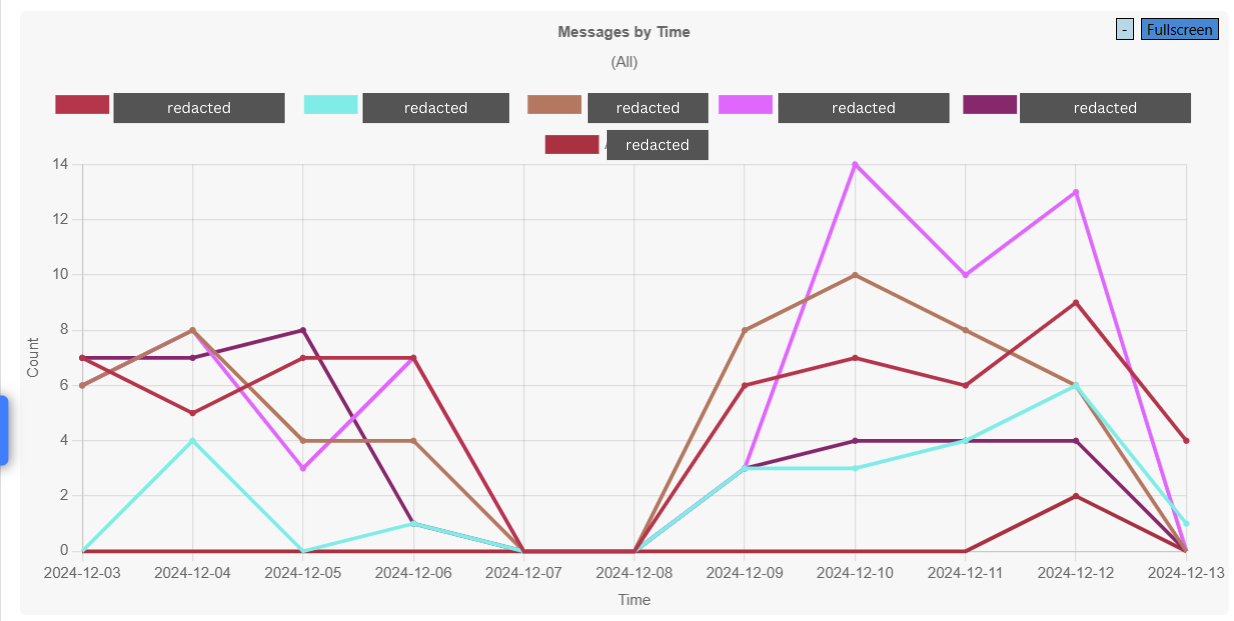
.jpg)
 Open Exchange
Open ExchangeThe latest "Bringing Ideas to Reality" InterSystems competition saw me trawling through the ideas portal for UI problems to have a go at.
I implemented the following ideas in the IRIS Whiz browser extension, so if you use the management portal to help with your day-to-day integration management this extension could be for you!
Feature Added: Queue refresh
Iris now has an auto refresh dropdown for the Queues page. Will refresh the queue at the interval selected. Does not load on Ensemble as it already has this feature.
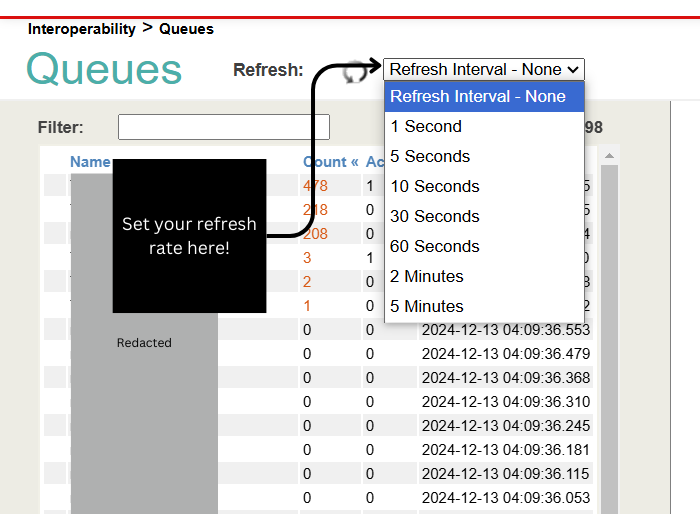
Useful if you have an upcoming clicking competition and need to rest your clicking finger.
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-487
Feature Added: Export Search as CSV
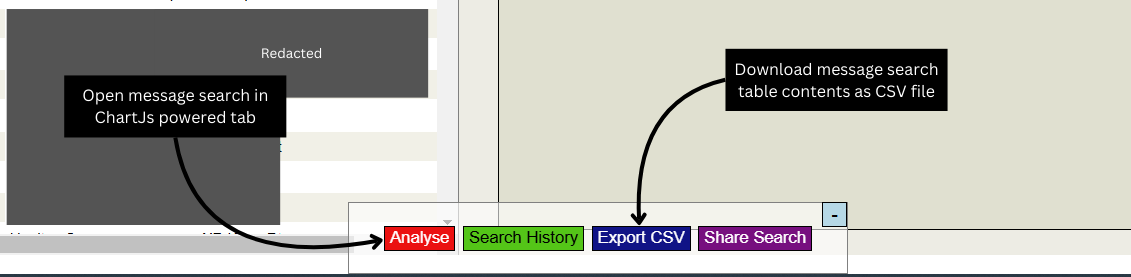
On the Message Viewer page you can click the Iris Whiz Export button to download a CSV copy of the data currently in your search table.
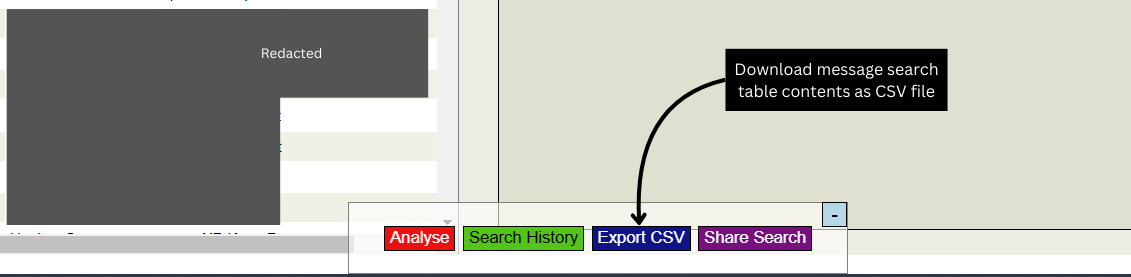
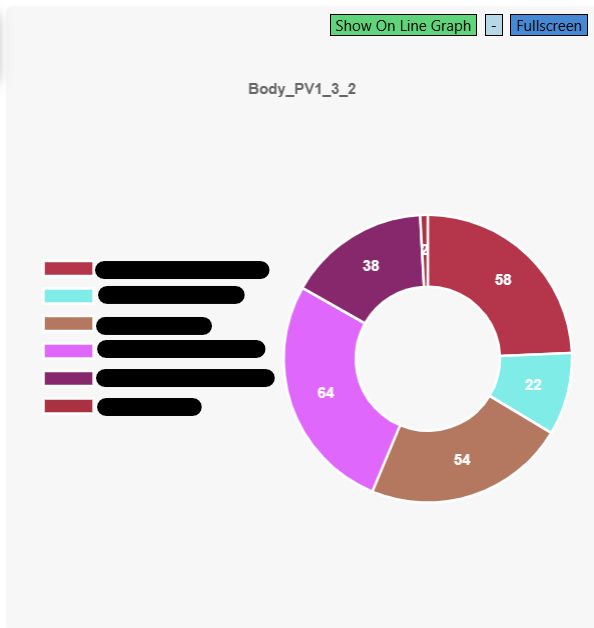
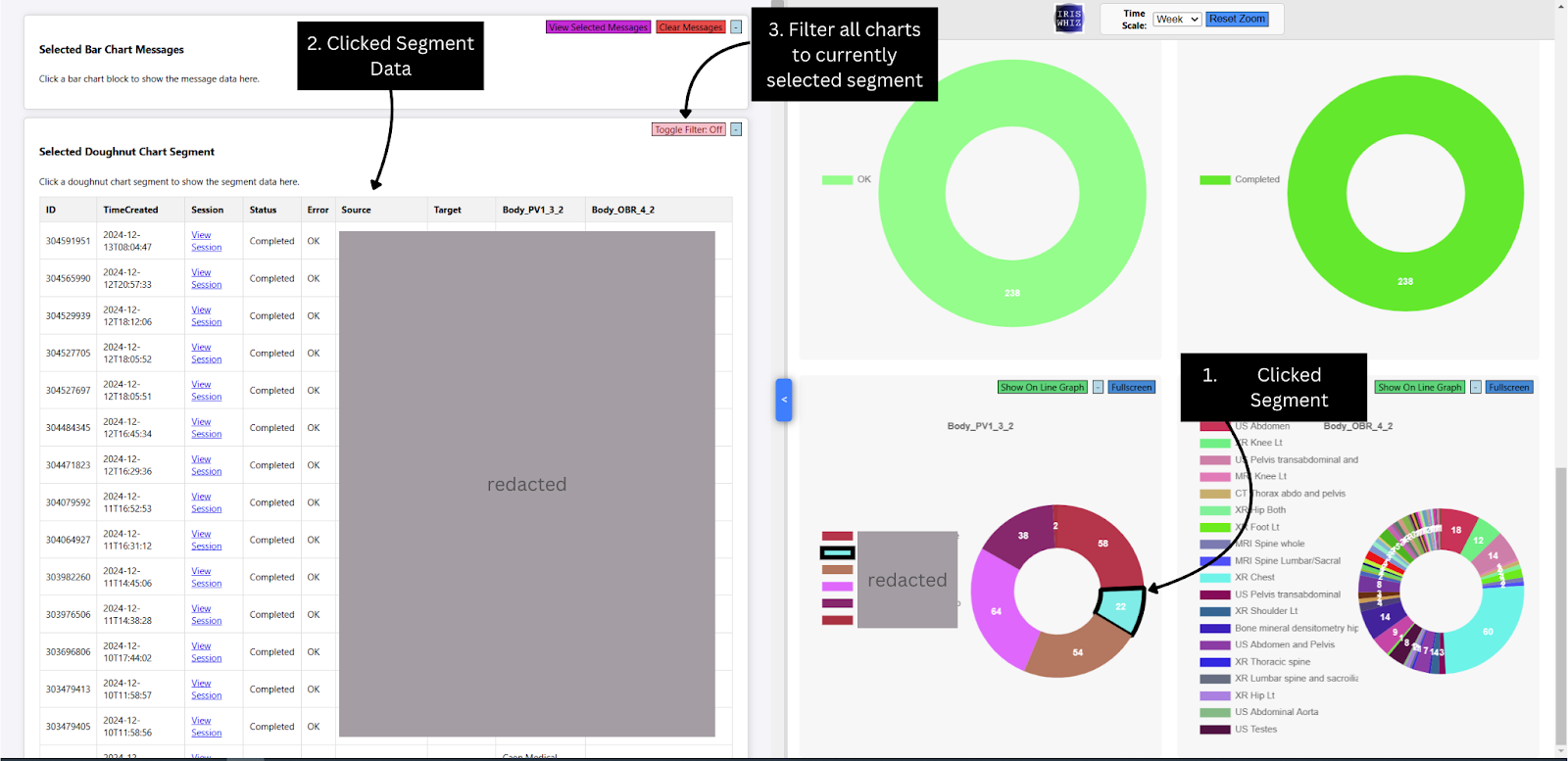
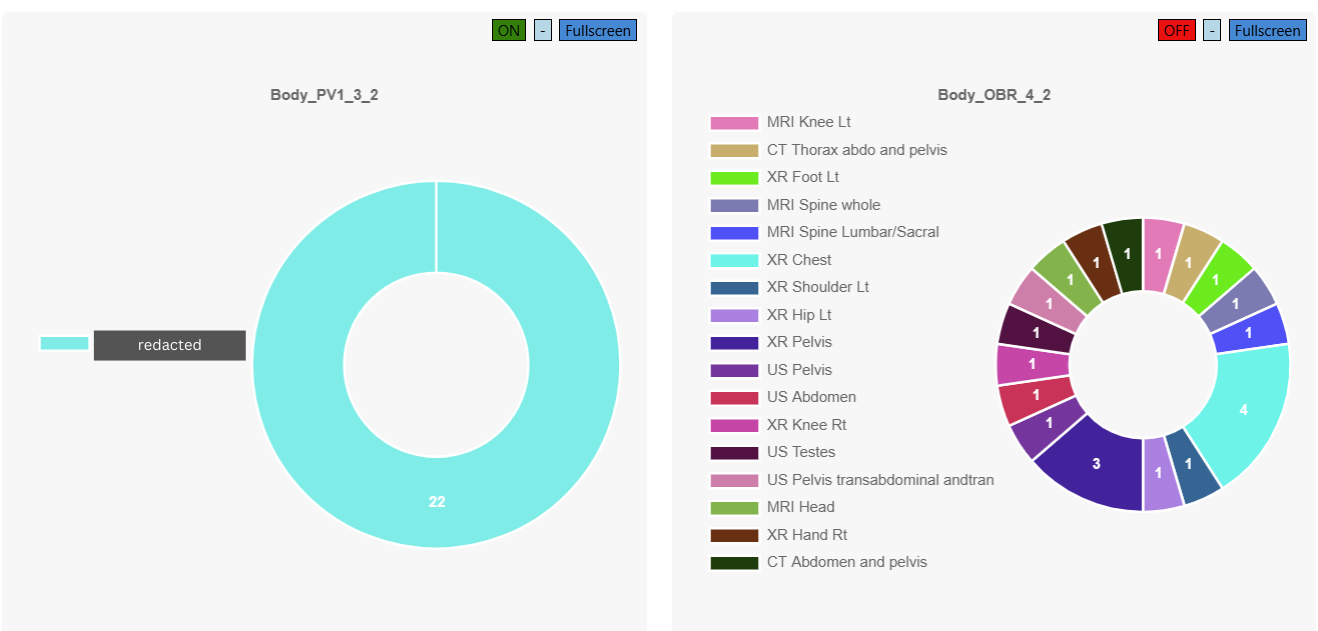
Useful if you want to do quick analysis on your data but don't want to use the fancy new Chart.JS page I spent ages creating (see that in action here!).
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-566
Feature Added: Production Page Queue Sort
Added sort options for the queue tab on the production page. Defaults to sorting by error count. Click a table header to switch between asc and desc sort order. Use the search bar to find items quickly.
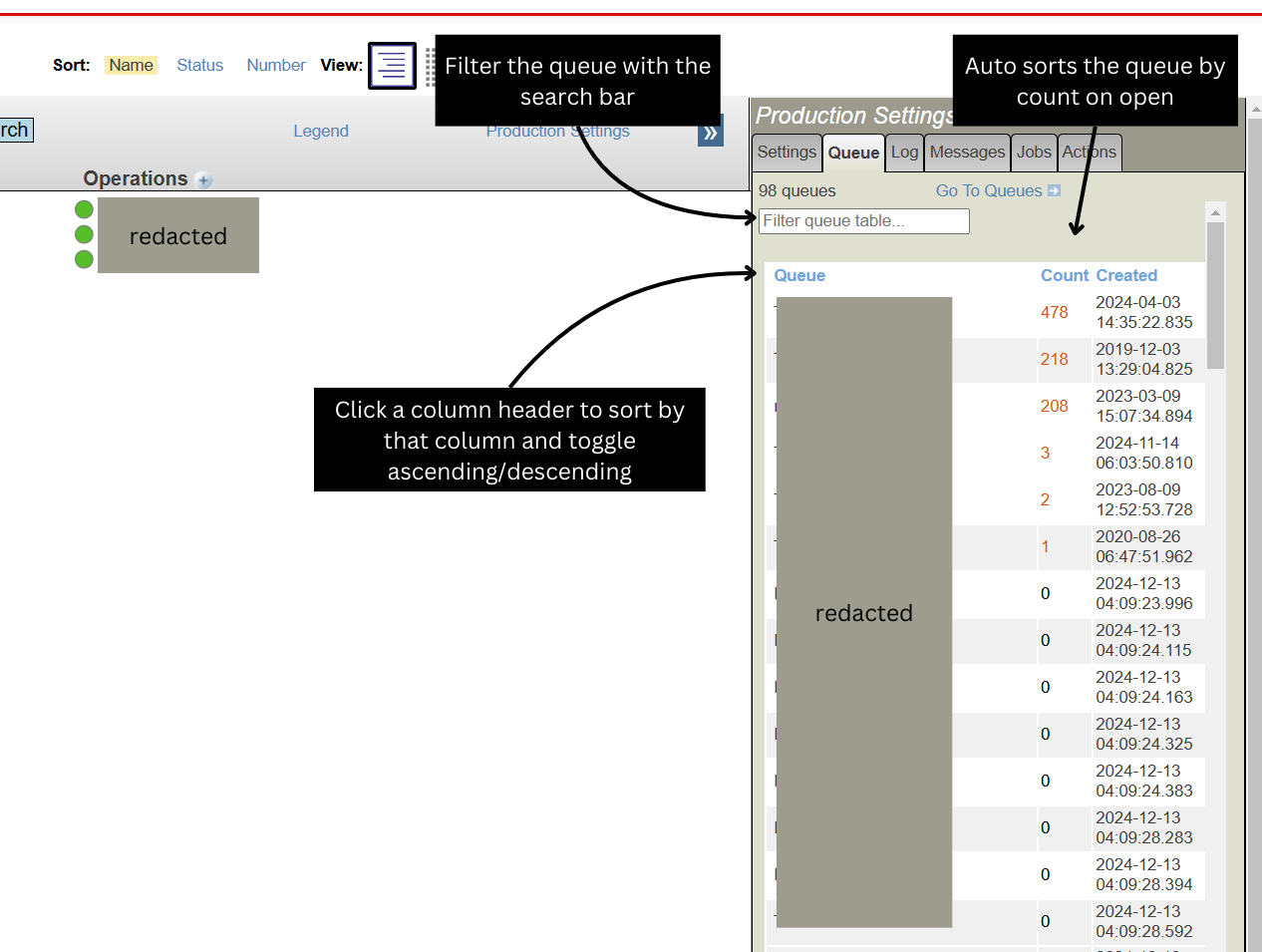
Useful if you don’t want to scroll to get to the biggest queue.
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-628
Feature Added: Category Dropdown Case-Insensitive Order
Alphabetises the category dropdown list on the production page, regardless of case. Without this the order is case dependent.
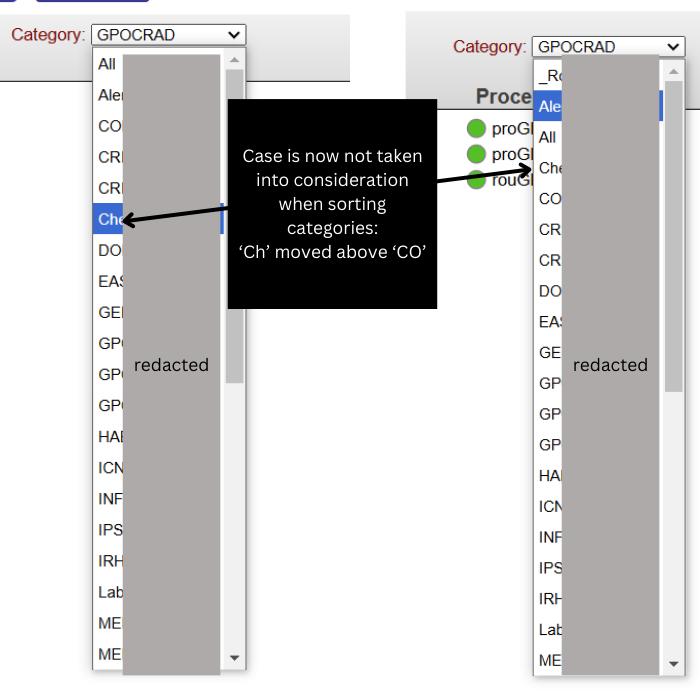
Useful if you want to find things in the category list but don’t want to have to re-categorise everything into the same case to do it.
Implemented from idea: https://ideas.intersystems.com/ideas/DPI-I-625
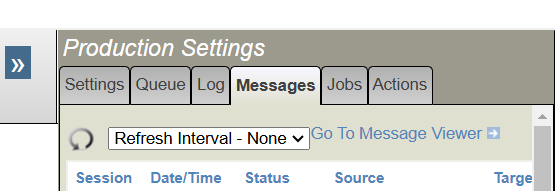
Bonus!
There’s also a refresh rate on the message viewer tab on the production page. This will also refresh your queue tab if you select an interval and navigate to the queue tab.
If you like any of these ideas please download the browser extension and let me know your thoughts. You can find a setup video on the OpenExchange listing which I recommend watching as you will need to complete some of it for most of the functionality to work!