Una introducción a Adaptive Analytics
Introducción
InterSystems IRIS Adaptive Analytics es una extensión opcional que proporciona una capa de modelo de datos virtual entre InterSystems IRIS y herramientas populares de Business Intelligence (BI) e Inteligencia Artificial (IA). Adaptive Analytics está impulsado por AtScale, y la documentación de AtScale puede consultarse en este enlace: https://documentation.intersystems.atscale.com
Este artículo mostrará algunas funcionalidades de AtScale que pueden facilitar el análisis de datos:
- Creación de cubos
- Visualización en Excel
- Períodos paralelos
- Consultas
- Snowflake
- Seguridad
-
Agregaciones
1. Creación de cubos
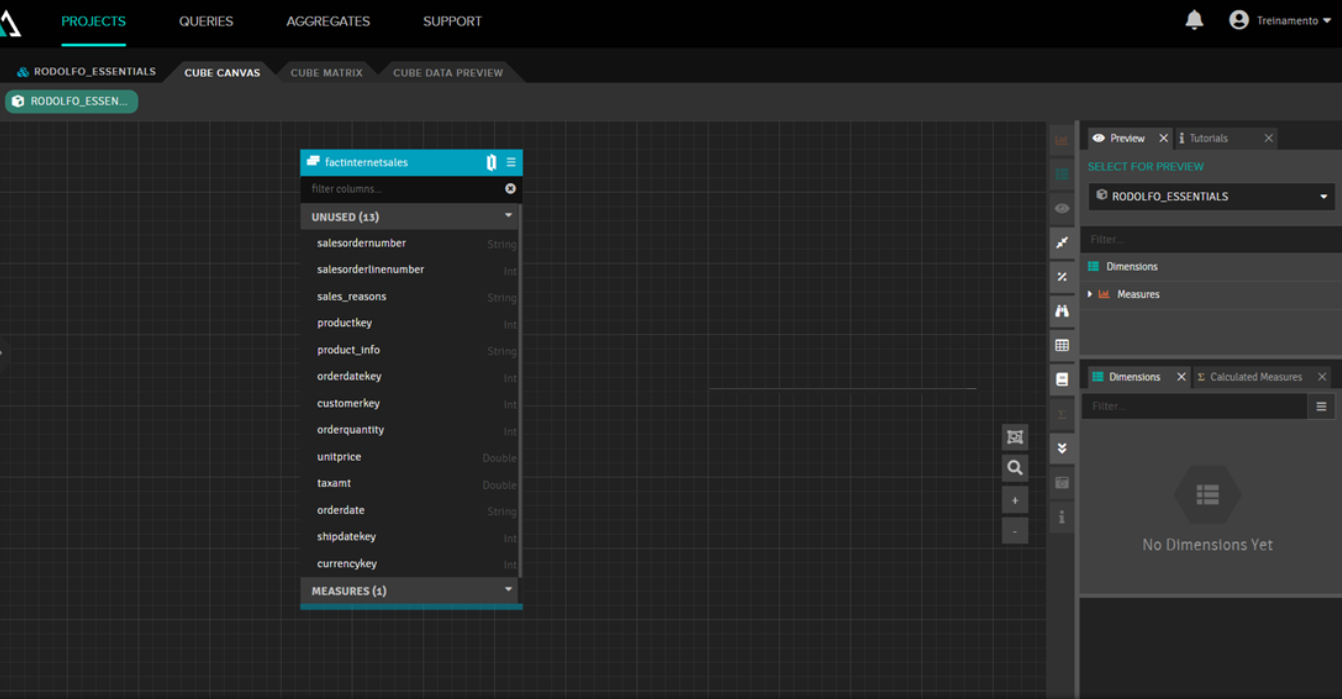
Crear un cubo en AtScale es sencillo. Dentro del lienzo del cubo, id al botón de Data Sources, seleccionad vuestra tabla de hechos (en nuestro ejemplo, ventas realizadas) y arrastradla al lienzo. La tabla de hechos se mostrará con una cabecera azul:
Después de eso, necesitáis añadir las tablas de dimensiones arrastrándolas al cuadro de Dimensions de la derecha y enlazándolas con la tabla de hechos mediante la propiedad que contiene el ID del registro. A continuación, debéis añadir las medidas; simplemente arrastrad los campos que queréis medir al cuadro de Measures de la derecha y especificad el tipo de agregación que queréis (suma, contador, promedio, etc.).
El objetivo de este artículo no es mostrar este paso en detalle, en parte porque es difícil representar el proceso de arrastrar y soltar en imágenes, así que solo mostramos cómo queda nuestro modelo:
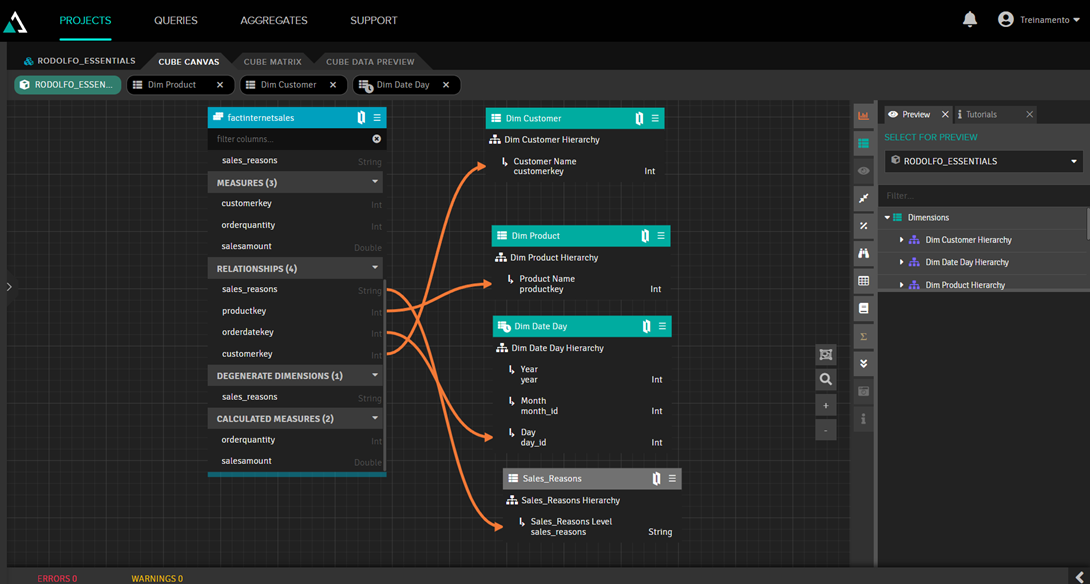
Observad que nuestra dimensión Sales_Reasons tiene una cabecera gris. Esto ocurre porque es una dimensión “junked”, es decir, una dimensión creada a partir de una propiedad de la tabla de hechos que no tiene relación con otra tabla. Para crearla, simplemente arrastrad la propiedad que queréis convertir en dimensión a cualquier espacio vacío del lienzo.
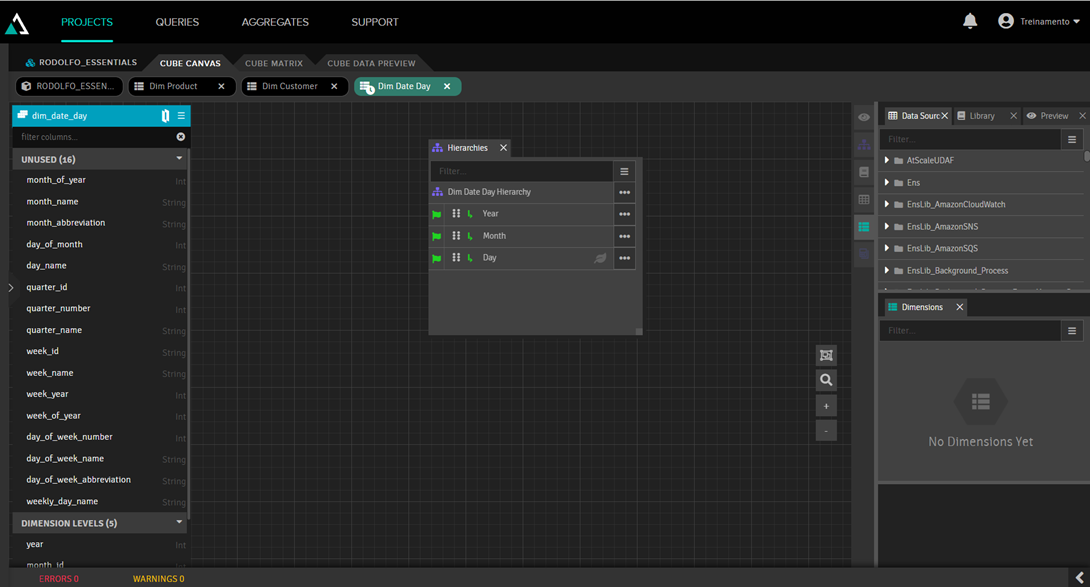
Otra observación es que hemos añadido la dimensión de calendario, que es una tabla con datos fijos para todas las fechas del calendario, detallando el día, el día de la semana, el mes, el año, el trimestre, etc. En esta dimensión, hemos establecido una jerarquía de año, mes y día para crear una navegación en profundidad (drilldown) para el usuario. Para ello, hemos hecho doble clic en la dimensión para acceder al editor de dimensiones, donde hemos introducido año, mes y día en su jerarquía:
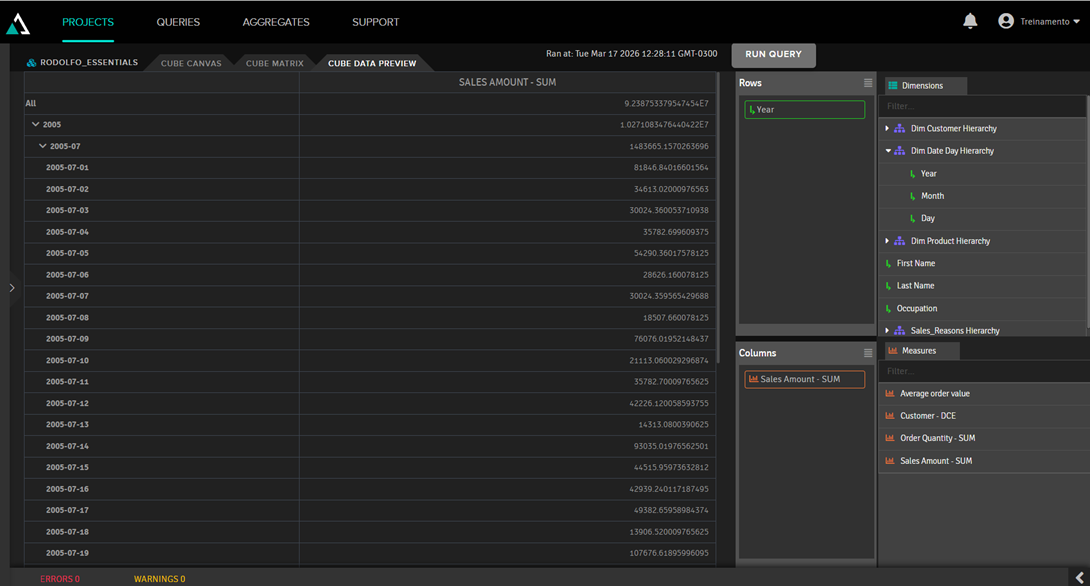
Al hacer clic en la pestaña Cube Data Preview, podemos ver cómo se mostrarán los datos:
- Visualización en Excel
Para visualizar los datos desde una aplicación externa (Power BI, Tableau, Excel), primero necesitáis publicar el cubo. Para ello, simplemente haced clic en Publish. Después de eso, se mostrarán las cadenas de conexión:
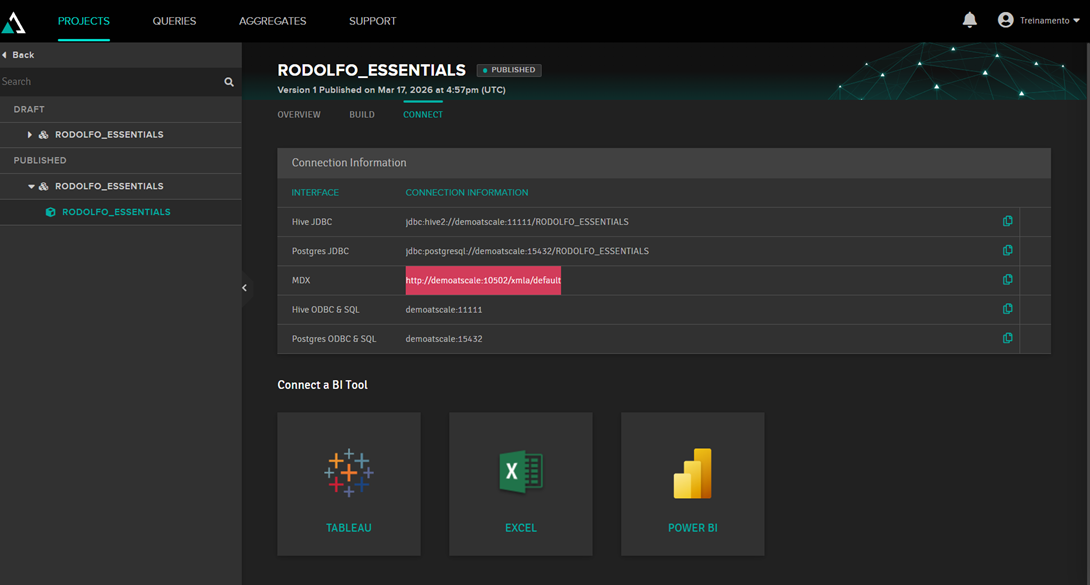
Con esta cadena en la mano, seleccionad la opción “From Analysis Server” en Excel para recuperar los datos desde AtScale:
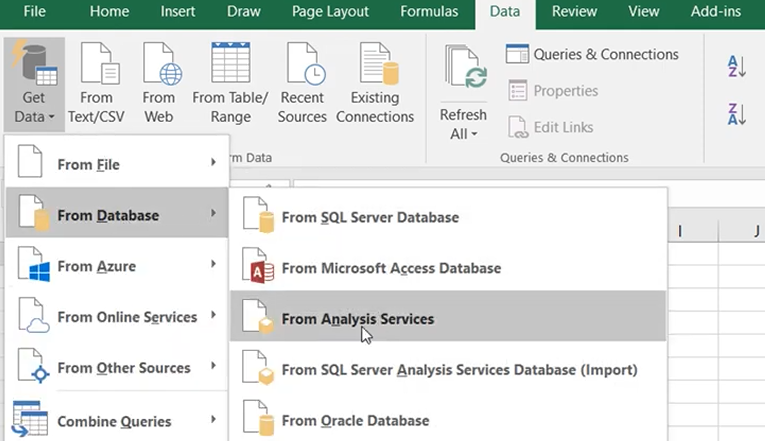
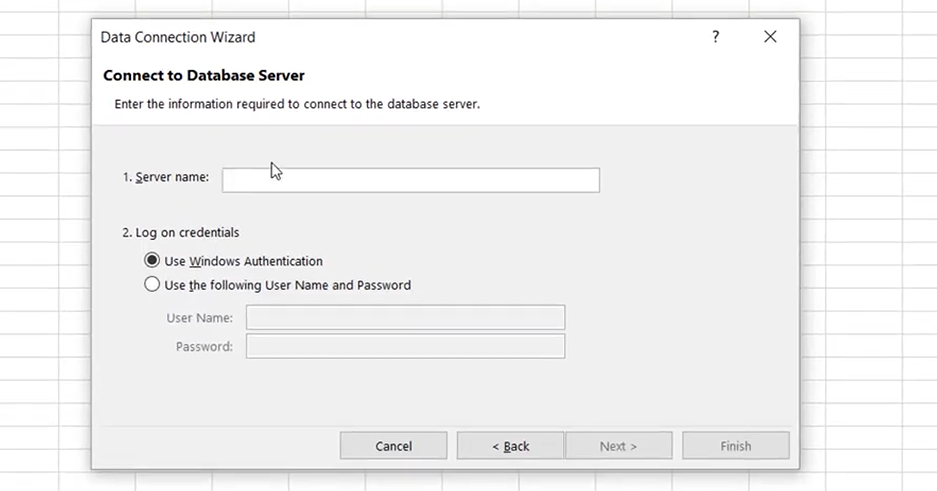
En la pantalla anterior, simplemente introducid la cadena de conexión en el campo Server Name y proporcionad el nombre de usuario y la contraseña de AtScale. A continuación, seleccionad el cubo:
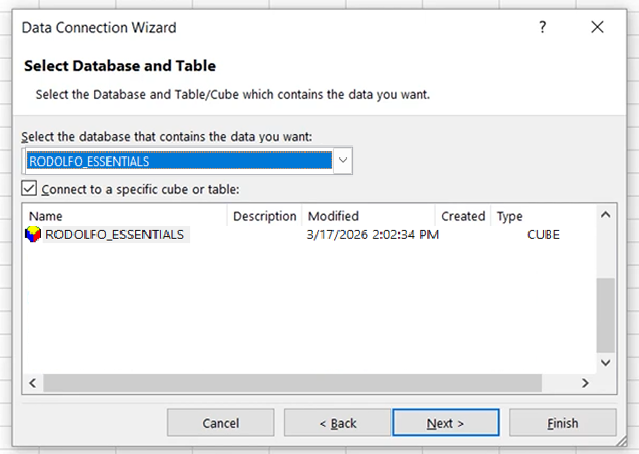
A continuación, los datos aparecerán como una tabla dinámica:
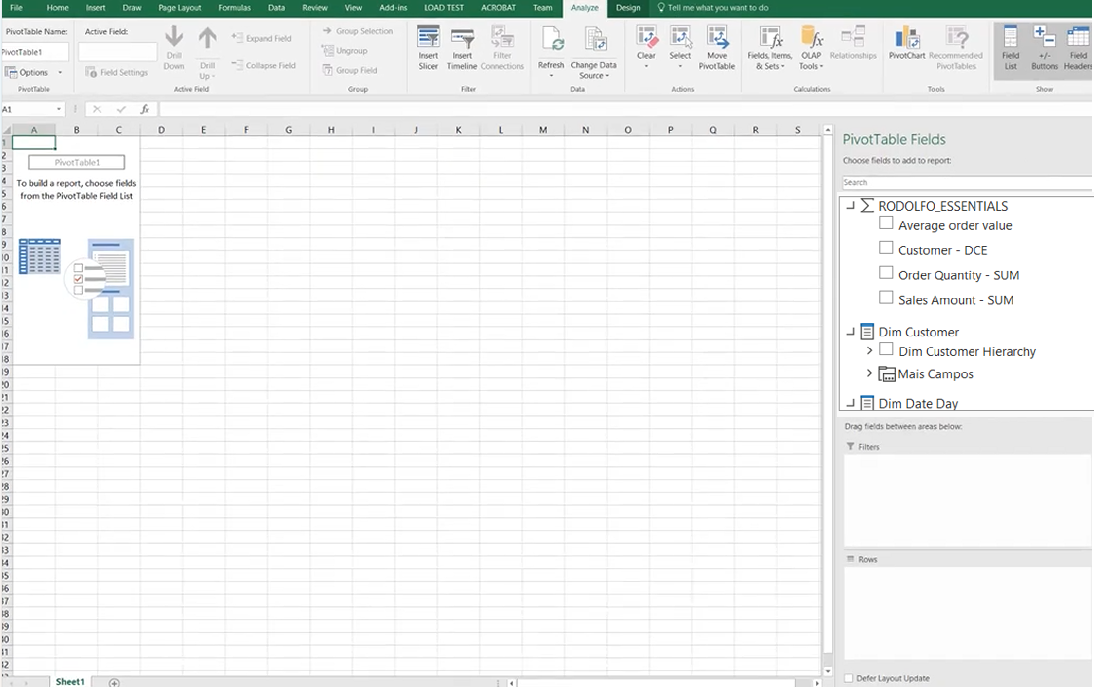
- Período paralelo
Período paralelo es una función muy útil para comparar datos de distintos periodos (una situación muy habitual es la necesidad de comparar las ventas del año actual con las del año anterior). En AtScale, esto se hace añadiendo una medida calculada y utilizando la función ParallelPeriod, como en este ejemplo:
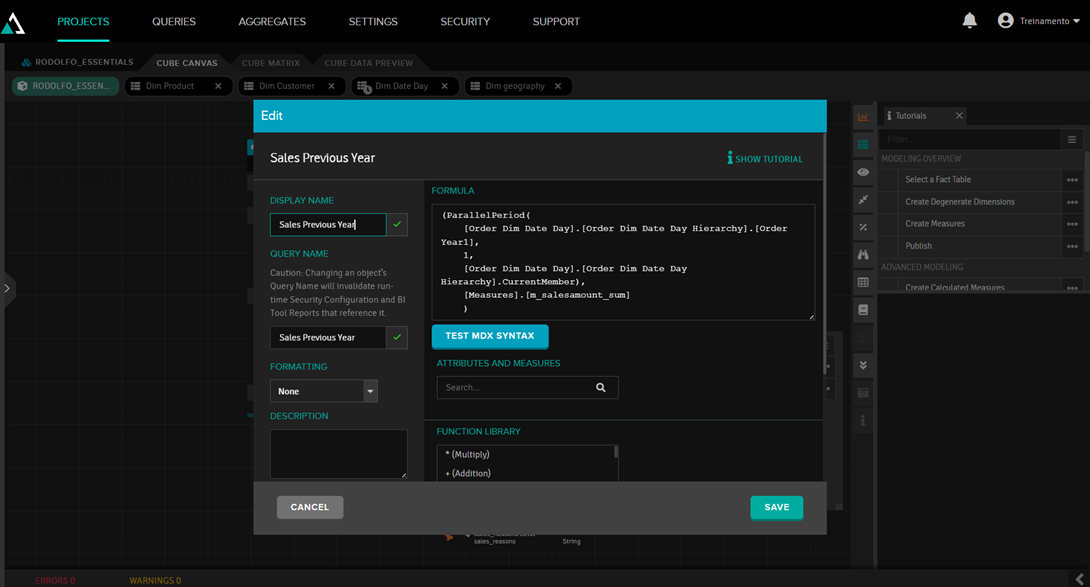
Por lo tanto, la métrica Sales Previous Year mostrará el valor del año anterior:
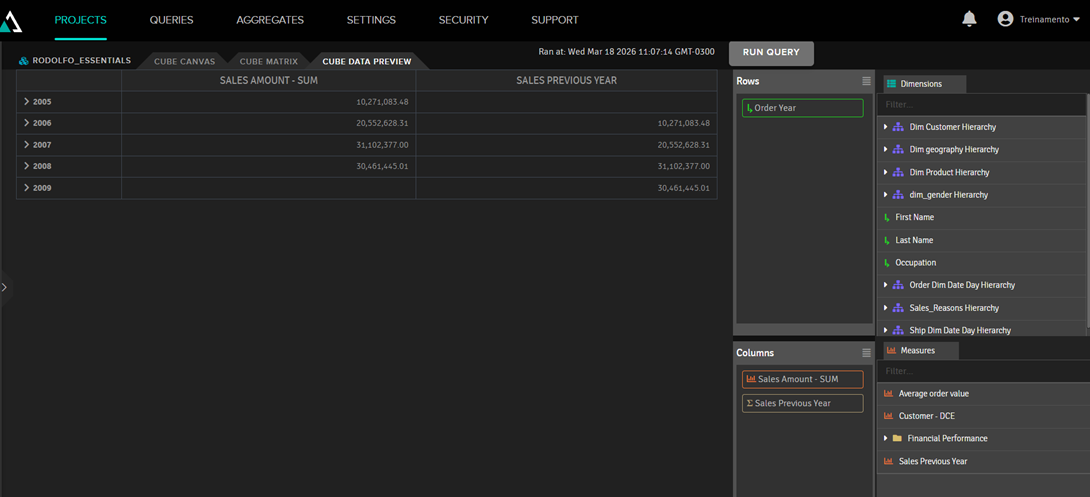
- Consultas
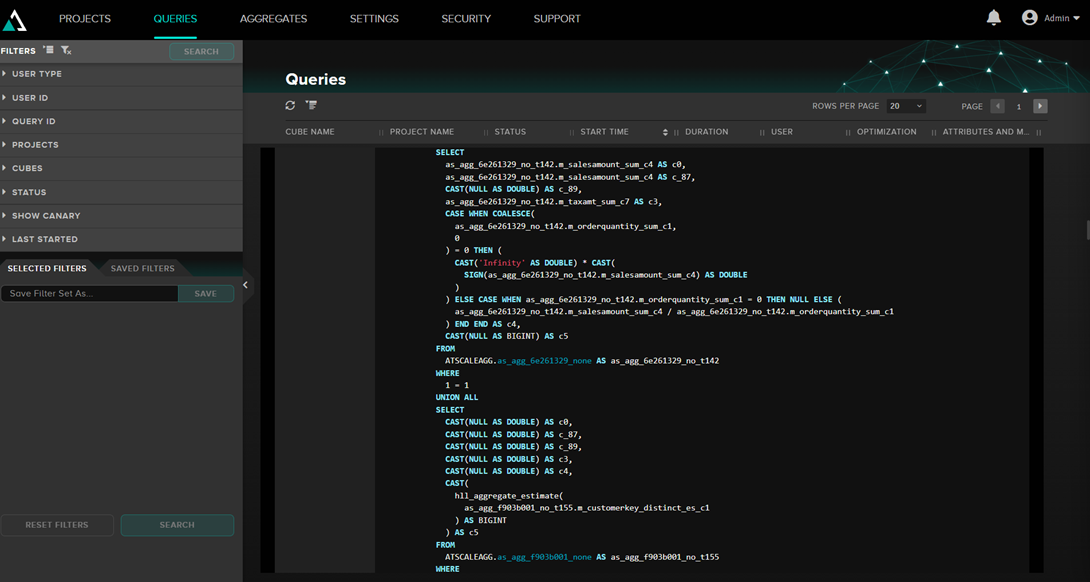
En la sección Queries de AtScale, podemos ver las consultas que se están ejecutando, tanto desde aplicaciones externas como Excel como desde la vista previa de AtScale. Ejemplo de consulta:
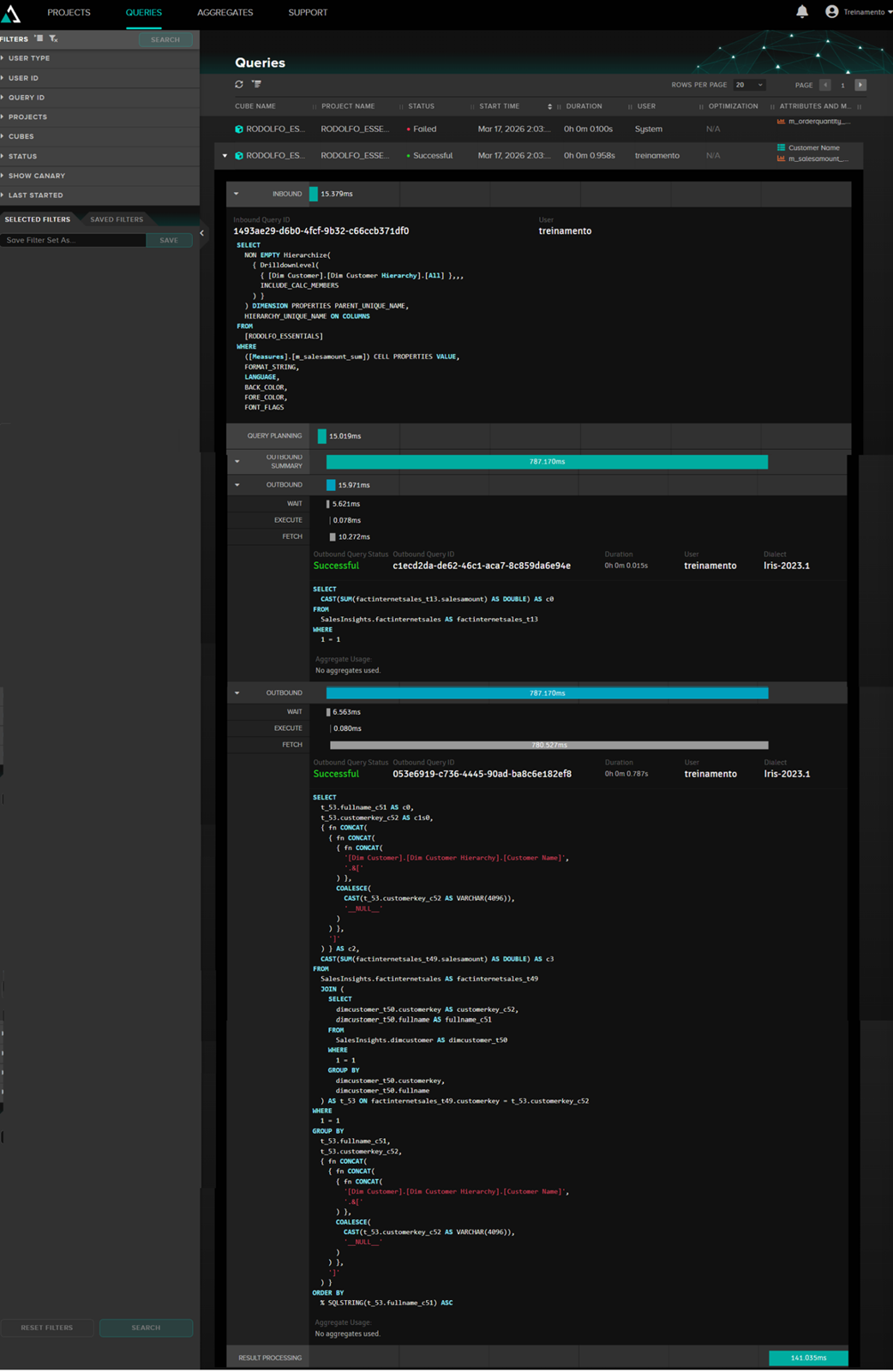
Aquí podemos ver la consulta MDX interna de AtScale y la consulta que se envía a IRIS, así como el tiempo de ejecución.
- Snowflake
Snowflake se refiere a la capacidad de ampliar el modelo. En el ejemplo siguiente, entramos en la dimensión de cliente y la ampliamos añadiendo información geográfica mediante una tabla de ciudades, así como información de género:
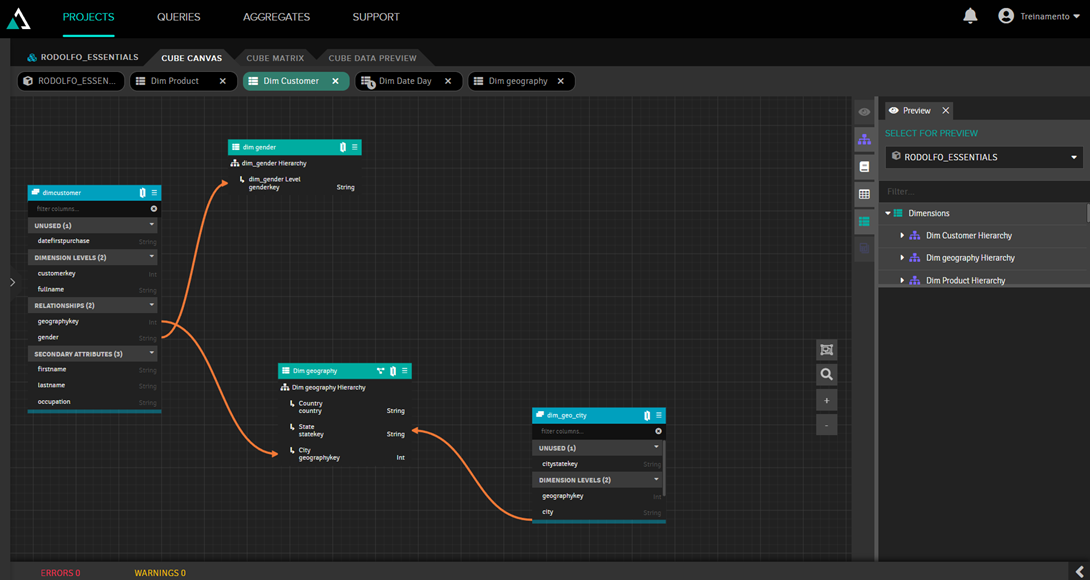
De esta forma, podemos añadir tablas al modelo manteniendo una organización fácil de entender.
- Seguridad
Dividiremos el aspecto de seguridad en dos temas: perspectives, que limitan qué columnas puede ver un usuario, y security dimension, que limita qué filas puede ver un usuario.
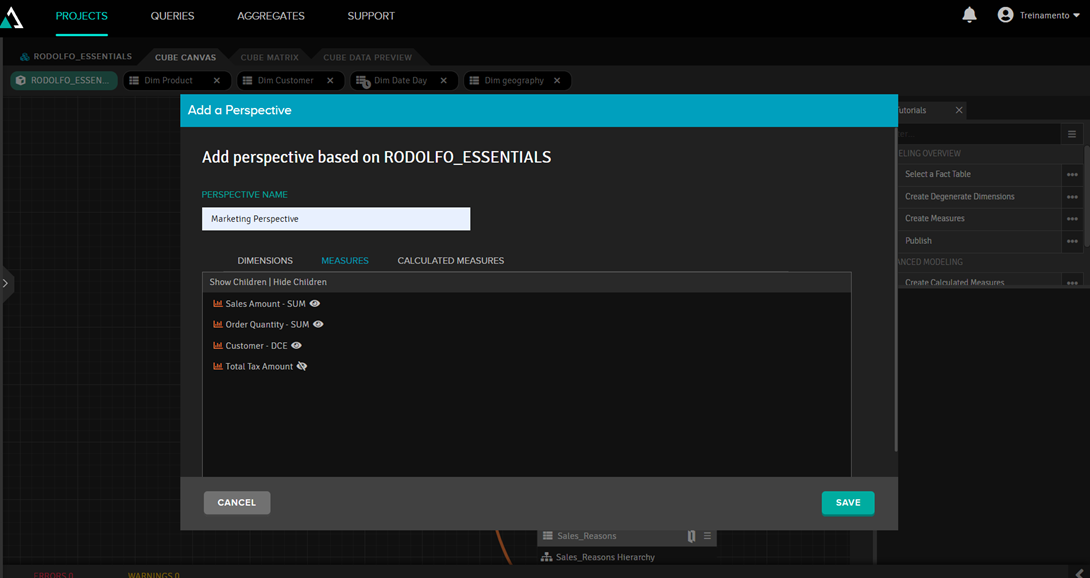
a) Perspectives
Las perspectives sirven para definir el alcance de un cubo, en caso de que haya usuarios que no puedan ver todos los datos. En el ejemplo siguiente, hemos creado la perspectiva de marketing. Al hacer clic en el icono del “ojo”, definimos qué pueden ver y qué no pueden ver:
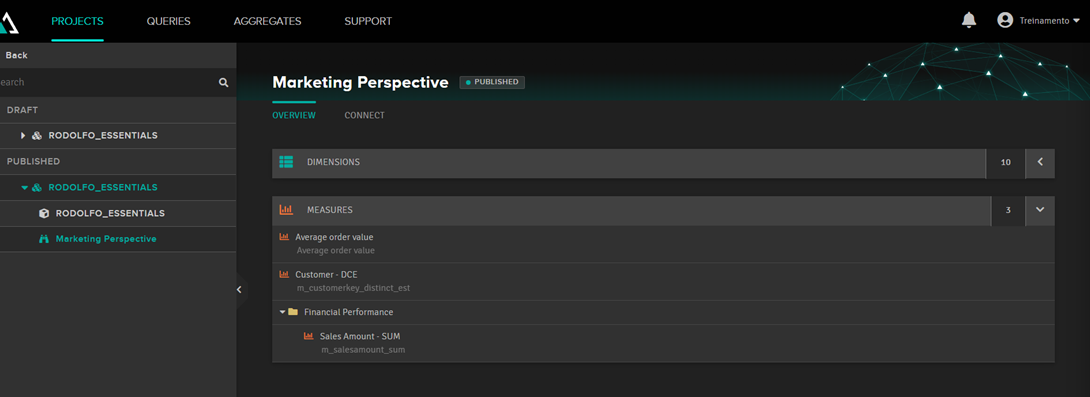
Cuando publiquéis el cubo, aparecerá otra entrada con el nombre de la perspectiva y sus cadenas de conexión:
b) Security dimension
La dimensión de seguridad se aplica a los datos como si fuera un filtro. Por ejemplo: los usuarios de Australia solo pueden ver los datos relacionados con Australia.
Para ello, primero necesitáis una tabla que especifique qué puede ver cada usuario. Esta puede ser una tabla normal de base de datos, pero en nuestro caso crearemos una tabla ficticia utilizando la opción “add new dataset”:
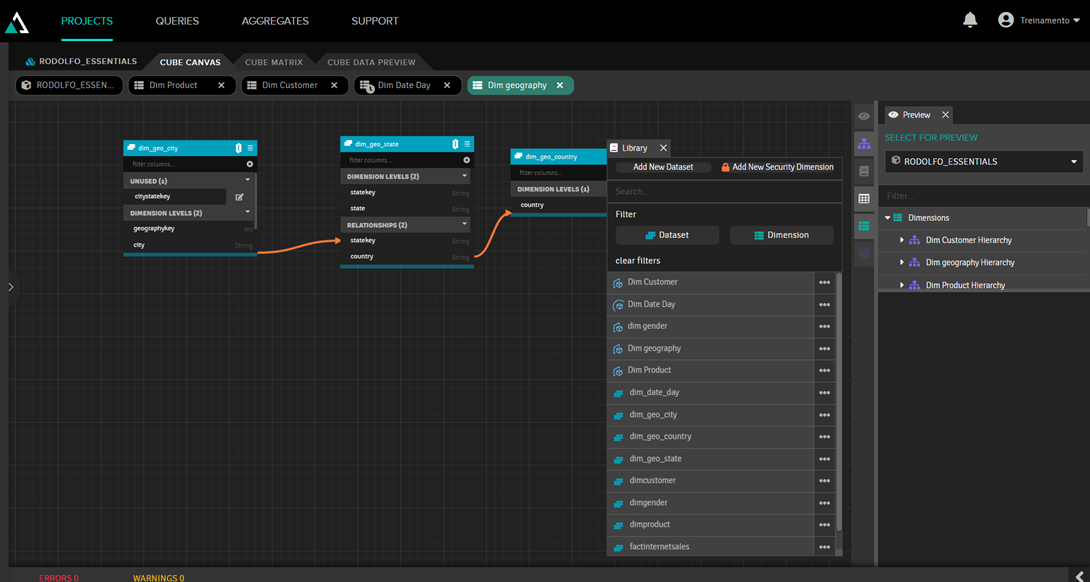
En este conjunto de datos, crearemos una consulta SQL con datos fijos:
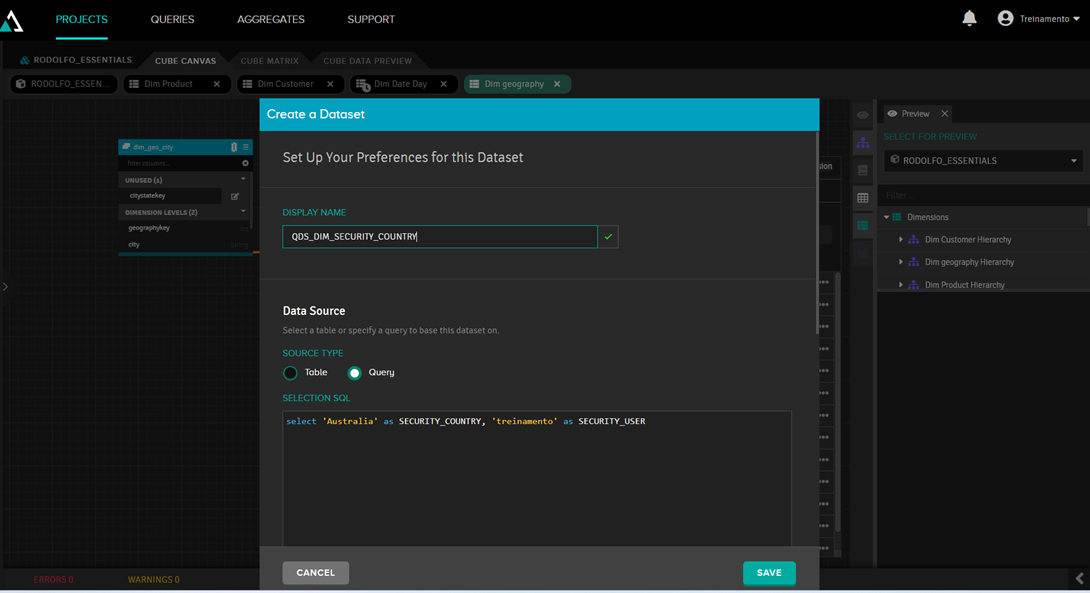
Después de esto, hacemos clic en “Add new security dimension” e introducimos los datos del conjunto de datos que acabamos de definir:
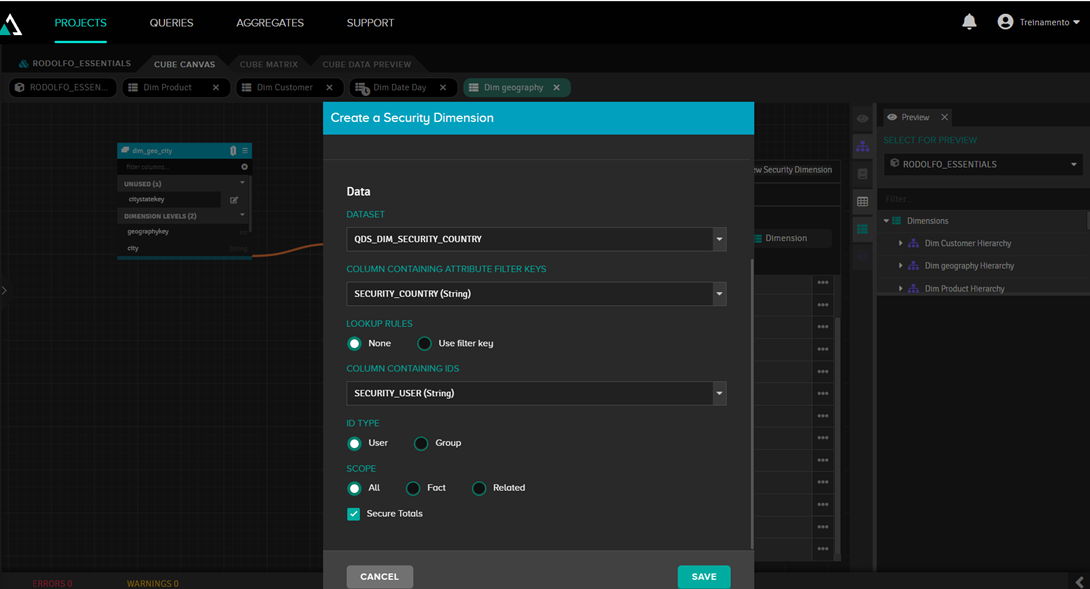
A continuación, lo vinculamos al campo “country”, ya que este es el campo que se filtrará:
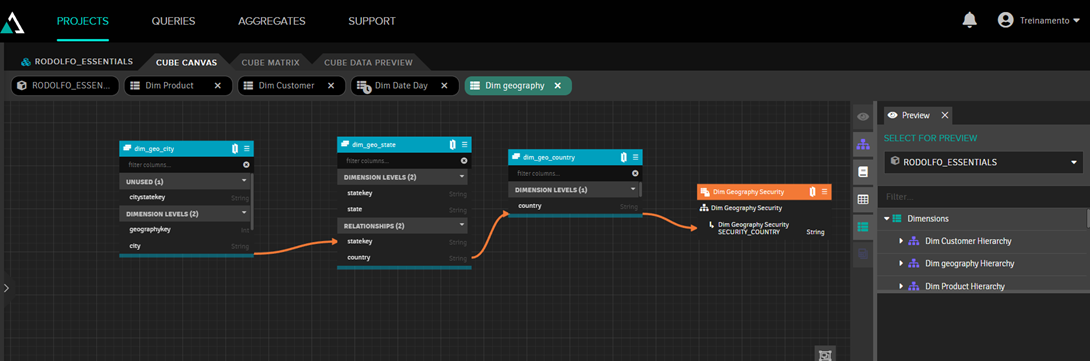
A partir de ahora, al ejecutar la tabla en Excel con el usuario “treinamento”, solo veremos los datos de Australia:

7. Aggregates
Las agregaciones en AtScale son tablas optimizadas que contienen datos pre-calculados y resumidos (como sumas, promedios o recuentos) a partir de conjuntos de datos de hechos. Estas tablas están diseñadas para mejorar el rendimiento de las consultas, ya que AtScale puede leer datos ya agregados en lugar de procesar miles de millones de filas de datos en bruto en tiempo real.
En la pestaña Aggregates, podemos ver las tablas de agregación creadas:
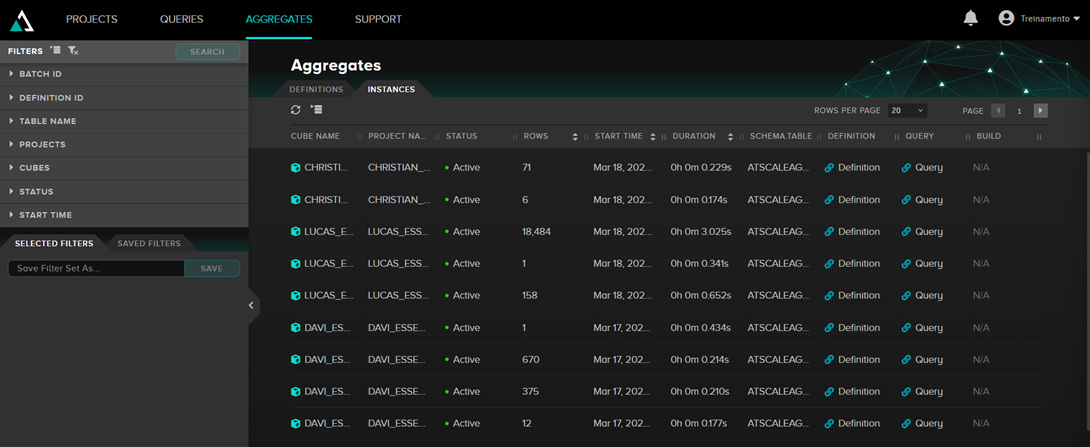
Cuando AtScale utiliza agregaciones, al observar la consulta que se está ejecutando, podéis ver que las tablas que se están leyendo son las denominadas ATSCALEAGG.as_agg_xxxx.
Estas tablas de agregación se almacenan en IRIS. En la configuración de AtScale, es posible definir en qué paquete se almacenarán (en el ejemplo anterior, ATSCALEAGG) e incluso si queremos almacenarlas en un namespace o en una instancia de IRIS separada.
AtScale decide si utiliza o no las agregaciones. El criterio más importante es si la tabla de agregación será realmente más pequeña que la tabla de hechos. Por defecto, AtScale utiliza una relación de 3, de modo que si la tabla de agregación es 3 veces más pequeña, se creará la tabla. Esto no es fijo y puede modificarse en la configuración de AtScale.
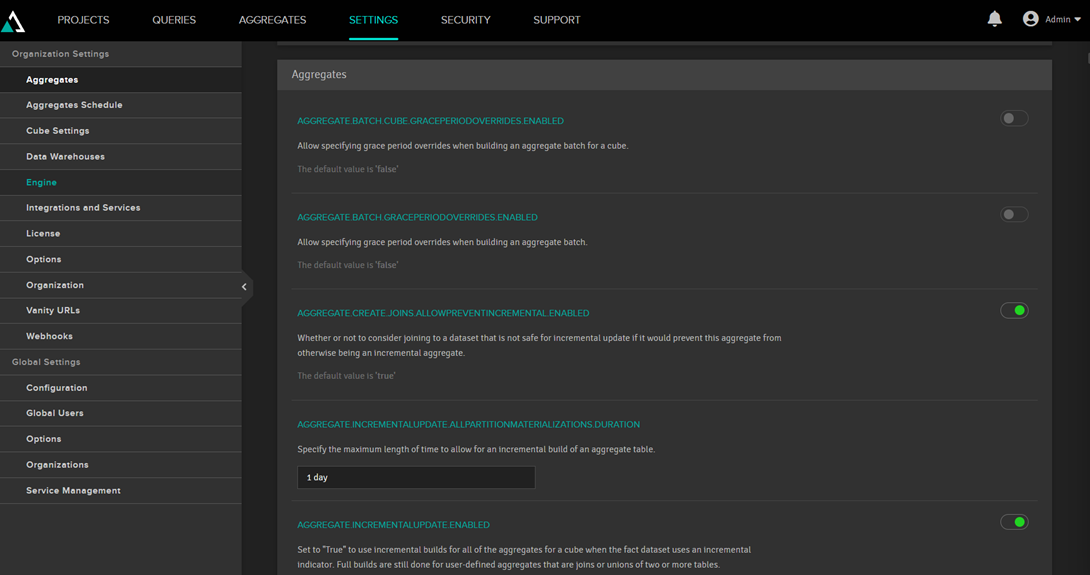
a) Actualización de las agregaciones
Las tablas de agregación deben actualizarse periódicamente para reflejar los cambios en los datos de hechos. Por defecto, esto se realiza a diario; se configura en los ajustes:
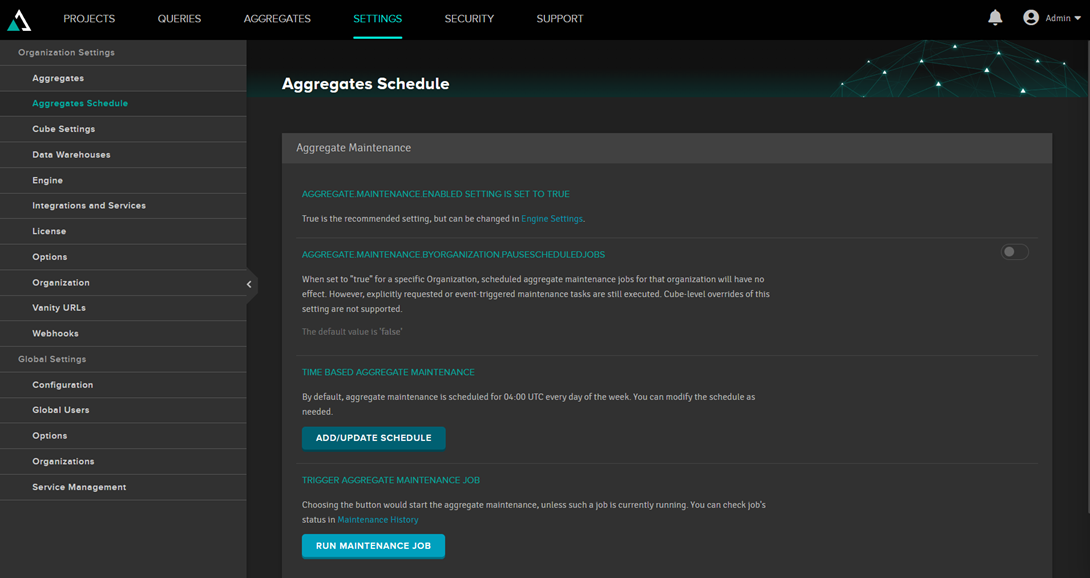
También es posible crear programaciones para la actualización:
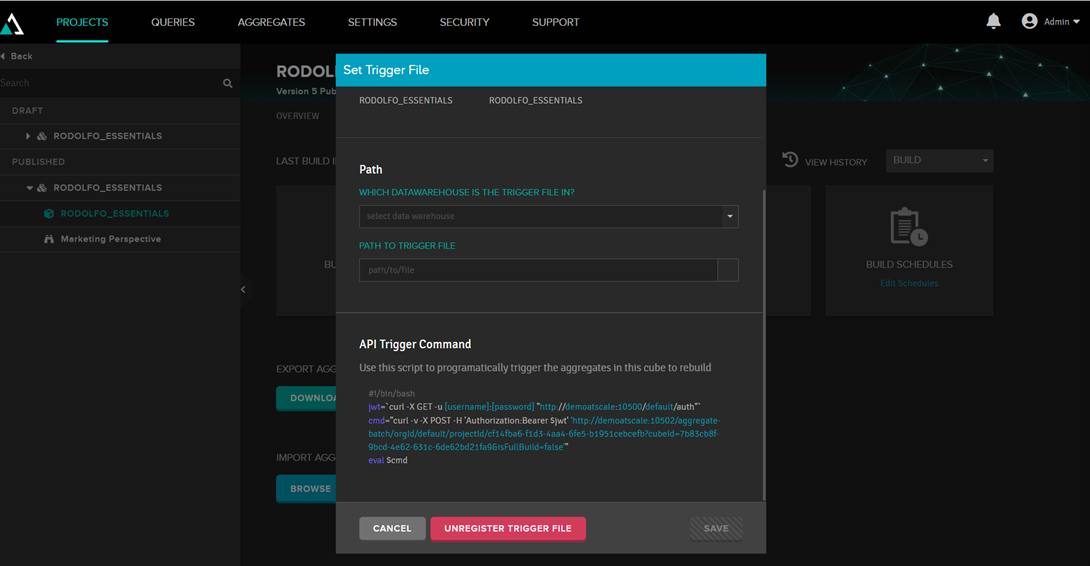
O podéis invocar un trigger para realizar esta actualización, de modo que podáis ejecutar la actualización desde algún programa externo:
Conclusión
Espero que este artículo haya mostrado algunas de las funcionalidades de Adaptive Analytics, ayudando a ofrecer una visión general de las capacidades de esta herramienta.