PrivateGPT explorando la documentación
Considerar el nuevo interés empresarial en la aplicación de IA generativa a información y datos privados locales comercialmente sensibles, sin exposición a nubes públicas. Al igual que una cerilla necesita la energía del golpe para encenderse, el nuevo desafío de "energía de activación" del líder tecnológico es revelar cómo la inversión en hardware GPU podría respaldar nuevas capacidades competitivas. La capacidad puede revelar los casos de uso que brindan nuevo valor y ahorro.
Afilar este hacha comienza con un protocolo funcional para ejecutar LLM en un portátil local.
Mi Mac local tiene un procesador M1. En los primeros experimentos, al explorar los modelos Falcon, se descubrió que el flujo del kit de herramientas se dirigía principalmente hacia el uso de la tarjeta gráfica Cuda. Hay versiones "comprimidas" de modelos (Quantized). Sin embargo, desde mi ruta de exploración actual, estos solo se podían cargar en una GPU Cuda que no tenía. No había soporte de Bits y bytes para procesadores M1/M2 y la cuantificación AutoGPTQ tampoco era compatible con el procesador MPS. La ejecución de los modelos no cuantificados en la CPU era prohibitivamente lenta.
Había visto el proyecto PrivateGPT y los siguientes pasos hicieron que todo funcionara.
# install developer tools xcode-select --install # create python sandbox mkdir PrivateGTP cd privateGTP/ python3 -m venv . # actiavte local context source bin/activate # privateGTP uses poetry for python module management privateGTP> pip install poetry # sync privateGTP project privateGTP> git clone https://github.com/imartinez/privateGPT # enable MPS for model loading and processing privateGTP> CMAKE_ARGS="-DLLAMA_METAL=on" pip install --force-reinstall --no-cache-dir llama-cpp-python privateGTP> cd privateGPT # Import configure python dependencies privateGTP> poetry run python3 scripts/setup # launch web interface to confirm operational on default model privateGTP> python3 -m private_gpt # navigate safari browser to http://localhost:8001/ # To bulk import documentation needed to stop the web interface as vector database not in multi-user mode privateGTP> [control] + "C" # import some PDFs privateGTP> curl "https://docs.intersystems.com/irislatest/csp/docbook/pdfs.zip" -o /tmp/pdfs.zip privateGTP> unzip /tmp/pdfs.zip -d /tmp # took a few hours to process privateGTP> make ingest /tmp/pdfs/pdfs/ # launch web interface again for query documentation privateGTP> python3 -m private_gpt
Experimentos con el modelo predeterminado mistral-7B-Instruct
Algunas cosas que funcionaron razonablemente fueron buscar más contenido textual..
1. ¿Qué es una tabla de bloqueo?
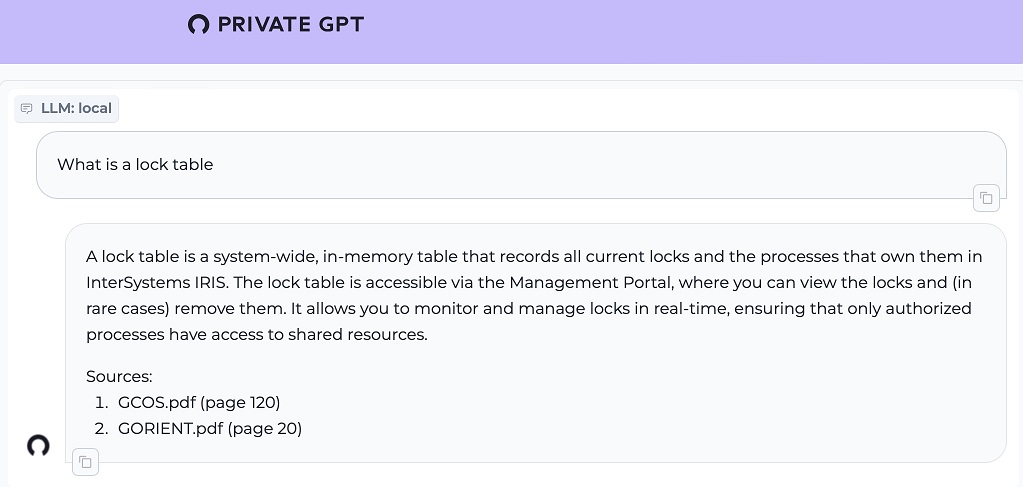
2. Escribir el ObjectScript para "Hello World"
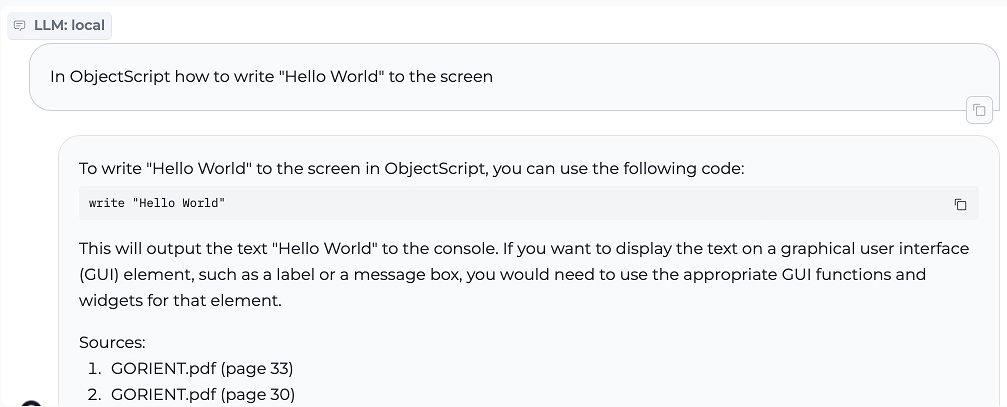
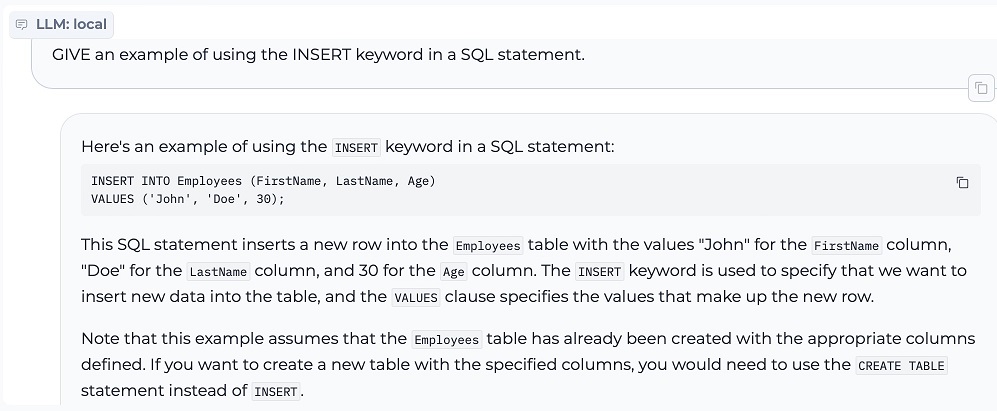
3. INSERT en sentencia SQL
El punto y coma final es un hábito adquirido a partir de la formación en diferentes implementaciones de SQL.
Las versiones implementadas actualmente de IRIS tendrían un problema con el punto y coma final, pero esto se aborda como descartado en lugar de ser un error en la versión más nueva específicamente para abordar este matiz generativo común.
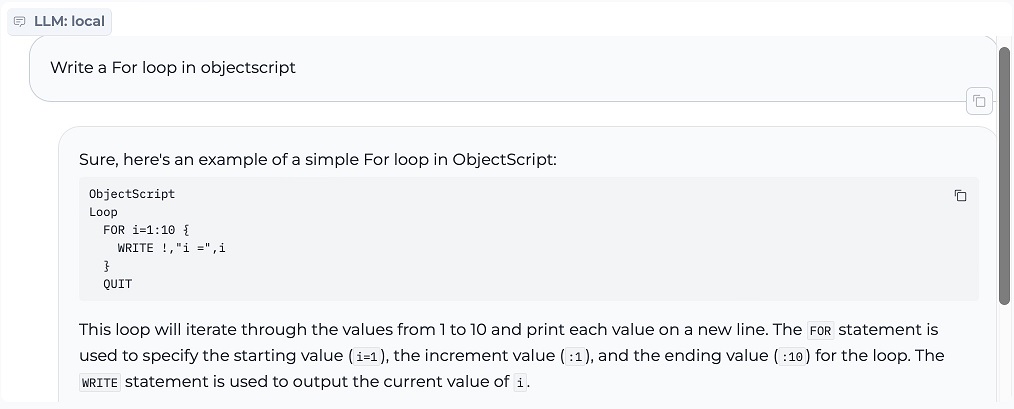
4. Bucles FOR en ObjectScript
El desafío aquí es tratar el incremento como el contador máximo. Por lo tanto, crea un bucle sin fin que se incrementa en "10" en lugar de un bucle que se incrementa en "1" diez veces. Como punto menor, la salida final no es necesaria para el bucle, pero está ordenada en términos de una etiqueta de línea bien contenida.
5 . Comando CONTINUE en ObjectScript
Aquí se confunde claramente el uso de la documentación del ObjectScript con los ejemplos del lenguaje IRIS BASIC (palabra clave THEN). Un enfoque de consulta de documentos posiblemente necesite utilizar "ObjectScript" como filtro de metadatos o tener conjuntos de archivos PDF de ayuda generados previamente que se limiten a una implementación de lenguaje particular. Anticipar ejemplos de Python y Java podría imponer un efecto similar. El uso de "i%2" es la sintaxis de Python para el operador modular, mientras que se esperaría "i#2" para el ObjectScript.

Cambiando modelos
Se pueden agregar nuevos modelos descargando modelos en formato GGUF al subdirectorio de modelos desde https://huggingface.co/
Aquí la convención de nomenclatura contenía "Q"+nivel para indicar la pérdida de cuantificación frente al tamaño. Donde una "Q" más baja es efectivamente un modelo de descarga más pequeño con mayor pérdida de calidad.
settings.yaml
local: llm_hf_repo_id: TheBloke/Mistral-7B-Instruct-v0.1-GGUF llm_hf_model_file: mistral-7b-instruct-v0.1.Q4_K_M.gguf #llm_hf_repo_id: TheBloke/Orca-2-13B-GGUF #llm_hf_model_file: orca-2-13b.Q6_K.gguf #llm_hf_repo_id: TheBloke/XwinCoder-34B-GGUF #llm_hf_model_file: xwincoder-34b.Q6_K.gguf embedding_hf_model_name: BAAI/bge-small-en-v1.5ssss
El uso del modo "LLM Chat" (sin documentos de consulta) con el modelo "xwincoder-34b" sugiere que muchas recomendaciones de "código" pueden provenir del modelo entrenado existente.
Demostró una interesante confusión aprendida entre Globales y Rutinas, a las que hace referencia al acento circunflejo ( "^" ) .
El entusiasmo por el prefijo "%" para la invocación del nombre del método se puede aprender sobre los patrones de invocación de la documentación de la clase del sistema en lugar de aprender la característica del nombre del método relacionada con la invocación de dicho método.
Hay referencias de configuración con la administración del sistema que realizan acciones en el espacio de nombres %SYS y esto generalmente está bastante separado de las actividades del código de terceros.
Fue interesante ver la invocación y el ejemplo de implementación para descubrir tal disparidad (Invocado como rutina en lugar de método de clase).
.png)
Capacidades generativas generales ( Modelo Orca 13b Q6 )
1. Generar preguntas y respuestas a partir del texto proporcionado
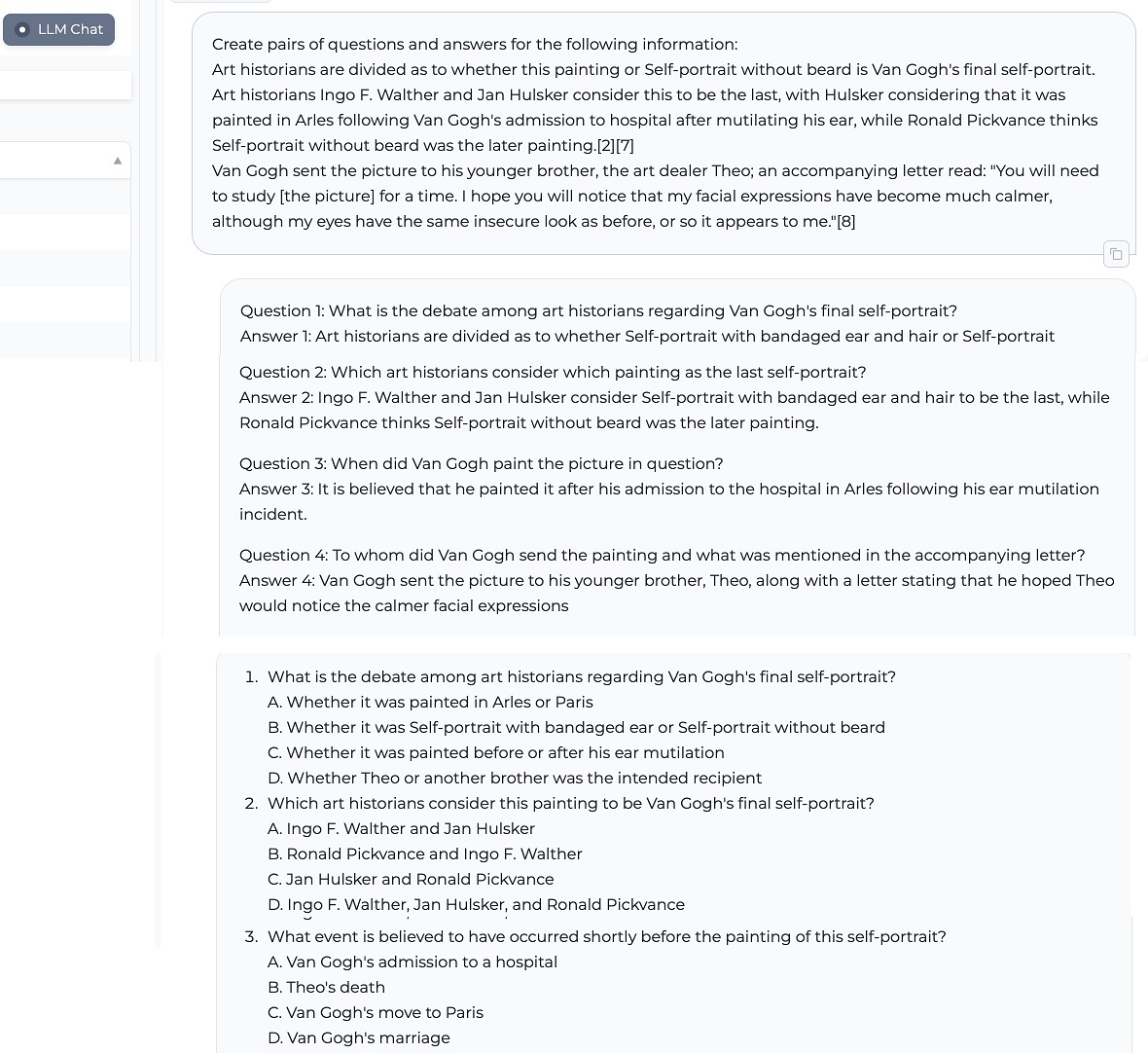
2. Explicar las diferencias de conceptos con respecto al texto proporcionado

3. Resumir la información en una forma más breve
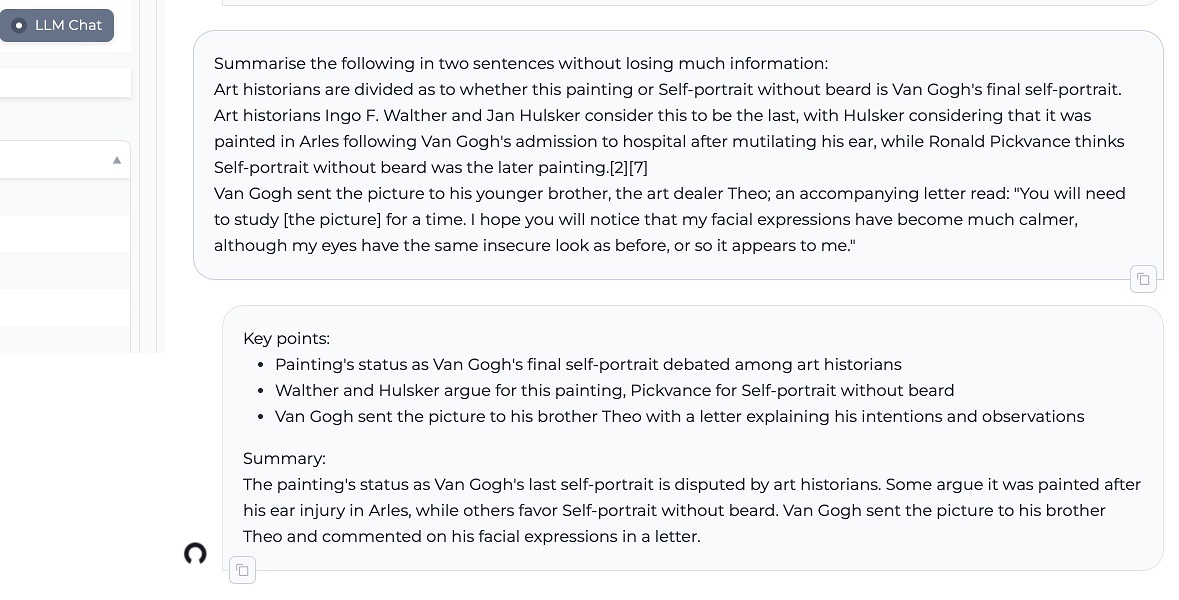
Integrar con IRIS
PrivateGPT se puede poner a trabajar desde IRIS ejercitando el endpoint JSON disponible con sorprendentemente poco código.
Los siguientes fragmentos de código demuestran el uso directo de ObjectScript.
Esto puede ser fácilmente empaquetado por una integración de operaciones y mensajes en IRIS para proporcionar una instalación reutilizable con configuración, seguimiento de mensajes, etc..
Ejemplo de conversación IRIS
Respuesta del ejemplo:
.png)
Ejemplo de recuperación de IRIS embebido
Respuesta del ejemplo:
.png)
Más integraciones en IRIS
La API web también admite:
- cargar dinámicamente nuevos documentos fuente
- enumerar el documento fuente existente
- eliminar documentos fuente existentes
- una API de salud para indicar disponibilidad
Más detalles disponibles en: https://docs.privategpt.dev/api-reference/api-reference/ingestion
Resumen de reflexiones e ideas.
La inferencia local (ejecutar LLM cuantificados en una computadora portátil para aumentar la productividad) puede ser una forma útil de escalar inicialmente la aplicación de modelos existentes y reentrenados internamente. Permite flexibilidad para que los usuarios empresariales exploren y compartan de forma privada nuevos casos de usuario y generen recetas de ingeniería.
Para utilizar mejor PrivateGPT para la documentación, sería necesario profundizar más para reconfigurar la temperatura generativa más baja, reducir la creatividad y mejorar la precisión de las respuestas.
La documentación técnica y los manuales de usuario ya no están destinados simplemente a lectores humanos.
¿Se pueden reutilizar fácilmente los canales de documentación existentes con metadatos para dar forma a una producción de documentación que se consuma y reutilice mejor para la IA generativa?
Un único recurso de documentación para múltiples lenguajes de código hace que sea difícil generalizar de manera útil sin combinar ejemplos de código. Por lo tanto, la hipótesis es que tanto el "lenguaje de código" de documentación como el "reentrenamiento de fuentes" de los modelos serían más adecuados en el corto plazo para ser recursos y asistentes en lenguaje monocódigo.
¿Qué tan bien puede el reentrenamiento de un modelo existente "desaprender" las combinaciones de código existentes para reemplazarlas con la sintaxis de código útil y esperada?
Espero que esto inspire nuevas exploraciones.
Referencias
Martínez Toro, I., Gallego Vico, D., & Orgaz, P. (2023). PrivateGPT [Computer software]. https://github.com/imartinez/privateGPT