Puesta en funcionamiento de Databricks para InterSystems Cloud SQL

Un inicio rápido para los datos de InterSystems Cloud SQL en Databricks
La puesta en funcionamiento de Databricks para InterSystems Cloud SQL consta de cuatro partes.
- Obtención de certificado y controlador JDBC para InterSystems IRIS
- Añadir un script init y una librería externa a vuestro Databricks Compute Cluster
- Obtención de Datos
- Colocación de datos
Descargar Certificado X.509/Controlador JDBC de Cloud SQL
Navegad a la página de vista general de vuestro despliegue. Si no tenéis habilitadas las conexiones externas, hacedlo y descargad vuestro certificado y el controlador JDBC desde la página de vista general.
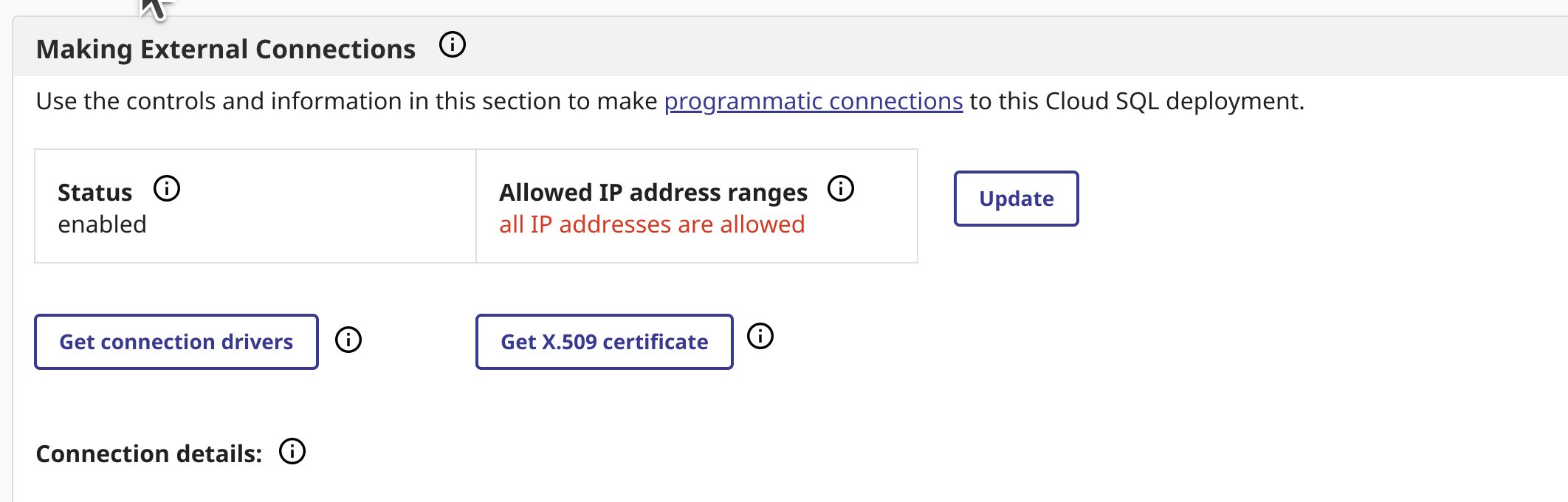
He utilizado `intersystems-jdbc-3.8.4.jar` e `intersystems-jdbc-3.7.1.jar` con éxito en Databricks desde Driver Distribution.
Script de inicio para vuestro clúster Databricks
La manera más fácil de importar uno o más certificados CA personalizados a vuestro clúster de Databricks es crear un script de inicio que añada toda la cadena de certificados CA tanto al almacén de certificados predeterminado de Linux SSL como al de Java, y que establezca la propiedad `REQUESTS_CA_BUNDLE`. Pegad el contenido de vuestro certificado X.509 descargado en el bloque superior del siguiente script:
import_cloudsql_certficiate.sh
#!/bin/bash
cat << 'EOF' > /usr/local/share/ca-certificates/cloudsql.crt
-----BEGIN CERTIFICATE-----
<PASTE>
-----END CERTIFICATE-----
EOF
update-ca-certificates
PEM_FILE="/etc/ssl/certs/cloudsql.pem"
PASSWORD="changeit"
JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
KEYSTORE="$JAVA_HOME/lib/security/cacerts"
CERTS=$(grep 'END CERTIFICATE' $PEM_FILE| wc -l)
# To process multiple certs with keytool, you need to extract
# each one from the PEM file and import it into the Java KeyStore.
for N in $(seq 0 $(($CERTS - 1))); do
ALIAS="$(basename $PEM_FILE)-$N"
echo "Adding to keystore with alias:$ALIAS"
cat $PEM_FILE |
awk "n==$N { print }; /END CERTIFICATE/ { n++ }" |
keytool -noprompt -import -trustcacerts \
-alias $ALIAS -keystore $KEYSTORE -storepass $PASSWORD
done
echo "export REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt" >> /databricks/spark/conf/spark-env.sh
echo "export SSL_CERT_FILE=/etc/ssl/certs/ca-certificates.crt" >> /databricks/spark/conf/spark-env.sh
Ahora que tenéis el script de inicio, subid el script a Unity Catalog en un Volumen.
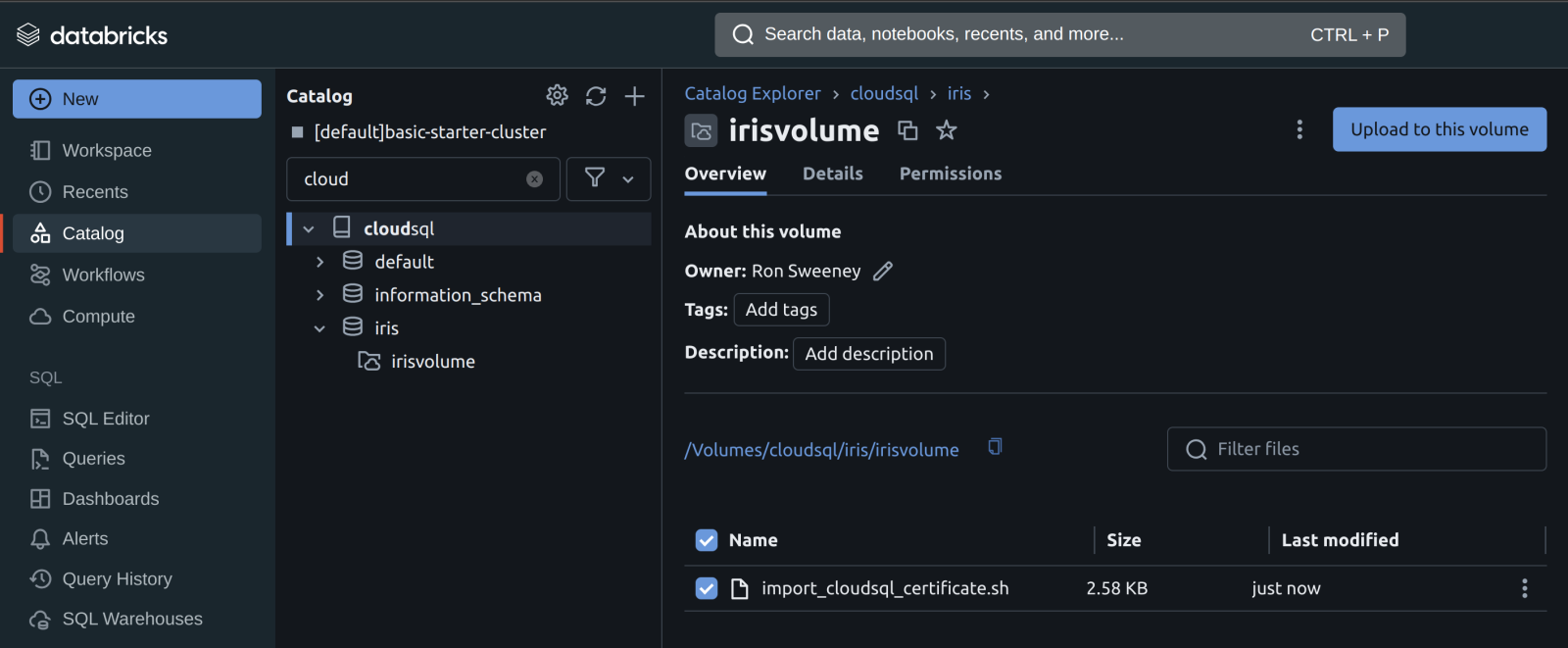
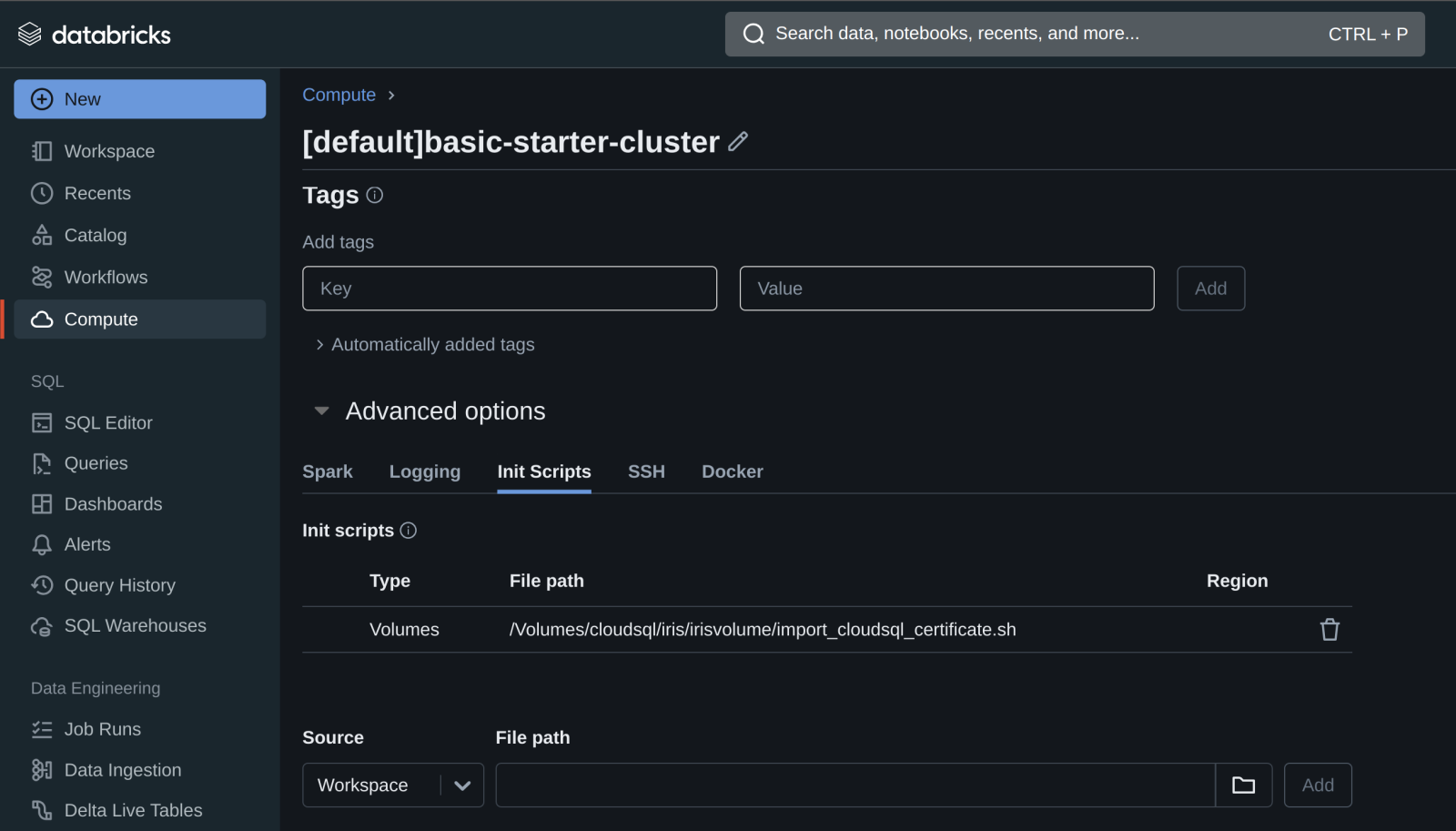
Una vez que el script esté en un volumen, podéis añadir el script de inicio al clúster desde el volumen en las Propiedades avanzadas de vuestro clúster.
 En segundo lugar, añadid el controlador/biblioteca JDBC de InterSystems al clúster...
En segundo lugar, añadid el controlador/biblioteca JDBC de InterSystems al clúster...
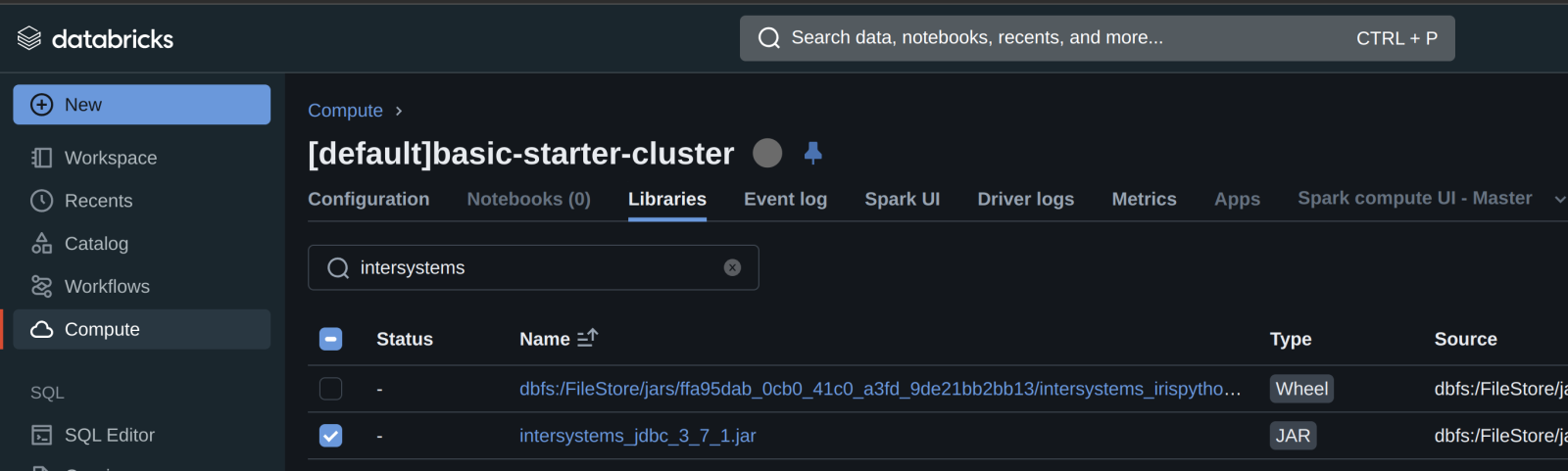
...y luego iniciad o reiniciad vuestro compute cluster.
Databricks Station - Entrada InterSystems IRIS Cloud SQL

Cread un cuaderno de Python en vuestro espacio de trabajo, adjuntadlo a vuestro clúster y probad la importación de datos a Databricks. En el fondo, Databricks va a estar utilizando pySpark, si eso no es inmediatamente obvio.
La siguiente construcción de dataframe de Spark es todo lo que necesitaréis; podéis obtener vuestra información de conexión desde la página de vista general como antes.
df = (spark.read
.format("jdbc")
.option("url", "jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("dbtable", "(SELECT name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
.option("user", "SQLAdmin")
.option("password", "REDACTED")
.option("driver", "com.intersystems.jdbc.IRISDriver")\
.option("connection security level","10")\
.option("sslConnection","true")\
.load())
df.show()
Ilustrando la salida del dataframe con datos de Cloud SQL... ¡boom!
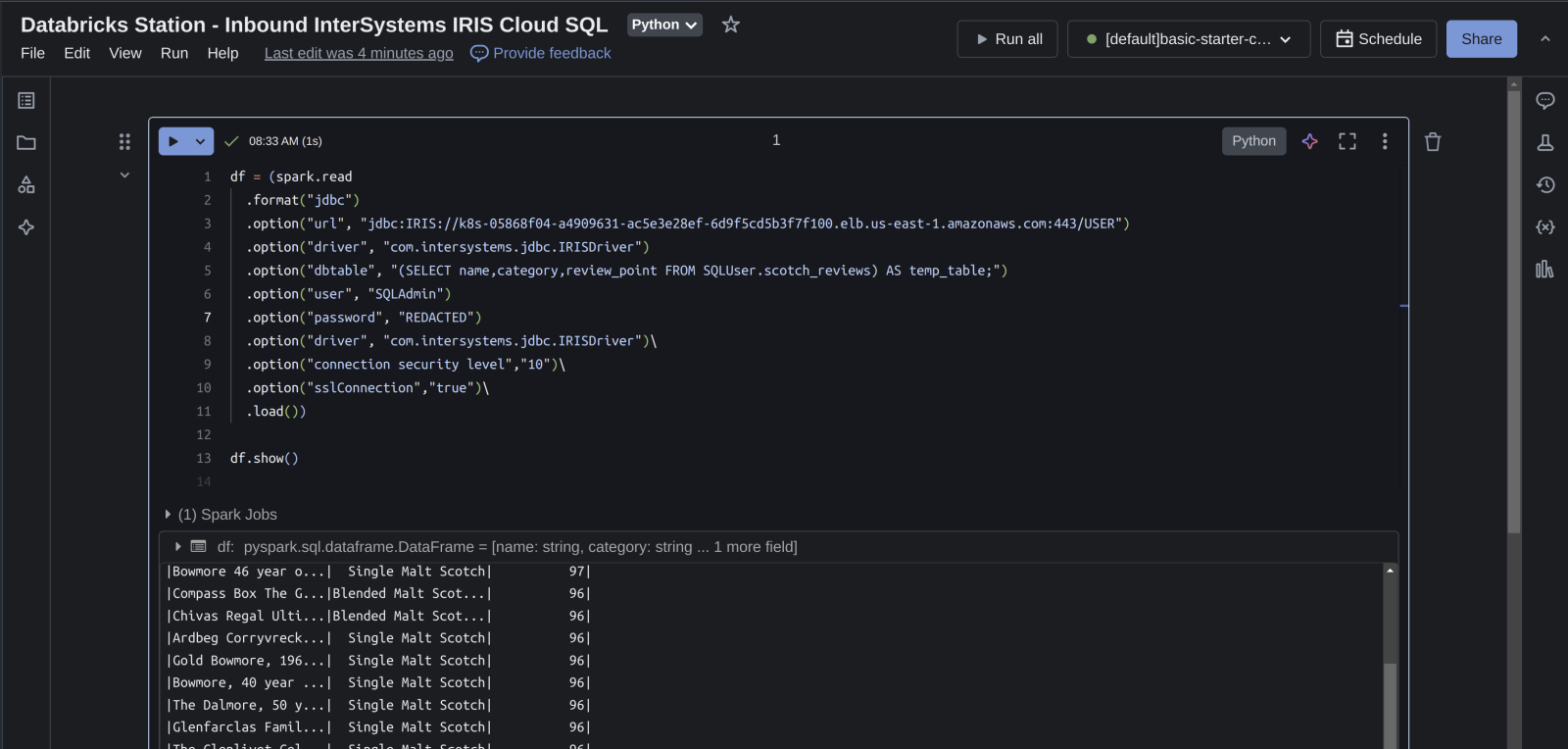
Databricks Station - Salida de InterSystems IRIS Cloud SQL

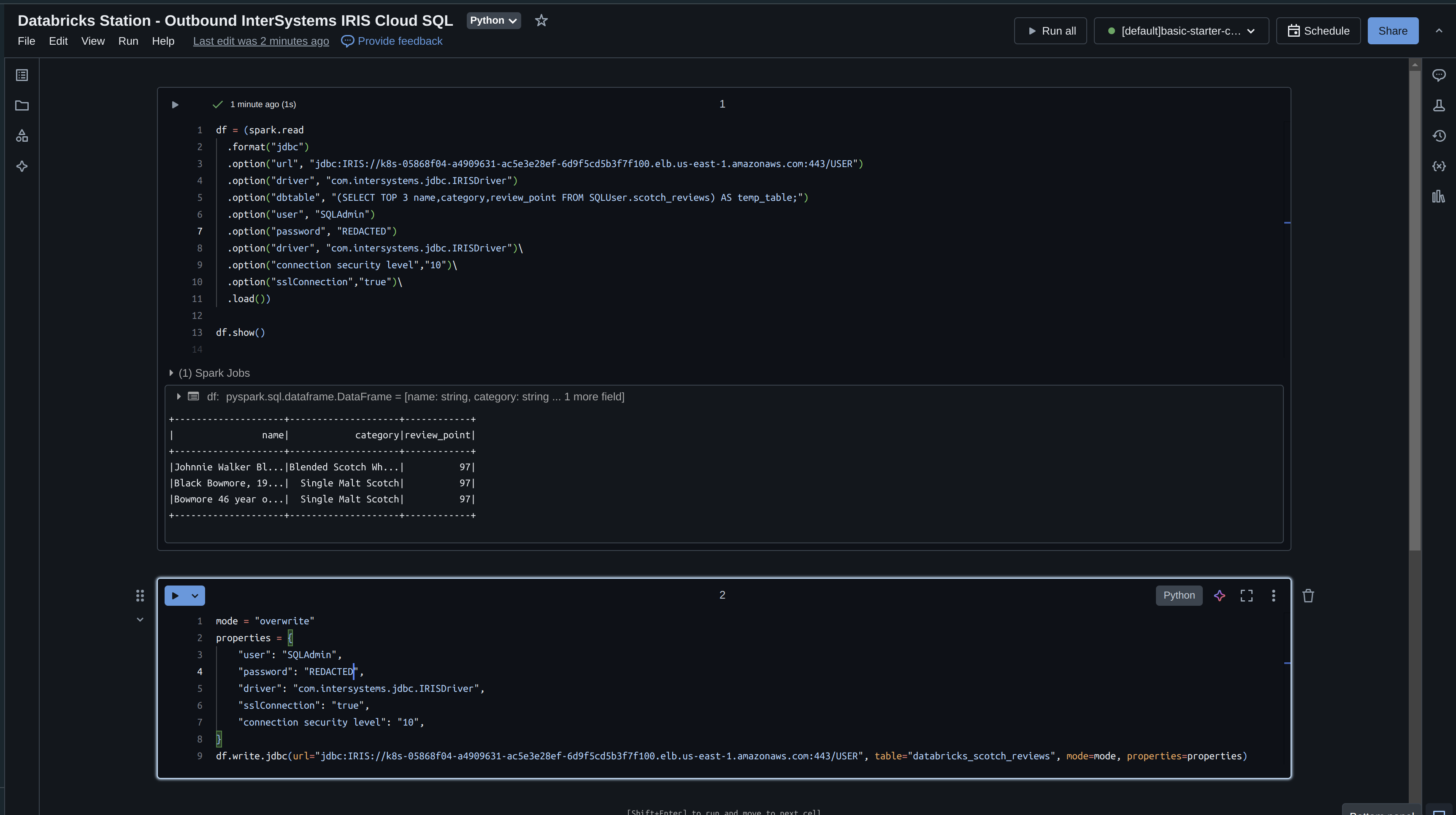
Ahora, tomad lo que hemos leído de IRIS y escribidlo de vuelta con Databricks. Si recordáis, solo leímos 3 campos en nuestro dataframe, así que escribidlo de vuelta inmediatamente y especificad el modo "overwrite".
df = (spark.read
.format("jdbc")
.option("url", "jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER")
.option("driver", "com.intersystems.jdbc.IRISDriver")
.option("dbtable", "(SELECT TOP 3 name,category,review_point FROM SQLUser.scotch_reviews) AS temp_table;")
.option("user", "SQLAdmin")
.option("password", "REDACTED")
.option("driver", "com.intersystems.jdbc.IRISDriver")\
.option("connection security level","10")\
.option("sslConnection","true")\
.load())
df.show()
mode = "overwrite"
properties = {
"user": "SQLAdmin",
"password": "REDACTED",
"driver": "com.intersystems.jdbc.IRISDriver",
"sslConnection": "true",
"connection security level": "10",
}
df.write.jdbc(url="jdbc:IRIS://k8s-05868f04-a4909631-ac5e3e28ef-6d9f5cd5b3f7f100.elb.us-east-1.amazonaws.com:443/USER", table="databricks_scotch_reviews", mode=mode, properties=properties)
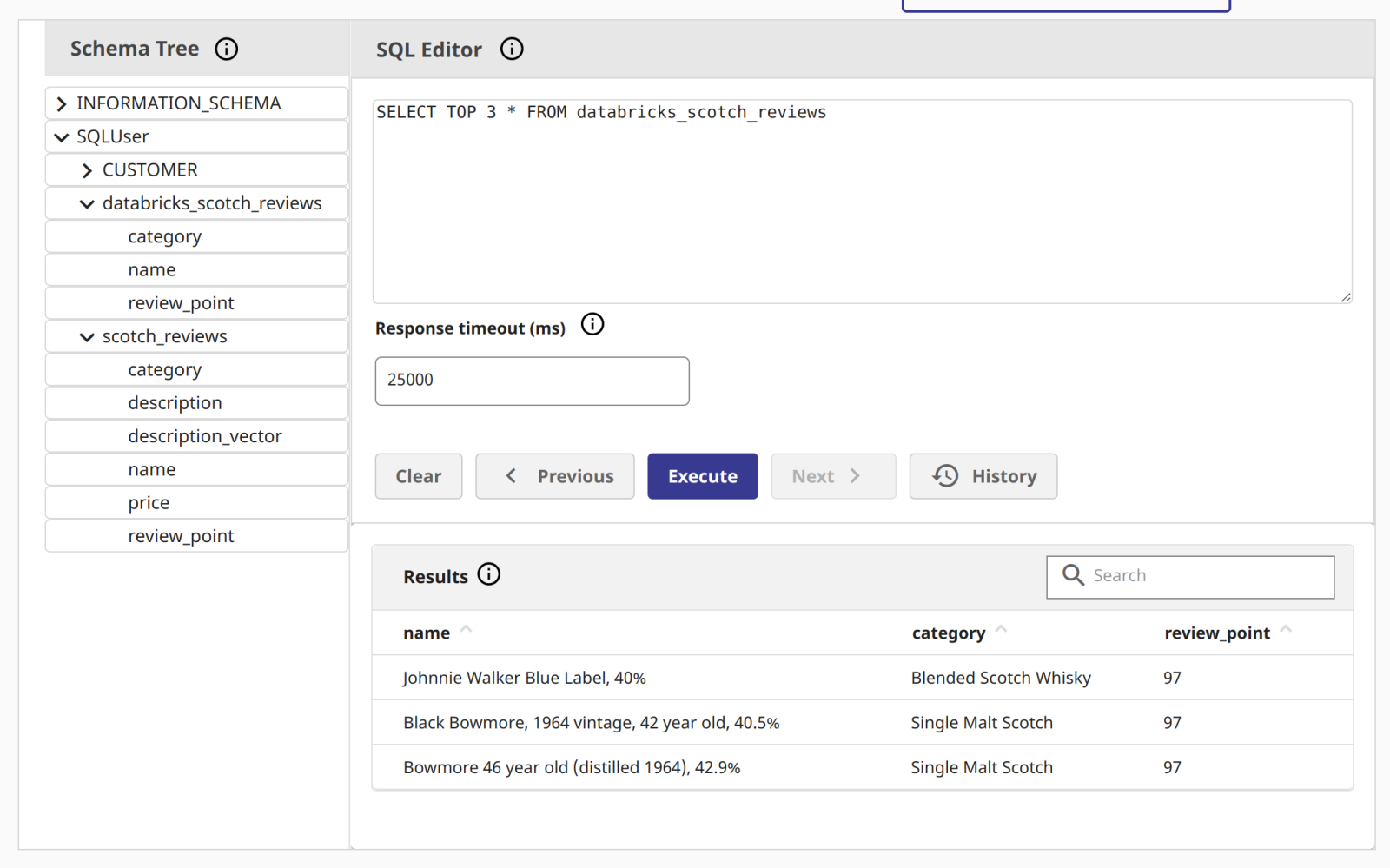
Ejecutando el cuaderno
 ¡Ilustrando los datos en InterSystems Cloud SQL!
¡Ilustrando los datos en InterSystems Cloud SQL!
Cosas a considerar
- Por defecto, PySpark escribe datos usando múltiples tareas concurrentes, lo que puede resultar en escrituras parciales si una de las tareas falla.
- Para asegurar que la operación de escritura es atómica y consistente, podéis configurar PySpark para que escriba los datos utilizando una única tarea (es decir, establecer el número de particiones en 1) o utilizar una característica específica de iris como las transacciones.
- Además, podéis utilizar la API DataFrame de PySpark para realizar operaciones de filtrado y agregación antes de leer los datos de la base de datos, lo que puede reducir la cantidad de datos que es necesario transferir a través de la red.