Búsqueda de documentación en InterSystems utilizando las tecnologías iKnow y iFind

El DBMS de InterSystems incorpora una tecnología para trabajar con datos no estructurados (iKnow) y una tecnología de búsqueda de textos completos (iFind). Decidimos profundizar en ambas y hacer algo útil. Como resultado, tenemos DocSearch, una aplicación web para realizar búsquedas en la documentación de InterSystems utilizando iKnow y iFind.
Cómo funciona la documentación de Caché
La documentación en Caché se basa en la tecnología Docbook. Tiene una interfaz web (que incluye la posibilidad de realizar búsquedas sin utilizar iFind ni iKnow). Los artículos se almacenan en clases de Caché, lo que nos permite realizar consultas de estos datos y, por supuesto, crear nuestra propia herramienta de búsqueda.
Qué son iKnow y iFind
Intersystems iKnow es una tecnología que se desarrolló para el análisis de datos no estructurados, y proporciona acceso a estos mediante la indexación de frases e instancias en ellos. Para iniciar el análisis, primero necesita crear un dominio, es decir, un almacenamiento para datos no estructurados y subir un texto en él.
The iFind technology es un módulo DBMS de Caché para llevar a cabo búsquedas de texto completo en las clases de Caché. iFind utiliza muchas clases de iKnow para realizar búsquedas inteligentes de texto. Para utilizar iFind en sus consultas, debe introducir un índice especial iFind en su clase de Caché.
Existen tres tipos de índices iFind, cada uno de los cuales ofrece todas las funciones del tipo anterior, más algunas funciones adicionales:
- El índice principal (%iFind.Index.Basic): es compatible con la búsqueda y las combinaciones de palabras
- El índice semántico (%iFind.Index.Semantic): es compatible con la búsqueda de objetos en iKnow
- La búsqueda analítica (%iFind.Index.Analytic): es compatible con todas las funciones iKnow de la búsqueda semántica, así como con la información sobre las rutas y la proximidad de las palabra
Dado que la documentación de las clases se almacena en un namespace separado, si desea que las clases estén disponibles en el nuestro, el programa de instalación también realiza un mapeo de los paquetes y los globals.
Código de instalación para el mapeo
XData Install [ XMLNamespace = INSTALLER ]
{
<Manifest>
// Specify the name of the namespace
<IfNotDef Var="Namespace">
<Var Name="Namespace" Value="DOCSEARCH"/>
<Log Text="Set namespace to ${Namespace}" Level="0"/>
</IfNotDef>
// Check if the area exists
<If Condition='(##class(Config.Namespaces).Exists("${Namespace}")=1)'>
<Log Text="Namespace ${Namespace} already exists" Level="0"/>
</If>
// Creating the namespace
<If Condition='(##class(Config.Namespaces).Exists("${Namespace}")=0)'>
<Log Text="Creating namespace ${Namespace}" Level="0"/>
// Creating a database
<Namespace Name="${Namespace}" Create="yes" Code="${Namespace}" Ensemble="" Data="${Namespace}">
<Log Text="Creating database ${Namespace}" Level="0"/>
// Map the specified classes and globals to a new namespace
<Configuration> <Database Name="${Namespace}" Dir="${MGRDIR}/${Namespace}" Create="yes" MountRequired="false"
Resource="%DB_${Namespace}" PublicPermissions="RW" MountAtStartup="false"/>
<Log Text="Mapping DOCBOOK to ${Namespace}" Level="0"/>
<GlobalMapping Global="Cache*" From="DOCBOOK" Collation="5"/>
<GlobalMapping Global="D*" From="DOCBOOK" Collation="5"/>
<GlobalMapping Global="XML*" From="DOCBOOK" Collation="5"/>
<ClassMapping Package="DocBook" From="DOCBOOK"/>
<ClassMapping Package="DocBook.UI" From="DOCBOOK"/>
<ClassMapping Package="csp" From="DOCBOOK"/>
</Configuration>
<Log Text="End creating database ${Namespace}" Level="0"/>
</Namespace> <Log Text="End creating namespace ${Namespace}" Level="0"/>
</If>
</Manifest>
}El dominio que iKnow requiere se construye sobre la tabla que contiene la documentación. Debido a que utilizamos una tabla como fuente de datos, utilizaremos a SQL.Lister. El campo de contenido tiene el texto de la documentación, así que lo especificaremos como el campo de datos. El resto de los campos se describirán en los metadatos.
Código del instalador para crear un dominio
ClassMethod Domain(ByRef pVars, pLogLevel As %String, tInstaller As %Installer.Installer) As %Status
{
#Include %IKInclude
#Include %IKPublic
set ns = $Namespace
znspace "DOCSEARCH"
// Create a domain or open it if it exists
set dname="DocSearch"
if (##class(%iKnow.Domain).Exists(dname)=1){
write "The ",dname," domain already exists",!
zn ns
quit
}
else {
write "The ",dname," domain does not exist",!
set domoref=##class(%iKnow.Domain).%New(dname)
do domoref.%Save()
}
set domId=domoref.Id
// Lister is used for searching for sources corresponding to the records in query results
set flister=##class(%iKnow.Source.SQL.Lister).%New(domId)
set myloader=##class(%iKnow.Source.Loader).%New(domId)
// Building a query
set myquery="SELECT id, docKey, title, bookKey, bookTitle, content, textKey FROM SQLUser.DocBook"
set idfld="id"
set grpfld="id"
// Specifying the fields for data and metadata
set dataflds=$LB("content")
set metaflds=$LB("docKey", "title", "bookKey", "bookTitle", "textKey")
// Putting all data into Lister
set stat=flister.AddListToBatch(myquery,idfld,grpfld,dataflds,metaflds)
if stat '= 1 {write "The lister failed: ",$System.Status.DisplayError(stat) quit }
//Starting the analysis process
set stat=myloader.ProcessBatch()
if stat '= 1 {
quit
}
set numSrcD=##class(%iKnow.Queries.SourceQAPI).GetCountByDomain(domId)
write "Done",!
write "Domain cointains ",numSrcD," source(s)",!
zn ns
quit
}Para buscar dentro de la documentación, utilizamos el índice %iFind.Index.Analytic:
Index contentInd On (content) As %iFind.Index.Analytic(LANGUAGE = "en", LOWER = 1, RANKERCLASS = "%iFind.Rank.Analytic");
Donde contentInd es el nombre del índice y content es el nombre del campo que creamos para el índice. El parámetro LANGUAGE = “en” establece el idioma del texto. El parámetro LOWER = 1 desactiva la sensibilidad para diferenciar las mayúsculas y las minúsculas. El parámetro RANKERCLASS = "%iFind.Rank.Analytic" permite que se utilice el resultado del algoritmo de clasificación TF-IDF.
Después de añadir y elaborar dicho índice, éste se puede utilizar, por ejemplo, en las consultas SQL. La sintaxis general para utilizar iFind en SQL es:
SELECT * FROM TABLE WHERE %ID %FIND search_index(indexname,'search_items',search_option)
Después de crear el índice %iFind.Index.Analytic con esos parámetros, se generan varios procedimientos SQL del siguiente tipo: [table_name]_[index name]Procedure name
En nuestro proyecto, utilizamos dos de ellos:
- DocBook_contentIndRank - devuelve el resultado del algoritmo de clasificación TF-IDF para una solicitud. El procedimiento tiene la siguiente sintaxis:
SELECT DocBook_contentIndRank(%ID, ‘SearchString’, ‘SearchOption’) Rank FROM DocBook WHERE %ID %FIND search_index(contentInd,‘SearchString’, ‘SearchOption’)
- DocBook_contentIndHighlight - devuelve los resultados de la búsqueda, donde las palabras buscadas se envolvieron en la etiqueta que se especificó:
SELECT DocBook_contentIndHighlight(%ID, ‘SearchString’, ‘SearchOption’,’Tags’) Text FROM DocBook WHERE %ID %FIND search_index(contentInd,‘SearchString’, ‘SearchOption’)
Entraré en más detalles sobre esto más adelante en el artículo.
Qué obtenemos al final:
-
Autocompletado en el campo de búsqueda
Cuando empiece a introducir texto en el campo de búsqueda, el sistema le sugerirá posibles variantes de la consulta, para ayudarle a encontrar la información necesaria más rápidamente. Estas sugerencias se generan de acuerdo a la palabra (o su inicio) que se escribe. El sistema muestra las diez mejores palabras o frases que coinciden con la búsqueda. Este proceso utiliza iKnow, es decir, el método %iKnow.Queries.Entity.GetSimilar
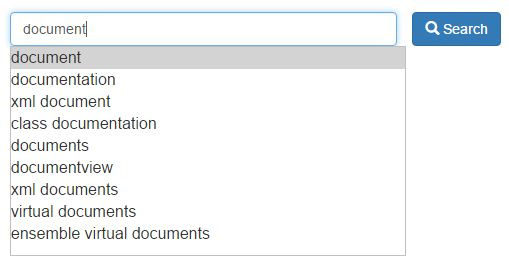
-
Búsqueda difusa
iFind es compatible con la búsqueda difusa, para encontrar palabras que coincidan parcialmente con la cadena de búsqueda introducida. Esto se logra al medir la distancia de Levenshtein que existe entre dos palabras. La distancia Levenshtein es el número mínimo de cambios en un carácter (inserciones, eliminaciones o sustituciones) que son necesarios para convertir una palabra en otra. Esto puede utilizarse para corregir errores tipográficis, pequeñas variaciones en la escritura, diferentes formas gramaticales (por ejemplo, el plural y el singular).
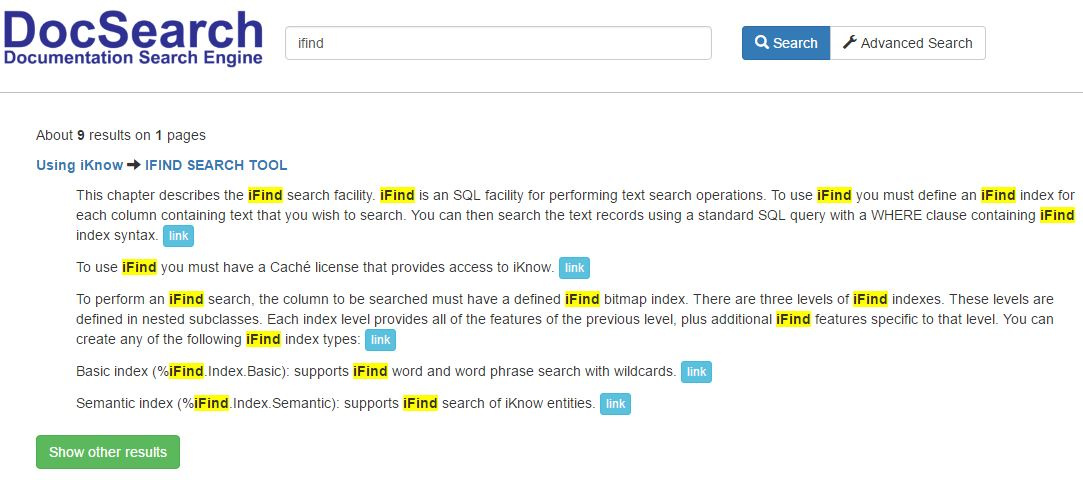
En las consultas SQL que se realizan con iFind, el parámetro search_option es responsable de la búsqueda difusa. El parámetro search_option = 3 denota una distancia de Levenshtein de 2. Para establecer una distancia Levenshtein que sea igual a n, es necesario establecer el parámetro search_option en ‘3:n’. En la búsqueda de documentación se utiliza una distancia Levenshtein de 1, así que vamos a demostrar cómo funciona esto: Escribamos "ifind" en el campo de búsqueda.
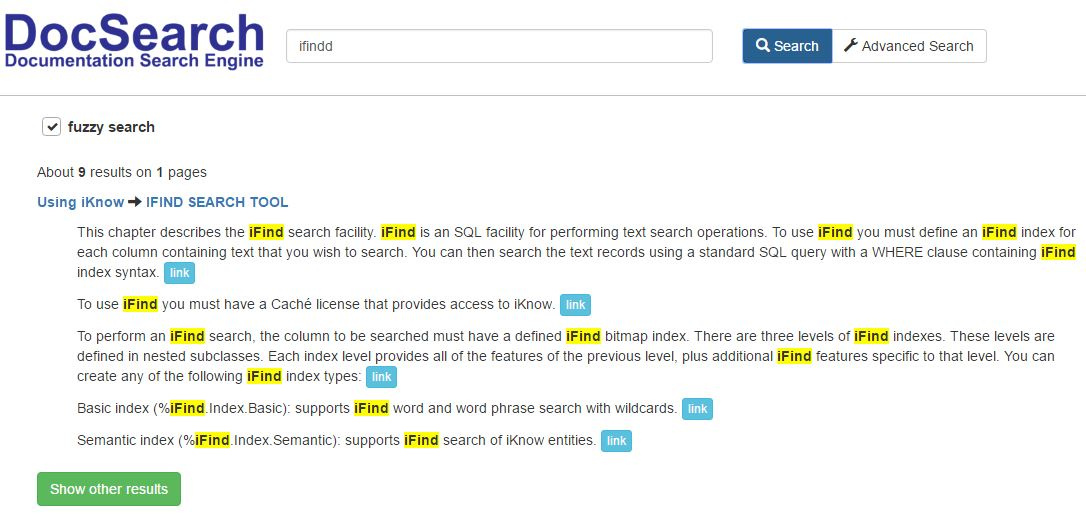
Vamos a realizar una búsqueda difusa poniendo un error tipográfico de forma intencional. Como podemos ver, la búsqueda corrigió el error tipográfico y encontró los artículos necesarios.
-
Búsquedas complejas
Gracias a que iFind es compatible con las consultas complejas con corchetes y con los operadores AND OR NOT, pudimos implementar la funcionalidad de búsquedas complejas. Esto es lo que puede especificar en su consulta: una palabra, una combinación de palabras, una de varias palabras, excepciones. Los campos pueden completarse uno por uno, o todos al mismo tiempo. Por ejemplo, vamos a buscar artículos que contengan la palabra “iknow”, la combinación “rest api” y los que tengan “domain” o “UI”.
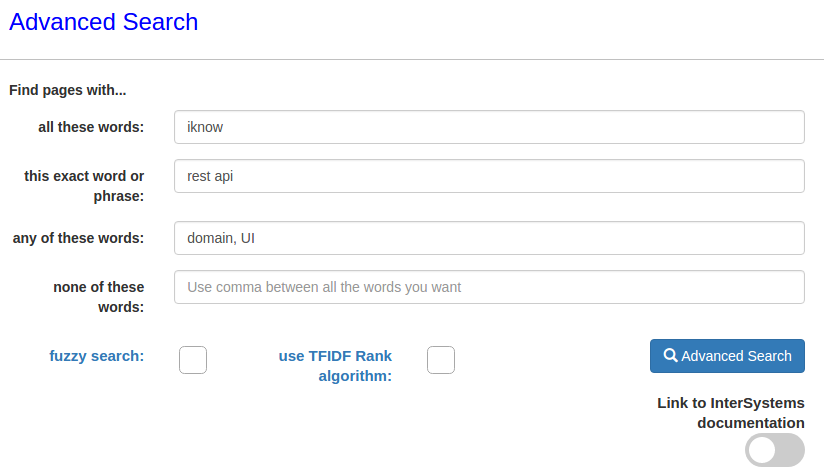 Podemos ver que existen dos artículos de este tipo:
Podemos ver que existen dos artículos de este tipo: 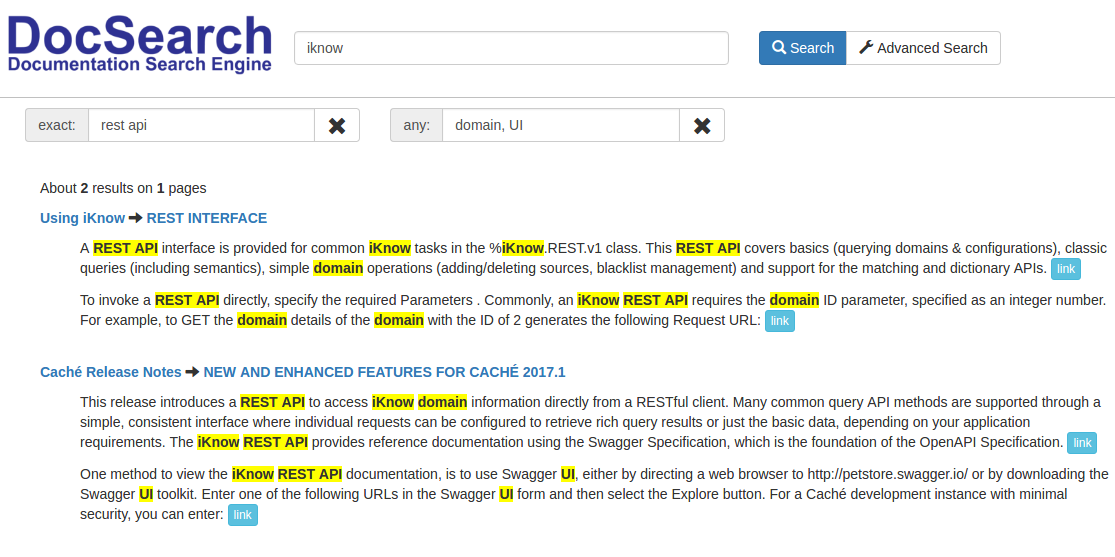 Tenga en cuenta que en el segundo artículo se menciona Swagger UI, de modo que podemos modificar la consulta para que excluya los que contengan la palabra Swagger.
Tenga en cuenta que en el segundo artículo se menciona Swagger UI, de modo que podemos modificar la consulta para que excluya los que contengan la palabra Swagger. 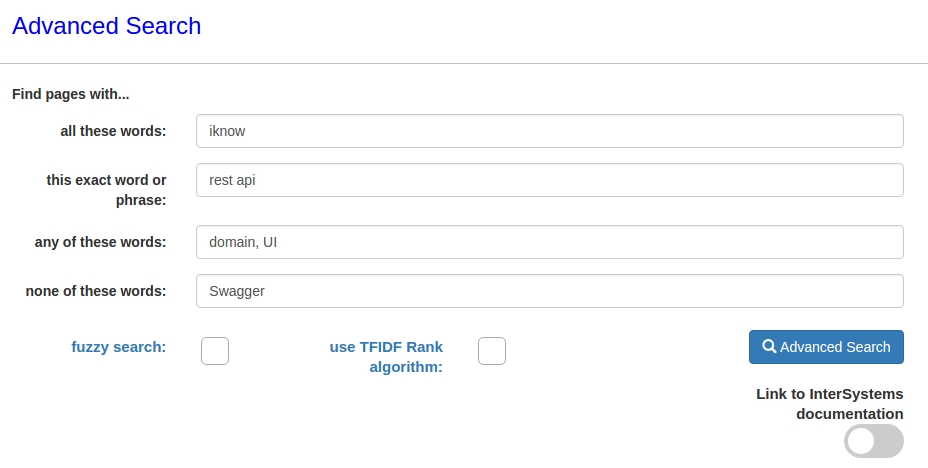 Como resultado, únicamente encontramos un artículo:
Como resultado, únicamente encontramos un artículo: 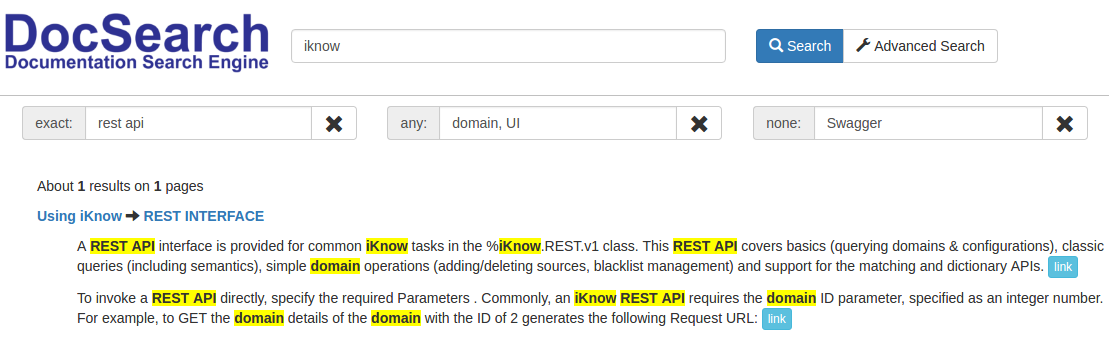
-
Resaltado en los resultados de búsqueda
Como se indicó anteriormente, el uso del índice iFind crea el procedimiento DocBook_contentIndHighlight. Utilicemos lo siguiente:
SELECT DocBook_contentIndHighlight(%ID, 'search_items', '0', '<span class=""Illumination"">', 0) Text FROM DocBookPara obtener el texto resultante dentro de una etiqueta
<span class=""Illumination"">Esto le ayudará a resaltar visualmente los resultados de la búsqueda en el front-end.

-
Clasificación de los resultados de la búsqueda
Find es capaz de clasificar los resultados mediante el algoritmo TF-IDF. TF-IDF se utiliza con frecuencia en las tareas para analizar texto y en la búsqueda de datos, por ejemplo, como un criterio de importancia cuando se realiza una consulta de búsqueda en un documento.
Como resultado de la consulta SQL, el campo Rank contendrá la importancia de la palabra, la cual será proporcional al número de veces que la palabra se utilizó en un artículo, e inversamente proporcional a la frecuencia con que aparece la palabra en otros artículos.
SELECT DocBook_contentIndRank(%ID, ‘SearchString’, ‘SearchOption’) Rank FROM DocBook WHERE %ID %FIND search_index(contentInd,‘SearchString’, ‘SearchOption’)
-
Integración con la búsqueda de documentos oficial
Después de la instalación, se añadirá el botón “Search using iFind” a la búsqueda de documentos oficial.
 Si el campo “Search words” está lleno, le llevará a la página de resultados de la búsqueda después de hacer clic en el botón “Search using iFind”. Si el campo está vacío, le llevará a una nueva página de búsqueda.
Si el campo “Search words” está lleno, le llevará a la página de resultados de la búsqueda después de hacer clic en el botón “Search using iFind”. Si el campo está vacío, le llevará a una nueva página de búsqueda.
Instalación
- Descargue la última versión disponible del archivo Installer.xml en la página correspondiente.
- Importe el archivo Installer.xml hacia el namespace %SYS y realice la compilación.
- Introduzca el siguiente comando dentro del terminal, en el namespace %SYS:
do ##class(Docsearch.Installer).setup(.pVars)
Después de eso, la búsqueda estará disponible en la siguiente dirección localhost:[port]/csp/docsearch/index.html
Demo
Aquí puede ver una demo online sobre cómo se realizan las búsquedas.
Conclusión
Este proyecto muestra las interesantes y útiles capacidades de las tecnologías iFind e iKnow, que hacen que la búsqueda de datos sea más relevante. Apreciamos mucho cualquier comentario o sugerencia que haga. El código fuente completo con el instalador y la guía de implementación está disponible en GitHub.