Modelos LLM y aplicaciones RAG paso a paso - Parte III - Buscando e inyectando el contexto
Bienvenidos a la tercera y última entrega de nuestros artículos dedicados al desarrollo de aplicaciones RAG basadas en modelos LLM. En este artículo final veremos sobre nuestro pequeño proyecto de ejemplo como podemos encontrar el contexto más adecuado a la pregunta que deseamos enviar a nuestro modelo LLM y para ellos haremos uso de la funcionalidad de búsquedas vectoriales incluida en IRIS.

Búsquedas vectoriales
Un elemento clave de toda aplicación RAG es el mecanismo de búsquedas vectoriales, este permite buscar dentro de una tabla con registros de este tipo aquellos más similares al vector de referencia. Para ello es necesario previamente generar el embedding de la pregunta que se va a pasar al LLM. Echemos un vistazo a nuestro proyecto de ejemplo para ver como generamos dicho embedding y lo utilizamos para lanzar la consulta a nuestra base de datos de IRIS:
model = sentence_transformers.SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
question = model.encode("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?", normalize_embeddings=True)
array = np.array(question)
formatted_array = np.vectorize('{:.12f}'.format)(array)
parameterQuery = []
parameterQuery.append(str(','.join(formatted_array)))
cursorIRIS.execute("SELECT distinct(Document) FROM (SELECT VECTOR_DOT_PRODUCT(VectorizedPhrase, TO_VECTOR(?, DECIMAL)) AS similarity, Document FROM LLMRAG.DOCUMENTCHUNK) WHERE similarity > 0.6", parameterQuery)
similarityRows = cursorIRIS.fetchall()Como podéis ver, instanciamos el modelo generador de embeddings y vectorizamos la pregunta que vamos a remitir a nuestro LLM. A continuación lanzamos una consulta a nuestra tabla de datos LLMRAG.DOCUMENTCHUNK buscando aquellos vectores cuya similitud supere el 0.6 (este valor esta totalmente basado en el criterio del desarrollador del producto).
Como podéis ver el comando utilizado para la búsqueda es VECTOR_DOT_PRODUCT, pero no es la única opción, echemos un vistazo a las dos opciones de las que disponemos para las búsquedas de similitudes.
Producto escalar (VECTOR_DOT_PRODUCT)
Esta operación algebraica no es más que la suma de los productos de cada par de elementos que ocupan la misma posición en sus respectivos vectores, representandose tal que así:
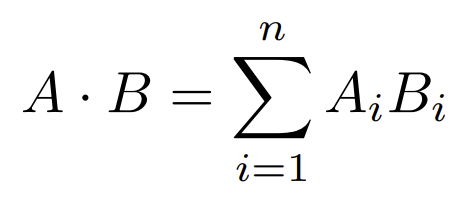
InterSystems recomienda la utilización de este método cuando los vectores sobre los que se trabajan son unitarios, es decir, su módulo es 1. Para los que no tengáis fresca el álgebra el módulo se calcula tal que así:

Similitud coseno (VECTOR_COSINE)
Dicho cálculo representa el producto escalar de los vectores dividido entre el producto de la longitud de los mismos y su fórmula es la siguiente:
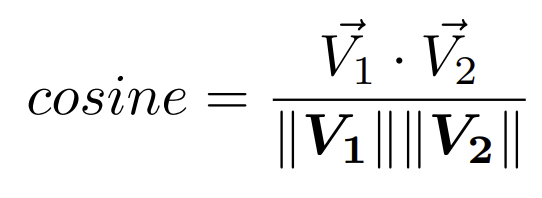
En ambos casos, cuanto más próximo sea el resultado a 1, mayor similitud entre los vectores existirá.
Inyección del contexto
Con la consulta anterior realizada obtendremos los textos que guardan relación con la pregunta que remitiremos al LLM, en nuestro caso no vamos a pasarle el texto que hemos vectorizado ya que nos resulta más interesante remitirle el documento entero con el prospecto del medicamento ya que el modelo de LLM será capaz de montar una respuesta mucho más completa con el documento íntegro. Echemos un vistazo a nuestro código para ver como lo estamos haciendo:
for similarityRow in similarityRows:
for doc in docs_before_split:
if similarityRow[0] == doc.metadata['source'].upper():
context = context +"".join(doc.page_content)
prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": lambda x: context, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?")Empezamos con un bucle for que nos recorrerá todos los registros vectorizados que son similares a la pregunta realizada. Como en nuestro ejemplo tenemos los documentos almacenados en la memoria del anterior paso de troceado y vectorizado lo hemos reutilizado en el segundo blucle para extraer el texto directamente, lo suyo sería acceder al documento que tendremos almacenado en nuestro sistema sin necesidad de utilizar ese segundo bucle for.
Una vez almacenado el texto de los documentos que van a formar el contexto de la pregunta en una variable el siguiente paso será el de informar al LLM de dicho contexto de la pregunta que le vamos a pasar. Una vez pasado el contexto sólo necesitamos enviar nuestra pregunta al modelo. En este caso queremos conocer que medicamentos podemos dar a nuestro hijo de 2 años para bajar la fiebre, veamos las respuestas sin contexto y con contexto:
Sin contexto:
La fiebre en niños pequeños puede ser preocupante, pero es importante manejarla adecuadamente. Para un niño de 2 años, los medicamentos más comúnmente recomendados para bajar la fiebre son el paracetamol (acetaminofén) y el ibuprofeno.
Con contexto:
Dalsy 40 mg/ml suspensión oral, que contiene ibuprofeno, puede ser utilizado en niños a partir de 3 meses para el alivio de la fiebre. La dosis recomendada para niños de 2 años depende de su peso y debe ser administrada por prescripción médica. Por ejemplo, para un niño de 10 kg, la dosis recomendada es de 1,8 a 2,4 mL por toma, con una dosis máxima diaria de 7,2 mL (288 mg). Siempre consulte a un médico antes de administrar cualquier medicamento a un niño.
Como podéis ver, cuando no disponemos de contexto la respuesta es bastante genérica, mientras que con el contexto adecuado la respuesta es mucho más directa e indicando que siempre debe ser bajo prescripción médica.
Conclusiones
En esta serie de artículos hemos presentado los fundamentos del desarrollo de aplicaciones RAG, como veis los conceptos básicos son bastante sencillos, pero ya se sabe que el demonio está siempre en los detalles, para todo proyecto es necesario tomar las siguientes decisiones:
- ¿Qué modelo LLM usar? ¿On premise o servicio online?
- ¿Qué modelo de embedding usar? ¿Funciona correctamente para el idioma que vamos a utilizar? ¿Necesitamos lematizar los textos que vamos a vectorizar?
- ¿Como vamos a trocear nuestros documentos para el contexto? ¿Por párrafo? ¿Por longitud de textos? ¿Con solapamientos?
- ¿Nuestro contexto sólo se basa en documentos no estructurados o tenemos diferentes orígenes de datos?
- ¿Necesitamos realizar re-ranking a los resultados de la búsqueda vectorial con la que hemos extraido el contexto? Y si es así ¿qué modelo aplicamos?
- ...
El desarrollo de aplicaciones RAG implica un mayor esfuerzo en la validación de los resultados que en el propio desarrollo técnico de la aplicación. Se debe estar muy muy seguro de que tu aplicación no proporcione respuestas erroneas o imprecisas, ya que podría tener graves consecuencias, no sólo legales sino también de confianza.
Comments
Fantástica aportación Luis
He incluido en el proyecto asociado un ejemplo utilizando en lugar de Mistral un modelo de respuestas a preguntas para poder ver la diferencia abismal que hay entre ambos casos, por si tenéis curiosidad.