Visión general de la IA Generativa - Parte 1
.png)
La inteligencia artificial generativa es una inteligencia artificial capaz de generar texto, imágenes u otros datos utilizando modelos generativos, a menudo en respuesta a indicaciones o "prompts". Los modelos de IA generativa aprenden los patrones y la estructura de sus datos de entrenamiento y luego generan nuevos datos con características similares.
La IA generativa es capaz de crear texto, imágenes y otros tipos de contenido. Lo que la convierte en una tecnología fantástica es que democratiza el uso de la IA; cualquiera puede utilizarla con tan solo una indicación escrita en lenguaje natural.
Cómo funcionan los modelos de lenguaje a gran escala (Large Language Models o LLMs en sus siglas en inglés):
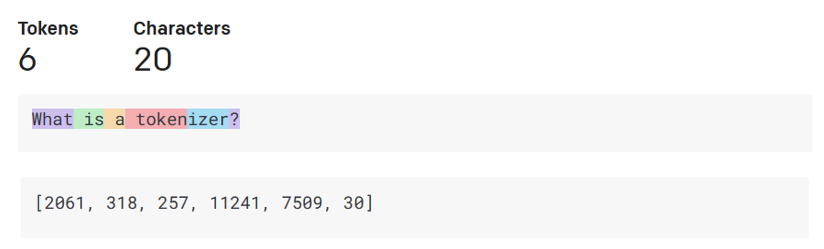
- Tokenizador, de texto a números: Los modelos de lenguaje a gran escala reciben un texto como entrada y generan un texto como salida. Sin embargo, al ser modelos estadísticos, funcionan mucho mejor con números que con secuencias de texto. Por eso, cada entrada al modelo es procesada por un tokenizador antes de ser utilizada por el modelo central. Un token es un fragmento de texto que consiste en un número variable de caracteres, por lo que la tarea principal del tokenizador es dividir la entrada en un conjunto de tokens. Luego, cada token se asigna a un índice de token, que es la codificación numérica del fragmento original de texto.
- Predicción de tokens de salida: Dado un número de tokens como entrada (con un máximo de n que varía de un modelo a otro), el modelo es capaz de predecir un token como salida. Este token se incorpora a la entrada de la siguiente iteración, en un patrón de ventana expansiva, lo que permite ofrecer una mejor experiencia de usuario al obtener una o varias frases como respuesta. Esto explica por qué, si alguna vez habéis jugado con ChatGPT, quizá habréis notado que a veces parece que se detiene a mitad de una frase.
- Proceso de selección, distribución de probabilidades: El token de salida es seleccionado por el modelo según su probabilidad de aparecer después de la secuencia de texto actual. Esto se debe a que el modelo predice una distribución de probabilidad sobre todos los posibles "siguientes tokens", calculada en función de su entrenamiento. Sin embargo, no siempre se selecciona el token con mayor probabilidad de la distribución resultante. Se añade un grado de aleatoriedad a esta elección, de manera que el modelo actúa de forma no determinista, lo que significa que no obtenemos exactamente la misma salida para una misma entrada. Este grado de aleatoriedad se añade para simular el proceso de pensamiento creativo y se puede ajustar utilizando un parámetro del modelo llamado temperatura.
En el próximo artículo realizaremos demostraciones prácticas.
Gracias