Demostración simple de LowCode que transforma mensajes HL7 SIU a Kafka y luego consume mensajes Kafka para almacenarlos en IRIS a través de SQL
Configuración de producción
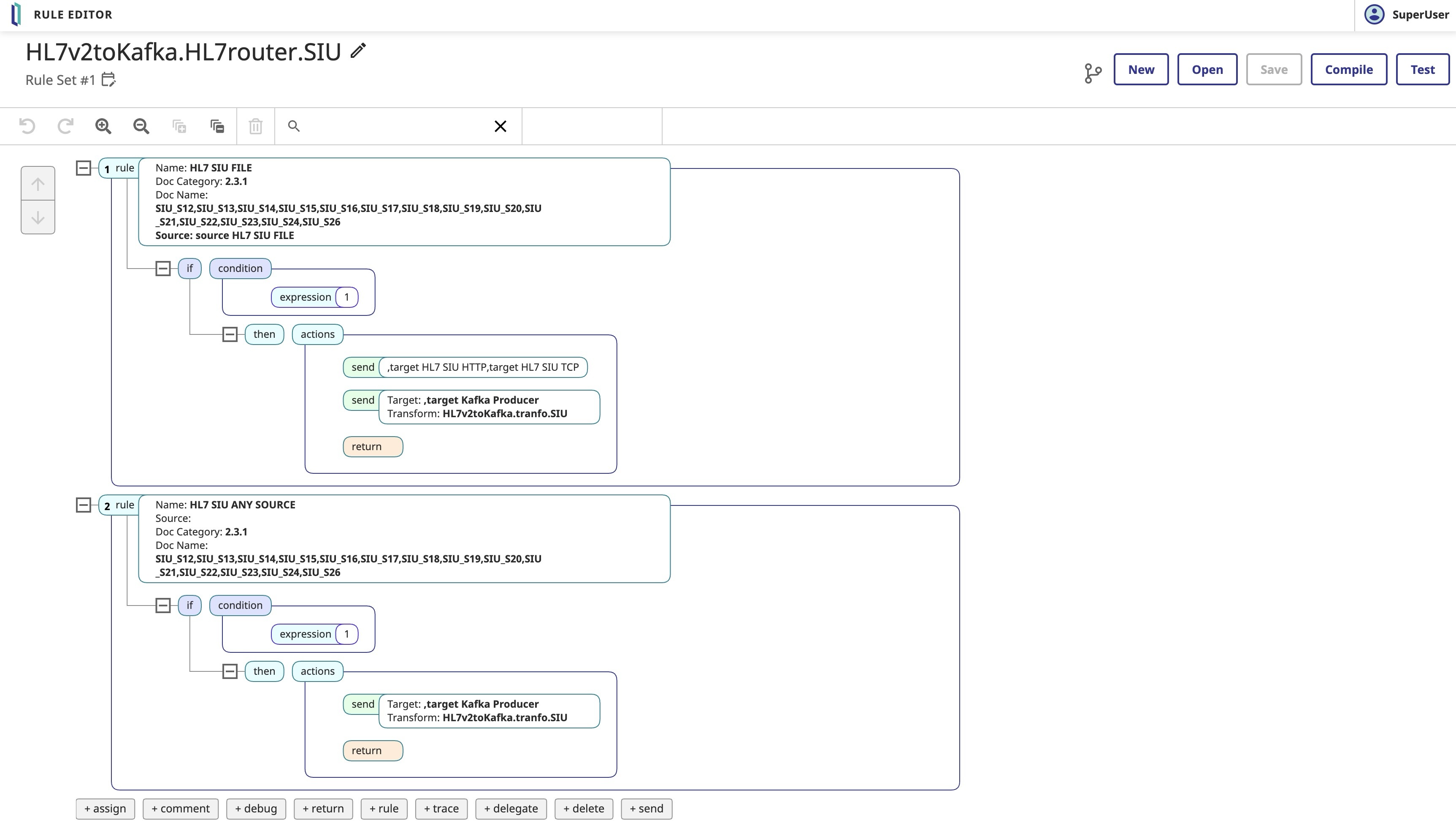
Esta demostración tiene una producción de interoperabilidad con 16 elementos.

Configuración de producción HL7 + Kafka Producer
La primera parte de esta demostración consiste en enviar un archivo HL7 SIU que será transmitido a los otros 2 flujos HL7 (HTTP y TCP), y transformado y transmitido al servidor Kafka. Los flujos HTTP y TCP transformarán los mensajes HL7 del mismo modo antes de enviarlos también a Kafka.
- 3 Servicios HL7
- 1 Enrutador HL7
- 2 Operaciones HL7
- 1 Operación de Negocio que envía los mensajes transformados a Kafka

Reglas de negocio
La producción tiene un proceso de negocio con un enrutador HL7, que transforma y envía mensajes HL7 a Kafka.
Transformación de datos
Data Transformation Builder permite la edición de la definición de una transformación entre fuentes SIU HL7v2 en mensajes Kafka. Transformación de datos
![]()
Visual Trace
Después de que se haya procesado un mensaje HL7, es decir, al copiar algunos mensajes de /data/HL7/test al directorio /data/HL7/in), podréis ver su seguimiento visual.

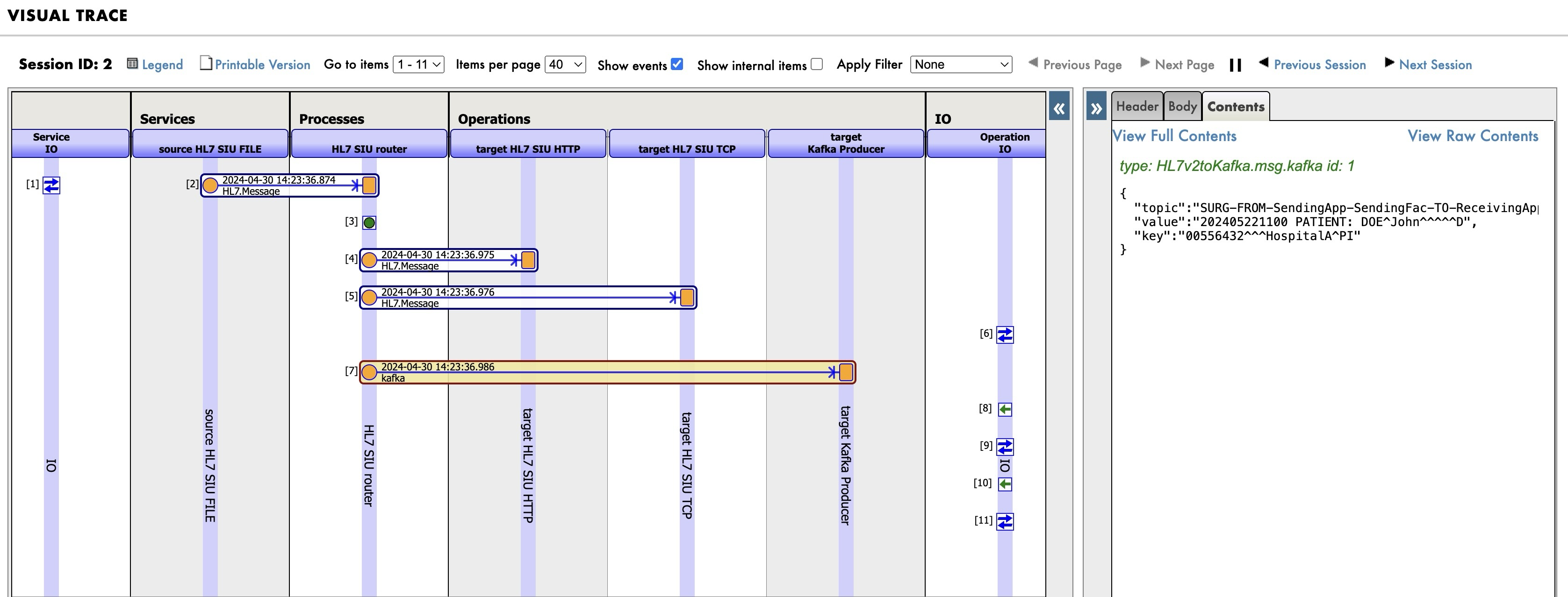
Podéis ver aquí el mensaje con I/O y el HL7 ACK
Kafka Manager
Luego, podéis verificar los mensajes en Kafka, usando la interfaz KafkaManager y obteniendo datos de los diferentes temas.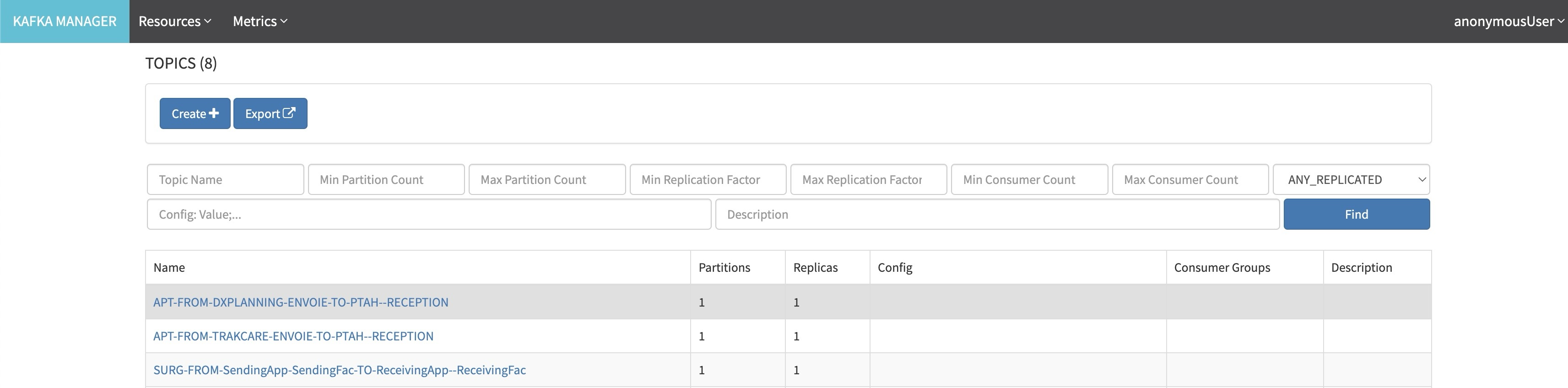
Y el contenido de un tema: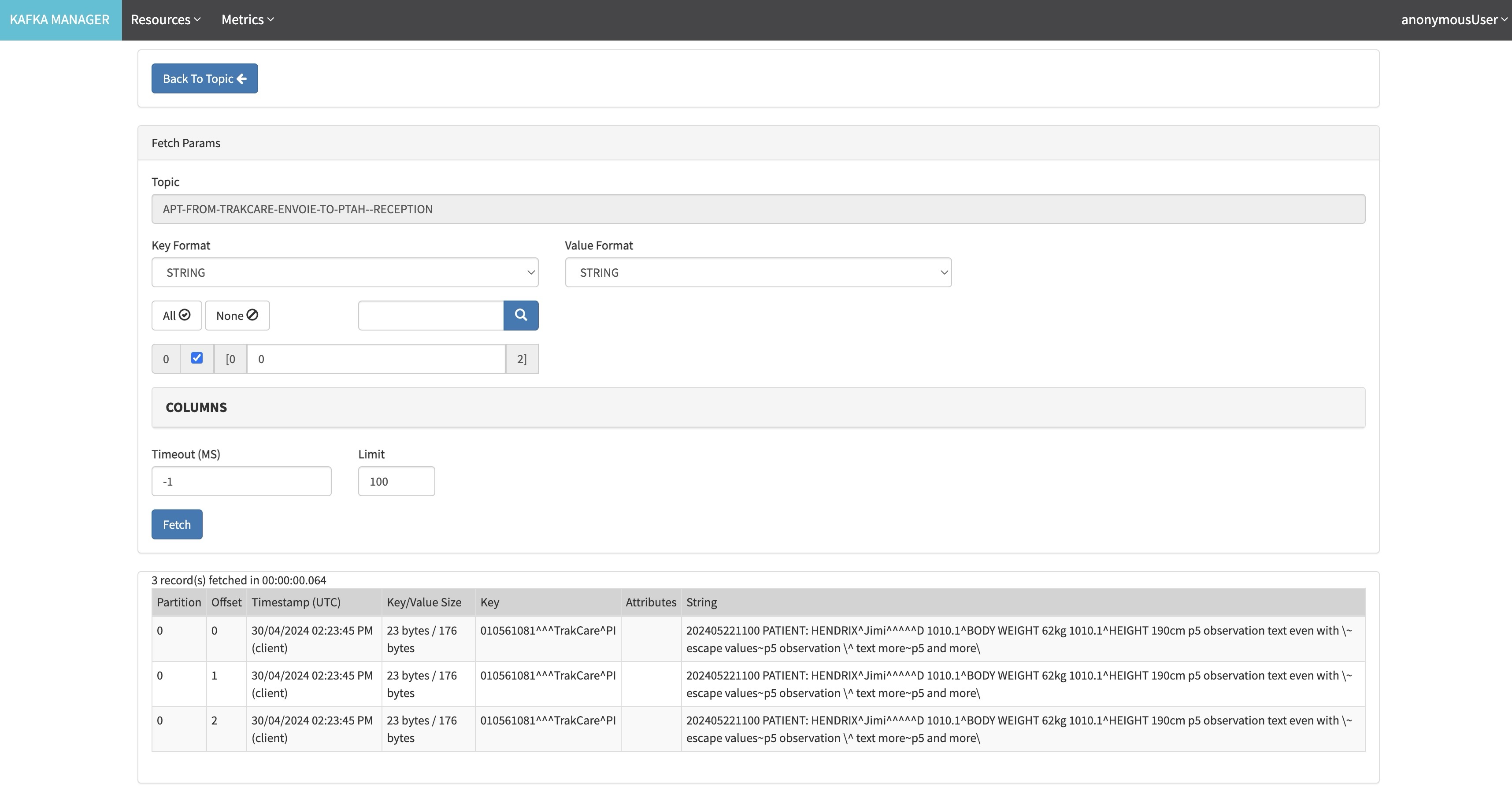
Configuración de Producción Kafka Consumer + SQL IRIS
La segunda parte de esta demostración consiste en consumir mensajes Kafka y enrutarlos a tablas IRIS a través de componentes SQL.
- 3 Servicios de Kafka que consumen 3 temas de Kafka
- 1 Enrutador
- 3 Operaciones SQL insertando datos en la base de datos IRIS

Reglas de negocio
La producción tiene un proceso de negocio con un enrutador Kafka, que envía mensajes Kafka a los componentes IRIS SQL. 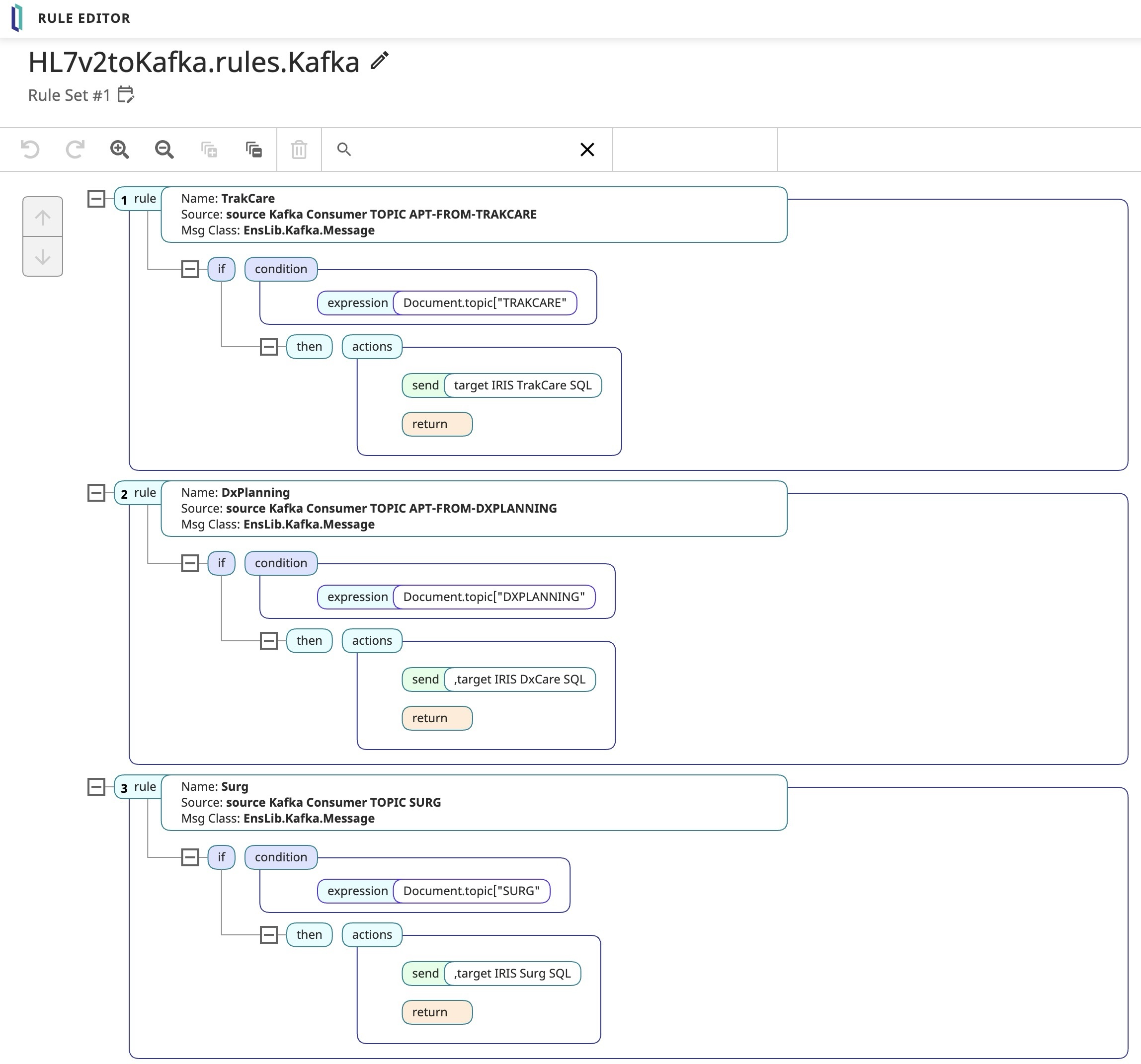
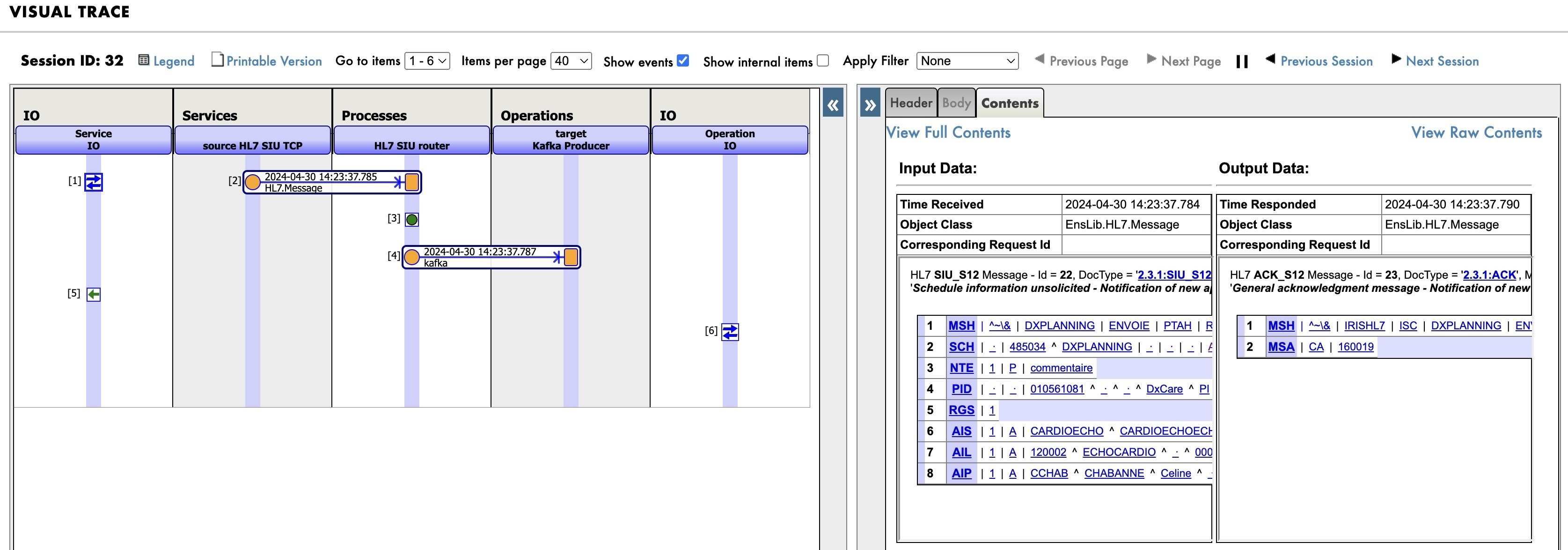
Visual Trace
Cada vez que se consume un tema de Kafka, se envía al proceso de enrutador de Kafka, que realiza el enrutamiento basado en contenido de los mensajes de Kafka, a las tablas SQL apropiadas en IRIS. Si observáis atentamente los mensajes, podréis notar que el mensaje se envía directamente a IRIS sin ser transformado (mismo ID de mensaje).
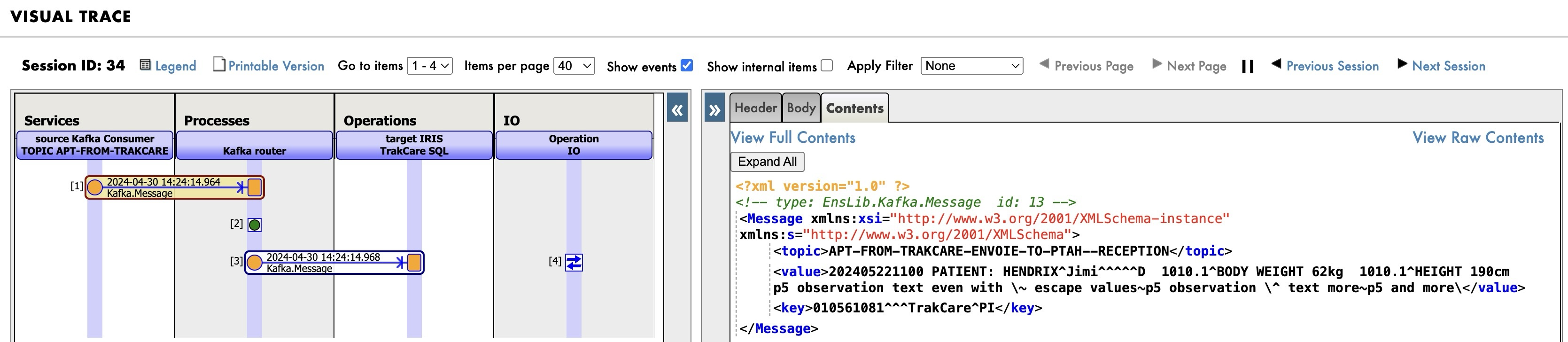
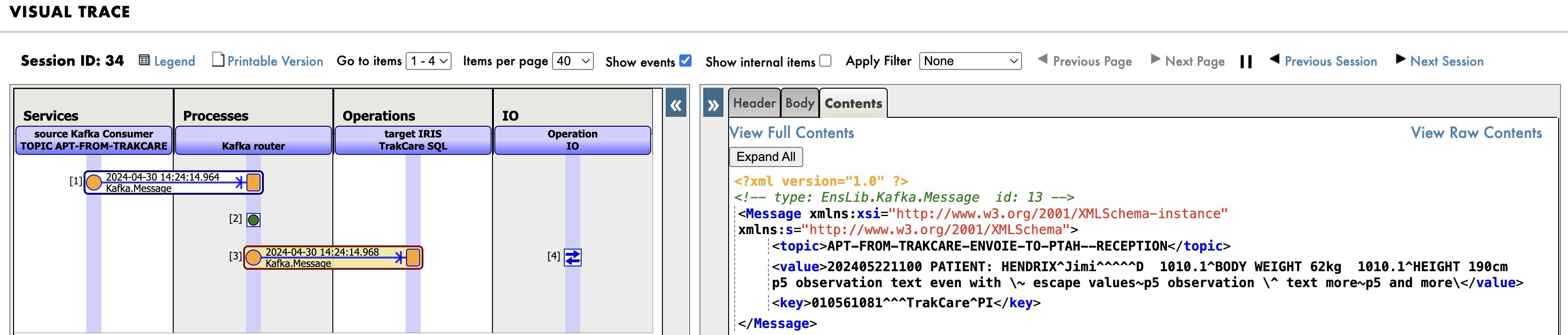
Podéis ver aquí el mensaje con I/O y el resultado de la inserción SQL.
SQL
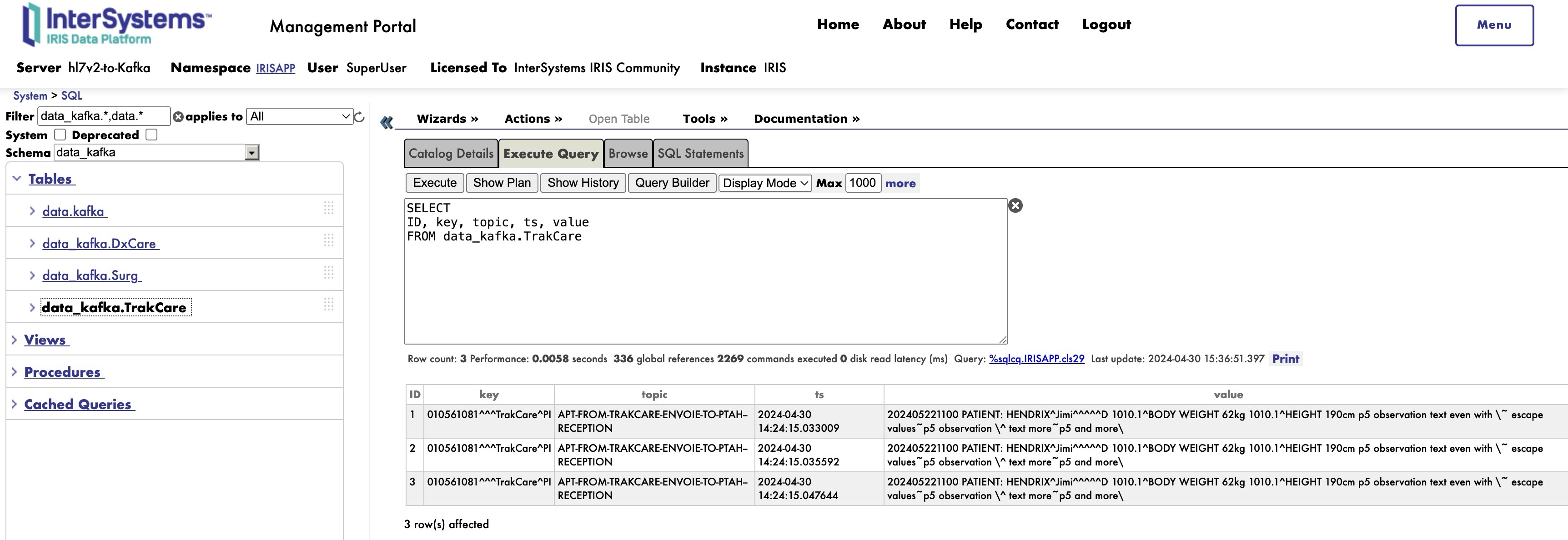
Luego podréis ver los resultados dentro de la base de datos IRIS a través de consultas SQL.
- TrakCare table
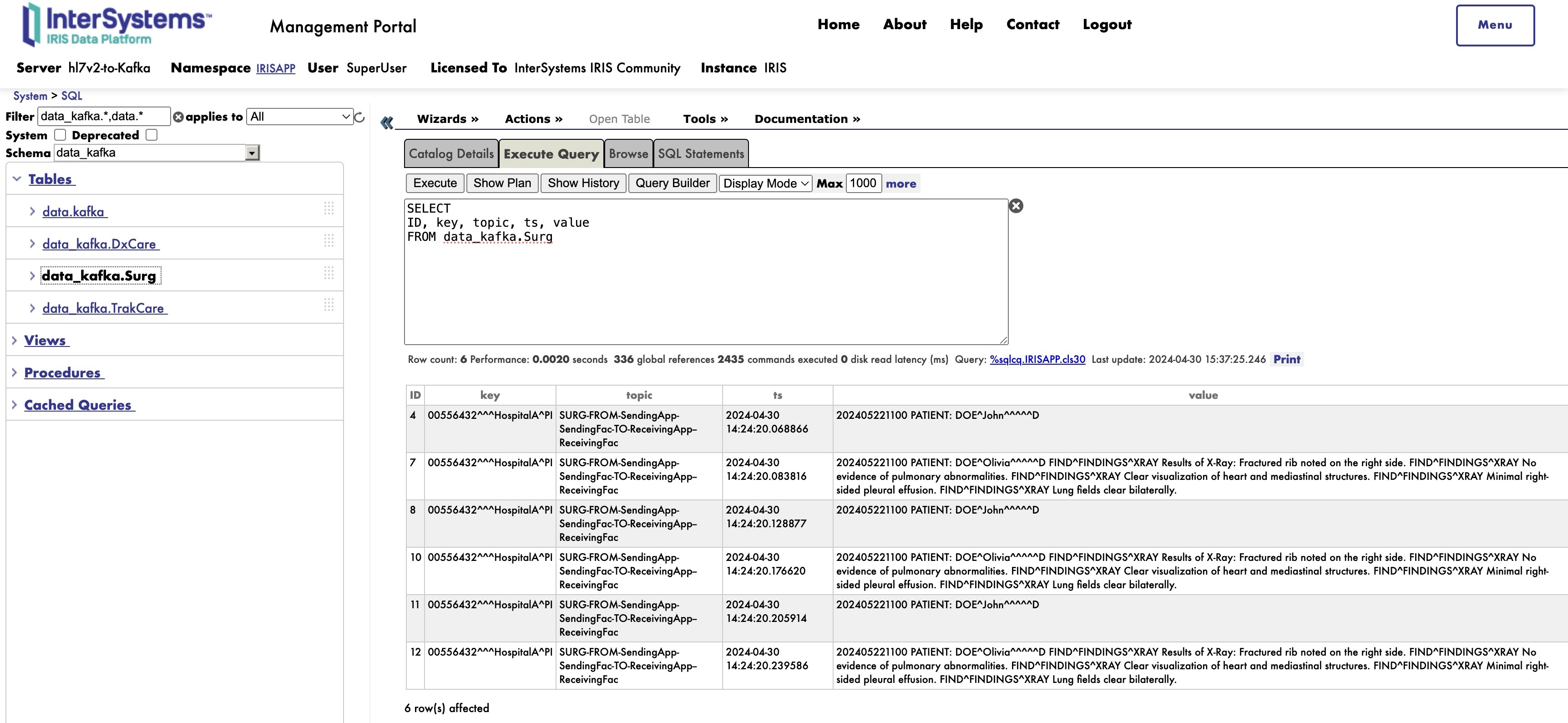
* Surg table
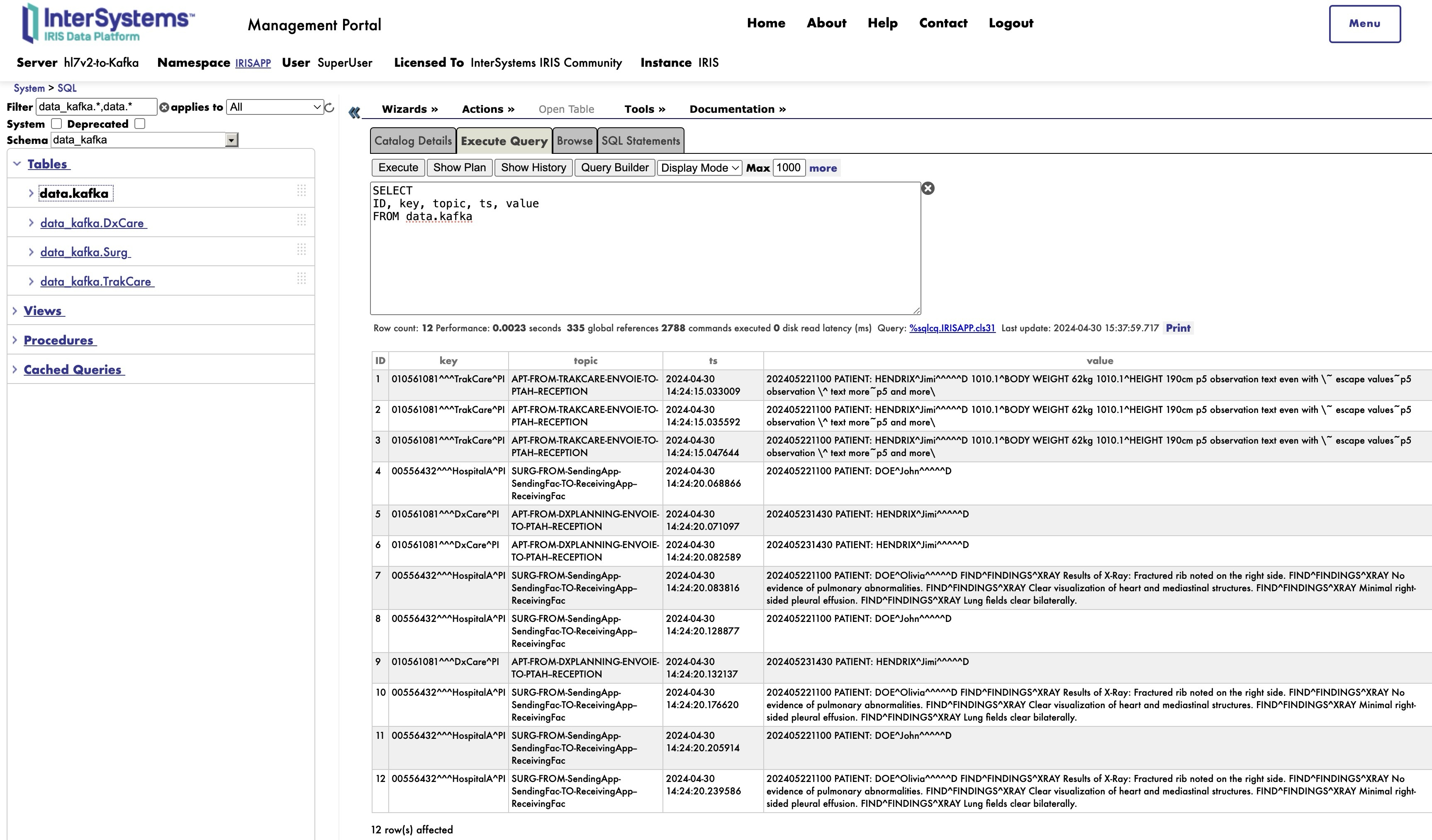
* Y gracias a la herencia, también podéis consultar todos los datos simplemente consultando la tabla raíz, aquí data.kafka
ClassExplorer
El Explorador de clases o ClassExplorer os permite ver el modelo de datos de las clases IRIS.
Ajustes predeterminados
Para simplificar el proceso de copiar una definición de producción de un entorno a otro y garantizar una separación perfecta entre los parámetros de los diferentes entornos, se recomienda establecer configuraciones fuera de la clase de producción, en la configuración predeterminada del sistema.
Entonces veréis los ajustes en azul en la configuración de producción.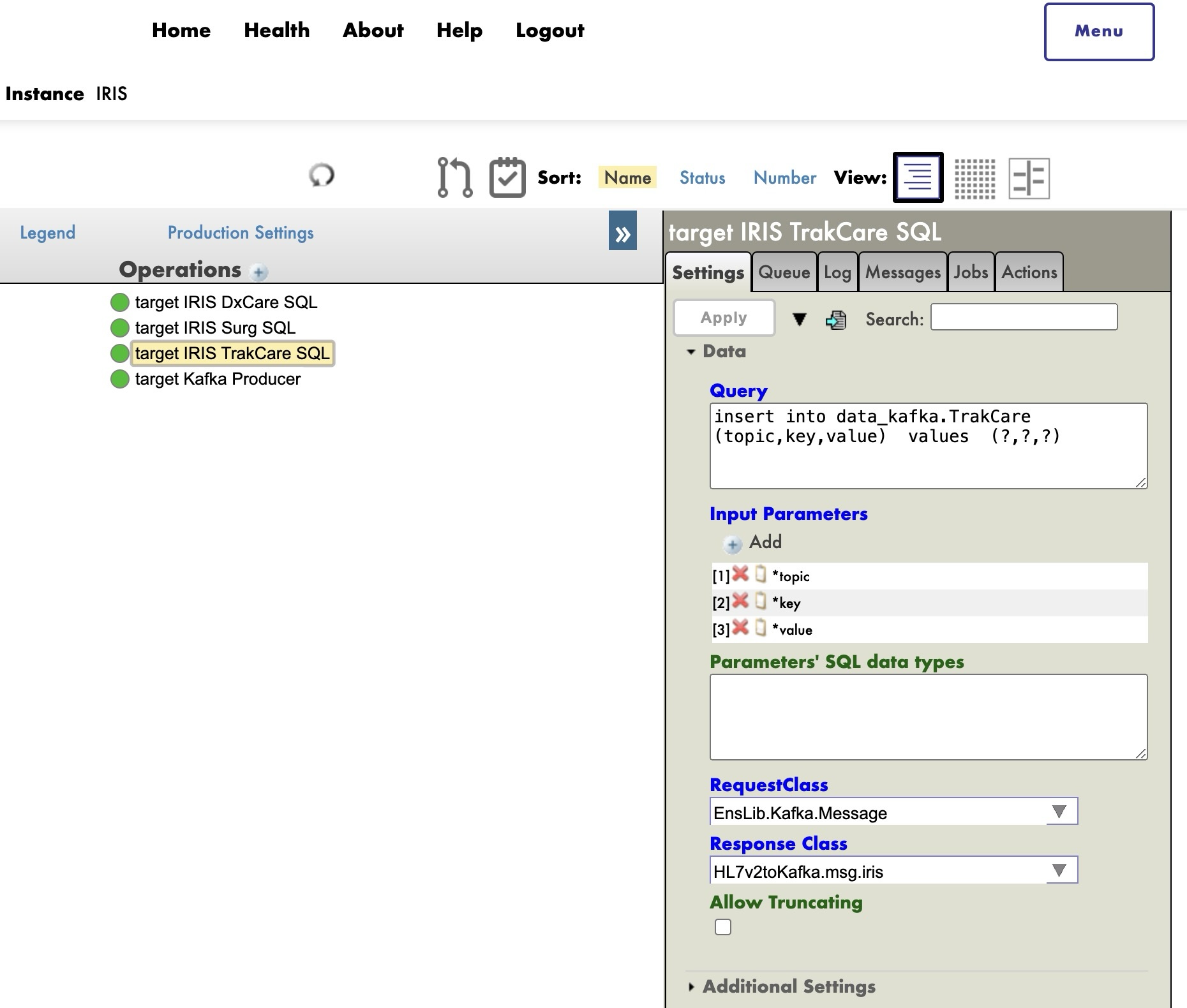
Pre requisitos
Aseguraos de tener git y Docker Desktop instalados.
Instalación: ZPM
Abrid el Espacio de nombres IRIS con la Interoperabilidad habilitada. Abrid Terminal y llamad: USER>zpm "install hl7v2-to-kafka"
Instalación: Docker
1. Clone/git extrae el repositorio a cualquier directorio local
$ git clone https://github.com/SylvainGuilbaud/hl7v2-to-kafka.git
2. Abrid la terminal en este directorio y ejecutad:
$ docker-compose build
3. Ejecutad el contenedor IRIS con vuestro proyecto:
$ docker-compose up -d
Cómo ejecutar la muestra
- copiad algunos mensajes HL7 de /data/HL7/test a /data/HL7/in
- comprobad en Visual Trace
- ved un seguimiento completo (full trace)
- Id a Kafka Manager y obtened datos de los diferentes temas.