QuinielaML - Captura de datos con Embedded Python
Proseguimos con la serie de artículos basados en la aplicación QuinielaML.
.png)
En el artículo de hoy describiré como trabajar con la funcionalidad de Embedded Python disponible en los productos de InterSystems.
Embedded Python nos permite la utilización de Python como lenguaje de programación dentro de nuestras producciones, pudiendo sacar provecho de todas las funcionalidades disponibles en Python. Aquí podéis ampliar información al respecto.
Antes de nada recordemos cómo es el diseñor de la arquitectura de nuestro proyecto:
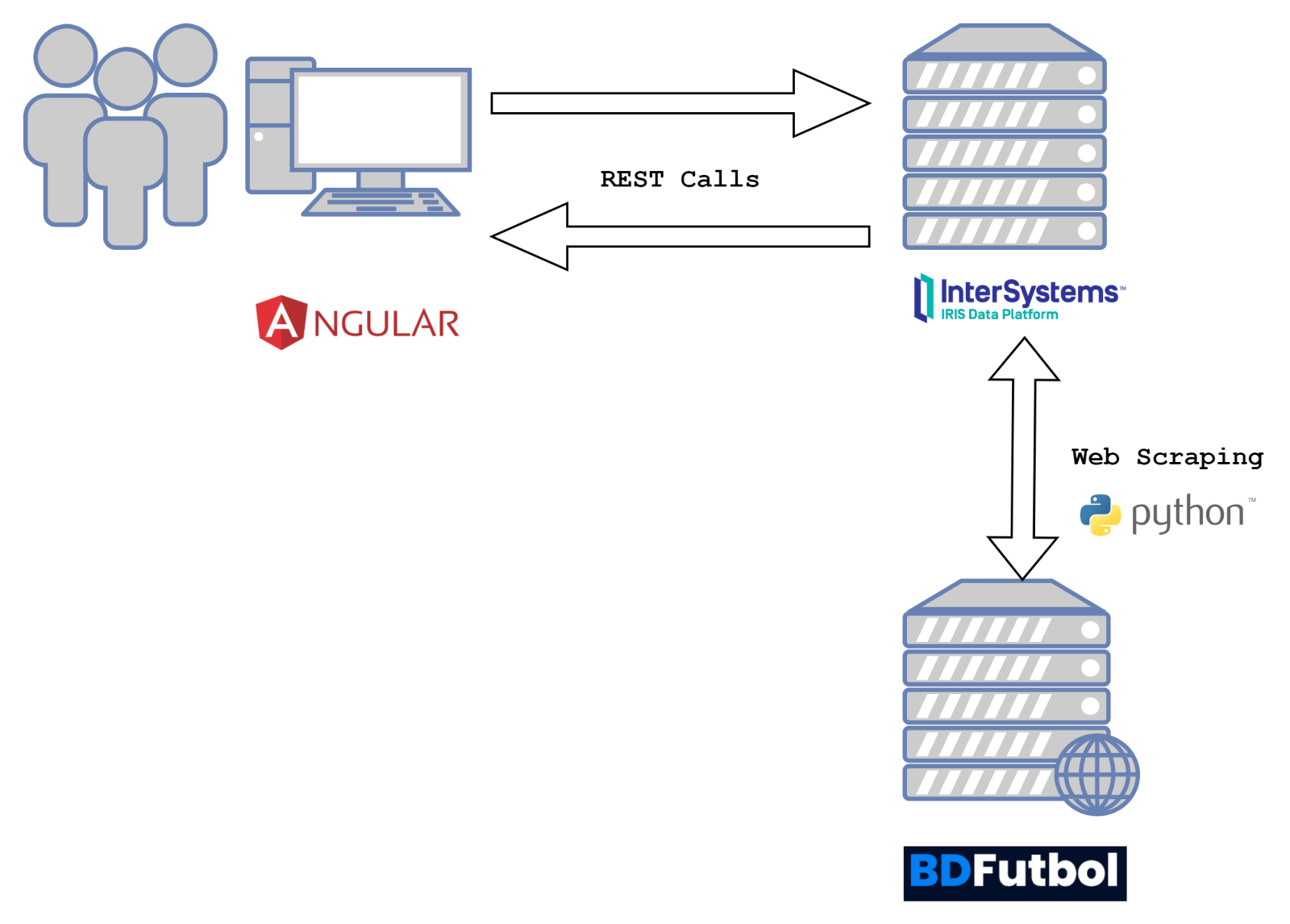
Problemática
En nuestro caso necesitamos obtener los resultados históricos de los partidos de Primera y Segunda División desde el año 2000. Hemos encontrado una página web BDFutbol, que nos proporciona todos esos datos, por lo que el web scraping parece lo más oportuno.
¿Qué es web scraping?
Web scraping es la técnica de capturar la información de las páginas web de forma automática simulando la navegación del mismo modo que lo realizaría un humano.
Para poder realizar el web scraping debemos buscar dos tipos de librerías, la primera que nos permita invocar las URLs de las que deseamos obtener la información y la segunda que nos permita recorrer la página web capturada y extraer la información necesaria. Para el primer caso usaremos la librería requests, mientras que para el segundo hemos encontrado beautifulsoup4, podéis echar un ojo a su documentación.
Configuración de Embedded Python en Docker
Para poder hacer uso de las librerías de Python desde nuestra instancia de IRIS en Docker deberemos añadir los siguientes comandos en nuestro archivo Dockerfile:
RUN apt-get update && apt-get install -y python3
RUN apt-get update && \
apt-get install -y libgl1-mesa-glx libglib2.0-0Con estos comandos estamos instalando Python en nuestro contenedor, a continuación instalaremos las librerías necesarias y que hemos registrado en el archivo requirements.txt
beautifulsoup4==4.12.2
requests==2.31.0Para instalarlo bastará con el siguiente comando en nuestro Dockerfile:
RUN pip3 install -r /requirements.txtYa tendríamos todo preparado en nuestro contenedor para utilizar las librerías de Python necesarias en nuestra producción.
Configuración de la producción
El primer paso será el de configurar en nuestra clase responsable de recibir las llamadas desde el frontend un método específico para gestionar las solicitudes de importación de los datos:
Class QUINIELA.WS.Service Extends %CSP.REST
{
Parameter HandleCorsRequest = 0;
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "https://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/getPrediction" Method="GET" Call="GetPrediction" />
<Route Url="/import" Method="GET" Call="ImportRawMatches" />
<Route Url="/getStatus/:operation" Method="GET" Call="GetStatus" />
<Route Url="/prepare" Method="GET" Call="PrepareData" />
<Route Url="/train" Method="GET" Call="TrainData" />
<Route Url="/getReferees" Method="GET" Call="GetReferees" />
<Route Url="/getTeams" Method="GET" Call="GetTeams" />
<Route Url="/saveMatch" Method="POST" Call="SaveMatch" />
<Route Url="/deleteMatch/:matchId" Method="DELETE" Call="DeleteMatch" />
<Route Url="/saveResult" Method="POST" Call="SaveResult" />
<Route Url="/getMatches/:division" Method="GET" Call="GetMatches" />
</Routes>
}Toda llamada con URL acabada en /import se gestionará desde el método ImportRawMatches, veamos el método con más detalle:
ClassMethod ImportRawMatches() As %DynamicObject
{
Try {
Do ##class(%REST.Impl).%SetContentType("application/json")
If '##class(%REST.Impl).%CheckAccepts("application/json") Do ##class(%REST.Impl).%ReportRESTError(..#HTTP406NOTACCEPTABLE,$$$ERROR($$$RESTBadAccepts)) Quit
set newRequest = ##class(QUINIELA.Message.OperationRequest).%New()
set newRequest.Operation = "Import"
set status = ##class(Ens.Director).CreateBusinessService("QUINIELA.BS.FromWSBS", .instance)
set response = ##class(QUINIELA.Message.ImportResponse).%New()
set response.Status = "In Process"
set response.Operation = "Import"
set status = instance.SendRequestAsync("QUINIELA.BP.ImportBPL", newRequest, .response)
if $ISOBJECT(response) {
Do ##class(%REST.Impl).%SetStatusCode("200")
return response.%JSONExport()
}
} Catch (ex) {
Do ##class(%REST.Impl).%SetStatusCode("400")
return ex.DisplayString()
}
}Como podemos ver estamos invocando al BPL ImportBPL de forma asíncrona, de tal forma que evitamos posibles problemas de timeout. Echemos un vistazo al diseño de la producción:
.png)
Abramos ImportBPL y veamos como gestionamos la importación de los partidos:
.png)
En una primera tarea creamos un mensaje que nos indique el estado en el que se encuentra la importación, a continuación invocamos a un Business Operation que se encargará de limpiar las tablas encargadas del almacenamiento de los datos de los partidos, una vez concluido y confirmado el éxito en la preparación de las tablas pasaremos a la parte en la que realizaremos el web scraping:
.png)
Como podéis observar en el flujo de tareas lanzaremos de forma asíncrona una llamada al Business Operation QUINIELA.BO.ImportBO en el que mediante Python recuperaremos la información de resultados históricos. Para acelerar la recuperación de los datos hemos dividido la recuperación de los resultados en dos tareas asíncronas, una para Primera División y otra para Segunda que se ejecutarán en paralelo.
Método para la importación de datos mediante Python
A continuación vamos a analizar el Class Method que se encarga de la realización del Web scraping.
ClassMethod ImportFromWeb(division As %String) As %String [ Language = python ]
{
from os import path
from pathlib import PurePath
import sys
from bs4 import BeautifulSoup
import requests
import iris
directory = '/shared/files/urls'+division+'.txt'
responses = 1
with open(directory.replace('\\', '\\\\'), 'r') as fh:
urls = fh.readlines()
urls = [url.strip() for url in urls] # strip `\n`
for url in urls:
file_name = PurePath(url).name
file_path = path.join('.', file_name)
raw_html = ''
try:
response = requests.get(url)
if response.ok:
raw_html = response.text
html = BeautifulSoup(raw_html, 'html.parser')
for match in html.body.find_all('tr', 'jornadai'):
count = 0
matchObject = iris.cls('QUINIELA.Object.RawMatch')._New()
matchObject.Journey = match.get('data-jornada')
for specificMatch in match.children:
if specificMatch.name is not None and specificMatch.name == 'td' and len(specificMatch.contents) > 0:
match count:
case 0:
matchObject.Day = specificMatch.contents[0].text
case 1:
matchObject.LocalTeam = specificMatch.contents[0].text
case 2:
if specificMatch.div is not None and specificMatch.div.a is not None and specificMatch.div.a.contents is not None and len(specificMatch.div.a.contents) > 1:
matchObject.GoalsLocal = specificMatch.div.a.contents[0].text
matchObject.GoalsVisitor = specificMatch.div.a.contents[1].text
case 3:
matchObject.VisitorTeam = specificMatch.contents[0].text
case 5:
matchObject.Referee = specificMatch.contents[0].text
matchObject.Division = division
count = count + 1
if (matchObject.Day != '' and matchObject.GoalsLocal != '' and matchObject.GoalsVisitor != ''):
status = matchObject._Save()
except requests.exceptions.ConnectionError as exc:
print(exc)
return exc
return responses
}Veamos ahora en detalle las líneas más relevantes de dicho método.
- Importación de las librerías request, BeautifulSoup e iris necesarias de Python:
from bs4 import BeautifulSoup import requests import iris
- Invocación de la URL y captura de su respuesta en una variable:
response = requests.get(url) if response.ok: raw_html = response.text html = BeautifulSoup(raw_html, 'html.parser')
- Análisis y extracción de los datos relevantes de cada partido y creación de un objeto de tipo QUINIELA.Object.RawMatch que será almacenado en la base de datos de IRIS:
for match in html.body.find_all('tr', 'jornadai'): count = 0 matchObject = iris.cls('QUINIELA.Object.RawMatch')._New() matchObject.Journey = match.get('data-jornada') for specificMatch in match.children: if specificMatch.name is not None and specificMatch.name == 'td' and len(specificMatch.contents) > 0: match count: case 0: matchObject.Day = specificMatch.contents[0].text case 1: matchObject.LocalTeam = specificMatch.contents[0].text case 2: if specificMatch.div is not None and specificMatch.div.a is not None and specificMatch.div.a.contents is not None and len(specificMatch.div.a.contents) > 1: matchObject.GoalsLocal = specificMatch.div.a.contents[0].text matchObject.GoalsVisitor = specificMatch.div.a.contents[1].text case 3: matchObject.VisitorTeam = specificMatch.contents[0].text case 5: matchObject.Referee = specificMatch.contents[0].text matchObject.Division = division count = count + 1 if (matchObject.Day != '' and matchObject.GoalsLocal != '' and matchObject.GoalsVisitor != ''): status = matchObject._Save()
Como podéis ver hemos importado la librería de Python IRIS que nos permite la utilización de clases definidas en nuestro Namespace, de tal forma que podemos ir poblando nuestra base de datos directamente desde el método en Python. Con este sencillo método ya podemos recuperar todos los datos que necesitamos de una forma sencilla y ágil.
Esta funcionalidad de web scraping nos puede resultar muy útil para integraciones de sistemas cerrados en los que no sea posible otro modo de interconexión.
Espero que esta funcionalidad os pueda resultar de utilidad y si tenéis alguna pregunta no dudeis en escribir un comentario.
¡Gracias por vuestra atención!