これは InterSystems FAQ サイトの記事です。
新しいインデックスを定義した後、インデックスの再構築が完了する前にクエリを実行するとデータが存在しているにもかかわらず「検索結果0件」や検索結果数が徐々に増えるような状況が発生します。
インデックスを永続クラス定義(またはテーブル定義)に追加しコンパイルすることで今まで使用していたクエリ実行経路が削除され、再度同じクエリを実行するタイミングで新しいインデックス定義を含めた実行経路が作成されるためです。(この時にインデックス再構築が完了していないとインデックスデータが存在しない、または不完全であるため0件や徐々に検索結果数が増えるような状況を起こします。)
これを起こさなために、新しいインデックスの再構築が終了するまでクエリオプティマイザにインデックスを使用させないように指定する方法が用意されています。
※ 2024/8/2: 2024.1以降から利用できる方法を追加しました。
2024.1以降
CREATE INDEXのDEFERオプションを使用します(オプションを付けないCREATE INDEX文では、作成時にインデックスの再構築も同時に行われます)。
DEFERオプションを使用することで、インデックスは追加されますがインデックスの再構築は行われず、追加したインデックスはクエリオプティマイザが使用しないように「選択不可」に設定されます。
再構築が行えるタイミングで BUILD INDEX文を利用することで、再構築が終了すると同時に追加したインデックスが「選択可能」に自動的に設定されます。
なお、追加したインデックスの選択可/不可は管理ポータルのSQL画面で確認できます(管理ポータル > [SQL] > ネームスペース選択 > テーブル選択 > (画面右)カタログの詳細 > [マップ/インデックス]をチェック)。
※インデックスの「選択可能」「選択不可」は、以降でご紹介するSetMapSelectability()メソッドを利用しても変更できます。
※永続クラス定義を利用している場合、デフォルトではDDLの発行が無効化されています。クラス定義文に DdlAllowed属性 を追加することでDDL文の発行ができます(設定後、クラス定義をコンパイルする必要があります)。
以下定義を行った場合は、管理ポータルでは図のように見えます。
CREATE INDEX NameIdx On Sample.Person (Name) DEFER
CREATE INDEX PrefIdx On Sample.Person (Pref)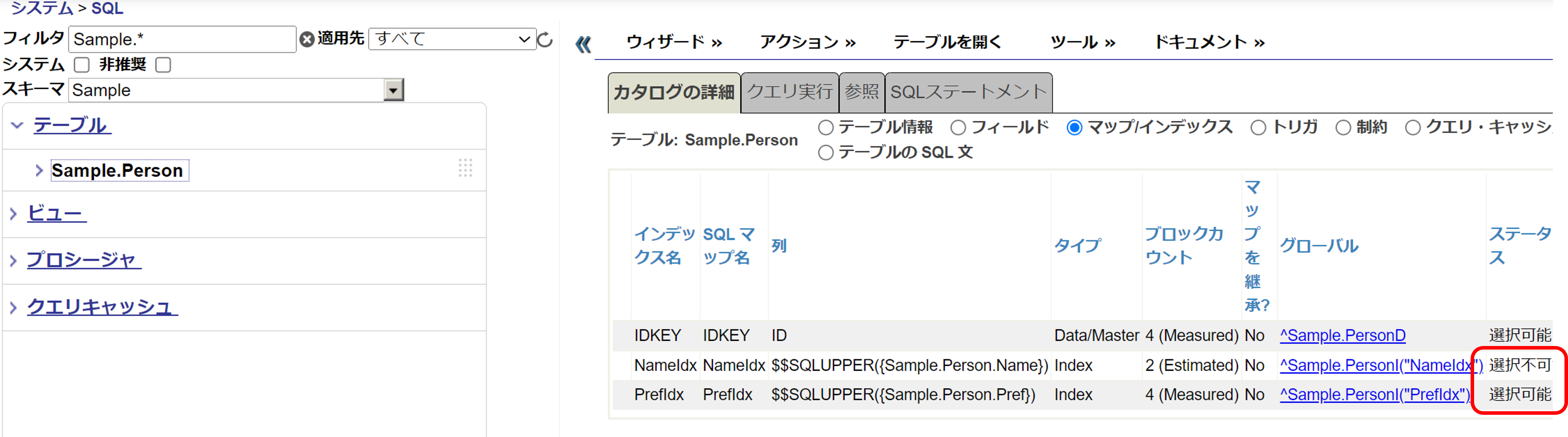
インデックス追加から再構築までの手順は以下の通りです。
1) 永続クラス定義の場合、DdlAllowed属性を設定します。
Class Sample.Person Extends %Persistent [ DdlAllowed ]
2) CREATE INDEXのDEFERオプションを付けてインデックス定義を追加します。
CREATE INDEX NameIdx On Sample.Person (Name) DEFER
3) 再構築ができるタイミングで、BUILD INDEXを実行します。
BUILD INDEX FOR TABLE Sample.Person INDEX NameIdx
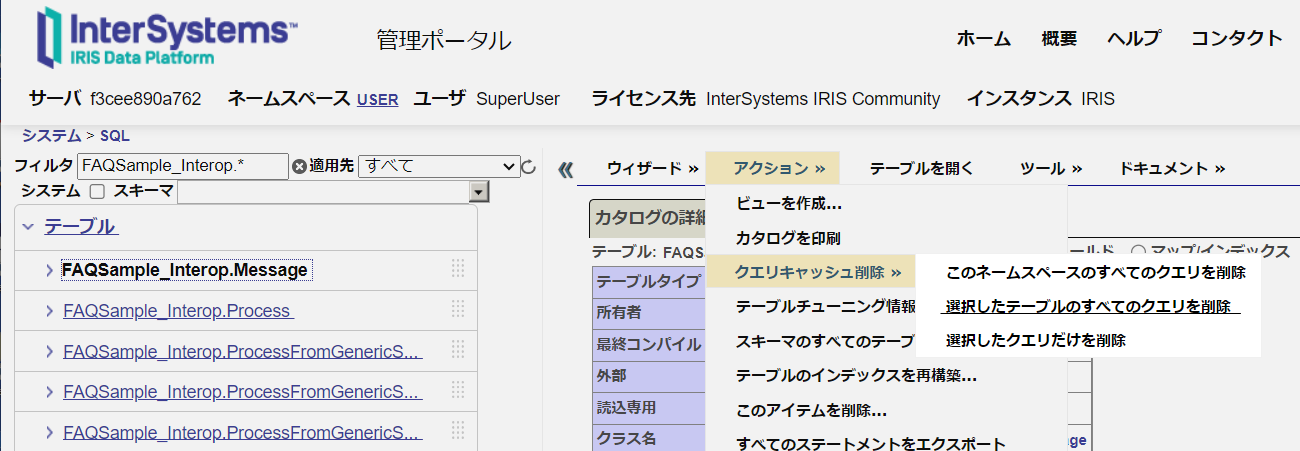
4) BUILD INDEXが終了したら、追加したインデックスで影響を受けそうなクエリキャッシュを破棄します。
管理ポータルでクエリキャッシュを削除するには、管理ポータル > [システムエクスプローラ] > [SQL] > (対象ネームスペースに切り替えた後) > [アクション] > [クエリキャッシュ削除]
プログラムからキャッシュを破棄する場合は、「プログラムでクエリキャッシュを削除する方法」をご参照ください。
2023.1以前
2022.1以降では、$SYSTEM.SQL.Util.SetMapSelectability()を使用します。
※インデックスの再構築が完了したら、必ず指定を元に戻してください。
(2021.1以前では、$SYSTEM.SQL.SetMapSelectability()を使用します。引数の指定方法は2022.1以降と同様です。)
SetMapSelectability()メソッドは%Statusの戻り値が設定されています。
ステータスOKの場合は1が戻ります。エラーステータスの場合は以下のメソッドを使用してエラー内容を確認してください。
write $SYSTEM.Status.GetErrorText(ステータスが入った変数)
以下、Training.Employeeに新インデックス:NewIndexを定義する例でご紹介します。
1) 定義予定の新インデックス名をクエリオプティマイザが使用しないように設定します。
set status=$SYSTEM.SQL.Util.SetMapSelectability("Training.Employee","NewIndex",0)- 第1引数:クラス名
- 第2引数:インデックス名(これから指定する新インデックス名を指定します。)
- 第3引数:隠す場合は0、見せる場合は1
2) インデックスを追加します。
- 永続クラスの場合はインデックスを追加しコンパイルし、インデックス再構築を実行します。
- SQL文で実行する場合はCREATE INDEXを実行した後インデックス再構築が自動的に開始されます。
3) クエリオプティマイザにインデックスを見せるように変更します。
※インデックスの再構築が終了してから行います。
$system.SQL.Util.SetMapSelectability("Training.Employee","NewIndex",1)4) クエリキャッシュを削除します。
方法詳細は、2024.1以降の手順でご紹介した図解をご参照ください。
関連項目として、インデックスの再構築を複数のプロセスで行う方法もあります。
詳細は:「アプリケーション使用中にインデックス再構築を複数プロセスで実行する方法」をご覧ください。
《注意》CREATE INDEX文でインデックスを追加した場合、インデックス追加後すぐに再構築が開始されますが、インデックスをクラス定義文で追加した場合インデックス再構築は実行を命令するまで開始されません。
 Open Exchange
Open Exchange.png)
.png)
.png)