Modelos LLM y aplicaciones RAG paso a paso - Parte I - Introducción
Seguramente hayáis oído en el último año hablar continuamente de los LLM (Large Language Model) y el desarrollo asociado a los mismos de las aplicaciones RAG (Retrieval Augmented Generation), pues bien, en esta serie de artículos desgranaremos los fundamentos de cada término utilizado y veremos como desarrollar una sencilla aplicación RAG.
¿Qué es un LLM?
Los modelos LLM forman parte de lo que conocemos como IA generativa y su fundamento es la vectorización de gigantescas cantidades de textos. Mediante esta vectorización obtendremos un espacio vectorial (valga la redundancia) en las que palabras o términos relacionadas estarán más próximas entre si que respecto a palabras menos relacionadas.
.png)
Si bien la forma más sencilla de visualizarlo es un gráfico de 3 dimensiones como el de la anterior imagen el número de dimensiones podrá ser tan grande como se desee, a mayores dimensiones más precisión en las relaciones entre términos y palabras y mayor consumo de recursos del mismo.
Estos modelos son entrenados con conjuntos masivos de datos que les permite disponer de la información suficiente para poder generar textos relacionados con la petición que se les haga, pero... ¿cómo sabe el modelo que términos están relacionados con la pregunta realizada? Muy sencillo, por la llamada "similitud" entre vectores, esto no es más que un cálculo matemático que nos permite dilucidar la distancia que hay entre dos vectores. Los cálculos más comunes son:
Mediante ese tipo de cálculo el LLM podrá montar una respuesta coherente basada en términos próximos a la pregunta realizada en relación a su contexto.
Todo esto está muy bien, pero estos LLM tienen una limitación de cara a su aplicación para usos específicos ya que la información con la que han sido entrenados suele ser bastante "general", si deseamos que un modelo LLM se adapte a las necesidades específicas de nuestro negocio tendremos dos opciones:
Fine tuning
El fine tuning es una técnica que permite el reentrenado de modelos LLM con datos relativos a una temática en específico (lenguaje procesal, terminología médica, etc). Mediante esta técnica se podrá disponer de modelos más ajustados a nuestra necesidad sin tener que entrenar un modelo desde 0.
La principal pega de esta técnica es que todavía necesitamos proporcionarle al LLM una cantidad ingente de información para dicho reentrenamiento y en ocasiones este puede quedarse "corto" para las expectativas de un determinado negocio.
Retrieval Augmented Generation
El RAG es una técnica que permite incluir al LLM el contexto necesario para contestar a una determinada pregunta sin necesidad de entrenar o reentrenar al modelo específicamente con la información relevante.
¿Cómo incluimos el contexto necesario a nuestro LLM? Muy sencillo, en el momento de enviar la pregunta al modelo le indicaremos explícitamente que tenga en consideración la información relevante que adjuntamos para contestar a la consulta realizada y para ello haremos uso de bases de datos vectoriales de las que podamos extraer el contexto relacionado con la pregunta remitida.
¿Cual es la mejor opción para mi problemática, Fine tuning o RAG?
Ambas opciones tienen sus ventajas y sus inconvenientes, por un lado el Fine tuning te permite incluir dentro del modelo LLM toda la información relativa al problema que quieres resolver, no necesitando de terceras tecnologías como puede ser una base de datos vectorial donde almacenar contextos, pero por otra parte te ata al modelo reentrenado, y si este no cubre las espectativas del mismo la migración a uno nuevo puede ser bastante tedioso.
Por otra parte RAG necesita de funcionalidades como las búsquedas vectoriales para poder conocer cual es el contexto más exacto a la pregunta que estamos pasando a nuestro LLM. Este contexto deberá almacenarse en una base de datos vectorial sobre la que posteriormente realizaremos consultas para extraer dicha información. La principal ventaja (a parte de indicarle al LLM explicitamente que utilice el contexto que le proporcionamos) es que no estamos atados al modelo LLM, pudiendo cambiarlo por otro que sea más ajustado a nuestras necesidades.
Como hemos presentado al comienzo del artículo, nos centraremos en el desarrollo de un ejemplo de aplicación en RAG (sin grandes pretensiones, sólo demostrar como podéis empezar).
Arquitectura de un proyecto RAG
Veamos de forma somera cual sería la arquitectura necesario para un proyecto RAG:
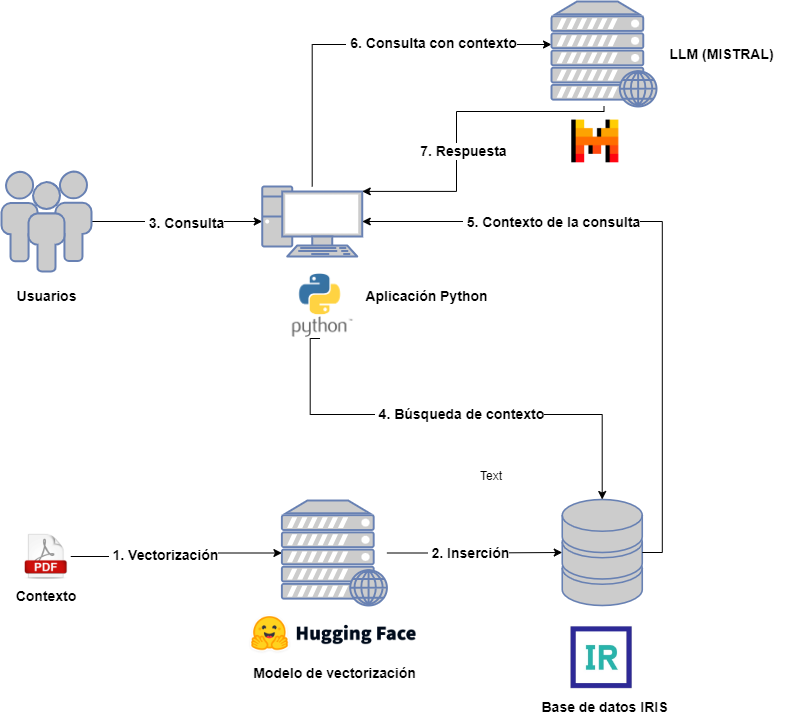
Por un lado tendremos los siguientes actores:
- Usuarios: que interactuarán con el LLM enviando consultas.
- Contexto: proporcionado previamente para incluirlo en las consultas del usuario.
- Modelo de vectorización: para vectorizar los diferentes documentos asociados al contexto.
- Base de datos vectorial: en este caso será IRIS y almacenará las diferentes partes de los documentos de contexto vectorizadas.
- LLM: modelo LLM que recibirá las consultas, para este ejemplo hemos elegido MISTRAL.
- Aplicación Python: destinada a la consulta sobre la base de datos vectorial para la extracción del contexto y su inclusión en la consulta al LLM.
Para no enredar demasiado el diagrama he obviado la aplicación encargada de la captura de los documentos del contexto, de su troceo y posterior vectorización e inserción. En la aplicación asociada podréis consultar este paso así como el posterior relativo a la consulta para la extracción, pero no os preocupéis, lo veremos con más detalle en los próximos artículos.
Asociado a este artículo tenéis el proyecto que usaremos como referencia para explicar con detalle cada paso, dicho proyecto está contenerizado en Docker y podéis encontrar una aplicación en Python haciendo uso de Jupyter Notebook y una instancia de IRIS. Necesitaréis una cuenta en MISTRAL AI para incluir la API Key que os permita el lanzamiento de consultas.
.png)
En la próxima entrega veremos como registrar nuestro contexto en una base datos vectorial. ¡Permanezcan a la escucha!
Comments
Muy buen artículo @Luis Angel Pérez Ramos ... nos quedamos con ganas de más! 😉