Limpiar filtro
Artículo
Esther Sanchez · 31 jul, 2019
¡Hola a tod@s, programadores deseosos de aprender!
Hace poco, un desarrollador que está empezando a utilizar la tecnología de InterSystems me preguntó cómo podía aprender en la Comunidad de Desarrolladores, para mejorar sus conocimientos de programación.
Y me pareció una muy buena pregunta. A la que podía responder con varias opciones. Por eso decidí escribir este artículo, esperando que sea de utilidad no solo para ese desarrollador, sino para otros muchos más.
Así que la pregunta era... ¿Cómo aprender sobre Intersystems IRIS e IRIS for Health en la Comunidad de Desarrolladores?
Etiquetas "Principiante" y "Tutorial"
Para empezar, puedes echar un vistazo a los artículos con las etiquetas "Principiante" y "Tutorial" en español o "Beginner" y "Tutorial" en inglés.
Los desarrolladores, al escribir sus artículos, ponen esas etiquetas cuando describen conceptos básicos de la tecnología de InterSystems o cuando redactan tutoriales sobre alguna funcionalidad de InterSystems IRIS.
Puedes encontrar un listado con todas las etiquetas en el menú "Publicaciones", aquí:
Etiqueta "Mejores prácticas"
Además de las etiquetas "Principiante" y "Tutorial", si quieres acceder a contenido más avanzado, puedes seguir la etiqueta "Mejores prácticas". Cada semana, el equipo de gestión de productos de InterSystems elige un artículo de entre los publicados esa semana, y lo etiqueta como "Best Practices". Así que, si te suscribes a esa etiqueta, recibirás una "Práctica recomendada" de InterSystems cada semana.
Votos y Visualizaciones
Otra forma de descubrir publicaciones interesantes es prestar atención a lo que votan los desarrolladores de la Comunidad y a los contenidos que más les interesan. Porque si a un miembro de la Comunidad le resulta útil una publicación, le puede dar un voto positivo. Así que podemos considerar que las publicaciones con más votos son las más útiles e interesantes. En la página principal de la Comunidad, puede elegir el filtro de ordenación de las publicaciones "Por votos" y le aparecerán las más votadas primero.
También, podría ser muy útil echar un vistazo a las publicaciones con el mayor número de visitas, porque no todos los miembros de la Comunidad votan (además de que hay que estar registrado para votar), pero sí se registran todas las visitas. Así que las publicaciones con más visitas no solo son las más populares, sino que seguramente también serán muy útiles e interesantes.
Y, a menudo, las preguntas "Con respuesta aceptada" pueden ser útiles, porque resuelven un problema. Se pueden filtrar las publicaciones con respuestas aceptadas e incluso combinar varios filtros: publicaciones con respuestas aceptadas, ordenadas por votos o publicaciones con respuestas aceptadas, ordenadas por visitas. En todas esas publicaciones, seguro que encontrará respuestas muy útiles e interesantes.
¡Y pregunta!
Por supuesto, la mejor forma de aprender y adquirir experiencia con la tecnología es practicando, encontrando problemas y resolviéndolos. Así que si le surge alguna duda, pregunte a través de la Comunidad de Desarrolladores - a veces le llegará la respuesta nada más pulsar el botón "Publicar"!
Recursos para principiantes
Para terminar, mencionar los recursos disponibles para desarrolladores principiantes en la tecnología de InterSystems (todos en inglés): el área de Documentación, el área de Formación online, el sandbox (entorno seguro para pruebas controladas) Pruebe InterSystems IRIS, el área de cursos y los vídeos del canal de YouTubes.
Si alguno conoce otras formas de aprender más sobre la tecnología de InterSystems, puede contárnoslas en los comentarios a este artículo.
¡Gracias!
Anuncio
Esther Sanchez · 20 ene, 2020
¡Hola Comunidad!
Tenemos un nuevo vídeo, disponible en el canal de YouTube de la Comunidad de Desarrolladores en inglés, grabado por @Benjamin.DeBoe:
⏯ InterSystems IRIS y Python
Benjamin De Boe, Product Manager de InterSystems, nos habla sobre Python, InterSystems IRIS y la API nativa de Python.
¡Esperamos que os resulte útil! 👍🏼
Podeis probar InterSystems IRIS aquí: https://www.intersystems.com/try
Anuncio
Esther Sanchez · 14 feb, 2020
¡Hola desarrolladores!
InterSystems Learning Services, el Servicio de Formación de InterSystems, se complace en anunciar el lanzamiento de Data Points, un nuevo podcast que incluirá conversaciones con expertos sobre las nuevas funcionalidades de los productos de InterSystems. Y también revisará los temas más innovadores y de actualidad en la industria tecnológica.
¡Ya hay disponibles tres episodios! El vídeo más abajo contiene un breve resumen de cada episodio, pero podéis entrar en https://datapoints.intersystems.com para escuchar los tres podcasts y suscribiros a través de una app. En los próximos días, publicaremos cada episodio por separado.
Os podéis suscribir al podcast en:
Apple Podcasts
Spotify
Stitcher
Google Play
Y contadnos qué os parece este nuevo servicio, si tenéis alguna pregunta o alguna sugerencia para los próximos podcasts.
Anuncio
Esther Sanchez · 17 feb, 2020
¡Hola desarrolladores!
Como sabéis, la Comunidad de Desarrolladores de InterSystems en español es una comunidad activa, en la que todos los días se publican artículos, vídeos, anuncios o preguntas. Y siempre se aprende sobre código y programación. Ya lleva varios meses funcionando de maravilla. Y ahora... ¡necesitamos vuestra ayuda! Ayuda de expertos en la tecnología de InterSystems, como vosotros.
¿Nos echáis una mano? Necesitamos gente que revise la traducción al español de los artículos en inglés que se publican en la Comunidad internacional. Son artículos con trucos, recomendaciones, mejores prácticas...
¿Cómo es el proceso? Muy fácil:
Te enviamos el listado de artículos pendientes de revisar
Te asignas el artículo o los artículos que quieres revisar
Lo ponemos en modo borrador a tu nombre en la Comunidad
Lo revisas
Lo publicas a tu nombre
Si alguien hace alguna pregunta sobre el contenido del artículo, respondes
Puedes revisar artículos todas las semanas, cada 15 días... o cuando puedas. ¡Toda colaboración es bien recibida!
Nota.- los artículos ya están traducidos al español, solo hay que revisar que la traducción esté bien 👍
Por cada artículo que publiques, obtendrás puntos en Global Masters, el programa de fidelización de InterSystems. Y los puntos se pueden canjear por premios y regalos, ¡claro!
Así que... ¿te animas a compartir tu conocimiento y convertirte en un #ReferenteInterSystems?
Puedes contactar con nosotros aquí: Quiero revisar artículos >>
Artículo
Alberto Fuentes · 3 mar, 2020
Hola a todos!
Os comparto el código que utilizamos en una sesión práctica del último InterSystems Iberia Summit en Barcelona sobre el desarrollo de una aplicación simple Angular utilizando InterSystems IRIS como backend.
En la aplicación de ejemplo:
Se importan datos desde un dataset público y se almacena en InterSystems IRIS.
Se crean APIs REST automáticas utilizando RESTForms2.
Se construye una aplicación Angular 8 app para consumir los datos desde InterSystems IRIS.
Todas las instrucciones están incluidas en el repositorio GitHub (podéis acceder desde Open Exchange). Excelente.
Muchas gracias por la información compartida Alberto ;)
Anuncio
Esther Sanchez · 14 abr, 2020
¡Hola Comunidad!
Os traemos un nuevo vídeo, disponible en el Canal de YouTube de la Comunidad de Desarrolladores en inglés:
InterSystems y Python: Primeros pasos
La plataforma de datos InterSystems IRIS soporta dos APIs de Python que ofrecen acceso directo a las bases de datos de InterSystems IRIS via tablas relacionales (PyODBC) o almacenamiento multidimensional (Native API):
PyODBC permite que tu aplicación, de forma rápida, recupere, actualice y elimine datos
La Native API para Python permite a tu aplicación acceder directamente a la estructura de datos subyacente dentro de InterSystems IRIS (los globals), así como llamar a métodos y rutinas de ObjectScript.
Echa un vistazo al video para revisar las formas de conectar tu aplicación con la plataforma de datos InterSystems IRIS.
También puedes seguir los pasos de este ejercicio en la página de formación de InterSystems, para usar PyODBC y la Native API para Python y conectarla con InterSystems IRIS: learning.intersystems.com.
Esperamos que os resulte útil
Artículo
Kurro Lopez · 16 jun, 2020
En mi anterior artículo, revisamos los posibles casos de uso para macros, así que pasemos ahora a un ejemplo más completo de usabilidad de macros. En este artículo diseñaremos y crearemos un sistema de registro.
Sistema de registro
El sistema de registro es una herramienta útil para monitorear el trabajo de una aplicación que ahorra mucho tiempo durante la depuración y el monitoreo. Nuestro sistema constaría de dos partes:
Clase de almacenamiento (para registros de anotaciones)
Conjunto de macros que agregan automáticamente un nuevo registro al registro
Clase de almacenamiento
Vamos a crear una tabla de lo que necesitamos almacenar y especificar cuándo se pueden obtener estos datos, durante la compilación o en tiempo de ejecución. Esto será necesario cuando trabaje en la segunda parte del sistema: macros, donde buscaremos tener tantos detalles registrables como sea posible durante la compilación:
Información
Obtenido durante
Tipo de evento
Compilación
Nombre de clase
Compilación
Nombre del método
Compilación
Argumentos pasados a un método
Compilación
Número de línea en el código fuente de cls
Runtime
Número de línea en el código int generado
Runtime
Nombre de usuario
Runtime
Date/Time
Runtime
Mensaje
Runtime
direccion IP
Runtime
Vamos a crear una clase App.Log que contenga las propiedades de la tabla anterior. Cuando se crea un objeto App.Log, las propiedades de UserName, TimeStamp y ClientIPAddress se completan automáticamente.
App.Log class:
Class App.Log Extends %Persistent
{
/// Type of event
Property EventType As %String(MAXLEN = 10, VALUELIST = ",NONE,FATAL,ERROR,WARN,INFO,STAT,DEBUG,RAW") [ InitialExpression = "INFO" ];
/// Name of class, where event happened
Property ClassName As %String(MAXLEN = 256);
/// Name of method, where event happened
Property MethodName As %String(MAXLEN = 128);
/// Line of int code
Property Source As %String(MAXLEN = 2000);
/// Line of cls code
Property SourceCLS As %String(MAXLEN = 2000);
/// Cache user
Property UserName As %String(MAXLEN = 128) [ InitialExpression = {$username} ];
/// Arguments' values passed to method
Property Arguments As %String(MAXLEN = 32000, TRUNCATE = 1);
/// Date and time
Property TimeStamp As %TimeStamp [ InitialExpression = {$zdt($h, 3, 1)} ];
/// User message
Property Message As %String(MAXLEN = 32000, TRUNCATE = 1);
/// User IP address
Property ClientIPAddress As %String(MAXLEN = 32) [ InitialExpression = {..GetClientAddress()} ];
/// Determine user IP address
ClassMethod GetClientAddress()
{
// %CSP.Session source is preferable
#dim %request As %CSP.Request
If ($d(%request)) {
Return %request.CgiEnvs("REMOTE_ADDR")
}
Return $system.Process.ClientIPAddress()
}
}
Macros de registro
Por lo general, las macros se almacenan en archivos * .inc separados que contienen sus definiciones. Los archivos necesarios se pueden incluir en clases usando el comando Include MacroFileName, que en este caso se verá de la siguiente manera: Include App.LogMacro.
Para comenzar, definamos la macro principal que el usuario agregará al código de su aplicación:
#define LogEvent(%type, %message) Do ##class(App.Log).AddRecord($$$CurrentClass, $$$CurrentMethod, $$$StackPlace, %type, $$$MethodArguments, %message)
Esta macro acepta dos argumentos de entrada: Tipo de evento y Mensaje. El usuario define el argumento Mensaje, pero el parámetro Tipo de evento requerirá macros adicionales con diferentes nombres que identificarán automáticamente el tipo de evento:
#define LogNone(%message) $$$LogEvent("NONE", %message)
#define LogError(%message) $$$LogEvent("ERROR", %message)
#define LogFatal(%message) $$$LogEvent("FATAL", %message)
#define LogWarn(%message) $$$LogEvent("WARN", %message)
#define LogInfo(%message) $$$LogEvent("INFO", %message)
#define LogStat(%message) $$$LogEvent("STAT", %message)
#define LogDebug(%message) $$$LogEvent("DEBUG", %message)
#define LogRaw(%message) $$$LogEvent("RAW", %message)
Por lo tanto, para realizar el registro, el usuario solo necesita colocar la macro $$$LogError("Additional message")
en el código de la aplicación.Todo lo que necesitamos hacer ahora es definir las macros $$$CurrentClass, $$$CurrentMethod, $$$StackPlace, $$$MethodArguments.Comencemos con las tres primeras:
#define CurrentClass ##Expression($$$quote(%classname))
#define CurrentMethod ##Expression($$$quote(%methodname))
#define StackPlace $st($st(-1),"PLACE")
%classname, %methodname
las variables se describen en la documentacion. La función $stack devuelve el número de línea del código INT. Para convertirlo en un número de línea CLS, podemos usar este código.
Usemos el paquete %Dictionary para obtener una lista de argumentos de métodos y sus valores. Contiene toda la información sobre las clases, incluidas las descripciones de los métodos. Estamos particularmente interesados en la clase %Dictionary.CompiledMethod y su propiedad FormalSpecParsed, que es una lista:
$lb($lb("Name","Classs","Type(Output/ByRef)","Default value "),...)
correspondiente a la firma del método. Por ejemplo:
ClassMethod Test(a As %Integer = 1, ByRef b = 2, Output c)
tendrá el siguiente valor FormalSpecParsed:
$lb(
$lb("a","%Library.Integer","","1"),
$lb("b","%Library.String","&","2"),
$lb("c","%Library.String","*",""))
Necesitamos que la macro $$$MethodArguments se expanda en el siguiente código (para el método Test):
"a="_$g(a,"Null")_"; b="_$g(b,"Null")_"; c="_$g(c,"Null")_";"
Para lograr esto, tenemos que hacer lo siguiente durante la compilación:
Obtenga un nombre de clase y un nombre de método
Abra una instancia correspondiente de la clase %Dictionary.CompiledMethod y obtenga su propiedad FormalSpec
Conviértalo en una línea de código fuente
Agreguemos los métodos correspondientes a la clase App.Log:
ClassMethod GetMethodArguments(ClassName As %String, MethodName As %String) As %String
{
Set list = ..GetMethodArgumentsList(ClassName,MethodName)
Set string = ..ArgumentsListToString(list)
Return string
}
ClassMethod GetMethodArgumentsList(ClassName As %String, MethodName As %String) As %List
{
Set result = ""
Set def = ##class(%Dictionary.CompiledMethod).%OpenId(ClassName _ "||" _ MethodName)
If ($IsObject(def)) {
Set result = def.FormalSpecParsed
}
Return result
}
ClassMethod ArgumentsListToString(List As %List) As %String
{
Set result = ""
For i=1:1:$ll(List) {
Set result = result _ $$$quote($s(i>1=0:"",1:"; ") _ $lg($lg(List,i))_"=")
_ "_$g(" _ $lg($lg(List,i)) _ ","_$$$quote(..#Null)_")_"
_$s(i=$ll(List)=0:"",1:$$$quote(";"))
}
Return result
}
Ahora definamos la macro $$$MethodArguments como:
#define MethodArguments ##Expression(##class(App.Log).GetMethodArguments(%classname,%methodname))
Caso de uso
A continuación, creemos una clase App.Use con un método de prueba para demostrar las capacidades del sistema de registro:
Include App.LogMacro
Class App.Use [ CompileAfter = App.Log ]
{
/// Do ##class(App.Use).Test()
ClassMethod Test(a As %Integer = 1, ByRef b = 2)
{
$$$LogWarn("Text")
}
}
Como resultado, la macro $$$LogWarn("Text") en el código int se convierte en la siguiente línea:
Do ##class(App.Log).AddRecord("App.Use","Test",$st($st(-1),"PLACE"),"WARN","a="_$g(a,"Null")_"; b="_$g(b,"Null")_";", "Text")
La ejecución de este código creará un nuevo registro de App.Log:
Mejoras
Después de haber creado un sistema de registro, aquí hay algunas ideas de mejora:
En primer lugar, existe la posibilidad de procesar argumentos de tipo objeto ya que nuestra implementación actual solo registra objetos oref.
Segundo, una llamada para restaurar el contexto de un método a partir de valores de argumentos almacenados.
Procesamiento de argumentos de tipo objeto
La línea que pone un valor de argumento en el registro se genera en el método ArgumentsListToString y tiene este aspecto:
"_$g(" _ $lg($lg(List,i)) _ ","_$$$quote(..#Null)_")_"
Realicemos una refactorización y muévala a un método GetArgumentValue separado que acepte un nombre y clase de variable (todo lo que sabemos de FormalSpecParsed) y genere un código que convertirá la variable en una línea. Usaremos el código existente para los tipos de datos, y los objetos se convertirán en JSON con la ayuda de los métodos SerializeObject (para llamar desde el código de usuario) y WriteJSONFromObject (para convertir un objeto en JSON):
ClassMethod GetArgumentValue(Name As %String, ClassName As %Dictionary.CacheClassname) As %String
{
If $ClassMethod(ClassName, "%Extends", "%RegisteredObject") {
// it's an object
Return "_##class(App.Log).SerializeObject("_Name _ ")_"
} Else {
// it's a datatype
Return "_$g(" _ Name _ ","_$$$quote(..#Null)_")_"
}
}
ClassMethod SerializeObject(Object) As %String
{
Return:'$IsObject(Object) Object
Return ..WriteJSONFromObject(Object)
}
ClassMethod WriteJSONFromObject(Object) As %String [ ProcedureBlock = 0 ]
{
Set OldIORedirected = ##class(%Device).ReDirectIO()
Set OldMnemonic = ##class(%Device).GetMnemonicRoutine()
Set OldIO = $io
Try {
Set Str=""
//Redirect IO to the current routine - makes use of the labels defined below
Use $io::("^"_$ZNAME)
//Enable redirection
Do ##class(%Device).ReDirectIO(1)
Do ##class(%ZEN.Auxiliary.jsonProvider).%ObjectToJSON(Object)
} Catch Ex {
Set Str = ""
}
//Return to original redirection/mnemonic routine settings
If (OldMnemonic '= "") {
Use OldIO::("^"_OldMnemonic)
} Else {
Use OldIO
}
Do ##class(%Device).ReDirectIO(OldIORedirected)
Quit Str
// Labels that allow for IO redirection
// Read Character - we don't care about reading
rchr(c) Quit
// Read a string - we don't care about reading
rstr(sz,to) Quit
// Write a character - call the output label
wchr(s) Do output($char(s)) Quit
// Write a form feed - call the output label
wff() Do output($char(12)) Quit
// Write a newline - call the output label
wnl() Do output($char(13,10)) Quit
// Write a string - call the output label
wstr(s) Do output(s) Quit
// Write a tab - call the output label
wtab(s) Do output($char(9)) Quit
// Output label - this is where you would handle what you actually want to do.
// in our case, we want to write to Str
output(s) Set Str = Str_s Quit
}
Una entrada de registro con un argumento de tipo objeto se ve así:
Restaurando el contexto
La idea de este método es hacer que todos los argumentos estén disponibles en el contexto actual (principalmente en la terminal, para la depuración). Para este fin, podemos usar el parámetro del método ProcedureBlock. Cuando se establece en 0, todas las variables declaradas dentro de dicho método permanecerán disponibles al salir del método. Nuestro método abrirá un objeto de la clase App.Log y deserializará la propiedad Argumentos.
ClassMethod LoadContext(Id) As %Status [ ProcedureBlock = 0 ]
{
Return:'..%ExistsId(Id) $$$OK
Set Obj = ..%OpenId(Id)
Set Arguments = Obj.Arguments
Set List = ..GetMethodArgumentsList(Obj.ClassName,Obj.MethodName)
For i=1:1:$Length(Arguments,";")-1 {
Set Argument = $Piece(Arguments,";",i)
Set @$lg($lg(List,i)) = ..DeserializeObject($Piece(Argument,"=",2),$lg($lg(List,i),2))
}
Kill Obj,Arguments,Argument,i,Id,List
}
ClassMethod DeserializeObject(String, ClassName) As %String
{
If $ClassMethod(ClassName, "%Extends", "%RegisteredObject") {
// it's an object
Set st = ##class(%ZEN.Auxiliary.jsonProvider).%ConvertJSONToObject(String,,.obj)
Return:$$$ISOK(st) obj
}
Return String
}
Así es como se ve en la terminal:
>zw
>do ##class(App.Log).LoadContext(2)
>zw
a=1
b=<OBJECT REFERENCE>[2@%ZEN.proxyObject]
>zw b
b=<OBJECT REFERENCE>[2@%ZEN.proxyObject]
+----------------- general information ---------------
| oref value: 2
| class name: %ZEN.proxyObject
| reference count: 2
+----------------- attribute values ------------------
| %changed = 1
| %data("prop1") = 123
| %data("prop2") = "abc"
| %index = ""
¿Que sigue?
La mejora potencial clave es agregar otro argumento a la clase de registro con una lista arbitraria de variables creadas dentro del método.
Conclusiones
Las macros pueden ser bastante útiles para el desarrollo de aplicaciones.
Preguntas
¿Hay alguna manera de obtener el número de línea durante la compilación?
Links
Part I. Macros
GitHub repository
Este artículo está etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Anuncio
Esther Sanchez · 6 mayo, 2020
¡Hola desarrolladores!
El segundo concurso de Programación con InterSystems IRIS ya ha terminado. ¡Gracias a todos los participantes!
Recibimos 7 apps excelentes y ya podemos anunciar los ganadores.
Un fuerte aplauso para estos desarrolladores y sus aplicaciones:
🏆 Nominación de los expertos - los ganadores han sido elegidos por un jurado especialmente formado para el concurso:
🥇 1er puesto y $2,000 para el proyecto iris-history-monitor de @Henrique.GonçalvesDias
🥈 2º puesto y $1,000 para el proyecto Production Manager de @Nikolay.Soloviev
🥉 3er puesto y $500 para el proyecto JSON-Filter de @Lorenzo.Scalese
🏆 Nominación de la Comunidad - las aplicaciones que recibieron el mayor número de votos:
🥇 1er puesto y $1,000 para el proyecto iris-history-monitor de @Henrique.GonçalvesDias
🥈 2º puesto y $500 para el proyecto simple-spellchecker de @Henry.HamonPereira
¡Enhorabuena a todos!
Y gracias de nuevo a todos los participantes por el esfuerzo e ingenio que habéis puesto en el concurso
¿Y qué más?
Hay una serie de concursos planificados para todo el año, así que ya podéis inscribiros al siguiente!
➡️ Echa un vistazo a los próximos concursos ¡Felicitaciones a todos los ganadores!
Artículo
Pierre-Yves Duquesnoy · 6 jul, 2020
Apache Spark se ha convertido rápidamente en una de las tecnologías más atractivas para la analítica de big data y el machine learning. Spark es un motor de procesamiento de datos generales, creado para usar con entornos de procesamiento en clúster. Su corazón es el RDD (Resilient Distributed Dataset), que representa un conjunto de datos distribuido con tolerancia a fallos, sobre el que se puede operar en paralelo entre los nodos de un clúster. Spark se implementa con una combinación de Java y Scala, por lo que viene como una biblioteca que puede ejecutarse sobre cualquier JVM. Spark también es compatible con Python (PySpark) y R (SparkR) e incluye bibliotecas para SQL (SparkSQL), machine learning (MLlib), procesamiento de gráficas (GraphX) y procesamiento de flujos (Spark Streaming).
El conector Spark de IRIS permite sacar el máximo provecho de las capacidades de la plataforma InterSystems IRIS mediante la optimización del throughput usando paralelización, y trasladando el trabajo de filtrado correspondiente a la base de datos, lo que minimiza la cantidad de datos que es necesario leer.
A continuación les presento mi intento de demostrar un "Hola mundo" de machine learning con Spark e IRIS ejecutándose localmente en un portátil. Les mostraré un par de ejemplos de machine learning(regresión lineal y clasificación naive Bayes) con Spark y una conexión a IRIS.
Una alternativa a la instalación local es hacer estas pruebas en un entorno proporcionado por InterSystems online en la plataforma de e-learning:
https://learning.intersystems.com/course/view.php?id=796
Los datos que usaremos aquí están disponibles en el repositorio github de ejemplos de InterSystems, y se pueden descargar como descrito en la documentación de producto:
https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ASAMPLES
Aquí, solo necesitamos una copia del conjunto de datos Iris, un clásico ejemplo de flores que se usa para las demostraciones de machine learning.
Configuración de Spark e IRIS local
A continuación, los requisitos de Instalación y la configuración local de los componentes, en un servidor Windows sin nada anterior:
Editor VSCode (Microsoft Visual Studio Core), como editor.
Cliente Git, (git for Windows): https://gitforwindows.org/
Java OpenJDK 1.8: https://adoptopenjdk.net/upstream.html?variant=openjdk8&jvmVariant=hotspot
Python 3.7.7
Apache Spark 2.4.5 pre-construido para Apache Hadoop 2.7
WinUtils
IRIS 2020.1 Community Edition
Configuración de Java OpenJDK 1.8
Después de descargar la versión OpenJDK 1.8 pre-compilada para Windows (https://adoptopenjdk.net/upstream.html?variant=openjdk8&jvmVariant=hotspot) en c:\openjdk, se tienen que definir 3 variables de entorno:
JAVA_HOME=C:\openjdk
PATH=$PATH;C:\OpenJDK\JRE\bin
_JAVA_OPTIONS=-Xmx512M -Xms512M
Descarga y configuración de Python
Al usar Apache spark versión 2.4 en esta configuración, es importante notar que pyspark 2.4 aún no soporta a python 3.8, por lo cual la versión que se descarga e instala es Python 3.7.7, usando el instalador para Windows diponible en:
https://www.python.org/downloads/windows/
Descarga de Spark y WinUtils
La descarga de Spark se hace desde el sitio https://spark.apache.org/downloads.html, escogiendo la versión spark-2.4.6-bin-hadoop2.7.tgz y se instala en c:\Spark, y a continuación, se definen estas variables de entorno:
SPARK_HOME=C:\spark
PATH=$PATH;c:\spark\bin
HADOOP_HOME=C:\spark
La utilidad WinUtils.EXE para esta versión de Spark esta disponible en: https://github.com/cdarlint/winutils
Se copia el WinUtils.EXE en c:\Spark\bin
Librerias Python y Validación de la instalación:
Para usar spark desde python, usaremos un editor “jupyter notebook” y la libreria findspark. Ambos se pueden instalar desde un command prompt con “pip”:
c:\>pip install findspark
c:\>pip install jupyter
C:\>pip install matplotlib
Ahora se puede validar la instalación de pyspark desde la línea de comando con pyspark. Debería ver una salida como esta:
Instalación de InterSystems IRIS y carga del dataset de ejemplo
Se descarga IRIS Community(“IRIS_Community-2020.1.0.215.0-win_x64”) del sitio web de InterSystems y se instala en C:\intersystems\iris.
El dataset de ejempl se puede descargar de github con git:
c:\dev>git clone https://github.com/intersystems/Samples-Data-Mining.git
Y se puede cargar en el namespace USER de IRIS desde un terminal, con una carga recursiva
USER>do $system.OBJ.LoadDir("c:\dev\","ck",1,1)
USER>do ##class(Build.DataMiningSample).Build()
Your input: c:\dev\Samples-Data-Mining
Copia de Librerías de IRIS para uso desde Spark
Para que las librerías del conector nativo spark de IRIS estén accesibles, el metodo que usamos aquí es copiar estas librerías de directorio de instalaión iris “c: y adjuntarlas al directorio c:\spark\jars:
intersystems-jdbc-3.1.0.jar
intersystems-spark-1.0.0.jar
El articulo y las muestras de código se han escrito en un notebook jupyter sobre IRIS. El notebook original para Caché (usa el driver JDBC que precede al conector nativo Spark) está disponible en GitHub: Machine learning con Spark y Caché. Cuando su entorno esté listo, puede ejecutar el bloc de notas y ejecutar todas las muestras de código directamente desde el mismo.
Primero usaremos findspark para hacer una prueba rápida para verificar que Spark está configurado correctamente y que podemos importarlo a nuestro entorno. Desde un prompt, se arranca con:
c:\dev>jupyter notebook
Cargar y examinar datos
Ahora crearemos una instancia de SparkSession y la usaremos para conectarnos a IRIS. SparkSession es el punto de partida para usar Spark. Lo usaremos para cargar el conjunto de datos Iris en un DataFrame de Spark. El DataFrame de Spark extiende la funcionalidad del RDD Spark original (discutido antes). Además de muchas optimizaciones, el DataFrame agrega la capacidad de acceder y manipular datos tanto a través de una interfaz de estilo SQL como con una lista de objetos.
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local")
spark = SparkSession.builder.config('spark.sql.warehouse.dir','file:///C:/spark/temp')
spark = SparkSession.builder.getOrCreate()
irisdf = spark.read.format("com.intersystems.spark") \
.option("url","IRIS://localhost:51773/USER") \
.option("user","_system") \
.option("password","SYS") \
.option("spark.sql.warehouse.dir","file:///C:/spark/temp") \
.option("dbtable","DataMining.IrisDataset").load()
Aquí podemos ejecutar un comando para mostrar las primeras 10 filas de datos de Iris como una tabla.
irisdf.show(10)
Por cierto, un sépalo es una hoja, generalmente verde, que sirve para proteger a una flor en su etapa de capullo, y luego para soportar físicamente la flor cuando se abre.
Podemos realizar una variedad de operaciones tipo SQL, por ejemplo encontrar el número de filas en las que PetalLength es mayor a 6.0, o encontrar los recuentos de las distintas especies:
irisdf.filter(irisdf["PetalLength"]>6.0).show()
irisdf.groupBy("Species").count().show()
Estas son las primeras 10 filas que se muestran como lista de Python de objetos de fila Spark:
irisdf.head(10)
El siguiente código accede a los datos de Iris a través de la interfaz de lista para crear un par de conjuntos que podamos usar con la biblioteca de creación de gráficas matplotlib. Lamentablemente Spark no tiene su propia biblioteca de creación de gráficas. El código crea un diagrama de dispersión que muestra PetalLength vs PetalWidth.
import matplotlib.pyplot as plt
#Recuperar una matriz de objetos de fila desde el DataFrame
items = irisdf.collect()
petal_length = []
petal_width = []
for item in items:
petal_length.append(item['PetalLength'])
petal_width.append(item['PetalWidth'])
plt.scatter(petal_width,petal_length)
plt.xlabel("Petal Width")
plt.ylabel("Petal Length")
plt.show()
Entrenamiento y prueba de un modelo de regresión lineal
Parece haber una relación lineal bastante fuerte entre PetalWidth y PetalLength. Supongo que eso no puede sorprender a nadie. Investiguemos la relación más de cerca con la biblioteca de machine learning de Spark. Entrenaremos un modelo simple de regresión lineal para que ajuste una línea a través de los datos. Cuando tengamos el modelo, podremos usarlo para predecir el largo de un pétalo de Iris en base a su ancho.
Este es un esquema de los pasos del siguiente código:
Crear un nuevo DataFrame y transformar la columna PetalWidth o "features" en el vector que requiere la biblioteca de Spark.
Dividir los datos de Iris al azar entre un conjunto de entrenamiento (70%) y uno de prueba (30%).
Usar los datos de entrenamiento para ajustar un modelo de regresión lineal, el machine learning.
Pasar los datos de prueba por el modelo y mostrar el resultado.
from pyspark.ml.regression import LinearRegression
from pyspark.ml.feature import VectorAssembler
# Transformar la(s) columna(s) de "Características" (Features) al formato vectorial correcto
df = irisdf.select('PetalLength','PetalWidth')
vectorAssembler = VectorAssembler(inputCols=["PetalWidth"],
outputCol="features")
data=vectorAssembler.transform(df)
# Dividir los datos entre conjuntos de entrenamiento y prueba.
trainingData,testData = data.randomSplit([0.7, 0.3], 0.0)
#Configurar el modelo.
lr = LinearRegression().setFeaturesCol("features").setLabelCol("PetalLength").setMaxIter(10)
# Entrenar el modelo con los datos de entrenamiento.
lrm = lr.fit(trainingData)
# Aplicar el modelo a los datos de prueba y mostrar sus predicciones de largo de pétalo (PetalLength).
predictions = lrm.transform(testData)
predictions.show()
La columna de predicción muestra el largo de pétalo pronosticado por el modelo. Podemos compararlo con los valores reales de la columna PetalLength.
Para evaluar el modelo, la siguiente parte del código calcula el error cuadrático medio (RMSE) para sus predicciones sobre los datos de prueba. Esto brinda una medida de la precisión del modelo. El código también recupera la pendiente e intersección con el eje vertical de la línea de regresión. Usaremos esto para agregar la línea de regresión a nuestro diagrama de dispersión anterior.
from pyspark.ml.evaluation import RegressionEvaluator
# recuperar la pendiente e intersección con el eje vertical de la línea de regresión del modelo.
slope = lrm.coefficients[0]
intercept = lrm.intercept
print("slope of regression line: %s" % str(slope))
print("y-intercept of regression line: %s" % str(intercept))
# Seleccionar (predicción, etiqueta verdadero) y calcular el error de la prueba
evaluator = RegressionEvaluator(
labelCol="PetalLength", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print("Root Mean Squared Error (RMSE) on test data = %g" % rmse)
En base a este valor de RMSE, no es totalmente claro para mí qué tan bien nuestro modelo logró predecir el largo de pétalo. Podemos comparar el error con el valor promedio de PetalLength para quizás darnos una idea de lo significativo del error.
iris.describe(["PetalLength"]).show()
Finalmente, para visualizar el modelo, agregaremos la línea de regresión determinada por la pendiente e intersección con el eje vertical anteriores a nuestro diagrama de dispersión original.
import matplotlib.pyplot as plt
items = irisdf.collect()
petal_length = []
petal_width = []
petal_features = []
for item in items:
petal_length.append(item['PetalLength'])
petal_width.append(item['PetalWidth'])
fig, ax = plt.subplots()
ax.scatter(petal_width,petal_length)
plt.xlabel("Petal Width")
plt.ylabel("Petal Length")
y = [slope*x+intercept for x in petal_width]
ax.plot(petal_width, y, color='red')
plt.show()
Entrenamiento y prueba de un modelo de clasificación
Los datos de Iris contienen tres especies distintas de Iris: Iris-Setosa, Iris-Verisicolor y Iris-Virginica. Podemos entrenar un modelo para que clasifique o prediga a qué especie pertenece una flor en base a sus características: PetalLength, PetalWidth, SepalLength y SepalWidth. Spark admite varios algoritmos de clasificación distintos. El siguiente código usa el algoritmo Naive Bayes, uno de los algoritmos más simples, a pesar de lo cual es muy potente.
Este es un esquema de los pasos a seguir:
Preparar los datos para el modelo. Esto implica poner las características en forma de vector. También implica indexar las clases, sustituyendo "Iris-Setosa" por 0.0, "Iris-verisicolor" por 1.0 y "Iris-Virginica" por 2.0.
Dividir los datos de Iris al azar entre un conjunto de entrenamiento (70%) y uno de prueba (30%).
Entrenar el clasificador con los datos de entrenamiento.
Pasar los datos de prueba por el modelo para generar clasificaciones pronosticadas.
Desindexar las predicciones para poder ver los nombres de las especies en lugar de los índices en la salida.
Mostrar las especies reales y las pronosticadas, lado a lado.
from pyspark.ml.classification import NaiveBayes
from pyspark.ml.feature import StringIndexer,IndexToString
# Para preparar los datos, indexar las clases y colocar las características en un vector.
speciesIndexer = StringIndexer(inputCol="Species", outputCol="speciesIndex")
vectorAssembler = VectorAssembler(inputCols=["PetalWidth","PetalLength","SepalWidth","SepalLength"],
outputCol="features")
data = vectorAssembler.transform(irisdf)
index_model = speciesIndexer.fit(data)
data_indexed = index_model.transform(data)
# Dividir los datos entre conjuntos de entrenamiento y prueba.
trainingData, testData = data_indexed.randomSplit([0.7, 0.3],0.0)
# Configurar el clasificador y luego entrenarlo con el conjunto de entrenamiento.
nb = NaiveBayes().setFeaturesCol("features").setLabelCol("speciesIndex").setSmoothing(1.0).setModelType("multinomial")
model = nb.fit(trainingData)
# Pasar el conjunto de prueba por el clasificador
classifications = model.transform(testData)
# Desindexar los datos para ver los nombres de las especies en lugar de los números de índice en la salida.
converter = IndexToString(inputCol="prediction", outputCol="PredictedSpecies", labels=index_model.labels)
converted = converter.transform(classifications)
# Mostrar las especies reales y las pronosticadas, lado a lado
converted.select(['Species','PredictedSpecies']).show(45)
Puede ver que el clasificador no fue perfecto. En el subconjunto de datos de arriba, clasificó erróneamente dos de las Iris-Verisicolor y una de las Iris-Virginica's. Podemos usar un evaluador para calcular la precisión exacta del clasificador con los datos de prueba.
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
# calcular la precisión con el conjunto de prueba
evaluator = MulticlassClassificationEvaluator(labelCol="speciesIndex", predictionCol="prediction",
metricName="accuracy")
accuracy = evaluator.evaluate(classifications)
print("Test set accuracy = " + str(accuracy))
Si esta precisión no es suficiente, podemos ajustar algunos parámetros del modelo o incluso probar con una algoritmo de clasificación totalmente distinto
Artículo
Joel Espinoza · 1 jul, 2020

[GraphQL](http://graphql.org/) es un lenguaje estándar para declarar estructuras y métodos de acceso a datos, que sirve como una capa de middleware entre el cliente y el servidor. Si nunca has oído hablar de GraphQL, aquí puedes encontrar algunos recursos útiles: [aquí](https://medium.freecodecamp.org/so-whats-this-graphql-thing-i-keep-hearing-about-baf4d36c20cf), [aquí](https://blog.apollographql.com/graphql-vs-rest-5d425123e34b) y [aquí](https://blog.apollographql.com/the-anatomy-of-a-graphql-query-6dffa9e9e747).
En este artículo, explicaré cómo puedes usar GraphQL en tus proyectos basados en las tecnologías de InterSystems.
Actualmente, las plataformas de InterSystems son compatibles con varios métodos para la creación de aplicaciones cliente/servidor:
- REST
- WebSocket
- SOAP
¿Cuál es la ventaja de usar GraphQL? ¿Qué beneficios aporta comparado con REST, por ejemplo?
GraphQL cuenta con varios tipos de solicitudes:
- **consultas (query)** - son solicitudes del servidor para la obtención de datos, funcionan de forma similar a las peticiones GET que se recomiendan para obtener datos mediante REST.
- **mutaciones** - este tipo de solicitudes es responsable de los cambios en los datos del lado del servidor, funcionan de forma similar a las solicitudes POST (PUT, DELETE) que se utilizan en REST.
Ambas (consultas y mutaciones) pueden devolver datos – esto es útil si quieres solicitar datos actualizados al servidor inmediatamente después de realizar una mutación.
- **suscripciones** - son similares a las consultas. La única diferencia es que las consultas se ejecutan mediante una página renderizada en el lado del cliente, mientras las suscripciones se activan por la mutaciones.
## Principales características y ventajas de GraphQL
### El cliente decide qué datos deben ser devueltos como respuesta
Una de las principales características de GraphQL es que la estructura y el volumen de los datos que son devueltos como respuesta se definen por la aplicación del cliente. La aplicación del cliente especifica qué datos quiere recibir, usando una estructura de tipo gráfico, muy parecida al formato JSON. La estructura de respuesta corresponde a la de la consulta.
Así es como se ve una sencilla consulta en GraphQL:
```json
{
Sample_Company {
Name
}
}
```
Una respuesta en el formato JSON:
```json
{
"data": {
"Sample_Company": [
{
"Name": "CompuSoft Associates"
},
{
"Name": "SynerTel Associates"
},
{
"Name": "RoboGlomerate Media Inc."
},
{
"Name": "QuantaTron Partners"
}
]
}
}
```
### Endpoint único
Cuando utilizamos GraphQL para trabajar con datos, siempre nos conectamos a un único **endpoint** (servidor GQL) y obtenemos diferentes datos al modificar la estructura, los campos y los parámetros de nuestras consultas. REST, en cambio, utiliza varios endpoints para distintos objetivos (aún cuando un endpoint soporta multiples verbos, e.g. /usuario puede soportar POST,GET,DEL y PUT).
Vamos a comparar REST con GraphQL mediante un sencillo ejemplo:

Vamos a suponer que tenemos que subir el contenido de un usuario. Si estamos usando REST, necesitamos enviar tres consultas al servidor:
1. Obtener los datos del usuario por medio de su id
2. Utilizar su id para subir sus publicaciones
3. Utilizar su id para obtener una lista de sus seguidores/suscriptores
Este es el mapa REST correspondiente a esas consultas:
```
```
Para obtener un nuevo conjunto de datos, necesitaremos actualizar este mapa REST con un nuevo endpoint.
GraphQL lo hace con una sola consulta. Para ello, solo hay que especificar lo siguiente en el cuerpo de la solicitud:
```
{
operationName: null, //la consulta puede tener un nombre ( query TestName(...){...} )
query: "query {
User(id: "ertg439frjw") {
name
posts {
title
}
followers(last: 3) {
name
}
}
}",
variables: null // inicializacion de las variables usadas en la query
}
```
Este es el mapa REST correspondiente a esta consulta:
```
```
Ten en cuenta que este es el único endpoint en el servidor.
## Instalación de GraphQL y GraphiQL
Antes de empezar a utilizar GraphQL, es necesario completar algunos pasos:
1. Descargar la [última versión](https://github.com/intersystems-ru/GraphQL/releases) de GitHub e importarla al namespace requerido
2. Ir al portal de administración del sistema y crear una nueva aplicación web basada en los productos de las plataformas de datos de InterSystems (Caché, Ensemble o IRIS):
- Nombre - **/**
- Namespace - **por ejemplo, SAMPLES**
- Clase del controlador - **GraphQL.REST.Main**
3. GraphiQL — es un intérprete para probar las consultas de GraphQL. Descargar la [última versión](https://github.com/intersystems-ru/GraphQL/releases) o [build](https://github.com/graphql/graphiql) tu propia versión desde los recursos disponibles.
4. Crear una nueva aplicación web:
- Nombre - **/graphiql**
- Namespace - **por ejemplo, SAMPLES**
- Ruta física hacia los archivos CSP - **C:\InterSystems\GraphiQL\**
## Veamos cuál es el resultado
Ve a este enlace en tu navegador **http://localhost:57772/graphiql/index.html** (servidor local — server, 57772 — puerto)

Espero que esté claro el uso de los namespaces **Query** y **Response**. Un **Esquema (Schema)** es un documento que se genera para todas las clases almacenadas en un namespace.
El esquema contiene:
- Las clases
- Las propiedades, los argumentos y sus tipos
- Las descripciones de todo lo visto anteriormente, generadas a partir de los comentarios
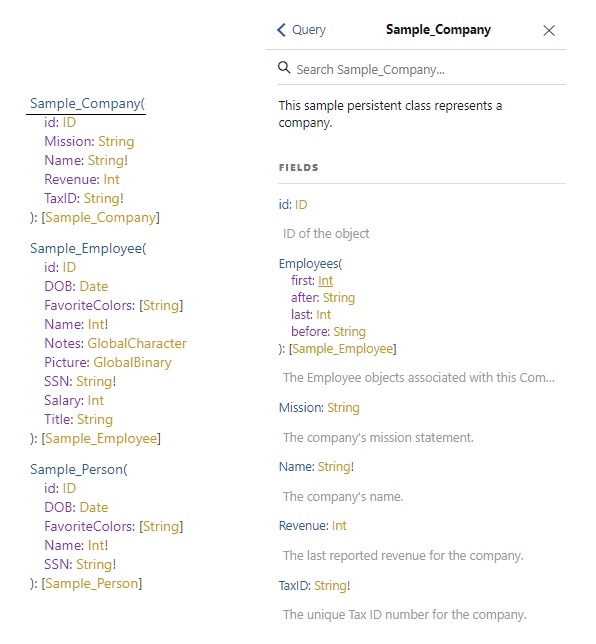
Vamos a ver con más detalle un esquema para la clase **Sample_Company**:
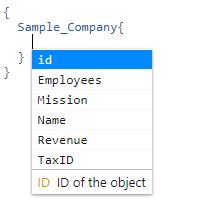
GraphiQL también es compatible con el completado automático del código, que puede activarse presionando al mismo tiempo las teclas **Ctrl + Space**:
## Consultas
Las consultas pueden ser tanto sencillas como complejas para varios conjuntos de datos. A continuación, se muestra un ejemplo de una consulta para los datos de diferentes clases, **Sample_Person** y **Sample_Company**:

## Filtros
Por el momento, solo se admite la igualdad estricta:

## Paginación
La paginación se sustenta mediante 4 funciones que pueden combinarse para lograr el resultado deseado:
- **after: n** – para todos los registros con un id mayor que n
- **before: n** – para todos los registros con un id menor que n
- **first: n** – para los primeros n registros
- **last: n** – para los últimos n registros

## Áreas visibles
En la mayoría de las situaciones, la lógica empresarial de una aplicación indica que únicamente ciertos clientes tendrán acceso a determinados namespace de las clases (autorizaciones basadas en las funciones). De acuerdo con esto, es posible que se necesite limitar la visibilidad de la clase para un cliente:
- Todas las clases que se encuentren en el namespace (**GraphQL.Scope.All**)
- Las clases que se hereden de una superclase (**GraphQL.Scope.Superclass**)
- Las clases que pertenecen a un paquete específico (**GraphQL.Scope.Package**)
Para cambiar el método con el que se restringe la visibilidad, en el entorno, cambia al namespace que necesites y después abre la clase **GraphQL.Settings**. Tiene un parámetro **SCOPECLASS** con el valor predeterminado de **GraphQL.Scope.All** — esta es la clase que contiene la descripción para la visibilidad de dicha clase en el namespace de la interfaz:

Para cambiar las restricciones en la visibilidad de la clase, es necesario definir alguno de los valores que se proporcionaron anteriormente: **GraphQL.Scope.Package** o **GraphQL.Scope.Superclass**.
Si seleccionaste **GraphQL.Scope.Package**, también tendrás que ir a esa clase y cambiar el valor del parámetro **Package** con el nombre del parámetro que se requiera – por ejemplo, **Sample**. Esto hará que todas las clases que se almacenaron desde este paquete estén completamente disponibles:

Si seleccionaste **GraphQL.Scope.Superclass**, simplemente serán las clases que se heredaron desde esta clase, una vez más en las clases requeridas:

## Actualmente es compatible con
Consultas:
- Básicas
- Objetos incrustados
- Únicamente los que tengan una relación de muchos a uno
- Lista de tipos simples
- Lista de objetos
## Actualmente en desarrollo
Consultas:
- Objetos incrustados
- Compatibles con todo tipo de relaciones
- Filtros
- Compatibles con desigualdades
## Planes
- Mutaciones
- [Alias](https://graphql.github.io/learn/queries/#aliases)
- [Directivas](https://graphql.github.io/learn/queries/#directives)
- [Fragmentos ](https://graphql.github.io/learn/queries/#fragments)
→ [Enlace ](https://github.com/intersystems-community/GraphQL) al repositorio del proyecto
→ [Enlace ](http://37.139.6.217:57773/graphiql/index.html) al servidor de demostración
Artículo
Jose-Tomas Salvador · 25 jun, 2020
¡Hola desarrolladores de ObjectScript!
InterSystems ObjectScript es probablemente el mejor lenguaje del mundo para trabajar con globals - y es un lenguaje interpretado.
Sí, tiene un compilador. Pero incluso el compilador puede dejar escapar y compilar algunas líneas en ObjectScript que después generen error en tiempo de ejecución.
Hay algunas técnicas para evitarlo tales como los tests unitarios, guías de programación y, por supuesto, ¡tu experiencia programando! ;)
Aquí quiero presentarte otra alternativa más para que puedas reducir el número de errores de ejecución de tu ObjectScript y reforzar la aplicación de tus guías de programación - se trata de la herramienta de Calidad de ObjectScript desarrollada por Lite Solutions, un partner de InterSystems.
Más detalles a continuación.
Le hemos solicitado a Lite Solutions que nos configure el análisis para las 17 reglas siguientes, que consideramos ejemplifican los casos más comunes de posibles errores y "código no desable" que el compilador "deja escapar" - violaciones de las guías de programación y funciones que han sido discontinuadas (deprecated).
Puedes comprobar como funcionan estas reglas contra esta clase en ObjectScript (probablemente la peor clase en ObjectScript de la historia), donde cada método representa un cierto problema que la herramienta reconoce. Y aquí está el análisis de esta clase creada como ejemplo.
Aquí puedes comprobar otros proyectos que ya han sido analizados por la herramienta ObjectScriptQ.
¿Cómo puedes añadir el análisis de ObjectScript a tu proyecto?
Es muy fácil. Lite Solutions proporciona gratis el análisis de todos los repositorios Open Source con ObjectScript en Github. Introduce este fichero objectscript-quality.yml en el directorio:
.github/workflows
de tu repositorio público en GitHub. Después de hacerlo, cada push al repositorio disparará un nuevo análisis y obtendrás un nuevo informe con los posibles problemas revisados en el repositorio.
Esta herramienta funciona también con repositorios privados - puedes ver las opciones disponibles y las tarifas en el site de ObjectScriptQ.
Colaboración y Evolución
Si encuentras falsos positivos o si quieres añadir una nueva regla para mejorar ObjectScript, envía el issue al repositorio de Lite Solutions o discútelo aquí en la Comunidad de Desarrolladores, por ejemplo.. en este mismo post.
Happy coding ... y que disfrutéis de un ObjectScript más límpio y saludable!
Artículo
Mathew Lambert · 7 jul, 2020
Introducción
Si gestionas múltiples instancias de Caché en varios servidores, puede que quieras ejecutar código arbitrario de una instancia de Caché en otra. Los administradores de sistemas y especialistas de soporte técnico también podrían querer ejecutar un código arbitrario en servidores Caché remotos. Para satisfacer estas necesidades, he desarrollado una herramienta especial llamada RCE.En este artículo, analizaremos cuáles son las formas más comunes de resolver tareas similares y cómo RCE (Remote Code Execution) puede ser útil.
¿Cuáles son los enfoques posibles?
Ejecutar comandos del SO localmente
Empecemos por lo más simple – Ejecutar comandos del SO localmente desde Caché. Para hacerlo, puedes ejecutar el comando $zf:
$ZF(-1) invocará un programa o comando del sistema operativo. Se realiza una llamada desde un nuevo proceso, y el proceso padre espera hasta que el proceso hijo finaliza. Una vez ejecutado el proceso, $ZF(-1) devuelve el código resultante del proceso hijo: 0 si se ejecutó con éxito, 1 si se ejecutó con errores o -1 si el sistema no fue capaz de crear el proceso hijo. Se ve así: set status = $ZF(-1,"mkdir ""test folder""")
$ZF(-2) es un comando similar, excepto que el proceso padre no espera a que el proceso hijo finaliza. El comando devuelve 0 si el proceso se creó con éxito o -1 si el sistema no logró crear el proceso hijo.
También hay métodos de la clase %Net.Remote.Utility (solo para uso de InterSystems) que ofrece "wrappers" prácticos para funciones estándar y muestra los resultados de procesos invocados de una forma más intuitiva:
RunCommandViaCPIPE ejecuta un comando usando Command Pipe. Devuelve el dispositivo creado y la salida del proceso.
RunCommandViaZF ejecuta un comando usando $ZF(-1). Escribe la salida del proceso en un archivo y devuelve la salida del proceso.
Una opción alternativa es usar el comando de terminal ! (o $, que es lo mismo) que abre el intérprete estándar del sistema operativo directamente dentro del terminal de Caché. Hay dos modos de funcionamiento disponibles:
Modo de una línea – todo el comando se pasa con ! y el intérprete de comandos lo ejecuta inmediatamente, mientras que la salida se envía al dispositivo de Caché actual. El ejemplo anterior se ve así:
SAMPLES>! mkdir ""test folder""
Modo multilínea – el sistema ejecuta ! primero y luego abre el intérprete, donde puedes introducir los comandos necesarios del sistema operativo. Para cerrar el intérprete, escribe "quit" o "exit", dependiendo del intérprete en el que estás trabajando:
SAMPLES>!
C:\InterSystems\Cache\mgr\samples\> mkdir "test folder"
C:\InterSystems\Cache\mgr\samples\> quit
SAMPLES>
Ejecución remota de código ObjectScript de Caché
La ejecución remota es posible a través de la clase %Net.RemoteConnection (discontinuada) que ofrece la siguiente funcionalidad:
Abrir y modificar objetos almacenados;
Ejecutar métodos y objetos de clase;
Ejecutar consultas.
Código de prueba para demostrar estas funcionalidades
Set rc=##class(%Net.RemoteConnection).%New()
Set Status=rc.Connect("127.0.0.1","SAMPLES",1972,"_system","SYS") break:'Status
Set Status=rc.OpenObjectId("Sample.Person",1,.per) break:'Status
Set Status=rc.GetProperty(per,"Name",.value) break:'Status
Write value
Set Status=rc.ResetArguments() break:'Status
Set Status=rc.SetProperty(per,"Name","Jones,Tom "_$r(100),4) break:'Status
Set Status=rc.ResetArguments() break:'Status
Set Status=rc.GetProperty(per,"Name",.value) break:'Status
Write value
Set Status=rc.ResetArguments() break:'Status
Set Status=rc.AddArgument(150,0) break:'Status // Addition 150+10
Set Status=rc.AddArgument(10,0) break:'Status // Addition 150+10
Set Status=rc.InvokeInstanceMethod(per, "Addition", .AdditionValue, 1) break:'Status
Write AdditionValue
Set Status=rc.ResetArguments() break:'Status
Set Status=rc.InstantiateQuery(.rs,"Sample.Person","ByName")
Este código realiza varias acciones:
Conecta con el servidor de Caché
Abre la instancia de clase Sample.Person con ID=1
Obtiene el valor del atributo
Modifica el valor del atributo
Define argumentos para el método
Llama al método de la instancia
Ejecuta la consulta Sample.Person:ByName
Para operar del lado del servidor, %Net.RemoteConnection necesita tener instalado C++ binding.También merece la pena mencionar la tecnología ECP. Esta tecnología permite ejecutar los procesos JOB remotamente en un servidor de base de datos desde el servidor de tu aplicación.En general, la combinación de estos dos enfoques puede resolver nuestra tarea eficientemente, pero los usuarios aún necesitan un flujo de trabajo simple para crear scripts por lotes, ya que estos enfoques pueden ser bastante complejos de entender e implementar.
RCE
Por lo tanto, los objetivos de estos proyectos fueron los siguientes:
Ejecución de scripts en servidores remotos desde Caché;
No tener necesidad de configurar servidores remotos (del lado del cliente);
Reducir al mínimo las configuraciones en servidores locales (del lado del servidor);
Alternar de forma transparente entre comandos del sistema operativo y ObjectScript de Caché;
Soportar clientes Windows y Linux.
La jerarquía de clases del proyecto se ve así:
La jerarquía "Máquina – SO – Instancia" almacena la información requerida para acceder a los servidores remotos.Todos los comandos se almacenan en la clase RCE.Script, que contiene la lista ordenada de objetos de clase RCE.Command, que sirven ya sea como comandos de SO o código ObjectScript de Caché.Ejemplos de comandos:
Set Сommand1 = ##class(RCE.Command).%New("cd 1", 0)
Set Сommand2 = ##class(RCE.Command).%New("zn ""%SYS""", 1)
El primer argumento es el texto del comando, el segundo argumento es el nivel de ejecución: 0 – SO, 1 – Cache.Ejemplo de creación de un nuevo script:
Set Script = ##class(RCE.Script).%New()
Do Script.Insert(##class(RCE.Command).%New("touch 123", 0))
Do Script.Insert(##class(RCE.Command).%New("set ^test=1", 1))
Do Script.Insert(##class(RCE.Command).%New("set ^test(1)=2", 1))
Do Script.Insert(##class(RCE.Command).%New("touch 1234", 0))
Do Script.%Save()
En este ejemplo, el sistema ejecutará el 1er y el 4º comando a nivel del SO y el 2º y el 3er comando a nivel de Caché. Alternar entre estos dos niveles es totalmente transparente para los usuarios.
Mecanismos de ejecución
Actualmente, se soportan las siguientes rutas de ejecución:
Servidor
Cliente
Linux
Linux, Windows (el servidor SSH debe estar instalado del lado del cliente)
Windows
Linux, Windows (deberías instalar un servidor SSH del lado del cliente o psexec del lado del servidor)
Si se soporta ssh del lado del cliente, el servidor generará el comando ssh y lo ejecutará del lado del cliente usando la clase estándar %Net.SSH.Session.Si tanto el servidor como el cliente operan bajo Windows, el sistema generará un archivo BAT y lo ejecutará del lado del cliente usando psexec.
Agregar un servidor
Carga clases desde el repositorio hacia cualquier namespace. Si tu servidor funciona en Windows y quieres gestionar otros servidores Windows, entonces asigna al global ^settings("exec") una ruta hacia psexec. ¡Y eso es todo!
Añadir un cliente
Añadir un cliente es básicamente guardar todos los datos necesarios para hacer la autenticación.
Ejemplo del código de programa que crea una nueva jerarquía "PC – SO – Instancia"
Set Machine = ##class(RCE.Machine).%New()
Set Machine.IP = "IP or Host"
Set OS = ##class(RCE.OS).%New("OС") // Linux or Windows
Set OS.Username = "Operation system user"
Set OS.Password = "User password"
Set Instance = ##class(RCE.Instance).%New()
Set Instance.Name = "Caché instance name"
Set Instance.User = "Caché user name" // Unrequired on minimal security settings
Set Instance.Pass = "Caché user password" // Unrequired on minimal security settings
Set Instance.Dir = "Path to cterm" // Required only on Windows clients, who don't have cterm in PATH
Set Instance.OS = OS
Set OS.Machine = Machine
Write $System.Status.GetErrorText(Machine.%Save())
Ejecución de scripts
Y, por último, ejecutamos nuestros scripts. Es muy fácil – solo necesitamos ejecutar el método ExecuteScript desde la clase RCE.Instance a la que se transfieren el objeto del script y el namespace (%SYS por defecto):
Set Status = Instance.ExecuteScript(Script, "USER")
Resumen
RCE ofrece un mecanismo práctico para ejecutar código de forma remota para InterSystems Caché. Como la herramienta solo usa scripts almacenados, deberás escribir cada uno de ellos solo una vez y luego ejecutarlos donde quieras, sobre cualquier cantidad de clientes.
Referencias
Repositorio de RCE en GitHubArchivo de clases del proyecto RCE
Anuncio
Esther Sanchez · 17 jul, 2020
¡Hola desarrolladores!
Os traemos el séptimo episodio de Data Points, el podcast de InterSystems en inglés.
En esta ocasión, charlamos con @Carmen.Logue (Product Manager de InterSystems) sobre InterSystems Reports, la nueva funcionalidad de InterSystems IRIS para realizar informes! Escuchad la conversación y descubrid lo que puede hacer la nueva herramienta, casos de uso y cómo se integra con el resto de herramientas de analítica. ¡Dadle al play!
También podéis escuchar el podcast entrando en la web de Data Points: datapoints.intersystems.com.
¿Queréis escuchar los episodios anteriores del podcast?:
Episodio 6. Certificación en InterSystems
Episodio 5. Bases de Datos en Mirroring para Alta Disponibilidad
Episodio 4. Optimización del rendimiento de tus consultas SQL
Episodio 3. IntegratedML en InterSystems IRIS
Episodio 2. ¿Qué es Kubernetes?
Episodio 1. ¿Qué es InterSystems IRIS?
Esperamos que os resulte útil
Anuncio
Esther Sanchez · 21 jul, 2020
¡Hola desarrolladores!
El cuarto concurso de programación con InterSystems IRIS ya ha terminado. ¡Muchas gracias a todos los participantes!
¡Y ya podemos anunciar los ganadores!
Un fuerte aplauso para estos desarrolladores y sus aplicaciones:
🏆 Nominación de los expertos - los ganadores fueron elegidos por un jurado especialmente formado para el concurso:
🥇 1er puesto y $2,000 para el proyecto iris-integratedml-monitor-example de @José.Pereira
🥈 2º puesto y $1,000 para el proyecto iris-ml-suite de @Renato.Banzai
🥉 3er puesto y $500 para el proyecto ESKLP de @Aleksandr.Kalinin6636
🏆 Nominación de la Comunidad - las aplicaciones que recibieron el mayor número de votos:
🥇 1er puesto y $1,000 para el proyecto iris-ml-suite de @Renato.Banzai
🥈 2º puesto y $250 para el proyecto iris-integratedml-monitor-example de @José.Pereira
🥈 2º puesto y $250 para el proyecto SAPPHIRE de @Yuri.Gomes
¡Enhorabuena a todos!
Y gracias de nuevo a todos los participantes, por el esfuerzo e ingenio que habéis puesto en el concurso
¿Y qué más?
Hay una serie de concursos planificados para todo el año, así que ya podéis inscribiros al siguiente!
➡️ Próximos concursos
Anuncio
Esther Sanchez · 27 jul, 2020
¡Hola desarrolladores!
Estamos encantados de anunciar el lanzamiento oficial de la Comunidad de Desarrolladores de InterSystems en japonés!
Y os presento a @Minoru.Horita y @Toshihiko.Minamoto, de InterSystems Japón, que serán las personas que gestionarán la Comunidad de Desarrolladores en japonés.
Repasamos algunos de los aspectos básicos sobre las traducciones (válidos tanto para japonés como para español):
➡️ Podéis elegir el idioma de la Comunidad con los botones situados en la parte superior derecha de la página de inicio:
Así que si sabes hablar japonés, sería genial que contribuyeras con artículos, preguntas, respuestas... en la nueva Comunidad!
Además...
➡️ En cada publicación en la Comunidad ahora aparece el botón JP, para que puedas ver la versión en japonés de esa publicación
O:
➡️ Puedes solicitar permiso para traducir a japonés cualquier Artículo, si aún no está traducido. Cualquier persona puede solicitar la traducción y publicarla y así todos colaboramos en la Comunidad!
Para añadir una traducción, solicita permiso al autor en el mismo artículo, en la pestaña "Traducción" o, si ya tienes la traducción hecha, añade la URL ahí:
Si el autor te concede el permiso, puedes publicar la traducción con tu nombre en el sitio de la Comunidad de Desarrolladores en japonés.
Si tú eres el autor del artículo, recibirás un email con la solicitud de traducción de un miembro de la Comunidad. Puedes conceder el permiso o no.
Si tú mismo quieres traducir tu artículo, tienes que solicitarte permiso a ti mismo y concedértelo.
➡️ De la misma forma sucede con la Comunidad en japonés – puedes traducir a inglés los artículos en japonés. Solo debes asegurarte de que conoces bien los dos idiomas! :)
¡Bienvenidos tod@s a la Comunidad de Desarrolladores en japonés! 🚀
Psss... Si tienes cualquier sugerencia o comentario sobre la nueva Comunidad, te escuchamos con mucho gusto!