimos con muchas otras tecnologías informáticas, en particular las herramientas de Inteligencia empresarial (BI) (desde escribir código a utilizar frameworks a soluciones configurables basadas en interfaces gráficas). Ya pasamos el punto de escribir código y actualmente usamos frameworks para configurar y calcular los modelos.
Otras mejoras, como uso de modelos pre-entrenados (“transfer learning” en inglés) , en el que el usuario final sólo debe terminar el entrenamiento de un modelo genérico con sus datos propios más específicos, también simplifican el proceso de adaptación. Estos avances hacen empezar en ML sea mucho más asequible tanto para individuos como para empresas.
Por otro lado, hoy en día recolectamos más datos sobre cada transacción que realiza una empresa. Con una plataforma de datos unificada, como InterSystems IRIS, es posible acceder a toda esta información de forma inmediata para usarla como alimento para los modelos predictivos.
Gracias al otro gran motor, la nube, procesar cargas de trabajo de IA/ML se vuelve más fácil que nunca. Permite consumir los recursos necesarios sin costes de adquisición, y gracias a la paralelización masiva que ofrecen las plataformas de nube, podemos ahorrar tiempo de implementación de una solución.
¿Pero qué pasa con los resultados? Aquí hay cierta complejidad. Existen muchas herramientas para construir un modelo, de las cuales hablaré más adelante, y no siempre es fácil construir un buen modelo, ¿pero qué viene después? Extraer valor comercial de un modelo tampoco es una tarea trivial. La raíz del problema es la separación de flujos de datos analíticos y transaccionales. Cuando entrenamos al modelo, generalmente lo hacemos con datos históricos de un repositorio analitico. Pero el mejor lugar para usar este modelo es en el corazón del procesamiento transaccional. ¿De qué sirve el mejor modelo de detección de fraude si lo ejecutamos una vez por día? Las transacciones fraudulentas ya habrán sido aceptadas y será demasiado tarde para tomar acción. Necesitamos entrenar un modelo en base a datos históricos, pero también necesitamos aplicar el modelo en tiempo real sobre los nuevos datos entrantes, para que nuestro proceso empresarial pueda actuar en base a las predicciones que realiza el modelo.
MLToolkit
MLToolkit es un completo conjunto de herramientas que apunta a hacer exactamente eso: unir los modelos predictivos a los entornos transaccionales, para que pueda aprovechar los modelos que construya directamente dentro de su proceso empresarial. El Python Gateway es parte del MLToolkit y brinda integración con un lenguaje Python.
Panorama
Antes de continuar, quisiera describir varias herramientas y bibliotecas para Python, que usaremos más tarde.
Herramientas
Python es un lenguaje de programación interpretado, de propósito general y de alto nivel. La principal ventaja del lenguaje es el gran número de librerías matemáticas, de aprendizaje automático e inteligencia artificial. Al igual que ObjectScript, se trata de un lenguaje orientado a objetos y dinámico. Los siguientes artículos asumen que el lector tiene una familiaridad básica con el lenguaje. Si desea comenzar a aprender, le recomiendo comenzar con la documentación.
Para nuestros siguientes ejercicios instale Python 3.6.7 64 bit.
IDE: Yo uso PyCharm, apuesto a que hay muchos otros. Si usa Atelier, existe Eclipse para desarrolladores Python.
Bloc de notas: en lugar del IDE, puede escribir y compartir sus scripts en un bloc de notas web. El más popular es Jupyter.
Bibliotecas
A continuación encontrará una lista (incompleta) de bibliotecas usadas para aprendizaje automático.
Numpy es el paquete fundamental para programación científica con Python.
Pandas es una biblioteca que brinda estructuras de datos y herramientas de análisis de datos que son fáciles de usar y potentes.
Matplotlib es una biblioteca gráfica 2D parar figuras en varios formatos del entorno o impresos.
Seaborn es una biblioteca de visualización de datos basada en matplotlib. Brinda una interfaz de alto nivel para crear gráficos estadísticos atractivos e informativos.
Sklearn es una biblioteca para aprendizaje automático.
XGBoost es una biblioteca optimizada para mejorar los gradientes distribuidos, diseñada para tener ser altamente eficiente, flexible y portátil. Implementa algoritmos de aprendizaje automático bajo el framework Gradient Boosting.
Gensim es una biblioteca para el modelado de temas no supervisado y procesamiento de lenguaje natural.
Keras es una API de alto nivel para redes neuronales, escrito en Python y capaz de ejecutarse sobre TensorFlow, CNTK o Theano.
Tensorflow es una plataforma de aprendizaje automático de extremo a extremo de código abierto.
PyTorch es una plataforma de aprendizaje profundo similar a Tensorflow pero enfocada en Python.
Nyoka genera PMML a partir de modelos de Python.
Resumen
Las tecnologías de inteligencia artificial y aprendizaje automático permiten a las empresas ser más efectivas y más adaptables. Hoy esas tecnologías se están volviendo más fáciles de usar e implementar. Comience a investigar sobre tecnologías de AI/ML y cómo puede ayudar a su organización a crecer y prosperar. Aquí hay ejemplos, historias y casos de uso para casi cualquier industria. No se pierda la oportunidad de usar hoy las tecnologías del futuro.
¿Cómo seguir?
En la siguiente sección, instalaremos el Python Gateway. ¡No olvide registrarse para el próximo seminario web (detalles a continuación)!
Enlaces
Python Gateway
Instalar Python 3.6.7 64 bits
Documentación/tutorial Python
Artículo
Pierre-Yves Duquesnoy · 16 feb, 2023
Como recordaréis, en el [Global Summit de 2022](https://learning.intersystems.com/course/view.php?id=2077) y en el [webinar de lanzamiento de la versión 2022.2](https://www.intersystems.com/resources/whats-new-in-intersystems-iris-2022-2/), presentamos una nueva e interesante funcionalidad para incluir en las soluciones analíticas de InterSystems IRIS. [Columnar Storage](https://learning.intersystems.com/course/view.php?id=2112) introduce una forma alternativa de almacenar los datos de las tablas SQL, que ofrece un aumento significativo en la velocidad de las consultas analíticas. Lanzada por primera vez como funcionalidad experimental en 2022.2, la [última versión de prueba en 2022.3](https://community.intersystems.com/post/intersystems-publishes-developer-preview-5-intersystems-iris-iris-health-healthshare-health) incluye numerosas actualizaciones que pensamos merecen una publicación aquí.
### Un breve resumen
Si no estáis familiarizados con Columnar Storage, echad un vistazo a [este breve video](https://learning.intersystems.com/course/view.php?id=2112) o a esta sesión [del Global Summit 2022](http://learning.intersystems.com/course/view.php?id=2077). En resumen, vamos a codificar los datos de la tabla en fragmentos de 64 000 valores por columna utilizando un nuevo tipo de datos `$vector`. `$vector` es un tipo de datos exclusivamente interno (por ahora) que aprovecha los esquemas de codificación adaptativa para permitir el almacenamiento eficiente de datos tanto dispersos como compactos. El código también está optimizado para un grupo de operaciones `$vector` especializadas, como calcular conjuntos, agrupar y filtrar fragmentos enteros de 64 000 valores a la vez, aprovechando las instrucciones [SIMD](https://en.wikipedia.org/wiki/Single_instruction,_multiple_data) cuando sea posible.
Al realizar la consulta SQL, aprovechamos estas operaciones desarrollando un plan de consulta que también opera sobre estos fragmentos, lo que supone, como podéis imaginar, una reducción masiva de la cantidad de IO y del número de instrucciones ObjectScript necesarias para ejecutar la consulta, en comparación con el procesamiento clásico fila por fila. Por supuesto, las IOs individuales son mayores y las operaciones `$vector` son un poco más complejas que las equivalentes a un solo valor del mundo orientado a filas, pero las ganancias son enormes. Utilizamos el término planes de consulta *vectorizados* para las estrategias de ejecución que procesan datos $vector, procesando bloques enteros mediante una cadena de operaciones individuales rápidas.
### Simplemente más rápido
Y lo que es más importante, todo va más rápido. Hemos ampliado la comprensión del optimizador sobre los índices en columnas y ahora veréis que más consultas utilizan índices en columnas, incluso si algunos de los campos solicitados no se almacenan en un índice en columnas o mapa de datos. Además, veréis que combina índices en columnas y de mapa de bits en varios casos, lo que es muy útil si estáis empezando a introducir índices en columnas en un esquema existente.
El nuevo kit también incluye una serie de cambios más generales que mejoran el rendimiento, desde optimizaciones hasta operaciones `$vector` de bajo nivel pasando por algunas mejoras en el procesamiento de consultas y un conjunto más amplio de planes de consulta vectorizados que se podrán paralelizar. Algunas formas de cargar datos, por ejemplo a través de las sentencias `INSERT .. SELECT`, ahora también emplearán un modelo de búfer que ya utilizamos para generar índices y ahora permiten desarrollar tablas enteras con un rendimiento realmente alto.
### JOINs vectorizados
La funcionalidad más interesante que hemos añadido en esta versión es el soporte a JOINs vectorizados sobre datos en columas . En la versión 2022.2, cuando se querían combinar datos de dos tablas en una consulta, aún recurríamos a una estrategia sólida de combinación JOIN fila por fila, que funciona tanto con datos organizados en columnas como en filas. Ahora, cuando ambos extremos del JOIN se almacenan en un formato en columnas, utilizamos una nueva API del kernel para hacer combinaciones JOIN en la memoria, manteniendo su formato `$vector`. Este es otro importante paso hacia los planes de consulta totalmente vectorizados, incluso para las consultas más complejas.
A continuación presentamos un ejemplo de consulta que aprovecha las ventajas de la nueva función, efectuando un self-JOIN del conjunto de datos de taxis de Nueva York que ya hemos utilizado en [otras demos](https://github.com/bdeboe/isc-taxi-demo):
SELECT
COUNT(*),
MAX(r1.total_amount - r2.total_amount)
FROM
NYTaxi.Rides r1,
NYTaxi.Rides r2
WHERE
r1.DOLocationID = r2.PULocationID
AND r1.tpep_dropoff_datetime = r2.tpep_pickup_datetime
AND r2.DOLocationID = r1.PULocationID
AND r1.passenger_count > 2
AND r2.passenger_count > 2
En esta consulta se buscan pares de viajes con más de 2 pasajeros, en los que el segundo viaje comenzó donde terminó el primero, exactamente a la misma hora y en los que el segundo viaje llevó a uno de vuelta a donde comenzó el primero. No es un análisis muy útil, pero solo tenía una tabla real en este esquema y la clave JOIN compuesta lo hizo un poco menos sencillo. En el plan de consulta para esta sentencia, veréis fragmentos sobre como `Apply vector operation %VHASH` (para crear la clave JOIN compuesta) y `Read vector-join temp-file A`, que indica que nuestro nuevo ensamblador vectorizado está funcionando! Esto puede parecer un pequeño detalle trivial en un plan de consulta larga, pero implica una gran cantidad de ingeniería inteligente en el interior, y hay un gran número de proveedores de bases de datos en columnas que simplemente no permiten nada de esto e imponen severas restricciones en el diseño de su esquema, así que ¡únete a nosotros para participar en esto! :-)
Cuando el plan de consultas continúa para leer ese archivo temporal, es posible observar que aún queda algo de procesamiento fila por fila en el trabajo posterior a la combinación, lo que nos llevará a preguntarnos...
### ¿Qué sigue?
Columnar Storage sigue considerándose "experimental" en 2022.3, pero cada vez estamos más cerca de estar listos para la producción y de disponer de la vectorización completa de extremo a extremo para las consultas de múltiples tablas. Esto incluye el trabajo posterior a la combinación (mencionado anteriormente), un mayor soporte con el optimizador de consultas, una carga aún más rápida de las tablas en columnas y nuevas mejoras del combinador, como el soporte a la memoria compartida. En resumen: ahora es un momento excelente para probar todo esto por primera vez con el [conjunto de datos de taxis de Nueva York](https://github.com/bdeboe/isc-taxi-demo/) (ahora en [IPM](https://openexchange.intersystems.com/package/NY-Taxi-Demo) o con los [scripts de docker](https://github.com/bdeboe/isc-taxi-demo)) utilizando la Community Edition 2022.3, y así solo tendréis que hacer clic en "Run" cuando saquemos la versión 2023.1!
Si alguien está interesado en recibir más asesoramiento personalizado sobre cómo aprovechar el almacenamiento en columnas con sus propios datos y consultas, poneos en contacto conmigo o con vuestros consultores habituales, y quizá nos veamos en el [Global Summit 2023](https://www.intersystems.com/gs2023/) ;-).
Artículo
Eduardo Anglada · 10 mayo, 2021
Vamos a ver cómo usar el gestor de paquetes [ZPM](https://openexchange.intersystems.com/package/ObjectScript-Package-Manager) para instalar módulos de [Node.js.](https://nodejs.org/es/). Para poder usar Node.js primero tenemos que cargar la [API nativa de Node.js](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=BJSNAT)
El principio aplicado con ZPM es similar al de los módulos de Python y funciona perfectamente. Tal y como veremos en el ejemplo de [github](https://github.com/rcemper/Using-ZPM-for-Node.js) ZPM se encarga de todo!
En el ejemplo vamos a usar InterSystems IRIS con WebSockets de forma nativa como un [cliente](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&PRIVATE=1&SYSTEM=0&CLASSNAME=%25Net.WebSocket.Client) eco (devuelve el texto introducido). Existen varios ejemplos como [este](https://community.intersystems.com/post/websocket-client-iris-internal), o este [otro](https://openexchange.intersystems.com/package/IRIS-internal-WebSocket-Client) en los que se puede ver a IRIS actuando de cliente.
La lógica del ejemplo siempre es la misma, después de la inicialización automática del servicio de eco, se escribe un comando y se espera su respuesta:
* seleccionar el servidor eco (en nuestro caso usamos la opción 1)
* escribes el texto que se va a transmitir y añades una línea con el carácter * para indicar que ya no hay más texto
* las respuestas se ven con el comando **S**
* para detener el servicio y salir se emplea **X**
Aclaración: como el servicio se ejecuta en segundo plano su salida estándar no es visible, pero se escribe un archivo que puede ser volcado mediante el comando **L**
## Requisitos previos
Asegúrate de tener instalado git y el escritorio Docker.
## Instalación
Clona el repositorio en un directorio local:
$ git clone https://github.com/rcemper/Using-ZPM-for-Node.js
Abre el terminal en este directorio y ejecuta:
$ docker-compose build
(esto puede llevar algún tiempo hasta que se complete)
Ejecuta el contenedor IRIS con este proyecto:
$ docker-compose up -d
## Cómo probarlo
Utilizando el Terminal de IRIS:
$ docker-compose exec iris iris session iris "##class(rccjs.WSockNodeJs).Run()"
*** Welcome to WebSocket by Node.js Native API Demo ***
********* Node.js process id = 1650 *********
Known Hosts (*=Exit) [1]:
1 ws://echo.websocket.org/
2 --- server 2 ----
3 --- server 3 ----
select (1): 1 ==> ws://echo.websocket.org/
#
Enter text to get echoed from WebSocketClient Service
Terminate with * at first position
or get generated text by %
or append new text with @
1 hello this is connected over
2 IRIS Native API for Node.js
3 -----------------
4 *
Select action for WebClient Service
New EchoServer (E), New Text(N), Send+Listen(S)
Show Log (L), Exit+Stop WsClient(X) [S] :s
%%%%%%%%%%%%%%%%%%%%%%%%%%
******* 3 Replies *******
1 hello this is connecte over
2 IRIS Native API for Node.js
3 -----------------
Select action for WebClient Service
New EchoServer (E), New Text(N), Send+Listen(S)
Show Log (L), Exit+Stop WsClient(X) [S]: L
%%%%%%%%%%%%%%%%%%%%%%%%%%
platform = linux: ubuntu
*****************************
*** no IRIS host defined ****
Connect to IRIS on: localhost
Successfully connected to InterSystems IRIS.
*** wait 3sec for request ***
******* Startup done ********
*** wait 3sec for request ***
*** wait 3sec for request ***
*** wait 3sec for request ***
*** wait 3sec for request ***
echoserver: ws://echo.websocket.org/
** Lines to process: 3 **
********* next turn *********
* WebSocket Client connected *
****** Client is ready ******
Line: 1 text> 'hello this is connecte over '
Received: 1 > 'hello this is connecte over '
Line: 2 text> 'IRIS Native API for Node.js '
Received: 2 > 'IRIS Native API for Node.js '
Line: 3 text> '----------------- '
Received: 3 > '----------------- '
******* lines sent: 3 ******
*** replies received: 3 ****
*** wait 3sec for request ***
*** wait 3sec for request ***
Select action for WebClient Service
New EchoServer (E), New Text(N), Send+Listen(S)
Show Log (L), Exit+Stop WsClient(X) [S] :x
%%%%%%%%%%%%%%%%%%%%%%%%%%
La carga del API nativa para Node.js se realiza en el iris.script:
do $System.OBJ.LoadDir("/opt/irisapp/src","ck")
zn "USER"
zpm "load /opt/irisapp/ -v":1:1
Que a su vez es ejecutado en el Dockerfile.
Este artículo está inspirado en [otro](https://community.intersystems.com/post/deploying-intersystems-iris-embedded-python-solutions-zpm-package-manager) de @Evgeny.Shvarov, pero en este caso se aplica a los módulos de **Node.js** y usa [este](https://community.intersystems.com/post/websocket-client-js-iris-native-api-docker-micro-server) ejemplo de la API nativa de IRIS para Node.js.
Artículo
Muhammad Waseem · 23 ago, 2022
Supongamos que has desarrollado tu propia aplicación web con las tecnologías de InterSystems y ahora quieres realizar una validación de Captcha en el lado del cliente para saber si el usuario es humano o no y hacerla más segura. Existen algunos frameworks modernos para abordar el problema de Captcha, pero la mayoría de ellos necesita acceso a Internet para generar códigos y, a veces, son complejos de implementar. Toma esto como un ejemplo básico, teniendo en cuenta que el reconocimiento de imágenes se ha vuelto demasiado bueno. Por eso hoy en día se tiende a ver más Captchas de reconocimiento de patrones que de solo lectura. (Por ejemplo, hacer clic en todas las imágenes que tengan un escaparate). Si necesitas algo más complejo, adelante, desarrolla, mejora este código y compártelo. Sigue leyendo para descubrir cómo usar este ejemplo básico:
Demo.Captcha clase
Usando esta clase, puedes crear archivos de imagen Captcha en un directorio físico para que se muestren en tu aplicación. Ten en cuenta que el directorio de imágenes donde se crean las imágenes debe estar disponible para que tu aplicación web acceda a esas imágenes. Para crear la imagen Captcha, llama al siguiente método pasando el nombre completo del archivo como parámetro:
Crear archivo de imagen
Set tCount = $Increment(^CacheTemp("CAPTCHA",0)) Set tPath = "C:\InterSystems\Ensemble201710\CSP\user\images\captcha\"If '##class(%File).DirectoryExists(tPath) { Set tSC = ##class(%File).CreateDirectoryChain(tPath) } Set tFileName = %session.SessionId_tCount_".bmp" Set tFullName = tPath_tFileNameSet tCaptcha = ##class(Demo.Captcha).CreateImage(tFullName) Write tCaptcha,!
En tu Sistema > Administración de seguridad > Aplicaciones web > Editar aplicación web, ten en cuenta que el CSP Files Physical Path es el mismo en el código anterior añadiendo la pieza "\images\captcha\".
Después de ejecutar el código anterior para crear las imágenes Captcha, echa un vistazo a esa ruta. Verás así todas las imágenes Captcha generadas (ten en cuenta que necesitarás un objeto %session):
El método CreateImage() de la clase Demo.Captcha también devolverá el código Captcha generado que te permitirá validar contra el código Captcha introducido por el usuario en tu aplicación web.
Ejemplo
Para hacerlo más sencillo, he preparado un archivo CSP simple que representa una imagen Captcha y la valida. Puedes importar el archivo XML adjunto y verificar y cambiar las rutas según sea necesario para que coincidan con tu aplicación web CSP.
Instalando en el namespace USER, abre Studio e importa el archivo XML;
Abre el archivo captcha.csp en tu navegador;
Haz clic en el botón "cambiar imagen" para crear y mostrar una nueva imagen Captcha si es necesario;
Introduce el código de la imagen en el cuadro de entrada en blanco;
Haz clic en el botón validar y verifica el mensaje;
Importación de clases
Abre Studio;
Selecciona el namespace USER;
Ve a Herramientas->Importar local y selecciona el archivo captcha.xml que has descargado;
Importa esas clases según la imagen siguiente;
Cambia la ruta de las imágenes Captcha según tu aplicación web CSP;
Abre los archivos captcha.csp en tu navegador web haciendo clic en el botón Ver página web , en Studio;
Si necesitas cambiar la imagen, haz clic en el botón Cambiar imagen;
Mira el directorio de imágenes Captcha;
Introduce el código Captcha en el cuadro de entrada en blanco y haz clic en validar;
Mira los resultados;
Repite estos pasos tanto como quieras;
No dudéis en poneros en contacto conmigo si tenéis alguna duda.
Espero que os resulte útil.
Artículo
Ricardo Paiva · 12 dic, 2022
@José.Pereira y yo hemos creado un proyecto del que queremos hablar en este artículo.
¿Qué es IRIS RAD Studio?
IRIS RAD Studio es nuestra idea de una solución low-code para hacer más fácil la vida del desarrollador.
¿Por qué?
¿Y por qué no? Las aplicaciones low-code se han hecho muy populares últimamente. La imagen de abajo muestra el "Cuadrante mágico" ofrecido por la consultora Gartner para plataformas de aplicaciones low-code empresariales, y que muestra lo interesante que es este mercado.
RESTForms2
RESTForms2 es una de las partes principales de nuestro proyecto. Como describió @Eduard.Lebedyuk en este artículo, RESTForms es un backend genérico REST API para aplicaciones web modernas.
RESTForms - REST API para tus clases
Características
Al usar RESTForms2, las clases persistenes heredadas de dc.irisrad.FormAdaptor consiguen automáticamente una forma CRUD (Create, Read, Update, Delete). Las formas disponibles se muestran en la página de inicio.
Cada forma, además de las características básicas de CRUD, también tiene:
Búsqueda general
Búsqueda condicional y avanzada para un campo específico
Creación de filtros combinados
Agrupación
Exportación de Datagrid a Excel
Además de la generación automática de formas basadas en JSON, ofrecida por RESTForms2, una cosa que queremos ofrecer a los usuarios es nuestro Import Wizard - Asistente de Importación.
Import Wizard
La funcionalidad presentada anteriormente con el proyecto iris-analytics-package permite a cualquier usuario:
Importar un fichero CSV
Crear una clase persistente según el fichero importado
Crear un cubo para ser utilizado por InterSystems Analytics
Generar un dashboard (cuadro de mando) de muestra, basado en los datos
¿Qué pasaría si también se pudiera editar este fichero? Añadir nueva información, editar la información en CSV, o incluso eliminar lineas innecesarias?!
¡Con IRIS RAD Studio se puede! 😃
Cómo crear nuevas clases
Imagina que tienes clases existentes que heredan de dc.irisrad.FormAdaptor, ahora puedes aprovechar las funcionalidades de RAD Studio.
Para clases nuevas, creamos un endpoint en el que se pone la clase deseada en formato JSON... y voilà!
Ejemplo:
{ "name": "My.ClassName", "displayFormName": "My tasks", "displayProperty": "text", "fields": [{ "name":"text", "displayName":"Task name", "type":"%Library.String", "required": false },{ "name":"taskDate", "displayName":"Task date", "type":"%Library.TimeStamp" },{ "name":"important", "displayName":"Important", "type":"%Library.Boolean" },{ "name":"completed", "displayName":"Completed", "type":"%Library.Boolean" }]}
Bastante fácil, ¿no?!
Mmmm... pero puedes estarte preguntando: "¿Qué pasa si no estoy tan familiarizado con JSON, o si no entiendo nada de la parte técnica?"
Calma, calma... ¡IRIS RAD Studio también ofrece una interfaz gráfica para la creación de nuevas clases!
Cómo crear nuevas clases - Wizard
La idea de low-code es precisamente evitar que el código sea escrito por el propio usuario. ¡Y eso incluye una clase y su propiedad en formato JSON!
La interfaz ofrecida por RAD Studio permite crear el nombre de la clase y ofrece una descripción que tendrá el formulario.
Al hacer clic en el botón Save se abre un cuadro de datos en el que puedes definir las propiedades de tu clase, o si prefieres llamarlo así, las columnas de tu tabla.
Una vez que terminas de definir, haz clic en Compile, y estás listo para usar tu nueva forma!
Plan
Creemos que este proyecto tiene mucho potencial para ser explorado. Si es bien recibido por la Comunidad, nos gustaría explorar sus posibilidades y crear un itinerario con todos.
Así, tendremos un producto que atienda cada vez mejor la necesidad general.
Descarga
https://openexchange.intersystems.com/package/iris-rad-studio
iris-rad-studio en el Gran Premio de InterSystems
https://openexchange.intersystems.com/contest/12
Artículo
Alberto Fuentes · 23 feb, 2023
Hola a todos!
Durante un proyecto necesitábamos poder definir temas sobre los que publicar mensajes, y crear diferentes subscriptores que recibiesen esos mensajes de forma asíncrona. Necesitábamos además que fuese lo más sencillo posible y que se pudiese utilizar directamente en InterSystems IRIS.
A modo de experimento os paso este [iris-pubsub](https://openexchange.intersystems.com/package/iris-pubsub).
# Infraestructura
Está construido sobre las funcionalidades de interoperabilidad de InterSystems IRIS, necesita tener una producción en marcha.
La primera vez que lo arranquemos definimos cuántas particiones queremos dedicar para atender mensajes. A mayor número de particiones, mayor capacidad. Por cada partición creará un Business Service y un Business Operation.
```
do ##class(dc.PubSub.API).AddPartitions(3)
```

# Temas (topics)
A continuación podemos crear temas o *topics* sobre los que queramos publicar mensajes. Opcionalmente se puede definir un `PartitionKey` que servirá para indicar qué campo del mensaje que publicamos se utilizará para decidir la partición lo gestionará. Los mensajes que se publican en una misma partición se procesan en orden.
Aquí creamos un tema llamado `simple/topic` e indicamos que la `PartitionKey` será el campo `patientId` de los mensajes que se publiquen.
```objectscript
set topic = ##class(dc.PubSub.API).CreateTopic("simple/topic", { "PartitionKey": "patientId" })
```
# Subscriptores
Ahora podemos crear subscriptores para el tema que hemos creado. Cuando se publique un mensaje en el tema o *topic* los subscriptores serán notificados.
Crearemos dos subscriptores que son dos *classmethod* de clases en ObjectScript. Una posible mejora sería poder definir subscriptores que fuesen endpoints HTTP.
```objectscript
do ##class(dc.PubSub.API).CreateSubscription("simple/topic", { "Protocol": "ClassMethod", "Endpoint": "USER:dc.PubSub.Test.Simple:Subscriber"})
do ##class(dc.PubSub.API).CreateSubscription("simple/topic", { "Protocol": "ClassMethod", "Endpoint": "USER:dc.PubSub.Test.Simple:Sub2"})
```
En este caso, los subscriptores son muy sencillos y sólo van a registrar información en la global `^zlog`:
```objectscript
ClassMethod Subscriber(payload As %String)
{
set obj = {}.%FromJSON(payload)
set ^zlog($i(^zlog)) = "["_$classname()_":Subscriber] Received: "_obj.%ToJSON()
}
ClassMethod Sub2(payload As %String)
{
set obj = {}.%FromJSON(payload)
set ^zlog($i(^zlog)) = "["_$classname()_":Sub2] Received: "_obj.%ToJSON()
}
```
# Publicar mensajes
Hemos creado un tema llamado `simple/topic` y hemos definido dos subscriptores. Vamos a publicar un par de mensajes:
```objectscript
do ##class(dc.PubSub.API).Publish("simple/topic", {"patientId": "HA98744455", "data": "dummy" } )
do ##class(dc.PubSub.API).Publish("simple/topic", {"patientId": "12TFFFHM88", "data": "dummy999" } )
```
Los mensajes podemos verlos en las trazas de interoperabilidad de IRIS:
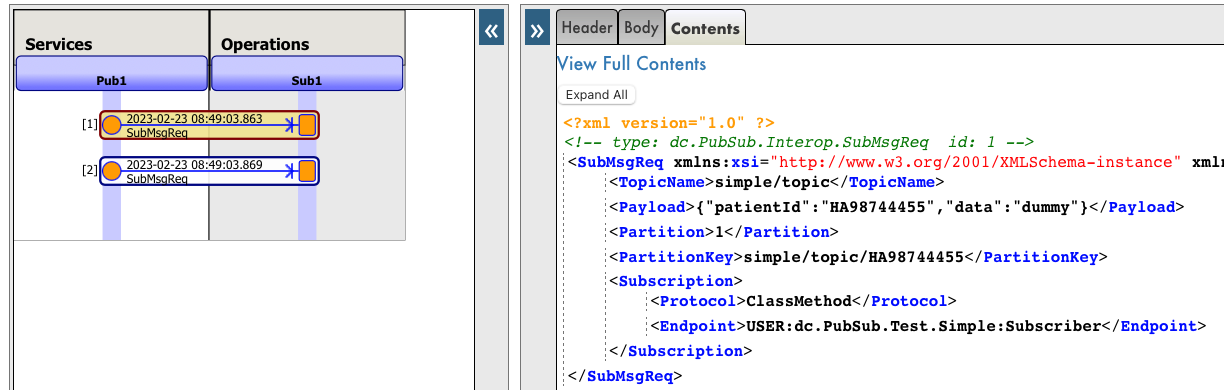
Y si comprobamos la global `^zlog` donde los subscriptores guardan información, veremos lo siguiente:
```objectscript
USER>zw ^zlog
^zlog=4
^zlog(1)="[dc.PubSub.Test.Simple:Subscriber] Received: {""patientId"":""HA98744455"",""data"":""dummy""}"
^zlog(2)="[dc.PubSub.Test.Simple:Sub2] Received: {""patientId"":""HA98744455"",""data"":""dummy""}"
^zlog(3)="[dc.PubSub.Test.Simple:Subscriber] Received: {""patientId"":""12TFFFHM88"",""data"":""dummy999""}"
^zlog(4)="[dc.PubSub.Test.Simple:Sub2] Received: {""patientId"":""12TFFFHM88"",""data"":""dummy999""}"
```
¡Y esto es todo! Cualquier sugerencia o *pull-request* es bienvenida :)
Una pregunta, ¿se podría conseguir lo mismo con las clases ya preconstruidas en IRIS, en el paquete EnsLib.PubSub? Mmm exactamente lo mismo no lo sé, pero en el pasado hemos utilizado `EnsLib.PubSub` para alguna funcionalidad que necesitábamos pero terminábamos desarrollando nuestras propias clases para gestionar la complejidad que nos hacía falta.
De todas maneras, aún estamos experimentando con esta utilidad :)
Artículo
Eduardo Anglada · 5 abr, 2022
Si estás implementando más de un entorno/región/nube/cliente, inevitablemente te encontrarás con el problema de la gestión de la configuración.
Aunque todas (o solo varias de) tus implementaciones pueden compartir el mismo código fuente, algunas partes, como la configuración (ajustes, contraseñas) son diferentes de una implementación a otra y se deben gestionar de alguna manera.
En este artículo, intentaré ofrecer varios consejos sobre ese tema. Y comentaré principalmente las implementaciones de los contenedores.
##
## Unificación del código base
Antes de comenzar con la gestión de la configuración, hablemos de la unificación del código base. El problema es el siguiente: el código base _debe_ pretender, por lo general, confluir en una sola versión. Por supuesto, en cualquier momento, tendrás varias versiones de tu código base: la versión DEV con todas las nuevas características, la versión TEST con un código de prueba adicional, la versión PROD, y así sucesivamente. Y eso está _bien_ porque, en este ejemplo, los cambios se fusionan en una versión a lo largo del tiempo. Varias ramas de DEV se convierten en una rama de TEST y así sucesivamente.
El problema comienza cuando tenemos varias versiones en el paso final de nuestro *pipeline* de implementación. Por ejemplo, el cliente ABC pidió una característica particular XYZ, y ahora hay dos versiones del código base PROD - con la característica XYZ y sin ella. Esto es problemático ya que duplica inmediatamente nuestros tiempos de creación y el consumo de recursos. Claro, algunas veces no hay manera de hacerlo. Sin embargo, supongamos que tienes este tipo de divergencias persistentes en el código base. En ese caso, quizá merezca la pena investigar si se pueden agrupar en una sola versión; en este caso, la característica XYZ se activa o no cuando se inicia.
Dicho esto, vamos a la gestión de la configuración.
##
## Gestión de la configuración
¿Qué queremos?
* No almacenar todas las configuraciones posibles en un solo contenedor (es inseguro para uno, y aún debemos elegir de alguna manera qué configuración aplicar para otro)
* No crear un contenedor en cada configuración (simplifica el *pipeline* de CD)
Necesitamos transferir la configuración (ajustes, información confidencial, ...) durante el arranque de InterSystems IRIS y asignarla a nuestra aplicación.
## Transferencia de la configuración
Hay varias maneras de transferir la configuración al inicio.
### Variables de entorno
Rápido y fácil. En caso de que quieras almacenar todo en una variable, utiliza JSON para realizar la serialización. Además, recuerda que Windows tiene un límite de 32K caracteres en las variables de entorno (megabytes en Linux). Para recuperar variables de entorno utiliza [$SYSTEM.Util.GetEnviron("ENV\_VAR\_NAME")](https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&CLASSNAME=%25SYSTEM.Util#GetEnviron). La principal ventaja es la facilidad de implementación. Además, verifica tu herramienta CD - por lo general, tiene algún tipo de soporte para variables de entorno durante la ejecución del *pipeline*, algunas veces con soporte de la información confidencial para que sea más seguro.
### Archivos montados
La configuración puede ser un archivo montado al inicio. La ventaja es que no tiene límites en la longitud. La desventaja es que no todas las ofertas de la nube son compatibles con los archivos montados, e incluso si lo hacen, la gestión de archivos puede ser más complicada que la gestión de las variables de entorno. Ten en cuenta que los archivos siempre se pueden recuperar de las capas antiguas de un contenedor, aunque se hayan eliminado en una capa posterior.
### Combinación en CPF
La configuración del sistema se puede transferir mediante un [Archivo Combinado de Configuración](https://docs.intersystems.com/iris20212/csp/docbook/DocBook.UI.Page.cls?KEY=ACMF). Y es una funcionalidad integrada. Desventaja: El Archivo de Combinación CPF no se encarga de la configuración a nivel de la aplicación.
### Docker/Información confidencial del CSP
Docker puede montar información confidencial como un archivo dentro de un contenedor. Las ofertas en la nube a menudo ofrecen una funcionalidad similar. Utilízalo en vez de los archivos sin formato para mejorar la seguridad.
## Análisis de la configuración
Bien, ya transmitiste la configuración dentro de un contenedor. ¿Y ahora qué? ¿Cómo la analizamos?
Hay varias opciones:
### %ZSTART
[%ZSTART](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSTU_CUSTOMIZE_STARTSTOP) incluye tu código personalizado, que se ejecuta cuando se inicia el sistema. Por ejemplo:
SYSTEM
try {
new $namespace
set $namespace = "USER"
// apply configuration
set $namespace = "%SYS"
} catch ex {
zn "%SYS"
do ex.Log()
}
quit 1
Es importante tener en cuenta que %ZSTART se debe probar _completamente_, ya que InterSystems IRIS no se iniciará (o se comportará de forma errática) si la rutina %ZSTART devuelve un error.
Ahora ya estás preparado para aplicar tu configuración.
La forma de almacenar/aplicar la configuración a nivel de la aplicación depende, naturalmente, de la aplicación, pero [La configuración predeterminada del sistema](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ECONFIG_other#ECONFIG_other_default_settings_purpose ""){.editor-rtfLink} está disponible si utilizas la interoperabilidad. Incluso si no utilizas las producciones de interoperabilidad, puedes utilizar la configuración predeterminada del sistema, ya que está disponible para todo el mundo (siempre y cuando la interoperabilidad esté activada en un *namespace*).
Para crear una nueva configuración, ejecuta:
Set setting = ##class(Ens.Config.DefaultSettings).%New()
Set setting.ProductionName = production
Set setting.ItemName = itemname
Set setting.HostClassName = hostclassname
Set setting.SettingName = settingname
Set setting.SettingValue = settingvalue
Set setting.Description = description
Set sc = setting.%Save()
Y para recuperar la configuración, llama a cualquiera:
set sc = ##class(Ens.Config.DefaultSettings).%GetSetting(production, itemname, hostclassname, "", settingname, .settingvalue)
set settingvalue = ##class(Ens.Director).GetProductionSettingValue(production, settingname, .sc)
Los *hosts* de interoperabilidad reciben su configuración automáticamente al iniciar el trabajo del host empresarial.
## Resumen
Es fundamental que tu aplicación se pueda configurar cuando se implementa en más de un servidor. Puede ser bastante fácil en la primera parte del ciclo de desarrollo, pero se irá complicando a medida que la aplicación crezca. InterSystems IRIS ofrece varias herramientas que se pueden utilizar para configurar el estado de tu aplicación durante el arranque.
.
¿Cómo gestionas las implementaciones múltiples?
.
Artículo
Dmitry Maslennikov · 17 feb, 2023
Os presento mi nuevo proyecto: irissqlcli, REPL (Read-Eval-Print Loop) para InterSystems IRIS SQL.
Resaltado de sintaxis
Sugerencias (tablas, funciones)
+20 formatos de salida
Soporte a stdin
Salida a ficheros
Instalación con pip
pip install irissqlcli
O se puede ejecutar con docker
docker run -it caretdev/irissqlcli irissqlcli iris://_SYSTEM:SYS@host.docker.internal:1972/USER
Conexión a IRIS
$ irissqlcli iris://_SYSTEM@localhost:1972/USER -W
Password for _SYSTEM:
Server: InterSystems IRIS Version 2022.3.0.606 xDBC Protocol Version 65
Version: 0.1.0
[SQL]_SYSTEM@localhost:USER> select $ZVERSION
+---------------------------------------------------------------------------------------------------------+
| Expression_1 |
+---------------------------------------------------------------------------------------------------------+
| IRIS for UNIX (Ubuntu Server LTS for ARM64 Containers) 2022.3 (Build 606U) Mon Jan 30 2023 09:05:12 EST |
+---------------------------------------------------------------------------------------------------------+
1 row in set
Time: 0.063s
[SQL]_SYSTEM@localhost:USER> help
+----------+-------------------+------------------------------------------------------------+
| Command | Shortcut | Description |
+----------+-------------------+------------------------------------------------------------+
| .exit | \q | Exit. |
| .mode | \T | Change the table format used to output results. |
| .once | \o [-o] filename | Append next result to an output file (overwrite using -o). |
| .schemas | \ds | List schemas. |
| .tables | \dt [schema] | List tables. |
| \e | \e | Edit command with editor (uses $EDITOR). |
| help | \? | Show this help. |
| nopager | \n | Disable pager, print to stdout. |
| notee | notee | Stop writing results to an output file. |
| pager | \P [command] | Set PAGER. Print the query results via PAGER. |
| prompt | \R | Change prompt format. |
| quit | \q | Quit. |
| tee | tee [-o] filename | Append all results to an output file (overwrite using -o). |
+----------+-------------------+------------------------------------------------------------+
Time: 0.012s
[SQL]_SYSTEM@localhost:USER>
$ irissqlcli --help
Usage: irissqlcli [OPTIONS] [URI] [USERNAME]
Options:
-h, --host TEXT Host address of the IRIS instance.
-p, --port INTEGER Port number at which the IRIS instance is listening.
-U, --username TEXT Username to connect to the IRIS instance.
-u, --user TEXT Username to connect to the IRIS instance.
-W, --password Force password prompt.
-v, --version Version of irissqlcli.
-n, --nspace TEXT namespace name to connect to.
-q, --quiet Quiet mode, skip intro on startup and goodbye on
exit.
-l, --logfile FILENAME Log every query and its results to a file.
--irissqlclirc FILE Location of irissqlclirc file.
--auto-vertical-output Automatically switch to vertical output mode if the
result is wider than the terminal width.
--row-limit INTEGER Set threshold for row limit prompt. Use 0 to disable
prompt.
-t, --table Display batch output in table format.
--csv Display batch output in CSV format.
--warn / --no-warn Warn before running a destructive query.
-e, --execute TEXT Execute command and quit.
--help Show this message and exit.
o en el modo Python Embebido (requiere que %Service_CallIn esté habilitado)
$ irissqlcli iris+emb:///USER
Server: IRIS for UNIX (Ubuntu Server LTS for ARM64 Containers) 2022.2 (Build 368U) Fri Oct 21 2022 16:39:41 EDT
Version: 0.1.0
[SQL]irisowner@/usr/irissys/:USER>
Soporta stdin, así que se pueden canalizar algunos ficheros SQL con un grupo de consultas SQL y comandos irissqcli. Por ejemplo, este comando producirá 3 ficheros en diferentes formatos (de entre más de 20 formatos disponibles).
$ cat <<EOF | irissqlcli iris://_SYSTEM:SYS@localhost:1972/USER
.mode csv;
tee -o test.csv;
select top 10 TABLE_SCHEMA,TABLE_NAME
from information_schema.tables
order by TABLE_SCHEMA,TABLE_NAME;
notee;
.mode latex;
tee -o test.tex;
select top 10 TABLE_SCHEMA,TABLE_NAME
from information_schema.tables
order by TABLE_SCHEMA,TABLE_NAME;
notee;
.mode html;
tee -o test.html;
select top 10 TABLE_SCHEMA,TABLE_NAME
from information_schema.tables
order by TABLE_SCHEMA,TABLE_NAME;
notee;
EOF
Además, es posible ejecutar un terminal web con docker
docker run -d --name irissqlcli \
--restart always \
-p 7681:7681\
caretdev/irissqlcli-web irissqlcli iris://_SYSTEM:SYS@host.docker.internal:1972/USER
http://localhost:7681/
Y con docker-compose
version: '3'
services:
iris:
image: intersystemsdc/iris-community
ports:
- 1972
- 52773
command:
- -a
- '##class(Security.Users).UnExpireUserPasswords("*")'
cli:
image: caretdev/irissqlcli-web
ports:
- 7681:7681
environment:
- IRIS_HOSTNAME:iris
- IRIS_PORT=1972
- IRIS_NAMESPACE=USER
- IRIS_USERNAME=_SYSTEM
- IRIS_PASSWORD=SYS
Este artículo ha sido etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Dani Fibla · 17 sep, 2020
¡Hola Comunidad!
Me gustaría compartir con vosotros mi experiencia sobre la depuración con Atelier.
Estoy desarrollando una API REST y quiero adjuntar un proceso cuando llamo a la API desde una herramienta cliente REST, por ejemplo Postman. El objetivo es inspeccionar valores del HEADER y el BODY de la solicitud HTTP durante el proceso de depuración.
Voy a demostrarlo usando una clase del namespace SAMPLES.
1 - Abre Atelier
2 - Abre tu clase de servicio REST
3- Ve al método relacionado con la URI que necesitas depurar
4- Agrega un HANG (sugiero de entre 10 y 15 segundos) que te permita poder adjuntar el proceso Caché / Ensemble. Observa la siguiente imagen:
5 - Cambia la vista al modo Depuración (DEBUG)
6 - Ve a Run->Debug Configurations->Application Atelier Attach
7 - Haz clic con el botón derecho en "Application Atelier Attach" y haz clic en New para configurar tu lista de proceso de servidor
8 - Configura tu lista de procesos del servidor Caché/Ensemble/Intersystems IRIS
9 - Haz clic en Apply
10 - Pásate a tu herramienta cliente REST
11 - Cuando llames a tu REST Api, retrasará (HANG) el proceso durante la cantidad de segundos que habías programado previamente
12 - En este momento, necesitarás volver a Atelier
13 - En Atelier, haz clic en Run->Debug Configuration->Application Atelier Attach y elige el proceso de la lista que configuraste
14 - Haz clic en Apply y cierra esta ventana
También puedes usar este pequeño botón como atajo:
En este punto, podrás depurar e inspeccionar tu código cuando lo necesites.
Por favor, no dejes de compartir tu experiencia y/o comentarios.
¡Gracias!
Artículo
David Reche · 2 feb, 2021
.png)
InterSystems IRIS es una excelente opción para desarrollar proyectos de aprendizaje automático (Machine Learning, ML), en escenarios de operaciones con datos masivos, debido a las siguientes razones:
1. Soporta el uso de shards para escalar el repositorio de datos, tal y como MongoDB por ejemplo.
2. Soporta la creación de cubos analíticos, y si unimos esto más el "sharding" nos permite tener volumen y rendimiento.
3. Soporta la recopilación de datos de forma planificada o en tiempo real, con una gran variedad de opciones de adaptadores de datos.
4. Permite automatizar todo el proceso de de-duplicación, utilizando lógica en Python u ObjectScript.
5. Permite organizar y automatizar el flujo de datos al repositorio, usando flujos visuales (BPL) y el Lenguaje para la transformación de datos (DTL).
6. Soporta el escalamiento automático avanzado, mediante Docker (IaC) y los scripts de Cloud Manager.
7. Soporta la carga de librerías ObjectScript *in provisioning*, mediante ZPM.
8. Dispone de interoperabilidad con Python y R para realizar ML en tiempo real.
9. Permite utilizar un motor AutoML, denominado IntegratedML para ejecutar el mejor algoritmo para el conjunto de datos indicados.
10. Permite crear análisis posteriores a la ejecución, como predicciones y clasificaciones de AutoML, salidas desde los procesos cognitivos de Python y R, tablas dinámicas de Inteligencia empresarial (BI), todo ello con visualizaciones propias o de terceros.
11. Permite crear vistas e informes avanzados con JReport.
12. Permite maximizar la reutilización y monetización de los datos con el API Management incluido.