Cargar datos de recetas con Foreign Tables y analizarlos utilizando LLMs con Python Embebido (Langchain + OpenAI)
Tenemos un conjunto de datos bastante apetecible con recetas escritas por múltiples usuarios de Reddit, sin embargo, la mayor parte de la información está en texto libre en forma de título y descripción de un mensaje. Vamos a averiguar cómo podemos, de forma muy sencilla, cargar los datos, extraer algunas características y analizarlos empleando funcionalidades de LLM (Large Language Model) de OpenAI desde Python Embebido y el framework Langchain.
Cargar los datos
Lo primero es lo primero: ¿necesitamos cargar los datos o podemos sencillamente conectarnos a ellos?
Hay diferentes formas para plantearlo: por ejemplo, con el Mapeo de registros CSV que puedes utilizar en una producción de interoperabilidad o incluso instalar directamente una aplicación de OpenExchange como csvgen para que nos ayude.
Utilizaremos en este caso las Foreign Tables. Una funcionalidad muy útil para proyectar datos físicamente almacenados en otra parte y tenerlos accesibles desde el SQL de IRIS. Podemos utilizarlo directamente para echar un primer vistazo a los ficheros del conjunto de datos.
Creamos un Foreign Server:
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
Y a continuación, creamos una Foreign Table que se conecta al fichero CSV:
CREATE FOREIGN TABLE dataset.Recipes (
CREATEDDATE DATE,
NUMCOMMENTS INTEGER,
TITLE VARCHAR,
USERNAME VARCHAR,
COMMENT VARCHAR,
NUMCHAR INTEGER
) SERVER dataset FILE 'Recipes.csv' USING
{
"from": {
"file": {
"skip": 1
}
}
}
¡Y ya está!, inmediatamente podemos lanzar consultas SQL sobre dataset.Recipes:
## ¿Qué datos necesitamos? Los datos son muy interesantes y tenemos hambre. Sin embargo, si queremos decidir qué receta vamos a cocinar necesitamos algo más de información que podamos utilizar para analizar las recetas.
Vamos a trabajar con dos clases persistentes (tablas):
- yummy.data.Recipe: una clase que contiene el título y la descripción de la receta así como algunas otras propiedades que queremos extraer y analizar (por ejemplo: Score, Difficulty, Ingredients, CuisineType, PreparationTime).
- yummy.data.RecipeHistory: una clase sencilla para anotar un registro de qué estamos haciendo con la receta.
Podemos ahora cargar en nuestras tablas yummy.data* el contenido del conjunto de datos de recetas:
do ##class(yummy.Utils).LoadDataset()
Hasta aquí tiene buena pinta, pero aún debemos averiguar cómo vamos a generar los datos para los campos como: Score, Difficulty, Ingredients, PreparationTime and CuisineType.
## Analizar las recetas Queremos procesar el título y la descripción de cada receta y:
- Extraer información como Difficulty, Ingredients, CuisineType, etc.
- Construir nuestra propia puntuación de la receta basada en nuestro criterio, de forma que podamos decidir qué vamos a cocinar.
Vamos a utilizar lo siguiente:
- yummy.analysis.Analysis - una estructura genérica de análisis que vamos a re-utilizar en caso de que queramos implementar diferentes tipos de análisis.
- yummy.analysis.SimpleOpenAI - un análisis que usa Python Embebido + framework Langchain + OpenAI LLM.
Los LLM (Large Language Models) son una herramienta realmente increíble para procesar lenguaje natural.
LangChain está preparado para trabajar con Python, así que podemos utilizarlo directamente en InterSystems IRIS a través de Embedded Python.
La clase SimpleOpenAI tiene esta pinta:
/// Simple OpenAI analysis for recipes
Class yummy.analysis.SimpleOpenAI Extends Analysis
{
Property CuisineType As %String;
Property PreparationTime As %Integer;
Property Difficulty As %String;
Property Ingredients As %String;
/// Run
/// You can try this from a terminal:
/// set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8))
/// do a.Run()
/// zwrite a
Method Run()
{
try {
do ..RunPythonAnalysis()
set reasons = ""
// mis estilos de cocina favoritos
if "spanish,french,portuguese,italian,korean,japanese"[..CuisineType {
set ..Score = ..Score + 2
set reasons = reasons_$lb("It seems to be a "_..CuisineType_" recipe!")
}
// no quiero estar el día entero cocinando :)
if (+..PreparationTime < 120) {
set ..Score = ..Score + 1
set reasons = reasons_$lb("You don't need too much time to prepare it")
}
// bonus para mis ingredientes favoritos!
set favIngredients = $listbuild("kimchi", "truffle", "squid")
for i=1:1:$listlength(favIngredients) {
set favIngred = $listget(favIngredients, i)
if ..Ingredients[favIngred {
set ..Score = ..Score + 1
set reasons = reasons_$lb("Favourite ingredient found: "_favIngred)
}
}
set ..Reason = $listtostring(reasons, ". ")
} catch ex {
throw ex
}
}
/// Update recipe with analysis results
Method UpdateRecipe()
{
try {
// call parent class implementation first
do ##super()
// add specific OpenAI analysis results
set ..Recipe.Ingredients = ..Ingredients
set ..Recipe.PreparationTime = ..PreparationTime
set ..Recipe.Difficulty = ..Difficulty
set ..Recipe.CuisineType = ..CuisineType
} catch ex {
throw ex
}
}
/// Run analysis using embedded Python + Langchain
/// do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8)).RunPythonAnalysis(1)
Method RunPythonAnalysis(debug As %Boolean = 0) [ Language = python ]
{
# load OpenAI APIKEY from env
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv('/app/.env')
# account for deprecation of LLM model
import datetime
current_date = datetime.datetime.now().date()
# date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# set the model depending on the current date
if current_date > target_date:
llm_model = "gpt-3.5-turbo"
else:
llm_model = "gpt-3.5-turbo-0301"
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
# init llm model
llm = ChatOpenAI(temperature=0.0, model=llm_model)
# prepare the responses we need
cuisine_type_schema = ResponseSchema(
name="cuisine_type",
description="What is the cuisine type for the recipe? \
Answer in 1 word max in lowercase"
)
preparation_time_schema = ResponseSchema(
name="preparation_time",
description="How much time in minutes do I need to prepare the recipe?\
Anwer with an integer number, or null if unknown",
type="integer",
)
difficulty_schema = ResponseSchema(
name="difficulty",
description="How difficult is this recipe?\
Answer with one of these values: easy, normal, hard, very-hard"
)
ingredients_schema = ResponseSchema(
name="ingredients",
description="Give me a comma separated list of ingredients in lowercase or empty if unknown"
)
response_schemas = [cuisine_type_schema, preparation_time_schema, difficulty_schema, ingredients_schema]
# get format instructions from responses
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
analysis_template = """\
Interprete and evaluate a recipe which title is: {title}
and the description is: {description}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=analysis_template)
messages = prompt.format_messages(title=self.Recipe.Title, description=self.Recipe.Description, format_instructions=format_instructions)
response = llm(messages)
if debug:
print("======ACTUAL PROMPT")
print(messages[0].content)
print("======RESPONSE")
print(response.content)
# populate analysis with results
output_dict = output_parser.parse(response.content)
self.CuisineType = output_dict['cuisine_type']
self.Difficulty = output_dict['difficulty']
self.Ingredients = output_dict['ingredients']
if type(output_dict['preparation_time']) == int:
self.PreparationTime = output_dict['preparation_time']
return 1
}
}
El método RunPythonAnalysis es donde sucede todo lo relativo a OpenAI :). Puedes probarlo directamente desde tu terminal utilizando una receta en particular:
do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
Obtendremos un resultado como el siguiente:
USER>do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
======ACTUAL PROMPT
Interprete and evaluate a recipe which title is: Folded Sushi - Alaska Roll
and the description is: Craving for some sushi but don't have a sushi roller? Try this easy version instead. It's super easy yet equally delicious!
[Video Recipe](https://www.youtube.com/watch?v=1LJPS1lOHSM)
# Ingredients
Serving Size: \~5 sandwiches
* 1 cup of sushi rice
* 3/4 cups + 2 1/2 tbsp of water
* A small piece of konbu (kelp)
* 2 tbsp of rice vinegar
* 1 tbsp of sugar
* 1 tsp of salt
* 2 avocado
* 6 imitation crab sticks
* 2 tbsp of Japanese mayo
* 1/2 lb of salmon
# Recipe
* Place 1 cup of sushi rice into a mixing bowl and wash the rice at least 2 times or until the water becomes clear. Then transfer the rice into the rice cooker and add a small piece of kelp along with 3/4 cups plus 2 1/2 tbsp of water. Cook according to your rice cookers instruction.
* Combine 2 tbsp rice vinegar, 1 tbsp sugar, and 1 tsp salt in a medium bowl. Mix until everything is well combined.
* After the rice is cooked, remove the kelp and immediately scoop all the rice into the medium bowl with the vinegar and mix it well using the rice spatula. Make sure to use the cut motion to mix the rice to avoid mashing them. After thats done, cover it with a kitchen towel and let it cool down to room temperature.
* Cut the top of 1 avocado, then slice into the center of the avocado and rotate it along your knife. Then take each half of the avocado and twist. Afterward, take the side with the pit and carefully chop into the pit and twist to remove it. Then, using your hand, remove the peel. Repeat these steps with the other avocado. Dont forget to clean up your work station to give yourself more space. Then, place each half of the avocado facing down and thinly slice them. Once theyre sliced, slowly spread them out. Once thats done, set it aside.
* Remove the wrapper from each crab stick. Then, using your hand, peel the crab sticks vertically to get strings of crab sticks. Once all the crab sticks are peeled, rotate them sideways and chop them into small pieces, then place them in a bowl along with 2 tbsp of Japanese mayo and mix until everything is well mixed.
* Place a sharp knife at an angle and thinly slice against the grain. The thickness of the cut depends on your preference. Just make sure that all the pieces are similar in thickness.
* Grab a piece of seaweed wrap. Using a kitchen scissor, start cutting at the halfway point of seaweed wrap and cut until youre a little bit past the center of the piece. Rotate the piece vertically and start building. Dip your hand in some water to help with the sushi rice. Take a handful of sushi rice and spread it around the upper left hand quadrant of the seaweed wrap. Then carefully place a couple slices of salmon on the top right quadrant. Then place a couple slices of avocado on the bottom right quadrant. And finish it off with a couple of tsp of crab salad on the bottom left quadrant. Then, fold the top right quadrant into the bottom right quadrant, then continue by folding it into the bottom left quadrant. Well finish off the folding by folding the top left quadrant onto the rest of the sandwich. Afterward, place a piece of plastic wrap on top, cut it half, add a couple pieces of ginger and wasabi, and there you have it.
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
json
{
"cuisine_type": string // What is the cuisine type for the recipe? Answer in 1 word max in lowercase
"preparation_time": integer // How much time in minutes do I need to prepare the recipe? Anwer with an integer number, or null if unknown
"difficulty": string // How difficult is this recipe? Answer with one of these values: easy, normal, hard, very-hard
"ingredients": string // Give me a comma separated list of ingredients in lowercase or empty if unknown
}
======RESPONSE
json
{
"cuisine_type": "japanese",
"preparation_time": 30,
"difficulty": "easy",
"ingredients": "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
}
Tiene muy buena pinta. Parece que nuestro prompt o pregunta a OpenAI es capaz de devolvernos información que realmente podemos utilizar. Vamos a ejecutar el análisis completo desde el terminal:
set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12))
do a.Run()
zwrite a
USER>zwrite a
a=37@yummy.analysis.SimpleOpenAI ; <OREF>
+----------------- general information ---------------
| oref value: 37
| class name: yummy.analysis.SimpleOpenAI
| reference count: 2
+----------------- attribute values ------------------
| CuisineType = "japanese"
| Difficulty = "easy"
| Ingredients = "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
| PreparationTime = 30
| Reason = "It seems to be a japanese recipe!. You don't need too much time to prepare it"
| Score = 3
+----------------- swizzled references ---------------
| i%Recipe = ""
| r%Recipe = "30@yummy.data.Recipe"
+-----------------------------------------------------
## Analizar todas las recetas Naturalmente, querremos ejecutar el análisis para todas las recetas que hemos cargado.
Puedes analizar un rango de recetas (utilizando sus identificadores), de esta forma:
USER>do ##class(yummy.Utils).AnalyzeRange(1,10)
> Recipe 1 (1.755185s)
> Recipe 2 (2.559526s)
> Recipe 3 (1.556895s)
> Recipe 4 (1.720246s)
> Recipe 5 (1.689123s)
> Recipe 6 (2.404745s)
> Recipe 7 (1.538208s)
> Recipe 8 (1.33001s)
> Recipe 9 (1.49972s)
> Recipe 10 (1.425612s)
Después de eso, vamos a echar un vistazo de nuevo a la tabla de recetas y comprobemos los resultados:
select * from yummy_data.Recipe
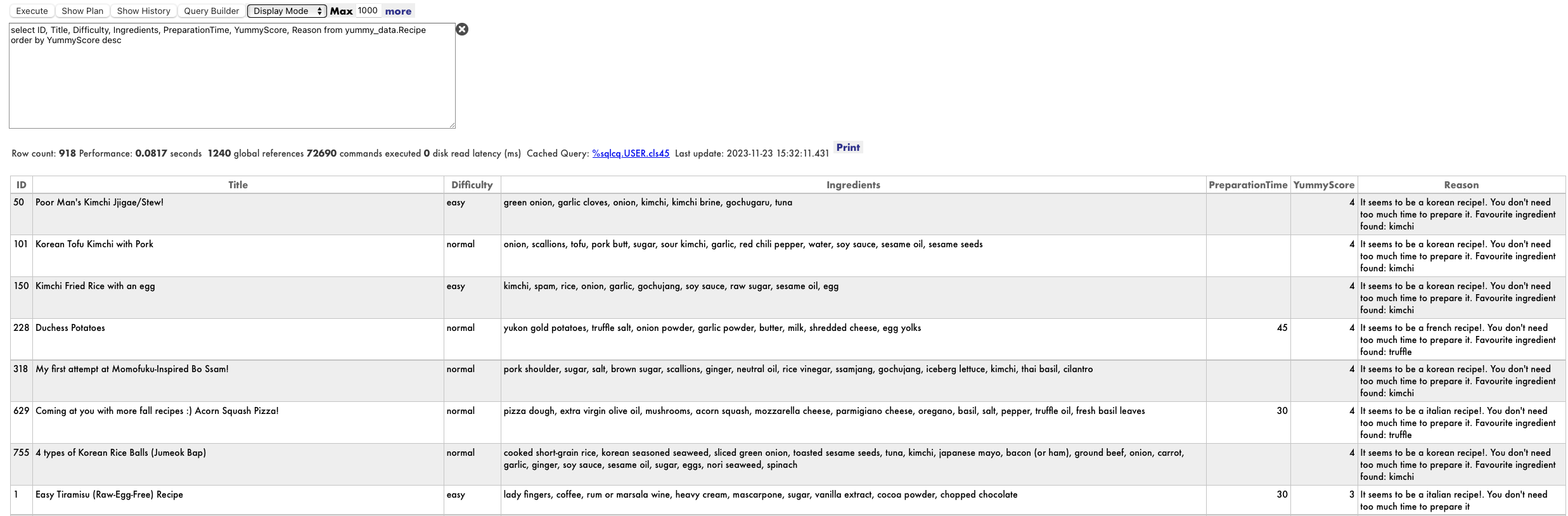
Creo que podría intentar la Pizza con calabaza o el Tofu con Kimchi y cerdo al estilo coreano :). De todas formas, debo asegurarme y preguntar en casa antes de empezar a cocinar :)
Conclusión
Puedes encontrar el ejemplo completo en https://github.com/isc-afuentes/recipe-inspector
Con este ejemplo sencillo hemos aprendido cómo utilizar técnicas LLM para extraer características y analizar ciertas partes de nuestros datos en InterSystems IRIS.
Con esto como punto de partida, podrías plantearte cosas como:
- Utilizar InterSystems BI para explorar y navegar tus datos utilizando cubos y cuadros de mando.
- Crear una aplicación web y añadir una interfaz gráfica (e.g. con Angular) para esta aplicación, podrías utilizar paquetes como RESTForms2 para generar automáticamente APIs REST para tus clases persistentes.
- ¿Qué tal si almacenas si una receta te gusta o no, y después intentas determinar si una nueva receta te gustará? Podrías plantearlo con IntegratedML, o incluso con LLM pasándole algunos datos de ejemplo e implementando un caso de uso tipo RAG (Retrieval Augmented Generation).
¿Qué otras cosas se os ocurren?