Uso de Python en InterSystems Iris
Uso de Python en InterSystems Iris
Hola
En este artículo veremos el uso de python como lenguaje de programación en InterSystems Iris. Para ello, utilizaremos como referencia la versión de Community 2025.1 que está disponible para ser descargada en https:// download.intersystems.com iniciando sesión en el entorno. Para obtener más información sobre cómo descargar e instalar Iris, consulte el enlace de la comunidad https://community.intersystems.com/post/how-download-and-install-intersystems-iris
Una vez instalado el iris, ahora necesitamos tener python disponible en nuestro entorno. Tenemos varios tutoriales que explican la instalación y configuración de python en Iris. Una buena fuente de referencia es el enlace a la documentación oficial de InterSystems en https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_epython
Una vez que hemos instalado y configurado python en Iris, podemos hacer una primera prueba: abrir el shell de python a través del terminal Iris. Para ello, abriremos una ventana de terminal Iris y ejecutaremos el comando Do $SYSTEM. Python.Shell():
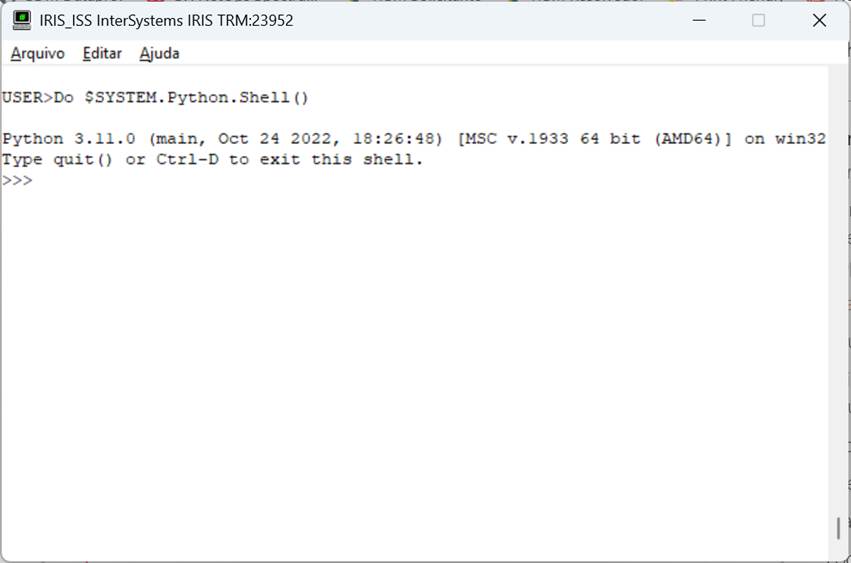
Fig. 1 – Pantalla de concha de Python en Iris
Si tienes tu entorno configurado correctamente, verás la pantalla de arriba. A partir de ahí podemos ejecutar comandos, como ver la versión de python. Para ello utilizaremos el módulo sys:
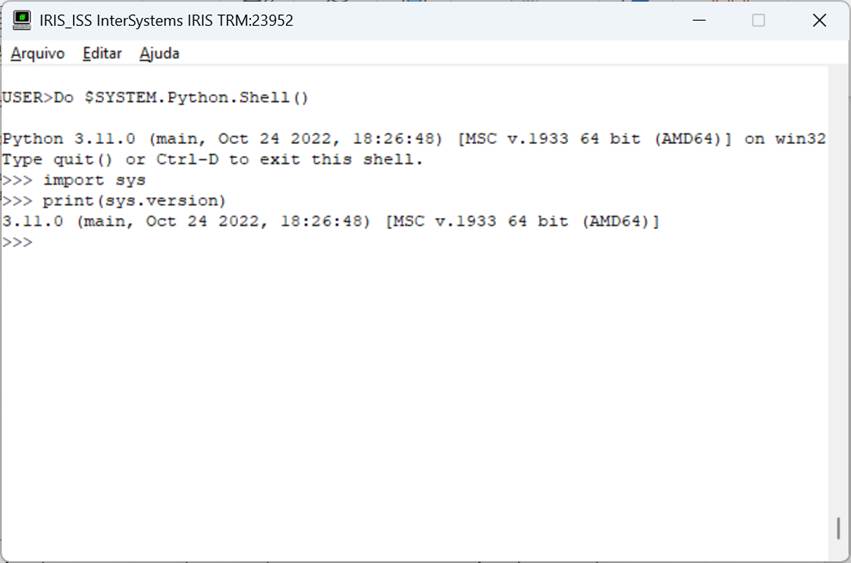
Fig. 2 – Pantalla de concha de Python en Iris
Listo. Tenemos a Iris y python listas para trabajar. Ahora podemos crear, por ejemplo, una clase Iris y programar algunos métodos usando python en ella. Veamos un ejemplo:
Class Demo.Pessoa Extends %Persistent
{
Property nome As %String;
Method MeuNome() [ Language = objectscript ]
{
write ..nome
}
Method MeuNomePython() [ Language = python ]
{
print(self.nome)
}
}
La clase anterior tiene una propiedad (nombre) y dos métodos, uno en objectscript y otro en python, solo para comparar. Llamando a estos métodos, tenemos el resultado en la siguiente pantalla:
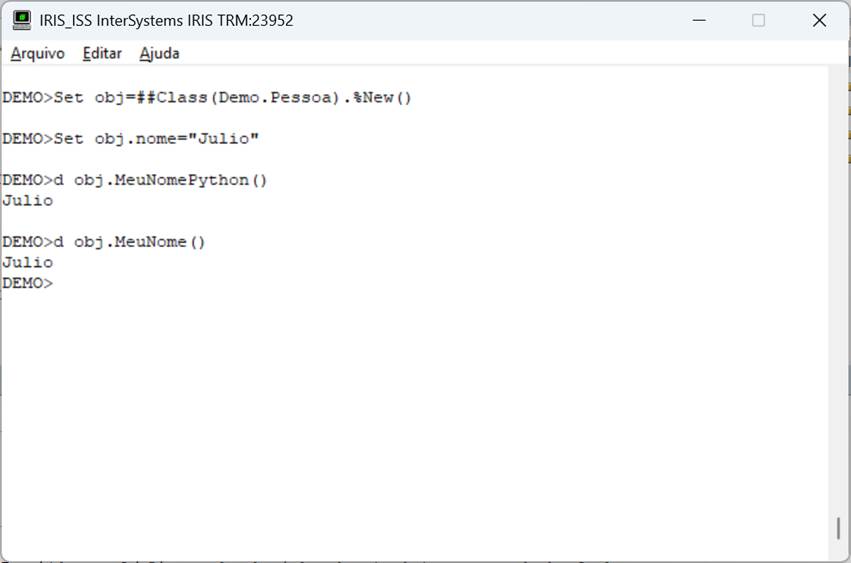
Fig. 3 – Llamada al método en Iris
Vea entonces que podemos tener en la misma clase métodos codificados en objectscript y en python. Y de uno de ellos podemos llamar al otro. Vea el siguiente ejemplo. Vamos a crear un nuevo método GetKey y desde el método MyPythonName vamos a hacer una llamada y recuperar la información:
Method MeuNomePython() [ Language = python ]
{
chave=self.GetChave()
print(self.nome)
print(chave)
}
Method GetChave() As %Integer [ Language = objectscript ]
{
Return $Get(^Chave)
}
Vamos a crear uno global con el valor que queremos que se recupere:
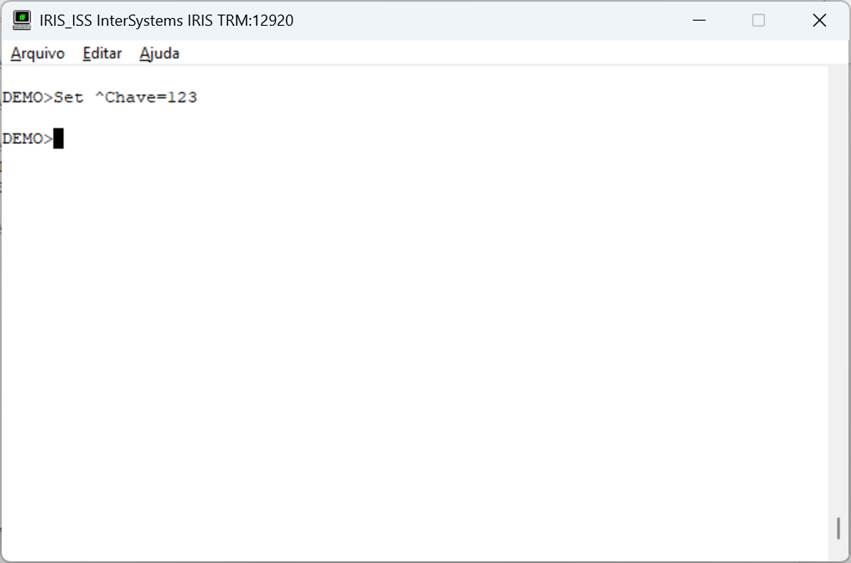
Fig. 4 – Creación de global en Iris
Listo. Con el global created, llamemos ahora a nuestro método:
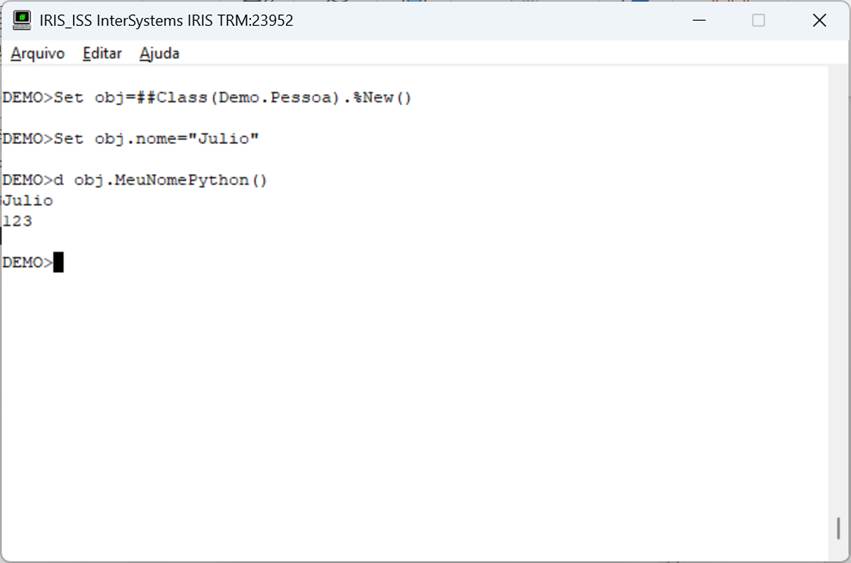
Fig. 5 – Llamada al método en Iris
Observe que ahora nuestro método python hace una llamada a otro método, este codificado en objectscript. Lo contrario también es cierto.
Python tiene una serie de bibliotecas útiles, como:
- iris: permite la interacción con la base de datos y el entorno de Iris
- matplot – Visualización de datos y gráficos
- numpy: proporciona soporte para matrices y estructuras de datos
- scikit-learn: le permite crear e implementar modelos de aprendizaje automático
- pandas: se utiliza para la manipulación y el análisis de datos
Otra característica presente en Iris con python es la posibilidad de acceder a los datos vía SQL, es decir, podemos tener los datos almacenados en tablas en Iris y código python consumiendo estos datos. Veamos un ejemplo de código que lee una tabla Iris y genera un archivo XLS utilizando la biblioteca Iris y Pandas:
ClassMethod tabela() As %Status [ Language = python ]
{
import iris
import pandas as pd
rs = iris.sql.exec("select * from demo.alunos")
df = rs.dataframe()
caminho_arquivo = 'c:\\temp\\dados.xlsx'
df.to_excel(caminho_arquivo, index=False)
return True
}
Como se ve, usamos las bibliotecas iris y pandas en el código. A continuación, creamos un conjunto de registros (rs) con el comando SQL deseado y después de eso un marco de datos pandas (df) de este conjunto de registros. Desde el marco de datos, exportamos los datos de la tabla a un archivo de Excel en la ruta especificada (df.to_excel). Fíjate que con muy pocas líneas armamos un código extremadamente útil. Aquí el uso de las bibliotecas de python fue clave. Ya nos han proporcionado el soporte para el dataframe (pandas) y a partir de ahí su manipulación (to_excel). Ejecutando nuestro código, tenemos la tabla de Excel generada a partir de los datos de la tabla:
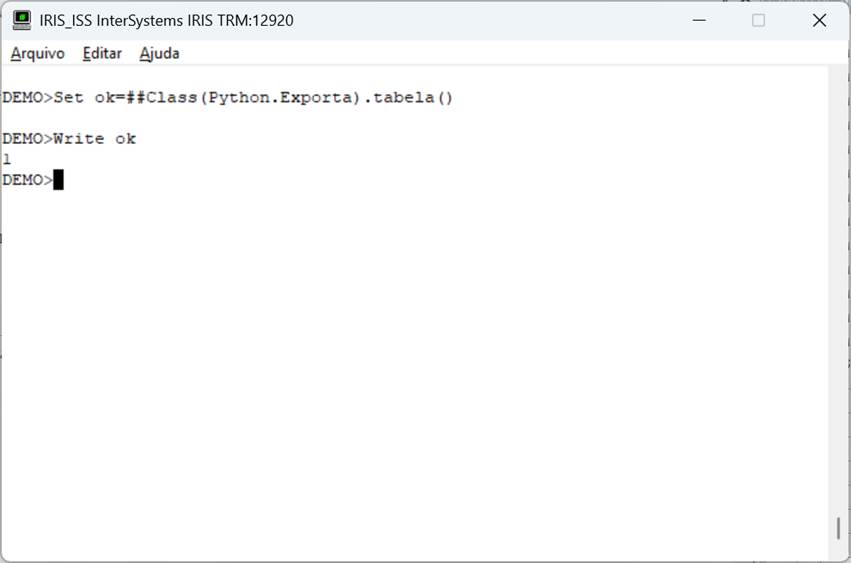
Fig. 6 – Llamada al método en Iris
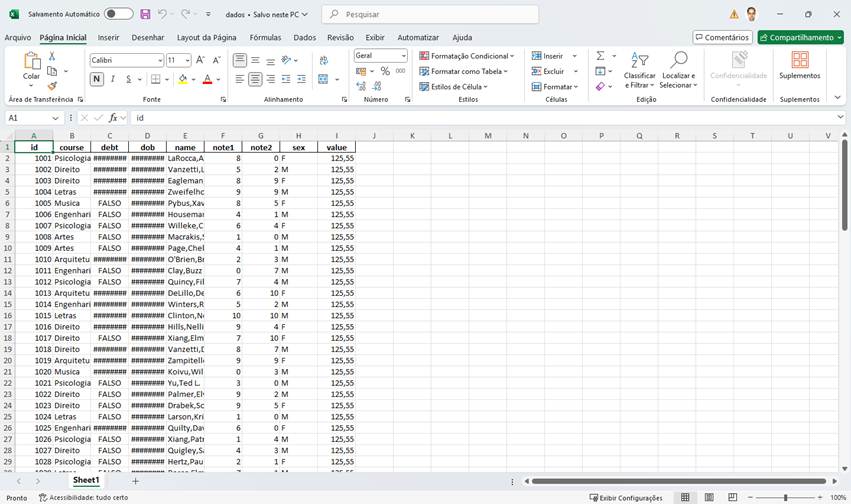
Fig. 7 – Hoja de trabajo generada por el método
Python tiene varias bibliotecas listas para usar con varias características, así como una gran cantidad de código en comunidades que se puede usar en aplicaciones.
Uno de ellos, que mencionamos anteriormente, es scikit-learn, que permite el uso de varios mecanismos de regresión, permitiendo la creación de métodos de predicción basados en información, como una regresión lineal. Podemos ver un ejemplo de código de regresión a continuación:
ClassMethod CalcularRegressaoLinear() As %String [ Language = python ]
{
import iris
import json
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("Agg")
rs = iris.sql.exec("select venda as x, temperatura as y from estat.fabrica")
df = rs.dataframe()
print(df)
# Reformatando x1 para uma matriz 2D exigida pelo scikit-learn
X = df[['x']]
y = df['y'] # Inicializa e ajusta o modelo de regressão linear
model = LinearRegression()
model.fit(X, y) # Extrai os coeficientes da regressão
coeficiente_angular = model.coef_[0]
intercepto = model.intercept_
r_quadrado = model.score(X, y)
# Calcula Y_pred baseado no X
Y_pred = model.predict(X)
# Calcula MAE
MAE = mean_absolute_error(y, Y_pred) # Previsão para a linha de regressão
x_pred = np.linspace(df['x'].min(), df['x'].max(), 100).reshape(-1, 1)
y_pred = model.predict(x_pred) # Geração do gráfico de regressão
plt.figure(figsize=(8, 6))
plt.scatter(df['x'], df['y'], color='blue', label='Dados Originais')
plt.plot(df['x'], df['y'], color='black', label='Linha dos Dados Originais')
plt.scatter(df['x'], Y_pred, color='green', label='Dados Previstos')
plt.plot(x_pred, y_pred, color='red', label='Linha da Regressão')
plt.scatter(0, intercepto, color="purple", zorder=5, label="Ponto do intercepto")
plt.title('Regressão Linear')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True) # Salvando o gráfico como imagem
caminho_arquivo = 'c:\\temp\\RegressaoLinear.png'
plt.savefig(caminho_arquivo, dpi=300, bbox_inches='tight')
plt.close()
# Formata os resultados em JSON
resultado = {
'coeficiente_angular': coeficiente_angular,
'intercepto': intercepto,
'r_quadrado': r_quadrado,
'MAE': MAE
} return json.dumps(resultado)
}
El código lee una tabla en Iris a través de SQL, crea un dataframe pandas basado en los datos de la tabla y calcula una regresión lineal, generando un gráfico con la línea de regresión, además de traer indicadores de regresión. Todo esto desde la biblioteca scikit-learn.
El artículo https://pt.community.intersystems.com/post/usando-o-python-no-intersystems-iris-%E2%80%93-calculando-uma-regress%C3%A3o-linear-simples proporciona más información sobre el uso de scikit-learn para calcular la regresión lineal.
Iris también permite el almacenamiento de datos vectoriales, lo que abre numerosas posibilidades. La biblioteca langchain_iris trae mecanismos que ayudan en el almacenamiento y recuperación de información en bases de datos vectoriales.
El siguiente código toma un archivo PDF y genera una base de datos vectorial con las incrustaciones generadas para futuras recuperaciones de datos:
ClassMethod Ingest(collectionName As %String, filePath As %String) As %String [ Language = python ]
{ import json
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader try:
apiKey = <chatgpt_api_key>
loader = PyPDFLoader(filePath)
splits = loader.load_and_split()
vectorstore = IRISVector.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(openai_api_key=apiKey),
dimension=1536,
collection_name=collectionName,
)
return json.dumps({"status": True})
except Exception as err:
return json.dumps({"error": str(err)})
}
Al leer el archivo PDF, se "divide" en partes y estas piezas se almacenan en forma de incrustaciones en Iris. Las incrustaciones son vectores que representan esa división.
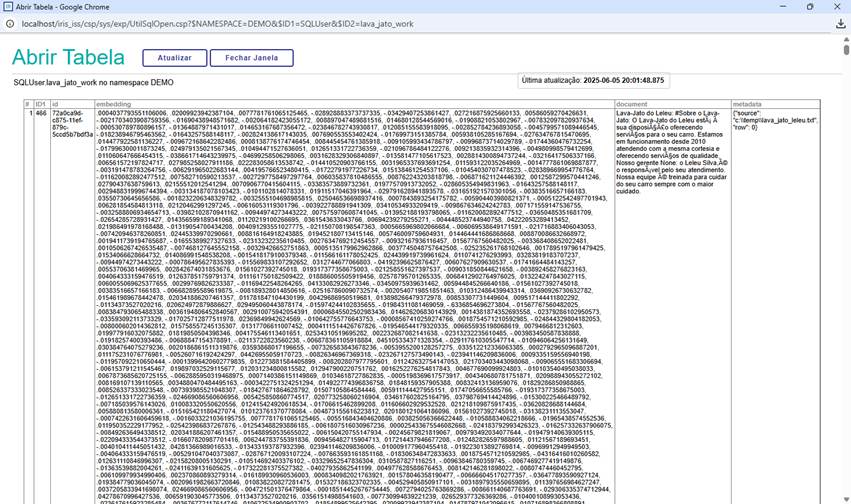
Fig. 8 – Tabla con columna vectorial en Iris
Una vez que se ha ingerido el archivo, ahora podemos recuperar información y pasarla al LLM para generar un texto de retorno basado en una pregunta formulada. La pregunta se convierte en vectores y se busca en la base de datos. A continuación, los datos recuperados se envían a LLM, que da formato a una respuesta. En el ejemplo usamos ChatGPT:
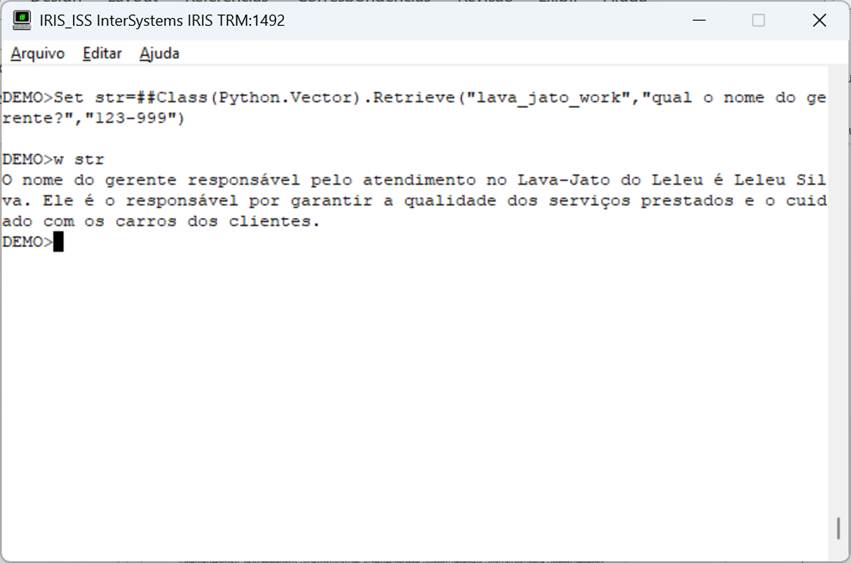
Fig.9 – Llamada al método en Iris
A continuación se muestra el código de la búsqueda realizada:
ClassMethod Retrieve(collectionName As %String, question As %String, sessionId As %String = "") [ Language = python ]
{
import json
import iris
from langchain_iris import IRISVector
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
try:
apiKey = <chatgpt_api_key>
model = "gpt-3.5-turbo"
llm = ChatOpenAI(model= model, temperature=0, api_key=apiKey)
embeddings = OpenAIEmbeddings(openai_api_key=apiKey) vectorstore = IRISVector(
embedding_function=OpenAIEmbeddings(openai_api_key=apiKey),
dimension=1536,
collection_name=collectionName,
) retriever = vectorstore.as_retriever() contextualize_q_system_prompt = """Dado um histórico de bate-papo e a última pergunta do usuário \
que pode fazer referência ao contexto no histórico do bate-papo, formule uma pergunta independente \
que pode ser entendido sem o histórico de bate-papo. NÃO responda à pergunta, \
apenas reformule-o se necessário e devolva-o como está."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
) qa_system_prompt = """
Você é um assistente inteligente que responde perguntas com base em dados recuperados de uma base. Dependendo da natureza dos dados, você deve escolher o melhor formato de resposta: 1. **Texto:** Se os dados contêm principalmente informações descritivas ou narrativas, responda em formato de texto.
2. **Tabela:** Se os dados contêm informações estruturadas (ex: listas, valores, métricas, comparações diretas), responda em formato HTML com o seguinte estilo:
- Bordas de 1px sólidas e de cor #dddddd.
- O cabeçalho deve ter um fundo cinza escuro (#2C3E50) e texto em branco.
- As células devem ter padding de 8px.
- As linhas pares devem ter um fundo cinza claro (#f9f9f9).
- As linhas devem mudar de cor ao passar o mouse sobre elas, usando a cor #f1f1f1.
- O texto nas células deve estar centralizado. 3. **Lista:** Se os dados contêm informações estruturadas (ex: listas, valores, métricas, comparações diretas), responda em formato HTML com o seguinte estilo:
- Bordas de 1px sólidas e de cor #dddddd.
- O cabeçalho deve ter um fundo cinza escuro (#2C3E50) e texto em branco.
- As células devem ter padding de 8px.
- As linhas pares devem ter um fundo cinza claro (#f9f9f9).
- As linhas devem mudar de cor ao passar o mouse sobre elas, usando a cor #f1f1f1.
- O texto nas células deve estar centralizado.
4. **Gráfico:** Se os dados contêm informações que são mais bem visualizadas em um gráfico (ex: tendências, distribuições, comparações entre categorias), gere um gráfico apropriado. Inclua um título, rótulos de eixo e uma legenda quando necessário. Responda utilizando um link do quickchart.io.
Contexto: {context}
Pergunta: {input}
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
) question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain) def get_session_history(sessionId: str) -> BaseChatMessageHistory:
rs = iris.sql.exec("SELECT * FROM (SELECT TOP 5 pergunta, resposta, ID FROM Vector.ChatHistory WHERE sessionId = ? ORDER BY ID DESC) SUB ORDER BY ID ASC", sessionId)
history = ChatMessageHistory()
for row in rs:
history.add_user_message(row[0])
history.add_ai_message(row[1])
return history def save_session_history(sessionId: str, pergunta: str, resposta: str):
iris.sql.exec("INSERT INTO Vector.ChatHistory (sessionId, pergunta, resposta) VALUES (?, ?, ?) ", sessionId, pergunta, resposta) conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
) ai_msg_1 = conversational_rag_chain.invoke(
{"input": question, "chat_history": get_session_history(sessionId).messages},
config={
"configurable": {"session_id": sessionId}
},
)
save_session_history(sessionId, question, str(ai_msg_1['answer']))
return str(ai_msg_1['answer'])
except Exception as err:
return str(err)
}
Aquí en este código entran varios aspectos que deben tenerse en cuenta en este tipo de código, como el contexto de la conversación, el prompt de LLM, las incrustaciones y la búsqueda vectorial.
E incluso podemos tener una interfaz para realizar las llamadas al método, lo que le da un aspecto más sofisticado a la consulta. En el ejemplo tenemos una página web accediendo a una api REST que llama al método de consulta:
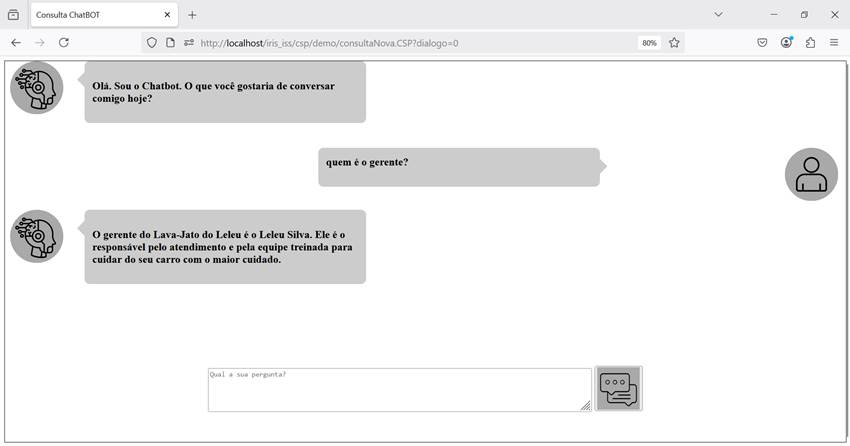
Fig. 10 – Llamada a la API REST en la pantalla de la aplicación web en Iris
Estos son ejemplos del uso de python en Iris. Pero el universo de bibliotecas disponibles es mucho mayor. Podemos usar bibliotecas para reconocimiento de imágenes, OCR, biometría, estadísticas y más.